
Pyccuracy provides an easy-to-read set of operations to drive the front end of a web application. This recipe shows how to use it to drive a shopping cart application and verify application functionality.
With these steps, we will explore the basics of writing a Pyccuracy test.
- Create a new file called
recipe36.acc. - Create a story for loading items into the shopping cart.
As a store customer I want to put things into my cart So that I can verify the store's functionality.
- Add a scenario where the empty cart is looked at in detail, with a confirmed balance of $0.00.
Scenario 1 - Inspect empty cart in detail Given I go to "http://localhost:8000" When I click "Cart" link and wait Then I see that current page contains "Your cart is empty" And I see that current page contains "0 - $0.00" - Add another scenario where a book is selected, and two of them are added to the cart.
Scenario 2 - Load up a cart with 2 of the same Given I go to "http://localhost:8000" When I click "Science Fiction" link And I click "Robots Attack!" link and wait And I fill "quantity" textbox with "2" And I click "addcart" button and wait And I click "Cart" link and wait Then I see that current page contains "Robots Attack!" And I see "quantity" textbox contains "2" And I see that current page contains "<td align="center">$7.99</td>" And I see that current page contains "<td align="center">$15.98</td>" And I see that current page contains "<td>$15.98</td>" - Run the story by typing
pyccuracy_console -p recipe36.acc.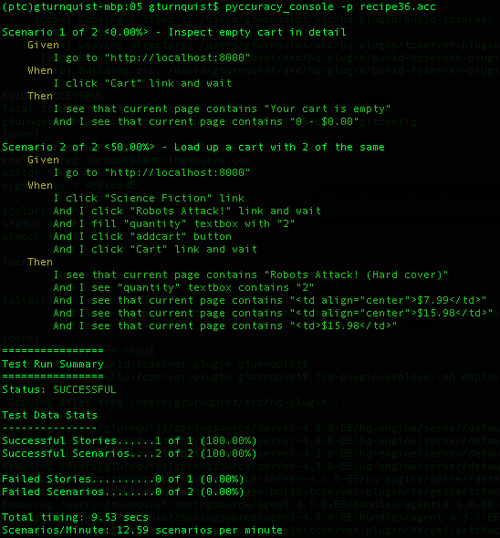
Pyccuracy has a lot of built-in actions based on driving the browser or reading the page. These actions are patterns used to parse the story file, and generate commands sent to the selenium server, which in turn drives the browser, and then reads the results of the page.
The key is picking the right text to identify the element being actioned or read.
The key is picking the right identifier and element type. With good identifiers, it is easy to do things like: I click on Cart link. Did you notice the issue we had with drilling into the shopping cart table? The HTML <table> tag had no identifier, which made it impossible for us to pick. Instead, we had to look at the whole page, and do a global search for some markup.
This makes it harder to read the test. A good solution is to alter the web app to include an ID in the <table> tag. Then we narrow down our acceptance criteria to just the table. With this application it was okay, but with complex web applications it will surely be much harder to find the exact bit of text we are looking for without good IDs.
This raises an interesting question: should an application be amended to support a test? Simply put, yes. It isn't a major upheaval to add some good identifiers to key HTML elements to support testing. It didn't involve major design changes to the application. The net result was easier to read test cases and better automated testing.
This begs another question: what if making the application more testable DID involve major design changes? This could be viewed as a major interruption in work. Or maybe it's a strong hint that our design has components that are too tightly coupled or not cohesive enough.
In software development, coupling and cohesiveness are subjective terms that aren't very measurable. What can be said is that applications that don't lend themselves to testing are often monolithic, hard to maintain, and probably have circular dependencies, which implies that it will be much harder for us to make changes (as developers) to meet needs without impacting the entire system.
Of course, all of this would be a big leap from our recipe's situation, where we simply lack an identifier for an HTML table. However, it's important to think what if we need more changes than something so small.