
18
Internal Structures and Operating Principles of Linux Real-Time Extensions
CONTENTS
18.3 The PREEMPT RT Linux Patch
The scheduling analysis introduced in previous chapters relies on a computing model with preemptible tasks. As soon as an event makes any task computable, the latter will contend for the processor, possibly becoming the current task in the case where its priority is greater than all the other computable tasks at that time. While in the model the task switch is considered instantaneous, in real-world systems this is not the case, and the delay between event occurrence and the consequent task switch may significantly alter the responsiveness of the system, possibly breaking its real-time requirements. This chapter will discuss this issue with reference to the Linux operating system.
In the last years Linux evolved toward improved responsiveness, and the current 2.6 version can be considered as a Soft Real-Time System. In a Soft real-time system, the latency of the system to external events can be considered almost always bounded even if this cannot be ensured for all cases. Observe that soft real-time requirements cover a wide range of embedded applications, in particular applications where the system is used in a control loop. In a feedback control application, the system acquires signals from the sensors, computes a control algorithm, and produces a set of reference values for the actuators of the controlled plant. In this case, those rare situations in which the system response does not occur within the given time limit will introduce a delayed update in the actuator references, which may be considered as an added noise in the control chain. Provided the stability margin of the system is large enough and that the likelihood of the deadline miss is low, this fact will not perturb the quality of the control.
Recent developments in Linux kernel add further real-time features to the mainstream 2.6 kernel distribution. Even if currently available as separate patches, they are being integrated in the kernel, and it is expected that they will become an integral part of the Linux kernel.
In addition to the evolution of the Linux kernel toward real-time responsiveness, other real-time extension of Linux have been developed following an alternative approach, and several solutions have been based on the development of a nanokernel between the hardware and the Linux kernel. The nanokernel will react to system events (interrupts) in real time, delegating non-real-time operations to the Linux kernel.
This chapter will first discuss the aspects of the Linux kernel organization that adversely affect real-time responsiveness, and will then show how Linux evolved to overcome such effects. Afterwards, two nano-kernel based extension real-time of Linux, Xenomai [30] and RTAI [63], will be described to illustrate a different approach to achieving real-time responsiveness.
18.1 The Linux Scheduler
The Linux scheduler represents the “heart” of the kernel and is responsible for the selection of the next process to be executed. Before discussing how it works, it is important to understand when the scheduler is invoked. Linux does not really make any distinction between a process and a thread from the scheduling point of view. Therefore, in the following we shall refer in a generic way to tasks, with the assumption that a task may refer to either a process or a thread.
The kernel code provides routine schedule() that can be invoked in a system routine or in response to an interrupt. In the former case, the running task voluntarily yields the processor, for example, when issuing an I/O operation or waiting on a semaphore. In these cases, the kernel code running in the task’s context will call schedule() after starting the I/O operation or when detecting that the semaphore count is already zero. More in general, schedule() will be called by the kernel code whenever the current task cannot proceed with computation and therefore the processor has to be assigned to another task. schedule() can also be called by an Interrupt Service Routine (ISR) activated in response to an interrupt. For example, if the interrupt has been issued by an I/O device to signal the termination of a pending I/O operation, the associated ISR, after handling the termination of the I/O operation, will signal to the systems that the task that issued the I/O operation and that was put in the waiting task queue, is now ready and therefore may be eligible for processor usage, based on its current priority.
Among the interrupt sources, the timer interrupt has an important role in task scheduling management. In fact, since the timer regularly interrupts the system, at every system tick (normally in the range of 1–10 ms) the kernel can regularly take control of the processor via kernel routine scheduler_tick() and then adjust task time slices as well as update the priorities of non-real-time tasks, possibly assigning the processor to a new task.
Unless declared as a First In First Out (FIFO) task, every task is assigned a timeslice, that is, a given amount of execution time. Whenever the task has been running for such an amount of time, it expires and the processor can be assigned to another task of the same priority unless a higher-priority task is ready at that time. The Linux scheduler uses a queue of task descriptors, called the run queue, to maintain task specific information. The run queue is organized in two sets of arrays:
Active: Stores tasks that have not yet used their timeslice.
Expired: Stores tasks that have used their timeslice.
For every priority level, one active and one expired array are defined. Whenever the active array becomes empty, the two arrays are swapped, and therefore, the tasks can proceed to the next timeslice. Figure 18.1 shows the organization of the run queue. In order to be able to select the highest-priority task in constant time, a bitmap of active tasks is used, where every bit corresponds to a given priority level and defines the presence or absence of ready tasks at that priority. With this organization of the run queue, adopted since kernel version 2.4.20, the complexity in the management of the queue is O(1), that is, the selection of a new task for execution as well as the reorganization of the queue, can be performed in constant time regardless of the number of active tasks in the system. Kernel routine scheduler_tick(), called at every timer interrupt, performs the following actions:
If no task is currently running, that is, all tasks are waiting for some event, the only action is the update of the statistics for every idle task. Statistics such as the amount of time a task has been in wait state are then used in the computation of the current priority for non-real-time tasks.
Otherwise, the scheduler checks the current task to see whether it is a real-time task (with priority above a given threshold). If the task is a real-time task, and if it has been scheduled as a FIFO task, no timeslice check is performed. In fact, a FIFO task remains the current task even in the presence of other ready tasks of the same priority. Otherwise, the task has been scheduled as round-robin and, as the other non-real-time tasks, its timeslice field is decremented. If the timeslice field goes to 0, the task descriptor is moved to the expired array and, if for that priority level the active array is empty, the two arrays are swapped, that is, a new timeslice starts for the tasks at that priority.
Based on the new statistics, the priority for non-real-time tasks are recalculated. Without entering the details of the dynamic priority computation, the priority is adjusted around a given base value so that tasks that are more likely to be in wait state are rewarded with a priority boost. On the other side, the priority of computing intensive tasks, doing very few I/O operations, tends to be lowered in order to improve the user-perceived responsiveness of the system even if at the price of a slightly reduced overall throughput.
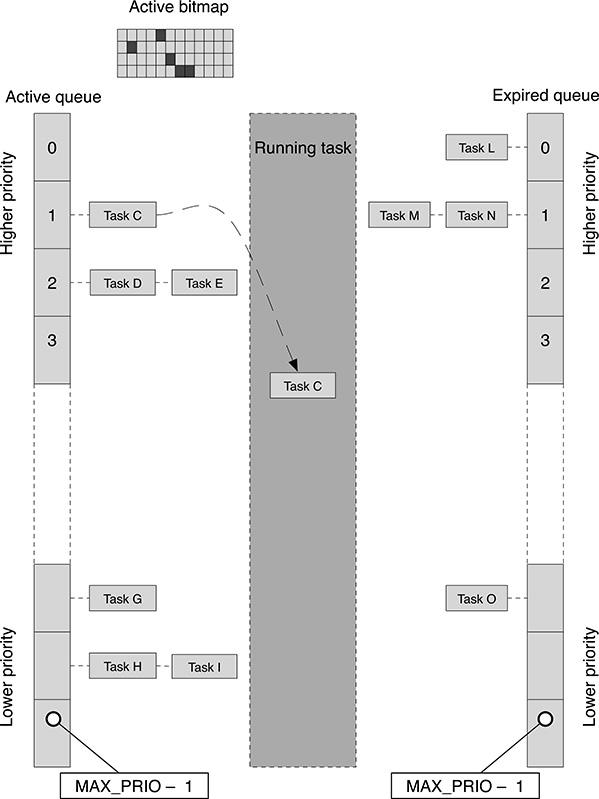
FIGURE 18.1
Data organization of the Linux O(1) scheduler.
Whenever scheduler_tick() detects that a task other than the current one is eligible to gain processor ownership, it passes control to kernel routine schedule(), which selects the new running task, possibly performing a context switch. Recall that routine schedule() can also be called by system routines or device drivers whenever the current task needs to be put in wait state, waiting for the termination of an I/O or synchronization operation, or, conversely, when a task becomes newly ready because of the termination of an I/O or synchronization operation. The actions performed by schedule() are the following:
It finds the highest-priority ready task at that time, first by checking the active bitmap to find the nonempty active queue at the highest priority (re-call that in Linux lowerpriority numbers correspond to higher priorities). The task at the head of the corresponding active queue is selected: if it corresponds to the current task, no further action is required and
schedule()terminates; otherwise, a context switch occurs.To perform a context switch, it is necessary to save first the context of the current task. Recall that the task context is represented by the set of processor registers, the kernel stack, that is, the stack (8 Kbytes) used by the kernel code within the specific task context, and the memory-mapping information represented by the task-specific content of the page table. In particular, switching the kernel stack only requires changing the content of the stack pointer register.
After saving the context of the current task, the context of the new task is restored by setting the current content of the page table and by changing the content of the stack pointer register to the kernel stack (in the task descriptor) of the new task. As soon as the machine registers are restored, in particular the Program Counter, the new task resumes, and the final part of the
schedule()routine is executed in the new context.
The replacement of the page table is the most time-consuming operation in a context switch. Observe that this is not always the case because the two tasks may refer to two different threads of the same process that share the same mapping. In this case, the context switch is much faster since no page table update is required.
Linux kernel routines use a reserved section of the virtual address space, that is, all the virtual addresses above a given one. As for user address space, the kernel address space is virtual, that is, it is subject to Memory Management Unit (MMU) address translation. However, while user address mapping may be different from task to task, kernel memory mapping never changes. Therefore, kernel routines can exchange pointers among tasks with the guarantee that they consistently refer to the same objects in memory. Recall that it is not possible to exchange memory pointers in user tasks because the same virtual address may refer to different physical memory due to the task-specific page table content.
18.2 Kernel Preemption
In addition to user processes and threads, the scheduler will handle another kind of tasks, such as kernel threads. A kernel thread runs only in kernel mode, and its memory context only includes the mapping for kernel memory pages. For this reason, the page table information for kernel threads does not need to be changed when a kernel thread is involved in a context switch. In this case, the context switch is a fast operation since it only requires swapping the stack pointer contents to switch the task-specific kernel stack, and to save and copy the general-purpose registers. We shall see later in this section how kernel threads have been used in Linux to reduce the latency of the system.
In order to avoid race conditions corrupting its data structures, it is necessary to protect kernel data against concurrent access. This has been achieved up to version 2.4 by making the kernel non-preemptible, that is, by ensuring that the kernel code cannot be interrupted. Observe that this does not mean disabling interrupts, but in any case, the interrupt service routine cannot directly invoke the scheduler; rather, they will set a scheduler request flag, when required, which will be checked upon the termination of the kernel code segment. On multiprocessor (multicore) systems, things are more complicated because the kernel data structure may be concurrently accessed by kernel code running on other processors. In principle, kernel data integrity could be achieved by disabling kernel preemption on all processors, but this would represent an overkill because the whole system would be affected by the fact that a single processor is running kernel code. To protect kernel data structures, a number of spinlocks are used. Every spinlock repeatedly tests and sets an associated flag: if the flag is already set, it means that another processor is running the associated critical section, and so, the requesting processor loops until the flag has been reset by the previous owner of the critical section.
Non-preemptible kernel represents the main reason for the non-real-time behavior of Linux up to version 2.4. In fact, if an interrupt is received by the system during the execution of kernel code, the possible task switch triggered by the interrupt and therefore the reaction of the system to the associated event was delayed for the time required by the kernel to complete its current action. The following versions of Linux introduced kernel preemption, that is the possibility of the kernel code being interrupted. The kernel cannot, of course, be made preemptible tout court because there would be the risk of corrupting the kernel data structures. For this reason, the kernel code will define a number of critical sections that are protected by spinlocks. A global counter, preempt_count, keeps track of the currently active critical sections. When its value equals to zero, the kernel can be interrupted; otherwise, interrupts are disabled. preempt_count is incremented every time a spinlock is acquired, and decremented when it is released.
Suppose a high-priority real-time task τ2 is waiting for an event represented by an interrupt that arrives at time T1 while the system is executing in kernel mode within the context of a low-priority task τ1, as shown in Figure 18.2. In a non-preemptible kernel, the context switch will occur only at time T2, that is, when the kernel section of task τ1 terminates. Only at that time, will the scheduler be invoked, and therefore, task τ2 will gain processor ownership with a delay of T2 − T1, which can be tens or even hundreds of milliseconds. In a preemptible kernel, it is not necessary to wait until the whole kernel section of task τ2 has terminated. If the kernel is executing in a preemptible section, as soon as the interrupt is received, the ISR is soon called and schedule() invoked, giving the processor to task τ1. In the case where the kernel is executing a critical section, the interrupt will be served at time , that is, when the kernel code exited the critical section. In this case, the delay experienced by task τ2 is , which is normally very short since the code protected by spinlocks is usually very limited.
An important consequence of kernel preemptability is that kernel activities can now be demanded to kernel threads. Consider the case in which an I/O device requires some sort of kernel activity in response to an interrupt, for example, generated by the disk driver to signal the termination of the Direct Memory Access (DMA) transfer for a block of data. If such activity were carried out by the ISR routine associated with the interrupt, the processor would not be able to perform anything else even if a more urgent task becomes ready in the meantime. If, after performing a minimal action, the ISR demanded the rest of the required activity from a kernel task, there would be the chance for a more urgent task to gain processor ownership before the related activity is terminated.
Spinlocks represent the most basic locking mechanism in the kernel and, as such, can be used also in ISR code. If the kernel code is not associated with ISR but runs within the context of a user or a kernel task, critical sections can be protected by semaphores. Linux kernel semaphores provide two basic function: up() and down(). If a task calls down() for a semaphore, the count field in the semaphore is decremented. If that field is less than 0, the task calling down() is blocked and added to the semaphore’s waiting queue. If the field is greater than 0, the task continues. Calling up() the task increments the count field and, if it becomes greater than 0, wakes a task waiting on the semaphore’s queue. Semaphores have the advantage over spinlocks of allowing another task gain processor usage while waiting for the resource, but cannot be used for synchronization with ISRs (the ISR does not run in the context of any task). Moreover, when the critical section is very short, it may be preferable to use spinlocks because they are simpler and introduce less overhead.
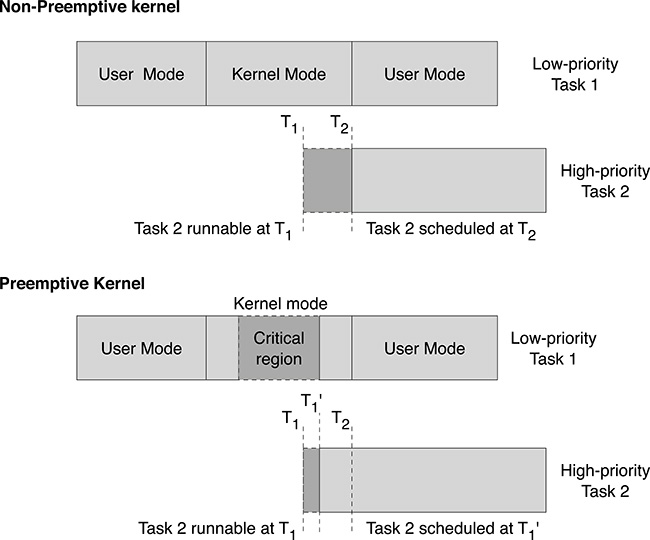
FIGURE 18.2
Latency due to non-preemptible kernel sections.
18.3 The PREEMPT_RT Linux Patch
The kernel preemtability introduced in Linux kernel 2.6 represents an important step toward the applicability of Linux in real-time applications because the delay in the system reaction to events is shorter and more deterministic. In this case, system latency is mainly due to
critical sections in the kernel code that are protected by spinlocks; preemption is in fact disabled as long as a single spinlock is active;
ISRs running outside any task context, and therefore potentially introducing delays in the system reaction to events because the scheduler cannot be invoked until no pending interrupts are present.
The PREEMPT_RT Linux patch represents one step further toward hard real-time Linux performance. Currently, PREEMPT_RT is available as a separate patch for Linux, but work is in progress to integrate the new functionality into the Linux mainstream distribution. The PREEMPT_RT provides the following features:
Preemptible critical section;
Priority inheritance for in-kernel spinlocks and semaphores;
Preemptible interrupt handlers.
In PREEMPT_RT, normal spinlocks are made preemptible. In this case, they are no more implemented as the cyclic atomic test and set but are internally implemented by a semaphore called rt-semaphore. This semaphore is implemented in a very efficient way if the underlying architecture supports atomic compare and exchange; otherwise, an internal spinlock mechanism is used. Therefore, the task entering a critical section can now be interrupted, the integrity of the section being still ensured since, if the new task tries to acquire the same lock, it will be put on wait. The impact of this different, semaphore-based implementation of the previous spinlock mechanism is not trivial since now spinlocks cannot be invoked with either preemption or interrupts disabled. In fact, in the case the spinlock resource is already busy and the task was put on wait, there would be no chance for other tasks to gain processor usage.
Another fact that may have an adverse effect in realtime performance is priority inversion. Consider for example the following sequence:
Low-priority task A acquires a lock;
Medium-priority task B starts executing preempting low-priority task A;
High-priority task C attempts to acquire the lock held by low-priority task A but blocks because of medium-priority task B having preempted low-priority task A.
Priority inversion can thus indefinitely delay a high-priority task. In order to avoid priority inversion, a possibility would be disabling preemptions so that, when task A acquires the lock, it cannot be preempted by task B. This works for “traditional” spinlocks but not for kernel semaphores. The other possibility is using priority inheritance by boosting the priority of task A to the highest priority among the tasks contending for that lock. In PREEMPT_RT, priority inheritance is provided for rt_semaphores used to implement spinlocks as well as for the other kernel semaphores.
We have already seen that a well-written device driver avoids defining lengthy ISR code. Rather, the ISR code should be made as short as possible, delegating the rest of the work to kernel threads. PREEMPT_RT takes one step further and forces almost all interrupt handlers to run in task context unless marked SA_NODELAY to cause it to run in interrupt context. By default, only a very limited set of interrupts is marked as SA_NODELAY, and, among them, only the timer interrupt is normally used. In this way, it is possible to define the priority associated with every interrupt source in order to guarantee a faster response to important events.
18.3.1 Practical Considerations
In summary, PREEMPT_RT currently represents the last step toward real-time responsiveness of the Linux kernel. The shorter the segments of non-interruptible kernel and interrupt-level code, the faster will be the system response. Figure 18.3 illustrates the evolution in the Linux kernel toward almost full preemtability.
It is, however, necessary that the application and the system be properly tuned to achieve the desired real-time behavior. Assume that the real-time application is composed of a number of threads and that the system consists of a multicore machine, then the steps to be taken for a proper configuration are the following:
Choose an appropriate organization for load balancing among cores. Depending on the complexity of the application, one or more cores can be designated to host the real-time application threads, leaving the others for the management of system activities such as network activity.
The selection of cores must be reflected in the application code.

FIGURE 18.3
The evolution of kernel preemption in Linux.The threads created by the application must be assigned to the selected core using the system routine
sched_setaffinity(). The arguments ofsched_setaffinity()are the task identifier and a processor mask that specifies the cores over which the Linux scheduler will let the thread run. Thread real-time priorities must also be set to ensure that the more important application thread can preempt lower priority ones.In order to avoid other tasks being scheduled over the cores selected for the application, it is necessary to instruct the Linux scheduler not to schedule tasks over the selected cores. This is achieved by the
isolcpuskernel configuration parameter. Observe that his setting is overridden by the CPU mask passed tosched_setaffinity(), so the combined use ofisolcpusandsched_setaffinity()allows running only the desired tasks over the selected processors. It is worth noting that a few kernel threads remain nevertheless resident on the selected core. Therefore it is necessary to assign a priority to the application task that is higher among those kernel threads.In order to avoid running unnecessary ISR code over the cores selected for the application, it is necessary to configure Linux accordingly. Interrupt dispatching is a feature that depends on the target architecture, and normally, an incoming interrupt is dispatched in a round-robin fashion among cores. Linux provides an architecture-independent way of configuring interrupt dispatching. The interrupt sources available in the system can be displayed by the shell command
cat /proc/interrupts. Every interrupt source is assigned a number n, and the file/proc/irq/<n>/smp affinitywill contain the processor mask for that interrupt source.
18.4 The Dual-Kernel Approach
We have seen so far how the evolution of Linux toward real-time responsiveness has been achieved by making its kernel more and more preemptive in order to achieve a fast response to system events. The complexity of the Linux kernel, however, makes such evolution a lengthy process, and several improvements have not been yet moved to the mainstream version because they still require extensive testing before the official release.
A different approach has been taken in several projects aiming at making Linux a real-time system. In this case, rather than changing the Linux kernel, a new software layer is added between the machine and the kernel. The key idea is simple: if system events such as interrupts are first caught by this software layer instead of being trapped by the original interrupt handlers of the kernel, there is a chance of serving them soon in case such events refer to some kind of real-time activity. Otherwise, the events are passed as they are to the Linux kernel that will serve them as usual. So, the added software layer takes control of the event management, “stealing” events related to real-time activity from the supervision of the Linux kernel.
This layer of software is often called a nanokernel because it behaves as a minimal operating system whose operation consists in the dispatching of interrupts and exceptions to other entities. At least two entities will operate on the top of the nanokernel: the real-time component, normally consisting in a scheduler for real-time tasks and a few interprocess communication facilities, and the non-real-time Linux kernel, carrying out the normal system activity.
In the following text we shall analyze two dual-kernel real-time extensions of Linux: Xenomai [30] and RTAI [63]. Both systems are based on Adeos [87], which stands for “Adaptive Domain Environment for Operating Systems” and can be considered a nanokernel.
18.4.1 Adeos
Adeos is a resource virtualization layer, that is, a software system that interfaces to the hardware machine and provides an Hardware Abstraction Layer (HAL). Adeos enables multiple entities, called domains, to exists simultaneously on the same machine. Instead of interfacing directly to the hardware, every domain relies on an Application Programming Interface (API) exported by Adeos to interact with the machine. In this way, Adeos can properly dispatch interrupts and exceptions to domains. A domain is a kernel-based software component that can ask the Adeos layer to be notified of incoming external interrupts, including software interrupts generated when system calls are issued by user applications. Normally, at least two domains will be defined: a real-time kernel application carrying out real-time activity, and a Linux kernel for the rest of the system activities. It is in principle possible to build more complex applications where more than one operating system is involved, each represented by a different domain. Adeos ensures that system events, including interrupts, are orderly dispatched to the various client domains according to their respective priority. So, a high-priority domain will receive system event notification before lower-priority domains and can decide whether to pass them to the other ones. All active domains are queued according to their respective priority, forming a pipeline of events (Figure 18.4). Incoming events are pushed to the head of the pipeline and progress down to its tail. Any pipeline stage corresponding to a domain can be stalled, which means that the next incoming interrupt will not be delivered to that domain, neither to the downstream domains. While a stage is being stalled, pending interrupts accumulate in the domain’s interrupt log and eventually get played when the stage gets unstalled. This mechanism is used by domains to protect their critical sections by interrupts. Recall that, in Linux, critical sections are protected also by disabling interrupts, thus preventing interrupt handler code to interfere in the critical section. If the Linux kernel is represented by an Adeos domain, critical sections are protected by stalling the corresponding pipeline stage. Interrupts are not delivered to downstream stages (if any), but upstream domains will keep on receiving events. In practice, this means that a real-time system running ahead of the Linux kernel in the pipeline would still be able to receive interrupts at any time with no incurred delay. In this way, it is possible to let real-time applications coexist with a non-real-time Linux kernel.
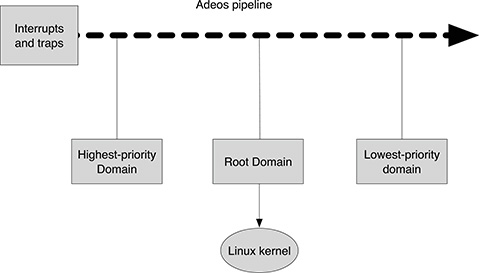
FIGURE 18.4
The Adeos pipeline.
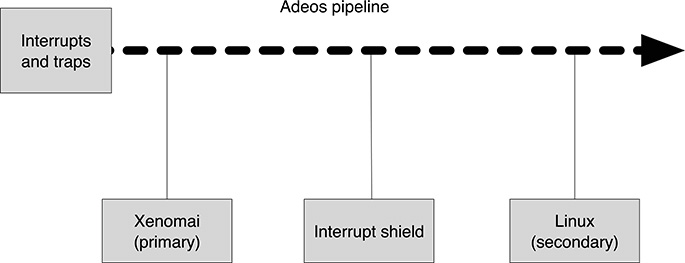
FIGURE 18.5
The Xenomai domains in the Adeos pipeline.
Implementing a HAL like Adeos from scratch would be a long and risky process due to the complexity of the kernel and the variety of supported hardware platforms. For this reason, Adeos developers took a canny approach, that is, they decided to use an already functional Linux kernel as a host for Adeos’ implementation. Adeos is implemented as a patch for the Linux kernel, and once the Adeos code has been integrated in the system, it will take control of the hardware, using most of the functionality of the HAL layer already provided by the Linux kernel. So, the Linux kernel carries out a twofold functionality within Adeos: it will provide low-level hardware management to Adeos code, and it will represent one of the domains in the Adeos pipeline. An Adeos-based realtime extension of Linux will therefore provide an additional domain carrying out real-time activity.
18.4.2 Xenomai
Xenomai is a real-time extension of Linux based on Adeos and defines three Adeos domains: the primary domain, which hosts the real-time nucleus including a scheduler for real-time applications; the interrupt shield, used to selectively block the propagation of interrupts; and the secondary domain, consisting in the Linux kernel (Figure 18.5). The primary domain receives all incoming interrupts first before the Linux kernel has had the opportunity to notice them. The primary domain can therefore use such events to perform real-time scheduling activities, regardless of any attempt of the Linux kernel to lock them, by stalling the corresponding pipeline stage to protect Linux kernel critical sections.
Xenomai allows running real-time threads, called Xenomai threads, either strictly in kernel space or within the address space of a Linux process. All Xenomai threads are known to the primary domain and normally run in the context of this domain, which is guaranteed to receive interrupts regardless of the activity of the secondary (Linux) domain. A Xenomai thread can use specific primitives for thread synchronization but is also free to use Linux system calls. In the latter case, the Xenomai thread is moved in the secondary domain and will rely on the services offered by the Linux kernel. Conversely, when a Xenomai thread running in the secondary domain invokes a possibly blocking Xenomai system call, it will be moved to the primary domain before the service is eventually performed, relying on the Xenomai-specific kernel data structures. Xenomai threads can be moved back and forth the primary and secondary domains depending on the kind of services (Linux vs. Xenomai system calls) requested. Even when moved to the secondary (Linux) domain, a Xenomai thread can maintain real-time characteristics: this is achieved by avoiding the Xenomai thread execution being perturbed by non-real-time Linux interrupt activities. A simple way to prevent delivery of interrupts to the Linux kernel when the Xenomai thread is running in the secondary (Linux) domain is to stall the interrupt shield domain lying between the primary and secondary ones. The interrupt shield will then be disengaged when the Xenomai thread finishes the current computation. In this way, Xenomai threads can have real-time characteristics even when running in the Linux domain, albeit suffering from an increased latency due to the fact that, in this domain, they are scheduled by the original Linux scheduler.
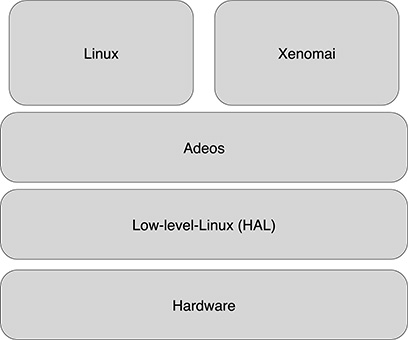
FIGURE 18.6
The Xenomai layers.
Letting real-time Xenomai threads work in user space and use Linux system calls simplify the development of real-time applications, and, above all, allows an easy porting of existing applications from other systems. To this purpose, the Xenomai API provides several sets of synchronization primitives, called skins, each emulating the set of system routines of a given operating system.
The Adeos functionality is used in Xenomai also for handling system call interception. In fact, system calls performed by Xenomai threads, including Linux system calls, must be intercepted by Xenomai to properly handle the migration of the thread between the primary and secondary domain. This is achieved thanks to the possibility offered by Adeos of registering an event handler that is then activated every time a syscall is executed (and therefore a software interrupt is generated).
The layers of Xenomai are shown in Figure 18.6. At the lowest level is the hardware, which is directly interfaced to the Linux HAL, used by Adeos to export a new kind of HAL that supports event and interrupts dispatching. This layer is then exported to the primary (xenomai) and secondary (Linux) domains.
18.4.3 RTAI
Real-Time Application Interface (RTAI) ia another example of dual-kernel real-time extension of Linux based on Adeos. Its architecture is not far from that of Xenomai, and the Xenomai project itself originates from a common development with RTAI, from which it separated in 2005.
In RTAI, the Adeos layer is used to provide the dispatching of system events to two different domains: the RTAI scheduler, and the Linux kernel. In RTAI, however, the Adeos software has been patched to adapt it to the specific requirements of RTAI. So, the clean distinction in layers of Xenomai (Figure 18.6) is somewhat lost, and parts of the RTAI code make direct access to the underlying hardware (Figure 18.7). The reason for this choice is the need for avoiding passing through the Adeos layer when dispatching of those events that are critical in real-time responsiveness. Despite this difference in implementation, the concept is the same: let interrupts, which may signal system events requiring some action from the system, reach the real-time scheduler before they are handled by the Linux kernel and regardless the possible interrupt disabling actions performed by the Linux kernel to protect critical sections.
The main components of RTAI are shown in Figure 18.8. Above the abstraction layer provided by the patched version of Adeos, the RTAI scheduler organizes the execution of real-time tasks. The RTAI component provides InterProcess Communication (IPC) among real-time and Linux tasks.
The RTAI scheduler handles two main kind of tasks:
Native kernel RTAI threads. These tasks live outside the Linux environment and therefore cannot use any Linux resource. It is, however, possible to let them communicate with Linux tasks using RTAI primitives, such as semaphores and real-time FIFOs, which interface to character devices on the Linux side.
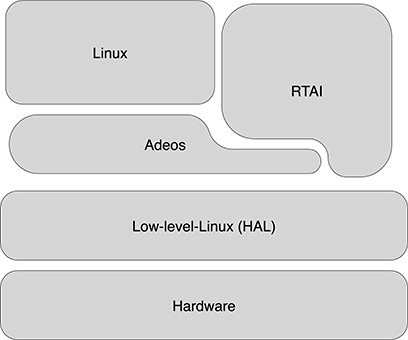
FIGURE 18.7
The RTAI layers.User-space Linux tasks. The ability to deal with user-mode tasks simplifies the development of real-time applications because of the possibility of using Linux resources and the memory protection provided by the MMU. Recall that wrong memory access in a user space task will let the kernel intervene and handle the fault, normally aborting the task, while a wrong memory access in kernel space may corrupt the operating system data structure and crash the system.
For very stringent real-time requirements, native RTAI threads provide the shortest context switch time since there is no need to change the page table contents and the context switch requires only exchanging the values of the (kernel) stack pointer and reloading the machine general-purpose registers. In addition to the use of fixed priorities, either in FIFO or round robin (RR) configuration, RTAI provides support for timed and cyclic task execution. To this purpose, the RTAI scheduler organizes task descriptors in two different queues: the ready list, where tasks are ordered by priority, and the timed list, for the timed tasks, organized by their resume time order. Several scheduling policies are supported, namely
Rate Monotonic scheduling (RM)
Earliest Deadline First (EDF)
First In First Out (FIFO)
Round Robin (RR)
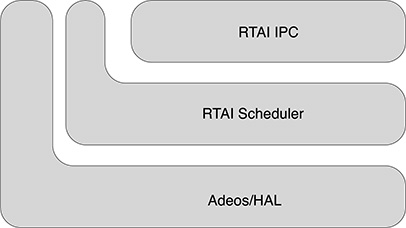
FIGURE 18.8
The RTAI components.
RM and EDF refer to timed tasks. RTAI interfaces directly to the hardware timer device in order to manage the occurrence of timer ticks with a minimum overhead. For the EDF scheduling policy, it is also necessary to define release time and deadline for each timed RTAI thread.
While the shortest latencies in the system are achieved using native kernel RTAI threads, the possibility of providing real-time responsiveness to selected Linux tasks increases the practical usability of RTAI. For this purpose, a new scheduler, called LinuX RealTime (LXRT), has been provided in RTAI, which is also able to manage Linux tasks. A Linux task can be made real-time by invoking the RTAI rt_make_hard_real_time() routine. In this case, the task is moved from the Linux scheduler to the RTAI one, and therefore, it enters the set of tasks that are considered by the RTAI scheduler for real-time responsiveness. In order to provide a fast response, the RTAI scheduler is invoked when either
a timer interrupt is received;
any ISR, which has been registered in RTAI, returns;
Any task managed by the RTAI scheduler is suspended.
Considering the fact that, thanks to the underlying Adeos layer, interrupts are first delivered to the RTAI domain, the LXRT scheduler has a chance to release new ready tasks whenever a significant system event occurs, including the soft interrupt originated by the activation of a system routine in the Linux kernel (traps are redirected by Adeos to the RTAI domain). Basically, the LXRT scheduler works as a coscheduler of the Linux one: whenever no real-time task (either “converted” Linux or native RTAI thread) can be selected for computation, control is passed to the Linux scheduler by invoking the original schedule() function.
A real-time Linux task can at any time return to its original condition by invoking rt_make_soft_real_time(). In this case, its descriptor is removed from the task queues of the LXRT scheduler queues and put back into the Linux scheduler.
Two levels of priority inheritance are supported by the RTAI scheduler:
In the Adaptive Priority Ceiling, the priority of the blocking task is set to the maximum value among the tasks waiting for that resource. Its priority is set to the base level only when all the blocking resources are released.
In the Full Priority Inheritance, the priority of the blocking task is still set to the maximum value among the tasks waiting for that resource, but when a resource is released, the current task priority is adjusted, depending on the current maximum priority of the remaining tasks blocked on any held resource.
Adaptive priority ceiling represents a trade-off between the real priority inheritance schema and the need of avoiding scanning task descriptor queues, an operation that may depend on the actual number of involved tasks and that may then introduce nondeterminism in the resource management time.
18.5 Summary
The interest toward real-time Linux is growing due to several factors, among which are the following
Linux applications are becoming more and more common in embedded systems and, consequently, the availability of reusable code and libraries is increasing. This represents a further factor driving the choice of Linux for embedded applications and represents a sort of “positive feedback” in this process.
The rapid evolution of processor technology allows the integration of a monolithic kernels like Linux in small and cheap processors also.
Linux is free. Traditionally, top-level realtime applications have been using commercial real-time operating systems. For example, the commercial VxWorks operating system has been used in several Mars missions. The availability of a free system with real-time performances that are approaching those offered by expensive award-winning systems is changing the scenario, and real-time Linux is more and more used for control in critical applications.
This chapter presented the two different approaches that have been followed in the implementation of real-time systems based on Linux: the “mainstream” evolution of the Linux kernel, and the dual-kernel organization. The former is a slower process: the Linux kernel is complex and changes in such a critical part of software require a long time to be fully tested and accepted by the user community because they potentially affect a great number of existing applications. The dual-kernel approach circumvents the problem of kernel complexity, and therefore, allows implementing working systems in a much shorter time with much less effort. Nevertheless, systems like Xenomai and RTAI are implemented as patches (for Adeos) and loadable modules for the Linux kernel, and require a continuous work to adapt them to the evolution of the Linux kernel. On the other side, such systems are likely to achieve shorter latencies because they remove the problem from its origin by defining a completely different path, outside the Linux kernel, for those system events that are involved in real-time operations.
The reader may wonder now which approach is going to be the “winner.” Giving an answer to such a question is not easy, but the authors’ impression is that the mainstream Linux evolution is likely to become the common choice, restricting the usage of dual-core solutions to a selected set of highly demanding applications.