
9
Network Communication
CONTENTS
We have seen in chapters 7 and in 8 how processes and threads can communicate within the same computer. This chapter will introduce the concepts and interfaces for achieving communication among different computers to implement distributed applications. Distributed applications involving network communication are used in embedded systems for a variety of reasons, among which are
Computing Power: Whenever the computing power needed by the application cannot be provided by a single computer, it is necessary to distribute the application among different machines, each carrying out a part of the required computation and coordinating with the others via the network.
Distributed Data: Often, an embedded system is required to acquire and elaborate data coming from different locations in the controlled plant. In this case, one or more computers will be dedicated to data acquisition and first-data processing. They will then send preprocessed data to other computers that will complete the computation required for the control loop.
Single Point of failure: For some safety-critical applications, such as aircraft control, it is important that the system does not exhibit a single point of failure, that is, the failure of a single computer cannot bring the system down. In this case, it is necessary to distribute the computing load among separate machines so that, in case of failure of one of them, another one can resume the activity of the failed component.
Here we shall concentrate on the most widespread programming interface for network communication based on the concept of socket. Before describing the programming interface, we shall briefly review some basic concepts in network communication with an eye on Ethernet, a network protocol widely used in local area networks (LANs).
9.1 The Ethernet Protocol
Every time different computers are connected for exchanging information, it is necessary that they strictly adhere to a communication protocol. A communication protocol defines a set of rules that allow different computers, possibly from different vendors, to communicate over a network link. Such rules are specified in several layers, usually according to the Open Systems Interconnection (OSI) ISO/IEC standard [47]. At the lowest abstraction level is the Physical Layer, which specifies how bits are transferred over the physical communication media. The Data Link Layer specifies how data is transferred between network entities. The Network Layer specifies the functional and procedural means to route data among different networks, and the Transport Layer provides transparent transfer of data between end users, providing reliable data transfer services.
The definition of the Ethernet protocol is restricted to the physical layer and the data link layer. The physical layer defines the electrical characteristics of the communication media, including:
Number of communication lines;
Impedance for input and output electronics;
Electrical levels and timing characteristics for high and low levels;
The coding schema used to transmit ones and zeroes;
Rules for ensuring that the communication links are not contended.
The physical layer specification often reflects the state of the art of electronic technology and therefore rapidly evolves over time. As an example, the physical layer of Ethernet evolved in the past years through several main stages, all discussed in IEEE Standard 802.3 [43]:
10Mbit/s connection over a coaxial cable. In this, a single coaxial cable was shared by all the partners in communication using Manchester Coding for the transmission of the logical ones and zeroes. Carrier sense multiple access with collision detection (CSMA/CD) was defined to avoid the communication line being driven by more than one transmitter.
100BASE-T (Fast Ethernet), which runs over two wire-pairs, normally one pair of twisted wires in each direction, using 4B5B coding and providing 100 Mbit/s of throughput in each direction (full-duplex). Each network segment can have a maximum distance of 100 metres and can be shared only by two communication partners. Ethernet hubs and switches provide the required connectivity among multiple partners.
1000BASE-T and 1000BASE-X (Gigabit Ethernet), ensuring a communication speed of 1 GBit/s over twisted pair cable or optical fiber, respectively.
The physical layer is continuously evolving, and 10 Gigabit Ethernet is currently entering the mainstream market. Conversely, the data link layer of Ethernet is more stable. This layer defines how information is coded by using the transmitted logical zeroes and ones (how logical zeroes and ones are transmitted is defined by the physical layer). Due to its complexity, the data link layer is often split into two or more sublayers to make it more manageable. For Ethernet, the lower sublayer is called Media Access Control (MAC) and is discussed in Reference [43], along with the physical layer. The upper sub-layer is the Logical Link Control (LLC) and is specified in Reference [46]. Data exchanged over Ethernet is grouped in Frames, and every frame is a packet of binary data that contains the following fields:
Preamble and Start Frame Identifier (8 octets): Formed by a sequence of identical octets with a predefined value (an octet in network communication terminology corresponds to a byte), followed by a single octet whose value differs only for the least significant bit. The preamble and the start frame identifier are used to detect the beginning of the frame in the received bit stream.
MAC Destination (6 octets): the Media Access Control (MAC) address of the designated receiver for the frame.
MAC Source (6 octets): The MAC address of the sender of the frame.
Packet Length (2 octets): Coding either the length of the data frame or other special information about the packet type.
Payload (46–1500 octets): Frame data.
CRC (4 octets): Cyclic Redundancy Check (CRC) used to detect possible communication errors. This field is obtained from the frame content at the time the frame is sent, and the same algorithm is performed when the packet is received. If the new CRC value is different form the CRC field, the packet is discarded because there has indeed been a transmission error.
Interframe Gap (12 octets): Minimum number of bytes between different frames.
An Ethernet frame can therefore be seen as an envelope containing some data (the payload). The additional fields are only required for the proper management of the packet, such as the definition of the sender and receiver addresses and checksum fields. The envelope is normally processed by the network board firmware, and the payload is returned to the upper software layers when a packet is received.
9.2 TCP/IP and UDP
It would be possible to develop distributed application directly interfacing to the data link layer of Ethernet, but in this way, in order to ensure proper and reliable communication, the program should also handle the following facts:
Address resolution: The Ethernet addresses are unique for every Hardware Board, and they must be known to the program. Changing a computer, or even a single Ethernet board, would require a change in the program.
Frame Splitting: The maximum payload in Ethernet is 1500 bytes, and therefore, if a larger amount of data must be transmitted, it has to be split in two or more packets. The original data must then be reassembled upon the reception of the packets.
Transmission Error Management: The network board firmware discards those packets for which a communication error has been detected using the CRC field. So the program must take into account the possibility that packets could be lost in the transmission and therefore must be able to detect this fact and take corrective actions, such as request for a new data packet.
It is clear that programming network communication at this level would be a nightmare: the programmer would be requested to handle a variety of problems that would overwhelm the application requirements. For this reason, further communication layers are defined and can be used to achieve effective and reliable network communication. Many different network communication layers are defined for different network protocols, and every layer, normally built on top of one or more other layers, provides some added functionality in respect of that provided by the layers below. Here we shall consider the Internet Protocol (IP), which addresses the Network Layer, and the Transmission Control Protocol (TCP), addressing the Transport Layer. IP and TCP together implement the well-known TCP/IP protocol. Both protocols are specified and discussed in detail in a number of Request for Comments (RFC), a series of informational and standardization documents about Internet. In their most basic form, IP version 4 and TCP are presented in References [74], and [75], respectively.
The IP defines the functionality needed for handling the transmission of packets along one or more networks and performs two basic functions:
Addressing: It defines an hierarchical addressing system using IP addresses represented by a 4-byte integer.
Routing: It defines the rules for achieving communication among different networks, that is, getting packets of data from source to destination by sending them from network to network. Based on the destination IP address, the data packet will be sent over the local networks from router to router up to the final destination.
The Internet Protocol can be built on top of other data link layers for different communication protocols. For LANs, the IP is typically built over Ethernet. Observe that, in both layers, data are sent over packets, and the IP packet defines, among other information, the source and destination IP addresses. However, when sent over an Ethernet segment, these fields cannot be recognized by the Ethernet board, which is only able to recognize Ethernet addresses. This apparent contradiction is explained by the fact the Internet layer data packet is represented by the payload of the Ethernet packet, as shown in Figure 9.1. So, when an Ethernet packet is received, the lowest communication layers (normally carried out by the board firmware) will use the Ethernet header, to acquire the payload and pass it to the upper layer. The upper Internet layer will interpret this chunk of bytes as an Internet Packet and will retrieve its content. For sending an Internet Packet over an Ethernet network, the packet will be encapsulated into an Ethernet packet and then sent over the Ethernet link. Observe that the system must know how to map IP addresses with Ethernet addresses: such information will be maintained in routing tables, as specified by the routing rules of the IP. If the resolution for a given IP address is not currently known by the system, it is necessary to discover it. The Address Resolution Protocol (ARP) [72] is intended for this purpose and defines how the association between IP addresses and Ethernet MAC addresses is exchanged over Ethernet. Basically, the machine needing this information sends a broadcast message (i.e., a message that is received by all the receivers for that network segment), bringing the MAC address of the requester and the IP address for which the translation is required. The receiver that recognizes the IP address sends a reply with its MAC address so that the client can update its routing tables with the new information.
Even if the IP solves the important problem of routing the network packets so that the world network can be seen as a whole, communication is still packet based, and reliability is not ensured because packets can be lost when transmission errors occur. These limits are removed by TCP, built over IP. This layer provides a connection-oriented view of the network transmissions: the partners in the communication first establish a connection and then exchange data. When the connection has been established, a stream of data can be exchanged between the connected entities. This layer removes the data packet view and ensures that data arrive with no errors, no duplications, and in order. In addition, this layer introduces the concept of port, that is, a unique integer identifier of the communicating entity within a single computer (associated with a given IP address). So, in TCP/IP, the address of the sender and the receiver will be identified by the pair (IP address, port), allowing communication among different entities even if sharing the same IP address. The operations defined by the TCP layer are complex and include management of the detection and retransmission of lost packets, proper sequencing of the packets, check for duplicated data assembling and de-assembling of data packets, and traffic congestion control. TCP defines its own data packet format, which brings, in addition to data themselves, all the required information for reliable and stream-oriented communication, including Source/Destination port definitions and Packet Sequence and Acknowledge numbers used to detect lost packets and handle retransmission.
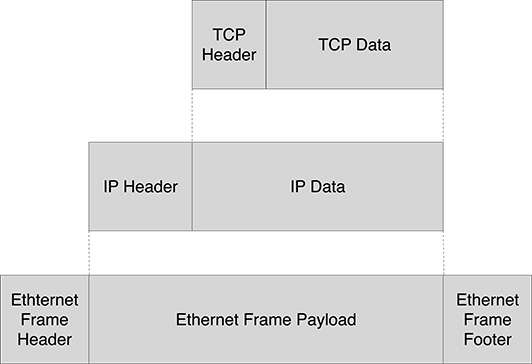
FIGURE 9.1
Network frames: Ethernet, IP, and TCP/IP.
Being the TCP layer built on top of the Internet layer, the latter cannot know anything about the structure of the TCP data packet, which is contained in the data part of the Internet packet, as shown in Figure 9.1. So, when a data packet is received by the Internet layer (possibly contained in the payload of a Ethernet data packet), the specific header fields will be used by the Internet layer, which will pass the data content of the packet to the above TCP layer, which in turn will interpret this as a TCP packet.
The abstraction provided by the TCP layer represents an effective way to achieve network communication and, for this reason, TCP/IP communication is widely used in applications. In the next section we shall present the programming model of TCP/IP and illustrate it in a sample client/server application. This is, however, not the end of the story: many other protocols are built over TCP/IP, such as File Transfer Protocol (FTP), and the ubiquitous Hypertext Transfer Protocol (HTTP) used in web communication.
Even if the connection-oriented communication provided by TCP/IP is widely used in practice, there are situations in which a connectionless model is required instead. Consider, for example, a program that must communicate asynchronous events to a set of listener entities over the network, possibly without knowing which are the recipients. This would not be possible using TCP/IP because a connection should be established with every listener, and therefore, its address must be known in advance. The User Datagram Protocol (UDP) [73], which is built over the Internet layer, lets computer applications send messages, in this case referred to as datagrams, to other hosts on an Internet network without the need of establishing point-to-point connections. In addition, UDP provides multicast capability, that is, it allows sending of datagrams to sets of recipients without even knowing their IP addresses. On the other side, the communication model offered by UDP is less sophisticated than that of TCP/IP, and data reliability is not provided. Later in this chapter, the programming interface of UDP will be presented, together with a sample application using UDP multicast communication.
9.3 Sockets
The programming interface for TCP/IP and UDP is centered around the concept of socket, which represents the endpoint of a bidirectional interprocess communication flow. The creation of a socket is therefore the first step in the procedure for setting up and managing network communication. The prototype of the socket creation routine is
int socket(int domain, int type, int protocol)
where domain selects the protocol family that will be used for communication. In the case of the Internet, the communication domain is AF_INET. type specifies the communication semantics, which can be SOCK_STREAM or SOCK_DGRAM for TCP/IP or UDP communication, respectively. The last argument, protocol, specifies a particular protocol within the communication domain to be used with the socket. Normally, only a single protocol exists and, therefore, the argument is usually specified as 0.
The creation of a socket represents the only common step when managing TCP/IP and UDP communication. In the following we shall first describe TCP/IP programming using a simple client–server application. Then UDP communication will be described by presenting a program for multicast notification.
9.3.1 TCP/IP Sockets
We have seen that TCP/IP communication requires the establishment of a connection before transmission. This implies a client–server organization: the client will request a connection to the server. The server may be accepting multiple clients’ connections in order to carry out a given service. In the program shown below, the server accepts character strings, representing some sort of command, from clients and returns other character strings representing the answer to the commands. It is worth noting that a high-level protocol for information exchange must be handled by the program: TCP/IP sockets in facts provide full duplex point-to-point communication where the communication partners can send and transmit bytes, but it is up to the application to handle transmission and reception to avoid, for example, situations in which the two communication partners both hang waiting to receive some data from the other. The protocol defined in the program below is a simple one and can be summarized as follows:
The client initiates the transaction by sending a command to be executed. To do this, it first sends the length (4 bytes) of the command string, followed by the command characters. Sending the string length first allows the server to receive the correct number of bytes afterwards.
The server, after receiving the command string, executes the command getting and answer string, which is sent back to the client. Again, first the length of the string is sent, followed by the answer string characters. The transaction is then terminated and a new one can be initiated by the client.
Observe that, in the protocol used in the example, numbers and single-byte characters are exchanged between the client and the server. When exchanging numbers that are represented by two, four, or more bytes, the programmer must take into account the possible difference in byte ordering between the client and the server machine. Getting weird numbers from a network connection is one of the main source of headache to novel network programmers. Luckily, there is no need to find out exotic ways of discovering whether the client and the server use a different byte order and to shuffle bytes manually, but it suffices to use a few routines available in the network API that convert short and integer numbers to and from the network byte order, which is, by convention, big endian.
Another possible source of frustration for network programmers is due to the fact that the recv() routine for receiving a given number of bytes from the socket does not necessarily return after the specified number of bytes has been read, but it may end when a lower number of bytes has been received, returning the actual number of bytes read. This occurs very seldom in practice and typically not when the program is tested, since it is related to the level of congestion of the network. Consequently, when not properly managed, this fact generates random communication errors that are very hard to reproduce. In order to receive a given number of bytes, it is therefore necessary to check the number of bytes returned by recv(), possibly issuing again the read operation until all the expected bytes are read, as done by routine receive() in this program.
The client program is listed below:
# include <stdio .h>
# include <sys/ types .h>
# include <sys/ socket .h>
# include <netinet /in.h>
# include <netdb .h>
# include <string .h>
# include <stdlib .h>
# define FALSE 0 # define TRUE 1
/∗ Receive routine : use recv to receive from socket and manage
the fact that recv may return after having read less bytes than
the passed buffer size
In most cases recv will read ALL requested bytes, and the loop body
will be executed once. This is not however guaranteed and must
be handled by the user program. The routine returns 0 upon
successful completion, −1 otherwise ∗/
static int receive ( int sd, char *retBuf, int size)
{
int totSize, currSize ;
totSize = 0;
while ( totSize < size)
{
currSize = recv(sd, & retBuf [ totSize ], size - totSize, 0);
if( currSize <= 0)
/∗ An error occurred ∗/
return -1;
totSize += currSize ;
}
return 0;
}
/∗ Main client program . The IP address and the port number of
the server are passed in the command line. After establishing
a connection, the program will read commands from the terminal
and send them to the server. The returned answer string is
then printed. ∗/
main( int argc, char ** argv)
{
char hostname [100];
char command [256];
char * answer ;
int sd;
int port ;
int stopped = FALSE ;
int len;
unsigned int netLen ;
struct sockaddr_in sin;
struct hostent *hp;
/∗ Check number of arguments and get IP address and port ∗/
if ( argc < 3)
{
printf (" Usage : client <hostname > <port > n" );
exit (0);
}
sscanf ( argv [1], "%s", hostname );
sscanf ( argv [2], "%d", & port );
/∗ Resolve the passed name and store the resulting long representation
in the struct hostent variable ∗/
if ((hp = gethostbyname( hostname )) == 0)
{
perror (" gethostbyname");
exit (0);
}
/∗ fill in the socket structure with host information ∗/
memset (& sin, 0, sizeof ( sin ));
sin. sin_family = AF_INET ;
sin. sin_addr . s_addr = (( struct in_addr *)(hp -> h_addr ))-> s_addr ;
sin. sin_port = htons ( port );
/∗ create a new socket ∗/
if (( sd = socket ( AF_INET, SOCK_STREAM, 0)) == -1)
{
perror (" socket ");
exit (0);
}
/∗ connect the socket to the port and host
specified in struct sockaddr_in ∗/
if ( connect (sd,( struct sockaddr *)& sin, sizeof ( sin )) == -1)
{
perror (" connect ");
exit (0);
}
while (! stopped )
{
/∗ Get a string command from terminal ∗/
printf (" Enter command : ");
scanf ( "%s", command );
if (! strcmp ( command, " quit" ))
break ;
/∗ Send first the number of characters in the command and then
the command itself ∗/
len = strlen ( command );
/∗ Convert the integer number into network byte order ∗/
netLen = htonl ( len);
/∗ Send number of characters ∗/
if( send (sd, &netLen, sizeof ( netLen ), 0) == -1)
{
perror (" send");
exit (0);
}
/∗ Send the command ∗/
if ( send (sd, command, len, 0) == -1)
{
perror (" send");
exit (0);
}
/∗ Receive the answer : first the number of characters
and then the answer itself ∗/
if( receive (sd, ( char *)& netLen, sizeof ( netLen )))
{
perror (" recv");
exit (0);
}
/∗ Convert from Network byte order ∗/
len = ntohl ( netLen );
/∗ Allocate and receive the answer ∗/
answer = malloc ( len + 1);
if( receive (sd, answer, len ))
{
perror (" send");
exit (1);
}
answer [len] = 0;
printf ("%s
", answer );
free( answer );
}
/∗ Close the socket ∗/
close (sd );
}
The above program first creates a socket and connects it to the server whose IP Address and port are passed in the command string. Socket connection is performed by routine connect(), and the server address is specified in a variable of type struct sockaddr_in, which is defined as follows
struct sockaddr_in {
short sin_family; // Address family e.g. AF_INET
unsigned short sin_port; // Port number in Network Byte order
struct in_addr sin_addr; // see struct in_addr, below
char sin_zero[8]; //Padding zeroes
};
struct in_addr {
unsigned long s_addr; //4 byte IP address
};
The Internet Address is internally specified as a 4-byte integer but is presented to users in the usual dot notation. The conversion from human readable notation and the integer address is carried out by routine gethostbyname(), which fills a struct hostent variable with several address-related information. We are interested here (and in almost all the applications in practice) in field h_addr, which contains the resolved IP address and which is copied in the corresponding field of variable sin. When connect() returns successfully, the connection with the server is established, and data can be exchanged. Here, the exchanged information is represented by character strings: command string are sent to the server and, for every command, an answer string is received. The length of the string is sent first, converted in network byte order by routine htonl(), followed by the string characters. Afterwards, the answer is obtained by reading first its length and converting from network byte order via routine ntohl(), and then reading the expected number of characters.
The server code is listed below, and differs in several points from the client one. First of all, the server does not have to know the address of the clients: after creating a socket and binding it to the port number (i.e., the port number clients will specify to connect to the server), and specifying the maximum length of pending clients via listen() routine, the server suspends itself in a call to routine accept(). This routine will return a new socket to be used to communicate with the client that just established the connection.
# include <stdio .h>
# include <sys/ types .h>
# include <sys/ socket .h>
# include <netinet /in.h>
# include <arpa / inet.h>
# include <netdb .h>
# include <string .h>
# include <stdlib .h>
/∗ Handle an established connection
routine receive is listed in the previous example ∗/
static void handleConnection(int currSd )
{
unsigned int netLen ;
int len;
char * command, * answer ;
for (;;)
{
/∗ Get the command string length
If receive fails, the client most likely exited ∗/
if( receive (currSd, ( char *)& netLen, sizeof ( netLen )))
break ;
/∗ Convert from network byte order ∗/
len = ntohl ( netLen );
command = malloc ( len + 1);
/∗ Get the command and write terminator ∗/
receive (currSd, command, len );
command [len] = 0;
/∗ Execute the command and get the answer character string ∗/
...
/∗ Send the answer back ∗/
len = strlen ( answer );
/∗ Convert to network byte order ∗/
netLen = htonl ( len);
/∗ Send answer character length ∗/
if ( send (currSd, & netLen, sizeof ( netLen ), 0) == -1)
break ;
/∗ Send answer characters ∗/
if ( send (currSd, answer, len, 0) == -1)
break ;
}
/∗ The loop is most likely exited when the connection is terminated ∗/
printf (" Connection terminated
");
close ( currSd );
}
/∗ Main Program ∗/
main( int argc, char * argv [])
{
int sd, currSd ;
int sAddrLen ;
int port ;
int len;
unsigned int netLen ;
char * command, * answer ;
struct sockaddr_in sin, retSin ;
/∗ The port number is passed as command argument ∗/
if( argc < 2)
{
printf (" Usage : server <port > n" );
exit (0);
}
sscanf ( argv [1], "%d", & port );
/∗ Create a new socket ∗/
if (( sd = socket ( AF_INET, SOCK_STREAM, 0)) == -1)
{
perror (" socket ");
exit (1);
}
/∗ Initialize the address (struct sokaddr_in ) fields ∗/
memset (& sin, 0, sizeof ( sin ));
sin. sin_family = AF_INET ;
sin. sin_addr . s_addr = INADDR_ANY;
sin. sin_port = htons ( port );
/∗ Bind the socket to the specified port number ∗/
if ( bind (sd, ( struct sockaddr *) &sin, sizeof ( sin )) == -1)
{
perror ("bind ");
exit (1);
}
/∗ Set the maximum queue length for clients requesting connection to 5 ∗/
if ( listen (sd, 5) == -1)
{
perror (" listen ");
exit (1);
}
sAddrLen = sizeof ( retSin );
/∗ Accept and serve all incoming connections in a loop ∗/
for (;;)
{
if (( currSd =
accept (sd, ( struct sockaddr *) & retSin, & sAddrLen )) == -1)
{
perror (" accept ");
exit (1);
}
/∗ When execution reaches this point a client established the connection .
The returned socket (currSd) is used to communicate with the client ∗/
printf (" Connection received from %s
", inet_ntoa(retSin.sin_addr));
handleConnection(currSd);
}
}
In the above example, the server program has two nested loops: the external loop waits for incoming connections, and the internal one, defined in routine handleConnection(), handles the connection just established until the client exits. Observe that the way the connection is terminated in the example is rather harsh: the inner loop breaks whenever an error is issued when either reading or writing the socket, under the assumption that the error is because the client exited. A more polite management of the termination of the connection would have been to foresee in the client–server protocol an explicit command for closing the communication. This would also allow discriminating between possible errors in the communication and the natural termination of the connection.
Another consequence of the nested loop approach in the above program is that the server, while serving one connection, is not able to accept any other connection request. This fact may pose severe limitations to the functionality of a network server: imagine a web server that is able to serve only one connection at a time! Fortunately, there is a ready solution to this problem: let a separate thread (or process) handle the connection established, allowing the main process accepting other connection requests. This is also the reason for the apparently strange fact why routine accept() returns a new socket to be used in the following communication with the client. The returned socket, in fact, is specific to the communication with that client, while the original socket can still be used to issue accept() again.
The above program can be turned into a multithreaded server just replacing the external loop accepting incoming connections as follows:
/∗ Thread routine. It calls routine handleConnection ()
defined in the previous program. ∗/
static void * connectionHandler( void *arg)
{
int currSock = *( int *) arg;
handleConnection( currSock );
free( arg );
pthread_exit(0);
return NULL ;
}
...
/∗ Replacement of the external ( accept ) loop of the previous program ∗/
for (;;)
{
/∗ Allocate the current socket.
It will be freed just before thread termination. ∗/
currSd = malloc ( sizeof ( int ));
if ((* currSd =
accept (sd, ( struct sockaddr *) & retSin, & sAddrLen )) == -1)
{
perror (" accept ");
exit (1);
}
printf (" Connection received from %s
", inet_ntoa( retSin . sin_addr ));
/∗ Connection received, start a new thread serving the connection ∗/
pthread_create(& handler, NULL, connectionHandler, currSd );
}
In the new version of the program, routine handleConnection() for the communication with the client is wrapped into a thread. The only small change in the program is due to the address of the socket being passed because the thread routine accepts a pointer argument. The new server can now accept and serve any incoming connection in parallel.
9.4 UDP Sockets
We have seen in the previous section how the communication model provided by TCP/IP ensures reliable connection between a client and a server application. TCP is built over IP and provides the functionality necessary to achieve communication reliability over unreliable packet-based communication layer, such as IP is. This is obtained using several techniques for timestamping messages in order to detect missing, duplicate, or out-of-order message reception and to handle retransmission in case of lost packets. As a consequence, although TCP/IP is ubiquitous and is the base protocol for a variety of other protocols, it may be not optimal for real-time communication. In real-time communication, in fact, it is often preferable not to receive a data packet at all rather than receive it out of time. Consider, for example, a feedback system where a controller receives from the network data from sensors and computes the actual reference values for actuators. Control computation must be performed on the most recent samples. Suppose that a reliable protocol such as TCP/IP is used to transfer sensor data, and that a data packet bringing current sensor values is lost: in this case, the protocol would handle the retransmission of the packet, which is eventually received correctly. However, at the time this packet has been received, it brings out-of-date sensor values, and the following sensor samples will likely arrive delayed as well, at least until the transmission stabilizes. From the control point of view, this situation is often worse than not receiving the input sample at all, and it is preferable that the input values are not changed in the next control cycle, corresponding to the assumption that sensor data did not change during that period. For this reason a faster protocol is often preferred for real-time application, relaxing the reliability requirement, and the UDP is normally adopted. UDP is a protocol built above IP that allows that applications send and receive messages, called datagrams, over an IP network. Unlike TCP/IP, the communication does not require prior communication to set up client–server connection, and for this reason, it is called connectionless. UDP provides an unreliable service, and datagrams may arrive out of order, duplicated, or lost, and these conditions must be handled in the user application. Conversely, faster communication can be achieved in respect of other reliable protocols because UDP introduces less overhead. As for TCP/IP, message senders and receivers are uniquely identified by the pair (IP Address, port). No connection is established prior to communication, and datagrams sent and received by routines sendto() and revfrom(), respectively, can be sent and received to/from any other partner in communication. In addition to specifying a datagram recipient in the form (IP Address, port), UDP allows broadcast, that is, sending the datagram to all the recipients in the network, and multicast, that is, sending the datagram to a set of recipients. In particular, multicast communication is useful in distributed embedded applications because it is often required that data are exchanged among groups of communicating actors. The approach taken in UDP multicast is called publish–subscribe, and the set of IP addresses ranging from 224.0.0.0 to 239.255.255.255 is reserved for multicast communication. When an address is chosen for multicast communication, it is used by the sender, and receivers must register themselves for receiving datagrams sent to such address. So, the sender is not aware of the actual receivers, which may change over time.
The use of UDP multicast communication is explained by the following sender and receiver programs: the sender sends a string message to the multicast address 225.0.0.37, and the message is received by every receiver that subscribed to that multicast address.
# include <sys/ types .h>
# include <sys/ socket .h>
# include <netinet /in.h>
# include <arpa / inet.h>
# include <string .h>
# include <stdio .h>
# include <stdlib .h>
/∗ Port number used in the application ∗/
# define PORT 4444
/∗ Multicast address ∗/
# define GROUP " 225.0.0.37"
/∗ Sender main program : get the string from the command argument ∗/
main( int argc, char * argv [])
{
struct sockaddr_in addr;
int sd;
char * message ;
/∗ Get message string ∗/
if(argc < 2)
{
printf (" Usage : sendUdp <message >
");
exit (0);
}
message = argv [1];
/∗ Create the socket. The second argument specifies that
this is an UDP socket ∗/
if (( sd = socket ( AF_INET, SOCK_DGRAM,0)) < 0)
{
perror (" socket ");
exit (0);
}
/∗ Set up destination address : same as TCP/IP example ∗/
memset (& addr,0, sizeof ( addr ));
addr. sin_family = AF_INET ;
addr. sin_addr . s_addr = inet_addr( GROUP );
addr. sin_port = htons ( PORT );
/∗ Send the message ∗/
if ( sendto (sd, message, strlen ( message ),0,
( struct sockaddr *) & addr, sizeof ( addr )) < 0)
{
perror (" sendto ");
exit (0);
}
/∗ Close the socket ∗/
close (sd );
}
In the above program, the translation of the multicast address 225.0.0.37 from the dot notation into its internal integer representation is carried out by routine inet_addr(). This routine is a simplified version of gethostbyname() used in the TCP/IP socket example. The latter, in fact, provides the resolution of names based on the current information maintained by the IP, possibly communicating with other computers using a specific protocol to retrieve the appropriate mapping. On the Internet, this is usually attained by means of the Domain Name System (DNS) infrastructure and protocol. The general ideas behind DNS are discussed in Reference [66], while Reference [65] contains the full specification.
The UDP sender program is simpler than in the TCP/IP connection because there is no need to call connect() first, and the recipient address is passed directly to the send routine. Even simpler is the receiver program because it is no more necessary to handle the establishment of the connection. In this case, however, the routine for receiving datagrams must also return the address of the sender since different clients can send datagrams to the receiver. The receiver program is listed below:
# include <sys/ types .h>
# include <sys/ socket .h>
# include <netinet /in.h>
# include <arpa / inet.h>
# include <time .h>
# include <string .h>
# include <stdio .h>
# include <stdlib .h>
# define PORT 4444
# define GROUP " 225.0.0.37"
/∗ Maximum dimension of the receiver buffer ∗/
# define BUFSIZE 256
/∗ Receiver main program . No arguments are passed in the command line. ∗/
main( int argc, char * argv [])
{
struct sockaddr_in addr;
int sd, nbytes, addrLen ;
struct ip_mreq mreq;
char msgBuf [ BUFSIZE ];
/∗ Create a UDP socket ∗/
if (( sd= socket ( AF_INET, SOCK_DGRAM,0)) < 0)
{
perror (" socket ");
exit (0);
}
/∗ Set up receiver address. Same as in the TCP/IP example. ∗/
memset (& addr,0, sizeof ( addr ));
addr. sin_family = AF_INET ;
addr. sin_addr. s_addr = INADDR_ANY;
addr. sin_port = htons ( PORT );
/∗ Bind to receiver address ∗/
if ( bind (sd,( struct sockaddr *) & addr, sizeof ( addr )) < 0)
{
perror ("bind ");
exit (0);
}
/∗ Use setsockopt () to request that the receiver join a multicast group ∗/
mreq. imr_multiaddr. s_addr = inet_addr( GROUP );
mreq. imr_interface. s_addr = INADDR_ANY;
if ( setsockopt(sd, IPPROTO_IP, IP_ADD_MEMBERSHIP,& mreq, sizeof ( mreq )) < 0)
{
perror (" setsockopt");
exit (0);
}
/∗ Now the receiver belongs to the multicast group :
start accepting datagrams in a loop ∗/
for (;;)
{
addrLen = sizeof ( addr );
/∗ Receive the datagram. The sender address is returned in addr ∗/
if ((nbytes = recvfrom (sd, msgBuf, BUFSIZE, 0,
(struct sockaddr *) & addr,& addrLen )) < 0)
{
perror (" recvfrom ");
exit (0);
}
/∗ Insert terminator ∗/
msgBuf [ nBytes ] = 0;
printf ("%s
", msgBuf );
}
}
After creating the UDP socket, the required steps for the receiver are
Bind to the receiver port, as for TCP/IP.
Join the multicast group. This is achieved via the generic
setsockopt()routine for defining the socket properties (similar in concept toioctl()) where theIP_ADD_MEMBERSHIPoperation is specified and the multicast address is specified in a variable of typestruct ip_mreq.Collect incoming datagrams using routine
recvfrom(). In addition to the received buffer containing datagram data, the address of the sender is returned.
Observe that, in this example, there is no need to send the size of the character strings. In fact, sender and receivers agree on communicating the characters (terminator excluded) in the exchanged datagram whose size will depend on the number of characters in the transferred string: it will be set by the sender and detected by the receiver.
9.5 Summary
This chapter has presented the programming interface of TCP/IP and UDP, which are widely used in computer systems and embedded applications. Even if the examples presented here refer to Linux, the same interface is exported in other operating systems, either natively as in Windows and VxWorks or by separate modules, and so it can be considered a multiplatform communication standard. For example, lwIP [27] is a lightweight, open-source protocol stack that can easily be layered on top of FreeRTOS [13] and other small operating systems. It exports a subset of the socket interface to the users.
TCP/IP provides reliable communication and represents the base protocol for a variety of other protocols such as HTTP, FTP and Secure Shell (SSH). UDP is a lighter protocol and is often used in embedded systems, especially for real-time applications, because it introduces less overhead. Using UDP, user programs need to handle the possible loss, duplication and out-of-order reception of datagrams. Such a management is not as complicated as it might appear, provided the detected loss of data packets is acceptable. In this case, it suffices to add a timestamp to each message: the sender increases the timestamp for every sent message, and the timestamp is checked by the receiver. If the timestamp of the received message is the previous received timestamp plus one, the message has been correctly received, and no datagram has been lost since the last reception. If the timestamp is greater than the previous one plus one, at least another datagram has been lost or will arrive out of order. Finally, if the timestamp is less or equal the previous one, the message is a duplicated one or arrived out of order, and will be discarded.
The choice between TCP/IP and UDP in an embedded system depends on the requirements: whenever fast communication is required, and the occasional loss of some data packet is tolerable, UDP is a good candidate. There are, however, other applications in which the loss of information is not tolerable: imagine what would happen if UDP were used for communicating alarms in a nuclear plant! So, in practice, both protocols are used, often in the same application, where TCP/IP is used for offline communication (no realtime requirements) and whenever reliability is an issue. The combined use of TCP/IP and UDP is common in many applications. For example, the H.323 protocol [51], used to provide audiovisual communication sessions on any packet network, prescribes the use of UDP for voice and image transmission, and TCP/IP for communication control and management. In fact, the loss of datapacket introduces degradation in the quality of communication, which can be acceptable to a certain extent. Conversely, failure in management information exchange may definitely abort a videoconference session.
Even if this chapter concentrated on Ethernet, TCP/IP, and UDP, which represent the most widespread communication protocols in many fields of application, it is worth noting that several other protocols exist, especially in industrial applications. For example, EtherCAT [44] is an Ethernet-based protocol oriented towards high-performance communication. This is achieved by minimizing the number of exchanged data packets, and the protocol is used in industrial machine controls such as assembly systems, printing machines, and robotics. Other widespread communication protocols in industrial application are not based on Ethernet and define their own physical and data link layers. For example, the Controller Area Network (CAN) [49, 50] bus represents a message-based protocol designed specifically for automotive applications, and Process Field Bus (PROFIBUS) [40] is a standard for field bus communication in automation technology.
As a final remark, recall that one of the main reasons for distributed computing is the need for a quantity of computing power that cannot be provided by a single machine. Farms of cheap personal computers have been widely used for applications that would have otherwise required very expensive solutions based on supercomputers. The current trend in computer technology, however, reduces the need of distributed systems for achieving more computing power because modern multicore servers allow distribution of computing power among the processor cores hosted in the same machine, with the advantages that communication among computing units is much faster since it is carried out in memory and not over a network link.