
3
Real-Time Concurrent Programming Principles
CONTENTS
This chapter lays the foundation of real-time concurrent programming theory by introducing what is probably its most central concept, that is, the definition of process as the abstraction of an executing program. This definition is also useful to clearly distinguish between sequential and concurrent programming, and to highlight the pitfalls of the latter.
3.1 The Role of Parallelism
Most contemporary computers are able to perform more than one activity at the same time, at least apparently. This is particularly evident with personal computers, in which users ordinarily interact with many different applications at the same time through a graphics user interface. In addition, even if this aspect is often overlooked by the users themselves, the same is true also at a much finer level of detail. For example, contemporary computers are usually able to manage user interaction while they are reading and writing data to the hard disk, and are actively involved in network communication. In most cases, this is accomplished by having peripheral devices interrupt the current processor activity when they need attention. Once it has finished taking care of the interrupting devices, the processor goes back to whatever it was doing before.
A key concept here is that all these activities are not performed in a fixed, predetermined sequence, but they all seemingly proceed in parallel, or concurrently, as the need arises. This is particularly useful to enhance the user experience since it would be very awkward, at least by modern standards, to be constrained to have only one application active on a personal computer at any given time and to have to quit one application before switching to the next. Similarly, having a computer stop doing anything else only because a hard disk operation is in progress would seem strange, to say the least.
Even more importantly, the ability of carrying out multiple activities “at once” helps in fulfilling any timing constraint that may be present in the system in an efficient way. This aspect is often of concern whenever the computer interacts with the outside world. For example, network interfaces usually have a limited amount of space to buffer incoming data. If the system as a whole is unable to remove them from the buffer and process them within a short amount of time—on the order of a few milliseconds for a high-speed network coupled with a low-end interface—the buffer will eventually overflow, and some data will be lost or will have to be retransmitted. In more extreme cases, an excessive delay will also trigger higher-level errors, such as network communication timeouts.
In this particular situation, a sequential implementation would be tricky, because all applications would have to voluntarily suspend whatever they were doing, at predetermined instants, to take care of network communication. In addition, deciding in advance when and how often to perform this activity would be difficult because the exact arrival time of network data and their rate are often hard to predict.
Depending on the hardware characteristics, the apparent execution parallelism may correspond to a true parallelism at the hardware level. This is the case of multiprocessor and multicore systems, in which either multiple processors or a single processor with multiple execution cores share a common memory, and each processor or core is able to carry out its own sequential flow of instructions.
The same end result can be obtained when a single processor or core is available, or when the number of parallel activities exceeds the number of available processors or cores, by means of software techniques implemented at the operating system level, known as multiprogramming, that repeatedly switch the processor back and forth from one activity to another. If properly implemented, this context switch is completely transparent to, and independent from, the activities themselves, and they are usually unaware of its details. The term pseudo parallelism is often used in this case, to contrast it with the real hardware-supported parallelism discussed before, because technically the computer is still executing exactly one activity at any given instant of time.
The notion of sequential process (or process for short) was born, mainly in the operating system community, to help programmers express parallel activities in a precise way and keep them under control. It provides both an abstraction and a conceptual model of a running program.
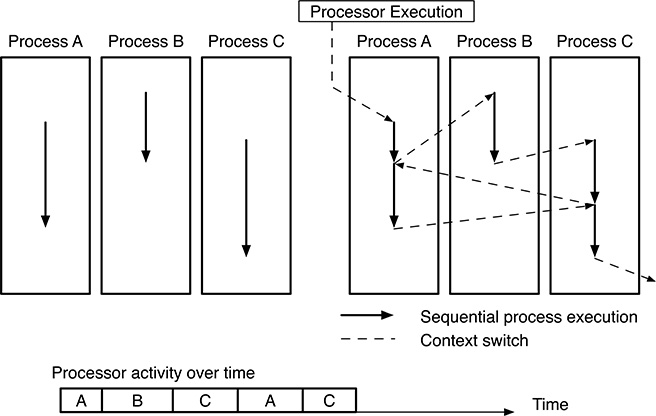
FIGURE 3.1
Multiprogramming: abstract model of three sequential processes (left) and their execution on a single-processor system (right).
3.2 Definition of Process
The concept of process was first introduced in the seminal work of Dijkstra [23]. In this model, any concurrent system, regardless of its nature or complexity, is represented by, and organized as, a set of processes that execute in parallel. Therefore, the process model encompasses both the application programs and the operating system itself. Each process is autonomous and holds all the information needed to represent the evolving execution state of a sequential program. This necessarily includes not only the program instructions but also the state of the processor (program counter, registers) and memory (variables).
Informally speaking, each process can be regarded as the execution of a sequential program by “its own” processor even if, as shown in Figure 3.1, in a multiprogrammed system the physical processors may actually switch from one process to another. The abstract view of the system given by the process model is shown on the left side of the figure, where we see three independent processes, each with its own control flow and state information. For the sake of simplicity, both of them have been depicted with an arrow, representing in an abstract way how the execution proceeds with time.
On the other hand, the right side of the figure shows one of the many possible sequences of operations performed by a single-processor system to execute them. The solid lines represent the execution of a certain process, whereas the dashed lines represent context switches. The multiprogramming mechanism ensures, in the long run, that all processes will make progress even if, as shown in the time line of processor activity over time at the bottom of the figure, the processor indeed executes only one process at a time.
Comparing the left and right sides of Figure 3.1 explains why the adoption of the process model simplifies the design and implementation of a concurrent system: By using this model, the system design is carried out at the process level, a clean and easy to understand abstraction, without worrying about the low-level mechanisms behind its implementation. In principle, it is not even necessary to know whether the system’s hardware is really able to execute more than one process at a time or not, or the degree of such a parallelism, as long as the execution platform actually provides multiprogramming.
The responsibility of choosing which processes will be executed at any given time by the available processors, and for how long, falls on the operating system and, in particular, on an operating system component known as scheduler. Of course, if a set of processes must cooperate to solve a certain problem, not all possible choices will produce meaningful results. For example, if a certain process P makes use of some values computed by another process Q, executing P before Q is probably not a good idea.
Therefore, the main goal of concurrent programming is to define a set of interprocess communication and synchronization primitives. When used appropriately, these primitives ensure that the results of the concurrent program will be correct by introducing and enforcing appropriate constraints on the scheduler decisions. They will be discussed in Chapters 5 and 6.
Another aspect of paramount importance for real-time systems—that is, systems in which there are timing constraints on system activities—is that, even if the correct application of concurrent programming techniques guarantees that the results of the concurrent program will be correct, the scheduling decisions made by the operating system may still affect the behavior of the system in undesirable ways, concerning timing.
This is due to the fact that, even when all constraints set forth by the interprocess communication and synchronization primitives are met, there are still many acceptable scheduling sequences, or process interleaving. Choosing one or another does not affect the overall result of the computation, but may change the timing of the processes involved.
As an example, Figure 3.2 shows three different interleavings of processes P, Q, and R. All of them are ready for execution at t = 0, and their execution requires 10, 30, and 20 ms of processor time, respectively. Since Q produces some data used by P, P cannot be executed before Q. For simplicity, it is also assumed that processes are always run to completion once started and that there is a single processor in the system.
Interleaving (a) is unsuitable from the concurrent programming point of view because it does not satisfy the precedence constraint between P and Q stated in the requirements, and will lead P to produce incorrect results. On the other hand, interleavings (b) and (c) are both correct in this respect—the precedence constraint is met in both cases—but they are indeed very different from the system timing point of view. As shown in the figure, the completion time of P and R will be very different. If we are dealing with a real-time system and, for example, process P must conclude within 50 ms, interleaving (b) will satisfy this requirement, but interleaving (c) will not.
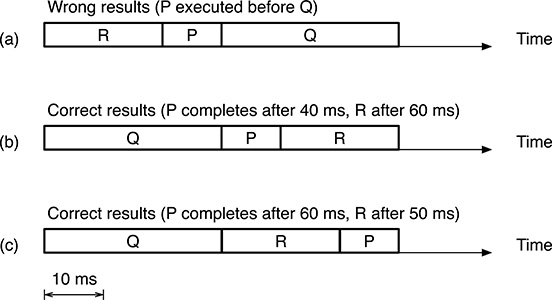
FIGURE 3.2
Unsuitable process interleavings may produce incorrect results. Process interleaving, even when it is correct, also affects system timing. All processes are ready for execution at t = 0.
In order to address this issue, real-time systems use specially devised scheduling algorithms, to be discussed in Chapters 11 and 12. Those algorithms, complemented by appropriate analysis techniques, guarantee that a concurrent program will not only produce correct results but it will also satisfy its timing constraints for all permitted interleavings. This will be the main subject of Chapters 13 through 16.
3.3 Process State
In the previous section, we discussed how the concept of process plays a central role in concurrent programming. Hence, it is very important to clearly define and understand what the “contents” of a process are, that is, what the process state components are. Interestingly enough, a correct definition of the process state is very important from the practical viewpoint, too, because it also represents the information that the operating system must save and restore in order to perform a transparent context switch from one process to another.
There are four main process state components, depicted in Figure 3.3:
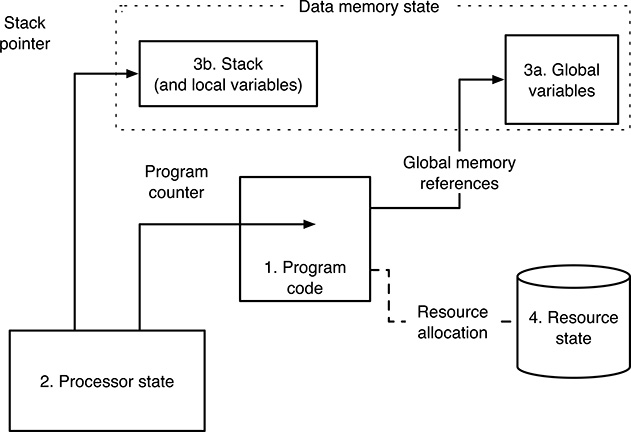
FIGURE 3.3
Graphical representation of the process state components.
Program code, sometimes called the text of the program;
Processor state: program counter, general purpose registers, status words, etc.
Data memory, comprising the program’s global variables, as well as the procedure call stack that, for many programming languages, also holds local variables;
The state of all operating system resources currently assigned to, and being used by the process: open files, input–output devices, etc.
Collectively, all memory locations a process can have access to are often called address space. The address space therefore includes both the program code and the data memory. See Chapter 2 for more general information about this and other related terms from the application programmer’s point of view.
The need of including the program code in the process state is rather obvious because, by intuition, the execution of different programs will certainly give rise to different activities in the computer system. On the other hand, the program code is certainly not enough to characterize a process. For example, even if the program code is the same, different execution activities still come out if we observe the system behavior at different phases of program execution, that is, for different values of the program counter. This observation can be generalized and leads to the inclusion of the whole processor state into the process state.
However, this is still not enough because the same program code, with the same processor state, can still give origin to distinct execution activities depending on the memory state. The same instruction, for example, a division, can in fact correspond to very different activities, depending on the contents of the memory word that holds the divisor. If the divisor is not zero, the division will be carried out normally; if it is zero, most processors will instead take a trap.
The last elements the process state must be concerned with are the operating system resources currently assigned to the process itself. They undoubtedly have an influence on program execution—that is, in the final analysis, on the process—because, for example, the length and contents of an input file may affect the behavior of the program that is reading it.
It should be noted that none of the process state components discussed so far have anything to do with time. As a consequence, by design, a context switch operation will be transparent with respect to the results computed by the process, but may not be transparent for what concerns its timeliness. This is another way to justify why different scheduling decisions—that is, performing a context switch at a certain instant instead of another—will not affect process results, but may lead to either an acceptable or an unacceptable timing behavior. It also explains why other techniques are needed to deal with, and satisfy, timing constraints in real-time systems.
The fact that program code is one of the process components but not the only one, also implies that there are some decisive differences between programs and processes, and that those two terms must not be used interchangeably. Similarly, processes and processors are indeed not synonyms. In particular:
A program is a static entity. It basically describes an algorithm, in a formal way, by means of a programming language. The machine is able to understand this description, and execute the instructions it contains, after a suitable translation.
A process is a dynamic concept and captures the notion of program execution. It is the activity carried out by a processor when it is executing a certain program and, therefore, requires some state information, besides the program code itself, to be characterized correctly.
A processor is a physical or virtual entity that supports program execution and, therefore, makes processes progress. There is not necessarily a one-to-one correspondence between processors and processes, because a single processor can be time-shared among multiple processes through multiprogramming.
3.4 Process Life Cycle and Process State Diagram
In the previous section, we saw that a process is characterized by a certain amount of state information. For a process to exist, it is therefore necessary to reserve space for this information within the operating system in a data structure often called Process Control Block (PCB), and initialize it appropriately.
This initialization, often called process creation, ensures that the new process starts its life in a well-known situation and that the system will actually be able to keep track of it during its entire lifetime. At the same time, most operating systems also give to each process a process identifier (PID), which is guaranteed to be unique for the whole lifetime of the process in a given system and must be used whenever it is necessary to make a reference to the process.
Depending on the purpose and complexity of the system, it may be possible to precisely determine how many and which processes will be needed right when the system itself is turned on. Process creation becomes simpler because all processes can be statically created while the system as a whole is being initialized, and it will not be possible to create new processes afterwards.
This is often the case with simple, real-time control systems, but it becomes more and more impractical as the complexity of the system and the variety of functions it must fulfill from time to time grow up. The most extreme case happens in general purpose systems: it would be extremely impractical for users to have to decide which applications they will need during their workday when they turn on their personal computer in the morning and, even worse, being constrained to reconfigure and restart it whenever they want to start an application they did not think about before.
In addition, this approach may be quite inefficient from the point of view of resource usage, too, because all the processes may start consuming system resources a long time before they are actively used. For all these reasons, virtually all general purpose operating systems, as well as many real-time operating systems, also contemplate dynamic process creation. The details of this approach vary from one system to another but, in general terms:
During initialization, the operating system crafts a small number, or even one single process. For historical reasons, this process is often called init, from the terminology used by most Unix and Unix-like systems [64].
All other processes are created (directly or indirectly) by init, through the invocation of an appropriate operating system service. All newly created processes can, in turn, create new processes of their own.
This kind of approach also induces a hierarchical relationship among processes, in which the creation of a new process sets up a relation between the existing process, also called the parent, and the new one, the child. All processes, except init, have exactly one parent, and zero or more children. This relationship can be conveniently represented by arranging all processes into a tree, in which
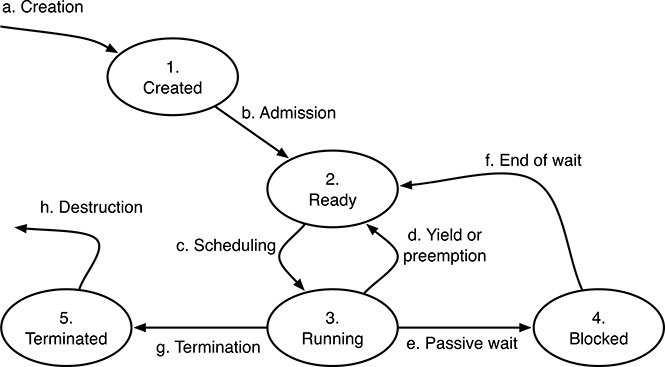
FIGURE 3.4
An example of process state diagram.
Each process corresponds to a node
Each parent–child relation corresponds to an arc going from the parent to the child.
Some operating systems keep track and make use of this relationship in order to define the scope of some service requests related to the processes themselves. For example, in most Unix and Unix-like systems only the parent of a process can wait for its termination and get its final termination status. Moreover, the parent–child relation also controls resource inheritance, for example, open files, upon process creation.
During their life, processes can be in one of several different states. They go from one state to another depending on their own behavior, operating system decision, or external events. At any instant, the operating systems has the responsibility of keeping track of the current state of all processes under its control.
A useful and common way to describe in a formal way all the possible process states and the transition rules is to define a directed graph, called Process State Diagram (PSD), in which nodes represent states and arcs represent transitions.
A somewhat simplified process state diagram is shown in Figure 3.4. It should be remarked that real-world operating systems tend to have more states and transitions, but in most cases they are related to internal details of that specific operating systems and are therefore not important for a general discussion.
Looking at the diagram, at any instant, a process can be in one of the following states:
A process is in the Created state immediately after creation. It has a valid PCB associated with it, but it does not yet compete for execution with the other processes present in the system.
A process is Ready when it is willing to execute, and competes with the other processes to do so, but at the moment there is not any processor available in the system to actually execute it. This happens, for example, when all processors are busy with other processes. As a consequence, processes do not make any progress while they are ready.
A process being actively executed by a processor is in the Running state. The upper limit to the number of running processes, at any given time, is given by the total number of processors available in the system.
Sometimes, a process will have to wait for an external event to occur, for example, the completion of an input–output (I/O) operation. In other cases, discussed in Chapters 5 and 6, it may be necessary to block a process, that is, temporarily stop its execution, in order to correctly synchronize it with other processes and let them communicate in a meaningful way. All those processes are put in the Blocked state. A process does not compete for execution as long as it is blocked.
Most operating systems do not destroy a process immediately when it terminates, but put it in the Terminated state instead. In this state, the process can no longer be executed, but its PCB is still available to other processes, giving them the ability to retrieve and examine the summary information it contains. In this way, it is possible, for example, to determine whether the process terminated spontaneously or due to an error.
The origin of a state transition may be either a voluntary action performed by the process that undergoes it, or the consequence of an operating system decision, or the occurrence of an event triggered by a hardware component or another process. In particular:
The initial transition of a newly created process into the Created state occurs when an existing process creates it and after the operating system has correctly initialized its PCB.
In most cases, during process creation, the operating system also checks that the bare minimum amount of system resources needed by the new process, for example, an adequate amount of memory to hold the program text, are indeed available.
The transition from the Created to the Ready state is under the control of an operating system function usually known as admission control. For general-purpose operating systems, this transition is usually immediate, and they may even lack the distinction between the Created and Ready states.
On the contrary, real-time operating systems must be much more careful because, as outlined in Section 3.2, the addition of a new process actively competing for execution can adversely affect the timings of the whole system.
In this case, a new process is admitted into the Ready state only after one of the schedulability and mode transition analysis techniques, to be described in Chapters 13 through 16, reaffirmed that the system will still meet all its timing requirements.
The transition from the Ready to the Running state is controlled by the operating system scheduler, according to its scheduling algorithm, and is transparent to the process that experiences it. Scheduling algorithms play a central role in determining the performance of a real-time system, and will be the main topic of Chapters 11 and 12.
The opposite transition, from Running to Ready, can be due to two distinct reasons:
Preemption, decided by the operating system scheduler, in which a process is forced to relinquish the processor even if it is still willing to execute.
Yield, requested by the process itself to ask the system to reconsider its scheduling decision and possibly hand over the processor to another process.
The high-level result is the same in both cases, that is, the process goes back to the Ready state both after a preemption and after a successful yield. The most important difference depends on the fact that, from the point of view of the process experiencing it, the transition is involuntary in the first case, and voluntary in the second.
Hence, a preemption may occur anywhere and at any time during process execution, whereas a yield may occur only at specific locations in the code, and at the time the process requests it.
A process transitions from the Running to the Blocked state when it voluntarily hands over the processor, because it is about to start a passive wait. This transition is typically a consequence of a synchronous input–output request or interprocess communication, to be discussed in Chapters 5 and 6. In all cases, the goal of the process is to wait for an external event to occur—for instance, it may be either the completion of the input–output operation or the availability of data from another process—without wasting processor cycles in the meantime.
When the event the process is waiting for eventually occurs, the process is awakened and goes back to the Ready state, and hence, it starts competing with the other processes for execution again. The process is not brought back directly to the Running state, because the fact that it has just been awakened does not guarantee that it actually is the most important process in the system at the moment. This decision pertains to the scheduler, and not to the passive wait mechanism. The source of the awakening event may be either another process, for interprocess communication, or a hardware component for synchronous I/O operations. In the latter case, the I/O device usually signals the occurrence of the event to the processor by means of an interrupt request, and the process is awakened as part of the consequent interrupt handling activity.
A process may go from the Running to the Terminated state for two distinct reasons:
When it voluntarily ends its execution because, for example, it is no longer needed in the system.
When an unrecoverable error occurs, unlike in the previous case, this transition is involuntary.
After termination, a process and its PCB are ultimately removed from the system with a final transition out of the Terminated state. After this transition, the operating system can reuse the same process identifier formerly assigned to the process for a new one.
This is crucial for what concerns process identification because, after this transition occurs, all uses of that PID become invalid or, even worse, may refer to the wrong process. It is therefore the responsibility of the programmer to avoid any use of a PID after the corresponding process went out of the Terminated state.
In some operating systems, the removal of the process and its PCB from the system is performed automatically, immediately after the summary information of the terminated process has been retrieved successfully by another process. In other cases, an explicit request is necessary to collect and reuse PCBs related to terminated processes.
From this discussion, it becomes evident that the PCB must contain not only the concrete representation of the main process state components discussed in Section 3.3, but also other information pertaining to the operating system and its process management activities.
This includes the current position of the process within the Process State Diagram and other process attributes that drive scheduling decisions and depend on the scheduling algorithm being used. A relatively simple scheduling algorithm may only support, for example, a numeric attribute that represents the relative process priority, whereas more sophisticated scheduling techniques may require more attributes.
3.5 Multithreading
According to the definition given in Section 3.3, each process can be regarded as the execution of a sequential program on “its own” processor. That is, the process state holds enough state information to fully characterize its address space, the state of the resources associated with it, and one single flow of control, the latter being represented by the processor state.
In many applications, there are several distinct activities that are nonetheless related to each other, for example, because they have a common goal. For example, in an interactive media player, it is usually necessary to take care of the user interface while decoding and playing an audio stream, possibly retrieved from the Internet. Other background activities may be needed as well, such as retrieving the album artwork and other information from a remote database.
It may therefore be useful to manage all these activities as a group and share system resources, such as files, devices, and network connections, among them. This can be done conveniently by envisaging multiple flows of control, or threads, within a single process. As an added bonus, all of them will implicitly refer to the same address space and thus share memory. This is a useful feature because many interprocess communication mechanisms, for instance, those discussed in Chapter 5, are indeed based on shared variables.
Accordingly, many modern operating systems support multithreading, that is, they support multiple threads within the same process by splitting the process state into per-process and per-thread components as shown in Figure 3.5. In particular,
The program code is the same for all threads, so that all of them execute from the same code base.
Each thread has its own processor state and procedure call stack, in order to make the flows of control independent from each other.
All threads evolve autonomously for what concerns execution, and hence, each of them has its own position in the PSD and its own scheduling attributes.
All threads reside in the same address space and implicitly share memory.
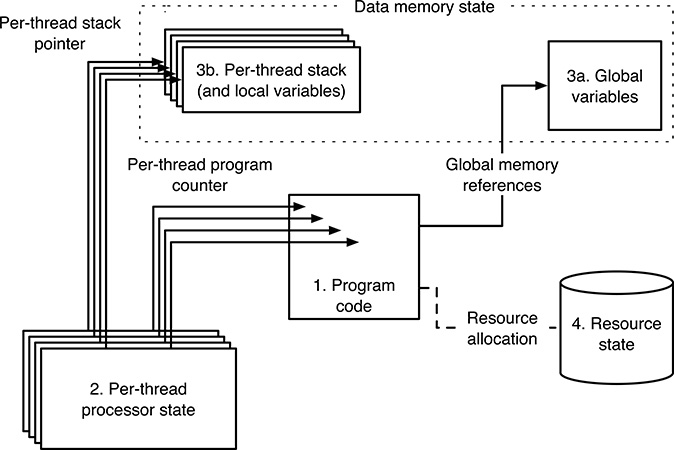
FIGURE 3.5
Graphical representation of the process state components in a multithreading system.All resources pertaining to the process are shared among its threads.
Another important reason for being aware of multithreading is that a full-fledged implementation of multiple processes must be assisted by hardware, particularly to enforce address space separation and protection. For example, on contemporary Intel processors, this is accomplished by means of a Memory Management Unit (MMU) integral to the processor architecture and other related hardware components, such as the Translation Lookaside Buffer (TLB) [45].
The main disadvantage of MMUs is that they consume a significant amount of silicon area and power. Moreover, since they contribute to chip complexity, they are also likely to increase the cost of the processor. For this reason some processor architectures such as, for example, the ARM architectures v6 [5] and v7-M [6] offer a choice between a full MMU and a simpler hardware component called Memory Protection Unit (MPU), which does not provide address translation but is still able to ensure that the address space of each process is protected from unauthorized access by other processes.
Nonetheless, many processors of common use in embedded systems have neither an MMU nor an MPU. Any operating systems running on those processors are therefore forced to support only one process because they are unable to provide address space protection. This is the case for many small real-time operating systems, too. In all these situations, the only way to still support multiprogramming despite the hardware limitations is through multithreading.
For example, the ARM Cortex-M3 [7] port of the FreeRTOS operating system [13], to be discussed in Chapter 17, can make use of the MPU if it is available. If it is not, the operating system still supports multiple threads, which share the same address space and can freely read and write each other’s data.
3.6 Summary
In this chapter, the concept of process has been introduced. A process is an abstraction of an executing program and encompasses not only the program itself, which is a static entity, but also the state information that fully characterizes execution.
The notion of process as well as the distinction between programs and processes become more and more important when going from sequential to concurrent programming because it is essential to describe, in a sound and formal way, all the activities going on in parallel within a concurrent system. This is especially important for real-time applications since the vast majority of them are indeed concurrent.
The second main concept presented in this chapter is the PSD. Its main purpose is to define and represent the different states a process may be in during its lifetime. Moreover, it also formalizes the rules that govern the transition of a process from one state to another.
As it will be better explained in the next chapters, the correct definition of process states and transitions plays a central role in understanding how processes are scheduled for execution, when they outnumber the processors available in the systems, how they exchange information among themselves, and how they interact with the outside world in a meaningful way.
Last, the idea of having more than one execution flow within the same process, called multithreading, has been discussed. Besides being popular in modern, general-purpose systems, multithreading is of interest for real-time systems, too. This is because hardware limitations may sometimes prevent real-time operating systems from supporting multiple processes in an effective way. In that case, typical of small embedded systems, multithreading is the only option left to support concurrency anyway.