
Modifying Observations Located by an Index
Overview
You
have learned that you can use a BY statement to access values that
you want to update in a master data set by matching. When you have
an indexed master data set, you can use the index to directly access
the observations that you want to update. To do this, you use the
following statements:
-
a MODIFY statement with the KEY= option to name an index to locate the observations for updating
-
a SET statement or INPUT statement to read a transaction data set with a like-named variable or variables whose values are supplied to the index
|
General form, MODIFY
statement with the KEY= option:
MODIFY SAS-data-set KEY=index-name;
SAS-data-set
is the master data
set, or the data set that you want to update.
index-name
is the name of the
simple or composite index that you are using to locate observations.
|
Updating with an index
is different from updating using a BY statement. When you use the
MODIFY statement with the KEY= option to name an index, the following
must occur:
-
You must explicitly specify the update that you want to occur.
-
Each observation in the transaction data set must have a matching observation in the master data set. If you have multiple observations in the transaction data set for one master observation, only the first observation in the transaction data set is applied. The other observations generate run-time errors and terminate the DATA step (unless you use the UNIQUE option, which is discussed later in this chapter).
Example
Suppose that airline
cargo weights for 1999 are stored in the master data set Cargo99,
which has a composite index named FlghtDte on the variables FlightID
and Date. Some of the data is incorrect and the data set needs to
be updated. The correct cargo data is stored in the transaction data
set Newcgnum.
In the program below,
the KEY= option specifies the FlghtDte index. When a matching observation
is found in Cargo99, three variables (CapCargo, CargoWgt, and CargoRev)
are updated.
Note: If you choose to run this
example, you must copy the data set Cargo99 from the Sasuser library
to the Work library.
proc print data=cargo99(obs=5);
run;
data cargo99;
set sasuser.newcgnum (rename =
(capcargo = newCapCargo
cargowgt = newCargoWgt
cargorev = newCargoRev));
modify cargo99 key=flghtdte;
capcargo = newcapcargo;
cargowgt = newcargowgt;
cargorev = newcargorev;
run;
proc print data=cargo99(obs=5);
run;The output below shows
the first five observations of the SAS data set Cargo99 before it
was modified by Newcgnum.
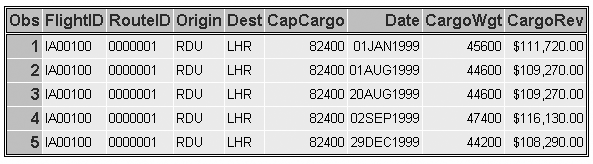
The output below shows
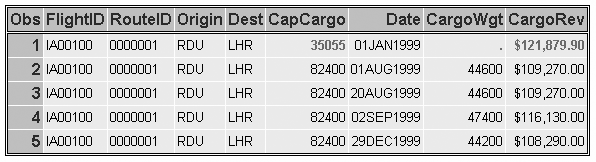
the first five observations of the SAS data set Cargo99 after it was
modified by Newcgnum. Notice that the three variables in the first
observation were updated by the values in Newcgnum.
Handling Duplicate Values
When
you use an index to locate observations to update, duplicate values
of the indexed variable in the transaction data set might cause problems.
We consider what happens with various scenarios when you use the following
code to update the master data set M with values from the transaction
data set T. The index on the M data set is built on the variable A:
data m; set t (rename=(b=newb)); modify m key=a; b=newb; run;
If there are duplications
in the master data set, only the first occurrence is updated.
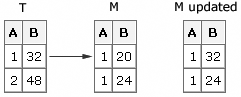
Tip
If you want all duplicates
in the master data set to be updated with the transaction value, use
a DO loop to execute a SET statement with the KEY= option multiple
times.
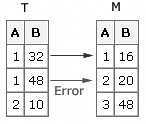
If
there are nonconsecutive duplications in the transaction data set,
SAS updates the first match in the master data set. The last duplicate
transaction value is the result in the master data set after the update.
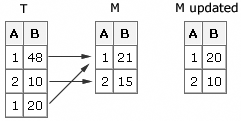
If there are consecutive
duplications in the transaction data set (that is, some that do not
have a match in the master data set), then SAS performs a one-to-one
update until it finds a non-match. At that time, the DATA step terminates
with an error.
Adding
the UNIQUE option to the MODIFY statement enables you to avoid the
error in the DATA step. The UNIQUE option causes the DATA step to
return to the top of the index each time it looks for a match. The
UNIQUE option can be used only with the KEY= option.
|
General form, MODIFY
statement with the UNIQUE option:
MODIFY SAS-data-set KEY=index-name
/UNIQUE;
SAS-data-set
is
the name of the SAS data set that you want to modify (the master data
set).
index-name
is the name of the
simple or composite index that you are using to locate observations.
|
You can specify the
UNIQUE option in order to do one of the following:
-
apply multiple transactions to one master observation
-
identify that each observation in the master data set contains a unique value of the index variable.
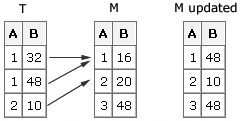
When you use the UNIQUE
option and there are consecutive duplications in the transaction data
set, SAS updates the first observation in the master data set. This
is similar to what happens when you have nonconsecutive duplications
in the transaction data set. If the values in the transaction data
set should be added to the value in the master data set, you can write
a statement to accumulate the values from all the duplicates.
..................Content has been hidden....................
You can't read the all page of ebook, please click here login for view all page.