
1.2. Random Vectors, Means, Variances, and Covariances
Suppose y1,...,yp are p possibly correlated random variables with respective means (expected values) μ1, ..., μp. Let us arrange these random variables as a column vector denoted by y, that is, let
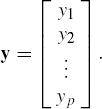
We do the same for μ1, μ2, ..., μp, and denote the corresponding vector by μ. Then we say that the vector y has the mean μ or in notation E(y) = μ.
Let us denote the covariance between yi and yj by σij, i, j = 1, ..., p, that is
σij = cov(yi, yj) = E[(yi - μi)(yj - μj)] = E[(yi - μi)yj] = E(yiyj) - μiμj
and let

Since cov(yi, yj) = cov(yj, yi), we have σij = σij. Therefore, Σ is symmetric with (i, j)th and (j, i)th elements representing the covariance between yi and yj. Further, since var(yi) = cov(yi, yi) = σii, the ith diagonal place of Σ contains the variance of yi. The matrix Σ is called the dispersion or the variance-covariance matrix of y. In notation, we write this fact as D(y) = Σ. Various books follow alternative notations for D(y) such as cov(y) or var(y). However, we adopt the less ambiguous notation of D(y).
Thus,
Σ = D(y) = E[(y - μ)(y - μ)′] = E[(y - μ)y′] = E(yy′) - μμ′,
where for any matrix (vector) A, the notation A′ represents its transpose.
The quantity tr(Σ) = ![]() is called total variance and a determinant of Σ, denoted by |Σ|, is often referred to as the generalized variance. The two are often taken as the overall measures of the variability of the random vector y. However, both of these two measures suffer from certain shortcomings. For example, the total variance tr(Σ) being the sum of only diagonal elements, essentially ignores all covariance terms. On the other hand, the generalized variance |Σ| can be misleading since two very different variance covariance structures can sometimes result in the same value of generalized variance. Johnson and Wichern (1998) provide certain interesting illustrations of such situations.
is called total variance and a determinant of Σ, denoted by |Σ|, is often referred to as the generalized variance. The two are often taken as the overall measures of the variability of the random vector y. However, both of these two measures suffer from certain shortcomings. For example, the total variance tr(Σ) being the sum of only diagonal elements, essentially ignores all covariance terms. On the other hand, the generalized variance |Σ| can be misleading since two very different variance covariance structures can sometimes result in the same value of generalized variance. Johnson and Wichern (1998) provide certain interesting illustrations of such situations.
Let up×1 and zq × 1 be two random vectors, with respective means μu and μz. Then the covariance of u with z is defined as
Σuz = cov(u, z) = E[(u - μu)(z - μz)′] = E[(u - μu)z′] = E(uz′) - μuμ′z.
Note that as matrices, the p by q matrix Σuz = cov(u,z) is not the same as the q by p matrix Σzu = cov(z,u), the covariance of z with u. They are, however, related in that
Σuz = Σ′zu.
Notice that for a vector y, cov(y, y) = D(y). Thus, when there is no possibility of confusion, we interchangeably use D(y) and cov(y) (= cov(y, y)) to represent the variance-covariance matrix of y.
A variance-covariance matrix is always positive semidefinite (that is, all its eigenvalues are nonnegative). However, in most of the discussion in this text we encounter dispersion matrices which are positive definite, a condition stronger than positive semidefiniteness in that all eigenvalues are strictly positive. Consequently, such dispersion matrices would also admit an inverse. In the subsequent discussion, we assume our dispersion matrix to be positive definite.
Let us partition the vector y into two subvectors as
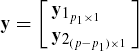
and partition Σ as
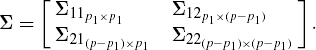
Then, E(y1) = μ1, E(y2) = μ2, D(y1) = Σ11, D(y2) = Σ22, cov(y1, y2) = Σ12, cov(y2, y1) = Σ21. We also observe that Σ12 = Σ′21.
The, Pearson's, correlation coefficient, between, yi, and, yj, denoted by ρij, is defined by

and accordingly, we define the correlation coefficient matrix of y as
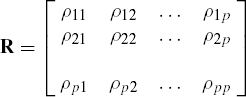
It is easy to verify that the correlation coefficient matrix R is a symmetric positive definite matrix in which all the diagonal elements are unity. The matrix R can be written, in terms of matrix Σ, as
where diag (Σ) is the diagonal matrix obtained by retaining the diagonal elements of Σ and by replacing all the nondiagonal elements by zero. Further, the square root of any matrix A, denoted by A![]() , is a symmetric matrix satisfying the condition, A = A
, is a symmetric matrix satisfying the condition, A = A![]() A
A![]() .
.
The probability distribution (density) of a vector y, denoted by f(y), is the same as the joint probability distribution of y1, ..., yp. The marginal distribution f1(y1) of y1 = (y1, ..., yp1)′, a subvector of y, is obtained by integrating out y2 = (yp1+1, ..., yp)′ from the density f(y). The conditional distribution of y2, when y1 has been held fixed, is denoted by g(y2|y1) and is given by
g(y2|y1) = f(y)f1(y1).
An important concept arising from conditional distribution is the partial correlation coefficient. If we partition y as (y′1, y′2)′ where y1 is a p1 by 1 vector and y2 is a (p - p1) by 1 vector, then the partial correlation coefficient between two components of y1, say yi and yj, is defined as the Pearson's correlation coefficient between yi and yj conditional on y2 (that is, for a given y2). If Σ11·2 = (aij) is the p1 by p1 variance-covariance matrix of y1 given y2, then the population partial correlation coefficient between yi and yj, i, j = 1, ..., p1 is given by
The matrix of all partial correlation coefficients ρij, p1+1, ..., p,i, j = 1, ..., p1 is denoted by R11·2. More simply, using the matrix notations, R11·2 can be computed as
[diag (Σ11·2)]−½Σ11·2[diag,(Σ11·2)]−½,
where diag, (Σ11·2) is a diagonal matrix with respective diagonal entries the same as those in Σ11·2.
Many times it is of interest to find the correlation coefficients between yi and yj, i, j = 1, ..., p, conditional on all yk, k = 1, ..., p, k ≠ i, k ≠ j. In this case, the partial correlation between yi and yj can be interpreted as the strength of correlation between the two variables after eliminating the effects of all the remaining variables.
In many linear model situations, we would like to examine the overall association of a set of variables with a given variable. This is often done by finding the correlation between the variable and a particular linear combination of other variables. The Multiple correlation coefficient is an index measuring the association between a random variable y1 and the set of remaining variables represented by a (p - 1) by 1 vector y2. It is defined as the maximum correlation between y1 and c′y2, a linear combination of y2, where the maximum is taken over all possible nonzero vectors c. This maximum value, representing the multiple correlation coefficient between y1 and y2, is given by
where
and the maximum is attained for the choice c = Σ22−1Σ21. The multiple correlation coefficient always lies between zero and one. The square of the multiple correlation coefficient, often referred to as the population coefficient of determination, is generally used to indicate the power of prediction or the effect of regression.
The concept of multiple correlation can be extended to the case in which the random variable y1 is replaced by a random vector. This leads to what are called canonical correlation coefficients.