
Chapter 3. Basic Concepts of Relational Database Design
The real key to writing a maintainable, performant business application is much the same as building a house: get the foundation right!
When talking about a house, if your foundation is constructed incorrectly, you may not notice it at first. You may notice that your door begins to stick in its frame, cracks appear in your walls over windows, or maybe tiles on your floor pop out—the first hints of trouble. The symptoms may seem small at first, but if not corrected may result in significant damage to the structure of your home.
While this isn’t a book about home building, it’s no coincidence that both software engineering and home building employ developers and architects with similar responsibilities to the design and development of their products. Wearing our software architect hat, we will start by discussing the foundation of our application: the database.
Normalization
You may wonder why we begin a book on SharePoint, SQL 2012, and LightSwitch with what might seem like an academic discussion of database normalization. Think back to our example of a house; everything we build from here on out will depend on the foundation of our application, which is the database. Once you master these basic concepts of database design, you have the tools to analyze any set of data and build a robust structure or schema that will ensure data integrity and keep your application maintainable for years to come.
When talking about database design, there are a couple of main concepts we should discuss. The first is called normalization; the second is called de-normalization. If you were to apply for a position on my team, I would ask why you might normalize or de-normalize a database. Today, I’ll give you the answer.
Normalization is the process of organizing your data to minimize redundancy. The goal of database normalization is to have smaller, less redundant tables with relationships between them. Database normalization is a practice used in an online transaction processing system (OLTP) to ensure the integrity and performance of a system that records data or is transactional in nature. De-normalization is the process of flattening your data and removing joins to simplify the schema and improve reporting performance.
These relational concepts were first presented in 1970 in a thesis by Edgar Codd of IBM. Modern data storage and business applications are primarily based on his concepts of a relational database. Interestingly enough, not only did the concepts of relational database normalization come from Codd, but he also coined the term OLAP or Online Analytical Processing, which is used to describe the data structures used for business intelligence, and which we will cover in later chapters. By 1971, Codd had expanded his guidance from first normal form (1NF) to second normal form (2NF) and finally third normal form (3NF). A database is referred to as normalized if it meets all the rules of 3NF, which we’ll walk you through next. It’s important to remember that these rules are additive: to meet the rules of 2NF, you must also meet 1NF; and to meet 3NF, you must meet the rules of 1NF, 2NF, and 3NF.
First Normal Form: Stop repeating yourself
When getting your data into 1NF, there are a few rules you need to follow:
Before Codd’s relational database model was published, the de facto standard for mainframe databases was a hierarchical database model where information was stored in a tree structure with parent-child relationships. The second rule is an important departure from hierarchical databases where the order of records and their level of indenture indicated parent-child relationships. This order independence not only allows records to be reordered, but accessed via relationships from other tables.
This last rule is often seen as the defining rule of first normal form. Figure 3-1, Figure 3-2, and Figure 3-3 show examples of tables that violate the rules of 1NF, specifically in the way that they store the PhoneNumber. Figure 3-1 adds additional columns to store PhoneNumber2 and PhoneNumber3. This is a common mistake made by end users who design systems or novice developers.

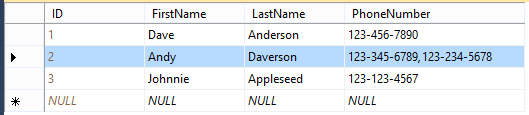
Figure 3-2 stores two values in the same column. SharePoint lists allow you to do this, but it violates the rules of first normal form and is not recommended when developing a business application.
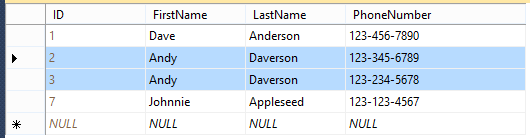
Figure 3-3 is creative in that is has a single phone number column, but uses a column to delimit the multiple phone numbers for Andy Daverson.
Imagine the challenges associated with storing your data in these ways. If I wanted to return all users with a phone number starting with ‘123,’ I’d need to write the following query against Figure 3-1:
Select * from MyTable where (PhoneNumber like '123%') or (PhoneNumber2 like '123%)' or (PhoneNumber3 like '123%')
Figure 3-2 and Figure 3-3 are perhaps worse because they lose the semantic significance of the PhoneNumber heading. That column could now contain a single telephone number, many numbers, or nothing at all.
We’ve talked about what not to do and identified examples that violate 1NF. Now let’s talk about an example that implements a structure that follows the rules of 1NF correctly. Figure 3-4 deconstructs the single table into two tables: one table describes the person, and the second table associates one or many PhoneNumbers with each person. You can see that by adding rows to the second table, one can add as many phone numbers as necessary. It’s easy to find a person who has a specific phone number.
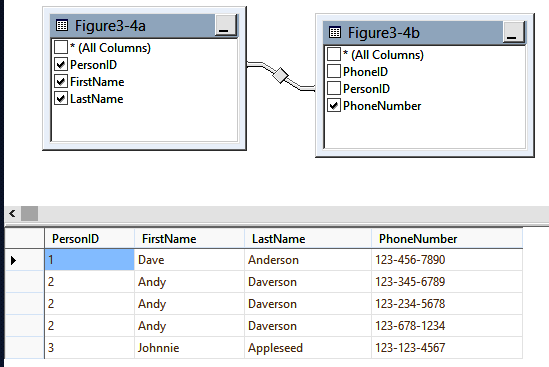
Now when we want to find everyone whose phone number starts with ‘123,’ we don’t need to know what column it’s stored in. The query to find everyone whose phone number starts with ‘123’ could be easily described as follows:
Select P.* from Person P inner join PhonerNumber PH on P.PersonID=PH.PersonID where PhoneNumber like '123%'
In short, by requiring that each row be uniquely identified, enforcing order independence, and removing repeating groups of data, Codd’s first normal form gives us the foundation to build a normalized database. Next, we’ll build on these concepts with the second normal form.
Second Normal Form: The Whole Key
The second normal form (2NF) focuses on removing repeating data from multiple rows by making sure that each attribute relies on the entire key. Having the same data across multiple rows can lead to errors when updating data in your table. Let’s look at Figure 3-5.
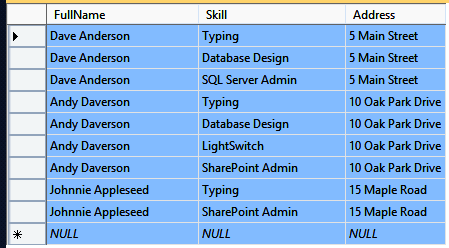
The first thing we need to do is identify the unique key for each row. In this case, we can’t use FullName or Skill because neither is unique. This example is tricky because uniqueness is defined by a composite key, which is composed of both FullName and Skill.
The Address column is only dependent on the FullName column, so this table does not conform to the rules of 2NF. Just like in Figure 3-4, we will normalize the data by breaking it into two tables as shown in Figure 3-6.
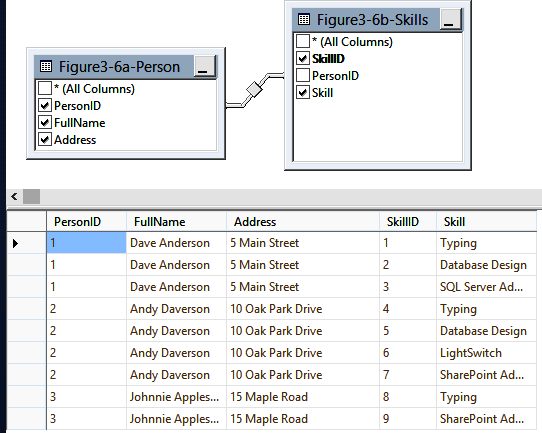
The first table has a key of PersonID, and both FullName and Address directly relate. The second table defines uniqueness with a composite key of PersonID and Skill. There are no columns in either table that do not relate to the full key, making this approach compliant with the rules of 2NF. When we update an address, it exists in only one place, preventing update errors.
Third Normal Form: Nothing but the Key
The third normal form (3NF) adds only one more rule for us to understand. 3NF simply states that every nonkey attribute or column in the table must provide a fact about the key.
Codd’s third normal form has been described memorably in a play on words similar to the swearing in of witnesses in a court of law: Every nonkey attribute must provide a fact about the key, the whole key, and nothing but the key, so help me Codd.
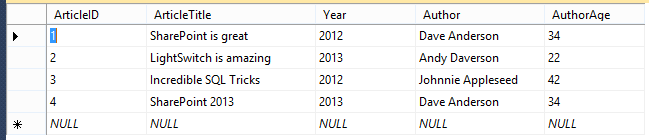
When we examine the data in Figure 3-7, this rule is easy to understand. ArticleID is the key for this table. ArticleTitle, Year, and Author directly relate to the article, but the AuthorAge does not.
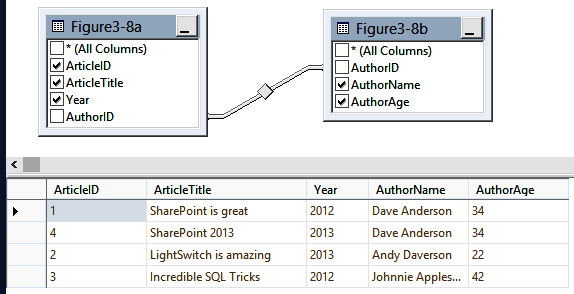
As you can see in Figure 3-8, we now have two tables in which every attribute or column relates directly to the key. We removed duplicate data, which ensures that we won’t have errors when updating the data.
Many-to-Many Relationships
Of all the database design issues seen over the years, many of them come from not knowing how to model a many-to-many relationship. Think of an example where you have many people and many products. You’d like to capture attributes about people and products, as well as capture who has worked on each of these products.
Let’s see how this works. We now have three tables (Figure 3-9). We have a Person table (Figure 3-9a) where all the attributes describe the person. It contains a PersonID and all attributes related back to that PersonID. We have a product table (Figure 3-9b) with a ProductID key. All attributes in the product table describe the ProductID. Finally, we have the table in the middle (Figure 3-9c) with a composite key that links them together by containing the keys of each table.
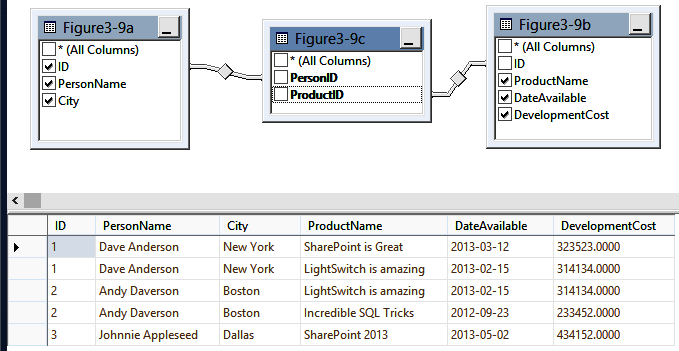
We could, of course, hang other attributes off this third table as long as they relate to the whole composite key following the rules we learned in 2NF.
Many-to-many relationships are easy to implement and are also very powerful. Think of the many real-world examples, such as a movie that has many actors, many of who have performed in other movies. You might also think of a recipe that has many ingredients, where each ingredient can be in several recipes. Many-to-many relationships are everywhere. Leverage this pattern and you can easily capture these relationships in your database design.
Summary
The concepts in this chapter are critical to designing any application that’s based on a relational database. If you’re still struggling with these concepts or want to learn more, check out some online resources. A good understanding of these fundamentals is essential to building a great business application.