
Chapter 12. C++ Wrapper API
Although many of the example applications described throughout this book have been developed using the programming language C++, we have focused exclusively on the OpenCL C API for controlling the OpenCL component. This chapter changes this by introducing the OpenCL C++ Wrapper API, a thin layer built on top of the OpenCL C API that is designed to reduce effort for some tasks, such as reference counting an OpenCL object, using C++.
The C++ Wrapper API was designed to be distributed in a single header file, and because it is built on top of the OpenCL C API, it can make no additional requirements on an OpenCL implementation. The interface is contained within a single C++ header, cl.hpp, and all definitions are contained within a single namespace, cl. There is no additional requirement to include cl.h. The specification can be downloaded from the Khronos Web site: www.khronos.org/registry/cl/specs/opencl-cplusplus-1.1.pdf.
To use the C++ Wrapper API (or just the OpenCL C API, for that matter), the application should include the line
#include <cl.hpp>
C++ Wrapper API Overview
The C++ API is divided into a number of classes that have a corresponding mapping to an OpenCL C type; for example, there is a cl::Memory class that maps to cl_mem in OpenCL C. However, when possible the C++ API uses inheritance to provide an extra level of type abstraction; for example, the class cl::Buffer derives from the base class cl::Memory and represents the 1D memory subclass of all possible OpenCL memory objects, as described in Chapter 7. The class hierarchy is shown in Figure 12.1.
Figure 12.1 C++ Wrapper API class hierarchy
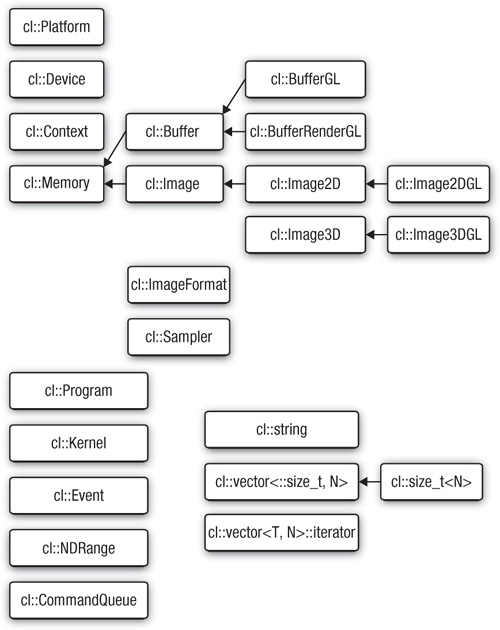
In general, there is a straightforward mapping from the C++ class type to the underlying OpenCL C type, and in these cases the underlying C type can be accessed through the operator (). For example, the following code gets the first OpenCL platform and queries the underlying OpenCL C type, cl_platform, assigning it to the variable platform:
std::vector<cl::Platform> platformList;
cl::Platform::get(&platformList);
cl_platform platform = platformList[0]();
In practice it should be possible to stay completely within the C++ Wrapper API, but sometimes an application can work only with the C API—for example, to call a third-party library—and in this case the () operator can be used. It is important to note that the C++ API will track the assignment of OpenCL objects defined via the class API and as such perform any required reference counting, but this breaks down with the application of the () operator. In this case the application must ensure that necessary calls to clRetainXX()/clReleaseXX() are peformed to guarantee the correctness of the program. This is demostrated in the following code:
extern void someFunction(cl_program);
cl_platform platform;
{
std::vector<cl::Platform> platformList;
cl::Platform::get(&platformList);
platform = platformList[0]();
someFunction(platform); // safe call
}
someFunction(platform); // not safe
The final line of this example is not safe because the vector platformList has been destroyed on exiting the basic block and thus an implicit call to clReleasePlatform for each platform in platformList happened, allowing the underlying OpenCL implementation to release any associated memory.
C++ Wrapper API Exceptions
Finally, before diving into a detailed example, we introduce OpenCL C++ exceptions. To track errors in an application that were raised because of an error in an OpenCL operation, the C API uses error values of type cl_int. These are returned as the result of an API function, or, in the case that the API function returns an OpenCL object, the error code is returned as the very last argument to the function. The C++ API supports this form of tracking errors, but it can also use C++ exceptions. By default exceptions are not enabled, and the OpenCL error code is returned, or set, according to the underlying C API.
To use exceptions they must be explicitly enabled by defining the following preprocessor macro before including cl.hpp:
__CL_ENABLE_EXCEPTIONS
Once enabled, an error value other than CL_SUCCESS reported by an OpenCL C call will throw the exception class cl::Error. By default the method cl::Error::what() will return a const pointer to a string naming the particular C API call that reported the error, for example, clGetDeviceInfo. It is possible to override the default behavior for cl::Error::what() by defining the following preprocessor macro before including cl.hpp:
__CL_USER_OVERRIDE_ERROR_STRINGS
You would also provide string constants for each of the preprocessor macros defined in Table 12.1.
Table 12.1 Preprocessor Error Macros and Their Defaults

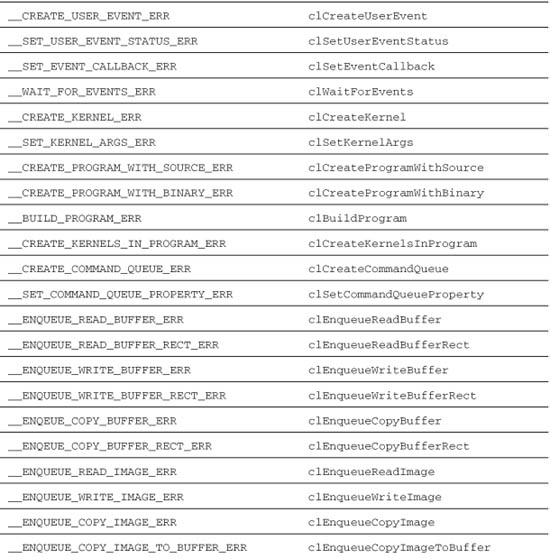
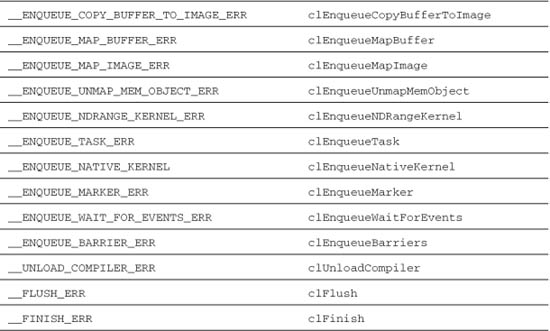
Vector Add Example Using the C++ Wrapper API
In Chapter 3, we outlined the structure of an application’s OpenCL usage to look something similar to this:
1. Query which platforms are present.
2. Query the set of devices supported by each platform.
a. Choose to select devices, using clGetDeviceInfo(), on specific capabilities.
3. Create contexts from a selection of devices (each context must be created with devices from a single platform); then with a context you can
a. Create one or more command-queues
b. Create programs to run on one or more associated devices
c. Create a kernel from those programs
d. Allocate memory buffers and images, either on the host or on the device(s)
e. Write or copy data to and from a particular device
f. Submit kernels (setting the appropriate arguments) to a command-queue for execution
In the remainder of this chapter we describe a simple application that uses OpenCL to add two input arrays in parallel, using the C++ Wrapper API, following this list.
Choosing an OpenCL Platform and Creating a Context
The first step in the OpenCL setup is to select a platform. As described in Chapter 2, OpenCL uses an ICD model where multiple implementations of OpenCL can coexist on a single system. As with the HelloWorld example of Chapter 2, the Vector Add program demonstrates the simplest approach to choosing an OpenCL platform: it selects the first available platform.
First cl::Platform::get() is invoked to retrieve the list of platforms:
std::vector<cl::Platform> platformList;
cl::Platform::get(&platformList);
After getting the list of platforms, the example then creates a context by calling cl::Context(). This call to cl::Context() attempts to create a context from a GPU device. If this attempt fails, then the program will raise an exception, as our program uses the OpenCL C++ Wrapper exception feature, and the program terminates with an error message. The code for creating the context is
cl_context_properties cprops[] = {
CL_CONTEXT_PLATFORM,
(cl_context_properties)(platformList[0])(),
0};
cl::Context context(CL_DEVICE_TYPE_GPU, cprops);
Choosing a Device and Creating a Command-Queue
After choosing a platform and creating a context, the next step for the Vector Add application is to select a device and create a command-queue. The first task is to query the set of devices associated with the context previously created. This is achieved with a call to cl::Context::getInfo<CL_CONTEXT_DEVICES>(), which returns the std::vector of devices attached to the context.
Before continuing, let’s examine this getInfo() method, as it follows a pattern used throughout the C++ Wrapper API. In general, any C++ Wrapper API object that represents a C API object supporting a query interface, for example, clGetXXInfo() where XX is the name of the C API object being queried, has a corresponding interface of the form
template <cl_int> typename
detail::param_traits<detail::cl_XX_info, name>::param_type
cl::Object::getInfo(void);
At first reading this may seem a little overwhelming because of the use of a C++ template technique called traits (used here to associate the shared functionality provided by the clGetXXInfo()), but because programs that use these getInfo() functions never need to refer to the trait components in practice, it does not have an effect on code written by the developer. It is important to note that all C++ Wrapper API objects that correspond to an underlying C API object have a template method called getInfo() that takes as its template argument the value of the cl_XX_info enumeration value being queried. This has the effect of statically checking that the requested value is valid; that is, a particular getInfo() method will only accept values defined in the corresponding cl_XX_info enumeration. By using the traits technique, the getInfo() function can automatically derive the result type.
Returning to the Vector Add example where we query a context for the set of associated devices, the corresponding cl::Context::getInfo() method can be specialized with CL_CONTEXT_DEVICES to return a std::vector<cl::Device>. This is highlighted in the following code:
// Query the set of devices attached to the context
std::vector<cl::Device> devices =
context.getInfo<CL_CONTEXT_DEVICES>();
Note that with the C++ Wrapper API query methods there is no need to first query the context to find out how much space is required to store the list of devices and then provide another call to get the devices. This is all hidden behind a simple generic interface in the C++ Wrapper API.
After selecting the set of devices, we create a command-queue, with cl::CommandQueue(), selecting the first device for simplicity:
// Create command-queue
cl::CommandQueue queue(context, devices[0], 0);
Creating and Building a Program Object
The next step in the Vector Add example is to create a program object, using cl::Program(), from the OpenCL C kernel source. (The kernel source code for the Vector Add example is given in Listing 12.1 at the end of the chapter and is not reproduced here.) The program object is loaded with the kernel source code, and then the code is compiled for execution on the device attached to the context, using cl::Program::build(). The code to achieve this follows:
cl::Program::Sources sources(
1,
std::make_pair(kernelSourceCode,
0));
cl::Program program(context, sources);
program.build(devices);
As with the other C++ Wrapper API calls, if an error occurs, then an exception occurs and the program exits.
Creating Kernel and Memory Objects
In order to execute the OpenCL compute kernel, the arguments to the kernel function need to be allocated in memory that is accessible on the OpenCL device, in this case buffer objects. These are created using cl::Buffer(). For the input buffers we use CL_MEM_COPY_FROM_HOST_PTR to avoid additional calls to move the input data. For the output buffer (i.e., the result of the vector addition) we use CL_MEM_USE_HOST_PTR, which requires the resulting buffer to be mapped into host memory to access the result. The following code allocates the buffers:
cl::Buffer aBuffer = cl::Buffer(
context,
CL_MEM_READ_ONLY | CL_MEM_COPY_HOST_PTR,
BUFFER_SIZE * sizeof(int),
(void *) &A[0]);
cl::Buffer bBuffer = cl::Buffer(
context,
CL_MEM_READ_ONLY | CL_MEM_COPY_HOST_PTR,
BUFFER_SIZE * sizeof(int),
(void *) &B[0]);
cl::Buffer cBuffer = cl::Buffer(
context,
CL_MEM_WRITE_ONLY | CL_MEM_USE_HOST_PTR,
BUFFER_SIZE * sizeof(int),
(void *) &C[0]);
The kernel object is created with a call to cl::Kernel():
cl::Kernel kernel(program, "vadd");
Putting this all together, Listing 12.1 at the end of the chapter gives the complete program for Vector Add using the C++ Wrapper API.
Executing the Vector Add Kernel
Now that the kernel and memory objects have been created, the Vector Add program can finally queue up the kernel for execution. All of the arguments to the kernel function need to be set using the cl::Kernel:setArg() method. The first argument to this function is the index of the argument, according to clSetKernelArg() in the C API. The vadd() kernel takes three arguments (a, b, and c), which correspond to indices 0, 1, and 2. The memory objects that were created previously are passed to the kernel object:
kernel.setArg(0, aBuffer);
kernel.setArg(1, bBuffer);
kernel.setArg(2, cBuffer);
As is normal after setting the kernel arguments, the Vector Add example queues the kernel for execution on the device using the command-queue. This is done by calling cl::CommandQueue::enqueueNDRangeKernel(). The global and local work sizes are passed using cl::Range(). For the local work size a special instance of the cl::Range() object is used, cl::NullRange, which, as is implied by the name, corresponds to passing NULL in the C API, allowing the runtime to determine the best work-group size for the device and the global work size being requested. The code is as follows:
queue.enqueueNDRangeKernel(
kernel,
cl::NullRange,
cl::NDRange(BUFFER_SIZE),
cl::NullRange);
As discussed in Chapter 9, queuing the kernel for execution does not mean that the kernel executes immediately. We could use cl::CommandQueue::flush() or cl::CommandQueue::finish() to force the execution to be submitted to the device for execution. But as the Vector Add example simply wants to display the results, it uses a blocking variant of cl::CommandQueue::enqueueMapBuffer() to map the output buffer to a host pointer:
int * output = (int *) queue.enqueueMapBuffer(
cBuffer,
CL_TRUE, // block
CL_MAP_READ,
0,
BUFFER_SIZE * sizeof(int));
The host application can then process the data pointed to by output, and once completed, it must release the mapped memory with a call to cl::CommandQueue::enqueueUnmapMemObj ():
err = queue.enqueueUnmapMemObject(
cBuffer,
(void *) output);
Putting this all together, Listing 12.1 gives the complete program for Vector Add.
This concludes the introduction to the OpenCL C++ Wrapper API. Chapter 18 covers AMD’s Ocean simulation with OpenCL, which uses the C++ API.
Listing 12.1 Vector Add Example Program Using the C++ Wrapper API
// Enable OpenCL C++ exceptions
#define __CL_ENABLE_EXCEPTIONS
#if defined(__APPLE__) || defined(__MACOSX)
#include <OpenCL/cl.hpp>
#else
#include <CL/cl.hpp>
#endif
#include <cstdio>
#include <cstdlib>
#include <iostream>
#define BUFFER_SIZE 20
int A[BUFFER_SIZE];
int B[BUFFER_SIZE];
int C[BUFFER_SIZE];
static char
kernelSourceCode[] =
"__kernel void
"
"vadd(__global int * a, __global int * b, __global int * c)
"
"{
"
" size_t i = get_global_id(0);
"
"
"
" c[i] = a[i] + b[i];
"
"}
"
;
int
main(void)
{
cl_int err;
// Initialize A, B, C
for (int i = 0; i < BUFFER_SIZE; i++) {
A[i] = i;
B[i] = i * 2;
C[i] = 0;
}
try {
std::vector<cl::Platform> platformList;
// Pick platform
cl::Platform::get(&platformList);
// Pick first platform
cl_context_properties cprops[] = {
CL_CONTEXT_PLATFORM,
(cl_context_properties)(platformList[0])(), 0};
cl::Context context(CL_DEVICE_TYPE_GPU, cprops);
// Query the set of devices attached to the context
std::vector<cl::Device> devices =
context.getInfo<CL_CONTEXT_DEVICES>();
// Create command-queue
cl::CommandQueue queue(context, devices[0], 0);
// Create the program from source
cl::Program::Sources sources(
1,
std::make_pair(kernelSourceCode,
0));
cl::Program program(context, sources);
// Build program
program.build(devices);
// Create buffer for A and copy host contents
cl::Buffer aBuffer = cl::Buffer(
context,
CL_MEM_READ_ONLY | CL_MEM_COPY_HOST_PTR,
BUFFER_SIZE * sizeof(int),
(void *) &A[0]);
// Create buffer for B and copy host contents
cl::Buffer bBuffer = cl::Buffer(
context,
CL_MEM_READ_ONLY | CL_MEM_COPY_HOST_PTR,
BUFFER_SIZE * sizeof(int),
(void *) &B[0]);
// Create buffer that uses the host ptr C
cl::Buffer cBuffer = cl::Buffer(
context,
CL_MEM_WRITE_ONLY | CL_MEM_USE_HOST_PTR,
BUFFER_SIZE * sizeof(int),
(void *) &C[0]);
// Create kernel object
cl::Kernel kernel(program, "vadd");
// Set kernel args
kernel.setArg(0, aBuffer);
kernel.setArg(1, bBuffer);
kernel.setArg(2, cBuffer);
// Do the work
queue.enqueueNDRangeKernel(
kernel,
cl::NullRange,
cl::NDRange(BUFFER_SIZE),
cl::NullRange);
// Map cBuffer to host pointer. This enforces a sync with
// the host backing space; remember we chose a GPU device.
int * output = (int *) queue.enqueueMapBuffer(
cBuffer,
CL_TRUE, // block
CL_MAP_READ,
0,
BUFFER_SIZE * sizeof(int));
for (int i = 0; i < BUFFER_SIZE; i++) {
std::cout << C[i] << " ";
}
std::cout << std::endl;
// Finally release our hold on accessing the memory
err = queue.enqueueUnmapMemObject(
cBuffer,
(void *) output);
// There is no need to perform a finish on the final unmap
// or release any objects as this all happens implicitly
// with the C++ Wrapper API.
}
catch (cl::Error err) {
std::cerr
<< "ERROR: "
<< err.what()
<< "("
<< err.err()
<< ")"
<< std::endl;
return EXIT_FAILURE;
}
return EXIT_SUCCESS;
}