
Chapter 14. Road Map to Part III
Every one is responsible for his own actions.
—Tamil proverb
While Part II was devoted to the static structure of the software solution, this part is devoted to the dynamics of the solution. Previously we examined what objects are, what they know, and how they are logically related. Now it is time to focus on what objects do.
Part III Road Map
In the translation methodologies in general and MBD in particular, the notion of dynamics has two parts: the structure of behavior, as captured in finite state machines (FSMs); and the actual algorithmic content, which we capture in an abstract action language. The use of finite state machines is mandatory in MBD for several reasons.
• Transitions define sequencing constraints from the problem space. Capturing such rules in static structure tends to simplify the executable code and enhance reliability.
• Certain types of sequencing errors can be detected and handled quite generically in a state machine infrastructure. Such errors can be detected in one place, the event queue manager, and handled in one place rather than having the detection code littered through many contexts.
• Interacting state machines are very unforgiving. Logical errors are very often immediately manifested. This makes it difficult to get them to interact properly initially, but once they are working they tend to be remarkably robust.
• State Transition Tables (STT) and State Transition Diagrams (STD) provide a high-level view of flow of control. This high-level view facilitates maintenance to a degree that is difficult to believe until we have actually used them. For example, in the author’s experience roughly 70% of all logical errors can be isolated to a single state action by simply inspecting the relevant STDs for a few minutes.
• Interacting state machines are the best approach to dealing with the asynchronous communication model that is used in OOA/D for behaviors.
• The rules of finite state automata that govern state machines happen to rigorously enforce a number of OO fundamentals, such as encapsulation, implementation hiding, and peer-to-peer collaboration.
All of these things are important, but the last is the most significant by far. If we were to try to design a mechanism to enforce good OO practice, it would end up looking very much like object state machines.1 Unfortunately, using state machines is not very intuitive to most newcomers to software development, which is why three full chapters are devoted to them.
State machines are not just for breakfast.
Sadly, the conventional wisdom contains a myth that state machines are only applicable to certain types of software development, specifically arcane areas of real-time embedded (R-T/E) programming. This perception is utterly untrue. Once we get used to using state machines it becomes clear that they can be applied to describe any behavior that is appropriate for OO design. The key insight is that state machines capture sequencing rules among behaviors in a very elegant manner. To the extent that sequencing of operations is absolutely critical to dynamics, state machines actually provide a very general tool for managing dynamics. In addition, most applications will be simpler, more robust, and more reliable for having employed them.
It’s All about Behavior
Software is ultimately computational; it executes a solution to a problem that consists of a sequence of a very large number of tiny operations. Those operations may manipulate data, and the operations may be organized into clusters, but ultimately there will be no useful results without the solution doing a lot of mundane computation. All the object behavior responsibilities that we abstract as necessary to solving the problem in hand must execute.
The computational nature of software remains in place, but at the OOA level we have done a lot to organize it in particular ways. We have been very careful to define what data the behaviors chew upon. We have been careful about defining associations that restrict what data the behaviors chew upon. We have organized combinations of logically related knowledge and behavior responsibilities into objects that are abstracted from real entities in the customer’s problem space. When we define behavior responsibilities, we define them in terms of intrinsic, logically indivisible responsibilities. All of that static structure defined in Part II was focused on one objective: providing a stable framework for specifying the behaviors that will be executed in the solution and the sequence in which they will be executed.
If you are unfamiliar with state machines, we will be discussing them in nauseating detail in the next few chapters. For the moment all you have to know is the summary in Figure 14-1. A state machine consists of states and transitions. A state is a condition where a particular suite of rules and policies apply, represented by the circles. We move from one state to another via a transition, which is a directed line between current and next states. The transition is triggered by an external event that carries a data packet with it. In the figure the alphabet is abstracted as individual data elements: a, b, c, and so on. Each state has an action that executes the relevant rules and policies when the state is entered, and that action processes the incoming alphabet according to the rules and policies of the state. That action is a behavior responsibility because it executes the rules and policies that prevail for the condition.
Figure 14-1. Notation for a Finite State Automata (FSA)
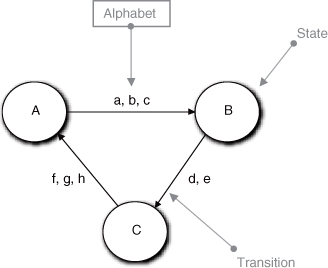
Particular events trigger transitions, so the state machine must be in the right current state to transition when a particular event is consumed. That is, there must be a transition exiting the current state to which the event is attached; otherwise, an error condition is raised. Thus the combination of events and transitions provides constraints on the sequencing of actions. A fundamental assumption of FSMs is that in a state, the action cannot know what state the machine was in previously or what the next state will be.
Now let’s look at the properties of state machines and see how they line up with OO practice (see Table 14-1).
Table 14-1. Comparison of State Machines and OO Practice
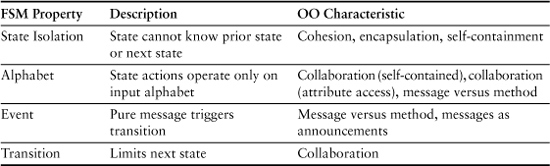
The fact that a state represents a condition where a unique suite of rules and policies apply, when combined with the constraint on knowing nothing about where it is going or where it is has been, provides a very rigorous encapsulation of a self-contained behavior. While the rules on processing an alphabet are more restrictive for finite state automata, they are generally relaxed for software state machines so that they match up exactly with the way the OO approach handles state variables. In other words, the action can obtain its alphabet either from the incoming event or by directly accessing state variables within the constraints of association navigation.2 The notion of a state machine event very clearly corresponds directly with the notion of a message in OO collaboration.
The rules that govern valid transitions place rigorous constraints on the way collaborations can be executed. That is, it is the developer’s job to make sure that a state machine is sent only events that will be valid for it when the event is consumed. Thus transitions provide constraints on behavior sequencing during collaborations that are analogous to the constraints on attribute access provided by association navigation. Providing this analogous suite of (static) constraints on behavior sequencing is one of the main reasons MBD chooses to employ object state machines to describe all behavior. If we simply define methods without the state machine infrastructure, there is no explicit, structural mechanism for enforcing such sequencing rules.
Object state machines define collaboration.
Because of the way we abstract objects, they tend to be rather simple. Thus we expect that their behaviors, as expressed in state machine actions, should be rather simple. One of the main things we do when we use state machines is provide a rigorous framework for collaboration. The sequencing rules inherent in the transitions constrain interactions between objects. Those constraints drive how the objects must collaborate when we connect the dots for the overall problem solution. This will become much more obvious after we talk about DbC in a state machine context later in Part III. For the moment, just hold the thought that the actions may implement the behaviors but the state machine structure provides the skeleton for collaboration between behaviors.
As was mentioned, state machines are very unforgiving—precisely because of the sequencing rules implicit in the transitions. When we do not have the sequencing quite right, a transition error will be raised very quickly because the state machine is in the wrong state to consume the event. That’s because those sequencing rules are explicitly incorporated in the static structure of the state machine itself. Without state machines to provide the necessary condition checking, the developer would have to encode it explicitly in the behaviors in every relevant context where the behavior is invoked, which would lead to very verbose, fragile, and redundant code.
The importance of strictly enforcing sequencing rules in the static structure of state machines cannot be overemphasized—it makes a huge difference for both code size and overall reliability. As a bonus, when the static structure constraints are violated it is very easy to detect, and we can provide that detection in the architectural infrastructure that the transformation engine provides. So, as application developers, we do not even have to even think about detecting the errors. The bad news is that you are likely to generate a lot of unexpected errors the first time you execute the overall model. The good news is that once you get them all fixed, you can be quite confident you have gotten the solution right.
Getting state machines to interact correctly usually requires implicit protocols for collaborations. Such protocols are known as handshaking. At its most basic level, the idea behind handshaking is that a message is not sent until the receiver announces that it is ready to accept the message. In effect we create a dialog between the objects that ensures that the solution steps will be executed in the correct sequence. The UML Interaction diagrams are classic examples of defining handshaking sequences, whether we employ object state machines or not.
Object Life Cycles
Complex behaviors that are related almost always entail some sort of sequential process; they must be performed in a set of steps that have a predefined order. Because the order is predefined, those steps are always executed in the same order no matter how many times the overall behavior is repeated. Such sequence and repetition is fundamental to hardware computational models. One way to think about the sequence of steps in an overall behavior is to think of the sequence as a life cycle of the overall behaviors, where the individual steps are stages in that life cycle.
In an OO environment this notion of life cycle is even more appropriate because we organize individual behaviors into cohesive suites in objects that represent problem space entities. Those entities very often have obvious life cycles in the problem space. For example, the construction of an automobile on a production line goes through a life cycle of growth from nothing to a fully assembled (mature) automobile. We can easily associate stages with that life cycle where various components are assembled: framing, drive train assembly, body assembly, and so forth. In the extreme, the notion of an instance of an object in a software application very clearly has a birth-to-death life cycle that never extends beyond a single execution of the software itself.
This notion of life cycle is just an analogy, but it is very pervasive in many problem space entities, computational sequences, software execution iterations, and the notion of objects being instantiated. Thus any construction paradigm based on the notion of life cycles is likely to be quite general in application.
That is especially true when we abstract objects as a collection of cohesive but stand-alone behavior responsibilities. Inevitably there will be some constraint in the overall solution that defines the order in which those individual responsibilities are executed. Thus, each responsibility has a designated place in the overall solution algorithm that defines a relative order. We use static transitions to define those sequencing dependencies as intrinsic constraints on the objects’ behaviors in the problem context.
When objects collaborate to solve the problem, those collaborations form sequences that are often repeated, forming small cycles of collaboration within the overall solution context. The sequencing of those interactions between objects is what we capture in the state machine transition rules. Thus the “stages” of the state machine life cycle are really determined by the sequencing of its interactions with the outside world. There are four ways to capture those sequencing rules for interaction.
- Enforcing the order in the implementations of behaviors that invoke other behaviors (i.e., “hard-wring” the sequence into method implementations)
- Providing elaborate checking at the end of behaviors to determine what to do next
- Daisy-chaining messages explicitly so that the order is enforced
- Enforcing the sequencing rules in an explicit static infrastructure.
The first approach is classically procedural in nature because it is based on functional decomposition, so it usually results in hierarchical implementation dependencies. You definitely do not want to go there if you are doing OO development. The second approach is tedious, bloats the application, and is usually error prone. You don’t want to go there unless you have a predilection toward masochism. The third approach is basically what the OO developer does if there is no explicit infrastructure to enforce the sequencing rules; the developer simply chains together operations in the right sequence. The problem here is that the developer has to get it right in every collaboration situation, and when it isn’t right that may not be readily detectable.
The last approach is exactly what a state machine life cycle provides. The transitions define the allowed sequences between one stage of interaction and the next within a suite of external collaborations. This has two big advantages over the third approach. First, it only needs to be done once when defining the life cycle of the object. Second, state machines are very unforgiving. When the sequence is wrong you always get an error. This makes finding logical sequencing problems in message generation much easier. The developer still has to get the message generation right, but it will usually be painfully clear immediately when it isn’t right.
Returning to the myth that state machines are just a niche tool, it should be clear that the opposite is actually the case. State machines provide an elegant mechanism of managing the sequences of operations that are inherent in any computational processing. More important, they actually enforce problem space rules on sequencing in a manner that makes it much easier to get the solution right.
Asynchronous Solution
In Chapter 2 it was noted that knowledge access is synchronous while behavior access is asynchronous in OOA/D. Now that we have the static structure under our belts we can expand upon the notion of asynchronous behavior communication. This is one of the fundamental things that distinguish OO design techniques, yet it is rarely explicitly mentioned in the OOA/D literature outside translation contexts. The author’s speculation is that translation grew up in R-T/E where there is simply no choice about rigorously making that distinction, while outside R-T/E methodologists choose to capture the distinction indirectly in design guidelines, principles, and rules.
The reason that an asynchronous model is employed for behavior collaboration is that the OOA model (aka MDA PIM) needs to be independent of the computing environment. Providing a synchronous versus asynchronous implementation is a decision that depends explicitly on the computing environment and nonfunctional requirements. An asynchronous model is the most general description of behavior collaboration. As indicated in Chapter 2, a synchronous implementation is a special case of asynchronous implementation. But to make this clear, we need to digress with some definitions because there is a lot of misunderstanding in the industry about the differences between synchronous, asynchronous, and concurrent implementations.
In synchronous processing, the order of execution of operations is deterministic in time for a given suite of inputs.
In asynchronous processing, the order of execution of operations is nondeterministic in time for a given suite of inputs.
Basically, this means that in a synchronous implementation the order of execution is predefined; it will always be exactly the same for any set of input data. Basic procedural flow of control, where a calling procedure pauses until the called procedure completes, is a synchronous mechanism because it guarantees that all procedures will be executed in a fixed order. Thus all 3GLs, including the OOPLs, are inherently synchronous in nature; we have to bootstrap special software artifacts, such as event queue managers, to deviate from the synchronous model.3
Essentially, asynchronous processing means that there is an arbitrary delay between when a message is sent and when an operation is executed in response to that message. So if we send multiple messages, the order in which the responses are executed is arbitrary. (There are some exceptions needed to preserve the developer’s sanity, which we will get to in the next chapter.) Note that this requires that the message be separated from the method, which is so fundamental to OOA/D that we have belabored it in almost every chapter of this book.
In asynchronous processing, the order of execution is not explicitly defined, and we can have different orders from one execution to the next even though the input data is identical. This view tends to be counterintuitive in a Turing world where the notion of a fixed sequence of operations is one of the cornerstones of the computational model. Unfortunately, the real world tends to be asynchronous when we deal with large problems. For example, network transmissions, particularly on the Internet, are notorious for having arbitrary delays due to traffic and routing problems. In Figure 14-2, assume Application A sends two messages, X and Y, to Application B and Application C, respectively.
Figure 14-2. Alternative sequences for message passing in a distributed environment
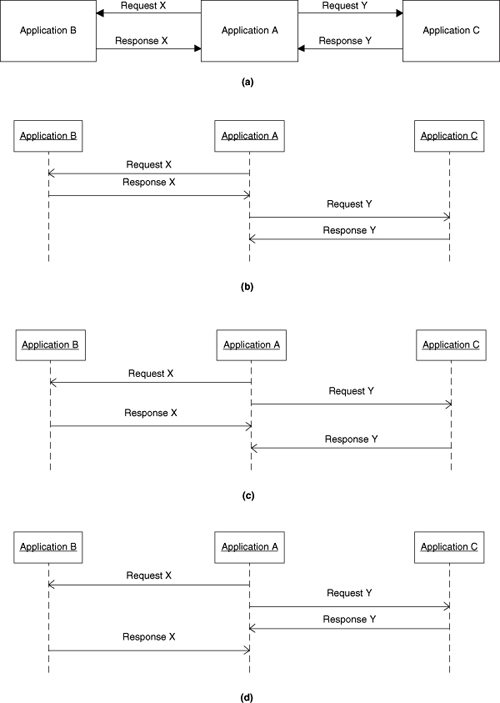
We would intuitively expect the responses from Application B and Application C to be in the same order that the requests were issued by Application A, as indicated in Figure 14-2(b). (In fact, Figure 14-2(b) represents a pure synchronous view if Application A pauses to wait for the response to Request X before sending Request Y.) However, on a network there is no guarantee of that because A does not wait for a response. Request X might be delayed so that Request Y could be consumed first, or Response X could be delayed to produce Figures 14-2(c) or 14-2(d) from Application A’s perspective. Any time we have processing that is load sensitive based upon something external to the problem solution, we have a potential for these sorts of physical delays. For example, the delay in recovering data from disk may depend upon the load placed on the DB server by other applications’ requests.
The notion of perspective is important when dealing with asynchronous behaviors because there is another source of asynchronous behavior besides physical delays, as in a network. Whenever the stimuli to an application are in arbitrary order, we have inherently asynchronous behavior. The message loop in a GUI application is a classic example of this. The user makes essentially arbitrary selections from menus and so forth that determine what the user wants to do. That ordering is entirely at the whim of the user. Therefore, from the application’s perspective, the order of requests for its functionality are in arbitrary order even though the data involved may be the same from one session to the next. So the user can ask for information on customer Ben and then customer Jerry in one session while asking for customer Jerry and then customer Ben in another session.
An alternative definition of asynchronous processing is that the order in which external messages are presented for consumption is arbitrary.
This sort of arbitrariness in the order of external requests is just a variation on the notion of delays, albeit more general.4 That is, we can interpret the variation in stimuli sequence in terms of delays. From the application’s viewpoint it always has the capability of processing a request for customer Ben or processing a request for customer Jerry, and the user requests both. As far as the application knows, the user always makes the requests in the same order, but there is a different arbitrary delay in their delivery from one session to the next. Thus the notions of message delays versus message ordering are just different perspectives of the same inherent arbitrary nature of communication ordering.
Asynchronous behavior is not the same as concurrent behavior.
One of the more common sources of confusion for novice developers is the difference between asynchronous behavior and concurrent behavior. As previously indicated, asynchronous behavior is about the ordering of messages or delays in responding to them. That is, asynchronous processing is about scheduling when a behavior is executed.
Concurrent processing involves the simultaneous execution of multiple behaviors.
Thus concurrency is about parallel execution of operations. If we have an application where only one method executes at a time, that application is not concurrent. Nonetheless, it can be asynchronous as long as the events that trigger each behavior’s execution are not presented in a predefined order. Using the previous example, if the application can only access customer Ben’s data or customer Jerry’s data but not both at the same time, it is inherently nonconcurrent.5 However, from the application’s viewpoint there is no way to tell which the user will request first during any given session, so the processing of those requests is inherently asynchronous.
Now suppose the application can process a request for customer Ben’s data and a request for customer Jerry’s data at the same time. Now the application is concurrent whenever the second user request arrives before the processing of the first request completes. (Note that it is still inherently asynchronous as well, since either message could be first.)
Now suppose the user can request both customer Ben’s data and customer Jerry’s data in a single request. Internally, the processing of customer Ben’s data is still a separate activity from processing customer Jerry’s data. As a design decision, the developer will probably decide to always kick off processing for customer Ben’s data first, immediately followed by kicking off processing for customer Jerry’s data.6 Now the order of kickoff events is predefined, so the application is synchronous. Yet it is still concurrent if the processing of the second event starts before the processing of the first event completes.
It is crucial to understand that asynchronous and concurrent processing are two very different things. Ironically, one reason this understanding is important is because in OOA we always think about asynchronous behavior communications while we never think about concurrent behavior processing! Understanding the difference explains why we can and do separate the two issues.
We can ignore concurrent processing in the OOA because it is a pure computing space implementation. The fundamental logic of the application will be correct whether parallel processing is used or not. That’s because we use parallel processing to address nonfunctional requirements like performance. Since our OOA solution to the customer’s problem is supposed to be independent of decisions made around nonfunctional requirements, we defer the decision to provide parallel processing or not.
Similarly, the decision to use a synchronous implementation versus an asynchronous implementation is a computing space decision. Alas, this situation is a bit different because we still need to have some model of behavior communications to define collaborations in the OOA. Since synchronous execution is a special case of asynchronous, we choose the more general model for the OOA and defer the decision to implement synchronously.
Time Slicing
Before leaving the topic of asynchronous/concurrent behavior communications we need to address a related topic. In the computational models of Turing and von Neumann there is no direct way to implement concurrency. In fact, with the advent of multiple processor ALUs, the academics had to work overtime to come up with entirely new branches of mathematics to deal with parallel computation.7
The main idea behind things like threads is the notion of time slicing, which is necessary if we have only one processor. If we have two sequences of machine instructions, each encapsulated in a procedure, and a single processor, we can emulate parallel processing by alternating the execution of statements from each procedure. Even though only one instruction from one procedure is executing at a time, from the perspective of an external observer the procedures both seem to execute in parallel. That’s because they both seem to start at about the same time and finish at about the same time. That’s because we subdivide the overall execution time into small time slices, and in each time slice we allocate the processor to a single procedure.
While this model of parallel processing is rather simplistic because of issues like instruction pipelining, it still conveys the general idea behind the practical implementation of concurrency. We just use things like threads to apply the scope of concurrency across multiple program units (methods). The onus is on the developer to ensure that the processing in one thread does not step on the toes of another thread’s processing. That is, the developer must be careful about defining threads that may access shared data.
The reason for bringing this up is because it demonstrates the sorts of issues the translation engine must address. This indirectly justifies a number of practices that are incorporated in OOA/D in general and MBD in particular—practices like separation of message and method; the use of object state machines; encapsulation of methods as logically indivisible, self-contained, intrinsic behaviors; treating knowledge access as synchronous while behavior access is asynchronous; and peer-to-peer messaging. All these things play together to manage scope in a way that makes life easier and deterministic for the transformation engine to implement things like concurrency.8
Synchronous Services
In a strict sense, not all behavior occurs in state machine actions, despite the previous discussion. Nor is all behavior asynchronous. Some behavior resides in what we cleverly call synchronous services, methods that are invoked directly rather than being triggered by events. MBD constrains what sorts of behaviors can be placed in synchronous services. But to understand those constraints we need to digress a bit into what constitutes behavior.
Thus far we have not distinguished among different sorts of behavior. That was fine so far because we were not dealing with the dynamics of solutions directly. Now, though, we need to identify certain characteristics of behaviors.
A problem-specific behavior is one that is unique to the customer problem in hand.
An invariant behavior is one that can be applied to multiple customer problems.
The overall solution to the customer’s problem is expressed in terms of problem-specific behaviors. When we talked about abstracting behavior responsibilities from the problem space that are necessary to solving the customer’s problem, we were talking about problem-specific behaviors. These behaviors make the developer’s solution for functional requirements unique. In practice, though, we often apply algorithms and whatnot that are not unique to the problem in hand. Such algorithms are generic or invariant relative to the customer problem space and can be applied to many different customer problems. Often we will “glue” together a number of such generic algorithms in our unique problem solution.
This picture is complicated by the abstraction of application partitioning into subject matters. In this view, any subsystem that can be reused in different applications is generic with regard to a particular application solution. Yet we abstract the content of service subsystems the same way we abstract the root problem subsystem. Application partitioning effectively changes our perspective about what a problem-specific behavior is and what an invariant behavior is. Thus each subsystem has its own subject matter problem space. When we abstract behaviors from the subject matter problem space, we are abstracting problem-specific behaviors for that problem space even though the application customer may not even know they exist.
For example, suppose we have an application that allocates a marketing budget to various advertising mediums (TV spots, newspaper ads, magazine ads, billboards, etc.). The overall solution will be all about notions like demographics, market size, media appeal, and region. Since it is a complex problem we may decide to use a particular mathematical operations research technique to solve the problem, say, a linear programming algorithm. Linear programming is a commonly used optimization technique, and the algorithm is self-contained.9 So the only thing about the algorithm that is unique to the budgeting problem is setting up the data the algorithm needs. That setup is problem specific because it depends on the semantics of the advertising context, such as demographics. But the linear programming algorithm itself is an invariant.
As a practical matter, the linear programming algorithm is fairly complicated, so it is likely we would encapsulate it in its own subsystem. For that subsystem the problem space is now a particular branch of operations research. The linear programming algorithm involves a bunch of standard manipulations of matrices in a particular sequence. We would likely abstract a number of specialized Matrix objects and would associate behaviors with them, such as transpose and invert. Those operations are defined in a much broader mathematical scope than linear programming, thus they are invariants relative to the subject matter’s problem of linear programming optimization.
The key point here is that our perception of what is problem specific and invariant is much like special relativity; it depends upon where the observer is standing. In particular, it depends upon which subsystem we are developing at the moment.
Problem-specific behaviors are organized by state machines.
Invariant behaviors are usually encapsulated in synchronous services or subsystems.
While our view of what is problem specific and what is invariant depends upon subject matter context, once we have established the appropriate perspective we need to be fastidious about where we put each sort of behavior. We put problem-specific behaviors in state machines because we use state machines to solve the subject matter problem via collaborations while state machine transitions define constraints on the sequencing. That’s because we need a disciplined way of connecting the dots for the overall solution, which is the creative part of solving the problem. Since invariant behaviors are defined elsewhere, we aren’t concerned with their internal flow of control because that is predefined. Therefore, we encapsulate them so they don’t distract us from solving the problem in hand.
The most common use of synchronous services is for objects that exist to hold knowledge. A classic example is a String class that we might use in OOP to manage text characters. Such an object has no intrinsic properties that are unique to the problem in hand. For example, if our String class is an ADT for a person’s address in the problem domain, the operations that the string class provides depend in no way on the problem semantics of address. Its intrinsic behaviors are solely manipulations of its knowledge (individual characters), even though they may be fairly complex, such as concatenation. Thus a String has no life cycle that is relevant to the problem in hand, so we would put all of its text manipulation behaviors in synchronous services.10
A similar logic applies to the Matrix abstraction in the prior example. The operations on a matrix’s elements can be quite complex algorithmically. But in the linear programming context they are self-contained data manipulations that are not at all dependent on a specific problem context like linear programming. Similarly, the entire linear programming technique is independent of a specific problem context like allocating marketing budgets. It is just so complex that it warrants being its own subsystem rather than being encapsulated as a synchronous service.
Generally we can classify synchronous services as the following:
• Accessor. The behavior reads or modifies the object’s knowledge. These are usually quite simple because they are limited to getting the value of the object’s knowledge or updating it with a new value.
• Tester. This behavior tests the value of the object’s information. For example, we might want to know if the current knowledge value is equal to a particular value.
• Transformer. This sort of synchronous service transforms the object’s information in some way. The classic examples are behaviors like transpose and invert that might be associated with a Matrix object.
• Instantiator. These synchronous services are used to instantiate objects and their associations.
There are three important characteristics of synchronous services that follow from this description. The first characteristic is that they are, indeed, synchronous. Unlike generating events, the synchronous service is invoked directly and the caller cannot continue until it is completed. The reason is that the client is accessing the object’s knowledge, which must be synchronous access in order to ensure data integrity. Since all synchronous services are ultimately invoked from state actions and we use an asynchronous model for behavior collaboration, this means that a synchronous service is an extension of the invoking state machine action.
The second characteristic is that they do not collaborate with problem-specific behaviors of other objects. Since we describe all significant problem-specific behavior with state machines in MBD and state machines provide the framework for behavior collaboration, this means that synchronous services should never generate events. This constraint is a direct result of the services being synchronous and being limited to operations on a narrowly defined set of data.11
The third characteristic of synchronous services is they do not apply rules and policies that are unique to the problem in hand. Drawing this line in the sand is usually easy for experienced OO developers, but it tends to seem quite arbitrary for novice OO developers. The problem is that if we want to get picky, any modification of data is behavior by definition. More to the point, modifying data is usually what behaviors live to do.
Sometimes we can use the uniqueness of the problem space as the criteria, as we did with the transform synchronous service of a Matrix object. We can stretch that to a conversion from volts units to millivolts units in an attribute setter because the conversion rule exists outside the specific problem’s space and the need to convert is implicit in the ADTs of source and target values. But what about a getter that computes the value of salaryCost by multiplying baseSalary by burdenRate?
The formula represents a business rule, but one can argue that it is dictated by invariant, external accounting standards. In the end, deciding whether business rules and policies can be in a synchronous service usually comes down to whether the knowledge change is intrinsic to the knowledge and does not depend on the overall solution state. In practice, this means that if there are constraints on when the knowledge can be modified relative to modifying other object knowledge or invoking object behaviors, then that constraint needs to be captured in a state machine transition so those rules and policies would have to be in a state machine action.
You will greatly reduce the risk associated with making the wrong guesses about using synchronous services versus state actions if your synchronous services are self-contained. They will also be more robust during maintenance if you keep them simple. In particular, it is a good idea to limit the content of each synchronous service to the categories identified at the start of the topic.12
Action Languages
Many moons ago, before MDA and UML, the dynamics of state actions and synchronous services were described using a special sort of Data Flow Diagram known as an Action Data Flow Diagram (ADFD). ADFDs are rarely used today because centuries of experience have provided us with very elegant text-based languages for describing algorithms. So by the mid-’90s, almost all the commercial translation tools had converted to using a text language to describe dynamics rather than the traditional ADFD. Alas, this conversion was not painless. Some of the early AALs quite literally mimicked the ADFD by mapping one process to one statement. This led to a very verbose syntax where every atomic process—read accessor, arithmetic operation, write accessor, etc.—had to be in a separate statement. That effectively eliminated compound expressions such as one typically finds in 3GL code. Worse, each such statement had to be on its own line. The end result was carpal tunnel syndrome for the developers and AAL code listings that killed more trees than the hard-copy printouts of the ADFDs! Fortunately, most modern AALs have adopted more conventional and compact syntax.
A far more serious problem, though, was the level of abstraction of the text AALs. Some vendors figured that if we used a 3GL directly as the action description language, we could save a lot of transformation processing and make the learning curve for the developer much easier. So a number of translation tools in the late ’80s and early ’90s decided to use C++ as the action description language.13 As it happens, those tools effectively became precursors of the round-trip tools that are common today.
Unfortunately this was a very slippery slope, because using a 3GL language to describe the dynamics completely trashes the level of abstraction of UML, which should be a 4GL. That’s because a 3GL is a language for implementing the design while the OOA model specifies the design. Moreover, in an MDA context the PIM should be independent of the choice of such languages. In addition, particular 3GLs introduce computing space implementations like stack-based memory scope management. But worst of all, from a language like C++ we can encode any strategy, access any available technology, and address any nonfunctional requirements. In other words, the developer can do anything that could normally be done during OOP. Thus, using a 3GL to describe dynamics opens a huge door for implementation pollution of the model that effectively destroys its value as an abstract design specification.
The AAL described later in Part III has a level of abstraction that is consistent with the rest of the OOA model and independent of particular implementations. Using such an AAL to describe detailed dynamics is the only way to obtain the advantages of a true 4GL problem solution.
Mealy versus Moore versus Harel
In Figure 14-1, a model for state machines was described where the relevant rules and policies were contained in an action executed on entry to a state. There are actually a number of different models for implementing finite state automata in state machines. The model described is known as the Moore model. In the Moore model, the state action is executed as a new state is entered, and it is quaintly called an entry action.
Another common model is the Mealy model where the action is attached to a transition rather than entry to the state. In this model we can have different actions associated with different transitions when there are multiple transitions to a given state. The Mealy model arose because of a conundrum with Moore when the practicalities of action execution were considered. A state machine must always be in some state, which implies that the transition between states is instantaneous. However, if an action is executed on entry to a state, this creates a problem because actions, in practice, take a finite time to execute. The Mealy model gets around this problem with the notion that the action is executed when the triggering event is “consumed” by the state machine, which enables the transition to be instantaneous upon completion of the action.
Mathematically, the Mealy and Moore models are fully convertible; any Mealy model has an equivalent Moore model and vice versa. There are some situations where a Moore state machine will have additional states compared to the Mealy version, but the logical equivalence holds.
MBD employs the Moore model.
MBD is adamant about using the Moore model. That’s because the Mealy model effectively associates the action with consuming the event. In other words, the notions of message (event) and method (action) are merged. From there it is a very short step to regarding the event as an imperative to do something (Do This). The MBD position is that we should avoid even the temptation to define collaborations in terms of imperatives, so MBD insists on rigorous separation of message and method to ensure events are regarded as announcements (I’m Done). By associating the action with entering the state rather than the event, MBD ensures a purist separation of the announcement message and the response action.
So how does MBD deal with the conundrum of an entry action taking finite time when the transition needs to be instantaneous? The short answer is that we don’t worry about it because it is an arcane theoretical issue. The engineering answer is that there is a logically equivalent Moore model for every Mealy model. If they are logically equivalent, then we can solve the OOA problem for the customer with Moore models. If that doesn’t satisfy you, then consider these two fundamental assumptions of MBD object state machines.
- An object’s state machine can consume only one event at a time.
- The current state of an object’s state machine is not visible outside the object’s implementation.
If these two practical rules apply, then it really doesn’t matter if the transition is instantaneous or not. The current state is only of interest for internally dispatching to the proper action. Prior to consuming an event, the state machine will be in a state. When finished consuming the event (i.e., when the action has completed execution), the state machine will be in the new state. Since the current state is externally inaccessible, any delay in transitioning cannot affect the solution results as long as only one event is consumed at a time.
Another popular state machine model found in OO contexts is the Harel model. The Harel model extends the Mealy model to include a notion of inheritance between distinct superclass state machines and subclass state machines. The Harel model also supports a notion of history about prior states that can be used to modify transitions. Using the Harel model can result in very elegant expressions of very complex interactions. This can be very useful for describing behavior at the subsystem level.
If you are tempted to use Harel for an object state machine, you probably have a serious problem with object abstraction.
The problem is that MBD does not use subsystem state machines; it only uses state machines to describe individual object behaviors. We take pains to provide cohesive abstractions of problem space entities that are self-contained, logically indivisible, and context-independent at the subject matter’s level of abstraction. We also tailor our object abstractions to the subject matter, which narrows the potential responsibilities. Those techniques tend to result in rather simple object abstractions. If the behavior of an individual object is so complex that it must be expressed using a Harel model, then it is very likely that the object has too many responsibilities, or it is not abstracted at the correct level of abstraction for the subsystem subject matter.14 If you are ever so tempted you should immediately look for a delegation in the problem space, as described in Part II.
The Learning Curve
Novices to OO development usually find it relatively easy to define abstract classes and relationships from the problem space. There are even mechanical techniques, such as Object Blitzes described in Part II, for identifying objects. Unfortunately, it often takes awhile before they get the knack of defining the right abstractions and getting them to play together properly. That is, the art of defining static structure lies in what we abstract from the problem space rather than in abstraction itself.
Exactly the opposite is usually true for dynamics. Novices often have difficulty in recognizing any life cycle in objects, which is why the myth arose that using state machines is a niche technique (i.e., they can be used everywhere except my problem). However, once the initial hurdle is overcome and they start to recognize life cycles readily, it becomes a fairly mechanical process to ensure that the state machines are well formed.
By the time the developer gets to the point of describing what goes on within state actions and synchronous services, the OO paradigm looks pretty much like procedural coding. Only the level of abstraction is different. As long as the responsibilities were properly defined during problem space abstraction, it is pretty hard to screw that up. And if we do screw it up, encapsulation and implementation hiding ensure that it won’t corrupt the rest of the solution.
So in Part III we are going to emphasize how we think about life cycles and provide some guidelines for making sure the life cycle is properly formed. An AAL will be described briefly, but only to the extent of describing how their level of abstraction is different from that of 3GLs.