
Communication is a crucial aspect of programming any multicore processor. If you can’t transfer data quickly between processing elements, you can’t take full advantage of the device. For this reason, the Cell provides direct memory access (DMA) for high-speed communication. DMA operates asynchronously to the SPU, which means you can transfer data while the SPU continues its regular processing.
The DMA commands presented in this chapter are simple to use and understand; the main concern is timing. With multiple SPUs transferring data simultaneously, coordination and synchronization become crucial concerns. DMA transfers can be ordered with fences and barriers. Resource access can be controlled with mutexes, readers/writers locks, condition variables, and completion variables.
This chapter discusses the code that performs DMA and the mechanisms available to coordinate communication. Most of this presentation centers on how the SPU transfers data to and from main memory, but before you start programming, you should have a basic understanding of how data is physically transported in the Cell.
DMA is made possible by two resources on the Cell: the Element Interconnect Bus (EIB) and the Memory Flow Controller (MFC). These are shown in Figure 12.1.
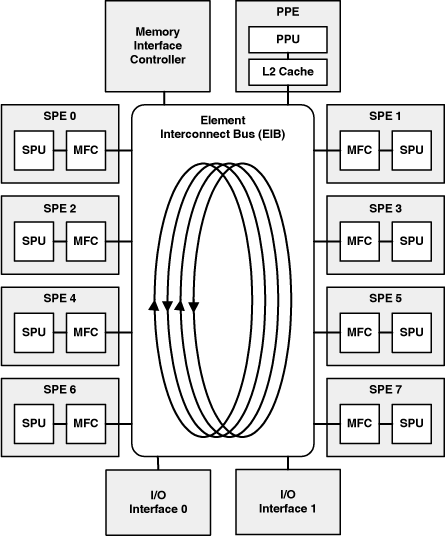
As shown, the EIB transfers data using four rings. Each ring is 16 bytes wide (the same width as a line of the SPU’s local store, LS) and carries data in one direction only. Two rings transport data in a clockwise direction, and two transport data in a counterclockwise direction.
An individual DMA operation takes eight bus cycles, for a maximum transport of 128 bytes of data. A DMA transfer may consist of multiple eight-cycle operations, for a maximum of 16KB. Each ring can support three DMA transfers simultaneously, so long as they don’t overlap. For example, if SPE1 attempts to send data to SPE7 while SPE3 is sending data to SPE5, the two transfers will have to be carried by separate rings.
Thankfully, you don’t have to choose which ring supports a given DMA transfer. The Cell provides a central arbitration mechanism that assigns resources to communication requests. But it’s still important to know how the bus operates, and there are three points to keep in mind:
To make best use of the EIB’s rings, make sure that communication doesn’t always flow in the same direction.
Avoid long-range data transfers that overlap other transfers. For example, try not to send data from the PPU to SPE7 while other SPUs need to use the bus.
No matter how much data you transport, each DMA transfer takes at least eight cycles on the EIB. It’s inefficient to use DMA to transfer less than 128 bytes at a time.
Of course, to follow guidelines 1 and 2, you need to know where your SPU contexts are positioned in the chip. This information isn’t easy to come by, but this topic is explored in Chapter 7, “The SPE Runtime Management Library (libspe),” specifically Section 7.5, “Direct SPE Access.”
In a single cycle, each of the four rings can sustain a maximum of three transfers of 16 bytes each. Thus, the EIB provides a maximum total bandwidth of 4 × 3 transfers/cycle × 16 bytes/transfer = 192 bytes/cycle. The more efficiently you use the bus, the closer your communication bandwidth will come to reaching this ideal.
SPUs don’t access the EIB directly. Instead, each SPU communicates with other processors through its Memory Flow Controller (MFC). The MFC is a coprocessor specifically designed to send and receive data on the EIB. The advantage of performing data transfer outside the SPU is that the MFC can perform its job without interfering with the SPU’s regular operation.
But the SPU still needs to tell the MFC what tasks to perform. To explain how the SPU interacts with the MFC, I’ve constructed an analogy that I’ll introduce here and elaborate upon in the next chapter.
Think of the SPU as an isolated scholar, taking books from a bookshelf (the LS) and reading them at a large desk (the register file). This scholar hates interruptions, but there are circumstances when it needs to interact with the rest of the world. These include the following:
The scholar needs to send/receive a short message to/from another scholar (mailboxes, signals).
The scholar needs to respond to an immediate emergency (events, interrupts).
The scholar needs more books for the bookshelf, or needs to send books to another scholar (DMA).
The scholar reads books quickly, so this last circumstance is common. But the scholar is too absorbed in work to get up from the desk, so it rings a bell and summons a butler (MFC). If the scholar needs new books, it tells the butler where to get them. If it needs to send books elsewhere, it tells the butler where to put them. Usually, this transfer is made between the bookshelf and a central library (main memory), but the butler can also carry books between the scholar’s bookshelf and another scholar’s bookshelf.
The scholar can give the butler up to 16 requests at a time, and can combine the requests into a list for greater efficiency. For each request, the scholar provides the butler with four pieces of information:
The number of books to be transported
The position in the bookshelf where books should be taken from or placed
The position in the library or other bookshelf where books should be taken from or placed
A number that identifies a series of similar requests (tag value)
When the butler receives this information, it leaves to perform the task. At this point, the scholar can return to reading or wait for the butler to finish.
Continuing this analogy, it’s important to note that a scholar’s butler (MFC) can also be contacted by other butlers, but the process isn’t as simple. Instead of ringing a bell, outside butlers must know the scholar’s home residence (effective address) and the location of the scholar’s bookshelf (LS). Once this information is obtained, scholars can use their butlers to trade books without difficulty.
Direct memory access (DMA) begins when the SPU sends a transfer request to the MFC. A single DMA transfer can transport data in sizes of 1, 2, 4, 8, and 16 bytes, and 16-byte multiples up to 16KB (16,384 bytes). The transfer is performed most efficiently when data is aligned on 128-byte boundaries, although DMA can transfer small data sizes that are naturally aligned (1-byte chars aligned on 1-byte boundaries, 2-byte shorts aligned on 2-byte boundaries, and so on).
volatile void *ls:If you’re only performing a single DMA transfer with a single SPU, the functions are simple: mfc_get and mfc_put. These functions take their names from the SPU’s point of view, so mfc_get tells the MFC to bring data into the LS and mfc_put tells the MFC to take data out of the LS. Both functions return void and have the same parameter list:
The LS address of the data to be transferred
unsigned long long ea:The effective address (EA) of the external data locationunsigned int size:The number of bytes to be transferredunsigned int tag:Value identifying a series of DMA requests (between 0 and 31)unsigned int tid:Transfer class identifierunsigned int rid:Replacement class identifier
The first three parameters are straightforward. Every SPU-initiated DMA transfer moves data between the LS and an effective address. The PPU commonly sends the value of ea to an SPU as one of its initialization parameters, such as argp. ls is usually a pointer to a data structure and size is set equal to the size of this data structure.
The next three arguments aren’t as simple. tag identifies a group of DMA transfers and makes it possible for the SPU to wait until communication is finished. The next section discusses tag groups in detail.
tid influences how the EIB assigns bandwidth to data transfers and rid influences the L2 cache’s replacement scheme. Using these capabilities requires privileged access to internal device registers, and both topics are poorly documented. In this book, tid and rid will always be set to 0.
For example, to transfer a data structure called buff out of the LS and into main memory at the address ea_addr, you’d use the following command:
mfc_put(&buff, ea_addr, sizeof(buff), 0, 0, 0);
After making a DMA request with mfc_get or mfc_put, the SPU can either continue processing data or wait for the transfer to complete. The instruction that tells the processor to wait is mfc_read_tag_status_all(). This is shown in the code in Listing 12.1, which calls mfc_get to fill an array of 128 chars. Then it invokes mfc_read_tag_status_all() to wait until the array is filled. When the transfer is finished, the SPU prints specific elements to standard output.
Example 12.1. Single DMA Transfer on the SPU: spu_dmabasic.c
#include <spu_mfcio.h>
#define TAG 31
int main(unsigned long long speid,
unsigned long long argp,
unsigned long long envp) {
/* The LS buffer that holds the data */
unsigned char asc[128] __attribute__ ((aligned (128)));
/* Transfer the array from argp to asc */
mfc_get(asc, argp, sizeof(asc), TAG, 0, 0);
/* Tell the MFC which tag group to monitor */
mfc_write_tag_mask(1<<TAG);
/* Wait for tag group to finish its transfer */
mfc_read_tag_status_all();
printf("%c%c%c%c%c %c%c%c%c%c%c
", asc[72], asc[101],
asc[108], asc[108], asc[111], asc[87], asc[111],
asc[114], asc[108], asc[100], asc[33]);
return 0;
}The PPU application in this example doesn’t call any DMA functions. It initializes an array of 128 chars and sends the SPU the array’s address through the argp parameter. The SPU transfers the array into its LS by calling mfc_get. Next, it tells the MFC that it wants to monitor tag group 31, and it calls mfc_read_tag_status_all to wait for the DMA transfer to finish.
In many cases, the SPU needs to transfer data in quantities that exceed the 16KB maximum for DMA. These bulk transfers, each consisting of multiple DMA requests, are managed using tag groups. Alternatively, a tag group can consist of a single transfer, as shown in Listing 12.1. The only requirement is that all transfers in a tag group are initialized with the same tag value.
Using tag groups provides two advantages. First, you can monitor when the transfers in a tag group complete their communication. Second, you can use synchronization commands to order individual DMA requests inside a tag group.
Transferring data with tag groups is like processing data with threads: You can’t control the operation, but you can find out when it completes. Checking for the completion of a tag group takes two steps. First, select the tag group or groups whose data transfer should be monitored. Second, read the tag status value to see whether the transfers have completed. The functions that make this possible are declared in spu_mfcio.h.
The first step involves placing a value in the SPU’s 32-bit tag group query mask. Each bit in this mask corresponds to one of the 32 possible tag groups, and if any of the bits are high, the SPU will monitor the status of the corresponding group. For example, the code in Listing 12.1 selects Tag Group 31 with the following function:
mfc_write_tag_mask(1<<31);
You can read the tag group query mask with mfc_read_tag_mask.
After you’ve selected a tag group or groups, the next step is to check the transfer status. In code, this status is represented by an unsigned int whose bits show whether the corresponding tag group has completed. If a status bit equals 1, the tag group’s DMA transfers have finished.
Three functions are available for checking the status of a tag group’s transfers:
mfc_read_tag_status_immediate: Returns the status immediatelymfc_read_tag_status_any: Returns the status when one of the selected tag groups completes its transfersmfc_read_tag_status_all: Returns the status when all the selected tag groups complete their transfers
The first function returns immediately, enabling the SPU to check the transfer status without interrupting its data processing. For example, the following code polls the tag group’s status value every time the routine() function finishes. The do-while loop completes when Tag Group 6 (0x0040 = 1<<6) completes its DMA transfers:
do {
routine();
status = mfc_read_tag_status_immediate();
} while(!(status && 0x0040));The next two functions halt the SPU until a desired status condition is met. mfc_read_tag_status_any halts the SPU until one of the selected tag groups finishes, and mfc_read_tag_status_all halts the SPU until all the transfers are completed. In a way, mfc_read_tag_status_all resembles pthread_join, which forces the calling thread to wait until all the Pthreads have finished processing.
The methods previously described are useful when the SPU creates multiple tag groups to transfer data. But if you’re performing simple DMA transfers, you can also check the communication status by reading the number of requests in the MFC’s command queue. This queue holds a maximum of 16 commands, and processing will stall if you attempt to write to a full queue.
The function mfc_stat_cmd_queue returns the number of open slots in the queue. In addition to checking for DMA transfer completion, it’s a good idea to use this function to prevent stalling in communication-intensive applications.
If you create many DMA requests in rapid succession, there’s no guarantee that the data transfers will be processed in order. For this reason, spu_mfcio.h provides variants of mfc_get and mfc_put that order DMA transfers according to their tag group. These variants are listed in Table 12.1.
The first two functions, mfc_getf and mfc_putf, order DMA communication using a fence mechanism. This ensures that all commands preceding the fenced command will be ordered earlier in the MFC command queue. A fence makes no requirement concerning subsequent commands; they may be ordered before or after the fenced command. The only requirement is that the fenced transfer will execute after the transfers preceding it. This is shown in part b of Figure 12.2.
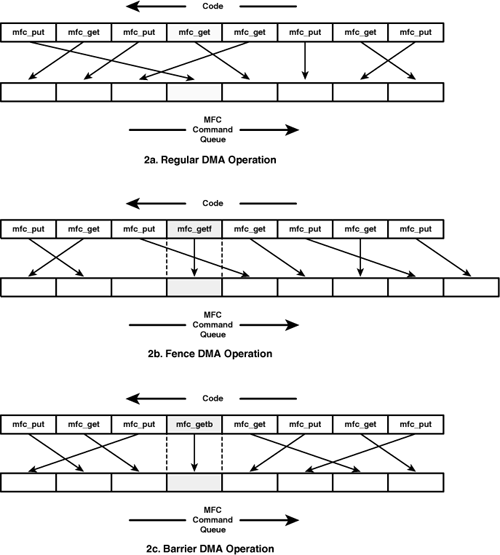
Fences are useful when you need to send information that should be received after a data transfer. For example, if you need to alert a recipient that a series of DMA transfers has finished, you can create a tag group whose final transfer uses the fence option. The fence ensures that the MFC places the alert transfer after the rest of the transfers in the tag group.
The next two functions in Table 12.1, mfc_getb and mfc_putb, use a barrier to order DMA commands. This is like a fence, but goes further. All requests preceding the barrier function must be placed in the MFC’s queue before the barrier function (just like a fence). In addition, all DMA requests following the barrier function must be placed in the queue after the barrier function. This is shown in Figure 12.2c.
Barriers are particularly useful when data needs to be read into the LS and then immediately written out from the same location. In this case, it’s important to make sure that calls to mfc_get and mfc_put are performed in a specific order.
If you want to place a barrier into the queue without using mfc_getb or mfc_putb, mfc_barrier is available. This function accepts a tag parameter, but provides a barrier for all DMA requests in the command queue, regardless of which tag group they belong to.
Many data-intensive applications use SPUs in the following three-step process:
The SPUs read unprocessed data from main memory into their LSs.
The SPUs process the data.
The SPUs write processed data from the LS into main memory.
If these steps are performed in sequence, the SPUs will sit idle while data is carried in and out of the LS. But because DMA transfers are performed asynchronously to the SPU, these steps can also be executed in parallel. This is called multibuffering.
Listing 12.2 presents code for a single-buffered application. It reads 4096 integers (16KB) into a buffer, adds one to each of its values, and transfers the updated values back to main memory. This is performed eight times.
Example 12.2. Single-Buffered DMA: spu_single.c
#include <spu_mfcio.h>
/* Vectors per iteration = 4096/4*/
#define SIZE 1024
#define TAG 3
int main(unsigned long long speid,
unsigned long long argp,
unsigned long long envp) {
int i, j;
vector unsigned int buff[SIZE]
__attribute__ ((aligned(128)));
for(i=0; i<8; i++) {
/* Read unprocessed data from main memory */
mfc_get(buff, argp+i*sizeof(buff),
sizeof(buff), TAG, 0, 0);
mfc_write_tag_mask(1<<TAG);
mfc_read_tag_status_all();
/* Process the data */
for(j=0; j<SIZE; j++)
buff[j] = spu_add(buff[j], 1);
/* Write the processed data to main memory */
mfc_put(buff, argp+i*sizeof(buff),
sizeof(buff), TAG, 0, 0);
mfc_write_tag_mask(1<<TAG);
mfc_read_tag_status_all();
}
return 0;
}This is very straightforward. The application stores data in a single buffer. Its DMA transfers take a single tag value. But we can improve performance by having the SPU process data while the DMA transfers take place.
A double-buffered application creates a buffer twice as large as the incoming data. While the SPU processes data in one half of the buffer, the data in the other half is transferred in or out of the LS. Then the halves switch: the SPU processes data in the second half of the buffer while data in the first half is transferred in or out of the LS.
The code in Listing 12.3 uses double buffering to perform the same task as the code in Listing 12.2. mfc_get is called twice at the start—first to fill the first half of buff, then to fill the second half. The data in the first half is processed (each vector is incremented) and transferred to main memory. As each loop iteration finishes, the buffer halves change roles.
It’s important to see how the loop counter i determines which half of buff is operated on. If i is odd (i&1 = 1), mfc_get transfers data into the buffer’s upper half. If i is even (1-(i&1) = 1), mfc_get fills the lower half. The loop counter also determines the tag value of the DMA transfers.
Example 12.3. Double-Buffered DMA: spu_double.c
#include <spu_mfcio.h>
/* Vectors per iteration = 4096/4 */
#define SIZE 1024
int main(unsigned long long speid,
unsigned long long argp,
unsigned long long envp) {
unsigned short i, j, start, end = 0;
/* The buffer is twice the size of the data */
vector unsigned int buff[SIZE*2]
__attribute__ ((aligned(128)));
unsigned short block_size = sizeof(buff)/2;
/* Fill low half with unprocessed data */
mfc_get(buff, argp, block_size, 0, 0, 0);
for(i=1; i<8; i++) {
/* Fill new buffer with unprocessed data */
mfc_get(buff + (i&1)*SIZE, argp+i*block_size,
block_size, i&1, 0, 0);
/* Wait for old buffer to fill/empty */
mfc_write_tag_mask(1<<(1-(i&1)));
mfc_read_tag_status_all();
/* Process data in old buffer */
start = (i&1) ? 0 : SIZE;
end = start + SIZE;
for(j=start; j<end; j++)
buff[j] = spu_add(buff[j], 1);
/* Write data in old buffer to memory */
mfc_put(buff + (1-(i&1))*SIZE, argp+(i-1)*block_size,
block_size, 1-(i&1), 0, 0);
}
/* Read the last unprocessed data */
mfc_write_tag_mask(2);
mfc_read_tag_status_all();
/* Process the last data */
start = SIZE; end = 2*SIZE;
for(j=start; j<end; j++)
buff[j] = spu_add(buff[j], 1);
/* Write the last processed data to memory */
mfc_put(buff + SIZE, argp+7*block_size,
block_size, 1, 0, 0);
mfc_read_tag_status_all();
return 0;
}After 10 trials with -O3 optimization, the single-buffered ppu_single takes an average of 7,198 ticks on my system. The double-buffered ppu_double takes an average of 5,722 ticks.
Multibuffering can be taken further. If buff is made three times as large as the incoming data, data can be received, processed, and sent in parallel. This is triple buffering. It takes experimentation to determine whether the increase in buffer memory is worth the improved performance.
Multibuffered applications can be difficult to code and even harder to debug. The SDK provides a tool that sets up DMA and multibuffering automatically. It’s called the Accelerated Library Framework (ALF) and is the subject of Appendix C.
Many processor systems make it possible to perform multiple I/O operations with a single routine. This is called vectorized I/O or scatter/gather I/O, and it removes the processing overhead associated with multiple function calls. Figure 12.3 shows how this works.
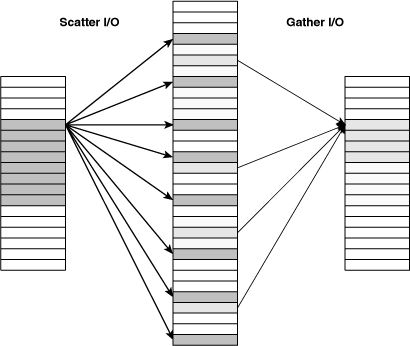
The SPU supports scatter/gather I/O with DMA request lists. A DMA list can hold up to 2,048 DMA transfers, which means a single DMA list could theoretically move a maximum of 2,048 × 16KB = 32MB of data. Of course, this is limited by the size of the SPU’s LS.
Different transfers in a DMA list can access different sections of main memory, but each must transfer data to/from the same location in the LS. Also, each transfer in a list must move data in the same direction, either to or away from the SPU. In other words, you can’t call mfc_get and mfc_put in the same list.
Performing DMA with request lists is a two-step process:
This section discusses both steps and ends with an example of how lists are created and executed in code.
Each DMA transfer in a list must have a corresponding list element. A list element contains three pieces of information: the low 32 bits of the effective address, the number of bytes to be transferred, and whether the MFC should stop processing when it reaches the list element in its queue. These fields form the 64-bit structure shown in Figure 12.4. The size of the DMA transfer can’t exceed 16KB (0x4000), so only 15 bits are needed for the size field.
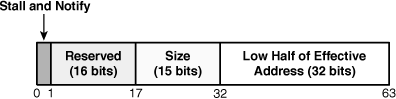
List elements are represented in code by mfc_list_element data structures. The spu_mfcio.h header declares this structure as follows:
typedef struct mfc_list_element {
unsigned int notify : 1;
unsigned int reserved : 16;
unsigned int size : 15;
unsigned int eal : 32;
} mfc_list_element_t;The notify field is usually set to 0, but when the MFC encounters a list element whose notify field is 1, it stops processing the commands in its queue. This allows the SPU to modify unprocessed list elements before continuing. The MFC will continue to stall until the SPU clears the DMA List Command Stall-and-Notify event. Chapter 13, “SPU Communication, Part 2: Events, Signals, and Mailboxes,” discusses event handling in detail.
When creating list elements, make sure the eal address is aligned on a 16-byte boundary. Each list element structure must be aligned on an 8-byte boundary.
Once you’ve created a list element for each of your DMA transfers, you can process the list using one of the six functions in Table 12.2.
Table 12.2. DMA List Functions
Function Name | Operation |
|---|---|
| Processes a list of elements that transfer data into the LS |
| Processes a list of elements that transfer data into the LS using the fence option |
| Processes a list of elements that transfer data into the LS using the barrier option |
| Processes a list of elements that transfer data out of the LS |
| Processes a list of elements that transfer data out of the LS using the fence option |
| Processes a list of elements that transfer data out of the LS using the barrier option |
These functions serve the same roles as the similarly named DMA functions listed earlier. But these six functions all accept a different parameter list than that of the regular mfc_get/mfc_put. Their arguments are as follows:
volatile void *ls: The LS address of the data to be transferredunsigned long long ea: The effective address (EA)volatile mfc_list_element_t *list: Array of list elementsunsigned int tag: Transfer identifier (between 0 and 31)unsigned int tid: Transfer class identifierunsigned int rid: Replacement class identifier
Most of these should look familiar, but there are two points to keep in mind. First, even though the ea value must be 64 bits, only the most significant 32 bits of the effective address are identified in the list command. The least significant 32 bits are provided by the list elements. Second, size refers to the number of bytes in the array of list elements, not the number of elements in the array or the size of an individual DMA transfer.
The code in the dmalist project shows how DMA transfer lists are created and executed. It calls mfc_getlb to transfer four arrays into the LS and mfc_putl to place the four arrays back into main memory. Figure 12.5 shows which arrays are transferred with each instruction.
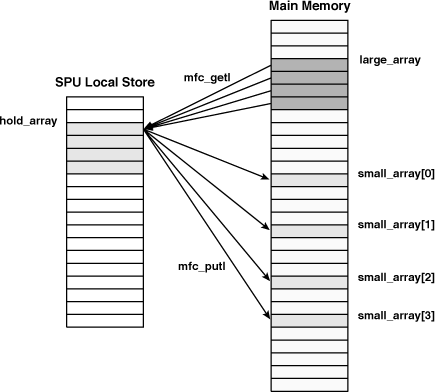
Listing 12.4 presents how DMA lists are implemented in code. The application creates two arrays of DMA list elements: get_element and put_element. Then it performs the transfers using DMA list commands.
Example 12.4. DMA List Processing: spu_dmalist.c
#include <spu_mfcio.h>
#include <spu_intrinsics.h>
#define SIZE 4096 /* Max # of ints in a transfer */
#define TAG 3
/* Array to hold the received values */
unsigned int hold_array[SIZE*4]
__attribute__ ((aligned (128)));
int main(vector unsigned long long arg1,
vector unsigned long long arg2,
vector unsigned long long arg3) {
int i;
unsigned long long get_addr, put_addr[4];
/* Retrieve the five addresses from parameters */
get_addr = spu_extract(arg1, 0);
put_addr[0] = spu_extract(arg1, 1);
put_addr[1] = spu_extract(arg2, 0);
put_addr[2] = spu_extract(arg2, 1);
put_addr[3] = spu_extract(arg3, 0);
/* Create list elements for mfc_getl */
mfc_list_element_t get_element[4];
for (i=0; i<4; i++) {
get_element[i].size = SIZE*sizeof(unsigned int);
get_element[i].eal = mfc_ea2l(get_addr)
+ i*SIZE*sizeof(unsigned int);
}
/* Transfer data into LS */
mfc_getlb(hold_array, get_addr, get_element,
sizeof(get_element), TAG, 0, 0);
mfc_write_tag_mask(1<<TAG);
mfc_read_tag_status_all();
/* Create list elements for mfc_putl */
mfc_list_element_t put_element[4];
for (i=0; i<4; i++) {
put_element[i].size = SIZE*sizeof(unsigned int);
put_element[i].eal = mfc_ea2l(put_addr[i]);
}
/* Transfer data out of LS */
mfc_putl(hold_array, put_addr[0], put_element,
sizeof(put_element), TAG, 0, 0);
mfc_write_tag_mask(1<<TAG);
mfc_read_tag_status_all();
return 0;
}In this application, the SPU accesses input parameters as three vectors (arg1, arg2, and arg3) instead of the usual 64-bit speid, argp, and envp. This makes it possible for the PPU application to initialize the SPU with the addresses of the five input arrays. Parameter transfer is configured in PPU code by calling spe_context_run with the SPE_RUN_USER_REGS flag.
The barrier created by mfc_getlb ensures that none of the transfers in the put_element list overlap the transfers in the get_element list. Even though the transfers are in two separate lists, there’s no guarantee that they will be performed separately.
For each list element, the eal field contains only the least significant half of the effective address. The code in Listing 12.5 uses mfc_ea2l to separate the 32-bit low part from the full 64-bit address. This is one of four utility functions that make it easier to manipulate effective addresses in code. Table 12.3 lists these functions and the roles they serve.
Table 12.3. Effective Address Utility Functions
Function Name | Operation |
|---|---|
| Extract high 32-bit |
| Extract low 32-bit |
| Combines high and low 32-bit |
| Round value to multiple of 128 |
The last function is particularly useful. Unaligned memory addresses in DMA functions can cause strange problems; so if you’re not sure whether an address is aligned, it’s a good idea to use mfc_ceil128.
Thus far, this chapter has discussed only how SPUs transfer data between LS addresses and effective addresses. However, the PPU can also initiate DMA requests, and each SPU can transfer data from its LS into another SPU’s LS. These two processes are related and this section explains how they work.
The PPU can’t issue DMA requests of its own; it has no MFC. But it can access the MFCs of the Cell’s SPEs and command them to perform DMA transfers on its behalf. When the MFC processes the PPU’s command, the transfers will execute as if they had been initiated by an SPU. But PPU-initiated DMA requires additional processing time and bus bandwidth, so it’s recommended that you rely on SPU-initiated DMA whenever possible.
The PPU accesses an SPE’s MFC through the SPE’s registers, which are memory-mapped within the effective address space. These memory-mapped I/O (MMIO) registers allow the PPU to create proxy commands that are similar to SPU commands, but have three important differences:
The PPU creates DMA requests with functions provided by the SPE Runtime Management library (libspe), discussed at length in Chapter 7. Table 12.4 lists each and explains what it accomplishes. These functions are similar to those used for SPU-initiated DMA. At first glance, the only difference is that PPU commands start with the spe_mfcio_ prefix rather than mfc_.
Table 12.4. PPU-Initiated DMA Functions
Function Name | Operation |
|---|---|
| Transfers data into the target SPE’s LS |
| Transfers data into the target SPE’s LS using the fence option |
| Transfers data into the target SPE’s LS using the barrier option |
| Transfers data out of the target SPE’s LS |
| Transfers data out of the target SPE’s LS using the fence option |
| Transfers data out of the target SPE’s LS using the barrier option |
| Reads the status of previously executed DMA transfers |
The first argument in each libspe function is the context of the SPU whose MFC is being accessed. The rest of the arguments are just like the ones used in SPU-initiated DMA functions. For example, if the PPU needs to transfer 16 bytes from the effective address ea_addr to the LS address ls_addr using the MFC associated with context ctx, it makes the following function call:
spe_mfcio_get(ctx, ls_addr, ea_addr, 16, tag, 0, 0);
Except for the first parameter, this looks and operates exactly like mfc_get.
The last function in Table 12.4, spe_mfcio_tag_status_read, reads the status of DMA transfers, but it’s quite different from the SPU function mfc_read_tag_status_all. Its full signature is given by the following:
int spe_mfcio_tag_status_read(spe_context_ptr_t spe, unsigned int mask, unsigned int behavior, unsigned int *tag_status)
The first argument identifies the SPU context and the second tells the MFC which DMA tag group should be monitored. There are no libspe functions like mfc_write_tag_mask, so the mask is identified by an unsigned int. Each bit in the mask parameter represents a tag group, and a value of 0 reads the status of all current DMA requests.
The third argument in this function, behavior, controls when the function returns. It can take one of three values:
SPE_TAG_ALL: The function returns when all the transfers specified in the mask are completed.SPE_TAG_ANY: The function returns when any of the transfers specified in the mask are completed.SPE_TAG_IMMEDIATE: The function returns immediately, whether the transfers have completed or not.
The final parameter in spe_mfcio_tag_status_read is an array of values corresponding to the status of each of the transfers identified by the mask value.
The ppudma project presents a trivially simple example of how PPU-initiated DMA works. The SPU code waits in a loop for the value 42 to be placed in a specific location in the LS. When this value appears, the SPU displays the result and ends the loop. The following code in ppu_ppudma.c performs the DMA:
ls_addr = 0x10000; for(i=0; i<4; i++) check_value[i] = 42; /* Send check_value to the SPU */ spe_mfcio_get(data.speid, ls_addr, check_value, sizeof(check_value), TAG, 0, 0); /* Wait for the data transfer to finish */ spe_mfcio_tag_status_read(data.speid, 1<<TAG, SPE_TAG_ANY, tag_status);
The spe_mfcio_get function tells the MFC to transfer the check_value array from main memory to an arbitrary address (0x10000) in the LS. Then spe_mfcio_tag_status waits until the transfer is finished. The PPU can perform the data transfer before or after spe_context_run is called; but if the transfer is performed afterward, spe_context_run must be called from inside a Pthread.
Transferring data to an arbitrary LS address is ill advised because of the possibility of overwriting critical memory. For this reason, PPU-initiated DMA usually uses additional communication mechanisms, such as mailboxes, to identify target addresses in advance.
The process of sending data directly from one SPU’s LS to another LS is like regular SPU-initiated DMA, but there’s a problem. All the Local Stores have effective addresses, but none of the SPUs know what these addresses are. Therefore, before one SPU can transfer data to another SPU, the PPU must tell it the effective address of the target’s LS.
To determine the effective address of an LS, the PPU must perform two steps:
Create an SPE context using the
SPE_MAP_PSoption (discussed in Chapter 7)Obtain the SPE’s LS address using
spe_ls_area_get
When the PPU sends the effective address of an LS to an SPU, the SPU can use it for DMA transfers as if it was a regular location in main memory.
In the spuspu project, the PPU application creates two SPU contexts, determines the addresses of their respective LSs, and initializes both SPUs with the address of the other’s LS. The SPUs access the effective address contained in the argp parameter to transfer data to one another. Listing 12.5 shows how this works.
Example 12.5. SPU-SPU DMA: spu_spuspu.c
#include <spu_mfcio.h>
#define TAG 3
int main(unsigned long long speid,
unsigned long long argp,
unsigned long long envp) {
/* The memory location to be read */
int *result;
result = (int*)0x10000;
/* The value to be transferred */
int check_value[4] __attribute__ ((aligned (16)));
int i;
for(i=0; i<4; i++)
check_value[i] = 42;
/* Transfer data to other SPE's LS */
mfc_put(check_value, argp+(unsigned long long)result,
sizeof(check_value), TAG, 0, 0);
/* Wait for the transfer to finish */
mfc_write_tag_mask(1<<TAG);
mfc_read_tag_status_all();
/* Check for updated result */
while(*result != 42);
printf("SPE %llu received the message.
", speid);
return 0;
}Again, it’s dangerous to transfer data to an arbitrary address (0x10000) inside an LS. The next chapter explains how to transfer small data payloads (such as LS addresses) using mailboxes.
At this point, you should have a good idea how to transfer data from any processing unit on the Cell to any other processing unit. But what happens when multiple processing units try to access the same memory location at once? To ensure predictable data transfer, the SDK provides two sets of functions: atomic DMA functions in spu_mfcio.h and synchronization functions in the Synchronization library.
In many computational tasks, the PPU partitions data into blocks and tells each SPU which block to process. In this case, you can use regular DMA commands because each SPU accesses a different memory location. But sometimes SPUs need to access shared data, such as a counter containing the number of blocks processed. Regular DMA commands aren’t reliable because they can be interrupted.
For this reason, spu_mfcio.h provides four atomic DMA transfer functions. These jump over the regular DMA command queue (except mfc_putqlluc) and are directly processed by the MFC’s atomic unit. Table 12.5 lists each of them.
Table 12.5. SPE Atomic DMA Functions
Function Name | Descriptive Name | Operation |
|---|---|---|
| Get Lock Line and Reserve | Receive cache line into LS |
| Put Lock Line If Reserved | Transfer data to lock line if reservation exists |
| Put Lock Line Unconditional | Transfer data to lock line regardless of existing reservation |
| Put Queued Lock Line Unconditional | Perform data transfer as part of the DMA queue |
| Read Atomic Command Status | Check status of atomic transfer |
The process of using atomic data transfers begins with mfc_getllar. This function brings a 128-byte line of the L2 cache into the LS. This line is referred to as a lock line. This transfer also updates a cache inside the MFC’s atomic unit. The MFC’s cache can hold up to four different 128-byte cache lines, and the most recent cache line is reserved for atomic operation. The signature for mfc_getllar is given as follows:
mfc_getllar(volatile void *ls, uint64_t ea, uint32_t tid, uint32_t rid)
The parameter list is like that of mfc_get, but leaves out the tag group and size. The tag group is unnecessary because mfc_getllar isn’t processed through the DMA queue like a regular DMA command. The size parameter is unnecessary because every atomic operation transfers 128 bytes.
mfc_putllc checks to make sure that a reservation exists and transfers data into the cache line reserved by mfc_getllar. Then the MFC updates the L2 cache with the new data. Most atomic DMA routines only call mfc_getllar and mfc_putllc. For example, the following three lines of code read in a count variable from the L2 cache into local_count, increment it, and write it back to memory:
mfc_getllar(&local_count, &count, 0, 0); local_count += 1; mfc_putllc(&local_count, &count, 0, 0);
mfc_putlluc transfers data whether a reservation exists or not. This has the same parameter list as mfc_getllar, but if ea doesn’t correspond to the address of the reserved cache line, the reservation will be cleared.
The mfc_putqlluc function differs from the preceding functions because it is inserted into the MFC’s queue like a regular DMA command. Its signature is given by the following:
(void) mfc_putqlluc(volatile void *ls, uint64_t ea, uint32_t tag, uint32_t tid, uint32_t rid)
mfc_putqlluc can be part of a tag group like mfc_put.
The last function in the table, mfc_read_atomic_status, waits for atomic DMA functions to complete in the same way that mfc_read_tag_status_all waits for regular DMA transfers to complete. The function halts the SPU until the status is available, and this status is returned as an unsigned int containing an ORed combination of the following values:
MFC_GETLLAR_STATUS: Equals 1 ifmfc_getllarsucceededMFC_PUTLLC_STATUS: Equals 1 ifmfc_putllcfailed (no reservation)MFC_PUTLLUC_STATUS: Equals 1 ifmfc_putllucsucceeded
For example, to check on the status of mfc_getllar, you would call the following:
status = mfc_read_atomic_status() & MFC_GETLLAR_STATUS;
These functions are helpful, but real-world synchronization routines require more advanced capabilities than basic atomic transfers. For example, Linux synchronization relies on mutexes, semaphores, and condition variables. The SDK’s Synchronization library provides these mechanisms, and its functions are built upon the four atomic DMA functions previously discussed.
The Synchronization library (libsync) contains functions that perform synchronization and atomic operations. These functions are declared in libsync.h and are available for the PPU and SPUs. They can be used as inline functions or callable functions, and if you want to inline func_name within your code, include func_name.h or spu/func_name.h and invoke the function as _func_name.
libsync’s functions can be divided into five categories: atomic operations, mutexes, readers/writers locks, condition variable operations, and completion operations.
Table 12.6 lists the atomic operations provided by the Synchronization library. Each is uninterruptible; once called, each function will complete without interference. Also, each function accepts an atomic_ea_t value as a parameter. This is an unsigned long long that identifies an effective address in main memory.
Table 12.6. Atomic Operations
Function Name | Operation |
|---|---|
| Read and return the |
| Write the value of |
| Add 1 to the value at |
| Add 1 to the value at |
| Add |
| Add |
| Subtract 1 from the value at |
| Subtract 1 from the value at |
| Subtract |
| Subtract |
These functions are simple. If called from SPU code, they transfer data into the LS using mfc_getllar and transfer the modified value back to memory using mfc_putllc. If called from PPU code, these functions use atomic assembly instructions described in the PowerPC Standard.
A common concern in PPU-SPU interaction is this: You want multiple SPUs to access the same shared data, but you want to make sure that only one SPU can access the data at a time. Nothing in libspe can make this possible. Thankfully, libsync provides mutexes. A mutex (mutual exclusion) prevents multiple threads from accessing shared data at once. The operation of a mutex depends on a variable that takes a “locked” value and an “unlocked” value.
To protect data with a mutex, the PPU creates a mutex variable, sets it to an unlocked state, and sends its memory location to the SPUs. Each SPU checks the mutex variable atomically and waits if its value is locked. When the variable reaches an unlocked state, the first SPU to respond locks the variable and accesses the shared data. When it’s finished, the SPU sets the variable to its unlocked value to allow another SPU to access the data.
The terms lock and unlock are used because the process of accessing protected data is like using a one-occupant-only locked room: The entrant waits for the door to be unlocked, enters the room and locks the door, and unlocks the door after leaving. The locking process is commonly called acquiring a lock, and the unlocking process is called releasing the lock.
For example, if you only want one SPU to access a buffer at a time, each SPU should execute code similar to the following:
mutex_lock(); access(buffer); mutex_unlock();
The first SPU to call mutex_lock will find the mutex unlocked. This SPU will acquire the lock and access the buffer. While it accesses the buffer, the other SPUs must wait because the first SPU holds the lock. When it’s finished, the first SPU releases the lock. Another SPU can acquire it and access the buffer.
Table 12.7 lists the libsync functions that provide mutex operation. Each accepts a mutex_ea_t as a parameter. This is an unsigned long long that represents the effective address of the mutex variable.
Table 12.7. Mutex Functions
Operation | |
|---|---|
| Initialize a mutex at |
| Wait until lock is available, and then acquire lock |
| Check whether lock is available, don’t wait |
| Release lock, set mutex to 0 |
The mutex variable is a signed int. mutex_init initializes it to 0, its unlocked value. When a thread calls mutex_lock, it does two things: First, the thread waits until the mutex equals 0. When the mutex value reaches 0, the thread sets the mutex value to 1, the locked value.
This waiting is commonly called spinning because mutex_lock forces the thread to enter an infinite loop. For this reason, the lock is commonly called a spinlock. Spinning is efficient if the thread doesn’t have too long to wait. Otherwise, spinning can waste a large number of cycles.
To check the mutex without spinning, a thread can call mutex_trylock. If the mutex is unlocked, this function acquires the lock and returns a value of 1. If not, it returns 0. If an SPU has to wait a long time to acquire a mutex lock, it’s more efficient to call mutex_trylock as a loop condition than mutex_wait.
The last function in the table, mutex_unlock, atomically sets the mutex value to 0, releasing the lock for other threads to acquire.
Let’s say you want to allow multiple threads to be able to read shared data simultaneously, but not when a writer thread is modifying the data. To maintain data integrity, only one writing process should be able to write at a time, and no thread should be able to interrupt it. A mutex won’t be suitable because it would only allow one reader to access the data at a time.
Instead, you’d want to use the reader locks and writer locks provided by libsync. Multiple readers can access shared data simultaneously using a readers lock, but only one writer can modify data at a time using a writer lock. These locks function like mutexes, and each lock accesses a mutex variable similar to the one described earlier.
Table 12.8 lists the functions used for reader/writer locks, and they are only available to run on the SPU. That is, after the PPU creates a mutex value and initializes it with mutex_init, only the SPUs can access the shared data by calling the functions in Table 12.9.
Table 12.8. Reader/Writer Lock Functions
Function Name | Operation |
|---|---|
| Wait for a writer lock to be unlocked |
| Check whether a writer lock is unlocked, don’t wait |
| Unlock a writer lock |
| Wait for a reader lock to be unlocked |
| Check if a reader lock is unlocked, don’t wait |
| Unlock a reader lock |
Table 12.9. Condition Variable Functions
Function Name | Operation |
|---|---|
| Initialize the value of the condition variable (0) |
| Release the mutex and force the thread to wait until the value is changed |
| Tell a waiting process to continue processing |
| Tell all waiting processes to continue processing |
These functions look and behave like the ones in Table 12.7. The eaddr_t parameter is just like mutex_ea_t and is initialized to 0. But whereas the mutex described earlier is unlocked at a value of 0 and locked at 1, the mutex for a writers lock is locked at −1. When a thread calls write_lock, it checks the mutex, and if its value is −1, the writing thread waits until the value is 0. When the mutex is unlocked, the thread sets its value to −1, locking the mutex and preventing other readers and writers from interrupting.
write_trylock reads the value of the mutex and returns immediately. It returns 1 if it acquires the lock and 0 if it doesn’t. write_unlock sets the mutex value to 0, releasing the lock for other readers and writers.
For readers locks, a mutex is locked at −1 (a writing thread is modifying shared data) and unlocked at 0 or above. When a thread calls read_lock, it waits until the mutex is unlocked, and then increments the mutex and reads the shared data. If another thread calls read_lock and the value is greater than 1, it also increments the mutex and reads the shared data. In this manner, the readers lock allows an unlimited number of readers to read the shared data at once.
read_trylock reads the value of the mutex and returns 1 if it acquires the lock and 0 if it doesn’t. write_unlock decrements the mutex. If the mutex value is still 0 or greater, other readers can access the shared data. If the mutex value reaches 0, both readers and writers can access the data.
A condition variable is like a regular mutex, but serves a different purpose. The goal of a mutex is to have threads wait so that only one can access shared data at a time. The goal of a condition variable is to have all threads wait until a specific condition occurs. This condition can be read and modified by other threads, so condition variables are always protected by mutexes.
A simple example of a condition variable is the color of a traffic light: When the color is red, I come to a halt. When the light turns green, I continue. In the Cell, it’s common for the PPU to create a condition variable and allow its value to control whether SPUs halt or continue.
Table 12.9 lists the libsync functions that enable synchronization with condition variables. Each accepts a cond_ea_t as a parameter.
The first function, cond_init, initializes the condition variable that other threads will wait on. When a thread calls cond_wait, it releases the mutex lock and waits for cond to reach the necessary condition. cond_wait is generally used in an arrangement like this:
mutex_lock(mutex); cond_wait(cond, mutex); mutex_unlock(mutex);
To set the condition that ends cond_wait, the thread that initialized the condition variable needs to call cond_signal or cond_broadcast. The first function changes the value in such a way as to free one of the waiting units from its endless loop. The second function changes the value in a way that frees all the waiting units.
Completion variables are similar to condition variables, but are specifically used to force one thread to wait until another thread finishes. Table 12.10 lists the completion variable functions provided by libsync.
Table 12.10. Completion Variable Functions
Function Name | Operation |
|---|---|
| Initialize the completion variable |
| Force the process to wait until completion |
| Alert a waiting process that processing is complete |
| Alert all waiting processes that processing is complete |
These functions are similar, but not identical to those in Table 12.9. init_completion creates the completion variable and external processes halt by calling wait_for_completion. Unlike cond_wait, wait_for_completion doesn’t require a mutex parameter.
The controlling thread calls complete to inform a single waiting process that completion has occurred. complete_all informs all waiting processes that completion has occurred.
Condition variables can be particularly useful when the SPUs need to halt until the PPU finishes bringing data into the Cell. In this case, the SPUs call wait_for_completion, and continue waiting until the PPU calls complete or complete_all.
To understand how libsync functions operate, it’s helpful to see how they’re used in code. Let’s look at a simple concurrency situation called the Store Problem. These are the constraints:
N customers enter a store in any order.
The cashier speaks to one customer at a time and processes the sale.
As each sale finishes, the customer adds one to the number of customers served.
When the number of customers served reaches N, the cashier stops working.
To coordinate this operation on the Cell, the PPU will be the cashier, and all the available SPUs will be customers. Each of the participants need to access the number of customers served, so this value, num_served, will be protected by a mutex, served_mutex. Also, each customer must wait until the cashier is ready. This means using a condition variable, cashier, and another mutex, cashier_mutex.
The PPU code below creates and initializes the condition variables and mutexes. Then it signals the customers (SPUs) and counts how many have been served:
/* Declare variables */
volatile int cashier_var __attribute__ ((aligned (128)));
volatile int cashier_mutex_var __attribute__ ((aligned (128)));
volatile int served_mutex_var __attribute__ ((aligned (128)));
volatile int num_served __attribute__ ((aligned (128)));
/* Create condition variable, mutexes, pointer */
cb.cashier = (cond_ea_t)&cashier_var;
cb.cashier_mutex = (mutex_ea_t)&cashier_mutex_var;
cb.served_mutex = (mutex_ea_t)&served_mutex_var;
cb.served_addr = (unsigned long long)&num_served;
/* Initialize values */
cond_init(cb.cashier);
mutex_init(cb.cashier_mutex);
cond_init(cb.served_mutex);
num_served = 0;
/* Process the incoming customers */
int count = 0;
while (count < spus) {
cond_signal(cb.cashier);
count = atomic_read((atomic_ea_t)cb.served_addr);
}Listing 12.6 presents the SPU code that receives the control block, waits for the cashier, and increments the number served.
Example 12.6. A Simple Concurrency Example: spu_cashier.c
#include <spu_mfcio.h>
#include <spu_intrinsics.h>
#include <libsync.h>
#define TAG 3
/* SPU initialization data */
typedef struct _control_block {
cond_ea_t cashier;
mutex_ea_t cashier_mutex, served_mutex;
unsigned long long served_addr;
} control_block;
control_block cb __attribute__ ((aligned (128)));
int main(unsigned long long speid,
unsigned long long argp,
unsigned long long envp) {
/* Get the control block from main memory */
mfc_get(&cb, argp, sizeof(cb), TAG, 0, 0);
mfc_write_tag_mask(1<<TAG);
mfc_read_tag_status_all();
/* Enter the store: get lock to wait for cashier */
mutex_lock(cb.cashier_mutex);
/* Wait for cashier */
cond_wait(cb.cashier, cb.cashier_mutex);
/* Allow others to wait for the cashier */
mutex_unlock(cb.cashier_mutex);
/* Leave the store: get lock to increment num_served */
mutex_lock(cb.served_mutex);
/* Increment the number of customers served */
atomic_inc((atomic_ea_t)cb.served_addr);
printf("Thread %llu incremented num_served to %u
",
speid, atomic_read((atomic_ea_t)cb.served_addr));
/* Allow others to access num_served */
mutex_unlock(cb.served_mutex);
return 0;
}atomic_inc is a convenient function. It atomically reads in the value from memory, increments it, and atomically puts the value back to memory. If you wanted to perform a similar operation with mfc_getllar and mfc_putllc, you’d have to use many more lines of code.
Direct Memory Access (DMA) is the primary method for transporting data between the Cell’s processing elements. DMA requests are sent by an SPU or the PPU to a Memory Flow Controller (MFC), which transfers the data through the Element Interconnect Bus (EIB). A DMA get transfers data into an SPU’s LS and a put transfers data out of the LS.
DMA transfers don’t require a great deal of time, but you can improve an application’s performance by transferring data in one section of the LS while processing data in another. Multibuffering reduces the amount of time spent waiting for DMA transfers to complete but increases the amount of memory needed to store the data.
In many applications, communication between processing units needs to be ordered or synchronized. This chapter discussed tag groups and the fences and barriers that control when the MFC processes DMA commands. In addition to groups, DMA transfers initiated by the SPU can be combined into lists, which function similarly to the scatter/gather processes found in many processors.
The last section of this chapter discussed atomic operations and synchronization. Atomic DMA routines can be hard to grasp, but the functions in the Synchronization library make it simple to perform atomic reads, writes, and simple data modification. This library also provides synchronization capabilities similar to those used in Linux: mutexes, condition variables, and completion variables. And should you ever encounter a situation similar to the classic readers/writers problem, libsync provides locks specifically suited for this purpose.
DMA is useful when you need to send large amounts of data. However, it’s unnecessarily time-consuming when you need to transfer only a single memory address or acknowledge receipt of data. For this reason, the Cell provides mailboxes, events, and signals.