
Chapter 19. Debugging and Troubleshooting
In this chapter
Troubleshooting Scripts and Calculations
Troubleshooting in Specific Areas: Performance, Context, Connectivity, and Globals
Using the Database Design Report
What Is Troubleshooting?
This chapter introduces you to some of the broader systematic problems that can occur in a FileMaker system. We explain how to spot these and fix them, and we discuss some useful debugging tools that the FileMaker product line offers you.
In addition to reactive troubleshooting—the art of finding and fixing problems after they happen—we’re also going to spend some time talking about proactive troubleshooting. To us, this means designing systems that are simply less error-prone and designing them in such a way that any errors that do appear are caught and handled in a systematic way. The better you become at this kind of proactive troubleshooting, the less often and less severely your reactive skills are likely to be tested.
Staying Out of Trouble
This section gives you a few of the proactive steps you can take to avoid problems.
Understand Software Requirements
Even if you are the user as well as the developer (and, perhaps, particularly in this case), understand what your solution is supposed to do. Draw the lines clearly as to what is in and out of the scope of the project. These lines might shift (as in a phased project), but at any given moment, make certain that you know what your current objective is.
Understanding the requirements also means understanding the data to be used. Avoid sample data: look at real data if you possibly can. People tend to remember extreme cases and might exaggerate their frequency. Likewise, routine errors that are easily corrected, particularly in a manual system, might be ignored. Grill your user (or yourself) with the limits of data: “Can part of an order be returned?” “Will you ever allow someone to register for two classes at the same time—even if the overlap is only five minutes?”
Avoid Unclear Code
Two things in particular are important: giving descriptive names to the components of your program (databases, tables, fields, layouts, and scripts, to name a few) and using comments liberally throughout your program.
Choosing Good Names
As much as possible, the names you choose should be descriptive and follow clear conventions where possible. We’ll offer some suggestions, but they should be taken as just that: suggestions. Think of them more as examples on which you could base your own naming conventions. The most important thing here is consistency: Try to adopt clear rules for naming things, and do your best to stick to them.
Databases and Tables
Each database file (a collection of tables) should be named for its overall function. If one file contains all the tables for an invoicing module, call the database Invoicing, not Module A. (And, if the tables in a single database file do not seem to have anything in common that you can use as a name, you might rethink the file structure.)
For tables, we recommend that you name the table according to the type of thing that it stores. For intermediate join tables, you should give thought to the function of the table and then decide what thing it represents. So, a join table between Students and Classes could be called StudentClass, but is better called Enrollment or StudentsForClasses. A join table between Magazines and Customers is called Subscriptions or MagazinesForCustomers, and so forth.
Some people like their table names to be in the singular form. So, a table of customers is called Customer, a table of pets is called Pet, and so forth. Others (including many starter solutions) use the plural form.
Some join tables don’t really evoke a natural function, in which case you may need to fall back on a less descriptive name that just incorporates the names of each file: ProjectsForEmployees, for example, or OrdersForPayments. This naming convention easily handles the case in which a variety of relationships is created for tables: ProjectsForEmployees, ProjectsForDepartments, and so forth. If there is a relationship between Employees and Departments, it is quite possible that the Relationships Graph will not allow you to use it to get from Projects to Departments, so you will need the explicit ProjectsForDepartments table. Of course, remember that FileMaker relationships are bidirectional, so ProjectsForDepartments is equally meaningful as DepartmentsForProjects; the name does not imply direction.
Some tables are naturally line item files. The children of other files, which are generally accessed through portals, are characteristic of certain kinds of business documents. Order line items and invoice line items are common examples. You can use a variety of abbreviations as long as you are consistent: OLI (for Order Line Item) or LI for Line Item (as in OrderLI, InvoiceLI, and so forth).
A number of developers feel that it’s helpful to name these tables in some way that indicates their base table, so that if the same base table has multiple occurrences in the Graph, it’s possible to discern this fact easily.
When it comes to field naming conventions, the debates among FileMaker developers often assume the character of holy wars (much like the arguments about bracing style among C programmers). We’re not going to inject ourselves here and make any strong pronouncements—we’ll just offer a few thinking points.
![]() For additional discussion of field naming conventions, see “Field Naming Conventions,” p. 93.
For additional discussion of field naming conventions, see “Field Naming Conventions,” p. 93.
Fields
One of the main issues with fields in FileMaker is that they’re a superset of what we normally think of as database fields. FileMaker fields include, of course, the classic fields, which are those that store static data, generally entered by users. But they also include fields with global storage, which are not data fields at all, but programming variables; calculation fields, which are in fact small functions, or units of programming logic; and summary fields, which are actually aggregating instructions intended for display in reports.
You, as a developer, need to decide what things you need to be able to distinguish quickly in this thicket of fields, and devise a suitable naming scheme. Generally, we like to be able to pick out the following database elements quickly:
- User data
- Globally stored fields (often prefixed by g)
- Calculation fields (often prefixed by c)
- Summary fields (often prefixed by s)
- Developer or internally used fields (often prefixed by z)
- Structural database keys
If you identify keys (not all programmers do), you can prefix them with kf for foreign keys and kp for primary keys. We sometimes go one step further in naming key fields. For primary keys, we precede the field name with a double underscore (__), and then “kp” to signify a primary key. For foreign keys, we precede the field name with a single underscore and the designation “kf”. The effect of this convention is to cause all the key fields to sort to the top of an alphabetized field list in FileMaker, and for the primary key to sort to the very top, above all foreign keys. This makes it very easy to access the keys when building relationships in the Relationships Graph.
Other developers consider keys in FileMaker as less important than they may be in other database environments and do not bother to identify them at all.
Making a broad distinction between user fields and developer fields is harder. Those that try to do this generally adopt some kind of overall field name prefix. It’s not uncommon to see a scheme where all developer fields are prefixed with an additional z. This puts them all together at the end of the field list and uses an uncommon letter that’s unlikely to overlap with the first letter of a user field (well, except ZIP code, which is common, but you can fudge this by calling the ZIP a “postal code” instead). In a z-based scheme, globals might be prefixed with zg and keys with zkp or zkf.
Layouts
With naming layouts, again, we advocate that you have some clear naming scheme to distinguish between layouts your users interact with directly and those that you build for behind-the-scenes use. One general rule is to prefix the names of all “developer” layouts with Dev_ or a similar tag. An equally common rule is to being internal or developer layouts with z, just as with internally-used fields.
If you follow the starter solutions general guidelines, you will find that you have two types of layouts: forms and lists. It is easy to name these layouts Client Form and Client List, for example.
Scripts
The new scripting tools in FileMaker Pro 9 provide major advances in script organization. Grouping scripts together makes sense both for users and developers. Access these features either from File, Manage, Scripts or Scripts, ScriptMaker.
![]() For additional discussion of scripts, see Chapter 9, “Getting Started with Scripting,” p. 283 and Chapter 16, “Advanced Scripting Techniques,” p. 477.
For additional discussion of scripts, see Chapter 9, “Getting Started with Scripting,” p. 283 and Chapter 16, “Advanced Scripting Techniques,” p. 477.
Other Elements
There are, of course, still other areas where improper names can sow confusion, such as the naming of value lists, extended privileges, and custom functions. Function and parameter naming are especially important, so we’ll touch on that area as well.
It pays to take care when naming custom functions, custom function parameters, and also the temporary local variables you create in a Let statement. A few simple choices here can greatly add to the clarity of your code or greatly detract from it.
Suppose that you have a custom function intended to compute a sales commission, with a single parameter, intended to represent a salesperson’s gross sales for the month. To be fully descriptive, you should call this parameter something like grossMonthlySales. That might seem like a lot to type, but if you call it something short and efficient like gms you’ll be scratching your head over it in a few months’ time. The longer name will stay descriptive.
For internal elements (script variables, field names, value lists, and the like) we like to use a style called camel case, popular among Java programmers, in which the first letter of the first word is lowercase and all other words in the name begin with uppercase. We don’t use this convention for names that the user sees; layout and script names, for example.
![]() For additional discussion of custom functions, see “Custom Functions,” p. 461.
For additional discussion of custom functions, see “Custom Functions,” p. 461.
Using Comments Wisely
A comment is a note that you, the programmer, insert into the logic of your program to clarify the intent or meaning of some piece of it. You can use comments many different ways, but we strongly suggest you find ways that work for you, and use them.
FileMaker 9 offers a number of useful commenting facilities. You can add comments onto field definitions and inside the body of calculations as well.
To add a comment to a field, just type your note into the Comment box in the field definition dialog. To view comments, you need to toggle the Comments/Options column of the field list—the list can display comments or options, but not both at once.
Comments can be useful for almost any field. They can be used to clarify the business significance of user data fields or to add clarity to the use of global and summary fields.
Also present in FileMaker 9 is the capability to insert comments into the text of calculations and custom functions. We recommend you make use of this feature as well as spaces and indentation to clarify complex calculations.
Finally, FileMaker enables you to add comments to your scripts. Some developers have elaborate script commenting disciplines. They might create an entire header of comments with space for the names of everyone who’s worked on it, the creation date, and even a full modification history.
Other developers use script comments more sparingly, reserving them for places where the flow of the script is less than self-explanatory, or for guiding the reader through the different cases of a complex logic flow. Short, pointed comments throughout a lengthy script can add a great deal to its clarity.
Commenting increases the longevity and reusability of your code, and we recommend you learn about the different commenting options that FileMaker allows.
Writing Modular Code
Modularity is one of those popular buzzwords for which it seems every programmer has a different interpretation. To us, a modular program is one that avoids unnecessary duplication of effort. Much as the concept of database normalization encourages that each piece of information be stored once and only once in a database, you should try to program in such a way that you avoid (as much as possible) writing multiple routines that do the same or similar things. Try instead to write that routine or piece of logic once and then draw on it in many places. Furthermore, separating interactive code from code that does not interact with users increases the reusability of scripts as well as often simplifying testing.
FileMaker Pro 9 offers several powerful features that can greatly increase the modularity of your code if used with discipline. Three of the most important are custom functions, script parameters, and script results. These topics have been covered thoroughly in their respective chapters, but it’s worthwhile to bring them up here again. You should thoroughly understand the mechanics and uses of custom functions and script parameters, and use them aggressively to make your code more general and extendable. Bear in mind that custom functions can be created only with FileMaker Pro Advanced, not with the regular FileMaker Pro 9 product. However, after they’re created and added to a database, they can be used in FileMaker Pro 9.
![]() For more on custom functions, see “Creating Custom Functions,” p. 464.
For more on custom functions, see “Creating Custom Functions,” p. 464.
![]() For more on script parameters and script results, see “Script Parameters and Script Results,” p. 478.
For more on script parameters and script results, see “Script Parameters and Script Results,” p. 478.
Planning for Trouble
One of the most important ways to avoid software defects (the graceful term for bugs) is to be aware of all the possible failure points in your system, and, most importantly, calculate the consequences of failure. Good programmers do this instinctively. They have a clear sense of what will happen if some element of their program fails. The question is never a surprise to them, and they almost always know the answer.
You can combine the proactive techniques in the previous section—particularly modularity—in creating code that is as fail-safe as possible. If each module (usually a script or subscript in FileMaker), does one logical thing, and if it reports the result of its processing via a script result, you can call the script with certainty that it is doing only one set of related processes. When it returns a result that you recognize as good, you can then move on. If the result is not good, you have only one set of steps to reverse.
For example, if you are performing an operation on a record that will result in the deletion of that record or the creation of one or more additional records, create a script that takes the record’s data as a script parameter, processes it, and then returns a value. At that point, the initial record will still exist, and you can delete it if you want to, but you will never have a case where the record is deleted before the consequent result is good.
Troubleshooting Scripts and Calculations
There are many specific areas of potential trouble in FileMaker, and we’ll get to those in the next sections. Here, though, we want to discuss some general principles for dealing with errors in scripts and calculations.
Handling Errors in Scripts
Many FileMaker actions can result in an error. Error in this context can mean any exceptional condition that has to be reported to the user. This can be something as simple as a search that returns no records or a field that fails to pass validation, or it can be a more esoteric error involving something like a missing key field. In general, in the normal operation of FileMaker, these errors are reported to the user via a dialog of some kind, often with some sort of choice as to how to proceed.
This is fine, up to a point. But you, the developer, might not want the user to see this default FileMaker dialog. You might want to present a different message or none at all. Well, if your user performs her searches by dropping into Find mode, filling in some search criteria, and clicking the Find button, there’s not much you can do. But if your user is performing a find via a script that you’ve written, you can intervene in such situations.
Using the Custom Menus feature of FileMaker Pro 9 Advanced, you can now bridge the gap between applications that rely mostly on the native, menu-driven functionality of FileMaker and those that provide much of their functionality through scripts. Using Custom Menus, you can override selected menu items from the regular FileMaker menu set and attach your own scripted functionality to them. You could, for example, replace the generic Find command in FileMaker’s View menu with a menu item called Find Customers, and tie that menu item to a specific, customized Find script of your own devising.
![]() For more on custom menus, see “Working with Custom Menus,” p. 421.
For more on custom menus, see “Working with Custom Menus,” p. 421.
There’s a very important script step called Set Error Capture. It’s worth your while to become familiar with it. This step allows you to tell FileMaker whether to suppress error messages while your script is running. If this step is not present in a script, or if it’s present and set to off, FileMaker reports errors to the user directly. If your script performs a search and no records are found, your users see the usual FileMaker dialog box for that situation. However, if you have error capture set to on, the user sees no visible response of any kind. After you’ve set the error capture state (on or off), this setting is carried down through all subscripts as well, unless you explicitly disable it by using Set Error Capture [Off] somewhere down in a subscript.
In general, you don’t just turn error capture on and walk away. In fact, error capture obliges you to do a lot more work than you normally might. With error capture on, FileMaker error dialogs are suppressed, so it’s up to you to check for errors and either handle them or inform the user of those that are important.
In addition to checking for specific conditions (such as a found count of zero), it’s also possible to check more generically to determine whether the previous script step produced an error. Typically, you use the Get ( LastError ) function. This function returns whatever error code was produced by the most recent operation. An error code of 0 means “no error.” Otherwise, an error of some kind has occurred. You often check for 0, and if that is not the case, you check for one or more specific errors, and then all others are lumped together. You can use custom dialogs or default behaviors to handle the various errors. (Remember that not all “errors” are actually errors. Although finding no records is a FileMaker error, it might not be an error in the context of your database.)
Get(LastError) can be tricky. It reports on the most recent action taken no matter whether the action was triggered directly by a user or by a script. Let’s say that you have the following script fragment:
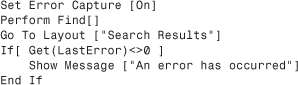
This is not going to do quite what you would hope. If the Perform Find script step found no records, at that point the “last error” would be 401 (the code for “no records found”). But after the Go To Layout step runs, that error code no longer applies. If that step runs successfully (which it might not if, for example, the particular user didn’t have privileges to view that layout), the last error code would now be 0. So, if you want to check for errors, check for them at the exact point of possible failure, not a couple of steps down the road. Alternatively, set one or more local variables to Get ( LastError ) immediately after the call and then test the local variables when it is logical to do so.
Tracking Down Errors
Suppose that, despite your best efforts at defensive programming, some aspect of your system just doesn’t work right. When this happens, of course, you’ll want to track the problem down and fix it. There are a couple of verbs you’ll want to keep in mind: reproduce and isolate.
Reproducing Errors
The first thing to do with any problem is to render it reproducible. Bugs that occur only occasionally are a programmer’s worst nightmare. Often the circumstances are clear and entirely reproducible: “If I hit Cancel in the search script, I end up on some goofy-looking utility layout, instead of back at the main search screen.” At other times, the problem is more slippery: “Sometimes, when I mark an invoice as closed, the system creates a duplicate of that invoice!”
If the bug is not transparently reproducible, you need to gather as much data on the bug as you can. Who experienced it? What type of computer and what operating system? Has it been experienced by one user or several? Does it appear consistently? Look for hidden patterns. Does it occur more at certain times of day? Only from specific computers? Only for a particular account or privilege set? Only during the last week of the fiscal quarter? And so on.
Reproducing the bug should be your first priority because you can’t isolate it until it’s reproducible, and isolating it is your best means of fixing it. You might find that you, yourself, are unable to make the bug happen. This might be a sign that you are using the software differently from your users. Your usage pattern might never cause the bug to happen. One way to leap this hurdle is just to sit down with a user and watch him work. You might find that he’s using a feature of the software differently than you had intended or expected or that he performs functions in a different order. This might give you the clue you need.
Debugging Calculations
As a general rule, we recommend that you debug complex calculations by breaking them down into smaller pieces and testing subunits of the calculation code. This suggestion contains a strong implication for how you should build complex calculations in the first place: Define and test the smaller pieces of functionality first, and then add additional pieces to the calculation. Or, if there’s anything at all reusable in the smaller pieces, don’t just fold them into a larger calculation, but define them as custom functions instead. You can recombine them if you want (the comments section in the Manage Database Design is important here so that you know what is being done).
The key to the idea of isolation is specifically to isolate the broken part. Pull out the pieces that are known to work. As you test each piece, remove it if it tests out correctly. As you do this, the area that contains the problem grows smaller and smaller.
Troubleshooting in Specific Areas: Performance, Context, Connectivity, and Globals
The individual troubleshooting sections in each chapter of this book cover particular isolated “gotchas” that we’ve wanted to highlight. In this section, we want to do two things: We want to talk generally about broad areas of potential FileMaker trouble and how to diagnose them, and we want to talk about a number of specific areas that don’t pop up in the other chapters, or at least don’t get a comprehensive treatment.
Performance
“The system is slow!” Performance is a critical part of the user experience. What can you do if things seem slow? Well, first of course, it’s important to isolate the problem. Is just one area of the system slow, or one particular function? Or does the system generally seem sluggish? In general here, we’re assuming that your solution is a multiuser solution hosted on FileMaker Server, but most remarks (except those entirely specific to Server) apply equally to Server and non-Server configurations.
General Slowness
If you’re not hosting the files on FileMaker Server, but rather have a peer-to-peer configuration, and things seem slow, you should seriously consider moving to Server. If you’re working with FileMaker Server, you also need to make sure that your server settings are configured correctly for your situation. The first thing to look at is what else is happening on the server computer: ideally, the answer is nothing. If someone is editing video on the same computer on which FileMaker Server runs, you will have serious performance problems.
The computer on which FileMaker Server runs might be your file server computer (this is a common source of confusion, so make certain you know what you mean by server). The absolutely most efficient configuration is a dedicated machine for FileMaker Server, but that is certainly not a requirement. If you are publishing databases on the Web, you can offload web publishing to a separate computer to keep the FileMaker Server machine dedicated solely to supporting the database. Even if you are sharing the hardware with other applications, you’ll want to look at FileMaker Server settings such as the percentage of cache hits, the frequency with which the cache is flushed, and the amount of RAM dedicated to the file cache size.
If you’re using Server and all the hardware seems reasonable, it’s time to look at your network. You should know your network’s exact topology. What connections are there, at what speeds? Where are the routers, switches, and hubs? (A fully switched 100MB network or greater is often a relatively inexpensive upgrade that produces a significant benefit.)
Today’s networks and computers are quite fast, but it is easy to wind up with an old router or computer sitting in the middle of the network slowing down everyone. You should also be familiar with your firewall situation. Does FileMaker traffic need to pass through any firewalls or packet filters? This can slow things down as well.
A last point is that FileMaker Server can be set to encrypt traffic between the client and the server. This encryption is somewhat processor-intensive and might impose a performance penalty. If you’re experiencing slowness in a client/server environment, and you’re using client/server encryption, you might want to disable the encryption and see whether that makes a difference. If so, you might consider investing in faster hardware.
Slowness in Searching and Sorting
Searching and sorting are among the operations that, in a Server configuration, are handled chiefly by the server. So, it’s possible the slowness in searching or sorting is symptomatic of some general networking issue of the type discussed in the previous section.
It’s also possible that there’s a problem with the search or sort itself. In terms of performance, the cardinal sin is to execute a search or a sort based on one or more unindexed fields. This, of course, means that there’s no index for the field, which in turn condemns FileMaker to examining each and every record in the database—somewhat akin to trying to find a word in a dictionary where the order of the words is random.
As you might recall, some fields in FileMaker can be unindexed merely because the designer chose to leave them that way, perhaps to save space. For certain fields, this setting can be changed, and FileMaker can be permitted to index the field. Other fields, though, such as globals, or any calculation that references a global or a field in another table, cannot be indexed under any circumstances. If your search or sort includes such a field, the operation will never go quickly, and in fact its performance degrades linearly as the database grows in size.
You should allow an unindexed search only if you’re sure that the set of searchable records is always going to remain fairly small, and there’s no other way to achieve the result you need. In general, programming a search or sort on unindexed fields should be considered a design error and should be avoided.
Note too that “unindexable-ness” has a certain viral character to it, where calculations are concerned. Suppose that you have a calculation A, which references calculation B, which references fields 1, 2, and 3. For reasons of saving space, you decide at some point to eliminate the index on field 3. Immediately, calculations A, B, and C all become unindexed as well, for the simple reason that they now all depend on an unindexed field. Any searches or sorts that use these calculations will now potentially run quite slowly. Be aware of this issue of cascading dependencies when working with indexes.
![]() For additional discussion of indexes, see “Storage and Indexing,” p. 110.
For additional discussion of indexes, see “Storage and Indexing,” p. 110.
Slowness in Executing Calculations
If you have a calculation that seems to execute very slowly, there are a few avenues you can explore. In general, the greater the number of fields and other calculations that your calculation references, the slower it’ll be. It’s possible to build up quite lengthy chains of dependencies or to have dependencies with a nonobvious performance impact. Consider the previous example, with a calculation C that references a calculation B that references a calculation A. Every time A or B changes, C gets re-evaluated as well. So, the calculation contains more work than you might expect. It’s very easy to create elaborate chains of such dependencies, so watch out for them. If you find such chains, see whether there are ways to restructure the chain, perhaps in a way that allows some of the intermediate data to be stored or set by a script.
Likewise beware if your calculations reference any custom functions with recursive behavior. A recursive function is like a little looping script. How long it loops for any case all depends on the inputs. If you’re referencing these in your calculations, be aware of this fact.
![]() For more information on recursion, see “Creating Custom Functions,” p. 464.
For more information on recursion, see “Creating Custom Functions,” p. 464.
Finally, if your calculation references related fields, it will likely be slower than a calculation that looks only at fields in the same table.
Slowness in Performing Lookups
Beginning in FileMaker 7, it’s possible, and indeed advisable, to replace the Lookup option with a different auto-entry option that gives exactly the same results and behavior but is much faster with large recordsets. The preferred method is to use the Calculated Value auto-entry option instead. The calculation should simply make a direct reference to the related field you intend to copy.
![]() For more information on the lookup auto-entry option, see “Working with Field Options,” p. 102.
For more information on the lookup auto-entry option, see “Working with Field Options,” p. 102.
Slowness in Scripts
You can do almost anything in a script, so in some sense a slow script could be caused by anything that could cause slowness elsewhere in FileMaker. But there’s one additional point we want to make here: You can often speed things up by using some of FileMaker’s complex built-in functionality from a script, rather than building things up from simpler script steps.
Use Replace Rather than Loop
Use the Replace Field Contents script step to update a set of records. This step lets you specify a field and a value to put into the field. The value can be a hard-coded value or the result of a calculation, possibly quite a complex one. (The latter technique is called a calculated replace—an essential tool in a FileMaker developer’s toolkit.)
A Replace Field Contents, calculated or otherwise, has almost exactly the same effect as a Loop/Set Field combination and is often much faster. In simple tests that we’ve performed, Replace seems to run about twice as fast as Loop.
Go To Related Records Versus Searching
The Go To Related Records script step is one of FileMaker’s most powerful tools. Using this step, you can navigate from a starting point in one table to a related set of records in some other table, via the relationships defined in the Relationships Graph (technically, you are navigating from one table occurrence to another via the Graph). This navigational hop can be much quicker than running a search in the desired table.
Creating Records
Under certain circumstances, creating records can be a slow process. Specifically, record creation will be slower the more indexes you have on a FileMaker table. Indexes on a table are updated every time a table record changes, and each index on that table might potentially have to be updated. As a general rule, indexes cause searches to run faster but may cause record creation to be slower.
Connectivity and Related Issues
There are many scenarios in which FileMaker’s behavior might be affected by network and connectivity considerations. Unless you are working alone with a FileMaker database that lives on one single computer, and is used on only that computer, you’re likely going to find yourself in a situation where FileMaker data is being distributed over a network. This situation offers a number of potential problems.
Inability to Contact the Server
What happens if you’re running FileMaker Server and your users can’t see your files? There could be any number of reasons for this turn of events, but this list contains a few of the most common reasons.
- Server is down— Verify that the server is running via inspection or a network utility such as
ping. - Server is up, but FileMaker service is not responding— Verify that both the FileMaker Server and FileMaker Server Helper processes are running. Without the Helper process, clients cannot connect to the server.
- The server machine is working and the processes are running correctly, but the files have not been correctly set for network hosting— Make sure that you have granted network access to the files for at least some users.
- The files have been placed on the server but are not opened for sharing on the server— Even if the files are on the server, with appropriate network hosting, it’s still necessary to instruct FileMaker Server to open the files for sharing. If the files are marked Closed, they are not open for hosted sharing.
- Recent files cannot be opened— If the server’s IP address has changed, a recent file might not be in the same place it was before the change. Using the Open Remote command to locate the file will allow you thereafter to use the new Open Recent command that is now established for the file.
- Users might not have appropriate permissions to see the hosted files— In the FileMaker Network Settings dialog, it’s possible to specify that the file will be visible for network sharing only to users with certain privilege sets. Users with insufficient privileges could in theory have no privileges that would allow them to see any of the hosted files.
 Making files available via network access is covered fully; see Chapter 29, “FileMaker Server and Server Advanced,” p. 785.
Making files available via network access is covered fully; see Chapter 29, “FileMaker Server and Server Advanced,” p. 785. - Firewall problems— If there’s a firewall between your server and any of your users, the firewall needs to pass traffic on port 5003. If this port is blocked, users will probably not even be able to see the server, much less access any files on it.
Crosstalk
If a user comes to you and says that all of last week’s sales data has disappeared, there are a number of possible causes for this effect. It’s possible, of course, that last week’s sales data really is gone (in which case you’ll want to price tickets to Nome). But it’s also possible you’ve been bitten by a case of crosstalk.
Crosstalk had the potential to be a serious problem in previous versions of FileMaker. The File Reference feature that debuted in FileMaker 7 has taken a lot of the sting out of the problem, but the potential for trouble remains.
![]() For a full discussion of file references, see “Working with Multiple Files,” p. 233.
For a full discussion of file references, see “Working with Multiple Files,” p. 233.
The trouble stems from the way FileMaker Pro resolves external file references. To access any content from another file, you must first create a file reference to it. You have to do this to add tables from an external file to the Relationships Graph, or to call a script from that file or to use a value list from that file. In FileMaker 9, you create and manage file references explicitly. In versions of the product prior to FileMaker 7, FileMaker managed them for you, behind the scenes, making it easy to lose track of what you were doing. FileMaker also had an automatic search routine, so that if it couldn’t find a file in the first place it looked, it might look elsewhere, and come up with the wrong copy of the file.
FileMaker does not perform this sort of automated search for your files. Instead, it looks to the file references you’ve set up. If it exhausts the search path for a file, it stops looking. However, if you specify a multi-element search path for a file, you could still get into trouble.
Suppose that you’re developing a system that has one file for Customers and another for Orders, each containing a cluster of tables to support its function. You’re developing the files locally, on your own computer, so to bring the Order file into the Relationships Graph in the Customers file, you’d create a local reference in the Customers file.
Now suppose that you deploy the files to FileMaker Server. Now you’d like to add an element to the Orders reference’s search path that points to the copy of the file on the Server. You place it before the local reference, so that FileMaker looks to the server first, as shown in Figure 19.1. This has become a bit dangerous! If FileMaker can’t find that file on the server, FileMaker looks for it on a user’s local hard drive. If FileMaker finds the file, it opens it and uses it. At the very least, you the developer have to be quite careful in this scenario about which version of the file you’re working with.
Figure 19.1. A file reference with multiple search locations defined.
Other users aren’t likely to have a copy of the file locally. But suppose that you had made a reference instead to a shared network drive? That could cause a real headache—the server goes down, the network drive is still in the search path, and clients begin to access and enter data into the non-served copy.
Again, the elegance of file references makes this danger much less severe than in the past, but it still pays to be aware of the issue to avoid any pitfalls.
If you have a system that’s being hosted on a network, and you are still doing development work on another copy of the system, there are several anti-crosstalk precautions you can take. In the first place, make sure to work in single-user mode. One useful practice is to add scripts to every file you create, to toggle between single-user and multiuser mode. In the case of multifile (not multitable) solutions, it’s possible to create a single master script that flips between single-user and multiuser mode for a whole file set. The other precaution is always to archive your old working copies by some form of compression so that they can’t be accidentally opened and hosted on the network.
Context Dependencies
The idea of context covers a lot of ground. Speaking generally, it refers to the fact that many actions that occur in FileMaker don’t happen in a vacuum. The effect of certain script steps, calculations, or references can vary depending on where you are in the system. Where you are means specifically what layout you’re on, what window you’re in, what mode you’re in (Browse, Find, Layout, or Preview), and what record you’re on in the current table. Each of these dependencies has its own pitfalls, and each one is discussed in the sections that follow.
Layout Dependencies
Be aware, when writing scripts, that a number of script steps might not function as you intend, depending on what layout is currently active. Most of these steps require certain fields to be present on the current layout. These include the Go To Field, virtually all the editing functions (Undo, Cut, Copy, Paste, Clear, Set Selection, Select All, Perform Find/Replace), all the Insert steps, Replace Field Contents, Relookup Field Contents, and Check Selection. These are all script steps that act on a field on the current layout. You can run each of them without specifying a field, in which case they run on whatever field is current. They can also be run with a particular field specified. If you specify a field, and for some reason the script is invoked on a layout that doesn’t contain the field, the desired action doesn’t take place. Even if you don’t specify a field, the odds are very strong that you have a specific layout on which you intend that script to be run. In general, these script steps are somewhat fragile and you should use them with care. If you do use them, you should be sure that your logic guarantees that the correct layout will be current when the script step runs.
Table Context
You’re certainly familiar with table context if you’ve read much of the rest of this book. The topic was introduced in Chapter 6, “Working with Multiple Tables,” and it plays an important role in most other chapters as well.
![]() For a full discussion of table context, see “Working with Tables,” p. 90.
For a full discussion of table context, see “Working with Tables,” p. 90.
FileMaker 9 databases can contain multiple tables. For many actions in FileMaker, then, it’s necessary to specify which table is the current one. For new records, to what table does the new record get added? When I check the current found count, for which table am I checking it? And so forth.
Table context introduces a new kind of layout dependency, and one that, in our opinion, dwarfs the old layout dependencies of earlier versions of FileMaker. If you’re not aware of table context and don’t handle it correctly, your FileMaker solutions might appear to be possessed. They will almost certainly not behave as you expect unless your system is extremely simple.
There are quite a number of areas in FileMaker 9 where table context comes into play. A brief recap of each of these is provided here.
As with other kinds of dependencies, it’s important to make sure that the context is correct for an operation before trying to perform that operation. This is a special pitfall for scripts, which can easily change context during script operation via a Go To Layout step. If your script steps are context sensitive, make very sure to establish the proper context first!
Table context is probably one of the trickiest areas of FileMaker: powerful, but full of pitfalls for the unwary.
Layouts
A layout’s table context is determined by the table occurrence to which it’s tied. Table context governs which records the layout displays. Note that the link is to a table occurrence, not to a base table—this is significant if you’ll be working with related fields, or navigating to related record sets (via the Go to Related Record step). In that case, the choice of table occurrence can make a difference in the contents of related fields.
![]() For a discussion of table occurrences and their implications for related fields, see Chapter 6, “Working with Multiple Tables,” p. 195, and Chapter 8, “Getting Started with Calculations,” p. 249.
For a discussion of table occurrences and their implications for related fields, see Chapter 6, “Working with Multiple Tables,” p. 195, and Chapter 8, “Getting Started with Calculations,” p. 249.
Importing Records
When you import records into FileMaker, the target table is determined by the current table context, which is of course determined by the current active layout. Before importing records, manually or via a script, be sure to go to the appropriate layout to set the context correctly.
Exporting Records
Exporting records is also context dependent. Furthermore, if you’re exporting related fields and you’re exporting from a base table with multiple table occurrences, the choice of table occurrence from which to export might also make a difference. As in the case of importing, make sure that you establish context before an export operation.
Calculations
Calculations can also be context dependent, in very specific circumstances. If a calculation lives in a base table that appears multiple times in the Relationships Graph (that is, there are multiple occurrences of that table in the Graph), and the calculation references related fields, the table context matters. The Calculation dialog in FileMaker 9 has a new menu choice at the very top, where you can choose the context from which to evaluate the calculation. If the calculation matches the criteria just mentioned, you should make sure that you get the context right. In other cases, you can ignore it.
Value Lists
Like calculations, value lists can also access and work with related data, via the Also Display Values From Second Field and/or Include Only Related Values options. Here again, if the value list lives in a base table that appears with multiple occurrences, and it works with related data, the table context will be an issue and you should make sure it’s set correctly.
Scripts
Every script executes in a particular table context, which is determined by the table context of the current layout in the active window. (FileMaker 9 can have several windows open within the same file, and they might even display the same layout.) A large number of script steps in FileMaker 9 are context dependent. If you fail to set the context correctly or change it inadvertently during a script by switching layouts or windows, you could end up deleting records in the wrong table (to take an extreme case). Interestingly, FileMaker 9 currently doesn’t offer a Set Context script step. You need to establish your context explicitly by using a Go To Layout step to reach a layout with the appropriate context.
Mode Dependencies
A variety of actions in FileMaker depend on the current mode. In other words, things taking place in scripts (which is where these dependencies occur) don’t happen in a vacuum; they depend on the current state of the application and the user interface. To take an easy example, some script steps don’t work if the application is in Preview mode, including especially the editing steps such as Cut, Copy, and Paste, and others such as Find/Replace and Relookup. If you have a script that’s trying to execute a Relookup step, and some other script has left the application in Preview mode, your Relookup won’t happen.
The Copy command does actually have one meaningful and useful behavior in Preview mode. If no target field is selected, a Copy command executed in Preview mode copies the graphic image of the current page to the Clipboard.
Most of these mode dependencies are really “Browse mode dependencies,” because in general it’s Browse mode that’s required. But a few other mode-based quirks are also important to remember. A few script steps have different meanings in Find mode than in Browse mode. In Find mode, the Omit script step causes the current Find request to become an Omit request, whereas New Record and Delete Record create and delete Find requests, respectively. These three steps work differently in Browse mode, where they respectively omit a record from the current found set, or create or delete a record.
If you’re using such script steps, the answer’s the same here as elsewhere: Explicitly set the context if you’re using script steps that depend on it. In this case, you should use an explicit Enter Browse Mode script step when using steps that depend on this mode.
Finally, there are also mode dependencies that occur outside the context of scripting. A number of FileMaker’s presentation features are dependent on Layout mode. These include the capability to display data in multiple columns, the capability to show the effects of any sliding options you may have set, and the capability to show summary parts and summary fields.
![]() To find full detail on these Preview-dependent layout features, see “Working with Objects on a Layout,” p. 137, and “Summarized Reports,” p. 329.
To find full detail on these Preview-dependent layout features, see “Working with Objects on a Layout,” p. 137, and “Summarized Reports,” p. 329.
The Record Pointer
In addition to all the other elements of context, there’s one other important one. Quite a number of scriptable actions depend on what record you’re currently on. You might remember that this is a function of two things: what layout you’re on (which in turn translates to a table occurrence, which in turn translates to a base table) and which window you’re in. FileMaker 9, you might remember, supports multiple windows open onto the same layout, each with its own found set.
Within each found set, FileMaker keeps track of something called the record pointer—in other words, on which record of the set you actually are. This is indicated both by the record number in the status area, and possibly by the small black bar that appears to the left of each record in list views.
Some script steps are affected by the record pointer, whereas others affect it. Obvious cases of the former are Delete Record and Set Field. The record that gets deleted, and the field that gets set, depend on which record you were on to start with. These kinds of cases are clear and trivial.
Less clear are the steps that affect the record pointer—in other words, that move it. Assume that you have a found set of 7 found records and you navigate to number 5 and delete it. Which record do you end up on? Old number 6 or old number 4? Old number 6 is the answer: Deletion advances the record pointer (except, of course, when you delete the last record of a set). The omission of one or more records from the found set is treated like deletion as far as the record pointer is concerned.
What about adding or duplicating a record? Is the additional record created immediately after the current record? Just before it? At the end or beginning of all records? Well, it depends on whether the current record set is sorted. If the record set is unsorted, new or duplicate records are added at the very end of the found set. (More exactly, the set is then sorted by creation order, so of course the newest records fall at the end.) But if the record set is sorted, things are different. New records are created right after the current record. A duplicate is created at its correct point in the sort order, which could be immediately after the current record, or possibly several records farther along.
The bottom line is that you have to be aware of which script steps move the record pointer. This is a particular pitfall inside looping scripts that perform these kinds of actions, such as a looping script that deletes some records as it goes. If, on a given pass through the loop, you don’t delete a record, you need a Go to Record/Request/Page [Next] to advance the record pointer. But if you delete a record on one pass, the pointer advances automatically, and unless you skip the “go to next record” step this time around, you’ll end up one record ahead of where you want to be.
Globals
Global fields (which in FileMaker 9 are more exactly called “fields with global storage” because “Global” is no longer really a field type) have long been a powerful feature of FileMaker Pro. But there are a few nonobvious facts about globals that can cause problems and confusion.
Unlike data values that are placed in record fields, the values of global fields are specific to each database user (if the databases are being run in a multiuser configuration). That is, if you have an invoicing system with an Invoice Date field, every logged-in user sees exactly the same invoice date for invoice record number 1300. By contrast, if you have a globally stored field called gFlag, it’s possible that every single user could see a different value for that global field. If a global field gets set to a value of 1300 by one user, that value isn’t seen by other users. They each have their own copy of the field, unlike a nonglobal data field.
It’s helpful to remember that when a file containing globally stored fields is first opened, all global fields are set to the last values they had when the files were last open in single-user mode. This means that users in a multiuser environment can’t save the values of global fields. When a user closes a file, all global fields associated with that file’s tables are wiped clean. (In effect, they disappear.) If the same user reopens the file, all the globals will have reverted to the server defaults. This is an important troubleshooting point. If you are relying on global fields to store important session information such as user preferences, be aware that if the user closes the file containing those globals, all those session settings disappear, and reopening the file does not, by itself, bring those stored global values back.
From a troubleshooting perspective, it’s important to remember that globals are volatile and session-specific. Even more important, in a very large number of cases, globals can be replaced by variables—sometimes global variables with a $$ prefix, but even more often by local variables within a single script with a $ prefix.
File Maintenance and Recovery
A corrupted database system is every developer’s nightmare, as well as every user’s. Database systems are complex and very sensitive to the integrity of their data structures. Errors in the way data is written to a database can damage a system, or in the worst case, render it unusable. Periodic maintenance can help you avoid file structure problems. In the worst case, if one of your files does become corrupted, FileMaker has tools to help you recover from this situation as well.
The best way to prevent corrupted database files is to prevent them from suddenly being corrupted with a power loss. All computers that host critical information should be equipped with an uninterruptible power supply (UPS) that provides battery backup and a connection (often USB [universal serial bus]) that allows the UPS to determine when the power is off and to shut down the computer in an orderly manner. The UPS needs only to protect your computer and, possibly, Internet connection and network hardware. Printers can generally fend for themselves.
File Recovery
It might occasionally happen that a FileMaker file becomes so badly damaged it cannot be opened. When this happens it’s usually because the file’s host (either the FileMaker client or the FileMaker Server) suffered a crash. If a file is damaged in this way, it’s necessary to use the File, Recover command available in any copy of FileMaker Pro. This command tries to rebuild the file and repair the damage in such a way that the file can again be opened and its data accessed. The recovery process can take from a few seconds to many minutes or occasionally hours, depending on the size of the file and how many indexes it contains. You will be prompted for a name of the recovered file. When recovery is complete, you normally rename the old file and then rename the newly recovered file to exactly the name of the original file.
In the case of files that FileMaker Server opens and claims need to be recovered, you might be able to work around the recovery process by opening the file in question using FileMaker Pro or FileMaker Pro Advanced. If that works, FileMaker Server might also be okay with the file after that little detour.
FileMaker has always performed a consistency check on files it suspects of having something wrong with them. The consistency checker built in to FileMaker Server 9 is more thorough and aggressive than previous versions, and any file that passes FileMaker Server 9’s consistency check can be considered safe to use.
File Maintenance
As you work with a database file, the file can become slowly more fragmented and less efficient over time. Large deletions can leave “holes” in the file’s data space. Heavy transaction loads can cause indexes to become fragmented. If your databases are large or heavily used, it’s a good idea to perform periodic file maintenance. There are two ways of doing this.
The first is to use the Save a Copy As command with the compacted copy (smaller) type from the File Menu. This will save the file with a new name and will rewrite some of the internal layout and script data in an optimized format. After you do this, you will need to close the original file and rename it; then, rename the copy to the original file’s name.
The other way is to use the File Maintenance feature, which is available only in FileMaker Pro 9 Advanced. File maintenance can be performed only on files that are open locally. It can’t be performed on files that are hosted. To invoke it, choose Tools, File Maintenance. You’ll see a dialog like the one in Figure 19.2, which allows you to choose to compact the file, optimize the file, or both. We recommend you execute both of these steps when performing file maintenance.
Figure 19.2. Periodic file maintenance (a feature of FileMaker Pro 9 Advanced) is a good idea if your files are large or heavily used.
There isn’t a firm rule of thumb for when and how often to perform file maintenance. A general rule might be that if you have a database file of more than 20–30 megabytes in size, or that is changed hundreds of times daily, it might be wise to perform a file maintenance every few months. If your file sizes rise into the hundreds of megabytes, or your activity rises into the thousands of records changed daily, you might want to perform maintenance monthly, or even more frequently.
Using the Database Design Report
Beyond documenting your solution within its structure and code, FileMaker Pro 9 Advanced includes a Database Design Report (DDR) feature that is quite useful and might very well stand as the centerpiece for your system documentation. The report includes an overview of the system, along with detailed information about your database schema, including tables, fields, relationships, layouts, value lists, scripts, accounts, privilege sets, extended privileges, and custom functions. The report can be created as an integrated set of linked HTML documents or as a set of XML files.
Using XSLT, you can transform the XML output of the DDR into a Microsoft Word document that your constituents might find easier to digest and more commonly associated with what they think of as documentation.
Creating a DDR
Creating a Database Design Report is a simple task. But first, you must have FileMaker Pro 9 Advanced and you must open all the files that you want to include in the report. The files must be opened with an account that has full access privileges. After the files have been opened, choose Tools, Database Design Report to display the dialog box shown in Figure 19.3.
Figure 19.3. FileMaker’s Database Design Report can document many aspects of your databases.
By default, all tables in all available files are included in the report. You can uncheck files or tables you do not want to include. You can also specify the types of information to include for each file. Choose either HTML or XML for the report format. Finally, click the Create button and specify the location to which to save the report files.
If you’re not sure whether the HTML or XML version of the DDR is more useful to you, think of it this way: The HTML version produces a set of linked web pages that you can open and navigate immediately in a browser. The XML output is more appropriate if you need the data in a raw form and plan to manipulate it in some way before viewing or presenting it. One type of manipulation might consist of writing one or more XSLT stylesheets to transform the DDR XML data into a form suitable for importing into a FileMaker database.
The HTML version of the DDR includes a Summary.html document along with various additional HTML documents (<filename>_ReportFrame.html, <filename>_TOCFrame.html, and and a Styles.css file. To view the report, open the Summary.html file in any frames-capable web browser.
Each of the solution’s files is listed, along with counts of elements within those files (fields, tables, layouts, accounts, and so forth). Click on a filename or any of the element counts to view details. All the details for a particular file are included on one (possibly lengthy) page. Use the navigation frame at the left side of the window to quickly move to the section you are interested in. You might also use your browser’s Find feature to locate a particular element within the report.
Figure 19.4 shows the navigator frame and the section of the report for scripts. Note that the new script hierarchy is supported in the DDR.
Figure 19.4. FileMaker Pro 9 Advanced can produce a Database Design Report in an HTML format.
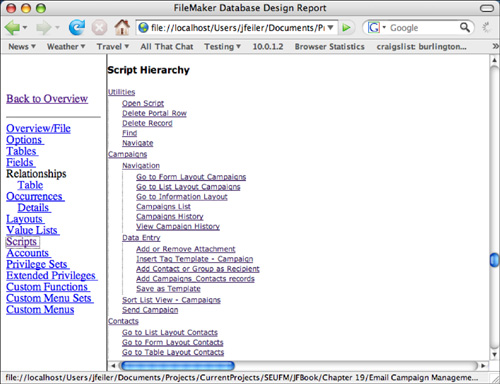
The DDR includes many hyperlinks that make it easy to navigate the report. For instance, the Fields section lists every layout, relationship, script, and value list that uses each field. Each of the listed items is a link that displays the element.
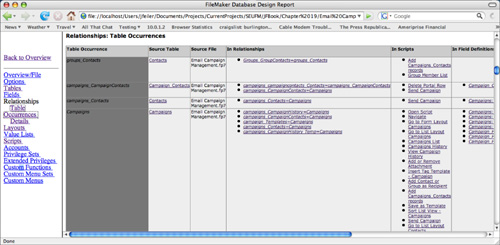
The DDR provides a concise summary of the database from a variety of perspectives. For example, in Figure 19.5, you can see how the Relationships Graph information is shown for each table occurrence. You can see the source file and source table, as well as how that table occurrence is used in relationships, in scripts, in field definitions, in value lists, and in layouts (the last two are scrolled off the right side of the image).
Figure 19.5. You can review table occurrences from the Relationships Graph in the DDR.
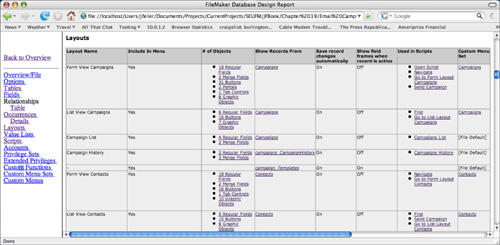
Whereas Figure 19.5 presents the graphical information from the Relationships Graph in a table, Figure 19.6 shows another use of the DDR. For a layout, it gathers data from a variety of places together in a single table so that you can see where the layout is used in scripts, what custom menu sets are associated with it, what it contains, and so forth.
Figure 19.6. The DDR collects information from a variety of places.
Using the Script Debugger
The principle of isolation applies to scripts as well as to calculations. Your problem might lie inside one script, or you might have a complex chain of scripts and subscripts that’s exhibiting failure. By far the best tools available for this are the Script Debugger and the Data Viewer, which are part of FileMaker Pro 9 Advanced. Both have been significantly changed in this release.
The Script Debugger vastly simplifies the process of script debugging, which once upon a time (prior to FileMaker 7) relied chiefly on the insertion of numerous Pause Script and Show Message script steps! But debugging scripts is still not an automatic process. In this section, we’ll walk you through the tools and how to use them.
About the Script Debugger
The Script Debugger and its close companion the Data Viewer are tools that are available only in FileMaker Pro Advanced. This alone is reason enough to invest in Advanced. Trying to troubleshoot a complex script without reasonable debugging tools is a bit like trying to assemble a jigsaw puzzle with your eyes closed. It’s not strictly impossible, but it’s much harder than it needs to be.
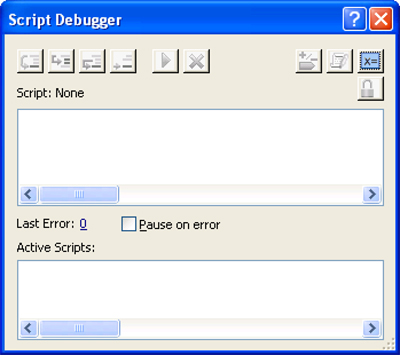
Script debugging can be enabled or disabled from within FileMaker Advanced at any time by choosing Debug Scripts from the Tools menu. This will open the Script Debugger window shown in Figure 19.7.
Figure 19.7. The Script Debugger window.
The next time a script is triggered, whether by clicking a button, opening a file, or some other means, the Script Debugger will be filled what that script’s information as shown in Figure 19.8.
Figure 19.8. The Script Debugger enables you to watch and control the flow of a script.
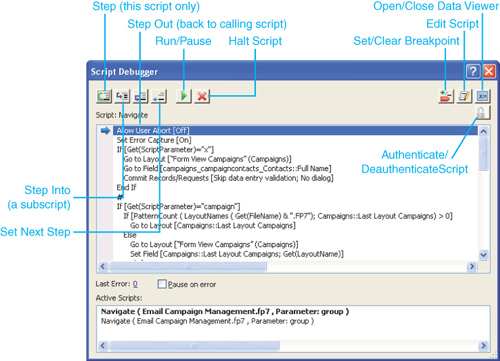
Using the Script Debugger, you can step through a script line by line as it executes. You can see when and whether it follows a certain logical path (which branch gets followed when it encounters an If statement, for example), when and how it breaks out of a loop, and which subscripts it calls, for example. Using the Data Viewer, you can see how record and calculation data change as the script runs (we’ll say more about the Data Viewer later on).
Figure 19.8 shows the tools available in the Script Debugger. Most of them have to do with controlling the flow of the script. In general, you’ll want to step through the script line by line (using the Step command), but you’ll also often want to follow the execution path into subscripts (the Step Into command). Sometimes, when you’re inside a subscript, you might want to finish with the subscript and start debugging step-by-step again back in the parent script (the Step Out command).
Much of the behavior of the Script Debugger is different in FileMaker Pro 9 Advanced. The major changes are integration with the new Edit Script dialog (including multiple windows). The Debugging Controls submenu of the Tools menu has also been redesigned. It reflects the major controls identified in Figure 19.8. Among the important changes is the Pause item in Debugging Controls. When a script is running, the Run command changes to Pause. Selecting that (or clicking the Run/Pause button) immediately stops the script wherever it is. (If the Script Debugger is not open, it will be opened.) Other changes include the display of the last error result and the Pause on Error check box.
Finally, The Authenticate/Deauthenticate Script allows for immediate overriding of the user’s privileges so as to use the Script Debugger. You can also stop the script altogether, open it in ScriptMaker, or use the breakpoint features to allow even more precise control over script execution. We discuss breakpoints in the following section.
Placing Breakpoints
The Script Debugger enables you to place a breakpoint in a script so that execution stops there and you can see what’s happening. In theory, if you have a troublesome script or script chain, you could place a breakpoint at the very start and step through the script. But if this is a lengthy script chain, or one that contains a loop that might run many times, this may not be very time effective.
Consider a case where you have a complex set of scripts that call each other—let’s say that there are three scripts total. Somewhere in the middle of that script, a date field on the current record is getting wiped out, but you don’t know where.
In a case like this, you can use a classic isolation technique called binary search. If you have no idea where the problem is happening, place a breakpoint more or less in the middle of everything, say halfway through script #2. Turn on the Script Debugger, let the script run, and see whether the field has been wiped out by the time you stop at the breakpoint. If the problem has already occurred, move the breakpoint to around the midpoint of the first half of the script chain (that is, 25%) and try again. If it hasn’t happened by the 50% mark, move the breakpoint to 75%. Repeat until you narrow the possible range to one or two lines. This may sound like it’s not much of a time-saver, but using this technique can find the error in a script of more than 1,000 lines using at most ten of these check-and-move operations.
If you have to a debug a looping script, it’s worthwhile to try to reduce the number of records on which the script runs. In general, if you need to debug the loop itself, one internal breakpoint should suffice at first, either at the beginning or end of the loop.
Using the Data Viewer
One of the most important uses of a debugger is to watch certain values and see how they change. These could be database fields, global variables, or aspects of FileMaker state such as the current layout.
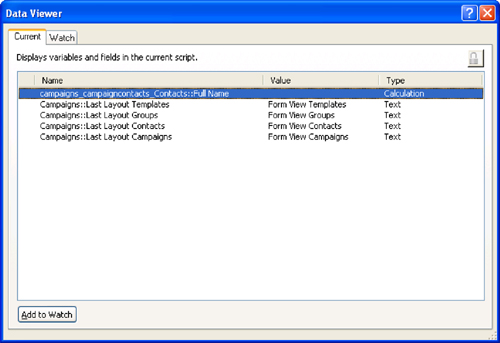
Like the Script Debugger, the Data Viewer has been substantially changed from the previous release. And like the Debug Scripts option, you can find the Data Viewer in the Tools menu of FileMaker Pro Advanced. There are now two tabs in the Data Viewer window. The first tab, Current, shows all the variables and scripts in the current script along with their current values. This view is shown in Figure 19.9. (You will notice a dimmed Authenticate/Deauthenticate script icon—the padlock—on this window. If you do not have the privileges to see the fields or variables, you can immediately get access or remove it.)
Figure 19.9. FileMaker’s Data Viewer, with Current tab selected.
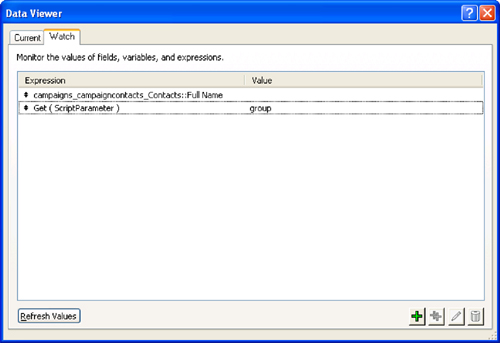
The Watch tab lets you add calculations to be evaluated as the script executes. You can use the Add to Watch button at the lower left of the Current tab to add a field or variable to the Watch list. You can also click the Add Expression button (the plus sign in the lower right of Figure 9.10) to add an expression to evaluate. (This uses the standard Specify Calculation dialog.) The other buttons in the lower right duplicate the selected expression, edit the expression by reopening the Specify Calculation dialog, and remove an expression from the Watch list.
In Figure 19.10, the first item in the Watch list was added by using the Add to Watch button on the Current tab. The second item, which displays the result of the Get ( ScriptParameter ) function was added with the Specify Calculation dialog and the Add Expression button.
Figure 19.10. FileMaker’s Data Viewer, with Watch tab selected.
As an example of a typical use of the Data Viewer, consider the example of a script that mysteriously clears out a field. You’d like to step through the script line by line and find out when that happens. Your first step is to bring up the Data Viewer, and click the Current tab. You can turn on Debug Scripts (if it’s not on already) and run your script. Using the various stepping operations, you can move slowly through the script, watching the fields and seeing how they change. In this case, you can pin down the exact step where the field gets cleared.
The Data Viewer is a critical tool in FileMaker troubleshooting, and we heartily recommend you become familiar with it.