
8.2 Error Resilience
In this section we will be discussing error resilience techniques. As we shall see over the rest of this chapter, it is sometimes difficult to make a clear demarcation as to whether a particular technique is an error resilience technique or rather belongs to one of the other types of techniques to be discussed in later sections. For the purpose of keeping an ordered presentation, we will consider error resilience those that introduce certain structure and techniques within the transmitted 3D video bit stream that reduces or limits the negative effects of channel errors on the recovered video.
One approach to provide larger error resilience to an encoded 3D video bit stream is to modify the compression procedure or the resulting compressed bit stream to aid in the recovery from errors or to provide a level of embedded redundancy in the encoding of information. This approach is contrary to the goals for signal compression, which aims at eliminating as much redundancy as possible from the source. Consequently, it is expected that the changes associated with added error resilience would result in the source encoder having less compression efficiency. This may not necessarily be a bad outcome since the measure of quality for 3D video has to be of an end-to-end nature, meaning with this that it has to include both distortion due to compression and distortion introduced in the communication channel. A good error resilience technique should trade a moderate or small increase in distortion from signal compression for a larger reduction in channel-induced distortion, with the overall result of achieving a lower end-to-end distortion.
An error resilience technique based on modifying the calculation of motion vectors was presented in [4]. The technique presented in this work is based on the observation that motion information from color and depth shows a high correlation. As such, the technique is applicable to the compression of 3D video based on separate motion-compensated differential encoding for the color and depth components. Error resilience is introduced by, instead of generating two correlated sets of motion vectors, generating one combined motion vector set resulting from the motion estimation jointly using the color and depth information. This is implemented by using an algorithm that searches for the best position to estimate motion by minimizing the cost function:
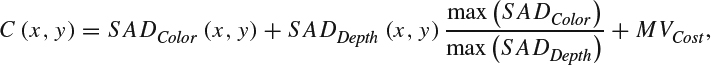
where C(x, y) is the cost associated with the motion vector with coordinates (x, y), SADColor(x, y) is the sum of absolute differences (SAD) of color information when the selected motion vector is the one with coordinates (x, y), SADDepth(x, y) is the SAD of depth information when the selected motion vector is the one with coordinates (x, y), SADColor is the matrix for color information with the SAD value for each coordinate within the search window, SADDepth is the same as SADColor but for depth information, and MVCost is the cost of the selected motion vector, which depends on the number of bits needed to transmit the differentially encoded motion vectors.
As a result of the joint motion estimation, the motion vectors transmitted for the color information and for the depth information are the same. This characteristic is used to improve the error concealment operation as the motion vectors received in the color stream can be used to conceal packet lost in the depth stream and vice versa. Since the motion vectors determined in this joint manner are not as closely matched to the motion vectors that would be obtained from independent motion estimation for the color and depth components, the compression efficiency of the resulting 3D video compressor is less than what would be achieved with a separate motion estimation procedure on the color and depth components. Nevertheless, as shown in [4], the end-to-end quality results, measured as PSNR as a function of packet loss rate, is better than a 3D video compression system with independent motion estimation by close to 1 dB. The only exception to the improvement in end-to-end performance is for sequences with low motion because for these sequences the penalty in compression efficiency due to the joint motion estimation is the largest.
Another technique for error resilience based on using the redundancy in the source encoder is given in [5]. The intrinsic characteristics of 3D video offers new opportunities for the exploitation of the redundancy within the source. Indeed, when considering a group of successive frames from multiple views it is possible to recognize three types of correlation between frames:
- temporal: the correlation between frames of the same view which are close by in time,
- disparity: the correlation between frames of different views occurring at the same time; this is also called inter-view correlation,
- mixed: the correlation between frames of different views occurring close by in time.
These types of correlation are important in 3D video coding because they can be leveraged through prediction for differential encoding or estimation for added error resilience. The names given to the different types of correlation are also used for the prediction and estimation using it. In this way, we can talk for example of a disparity prediction or a temporal estimation.
The 3D video encoder designed in [5] adds error resilience to the compressed bit stream by including for one view frame two descriptions: one that could be seen as the usually present one, obtained from exploiting disparity correlation on I-frames with exploiting temporal correlation on P-frames, and a second one that is obtained from disparity prediction on all frames and that adds error resilience (see Figure 8.8). As can be seen in the figure, the structure of the encoder also recognizes two layers: a base layer, which is the representation of one view from which the representation of the second view is derived, and an enhancement layer which is the representation of the second view. Error resilience is introduced in the enhancement layer only, because its generation depends on the information in the base layer. As a brief side comment, we note that this technique can also be seen as an instance of multiple description coding, a technique that will be discussed later in this chapter.
The redundant disparity-based description that is added to the compressed bit stream provides error resilience by providing an alternative information source that can be used during decoding when certain parts of the compressed video stream are lost during transmission. As such, if a temporally predicted part of a frame from view 1 is lost, most of the lost information can be recovered from the corresponding disparity-predicted data and the use of error concealment techniques (to be discussed in the next section). Also, if both the temporally predicted and its corresponding disparity-predicted part of a frame in view 1 are lost, the potential error propagation that would occur due to the use of differential encoding could be stopped by discarding the correlated temporally predicted information and replacing it with the corresponding disparity-predicted data. Error propagation would be stopped in this case because the disparity-predicted data is not correlated with the lost information from view 1 but, instead, is correlated with the received information from view 0.

Figure 8.8 Frame interdependencies for an error resilient 3D video encoder by adding an extra representation using disparity correlation as in [5].
As is to be expected, when adding redundancy into the source encoder operation, the efficiency in compressing 3D video is reduced with this scheme. In fact, the compression performance results reported in [5] show quality losses, measured as PSNR, between 1 and 2 dB. Nevertheless, as pointed out earlier, the advantages of error resilience become clear when considering the end-to-end distortion and not just distortion due to compression. When evaluating end-to-end PSNR the results in [5] show quality improvement of up to 3 dB with high packet loss rates of 20%. The results also show that when the packet loss rate is relatively low, below around 7%, an equivalent scheme without error resilience has better end-to-end quality. This is obviously because at packet loss rates that are relatively low, the major component in end-to-end distortion is due to the source compression, so there is no advantage to be gained by using error resilience under these operating conditions. In fact, the metric that determines what should be considered as a large or small packet loss rate is the relation between source compression and channel-induced distortion. In the range of operating conditions where source compression distortion accounts for the majority of end-to-end distortion, the packet loss rate, and the channel effects for any general consideration, is considered to be low. When the end-to-end distortion has a major component due to transmission impairments, the packet loss rate, or the channel impairments in general, are large. Finally, recall that when using differential encoding, as is the case with most video encoders, when the channel introduces an error, the error propagates over the correlated encoded information. As illustrated in Figure 8.2, this error may eventually die off at a rate that is given by the prediction filter characteristics. The results in [5] also show how the use of error resilience damps the error propagation from using differential encoding.