
15
Task Interactions and Blocking
CONTENTS
15.1 The Priority Inversion Problem
15.2 The Priority Inheritance Protocol
15.3 The Priority Ceiling Protocol
The basic process model, first introduced in Chapter 11, was used in Chapters 12 through 14 as an underlying set of hypotheses to prove several interesting properties of real-time scheduling algorithms and, most importantly, all the schedulability analysis results we discussed so far. Unfortunately, as it has already been remarked at the end of Chapter 14, some aspects of the basic process model are not fully realistic, and make those results hard to apply to real-world problems.
The hypothesis that tasks are completely independent from each other regarding execution is particularly troublesome because it sharply goes against the basics of all the interprocess communication methods introduced in Chapters 5 and 6. In one form or another, they all require tasks to interact and coordinate, or synchronize, their execution. In other words, tasks will sometimes be forced to block and wait until some other task performs an action in the future.
For example, tasks may either have to wait at a critical region’s boundary to keep a shared data structure consistent, or wait for a message from another task before continuing. In all cases, their execution will clearly no longer be independent from what the other tasks are doing at the moment.
We shall see that adding task interaction to a real-time system raises some unexpected issues involving task priority ordering—another concept of paramount importance in real-time programming—that must be addressed adequately. In this chapter, the discussion will mainly address task interactions due to mutual exclusion, a ubiquitous necessity when dealing with shared data. The next chapter will instead analyze the situation in which a task is forced to wait for other reasons, for instance, an I/O operation.
15.1 The Priority Inversion Problem
In a real-time system, task interaction must be designed with great care, above all when the tasks being synchronized have different priorities. Informally speaking, when a high-priority task is waiting for a lower-priority task to complete some required computation, the task priority scheme is, in some sense, being hampered because the high-priority task would take precedence over the lower-priority one in the model.
This happens even in very simple cases, for example, when several tasks access a shared resource by means of a critical region protected by a mutual exclusion semaphore. Once a lower-priority task enters its critical region, the semaphore mechanism will block any higher-priority task wanting to enter its own critical region protected by the same semaphore and force it to wait until the former exits. This phenomenon is called priority inversion and, if not adequately addressed, can have adverse effects on the schedulability of the system, to the point of making the response time of some tasks completely unpredictable because the priority inversion region may last for an unbounded amount of time. Accordingly, such as a situation is usually called unbounded priority inversion.
It can easily be seen that priority inversion can (and should) be reduced to a minimum by appropriate software design techniques aimed at avoiding, for instance, redundant task interactions when the system can be designed in a different way. At the same time, however, it is also clear that the problem cannot completely solved in this way except in very simple cases. It can then be addressed in two different ways:
Modify the mutual exclusion mechanism by means of an appropriate technique, to be discussed in this chapter. The modification shall guarantee that the blocking time endured by each individual task in the system has a known and finite upper bound. This worst-case blocking time can then be used as an additional ingredient to improve the schedulability analysis methods discussed so far.
Depart radically from what was discussed in Chapter 5 and devise a way for tasks to exchange information through a shared memory in a meaningful way without resorting to mutual exclusion or, more in general, without ever forcing them to wait. This has been the topic of Chapter 10.
Before going further with the discussion, presenting a very simple example of unbounded priority inversion is useful to better understand what the priority inversion problem really means from a practical standpoint. The same example will also be used in the following to gain a better understanding of how the different methods address the priority inversion issue.
Let us consider the execution of three real-time tasks τH (high priority), τM (middle priority), and τL (low priority), executed under the control of a fixed-priority scheduler on a single-processor system. We will also assume, as shown in Figure 15.1, that τH and τL share some information, stored in a certain shared memory area M.
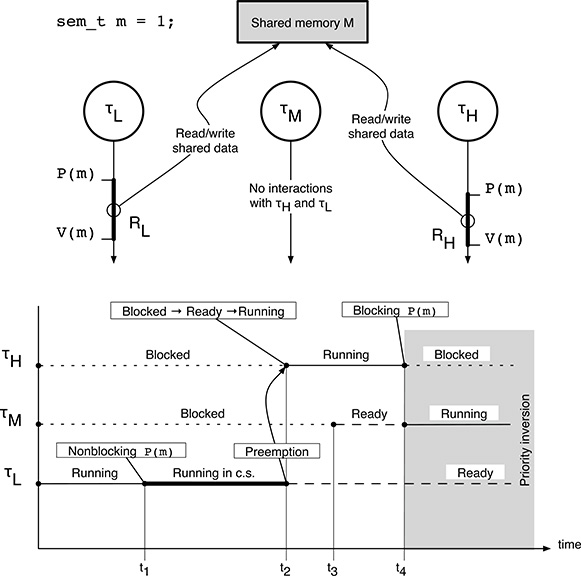
FIGURE 15.1
A simple example of unbounded priority inversion involving three tasks.
Being written by proficient concurrent programmers (who carefully perused Chapter 5) both τH and τL make access to M only within a suitable critical region, protected by a mutual exclusion semaphore m. On the contrary, τM has nothing to do with τH and τL, that is, it does not interact with them in any way. The only relationship among τM and the other two tasks is that “by chance” it was assigned a priority that happens to be between the priority of τH and τL.
In the previous statement, the meaning of the term “by chance” is that the peculiar priority relationship may very well be unknown to the programmers who wrote τH, τM, and τL. For example, we saw that, according to the Rate Monotonic (RM) priority assignment, the priority of a task depends only on its period. When different software modules—likely written by distinct groups of programmers and made of several tasks each—are put together to build the complete application, it may be very hard to predict how the priority of a certain task will be located, with respect to the others.
The following sequence of events may happen:
Initially, neither τH nor τM are ready for execution. They may be, for instance, periodic tasks waiting for their next execution instance or they may be waiting for the completion of an I/O operation.
On the other hand, τL is ready; the fixed-priority scheduler moves it into the Running state and executes it.
During its execution, at t1 in the figure, τL enters into its critical region RL, protected by semaphore
m. The semaphore primitiveP(m)at the critical region’s boundary is nonblocking because no other tasks are accessing the shared memory M at the moment. Therefore, τL is allowed to proceed immediately and keeps running within the critical region.If τH becomes ready while τL still is in the critical region, the fixed-priority scheduler stops executing τL, puts it back into the Ready state, moves τH into the Running state and executes it. This action has been called preemption in Chapter 12 and takes place at t2 in the figure.
At t3,task τM becomes ready for execution and moves into the Ready state, too, but this has no effect on the execution of τH, because the priority of τM is lower than the priority of τH.
As τH proceeds with its execution, it may try to enter its critical region. In the figure, this happens at t4.At thispoint, τH is blocked by the semaphore primitive
P(m)because the value of semaphoremis now zero. This behavior is correct since τL is within its own critical region RL, and the semaphore mechanism is just enforcing mutual exclusion between RL and RH, the critical region τH wants to enter.Since τH is no longer able to run, the scheduler chooses another task to execute. As τM and τL are both Ready but the priority of τM is greater than the priority of τL, the former is brought into the Running state and executed.
Therefore, starting from t4 in Figure 15.1, a priority inversion region begins: τH (the highest priority task in the system) is blocked by τL (a lower priority task) and the system executed τM (yet another lower priority task). In the figure, this region is highlighted by a gray background.
Although the existence of this priority inversion region cannot be questioned because it entirely depends on how the mutual exclusion mechanism for the shared memory area M has been designed to work, an interesting question is for how long it will last.
Contrary to expectations, the answer is that the duration of the priority inversion region does not depend at all on the two tasks directly involved in it, that is, τH and τL. In fact, τH is in the Blocked state and, by definition, it cannot perform any further action until τL exits from RL and executes V(m) to unblock it. On its part, τL is Ready, but it is not being executed because the fixed-priority scheduler does not give it any processor time. Hence, it has no chance of proceeding through RL and eventually execute V(m).
The length of the priority inversion region depends instead on how much time τM keeps running. Unfortunately, as discussed above, τM has nothing to do with τH and τL. The programmers who wrote τH and τL may even be unaware that τM exists. The existence of multiple middle-priority tasks τM1, ..., τMn instead of a single one makes the situation even worse. In a rather extreme case, those tasks could take turns entering the Ready state and being executed so that, even if none of them keeps running for a long time individually, taken as a group there is always at least one task τMk in the Ready state at any given instant. In that scenario, τH will be blocked for an unbounded amount of time by τM1, ..., τMn even if they all have a lower priority than τH itself.
In summary, we are willing to accept that a certain amount of blocking of τH by some lower-priority tasks cannot be removed. By intuition, when τH wants to enter its critical region RH in the example just discussed, it must be prepared to wait up to the maximum time needed by τL to execute within critical region RL. This is a direct consequence of the mutual exclusion mechanism, which is necessary to access the shared resources in a safe way. However, it is also necessary for the blocking time to have a computable and finite upper bound. Otherwise, the overall schedulability of the whole system, and of τH in particular, will be compromised in a rather severe way.
As for many other concurrent programming issues, it must also be remarked that this is not a systematic error. Rather, it is a time-dependent issue that may go undetected when the system is bench tested.
15.2 The Priority Inheritance Protocol
Going back to the example shown in Figure 15.1, it is easy to notice that the root cause of the unbounded priority inversion was the preemption of τL by τH while τL was executing within RL. If the context switch from τL to τH had been somewhat delayed until after the execution of V(m) by τL—that is, until the end of RL—the issue would not have occurred.
On a single-processor system, a very simple (albeit drastic) solution to the unbounded priority inversion problem is to forbid preemption completely during the execution of all critical regions. This may be obtained by disabling the operating system scheduler or, even more drastically, turning interrupts off within critical regions. In other words, with this approach any task that successfully enters a critical region implicitly gains the highest possible priority in the system so that no other task can preempt it. The task goes back to its regular priority when it exits from the critical region.
One clear advantage of this method is its extreme simplicity. It is also easy to convince oneself that it really works. Informally speaking, if we prevent any tasks from unexpectedly losing the processor while they are holding any mutual exclusion semaphores, they will not block any higher-priority tasks for this reason should they try to get the same semaphores. At the same time, however, the technique introduces a new kind of blocking, of a different nature.
That is, any higher-priority task τM that becomes ready while a low-priority task τL is within a critical region will not get executed—and we therefore consider it to be blocked by τL—until τL exits from the critical region. This happens even if τM does not interact with τL at all. The problem has been solved anyway because the amount of blocking endured by τM is indeed bounded. The upper bound is the maximum amount of time τL may actually spend running within its critical region. Nevertheless, we are now blocking some tasks, like τM, which were not blocked before.
For this reason, this way of proceeding is only appropriate for very short critical regions, because it causes much unnecessary blocking. A more sophisticated approach is needed in the general case, although introducing additional kinds of blocking into the system in order to set an upper bound on the blocking time is a trade-off common to all the solutions to the unbounded priority inversion problem that we will present in this chapter. We shall see that the approach just discussed is merely a strongly simplified version of the priority ceiling emulation protocol, to be described in Section 15.3.
In any case, the underlying idea is useful: the unbounded priority inversion problem can be solved by means of a better cooperation between the synchronization mechanism used for mutual exclusion and the processor scheduler. This cooperation can be implemented, for instance, by allowing the mutual exclusion mechanism to temporarily change task priorities. This is exactly the way the priority inheritance algorithm, or protocol, works.
The priority inheritance protocol has been proposed by Sha, Rajkumar, and Lehoczky [79], and offers a straightforward solution to the problem of unbounded priority inversion. The general idea is to dynamically increase the priority of a task as soon as it is blocking some higher-priority tasks. In particular, if a task τL is blocking a set of n higher-priority tasks τH1, ..., τHn at a given instant, it will temporarily inherit the highest priority among them. This prevents any middle-priority task from preempting τL and unduly make the blocking experienced by τH1, ..., τHn any longer than necessary.
In order to define the priority inheritance protocol in a more rigorous way and look at its most important properties, it is necessary to set forth some additional hypotheses and assumptions about the system being considered. In particular,
It is first of all necessary to distinguish between the initial, or baseline, priority given to a task by the scheduling algorithm and its current, or active, priority. The baseline priority is used as the initial, default value of the active priority but, as we just saw, the latter can be higher if the task being considered is blocking some higher-priority tasks.
The tasks are under the control of a fixed-priority scheduler and run within a single-processor system. The scheduler works according to active priorities.
If there are two or more highest-priority tasks ready for execution, the scheduler picks them in First-Come First-Served (FCFS) order.
Semaphore wait queues are ordered by active priority as well. In other words, when a task executes a
V(s)on a semaphoresand there is at least one task waiting ons, the highest-priority waiting task will be put into the Ready state.Semaphore waits due to mutual exclusion are the only source of blocking in the system. Other causes of blocking such as, for example, I/O operations, must be taken into account separately, as discussed in Chapter 16.
The priority inheritance protocol itself consists of the following set of rules:
When a task τH attempts to enter a critical region that is “busy”—that is, its controlling semaphore has already be taken by another task τL—it blocks, but it also transmits its active priority to the task τL that is blocking it if the active priority of τL is lower than τH ’s.
As a consequence, τL will execute the rest of its critical region with a priority at least equal to the priority it just inherited. In general, a task inherits the highest active priority among all tasks it is blocking.
When a task τL exits from a critical region and it is no longer blocking any other task, its active priority returns back to the baseline priority.
Otherwise, if τL is still blocking some tasks—this happens when critical regions are nested into each other—it inherits the highest active priority among them.
Although this is not a formal proof at all, it can be useful to apply the priority inheritance protocol to the example shown in Figure 15.1 to see that it really works, at least in a very simple case. The result is shown in Figure 15.2. The most important events that are different with respect to the previous figure are highlighted with a gray background:
From t1 to t4 the system behaves as before. The priority inheritance protocol has not been called into action yet, because no tasks are blocking any other, and all tasks have got their initial, or baseline, priority.
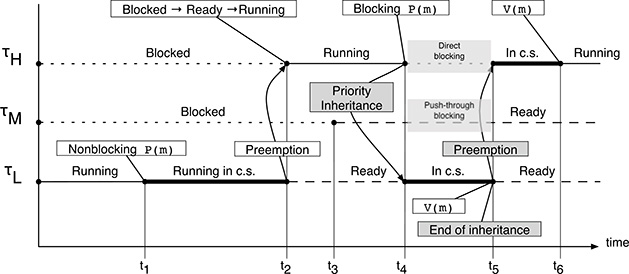
FIGURE 15.2
A simple application of the priority inheritance protocol involving three tasks.At t4, τH is blocked by the semaphore primitive
P(m)because the value of semaphoremis zero. At this point, τH is blocked by τL because τL is within a critical region controlled by the same semaphorem. Therefore, the priority inheritance protocol makes τL inherit the priority of τH.Regardless of the presence of one (or more) middle-priority tasks like τM, at t4 the scheduler resumes the execution of τL because its active priority is now the same as τH ’s priority.
At t5, τL eventually finishes its work within the critical region RL and releases the mutual exclusion semaphore with a
V(m). This has two distinct effects: the first one pertains to task synchronization, and the second one concerns the priority inheritance protocol:Task τH acquires the mutual exclusion semaphore and returns to the Ready state;
Task τL returns to its baseline priority because it is no longer blocking any other task, namely, it is no longer blocking τH.
Consequently, the scheduler immediately preempts the processor from τL and resumes the execution of τH.
Task τH executes within its critical region from t5 until t6. Then it exits from the critical region, releasing the mutual exclusion semaphore with
V(m), and keeps running past t6.
Even from this simple example, it is clear that the introduction of the priority inheritance protocol makes the concept of blocking more complex than it was before. Looking again at Figure 15.2, there are now two distinct kinds of blocking rather than one, both occurring between t4 and t5:
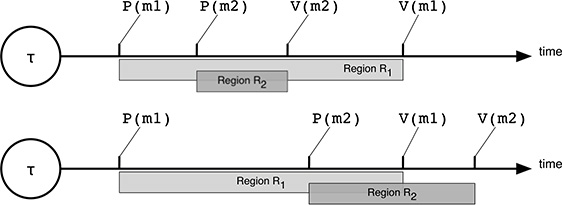
FIGURE 15.3
In a task τ, critical regions can be properly (above) or improperly (below) nested.
Direct blocking occurs when a high-priority task tries to acquire a resource held by a lower-priority task. In this case, τH is blocked by τL. Direct blocking was already present in the system and is necessary for mutual exclusion, to ensure the consistency of the shared resources.
Instead, push-through blocking is a consequence of the priority inheritance protocol. It occurs when an intermediate-priority task (τM in this example) cannot run because a lower-priority task (τL in our case) has temporarily inherited a higher priority. This kind of blocking may affect a task even if it does not use any shared resource, just as it happens to τM in the example. Nevertheless, it is necessary to avoid unbounded priority inversion.
In the following, we will present the main properties of the priority inheritance protocol. The final goal will be to prove that the maximum blocking time that each task may experience is bounded in all cases. The same properties will also be useful to define several algorithms that calculate the worst-case blocking time for each task in order to analyze the schedulability of a periodic task set. As the other schedulability analysis algorithms discussed in Chapters 13 and 14, these algorithms entail a trade-off between the tightness of the bound they compute and their complexity.
For simplicity, in the following discussion the fact that critical regions can be nested into each other will be neglected. Under the assumption that critical regions are properly nested, the set of critical regions belonging to the same task is partially ordered by region inclusion. Proper nesting means that, as shown in Figure 15.3, if two (or more) critical regions R1 and R2 overlap in a given task, then either the boundaries of R2 are entirely contained in R1 or the other way around.
For each task, it is possible to restrict the attention to the set of maximal blocking critical regions, that is, regions that can be a source of blocking for some other task but are not included within any other critical region with the same property. It can be shown that most results discussed in the following are still valid even if only maximal critical regions are taken into account, unless otherwise specified. The interested reader should refer to Reference [79] for more information about this topic.
The first lemma we shall discuss establishes under which conditions a high-priority task τH can be blocked by a lower-priority task.
Under the priority inheritance protocol, a task τH can be blocked by a lower-priority task τL only if τL is executing within a critical region Z that satisfies either one of the following two conditions when τH is released:
The critical region Z is guarded by the same semaphore as a critical region of τH. In this case, τL can block τH directly as soon as τH tries to enter that critical region.
The critical region Z can lead τL to inherit a priority higher than or equal to the priority of τH. In this case, τL can block τH by means of push-through blocking.
Proof. The lemma can be proved by observing that if τL is not within a critical region when τH is released, it will be preempted immediately by τH itself. Moreover, it cannot block τH in the future, because it does not hold any mutual exclusion semaphore that τH may try to acquire, and the priority inheritance protocol will not boost its priority.
On the other hand, if τL is within a critical region when τH is released but neither of the two conditions is true, there is no way for τL to either block τH directly or get a priority high enough to block τH by means of push-through blocking.
When the hypotheses of Lemma 15.1 are satisfied, then task τL can block τH. The same concept can also be expressed in two slightly different, but equivalent, ways:
When the focus of the discussion is on critical regions, it can also be said that that the critical region Z, being executed by τL when τH is released, can block τH. Another, equivalent way of expressing this concept is to say that Z is a blocking critical region for τH.
Since critical regions are always protected by mutual exclusion semaphores in our framework, if critical region Z is protected by semaphore SZ, it can also be said that the semaphore SZ can block τH.
Now that the conditions under which tasks can block each other are clear, another interesting question is how many times a high-priority task τH can be blocked by lower-priority tasks during the execution of one of its instances, and for how long. One possible answer is given by the following lemma:
Under the priority inheritance protocol, a task τH can be blocked by a lower-priority task τL for at most the duration of one critical region that belongs to τL and is a blocking critical region for τH regardless of the number of semaphores τH and τL share.
Proof. According to Lemma 15.1, for τL to block τH, τL must be executing a critical region that is a blocking critical region for τH. Blocking can by either direct or push-through.
When τL eventually exits from that critical region, its active priority will certainly go back to a value less than the priority of τH. From this point on, τH can preempt τL, and it cannot be blocked by τL again. Even if τH will be blocked again on another critical region, the blocking task will inherit the priority of τH itself and thus prevent τL from being executed.
The only exception happens when τH relinquishes the processor for other reasons, thus offering τL a chance to resume execution and acquire another mutual exclusion semaphore. However, this is contrary to the assumption that semaphore waits due to mutual exclusion are the only source of blocking in the system.
In the general case, we consider n lower-priority tasks τL1, ..., τLn instead of just one. The previous lemma can be extended to cover this case and conclude that the worst-case blocking time experienced by τH is bounded even in that scenario.
Under the priority inheritance protocol, a task τH for which there are n lower-priority tasks τL1, ..., τLn can be blocked for at most the duration of one critical region that can block τH for each τLi, regardless of the number of semaphores used by τH.
Proof. Lemma 15.2 states that each lower-priority task τLi can block τH for at most the duration of one of its critical sections. The critical section must be one of those that can block τH according to Lemma 15.1.
In the worst case, the same scenario may happen for all the n lower-priority tasks, and hence, τH can be blocked at most n times, regardless of how many semaphores τH uses.
More important information we get from this lemma is that, provided all tasks only spend a finite amount of time executing within their critical regions in all possible circumstances, then the maximum blocking time is bounded. This additional hypothesis is reasonable because, by intuition, if we allowed a task to enter a critical region and execute within it for an unbounded amount of time without ever leaving, the mutual exclusion framework would no longer work correctly anyway since no other tasks would be allowed to get into any critical region controlled by the same semaphore in the meantime.
It has already been discussed that push-through blocking is an additional form of blocking, introduced by the priority inheritance protocol to keep the worst-case blocking time bounded. The following lemma gives a better characterization of this kind of blocking and identifies which semaphores can be responsible for it.
A semaphore S can induce push-through blocking onto task τH only if it is accessed both by a task that has a priority lower than the priority of τH , and by a task that either has or can inherit a priority higher than the priority of τH.
Proof. The lemma can be proved by showing that, if the conditions set forth by the lemma do not hold, then push-through blocking cannot occur.
If S is not accessed by any task τL with a priority lower than the priority of τH, then, by definition, push-through blocking cannot occur.
Let us then suppose that S is indeed accessed by a task τL, with a priority lower than the priority of τH. If S is not accessed by any task that has or can inherit a priority higher than the priority of τH, then the priority inheritance mechanism will never give to τL an active priority higher than τH. In this case, τH can always preempt τL and, again, push-through blocking cannot take place.
If both conditions hold, push-trough blocking of τH by τL may occur, and the lemma follows.
It is also worth noting that, in the statement of Lemma 15.4, it is crucial to perceive the difference between saying that a task has a certain priority or that it can inherit that priority:
When we say that a task has a certain priority, we are referring to its baseline priority.
On the other hand, a task can inherit a certain priority higher than its baseline priority through the priority inheritance mechanism.
Lemma 15.3 states that the number of times a certain task τH can be blocked is bounded by n, that is, how many tasks have a priority lower than its own but can block it. The following lemma provides a different bound, based on how many semaphores can block τH. As before, the definition of “can block” must be understood according to what is stated in Lemma 15.1.
The two bounds are not equivalent because, in general, there is no oneto-one correspondence between tasks and critical regions, as well as between critical regions and semaphores. For example, τH may pass through more than one critical region but, if they are guarded by the same semaphore, it will be blocked at most once. Similarly, a single task τL may have more than one blocking critical region for τH, but it will nevertheless block τH at most once.
If task τH can endure blocking from m distinct semaphores S1, ..., Sm, then τH can be blocked at most for the duration of m critical regions, once for each of the m semaphores.
Proof. Lemma 15.1 establishes that a certain lower-priority task—let us call it τL—can block τH only if it is currently executing within a critical region that satisfies the hypotheses presented in the lemma itself and is therefore a blocking critical region for τH.
Since each critical region is protected by a mutual exclusion semaphore, τL must necessarily have acquired that mutual exclusion semaphore upon entering the critical region and no other tasks can concurrently be within another critical region associated with the same semaphore. Hence, only one of the lower-priority tasks, τL in our case, can be within a blocking critical region protected by any given semaphore Si.
Due to Lemma 15.2, as soon as τL leaves the blocking critical region, it can be preempted by τH and can no longer block it. Therefore, for each semaphore Si, at the most one critical region can induce a blocking on τH. Repeating the argument for the m semaphores proves the lemma.
At this point, by combining Lemmas 15.3 and 15.5, we obtain the following important theorem, due to Sha, Rajkumar, and Lehoczky [79].
Under the priority inheritance protocol, a task τH can be blocked for at most the worst-case execution time, or duration, of min(n, m) critical regions in the system, where
n is the number of lower-priority tasks that can block τH, and
m is the number of semaphores that can block τH.
It should be stressed that a critical region or a semaphore can block a certain task τH even if the critical region does not belong to τH, or τH does not use the semaphore.
An important phenomenon that concerns the priority inheritance protocol and makes its analysis more difficult is that priority inheritance must be transitive. A transitive priority inheritance occurs when a high-priority task τH is directly blocked by an intermediate-priority task τM, which in turn is directly blocked by a low-priority task τL.
In this case, the priority of τH must be transitively transmitted not only to τM but to τL, too. Otherwise, the presence of any other intermediate-priority task could still give rise to an unbounded priority inversion by preempting τL at the wrong time. The scenario is illustrated in Figure 15.4. There, if there is no transitive priority inheritance, τH’s blocking may be unbounded because τB can preempt τL. Therefore, a critical region of a task can block a higher-priority task via transitive priority inheritance, too.
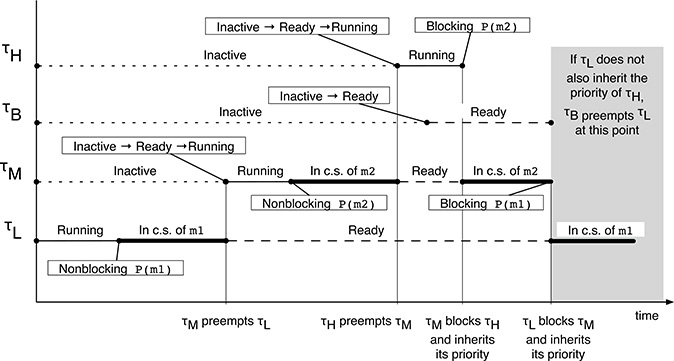
FIGURE 15.4
An example of transitive priority inheritance involving three tasks. If transitive inheritance did not take place, τH’s blocking would be unbounded due to the preemption of τL by τB.
Fortunately, the following lemma makes it clear that transitive priority inheritance can occur only in a single, well-defined circumstance.
Transitive priority inheritance can occur only in presence of nested critical regions.
Proof. In the proof, we will use the same task nomenclature just introduced to define transitive priority inheritance. Since τH is directly blocked by τM, then τM must hold a semaphore, say SM. But, by hypothesis, τM is also directly blocked by a third task τL on a different semaphore held by τL, say SL.
As a consequence, τM must have performed a blocking P() on SL after successfully acquiring SM, that is, within the critical region protected by SM. This corresponds to the definition of properly nested critical regions.
If transitive priority inheritance is ruled out with the help of Lemma 15.6, that is, if nested critical regions are forbidden, a stronger version of Lemma 15.4 holds:
In the absence of nested critical regions, a semaphore S can block a task τH only if it is used both by (at least) one task with a priority less than τH, and (at least) one task with a priority higher than or equal to τH.
Proof. As long as push-through blocking is concerned, the statement of the lemma is the same as Lemma 15.4, minus the “can inherit” clause. The reasoning is valid because Lemma 15.6 rules out transitive priority inheritance if critical regions are not nested. Moreover, transitive inheritance is the only way for a task to acquire a priority higher than the highest-priority task with which it shares a resource.
The conditions set forth by this lemma also cover direct blocking because semaphore S can directly block a task τH only if it is used by another task with a priority less than the priority of τH,and by τH itself. As a consequence, the lemma is valid for all kinds of blocking (both direct and push-through).
If nested critical regions are forbidden, as before, the following theorem provides an easy way to compute an upper bound on the worst-case blocking time that a task τi can possibly experience.
Let K be the total number of semaphores in the system. If critical regions cannot be nested, the worst-case blocking time experienced by each activation of task τi under the priority inheritance protocol is bounded by Bi:
where
usage(k, i) is a function that returns 1 if semaphore Sk is used by (at least) one task with a priority less than the priority of τi and (at least) one task with a priority higher than or equal to the priority of τi. Otherwise, usage(k, i) returns 0.
C(k) is the worst-case execution time among all critical regions corresponding to, or guarded by, semaphore Sk.
Proof. The proof of this theorem descends from the straightforward application of the previous lemmas. The function usage(k, i) captures the conditions under which semaphore Sk can block τi by means of either direct or push-through blocking, set forth by Lemma 15.7.
A single semaphore Sk may guard more than one critical region, and it is generally unknown which specific critical region will actually cause the blocking for task τi. It is even possible that, on different execution instances of τi, the region will change. However, the worst-case blocking time is still bounded by the worst-case execution time among all critical regions guarded by Sk, that is, C(k).
Eventually, the contributions to the worst-case blocking time coming from the K semaphores are added together because, as stated by Lemma 15.5, τi can be blocked at most once for each semaphore.
It should be noted that the algorithm discussed in Theorem 15.2 is not optimal for the priority inheritance protocol, and the bound it computes is not so tight because
It assumes that if a certain semaphore can block a task, it will actually block it.
For each semaphore, the blocking time suffered by τi is assumed to be equal to the execution time of the longest critical region guarded by that semaphore even if that particular critical region is not a blocking critical region for τi.
However, it is an acceptable compromise between the tightness of the bound it calculates and its computational complexity. Better algorithms exist and are able to provide a tighter bound of the worst-case blocking time, but their complexity is much higher.
15.3 The Priority Ceiling Protocol
Even if the priority inheritance protocol just described enforces an upper bound on the number and the duration of blocks a high-priority task τH can encounter, it has several shortcomings:
In the worst case, if τH tries to acquire n mutual exclusion semaphores that have been locked by n lower-priority tasks, it will be blocked for the duration of n critical regions. This is called chained blocking.
The priority inheritance protocol does not prevent deadlock from occurring. Deadlock must be avoided by some other means, for example, by imposing a total order on semaphore accesses, as discussed in Chapter 4.
All of these issues are addressed by the priority ceiling protocols, also proposed by Sha, Rajkumar, and Lehoczky [79]. In this chapter we will discuss the original priority ceiling protocol and its immediate variant; both have the following properties:
A high-priority task can be blocked at most once during its execution by lower-priority tasks.
They prevent transitive blocking even if critical regions are nested.
They prevent deadlock.
Mutual exclusive access to resources is ensured by the protocols themselves.
The basic idea of the priority ceiling protocol is to extend the priority inheritance protocol with an additional rule for granting lock requests to a free semaphore. The overall goal of the protocol is to ensure that, if task τL holds a semaphore and it could lead to the blocking of an higher-priority task τH, then no other semaphores that could also block τH are to be acquired by any task other than τL itself.
A side effect of this approach is that a task can be blocked, and hence delayed, not only by attempting to lock a busy semaphore but also when granting a lock to a free semaphore could lead to multiple blocking on higher-priority tasks.
In other words, as we already did before, we are trading off some useful properties for an additional form of blocking that did not exist before. This new kind of blocking that the priority ceiling protocol introduces in addition to direct and push-through blocking, is called ceiling blocking.
The underlying hypotheses of the original priority ceiling protocol are the same as those of the priority inheritance protocol. In addition, it is assumed that each semaphore has a static ceiling value associated with it. The ceiling of a semaphore can easily be calculated by looking at the application code and is defined as the maximum initial priority of all tasks that use it.
As in the priority inheritance protocol, each task has a current (or active) priority that is greater than or equal to its initial (or baseline) priority, depending on whether it is blocking some higher-priority tasks or not. The priority inheritance rule is exactly the same in both cases.
A task can immediately acquire a semaphore only if its active priority is higher than the ceiling of any currently locked semaphore, excluding any semaphore that the task has already acquired in the past and not released yet. Otherwise, it will be blocked. It should be noted that this last rule can block the access to busy as well as free semaphores.
The first property of the priority ceiling protocol to be discussed puts an upper bound on the priority a task may get when it is preempted within a critical region.
If a task τL is preempted within a critical region ZL by another task τM, and then τM enters a critical region ZM, then, under the priority ceiling protocol, τL cannot inherit a priority higher than or equal to the priority of τM until τM completes.
Proof. The easiest way to prove this lemma is by contradiction. If, contrary to our thesis, τL inherits a priority higher than or equal to the priority of τM, then it must block a task τH. The priority of τH must necessarily be higher than or equal to the priority of τM. If we call PH and PM the priorities of τH and τM, respectively, it must be PH ≥ PM.
On the other hand, since τM was allowed to enter ZM without blocking, its priority must be strictly higher than the maximum ceiling of the semaphores currently locked by any task except τM itself. Even more so, if we call C* the maximum ceiling of the semaphores currently locked by tasks with a priority lower than the priority of τM, thus including τL, it must be PM > C*.
The value of C* cannot undergo any further changes until τM completes because no tasks with a priority lower than its own will be able to run and acquire additional semaphores as long as τM is Ready or Running. The same is true also if τM is preempted by any higher-priority tasks. Moreover, those higher-priority tasks will never transmit their priority to a lower-priority one because, being PM > C*, they do not share any semaphore with it. Last, if τM ever blocks on a semaphore, it will transmit its priority to the blocking task, which will then get a priority at least equal to the priority of τM.
By combining the two previous inequalities by transitivity, we obtain PH > C*. From this, we can conclude that τH cannot be blocked by τL because the priority of τH is higher than the ceiling of all semaphores locked by τL. This is a contradiction and the lemma follows.
Then, we can prove that no transitive blocking can ever occur when the priority ceiling protocol is in use because
The priority ceiling protocol prevents transitive blocking.
Proof. Again, by contradiction, let us suppose that a transitive blocking occurs. By definition, there exist three tasks τH, τM, and τL with decreasing priorities such that τL blocks τM and τM blocks τH.
Then, also by definition, τL must inherit the priority of τH by transitive priority inheritance. However, this contradicts Lemma 15.8. In fact, its hypotheses are fulfilled, and it states that τL cannot inherit a priority higher than or equal to the priority of τM until τM completes.
Another important property of the priority ceiling protocol concerns deadlock prevention and is summarized in the following theorem.
The priority ceiling protocol prevents deadlock.
Proof. We assume that a task cannot deadlock “by itself,” that is, by trying to acquire again a mutual exclusion semaphore it already acquired in the past. In terms of program code, this would imply the execution of two consecutive P() on the same semaphore, with no V() in between.
Then, a deadlock can only be formed by a cycle of n ≥ 2tasks {τ1, ..., τn} waiting for each other according to the circular wait condition discussed in Chapter 4. Each of these tasks must be within one of its critical regions; otherwise, deadlock cannot occur because the hold & wait condition is not satisfied.
By Lemma 15.9, it must be n = 2; otherwise, transitive blocking would occur, and hence, we consider only the cycle {τ1,τ2}. For a circular wait to occur, one of the tasks was preempted by the other while it was within a critical region because they are being executed by one single processor. Without loss of generality, we suppose that τ2 was firstly preempted by τ1 while it was within a critical region. Then, τ1 entered its own critical region.
In that case, by Lemma 15.8, τ2 cannot inherit a priority higher than or equal to the priority of τ1. On the other hand, since τ1 is blocked by τ2, then τ2 must inherit the priority of τ1, but this is a contradiction and the theorem follows.
This theorem is also very useful from the practical standpoint. It means that, under the priority ceiling protocol, programmers can put into their code an arbitrary number of critical regions, possibly (properly) nested into each other. As long as each task does not deadlock with itself, there will be no deadlock at all in the system.
The next goal is, as before, to compute an upper bound on the worst-case blocking time that a task τi can possibly experience. First of all, it is necessary to ascertain how many times a task can be blocked by others.
Under the priority ceiling protocol, a task τH can be blocked for, at most, the duration of one critical region.
Proof. Suppose that τH is blocked by two lower-priority tasks τL and τM, where PL ≤ PH and PM ≤ PH. Both τL and τM must be in a critical region.
Let τL enter its critical region first, and let be the highest-priority ceiling among all semaphores locked by τL at this point. In this scenario, since τM was allowed to enter its critical region, it must be ; otherwise, τM would be blocked.
Moreover, since we assumed that τH can be blocked by τL, it must necessarily be . However, this implies that PM > PH, leading to a contradiction.
The next step is to identify the critical regions of interest for blocking, that is, which critical regions can block a certain task.
Under the priority ceiling protocol, a critical region Z, belonging to task τL and guarded by semaphore S, can block another task τH only if PL < PH , and the priority ceiling of S, is greater than or equal to PH, that is, .
Proof. If it were PL ≥ PH, then τH could not preempt τL, and hence, could not be blocked by S. Hence, it must be PL < PH for τH to be blocked by S.
Let us assume that , that is, the second part of the hypothesis, is not satisfied, but τH is indeed blocked by S. Then, its priority must be less than or equal to the maximum ceiling C* among all semaphores acquired by tasks other than itself, that is, PH ≤ C*. But it is , and hence, and another semaphore, not S, must be the source of the blocking in this case.
It is then possible to conclude that τH can be blocked by τL, by means of semaphore S, only if PL < PH and .
By combining the previous two results, the following theorem provides an upper bound on the worst-case blocking time.
Let K be the total number of semaphores in the system. The worst-case blocking time experienced by each activation of task τi under the priority ceiling protocol is bounded by Bi:
where
usage(k, i) is a function that returns 1 if semaphore Sk is used by (at least) one task with a priority less than τi and (at least) one task with a priority higher than or equal to τi. Otherwise, it returns 0.
C(k) is the worst-case execution time among all critical regions guarded by semaphore Sk.
Proof. The proof of this theorem descends from the straightforward application of
Theorem 15.4, which limits the blocking time to the duration of one critical region, the longest critical region among those that can block τi.
Lemma 15.10, which identifies which critical regions must be considered for the analysis. In particular, the definition of usage(k, i) is just a slightly different way to state the necessary conditions set forth by the lemma to determine whether a certain semaphore SK can or cannot block τi.
The complete formula is then built with the same method already discussed in the proof of Theorem 15.2.
The only difference between the formulas given in Theorem 15.2 (for priority inheritance) and Theorem 15.5 (for priority ceiling), namely, the presence of a summation instead of a maximum can be easily understood by comparing Lemma 15.5 and Theorem 15.4.
Lemma 15.5 states that, for priority inheritance, a task τH can be blocked at most once for each semaphore that satisfies the blocking conditions of Lemma 15.7, and hence, the presence of the summation for priority inheritance. On the other hand, Theorem 15.4 states that, when using priority ceiling, τH can be blocked at most once, period, regardless of how many semaphores can potentially block it. In this case, to be conservative, we take the maximum among the worst-case execution times of all critical regions controlled by all semaphores that can potentially block τH.
An interesting variant of the priority ceiling protocol, called immediate priority ceiling or priority ceiling emulation protocol, takes a more straightforward approach. It raises the priority of a task to the priority ceiling associated with a resource as soon as the task acquires it, rather than only when the task is blocking a higher-priority task. Hence, it is defined as follows:
Each task has an initial, or baseline, priority assigned.
Each semaphore has a static ceiling defined, that is, the maximum priority of all tasks that may use it.
At each instant a task has a dynamic, active priority, that is, the maximum of its static, initial priority and the ceiling values of any semaphore it has acquired.
It can be proved that, as a consequence of the last rule, a task will only suffer a block at the very beginning of its execution. The worst-case behavior of the immediate priority ceiling protocol is the same as the original protocol, but
The immediate priority ceiling is easier to implement, as blocking relationships must not be monitored. Also, for this reason, it has been specified in the POSIX standard [48], along with priority inheritance, for mutual exclusion semaphores.
It leads to less context switches as blocking is prior to the first execution.
On average, it requires more priority movements, as this happens with all semaphore operations rather than only if a task is actually blocking another.
A different method of addressing the unbounded priority inversion issue, known as adaptive priority ceiling, is used by RTAI, one of the Linux real-time extensions. It has a strong similarity with the algorithms just discussed but entails a different trade-off between the effectiveness of the method and how much complex its implementation is. More details about it can be found in Chapter 18.
15.4 Schedulability Analysis and Examples
In the previous section, an upper bound for the worst-case blocking time Bi that a task τi can suffer has been obtained. The bound depends on the way the priority inversion problem has been addressed. The worst-case response time Ri, already introduced in Chapter 14, can be redefined to take Bi into account as follows:
In this way, the worst-case response time Ri of task τi is expressed as the sum of three components:
the worst-case execution time Ci,
the worst-case interference Ii, and
the worst-case blocking time Bi.
The corresponding recurrence relationship introduced for Response Time Analysis (RTA) becomes
It can be proved that the new recurrence relationship still has the same properties as the original one. In particular, if it converges, it still provides the worst-case response time Ri for an appropriate choice of . As before, either 0 or Ci are good starting points.
The main difference is that the new formulation is pessimistic, instead of necessary and sufficient, because the bound Bi on the worst-case blocking time is not tight, and hence, it may be impossible for a task to ever actually incur in a blocking time equal to Bi.
Let us now consider an example. We will consider a simple set of tasks and determine the effect of the priority inheritance and the immediate priority ceiling protocols on their worst-case response time, assuming that their periods are large (> 100 time units). In particular, the system includes
A high-priority task τH, released at t = 4 time units, with a computation time of CH = 3 time units. It spends the last 2 time units within a critical region guarded by a semaphore, S.
An intermediate-priority task τM, released at t = 2 time units, with a computation time of 4 time units. It does not have any critical region.
A low-priority task τL, released at t = 0 time units, with a computation time of 4 time units. It shares some data with τH, hence it spends its middle 2 time units within a critical region guarded by S.
The upper part of Figure 15.5 sketches the internal structure of the three tasks. Each task is represented as a rectangle with the left side aligned with its release time. The rectangle represents the execution of the task if it were alone in the system; the gray area inside the rectangle indicates the location of the critical region the task contains, if any.
The lower part of the figure shows how the system of tasks being considered is scheduled when nothing is done against unbounded priority inversion. When τH is blocked by its P(s) at t = 5 time units, task τM is resumed because it is the highest-priority task ready for execution. Hence, τL is resumed only after τM completes its execution, at t = 7 time units.
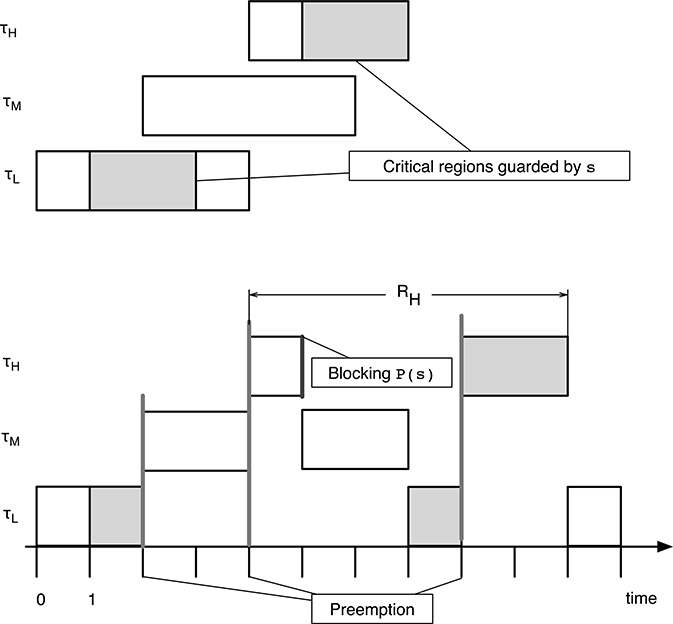
FIGURE 15.5
An example of task scheduling with unbounded priority inversion.
Thereafter, τL leaves its critical region at t = 8 and is immediately preempted by τH, which is now no longer blocked by τL and is ready to execute again. τH completes its execution at t = 10 time units. Last, τL is resumed and completes at t = 11 time units.
Overall, the task response times in this case are: RH = 10 − 4 = 6, RM = 7 − 2 = 5, RL = 11 − 0 = 11 time units. Looking at Figure 15.5, it is easy to notice that RH, the response time of τH, includes part of the execution time of τM ; even if τM ’s priority is lower, there is no interaction at all between τH and τM, and executing τM instead of τH is not of help to any other higher-priority tasks.
The behavior of the system with the priority inheritance protocol is shown in Figure 15.6. It is the same as before until t = 5 time units, when τH is blocked by the execution of P(s). In this case, τH is still blocked as before, but it also transmits its priority to τL. In other words τL, the blocking task, inherits the priority of τH, the blocked one.
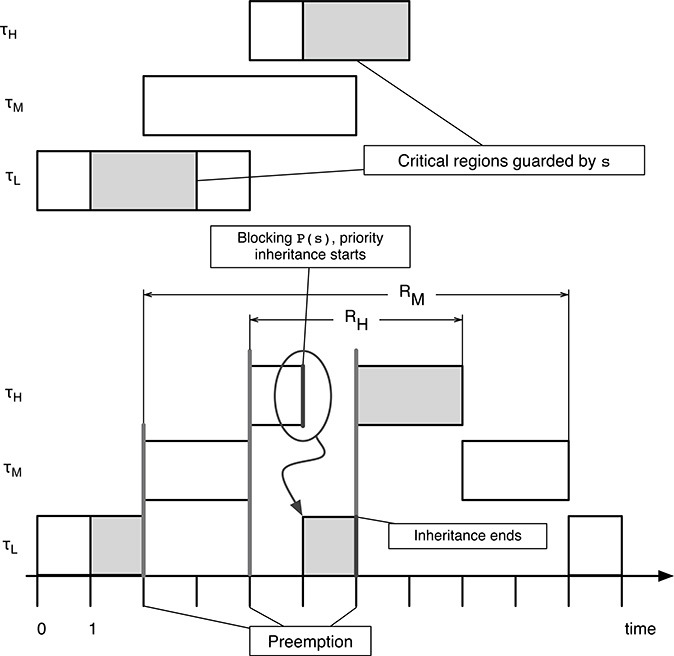
FIGURE 15.6
An example of task scheduling with priority inheritance.
Hence, τL is executed (instead of τM ) and leaves its critical region at t = 6 time units. At that moment, the priority inheritance ends and τL returns to its original priority. Due to this, it is immediately preempted by τH. At t = 8 time units, τH completes and τM is resumed. Finally, τM and τL complete their execution at t = 10 and t = 11 time units, respectively.
With the priority inheritance protocol, the task response times are RH = 8 − 4 = 4, RM = 10 − 2 = 8, RL = 11 − 0 = 11 time units. From Figure 15.6, it can be seen that RH no longer comprises any part of τM. It does include, instead, part of the critical region of τL, but this is unavoidable as long as τH and τL share some data with a mutual exclusion mechanism. In addition, the worst-case contribution it makes to RH is bounded by the maximum time τL spends within its critical region.
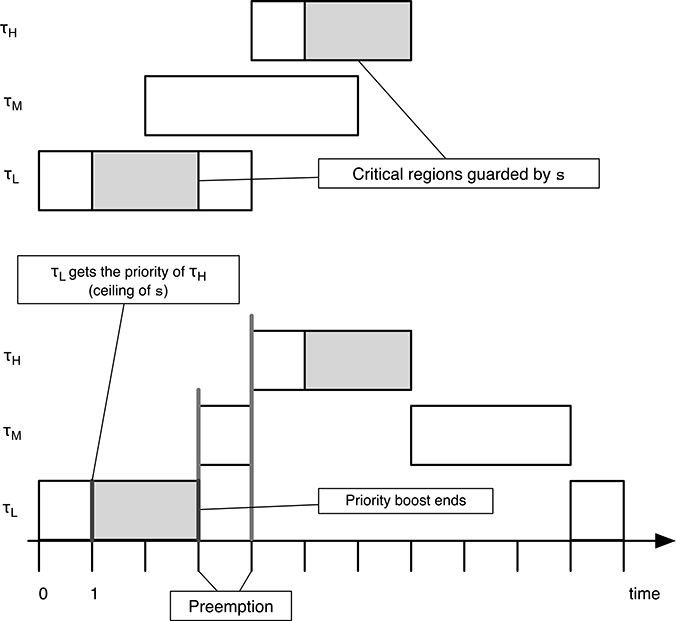
FIGURE 15.7
An example of task scheduling with immediate priority ceiling.
It can also be noted that RM, the response time of τM, now includes part of the critical region of τL, too. This is a very simple case of push-through blocking and is a side effect of the priority inheritance protocol. In any case, the contribution to RM is still bounded by the maximum time τL spends within its critical region.
As shown in Figure 15.7, with the immediate priority ceiling protocol, τL acquires a priority equal to the priority of τH, the ceiling of s, as soon as it enters the critical region guarded by s itself at t = 1 time unit.
As a consequence, even if τM is released at t = 2, it does not preempt τL up to t = 3 when τL leaves the critical region and returns to its original priority. Another preemption, of τM in favor of τH, occurs at t = 4 time units, as soon as τH is released.
Then, τM is resumed, after the completion of τH, at t = 7 time units, and completes at t = 10 time units. Finally, τL completes at t = 11 time units. With the immediate priority ceiling protocol, the task response times are RH = 7 − 4 = 3, RM = 10 − 2 = 8, RL = 11 − 0 = 11 time units.
TABLE 15.1
Task response times for Figures 15.5–15.7
| Actual Response Time | Worst Case Response Time | |||
| Task | Nothing | P. Inheritance | Imm. P. Ceiling | |
| τH | 6 | 4 | 3 | 5 |
| τM | 5 | 8 | 8 | 9 |
| τL | 11 | 11 | 11 | 11 |
Applying RTA to the example is particularly easy. The task periods are large with respect to their response time, and hence, each interfering task must be taken into account only once, and all the successions converge immediately. Moreover, since there is only one critical section, the worst-case blocking times are the same for both protocols.
The worst-case execution time among all critical regions guarded by s is 2 time units. Therefore,
BH = 2 because
scan block τH;BM = 2 because
scan block τM ;BL = 0 because
scannot block τL.
Substituting back into (15.2), we get
For τH, hp(H) = ∅ and BH = 2, and hence: RH = CH + BH = 5 time units.
For τM : hp(M ) = {H} and BM = 2, and hence: RM = CM +BM +CH = 9 time units.
For τL : hp(L) = {H, M } and BL = 0, and hence: RL = CL+CH +CM = 11 time units.
Table 15.1 summarizes the actual response time of the various tasks involved in the example, depending on how the priority inversion problem has been addressed. For comparison, the rightmost column also shows the worst-case response times computed by the RTA method, extended as shown in (15.2). The worst-case response times are the same for both priority inheritance and immediate priority ceiling because their Bi are all the same.
Both the priority inheritance and the immediate priority ceiling protocols bound the maximum blocking time experienced by τH. It can be seen that its response time gets lower when any of these protocols are in use. On the other hand, the response time of τM increases as a side effect.
The response time of τL does not change but this can be expected because it is the lowest priority task. As a consequence, it can only suffer interference from the other tasks in the system but not blocking. For this reason, its response time cannot be affected by any protocol that introduces additional forms of blocking. It can also be seen that RTA provides a satisfactory worst-case response time in all cases except when the priority inversion problem has not been addressed at all.
15.5 Summary
In most concurrent applications of practical interest, tasks must interact with each other to pursue a common goal. In many cases, task interaction also implies blocking, that is, tasks must synchronize their actions and therefore wait for each other.
In this chapter we saw that careless task interactions may undermine priority assignments and, eventually, jeopardize the ability of the whole system to be scheduled because they may lead to an unbounded priority inversion. This happens even if the interactions are very simple, for instance, when tasks manipulate some shared data by means of critical regions.
One way of solving the problem is to set up a better cooperation between the scheduling algorithm and the synchronization mechanism, that is, to allow the synchronization mechanism to modify task priorities as needed. This is the underlying idea of the algorithms discussed in this chapter: priority inheritance and the two variants of priority ceiling.
It is then possible to show that all these algorithms are actually able to force the worst-case blocking time of any task in the system to be upper-bounded. Better yet, it is also possible to calculate the upper bound, starting from a limited amount of additional information about task characteristics, which is usually easy to collect.
Once the upper bound is known, the RTA method can also be extended to take consider it and calculate the worst-case response time of each task in the system, taking task interaction into account.