
Chapter 8. Supervisors
Now that we are able to monitor and handle predictable errors, such as running out of frequencies, we need to tackle unexpected errors arising as the result of corrupt data or bugs in the code. The catch is that unlike the errors returned to the client by the frequency allocator or alarms raised by the event managers, we will not know what the unexpected errors are until they have occurred. We could speculate, guess, and try to add code that handles the unexpected and hope for the best. Using automated test generation tools based on property-based testing, such as QuickCheck or PropEr, can definitely help create failure scenarios you would never devise on your own. But unless you have supernatural powers, you will never be able to predict every possible unexpected error that might occur, let alone handle it before knowing what it is.
Too often, developers try to cater for bugs or corrupt data by
implementing their own error-handling and recovery strategies in their code,
with the result that they increase the complexity of the code along with
the cost of maintaining it (and, yet handle only a fraction of the issues
that can arise, and more often than not, end up inserting more bugs in the
system than they solve). After all, how can you handle a bug if you don’t
know what the bug is? Have you ever come across a C
programmer who checks the return values of printf
statements, but is unsure of what to do if an error actually occurs? If
you’ve come to Erlang from another language that supports exception
handling, such as Java or C++, how many times have you seen catch
expressions that contain nothing more than TODO
comments to remind the development team to fix the exception handlers at
some point in the future—a point that unfortunately never arrives?
This is where the generic supervisor behavior makes its entrance. It takes over the responsibility for the unexpected-error-handling and recovery strategies from the developer. The behavior, in a deterministic and consistent manner, handles monitoring, restart strategies, race conditions, and borderline cases most developers would not think of. This results in simpler worker behaviors, as well as a well-considered error-recovery strategy. Let’s examine how the supervisor behavior works.
Supervision Trees
Supervisors are processes whose only task is to monitor and manage children.
They spawn processes and link themselves to these processes. By
trapping exits and receiving EXIT signals, the supervisors
can take appropriate actions when something unexpected occurs. Actions
vary from restarting a child to not restarting it, terminating some or
all the children that are linked to the supervisor, or even terminating
itself. Child processes can be both supervisors and workers.
Fault tolerance is achieved by creating supervision trees, where the supervisors are the nodes and the workers are the leaves (Figure 8-1). Supervisors on a particular level monitor and handle children in the subtrees they have started.
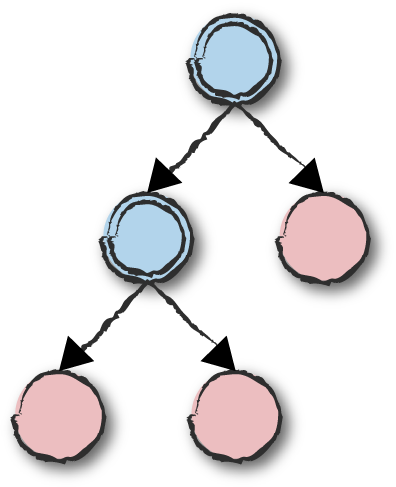
Figure 8-1. Supervision trees
Figure 8-1 uses a double ring to denote processes that trap exits. Only supervisors are trapping exits in our example, but there is nothing stopping workers from doing the same.
Let’s start by writing our own simple supervisor. It will allow us to better appreciate what needs to happen behind the scenes before examining the OTP supervisor implementation. Given a list of child process specifications, our simple supervisor starts the children as specified and links itself to them. If any child terminates abnormally, the simple supervisor immediately restarts it. If the children instead terminate normally, they are removed from the supervision tree and no further action is taken. Stopping the supervisor results in all of the children being unconditionally terminated.
Here is the code that starts the supervisor and child processes:
-module(my_supervisor).-export([start/2,init/1,stop/1]).start(Name,ChildSpecList)->register(Name,Pid=spawn(?MODULE,init,[ChildSpecList])),{ok,Pid}.stop(Name)->Name!stop.init(ChildSpecList)->process_flag(trap_exit,true),loop(start_children(ChildSpecList)).start_children(ChildSpecList)->[{element(2,apply(M,F,A)),{M,F,A}}||{M,F,A}<-ChildSpecList].
When starting my_supervisor, we
provided the init/1 function with child specifications. This a list of {Module,
Function, Arguments} tuples containing the functions that will
spawn and link the child process to its parent. We assume that this
function always returns {ok, Pid}, where Pid is
the process ID of the newly spawned child. Any other return value is
interpreted as a startup error.
We start each child in start_children/1 by calling
apply(Module,Function,Args) within a list
comprehension that processes the ChildSpecList. The result of
the list comprehension is a list of tuples where the first element is the
child pid, retrieved from the {ok, Pid} tuple returned from
apply/3, and a tuple of the module, function, and arguments
used to start the child. If Module does not
exist, Function is not exported, and if
Args contains the wrong number of arguments,
the supervisor process terminates with a runtime exception. When the
supervisor terminates, the runtime ensures that all
processes linked to it receive an EXIT signal. If the linked
child processes are not trapping exits, they will terminate.
But if they are trapping exits, they need to handle the EXIT
signal, most likely by terminating themselves, thereby propagating the
EXIT signal to other processes in their link set.
It is a valid assumption that nothing abnormal should happen when starting your system. If a supervisor is unable to correctly start a child, it terminates all of its children and aborts the startup procedure. While we are all for a resilient system that tries to recover from errors, startup failures is where we draw the line.
loop(ChildList)->receive{'EXIT',Pid,normal}->loop(lists:keydelete(Pid,1,ChildList));{'EXIT',Pid,_Reason}->NewChildList=restart_child(Pid,ChildList),loop(NewChildList);stop->terminate(ChildList)end.restart_child(Pid,ChildList)->{Pid,{M,F,A}}=lists:keyfind(Pid,1,ChildList),{ok,NewPid}=apply(M,F,A),lists:keyreplace(Pid,1,ChildList,{NewPid,{M,F,A}}).terminate(ChildList)->lists:foreach(fun({Pid,_})->exit(Pid,kill)end,ChildList).
The supervisor loops with a tuple list of the format {Pid,
{Module, Function, Argument}} returned from the
start_children/1 call. This tuple list is the supervisor
state. We use this information if a child terminates abnormally, mapping
the pid to the function used to start it and needed to restart it. If we
want to register supervisors with an alias, we pass it as an argument
using the variable name. The reason for not hardcoding it in the module
is that you will often have multiple instances of a supervisor in your
Erlang node.
Having started all the children, the supervisor process enters the
receive-evaluate loop. Notice how this is no different from the process
skeleton described in “Process Skeletons”, and similar to
the generic loop in servers, FSMs, and event handler processes. The only
difference from the other behavior processes we have implemented in Erlang
is that here we handle only EXIT messages and take specific
actions when receiving the stop message.
In our supervisor, if a child process terminates with reason
normal, it is deleted from the
ChildSpecList and the supervisor continues monitoring other
children. If it terminates with a reason other than normal, the child is restarted and its old pid is
replaced with NewPid in the tuple {Pid, {Module,
Function, Argument}} of the child specification list. If our
supervisor receives the stop message,
it traverses through its list of child processes, terminating each
one.
Let’s try out my_supervisor
with the Erlang implementation of the coffee FSM. If you do the same, don’t forget to compile
coffee_fsm.erl and
hw.erl. Actually, on second thought, don’t compile
hw.erl. Start your coffee FSM from the supervisor and see
what happens if the hw.erl stub module is not available. When
all of the error reports are being printed out, compile or load hw.erl from the shell, making it accessible:
1>my_supervisor:start(coffee_sup, [{coffee_fsm, start_link, []}]).{ok, <0.39.0>} =ERROR REPORT==== 4-May-2013::08:26:51 === Error in process <0.468.0> with exit value: {undef,[{hw,reboot,[],[]},{coffee,init,0,[....]}]} ...<snip>... =ERROR REPORT==== 4-May-2013::08:26:58 === Error in process <0.474.0> with exit value: {undef,[{hw,reboot,[],[]},{coffee,init,0,[....]}]} 2>c(hw).Machine:Rebooted Hardware Display:Make Your Selection {ok,hw} 3>Pid = whereis(coffee_fsm).<0.476.0> 4>exit(Pid, kill).Machine:Rebooted Hardware Display:Make Your Selection true 5>whereis(coffee).<0.479.0> 6>my_supervisor:stop(coffee_sup).stop 7>whereis(coffee).undefined
What is happening? The coffee FSM, in its init
function, calls hw:reboot/0, causing an undef
error because the module cannot be loaded. The supervisor receives the
EXIT signal and restarts the FSM. The restart becomes cyclic,
because restarting the FSM will not solve the issue; it will continue to
crash until the module is loaded and becomes available. Compiling the
hw.erl module in shell command 2 also
loads the module, allowing the coffee FSM to initialize itself and start
correctly. This puts an end to the cyclic restart.
Cyclic restarts happen when restarting a process after an abnormal termination does not solve the problem, resulting in the process crashing and restarting again. The supervisor behavior has mechanisms in place to escalate cyclic restarts. We cover them later in this chapter. Now, back to our example.
In shell command 3, we find the pid of the FSM and use it to send an
exit signal, which causes the coffee FSM to terminate. It is immediately
restarted, something visible from the printouts in the shell generated in
the init/0 function. We stop the supervisor in shell command
6, which, as a result, also terminates its workers.
Now comes the question we’ve been asking for every other behavior. Have a look at the code in my_supervisor.erl and, before looking at the answer in Table 8-1, ask yourself: what is generic and what is specific?1
| Generic | Specific |
|---|---|
|
|
Spawning the supervisor and registering it will be the same, irrespective of what children the supervisor starts or monitors. Monitoring the children and restarting them are also generic, as are stopping the supervisor and terminating all of the children. In other words, all of the code in my_supervisor.erl is generic. All of the specific functionality is passed as variables. It includes the child spec list, the order in which the children have to be started, and the supervisor alias.
Although my_supervisor will
cater for some use cases, it barely scratches the surface of what a
supervisor has to do. We decided to keep our example simple, but could
have added more specific parameters. We’ve already seen that child startup
failures cause endless retries. Supervisors should provide the ability to
specify the maximum number of restarts within a time interval so that
rather than trying endlessly, they can take further action if the child
does not start properly. And what about dependencies? If a child
terminates, shouldn’t the supervisor offer the option of terminating and
restarting other children that depend on that child? These are some of the
configuration parameters included in the OTP supervisor behavior library
module, which we cover next.
OTP Supervisors
In OTP, we structure our programs with one or more supervision trees. We group together, under the same subtree, workers that are either similar in nature or have dependencies, starting them in order of dependency. When describing supervision trees, worker behaviors are usually represented as circles, while supervisors are represented as squares. Figure 8-2 shows what the supervision structure of the frequency allocator example we’ve been working on could look like.
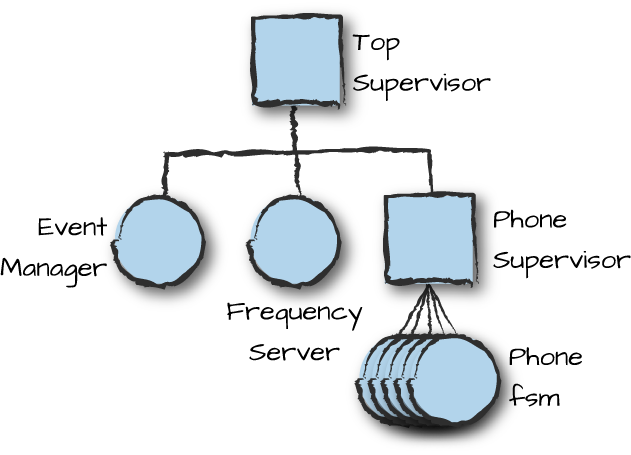
Figure 8-2. Supervision trees
Taking dependencies into consideration, the top supervisor first starts the event manager worker that handles alarms, because it is not dependent on any other worker. The top supervisor then starts the frequency allocator, because it sends alarms to the event manager. The last process on that level is a phone supervisor, which takes responsibility for starting and monitoring all of the FSMs representing the cell phones.
Note how we have grouped dependent processes together in one subset of the tree and related processes in another, starting them from left to right in order of dependency. This forms part of the supervision strategy of a system and in some situations is put in place not by the developer, who focuses only on what particular workers have to do, but by the architect, who has an overall view and understanding of the system and how the different components interact with each other.
The Supervisor Behavior
In OTP, the supervisor behavior is implemented in the supervisor
library module. Like with all behaviors, the callback module is used for
nongeneric code, including the behavior and version directives. The
supervisor callback module needs to export a single callback function
used at startup to configure and start the subset of the tree handled by
that particular supervisor (Figure 8-3).
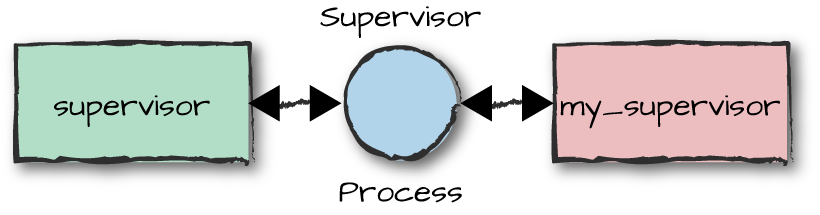
Figure 8-3. Generic supervisors
You may have guessed that the single exported function is the
init/1 function, containing all of the specific supervisor
configuration. The callback module usually also provides the function
used to start the supervisor itself. Let’s look at these calls more
closely.
Starting the Supervisor
As a first step in getting our complete supervision tree in place, we create a supervisor that starts and monitors our frequency server and overload event manager. Because the frequency server calls the overload event manager, it has a dependency on the event manager. That means that the overload manager needs to be started before the frequency server, and if the overload manager terminates, we need to terminate the frequency server as well before restarting them both. Supervision tree diagrams, such as that in Figure 8-4, show not only the supervision hierarchy, but also dependencies and the order in which processes are started.
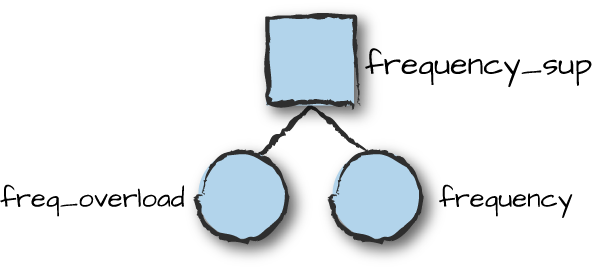
Figure 8-4. Frequency server supervision tree
Let’s look at the code for the frequency supervisor callback
module. Like with all other behaviors, you have to include the behavior directive.
You start the supervisor using the start or
start_link functions, passing the optional supervisor name, the callback module,
and arguments passed to init/1. As with event managers, there is no Options argument
allowing you to set tracing, logging, or memory fine-tuning options:
-module(frequency_sup).-behavior(supervisor).-export([start_link/0,init/1]).-export([stop/0]).start_link()->supervisor:start_link({local,?MODULE},?MODULE,[]).stop()->exit(whereis(?MODULE),shutdown).init(_)->ChildSpecList=[child(freq_overload),child(frequency)],{ok,{{rest_for_one,2,3600},ChildSpecList}}.child(Module)->{Module,{Module,start_link,[]},permanent,2000,worker,[Module]}.
In our example, the [] in the
start_link/3 call denotes the arguments sent to the
init/1 callback, not the Options. You cannot
set sys options in supervisors at startup, but you can do
so once the supervisor is started. Another difference from other
behaviors is that supervisors do not expose built-in stop functionality
to the developer. They are usually terminated by their supervisors or
when the node itself is terminated. For those of you who do not want to
write systems that never stop and insist on shutting down the supervisor
from the shell, look at the stop/0 function we’ve included;
it simulates the shutdown procedure from a higher-level
supervisor.
Calling start_link/3 results in invocation of the
init/1 callback function. This function returns a tuple of
the format {ok, SupervisorSpec}, where
SupervisorSpec is a tuple containing the supervisor
configuration parameters and the child specification list (Figure 8-5). This specification is a bit more complicated
than our pure Erlang example, because more is happening behind the
scenes. The next section provides a complete overview of SupervisorSpec. For now, we informally introduce it by
walking through the example.
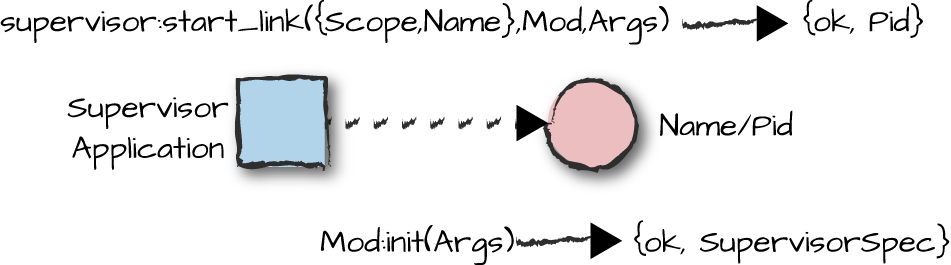
Figure 8-5. Generic supervisors
In our example, the first element of the
SupervisorSpec configuration parameter tuple tells the
supervisor that if a child terminates, we want to terminate all children
that were started after it before restarting them all. In general this
element is called the restart strategy, and to obtain the desired
restart approach we need for this case, we specify the rest_for_one strategy. Following the restart
strategy, the numbers 2 and 3600 in the tuple, called the intensity and
period, respectively, tell the supervisor that it is allowed a maximum
of two abnormal child terminations per hour (3,600 seconds). If this
number is exceeded, the supervisor terminates itself and its children,
and sends an exit signal to all the processes in its link set with
reason shutdown. So, if this supervisor were part of a
larger supervision tree, the supervisor monitoring it would receive the
exit signal and take appropriate action.
The second element in the SupervisorSpec
configuration parameter tuple is the child specification list. Each item
in the list is a tuple specifying details for how to start and manage
the static child processes. In our example, the first element in the
tuple is a unique identifier within the supervisor in which it is
started. Following that is the {Module,Function,Arguments}
tuple indicating the function to start and link the worker to the
supervisor, which is expected to return {ok,Pid}. Next, we
find the restart directive; the atom permanent specifies
that when the supervisor is restarting workers, this worker should
always be restarted.
Following the restart directive is the shutdown directive,
specified here as 2000. It tells the supervisor to wait
2,000 milliseconds for the child to shut down (including the time spent in the
terminate function) after sending the EXIT
signal. There is no guarantee that terminate is called, as the child
might be busy serving other requests and never reach the
EXIT signal in its mailbox.
Following that, the worker atom indicates that the
child is a worker as opposed to another supervisor, and finally the
single-element list [Module] specifies the callback module
implementing the worker.
supervisor:start_link(NameScope,Mod,Args)supervisor:start_link(Mod,Args)->{ok,Pid}{error,Error}ignoreMod:init/1->{ok,{{RestartStrategy,MaxR,MaxT},[ChildSpec]}}ignore
Because it can be difficult to remember the purpose and order of
all the fields of the SupervisorSpec, Erlang 18.0 and newer
allow it to be specified instead as a map. Here are implementations of
init/1 and child/1 that return our
SupervisorSpec as a map rather than a tuple:
init(_)->ChildSpecList=[child(overload),child(frequency)],SupFlags=#{strategy=>rest_for_one,intensity=>2,period=>3600},{ok,{SupFlags,ChildSpecList}}.child(Module)->#{id=>Module,start=>{Module,start_link,[]},restart=>permanent,shutdown=>2000,type=>worker,modules=>[Module]}.
As you can see, the SupervisorSpec map code is much
easier to read because unlike in the tuple, all the fields are named. If
you’re using Erlang 18.0 or newer, use maps for your supervisor
specifications.
Supervisors, just like all other behaviors, can be registered or
referenced using their pids. If registering the supervisor, valid values
to NameScope include {local,Name} and
{global,Name}. You can also use the name registry
represented in the {via, Module, Name} tuple, where
Module exports the same API defined in the global name
registry.
The init/1 callback function normally returns the
whole tuple comprising the restart tuple and a list of child
specifications. But if it instead returns ignore, the supervisor terminates with reason
normal. Note how supervisors do not export
start/2,3 functions, forcing you to link to the parent. In
the next section, we look at all the available options and restart
strategies in more detail. We refer to these options and strategies
as the supervisor
specification.
The Supervisor Specification
The supervisor specification is a tuple containing two elements (Figure 8-6):
The nongeneric information about the restart strategy for that particular supervisor
The child specifications relevant to all static workers the supervisor starts and manages
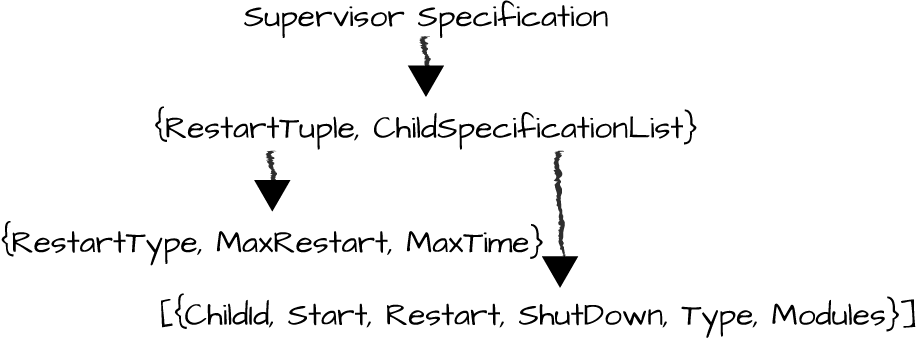
Figure 8-6. Supervisor specification
Let’s look at these values in more detail, starting with the restart tuple.
The restart specification
The restart tuple, of the format:
{RestartType,MaxRestart,MaxTime}
specifies what happens to the other children in its supervision tree if a child terminates abnormally. By “child” we mean either a worker or another supervisor. Starting with Erlang 18.0, you can also use a map. The map defining the restart specification has the following type definition:
#{strategy=>strategy(),intensity=>non_neg_integer(),period=>pos_integer()}
There are four different restart types: one_for_one, one_for_all, rest_for_one, and simple_one_for_one. Under the one_for_one
strategy (Figure 8-7), only the crashed process is
restarted. This strategy is ideal if the workers don’t depend on each
other and the termination of one will not affect the others. Imagine a
supervisor monitoring the worker processes that control the instant
messaging sessions of hundreds of thousands of users. If any of these
processes crashes, it will affect only the user whose session is
controlled by the crashed process. All other workers should continue
running independently of each other.
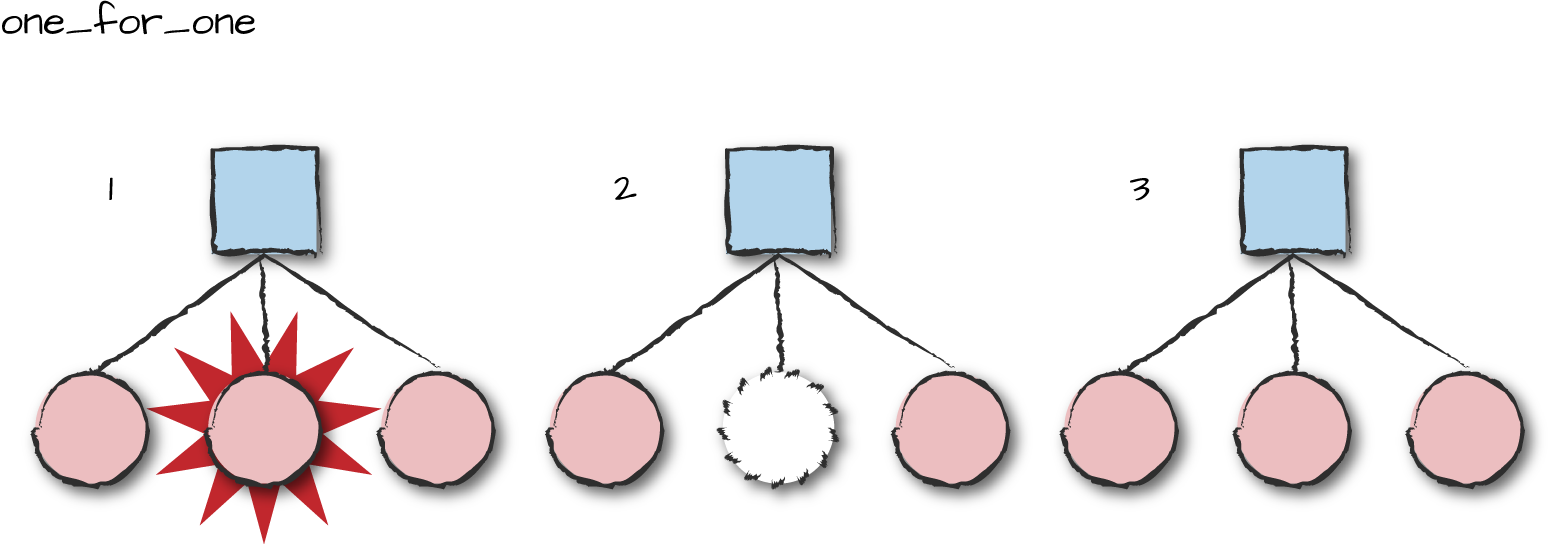
Figure 8-7. One for one
Under the one_for_all
strategy shown in Figure 8-8, if a process
terminates, all processes are terminated and restarted. This strategy
is used if all or most of the processes depend on each other. Picture
a very complex FSM handling a protocol stack. To simplify the design,
the machine has been split into separate FSMs that communicate with
each other asynchronously, and these workers all depend on each other.
If one terminates, the others would have to be terminated as well. For
these cases, pick the one_for_all
strategy.
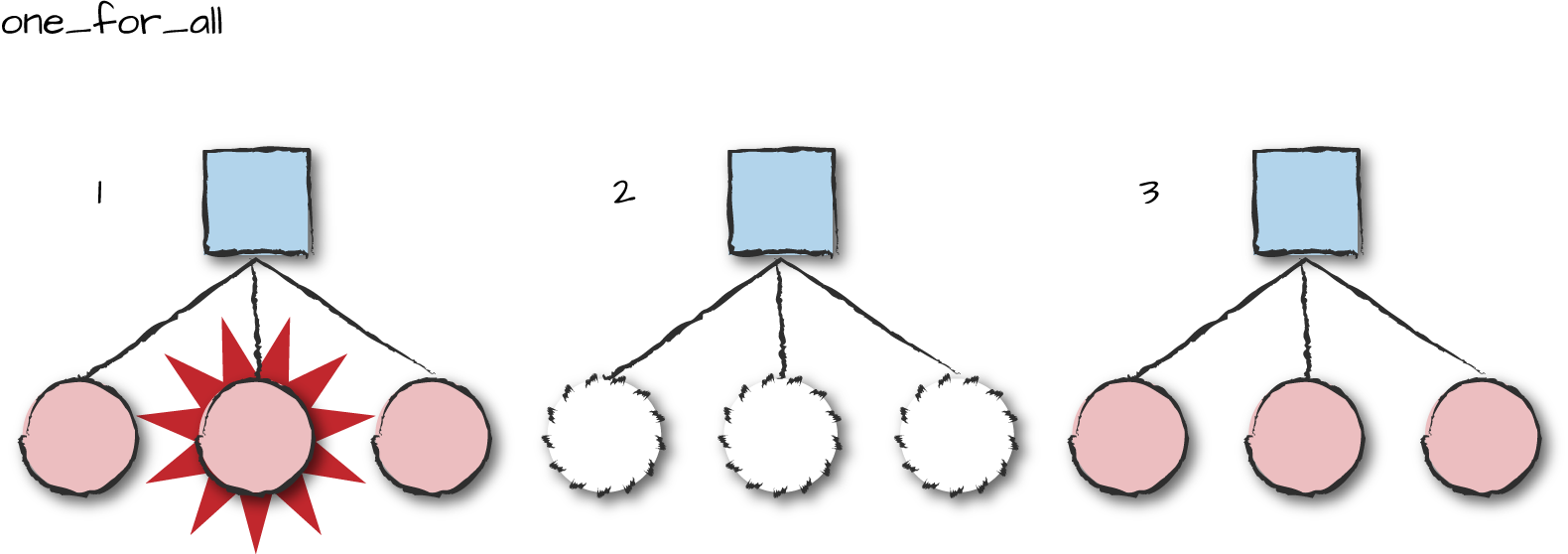
Figure 8-8. One for all
Under the rest_for_one
strategy (Figure 8-9), all processes started
after the crashed process are terminated and
restarted. Use this strategy if you start the processes in order of
dependency. In our frequency_sup example, we first start
the overload event manager, followed by the frequency allocator. The
frequency allocator sends requests to the overload event
manager whenever it runs out of frequencies. So if the overload
manager has crashed and is being restarted, there is a risk the
frequency server might send it requests that get lost. Under such
circumstances, we want to first terminate the frequency allocator, and
then restart the overload manager and the frequency allocator in that
order.
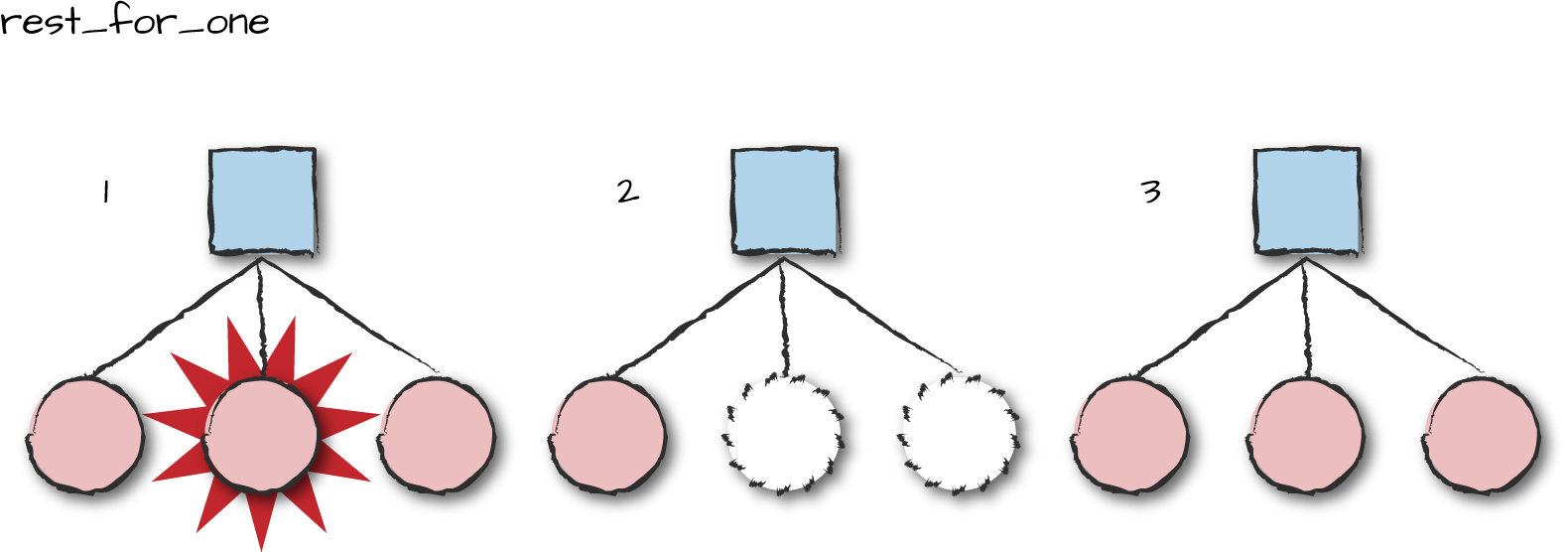
Figure 8-9. Rest for one
If losing the alarms sent to the frequency allocator did not
matter (as the requests were asynchronous), we could have used the one_for_one strategy. Or we could have taken it a step further by
making the raising and clearing of the alarms to the overload manager
synchronous. In this case, if the overload manager had crashed and was
being restarted, the frequency allocator would have also been
terminated only when trying to make a synchronous call to it. Had the
frequency allocator not run out of frequencies, thus not needing to
raise or clear alarms, it could have continued functioning. As we have
seen, there is no “one size fits all” solution; it all depends on the
requirements you have and behavior you want to give your
system.
There is one last restart strategy to cover: simple_one_for_one. It is used for children
of the same type added dynamically at runtime, not at startup. An
example of when we would use this strategy is in a supervisor handling
the processes controlling mobile phones that are added to and removed
from the supervision tree dynamically. We cover dynamic children and
the simple_one_for_one restart strategy later in
this chapter.
The last two elements in the restart tuple are
MaxRestart and MaxTime.
MaxRestart specifies the maximum number of restarts all
child processes are allowed to do in MaxTime seconds. If
the maximum number of restarts is reached in this number of seconds,
the supervisor itself terminates with reason shutdown, escalating the termination to its
higher-level supervisor. What is in effect happening is that we are
giving the supervisor MaxRestart chances to solve the
problem. If crashes still occur in MaxTime seconds, it
means that a restart is not solving the problem, so the supervisor
escalates the issue to its supervisor, which will hopefully be able to
solve it.
Look at the supervision tree in Figure 8-2. What if the phone FSMs under the phone supervisor are crashing because of corrupt data in the frequency handler? No matter how many times we restart them, they will continue to crash, because the problem lies in the frequency allocator, a worker supervised outside of our supervision subtree. We solve cyclic restarts of this nature through escalation. If we allow the phone supervisor to terminate, the top supervisor will receive the exit signal and restart the frequency server and event manager workers before restarting the phone supervisor. Hopefully, the restart can clear the corrupt data, allowing the phone FSMs to function as expected.
The key to using supervisors is to ensure you have properly designed your start order and the restart strategy associated with it. Though you will never be able to fully predict what will cause your processes to terminate abnormally, you can nevertheless try to design your restart strategy to recreate the process state from known-good sources. Instead of storing the state persistently and assuming it is uncorrupted such that it reading it after a crash will correctly restore it, retrieve the various elements that created your state from their original sources.
For example, if the corrupted data causing your worker to crash was the result of a transient transmission error, rereading it might solve the problem. The supervisor would restart the worker, which in turn would successfully reread the transmission and continue operating. And since the system would have logged the crash, the developer could look into its cause, modify the code to handle it appropriately, and prepare and deploy a new release to ensure that future similar transmission errors do not negatively impact the system.
In other cases, recovery might not be as straightforward. More difficult transmission errors might cause repeated worker crashes, in turn causing the supervisor to restart the worker. But since the restarts do not correct the problem, the client supervisor eventually reaches the restart threshold and terminates itself. This in turn affects the top-level supervisor, which eventually reaches its own restart threshold, and by terminating itself it takes the entire virtual machine down with it. When the virtual machine terminates, heart, a monitoring mechanism we cover in Chapter 11, detects that the node is down and invokes a shell script. The recovery actions in this script could be as simple as restarting the Erlang VM or as drastic as rebooting the computer. Rebooting might reset the link to the hardware that is suffering from transmission problems and solve the problem. If it doesn’t, after a few reboot attempts the script might decide not to try again and instead alert an operator, requesting manual intervention.
Hopefully, a load balancer will already have kicked in to forward requests to redundant hardware, providing seamless service to end users. If not, this is when you receive a call in the middle of the night from a panicking first-line support engineer informing you there is an outage. In either case, the crash is logged, hopefully with enough data to allow you to investigate and solve the bug: namely, ensuring that data is checked before being introduced into your system so that data corrupted by transmission errors is not allowed in the first place. We look at distributed architectures and fault tolerance in Chapter 13. For now, let’s stay focused on recovery of a single node. Next in line are child specifications.
The child specification
The child specification contains all of the information the supervisor needs to start, stop, and delete its child processes. The specification is a tuple of the format:
{Name,StartFunction,RestartType,ShutdownTime,ProcessType,Modules}
or, in Erlang 18.0 or newer, a map with the following type specification:
child_spec()=#{id=>child_id(),% mandatorystart=>mfargs(),% mandatoryrestart=>restart(),% optionalshutdown=>shutdown(),% optionaltype=>worker(),% optionalmodules=>modules()}% optional
The elements of the tuple are:
NameAny valid Erlang term, used to identify the child. It has to be unique within a supervisor, but can be reused across supervisors within the same node.
StartFunctionA tuple of the format
{Module, Function, Args}, which, directly or indirectly, calls one of the behaviorstart_linkfunctions. Supervisors can start only OTP-compliant behaviors, and it is their responsibility to ensure that the behaviors can be linked to the supervisor process. You cannot link regular Erlang processes to a supervision tree, because they do not handle the system calls.RestartTypeTells the supervisor how to react to a child’s termination. Setting it to
permanentensures that the child is always restarted, irrespective of whether its termination is normal or abnormal. Setting it totransientrestarts a child only after abnormal termination. If you never want to restart a child after termination, setRestartTypetotemporary.ShutdownTimeShutdownTimeis a positive integer denoting a time in milliseconds, or the atominfinity. It is the maximum time allowed to pass between the supervisor issuing theEXITsignal and theterminatecallback function returning. If the child is overloaded and it takes longer, the supervisor steps in and unconditionally terminates the child process. Note thatterminatewill be called only if the child process is trapping exits. If you are feeling grumpy or do not need the behavior to clean up after itself, you can instead specifybrutal_kill, allowing the supervisor to unconditionally terminate the child usingexit(ChildPid, kill).Choose your shutdown time with care, and never set it to
infinityfor a worker, because it might cause the worker to hang in itsterminatecallback function. Imagine that your worker is trying to communicate with a defunct piece of hardware, the very reason for your system needing to be rebooted. You will never get a response because that part of the system is down, and this will stop the system from restarting. If you have to, use an arbitrarily large number, which will eventually allow the supervisor to terminate the worker. For children that are supervisors themselves, on the other hand, it is common but not mandatory to selectinfinity, giving them the time they need to shut down their potentially large subtree.ProcessTypeandModulesThese are used during a software upgrade to control how and which processes are being suspended during the upgrade.
ProcessTypeis the atomworkerorsupervisor, whileModulesis the list of modules implementing the behavior. In the case of the frequency server, we would includefrequency, while for our coffee machine we would specifycoffee_fsm. If your behavior includes library modules specific to the behavior, include them if you are concerned that an upgrade of the behavior module will be incompatible with one of library modules. For example, if you changed the API in thehwinterface module as well as thecoffee_fsmbehavior calling it, you would have to atomically upgrade both modules at the same time to ensure thatcoffee_fsmdoes not call the old version ofhw. By listing both of these modules, you would be covered. But if you did not listhw, as in our example, you would have to ensure that any upgrade would be backward-compatible and handle both the old and the new APIs. We cover software upgrades in more detail in Chapter 12.What if you don’t know your
Modulesat compile time? Think of the event manager, which is started without any event handlers. When you do not know what will be running when you do a software upgrade, setModulesto the atomdynamic. When using dynamic modules, the supervisor will send a request to the behavior module and retrieve the module names when it needs them.
Before looking at the interface and callback details, let’s test
our example with what we’ve learned. Looking at their child
specifications, we see that both the overload event manager and the
frequency server are permanent worker processes given 2 seconds to
execute in their terminate functions. We start the supervisor and its
children, and see immediately that they have started correctly.
In shell command 4, we stop the frequency server, but because it has
its RestartType set to permanent, the supervisor will immediately
restart it. We verify the restart in shell command 5 by retrieving the
pid for the new frequency server process and noting that it differs
from the pid of the original server returned from shell command 2. In
shell command 6 we explicitly kill the frequency server, and shell
command 7 shows that, once again, it restarted:
1>frequency_sup:start_link().{ok,<0.35.0>} 2>whereis(frequency).<0.38.0> 3>whereis(freq_overload).<0.36.0> 4>frequency:stop().ok 5>whereis(frequency).<0.42.0> 6>exit(whereis(frequency), kill).true 7>whereis(frequency).<0.45.0> 8>supervisor:which_children(frequency_sup).[{frequency,<0.45.0>,worker,[frequency]}, {freq_overload,<0.36.0>,worker,[freq_overload]}] 9>supervisor:count_children(frequency_sup).[{specs,2},{active,2},{supervisors,0},{workers,2}]
In shell command 8, which_children/1 returns a tuple
list containing the ChildId its pid,
worker or supervisor to denote its role,
and the Modules list. Be careful when using this function
if your supervisor has lots of children, because it will consume lots
of memory. If you are calling the function from the shell, remember
that the result will be stored in the shell history and not be garbage
collected until the history is cleared.
supervisor:which_children(SupRef)->[{Id,Child,Type,Modules}]supervisor:count_children(SupRef)->[{specs,SpecCount},{active,ActiveProcessCount},{supervisors,ChildSupervisorCount},{workers,ChildWorkerCount}]supervisor:check_childspecs(ChildSpecs)->ok{error,Reason}
The function count_children/1 returns a
property list covering the supervisor’s child specifications and
managed processes. The elements are:
specsThe total number of children, both those that are active and those that are not
activeThe number of actively running children
workersandsupervisorsThe number of children of the respective type
And finally, check_childspecs/1 is useful when
developing and troubleshooting child specifications and startup
issues. It validates a list of child specifications, returning an
error if any are incorrect or the atom ok if it finds no
problems.
Supervisor specifications are easy to write. And as a result, they are also easy to get wrong. Too often, programmers pick configuration values that do not reflect the reality and conditions under which the application is running, or copy specifications from other applications, or, even worse, use the default values from skeleton templates that different editors provide. You must take care to get your supervision structure right when designing your start and restart strategy, and must build in fault tolerance and redundancy. The tasks include starting your processes in order of dependency, and setting restart thresholds that will propagate problems to supervisors higher up in the hierarchy and allow them to take control if supervisors lower down in the supervision tree cannot solve the issue.
Dynamic Children
Having gone through the supervisor specification returned by the
init/1 callback function, you must have come to the
realization that the only child type we have dealt with so far is
static children started along with the supervisor. But another approach
is viable as well: dynamically creating the child specification list in
our init/1 call when starting the supervisor. For instance,
we could inspect the number of active mobile devices and start a worker
for each of them. We have already handled the end of the worker’s
lifecycle (by making the worker transient, so that if the phone is shut off,
the worker is terminated), but we don’t yet have similar flexibility for
the start of the lifecycle. What if a mobile device attaches itself to
the network after we have started the supervisor? The solution to the problem is dynamic children, represented in
Figure 8-10.
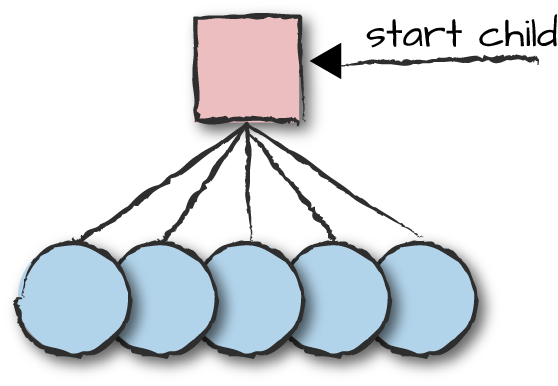
Figure 8-10. Dynamic children
Let’s start an empty supervisor
whose sole responsibility will be that of dynamically starting and
monitoring the FSM processes controlling mobile devices. The FSM we’ll
be using is the one described but left as an exercise in “The Phone Controllers”. If you
have not already solved it, download the code from the book’s code
repository. The code includes a phone simulator, phone.erl, which starts a specified number of
mobile devices and lets them call each other. We’ll make the phone
supervisor a child of the frequency supervision tree. Let’s take a look at the code for the phone_sup module:
-module(phone_sup).-behavior(supervisor).-export([start_link/0,attach_phone/1,detach_phone/1]).-export([init/1]).start_link()->supervisor:start_link({local,?MODULE},?MODULE,[]).init([])->{ok,{{one_for_one,10,3600},[]}}.attach_phone(Ms)->casehlr:lookup_id(Ms)of{ok,_Pid}->{error,attached};_NotAttached->ChildSpec={Ms,{phone_fsm,start_link,[Ms]},transient,2000,worker,[phone_fsm]},supervisor:start_child(?MODULE,ChildSpec)end.detach_phone(Ms)->casehlr:lookup_id(Ms)of{ok,_Pid}->supervisor:terminate_child(?MODULE,Ms),supervisor:delete_child(?MODULE,Ms);_NotAttached->{error,detached}end.
In the init/1 supervisor callback function we
set the maximum number of restarts to 10 per hour, and because mobile
devices run independently of each other, the one_for_one restart
strategy will do. Note that since we intend to start all children
dynamically, the return value from init/1 includes an empty
list of child specifications. Further down in the module is the
phone_sup:attach_phone/1 call, which, given a mobile device
number Ms, checks whether the number is already registered
on the network. If not, it creates a child specification and uses the
supervisor:start_child/2 call to start it.
Let’s experiment with this code. In shell commands 1 through 3 in the following interaction, we
start the supervisors and initialize the home location register
database, hlr (covered in “ETS: Erlang Term Storage”). We start two phones in shell commands 4 and 5,
providing simple phone numbers as arguments. In shell command 6, we make
phone 2, controlled by process P2, start an outbound call to the phone
with phone number 1. Debug printouts are turned on for both phone FSMs,
allowing you to follow the interaction between the phone FSMs and the
phone simulator, implemented in the phone module. Following the debug printouts,
we can see that phone 2 starts an outbound call to phone 1. Phone 1
receives the inbound call and rejects it, terminating the call and
making both phones return to idle (as the simulator is based on random
responses, you might get a different result when running the
code):
1>frequency_sup:start_link().{ok,<0.35.0>} 2>phone_sup:start_link().{ok,<0.40.0>} 3>hlr:new().ok 4>{ok, P1} = phone_sup:attach_phone(1).{ok,<0.43.0>} 5>{ok, P2} = phone_sup:attach_phone(2).{ok,<0.45.0>} 6>phone_fsm:action({outbound,1}, P2).*DBG* <0.45.0> got {'$gen_sync_all_state_event', {<0.33.0>,#Ref<0.0.4.55>}, {outbound,1}} in state idle <0.45.0> dialing 1 *DBG* <0.45.0> sent ok to <0.33.0> and switched to state calling *DBG* <0.43.0> got event {inbound,<0.45.0>} in state idle *DBG* <0.43.0> switched to state receiving ok *DBG* <0.43.0> got event {action,reject} in state receiving *DBG* <0.43.0> switched to state idle *DBG* <0.45.0> got event {reject,<0.43.0>} in state calling 1 connecting to 2 failed:rejected <0.45.0> cleared *DBG* <0.45.0> switched to state idle 7>supervisor:which_children(phone_sup).[{2,<0.45.0>,worker,[phone_fsm]}, {1,<0.43.0>,worker,[phone_fsm]}] 8>supervisor:terminate_child(phone_sup, 2).ok 9>supervisor:which_children(phone_sup).[{2,undefined,worker,[phone_fsm]}, {1,<0.43.0>,worker,[phone_fsm]}] 10>supervisor:restart_child(phone_sup, 2).{ok,<0.53.0>} 11>supervisor:delete_child(phone_sup, 2).{error,running} 12>supervisor:terminate_child(phone_sup, 2).ok 13>supervisor:delete_child(phone_sup, 2).ok 14>supervisor:which_children(phone_sup).[{1,<0.43.0>,worker,[phone_fsm]}]
Have a look at the other shell commands in our example. You will
find functions used to start, stop, restart, and delete children from
the child specification list, some of which we use in our phone_sup module. Note how we get the list of
workers when calling supervisor:which_children/1. We
terminate the child in shell command 8, and note in the response to shell command 9 that
it is still part of the child specification list but with the pid set to
undefined. This means that the child
specification still exists, but the process is not running. We can now
restart the child using only the child Name in shell
command 10.
Keep in mind that these function calls do not use pids, but only unique names identifying the child specifications. This is because children crash and are restarted, so their pids might change. Their unique names, however, will remain the same.
Once the supervisor has stored the child specification, we can
restart it using its unique name. To remove it from the child
specification list, we need to first terminate the child as shown in
shell command 12, after which we call supervisor:delete_child/2 in
shell command 13. Looking at the child specifications in shell command
14, we see that the specification of phone 2 has been deleted.
Simple one for one
The simple_one_for_one restart strategy is used when there is only one child
specification shared by all the processes under a single supervisor.
Our phone supervisor example fits this description, so let’s rewrite
it using this strategy. In doing so, we have added the
detach_phone/1 function, which we explain later. Note how
we have moved the hlr:new() call to the supervisor
init function:
-module(simple_phone_sup).-behavior(supervisor).-export([start_link/0,attach_phone/1,detach_phone/1]).-export([init/1]).start_link()->supervisor:start_link({local,?MODULE},?MODULE,[]).init([])->hlr:new(),{ok,{{simple_one_for_one,10,3600},[{ms,{phone_fsm,start_link,[]},transient,2000,worker,[phone_fsm]}]}}.attach_phone(Ms)->casehlr:lookup_id(Ms)of{ok,_Pid}->{error,attached};_NotAttached->supervisor:start_child(?MODULE,[Ms])end.detach_phone(Ms)->casehlr:lookup_id(Ms)of{ok,Pid}->supervisor:terminate_child(?MODULE,Pid);_NotAttached->{error,detached}end.
If you have looked at the code in detail, you might have spotted
a few differences between the simple_one_for_one restart strategy and the
one we used earlier for dynamic children. The first change is the
arguments passed when starting the children. In the supervisor
init/1 callback function, the {phone_fsm,
start_link, ChildSpecArgs} in the child specification specifies
no arguments (ChildSpecArgs is []), whereas
the function phone_fsm:start_link(Args) in the earlier
example takes one, Ms. As the children are dynamic, they
are started via the function supervisor:start_child(SupRef,
StartArgs). This function takes its second parameter,
which it expects to be a list of terms, appends that list to the list
of arguments in the child specification, and calls apply(Module,
Function, ChildSpecArgs ++ StartArgs).
For the phone FSM, ChildSpecArgs in the child
specification is empty, so the result of passing [Ms] as
the second argument (StartArgs) to
supervisor:start_child/2 is that it calls
phone_fsm:start_link(Ms). It is also worth noting that we
are initializing the ETS tables using the hlr:new() call
in the init/1 callback, making the supervisor the owner
of the tables.
The second difference is that in the simple_one_for_one
strategy you do not use the child’s name to reference it, you use its
pid. If you study the detach_phone/1 function, you will
notice this. You will also notice in the code that we are terminating
the child without deleting it from the child specification list. We
don’t have to, as it gets deleted automatically when terminated. Thus, the
functions supervisor:restart_child/1 and
supervisor:delete_child/1 are not allowed. Only supervisor:terminate_child/2 will
work. Testing the supervisor reveals no surprises:
1>frequency_sup:start_link().{ok,<0.35.0>} 3>simple_phone_sup:start_link().{ok,<0.40.0>} 4>simple_phone_sup:attach_phone(1), simple_phone_sup:attach_phone(2).{ok,<0.43.0>} 5>simple_phone_sup:attach_phone(3).{ok,<0.45.0>} 6>simple_phone_sup:detach_phone(3).ok 7>supervisor:which_children(simple_phone_sup).[{undefined,<0.42.0>,worker,[phone_fsm]}, {undefined,<0.43.0>,worker,[phone_fsm]}]
Once we’ve detached the phone, it does not appear among the
supervisor children. This is specific to the simple_one_for_one
strategy, because with the other strategies, you need to both
terminate and delete the children. Another difference is during
shutdown; as simple_one_for_one
supervisors often grow to have many children running independently of
each other (often a child per concurrent request), when shutting down,
they terminate the children in no specific order, often concurrently.
This is acceptable, as determinism in these cases is irrelevant, and
most probably not needed. Finally, simple_one_for_one supervisors scale better
with a large number of dynamic children, as they use a dict key-value dictionary library module to
store child specifications, unlike other supervisor types, which use a
list. While other supervisors might be faster for small numbers of
children, performance deteriorates quickly if the frequency at which
dynamic children are started and terminated is high.
This is quite a bit of information to absorb. Before going
ahead, let’s review the functional API used to manage dynamic
children. Keep in mind that terminate_child/2,
restart_child/2, and delete_child/2 cannot
be used with simple_one_for_one strategies:
supervisor:start_child(Name,ChildSpecOrArgs)->{ok,Pid}{ok,Pid,Info}{error,already_started|{already_present,Id}|Reason}supervisor:terminate_child(Name,Id)->ok{error,not_found|simple_one_for_one}supervisor:restart_child(Name,Id)->{ok,Pid}{ok,Pid,Info}{error,running|restarting|not_found|simple_one_for_one}supervisor:delete_child(Name,Id)->ok{error,running|restarting|not_found|simple_one_for_one|Reason}
Gluing it all together
Before wrapping up this example, let’s create the top-level
supervisor, bsc_sup, which starts
both the frequency_sup and the
simple_phone_sup functions. We will test the system using the
phone.erl phone test simulator,
which lets us specify the number of phones and the number of calls
each phone should attempt, and then makes random calls, replying to
and rejecting calls. The code for the top-level supervisor is as follows:
-module(bsc_sup).-export([start_link/0,init/1]).-export([stop/0]).start_link()->supervisor:start_link({local,?MODULE},?MODULE,[]).stop()->exit(whereis(?MODULE),shutdown).init(_)->ChildSpecList=[child(freq_overload,worker),child(frequency,worker),child(simple_phone_sup,supervisor)],{ok,{{rest_for_one,2,3600},ChildSpecList}}.child(Module,Type)->{Module,{Module,start_link,[]},permanent,2000,Type,[Module]}.
We pick the rest_for_one strategy because if the phones or the
phone supervisor terminates, we do not want to affect the frequency
allocator and overload handler. But if the frequency allocator or the
overload handler terminates, we want to restart all of the phone FSMs.
We allow a maximum of two restarts per hour, after which we escalate
the problem to whatever is responsible for the bsc_sup supervisor.
Suppose that corrupted data in the frequency server is causing
the phone FSMs to crash. After the simple_phone_sup has terminated three times
within an hour, thus surpassing its maximum restart threshold,
bsc_sup will terminate all of its
children, bringing the frequency server down with it. The restart will
hopefully clear up the problem, allowing the phones to function
normally. We show how this escalation is handled in the upcoming
chapters. Until then, let’s use our phone.erl simulator and test our
supervision structure and phone FSM by starting 150 phones, each
attempting to make 500 calls:
1>bsc_sup:start_link().{ok,<0.35.0>} 2>phone:start_test(150, 500).*DBG* <0.107.0> got {'$gen_sync_all_state_event', {<0.33.0>,#Ref<0.0.4.37>}, {outbound,109}} in state idle <0.107.0> dialing 109 ...<snip>... *DBG* <0.92.0> switched to state idle *DBG* <0.53.0> switched to state idle 3>counters:get_counters(freq_overload).{counters,[{{event,{frequency_denied,<0.38.0>}},27}, {{set_alarm,{no_frequency,<0.38.0>}},6}, {{clear_alarm,no_frequency},6}]}
For the sake of brevity, we’ve cut out all but one of the debug printouts. Having run the test, we retrieve the counters and see that during the trial run, we ran out of available frequencies six times, raising and eventually clearing the alarm accordingly. During these six intervals, 27 phone calls could not be set up as a result. Examining the logs, we can get the timestamps when these calls were rejected. If a pattern emerges, we can use the information to improve the availability of frequencies at various hours.
Before moving on to the next section, if you ran the test just shown on your computer and still have the shell open, try killing the
frequency server three times using exit(whereis(frequency),
kill). You will cause the top-level supervisor to reach its
maximum restart threshold and terminate. Note how, when the phone FSM
detaches itself in the FSM terminate function, you get a badarg error as a result of the hlr ETS tables no longer being present. The
error reports originate in the terminate function if the
supervisor has terminated before the phone FSM, taking the ETS tables
with it. These error reports might shadow more important errors, so it
is always a good idea within a terminate function to
embed calls that might fail within a try-catch and, by default, return
the atom ok.
Non-OTP-Compliant Processes
Child processes linked to an OTP supervision tree have to be OTP behaviors, or follow the behavior principles, and be able to handle and react to OTP system messages. There are, however, times when we want to bypass behaviors and use pure processes, either because of performance reasons or simply as a result of legacy code. We get around this problem by using supervisor bridges, implementing our own behaviors, or having a worker spawn and link itself to regular Erlang processes.
Supervisor bridges
In the mid-1990s, when major projects for the next generation of telecom
infrastructure of that time were started at Ericsson, OTP was being
implemented. The first releases of these systems, while following many
of the design principles, were not OTP-compliant because OTP did not
exist. When OTP R1 was released, we ended up spending more time in
meetings discussing whether we should migrate these systems to OTP
than it would actually have taken to do the job. It is at times
like these, when no progress is made, that the supervisor_bridge behavior comes in
handy.
The supervisor bridge is a behavior that allows you to connect a non-OTP-compliant set of processes to a supervision tree. It behaves like a supervisor toward its supervisor, but interacts with its child processes using predefined start and stop functions. In Figure 8-11, the right-hand side of the supervision tree consists of OTP behaviors, while the left-hand side of the supervision tree connects the non-OTP-compliant processes.
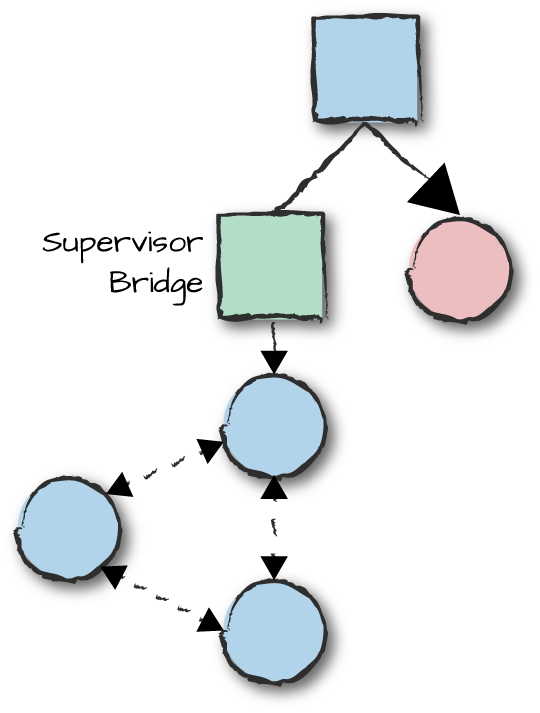
Figure 8-11. Supervisor bridges
Start a supervisor bridge using the supervisor_bridge:start_link/2,3
call, passing the optional NameScope, the callback
Mod, and the Args. This results in
calling the init(Args) callback function,
in which you start your Erlang process subtree, ensuring all processes
are linked to each other. The init/1 callback, if
successful, has to return {ok, Pid, State}. Save the
State and pass it as a second argument to the
terminate/2 callback.
If the Pid process terminates, the supervisor bridge will terminate with the
same reason, causing the terminate/2 callback function to
be invoked. In terminate/2, all calls required to shut down the non-OTP-compliant
processes have to be made. At this point, the supervisor bridge’s
supervisor takes over and manages the restart. If the supervisor
bridge receives a shutdown message from its supervisor,
terminate/2 is also called. While the supervisor bridge
handles all of the debug options in the sys module, the processes it starts and
is connected to have no code upgrade and debug functionality.
Supervision will be limited to what has been implemented in the
subtree.
supervisor_bridge:start_link(NameScope,Mod,Args)->{ok,Pid}|ignore|{error,{already_started,Pid}}Mod:init(Args)->{ok,Pid,State}|ignore|{error,Reason}Mod:terminate(Reason,State)->term()
Adding non-OTP-compliant processes
Remember that supervisors can accept only OTP-compliant
processes as part of their supervision tree. They include workers,
supervisors and supervisor bridges. There is one last group,
however, that can be added: processes that follow a subset of the OTP
design principles, the same ones standard behaviors follow. We call
processes that follow OTP principles but are not part of the standard
behaviors special processes. You
can implement your own special processes by using the proc_lib module to start your processes and handle system messages in
the sys module. With little effort, the sys, debug, and
stats options can be added. Processes implemented following these
principles can be connected to the supervision tree. We cover them in
more detail in Chapter 10.
Scalability and Short-Lived Processes
Typical Erlang design creates one process for each truly concurrent activity in
your system. If your system is a database, you will want to spawn a
process for every query, insert, or delete operation. But don’t get
carried away. Your concurrency model will depend on the resources in
your system, as in practice, you could have only one connection to the
database. This becomes your bottleneck, as it ends up serializing your
requests. In this case, is sending this process a message easier than
spawning a new one? If your system is an instant messaging server, you
will want a process for every inbound and outbound message, status
update, or login and logout operation. We are talking about tens or
possibly hundreds of thousands of simultaneous processes that are
short-lived and reside under the same supervisor. At the time of
writing, supervisors that have a large number of dynamic children
starting and terminating at very short continuous intervals will not
scale well because the supervisor becomes the bottleneck. The
implementation of the simple_one_for_one strategy scales better, as
unlike other supervisor types that store their child specifications in
lists, it uses the dict key-value library module. But
despite this, it will also have its limits. Giving a rule-of-thumb
measure of the rate at which dynamic children can be started and
terminated is hard, because it depends on the underlying hardware, OS,
and cores, as well as the behavior of the processes themselves (including
the amount of data that needs to be copied when spawning a process).
These issues are rare, but if a supervisor message queue starts growing
to thousands of messages, you know you are affected. There are two
approaches to the problem.
The clean approach, shown in Figure 8-12, is to create a pool of supervisors, ensuring that each does not need to cater for more children than it can handle. This is a recommended strategy if the children have to interact with other processes and are often long-lived. The process on the left is the dispatcher, which manages coordination among the supervisors and, if necessary, starts new ones. You can pick a supervisor in the pool using an algorithm that best suits your needs, such as round robin, consistent hashing, or random.
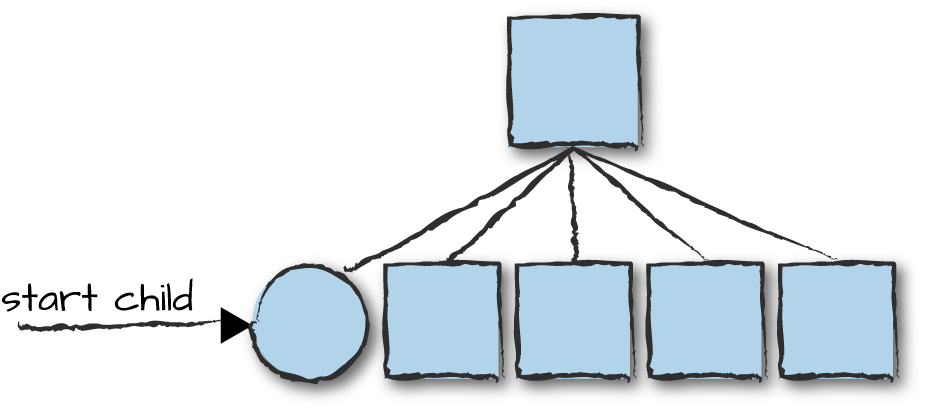
Figure 8-12. Supervisor pools
The second approach taken by many is to have a worker, more often
than not a generic server, that spawn_links a non-OTP-compliant process
for every request (Figure 8-13). You will often find
this strategy in messaging servers, web servers, and databases. This
non-OTP-compliant process usually executes a sequential, synchronous set
of operations and terminates as soon as it has completed its task. This
solution potentially sacrifices OTP principles for speed and
scalability, but it ensures that your process is linked to the behavior
that spawned it; if the process tree shuts down, the linked processes
will also terminate.
Figure 8-13. Linking to a worker
Why link? Don’t forget that your system will run for years without being restarted. You can’t predict what upgrades, new functionality, or even abnormal terminations will occur. The last thing you want is a set of dangling processes you can’t control, left there after the last failed upgrade. Because you link the non-OTP-compliant children to their parent, if the parent terminates, so do the children.
Synchronous Starts for Determinism
Remember that when you start behaviors with either the
start or start_link calls, process creation
and the execution of the init/1 function are synchronous.
The functions return only when the init/1 callback function returns. The
same applies to the supervisor behavior. A crash during the start of any
behavior will cause the supervisor to fail, terminating all the children
it has already started. Because starts are synchronous and if start and
restart times are critical, try to minimize the amount of work done in
the init/1 callback. You need to guarantee that the process
has been restarted and is in a consistent state. If starting up involves
setting up a connection toward a remote node or a database—a connection
that can later fail as a result of a transient error—start setting up
the connection in your init/1 function, but do not wait for
the connection to come up.
A trick you can use to postpone your initialization is to set the
timeout to 0 in your init/1 behavior callback function.
Setting a timeout in this manner results in your callback module
receiving a timeout message immediately after
init/1 returns, allowing you to asynchronously continue
initializing your behavior. This could involve waiting for node or
database connections or any other noncritical parts over which your
init/1 function does not provide guarantees. A more general
alternative to a timeout is for init/1 to send a suitable
asynchronous message to self(), which is handled after
init/1 returns, in order to asynchronously proceed with
initialization.
Why are synchronous starts important? Imagine first spawning all
your child processes asynchronously and then checking that they have all
started correctly. If something goes wrong at startup, the issue might
have been caused by the order in which processes were started or the
order the expressions in their respective init callbacks
were executed. Recreating the race condition that resulted in the
startup error might not be trivial. Your other option is to start a
process, allow it to initialize, and start the next one only when the
init function returns. This will give you the ability to
reproduce the sequence that led to a startup error without having to
worry about race conditions. Incidentally, this is the way we do it when
using OTP, where the combination of applications (covered in Chapter 9), supervisors, and the synchronous
startup sequence together provide a “simple core” that guarantees a
solid base for the rest your system.
Testing Your Supervision Strategy
In this chapter, we’ve explained how to architect your supervision tree, group and start processes based on dependencies, and ensure that you have picked the right restart strategy. These tasks should not be overlooked or underestimated. Although you are encouraged to avoid defensive programming and let your behavior terminate if something unexpected happens, you need to make sure that you have isolated the error and are able to recover from this exception. You might have missed dependencies, picked the wrong restart strategy, or set your allowed number of restarts too high (or low) in a possibly incorrect time interval. How to you test these scenarios and detect these design anomalies?
All correctly written test specifications for Erlang systems will contain negative test cases where recovery scenarios and supervision strategies have to be validated by simulating abnormal terminations. You need to ensure that the system is not only able to start, but also to restart and self-heal when something unexpected happens.
In our first test system, exit(Pid, Reason) was used
to kill specific processes and validate the recovery scenarios. In later
years, we used Chaos Monkey, an
open source tool that randomly kills processes, simulating abnormal
errors. Try it while stress testing your system, complementing it with
fault injections where hardware and network failures are being
simulated. If your system comes out of it alive, it is on track to
becoming production-ready.
Don’t Tell the World You Are Killing Children!
While working on the R1 release of OTP, a group of us left the office and took the commuter train into Stockholm. We were talking about the ease of killing children, children dying, and us not having to worry about it, as supervisors would trap exits and restart them. We were very excited and vocal about this, as it was at the time a novel approach to software development, and one we were learning about as we went along. We were all so engrossed in this conversation that we failed notice the expressions of horror on the faces of some elderly ladies sitting next to us. I have never seen an expression of alarm turn so quickly into an expression of relief as when we finally got off the train. Pro Tip: when in public, talk about behaviors, not children, and do not kill them—terminate them instead. It will help you make friends, and you won’t risk having to explain yourself to a law enforcement officer who probably has no sense of humor.
How Does This Compare?
How does the approach of nondefensive programming, letting supervisors handle errors, compare to conventional programming languages? The urban legend among us Erlang programmers boasted of less code and faster time to market. But the numbers we quoted were based on gut feelings or studies that were not public. The very first study, in fact, came from Ericsson, where a sizable number of features in the MD110 corporate switch were rewritten from PLEX (a proprietary language used at the time) to Erlang. The result was a tenfold decrease in code volume. Worried that no one would believe this result, the official stance was that you could implement the same features with four times less code. Four was picked because it was big enough to be impressive, but small enough not to be challenged. We finally got a formal answer when Heriot-Watt University in Scotland ran a study focused on rewriting C++ production systems to Erlang/OTP. One of the systems was Motorola’s Data Mobility (DM), a system handling digital communication streams for two-way radio systems used by emergency services. The DM had been implemented in C++ with fault tolerance and reliability in mind. It was rewritten in Erlang using different approaches, allowing the various versions to be compared and contrasted.
Many academic papers and talks have been written on this piece of research. One of the interesting discoveries was an 85% reduction in code in one of the Erlang implementations. This was in part explained by noting that 27% of the C++ code consisted of error handling and defensive programming. The counterpart in Erlang, if you assumed OTP to be part of the language libraries, was a mere 1%!
Just by using supervisors and the fault tolerance built into OTP behaviors, you get a code reduction of 26% compared to other conventional languages. Remove the 11% of the C++ code that consists of memory management, remove another 23% consisting of high-level communication—all features that are part of the Erlang semantics or part of OTP—and include declarative semantics and pattern matching, and you can easily understand how an 85% code reduction becomes possible. Read one or two of the papers2 and have a look at the recordings of the presentations available online if you want to learn more about this study.
Summing Up
Building on previous chapters that covered OTP worker processes, this chapter explained how to group them together in supervision trees. We have looked at dependencies and recovery strategies, and how they allow you to handle and isolate failures generically. The bottom line is for you not to try to handle software bugs or corrupt data in your code. Focus on the positive cases and, in the case of unexpected ones, let your process terminate and have someone else deal with the problem. This strategy is what we refer to as fail safe.
In Table 8-2 we list the functions exported by the supervisor and supervisor bridge behaviors, together with their respective callback functions. You can read more about them in their respective manual pages.
| Supervisor function or action | Supervisor callback function |
|---|---|
supervisor:start_link/2, supervisor:start_link/3 | Module:init/1 |
supervisor_bridge:start_link/2,
supervisor_bridge:start_link/3 | Module:init/1, Module:terminate/2 |
Before reading on, you should also read through the code of the examples provided in this chapter and look for examples of supervisor implementations online. Doing so will help you understand how to design your system while keeping fault tolerance and recovery in mind.
What’s Next?
In the next chapter, we cover how to package supervision trees into a behavior called an application. Applications contain supervision trees and provide operations to start and stop them. They are seen as the basic building blocks of Erlang systems. In Chapter 11, we look at how we group applications into a release, giving us an Erlang node.
1 If you are someone who reads footnotes, good for you, as you can now consider yourself warned that this is a trick question.
2 The most comprehensive being Nyström, J. H., Trinder, P. W., and King, D. J. (2008), “High-level distribution for the rapid production of robust telecoms software: Comparing C++ and ERLANG,” Concurrency Computat.: Pract. Exper, 20: 941–968. doi: 10.1002/cpe.1223.