
Chapter 11
Mixed-effects multinomial logit model for nominal outcomes
Abstract
In this chapter, I first provide an overview of the classical multinomial logit regression model, and then specify the mixed-effects multinomial logit model. Next, a retransformation method is introduced that derives unbiased nonlinear predictions of the response probabilities by using analytic results of the mixed-effects multinomial logit model. The method is designed to retransform two random components, the between-subjects random effects and the within-subject random disturbances. The delta method is applied to compute the standard errors of the predicted probabilities based on the approximate variance-covariance matrix for a mean multinomial logit function. As it is difficult to interpret the regression coefficients of covariates in the multinomial logit model, the conditional effects are created on a set of predicted probabilities to aid in the interpretation of the analytic results. An empirical illustration is provided to display the application of the mixed-effects multinomial logit model in the analysis of longitudinal data taking three or more discrete levels.
Keywords
Empirical Bayes method
Fisher information matrix
growth trajectories
mixed-effects multinomial logit model
random components
score function
In longitudinal data analysis, researchers often encounter response outcomes characterized with three or more ordinal or nominal categories. The mixed-effects multinomial logit model is perhaps the most appropriate statistical perspective for analyzing such data by accounting for the potential lack of independence in longitudinal outcome data (Hedeker and Gibbons, 2006; Liu and Engel, 2012). As a basic feature underlying GLMMs, the random components in the mixed-effects multinomial logit model are conventionally viewed as multivariate normal with mean 0 and variance–covariance matrix V. In using parameter estimates to describe longitudinal trajectories of a set of probabilities, the usual application is to retransform the multinomial logit parameter estimates – the fixed effects and the between-subjects random effects – to predict the probabilities of a multinomial response without taking within-subject random errors into consideration. As in the analysis of binary longitudinal data, this specification perhaps arises from a widely held belief that because the between-subjects random effects primarily reflect individual differences in the multinomial response given specified model parameters, the specification of within-subjects variability is unnecessary.
A closer look at this classical predicting approach suggests caution in accepting the rationale for this computation. For the mixed-effects multinomial logit model, both the between-subjects random effects and the within-subject random errors need to be considered in the retransformation process; otherwise, the predicted probabilities of a multinomial response at each time point can be misspecified, resulting in severe prediction bias in nonlinear predictions. As indicated in Chapter 8, when one retransforms a transformed linear function to predict the response at the untransformed scale, normality of the random components in the linear predictor must be retransformed as well to a nonnormal distribution. Consequently, the expectation of the posterior predictive distribution for the random components, after retransformation, is often not unity but some other quantity (Liu, 2012; Zeger et al., 1988). Even if the true values of model parameters are known, analytic results from a well-specified mixed-effects multinomial logit model cannot convert to unbiased nonlinear predictions without retransforming all the variance and covariance components. In Chapter 10, this retransformation issue was discussed and empirically displayed in the context of the mixed-effects binary logit model. In this chapter, the discussion about retransformation bias in nonlinear predictions is extended to the case of the multinomial response.
I first provide an overview of the general multinomial logit regression and then present the detailed specifications of the mixed-effects multinomial logit model. Next, a retransformation method is developed that derives unbiased nonlinear predictions of the response probabilities by using analytic results of the mixed-effects multinomial logit model. The method is designed to retransform two random components: the between-subjects random effects and the within-subject random errors. The delta method is applied to compute the standard errors of the predicted probabilities based on the approximate variance–covariance matrix for a mean multinomial logit function. As it is difficult to interpret the regression coefficients of covariates in the multinomial logit model (Greene, 2003; Liu et al., 1995), the conditional effects of a given covariate are created on a set of predicted probabilities to aid in the interpretation of the analytic results. Lastly, an empirical illustration is provided to display the application of the mixed-effects multinomial logit model in the analysis of longitudinal data taking three or more discrete levels.
11.1. Overview of multinomial logistic regression model
Suppose that we have a sample of N cases observed at a single time occasion. Let Yi be an underlying response variable taking (K + 1) values for subject i in the sample. A general multinomial logit model implies a combination of linear specifications on K log odds, using the (K + 1)th category as the reference level. Let Pik represent Pr(Yi = k where k = 1, 2, ..., K) and Pi(K+1) be Pr(Yi = K + 1). It follows then that a typical multinomial logit function with covariate vector Xi is given by
Log(PikPi(K+1))=X′iβk, k=1,...,K,
 (11.1)
(11.1)where Xi is the M × 1 covariate vector with the first element being one and βk is the M × 1 vector of unknown regression parameters with the first element being the intercept. This model is widely applied in econometrics to analyze the probabilities of product or occupational choices.
The inverse of the multinomial logit function with covariate vector Xi specifies the probability of falling in the kth level for subject i, where k = 1, …, K, given by
Pik=Pr(Yi=k|Xi)=[1+∑Kl=1exp(X′iβl)]−1exp(X′iβk).
 (11.2)
(11.2)The probability Pi(K+1) is the reference or the residual probability given the constraint that a set of choice probabilities must sum up to unity. Formally, the reference probability can be written as
Pi(K+1)=Pr(Yi=K+1|Xi)=[1+∑Kl=1exp(X′iβl)]−1.
 (11.3)
(11.3)The likelihood function for the multinomial logit regression model can be expressed in terms of a joint probability, given by
L=∏Ni=1(Pi1)Yi1Pi2Yi2...[Pi(K+1)]Yi(K+1),
 (11.4)
(11.4)where Yik is 1 if the ith observation makes the kth choice and is 0 if otherwise, and Pik, where k = 1, …, K + 1 is defined by Equation (11.2) or Equation (11.3).
Taking log values on both sides of Equation (11.4) leads to the following log-likelihood function
l=∑Ni=1∑K+1k=1 Yik log(Pik).
 (11.5)
(11.5)Maximizing Equation (11.5) requires that this log-likelihood function be differentiated with respect to β using the standard procedures described in Chapter 8. In the construct of the multinomial logit regression model, the score statistic, mathematically defined as the first partial derivative of the log-likelihood function with respect to β and denoted by ˜U(β) , is
, is
˜U(β)=∂l∂β=∑Ni=1∑K+1k=1YikPik∂Pik∂β=∑Ni=1∑K+1k=1Yik[Xik−E(Xi)],
 (11.6)
(11.6)where
E(Xi)=[1+∑Kl=1exp(X′iβl)]−1[1+∑Kl=1exp(X′iβl)]Xi.

It is interesting to note that the score statistic in the multinomial logit model can be conveniently simplified as a permutation test based on residuals computed for the regression on covariates, rather than on the regression coefficients themselves, as is also the case in statistical inference of other generalized linear models.
The second partial derivative of the log-likelihood is
∂2l∂β∂β′=∑Ni=1∑K+1k=1YikPik[∂2Pik∂β∂β′−1Pik∂Pik∂β∂Pik∂β′]=−∑Ni=1∑K+1k=1Pik[Xik−E(Xi)] [Xik−E(Xi)]′.
 (11.7)
(11.7)As defined, the negative of the expectation of the second derivatives with respect to β of the log-likelihood function is the Fisher information, denoted by I(β). Given the expectation of the score to be zero, the Fisher information matrix yields the estimated variances and covariances of ˜U(β).
Also generalized in Chapter 8, the parameter vector β can be efficiently estimated by solving the equation
˜U(β)=∂ l∂β=0.
 (11.8)
(11.8)The previous procedure is the formalization of the maximum likelihood estimator in GLM given the link function specified as the multinomial logit. For a large sample, ˆβ is the unique solution of ˜U(β)=0
is the unique solution of ˜U(β)=0 , and therefore, ˆβ is consistent for β and distributed as multivariate normal, denoted by
, and therefore, ˆβ is consistent for β and distributed as multivariate normal, denoted by
ˆβ∼N[0,ˆI(β)−1],
where ˆI(β) is the observed Fisher information matrix
is the observed Fisher information matrix
I(ˆβ)=−(∂2l(ˆβ)∂ˆβ∂ˆβ′).

Given the previous specifications, the score, the Wald, and the likelihood-ratio test statistics can be readily formulated, as presented in Chapter 8. For more details about the statistical inference of the multinomial logit model, the interested reader is referred to Amemiya (1985), Greene (2003), Long (1997), and Maddala (1983).
The previous equations do not specify a random component as the residual term is simply integrated out in the estimation of a general multinomial logit model. Such a modeling approach is based on the so-called independence from irrelevant alternatives (IIA) hypothesis (Amemiya, 1985; McFadden, 1974). This fixed-effects specification can usher in some specification problems given the multivariate nature of a multinomial response. In view of the constraint that a set of choice probabilities always sum up to unity, an increase in one probability implies corresponding variations in one or more of the others, thereby implying dependence in a set of log odds. The invalid hypothesis of independence in random errors does not necessarily result in biased regression coefficients given the statistical property that the asymptotic process √n(ˆβ−β0) , where β0
, where β0 is the true parameter vector, tends to converge in probability to a normal vector with mean 0 and the covariance matrix I−1(ˆβ,t)
is the true parameter vector, tends to converge in probability to a normal vector with mean 0 and the covariance matrix I−1(ˆβ,t) for large samples. When used to predict marginalized probabilities, however, this fixed-effects logit perspective on the multinomial data does not yield robust and consistent estimators, as will be shown in the succeeding texts.
for large samples. When used to predict marginalized probabilities, however, this fixed-effects logit perspective on the multinomial data does not yield robust and consistent estimators, as will be shown in the succeeding texts.
11.2. Mixed-effects multinomial logit models and nonlinear predictions
Methodologically, the mixed-effects multinomial logit model is simply an extension of the classical, fixed-effects perspective by adding up the random components in statistical inference. Given the normality assumption on the random effects in the multinomial logit model, exponentiation of the random components yields a set of lognormally distributed random parameters, with the means and the variances being well defined.
Let Yij denote the value of an ordinal or a nominal categorical variable with (K + 1) levels (for e.g., a health state) for subject i at time point j. For illustrative simplicity and analytic convenience without loss of generality, a random intercept multinomial logit model is specified first. Conventionally, adding the scalar between-subjects random effects to the fixed-effects multinomial logit model, the probability that Yij = k (k = 1, …, K) for person i at time point j is given by
Pijk=Pr(Yij=k|Xij)=[1+∑Kl=1exp(X′ijβl+bil)]−1exp(X′ijβk+bik) =[1+∑Kl=1exp(X′ijβl)exp(bil)]−1exp(X′ijβk)exp(bik),
 (11.10)
(11.10)where Xij is the M × 1 covariate vector for subject i at time point j, including, in the context of longitudinal analysis, a time variable or a set of time polynomials. Likewise, βk is the M × 1 vector of unknown regression parameters to be estimated, and bik is the between-subjects random effect on the kth logit component, assumed to be distributed as N(0,σ2bk) . The probability Pij(K+1) is the reference or residual probability, as indicated earlier.
. The probability Pij(K+1) is the reference or residual probability, as indicated earlier.
Equation (11.10) does not specify a term for within-subjects random errors. The underlying rationale is indicated earlier; that is, specification of the between-subjects random effects accounts for individual differences in unspecified characteristics, thereby addressing within-subject variability (Diggle et al., 2002; Littell et al., 2006; Molenberghs and Verbeke, 2010). The BLUP on nonlinear longitudinal data, described in Chapter 8 and applied in Chapter 10, is primarily based on this specification (Fitzmaurice et al., 2004; Littell et al., 2006). In certain situations, Equation (11.10) does not necessarily reflect the true experiences generated by the stochastic longitudinal process because within-subject variability can sometimes have a unique impact on a multinomial response, even conditionally on the between-subjects random effects (Hedeker and Gibbons, 2006; Liu and Engel, 2012).
If within-subject variability, assumed to be independent of Xij and bik, is considered, the specification of Pij = k (k = 1, …, K) for person i at time point j becomes
Pijk=Pr(Yij=k|Xij)=[1+∑Kl=1exp(X′ijβl+bil+ɛijl)]−1exp(X′ijβk+bik+ɛijk)=[1+∑Kl=1exp(X′ijβl)exp(bil+ɛijl)]−1exp(X′ijβk)exp(bik+ɛijk),
 (11.11)
(11.11)where ɛijk is the within-subject random disturbance distributed as N(0,σ2ɛijk)
is the within-subject random disturbance distributed as N(0,σ2ɛijk) .
.
Equation (11.11) can be conveniently transformed into a combination of linear specifications for K log odds. With the (K + 1)th level serving as the reference, the inverse of Equation (11.11) for level k is
log(PijkPij(K+1))=X′ijβk+bik+ɛijk, where k=1,...,K.
 (11.12)
(11.12)Because an individual’s probability is not empirically observable at a specific time point, the inherent within-subject variability is not directly obtainable in the observed multinomial response. The fixed-effects multinomial logit model assumes the random errors to be embedded in the fixed effects, thereby evading the specification of a random term for uncertainty (Amemiya, 1985; Greene, 2003; McFadden, 1974). Within the longitudinal setting, the specification of the random components is inescapable because there are two sources of the random components and one of them, the between-subjects, is observable and estimable. Ignoring the presence of the random components implies that repeated measurements of the response for the same subject are conditionally independent given the specified fixed effects, an invalid hypothesis in longitudinal data analysis also indicated in Chapter 10 (Diggle et al., 2002; Fitzmaurice et al., 2004; McCulloch et al., 2008; Molenberghs and Verbeke, 2010; Zeger et al., 1988).
As indicated in Chapter 8, some researchers recommend the application of the latent variable approach (Amemiya, 1985; Bock, 1975; Long, 1997) to estimate the within-subject random errors in the application of GLMMs (Hedeker and Gibbons, 2006). This approximation is particularly invalid for the mixed-effects multinomial logit model. First, the standardized approach specifies a constant variance of within-subject random errors, regardless of the response type and the number of covariates considered in a particular model. Second, when the between-subjects random effects are specified, not that much variability remains in the multinomial response (Littell et al., 2006). Third, this approach does not specify covariance between two related logit components, therefore overlooking the multivariate nature of the multinomial logit function.
Statistically, within-subject random errors can be approximated by using the score equation, which is the first partial derivative of the log-likelihood in the estimation of a mean multinomial logit function. In this inference, the approximation approach for the mixed-effects binary logit model, described in Chapter 10, can be extended to the context of the mixed-effects multinomial logit model. If all covariates are rescaled to be centered at some selected values, represented by X0, the logit intercepts correspond to a mean multinomial logit function with respect to X0, with K logit components. For example, if time T is centered at five and other covariates are rescaled to be centered at sample means, the intercepts in the mixed-effects multinomial logit model predict the mean logits for an average person or the corresponding population group at time five. Accordingly, the score function approximates the within-subject residuals for this mean multinomial function conditionally on the specified random effects and the covariates. Consequently, the variance and covariance estimates of within-subject random errors can be approximated by the local subset of the intercepts in the variance–covariance matrix for the fixed effects.
Given the approximates of σ2ɛijk , the probability that Yij = k (k = 1, …, K) for person i at time point j can be predicted by retransforming the linear predictor specified in Equation (11.12), given by
, the probability that Yij = k (k = 1, …, K) for person i at time point j can be predicted by retransforming the linear predictor specified in Equation (11.12), given by
ˆPijk=[1+∑Kl=1exp(X′ijˆβl)ˆΦijl]−1exp(X′ijˆβk)ˆΦijk, for k=1,...,K; l=1,...,K,
 (11.13)
(11.13)where ˆΦijk=exp(bik+ɛijk) is the estimated multiplicative random effect variable for subject i at time point j on response level k (k = 1, …, K). Given the definition of a lognormal distribution, the expectation of the posterior predictive distribution for the random variable is
is the estimated multiplicative random effect variable for subject i at time point j on response level k (k = 1, …, K). Given the definition of a lognormal distribution, the expectation of the posterior predictive distribution for the random variable is
E(Φijk|bik)=exp(σ2bik+σ2ɛijk2),

and variance
var(Φijk|bik)=exp[2(σ2bik+σ2ɛijk)−exp(σ2bik+σ2ɛijk)].

In the literature of statistics and econometrics, Equation (11.13) is defined as the inverse link function of the mixed-effects multinomial logit model, with the random components parameterized by two variance terms. The positive skewness of the lognormal distribution mandates that the expectation of Φijk is greater than unity, with equality holding if and only if σ2bik=σ2ɛijk=0 . Obviously, as is the case in the mixed-effects binary logit model, only using the fixed effects does not yield an unbiased prediction of a given probability marginalized at Xij, even if the true value of β is known. Conditionally on βk, the vectors of variances for the between-subjects effects and for the within-subject random errors with K levels, written as Vi(O) and Vij(E), respectively, contain values {σ2bi1,...,σ2biK}′
. Obviously, as is the case in the mixed-effects binary logit model, only using the fixed effects does not yield an unbiased prediction of a given probability marginalized at Xij, even if the true value of β is known. Conditionally on βk, the vectors of variances for the between-subjects effects and for the within-subject random errors with K levels, written as Vi(O) and Vij(E), respectively, contain values {σ2bi1,...,σ2biK}′ and {σ2ɛij1,...,σ2ɛijK}′
and {σ2ɛij1,...,σ2ɛijK}′ , with the latter varying over different time points. The relative size of {σ2bi1,...,σ2biK}′
, with the latter varying over different time points. The relative size of {σ2bi1,...,σ2biK}′ determines whether within-subjects random errors can be left unspecified in the prediction of K + 1 probabilities at a series of time points. As σ2ɛijk depends on the mean logit given the specification of the variance function, the variance of the joint random variable is not constant across time points, even with the specification of CS for the covariance structure of the between-subjects random effects.
determines whether within-subjects random errors can be left unspecified in the prediction of K + 1 probabilities at a series of time points. As σ2ɛijk depends on the mean logit given the specification of the variance function, the variance of the joint random variable is not constant across time points, even with the specification of CS for the covariance structure of the between-subjects random effects.
and {σ2ɛij1,...,σ2ɛijK}′, with the latter varying over different time points. The relative size of {σ2bi1,...,σ2biK}′If the effect of one or more covariates, like the time factor, is considered random across subjects, the random coefficient multinomial logit model needs to be specified by extending the random intercept multinomial logit regression. Given the specification of random coefficients, the mixed-effects multinomial logit model can be written as
Pijk=Pr(Yij=k|Xij)=[1+∑Kl=1exp(X′ijβl+Z′ijbil+ɛijl)]−1exp(X′ijβk+Z′ijbik+ɛijk)=[1+∑Kl=1exp(X′ijβl)exp(Z′ijbil+ɛijl)]−1exp(X′ijβk)exp(Z′ijbik+ɛijk),
 (11.14)
(11.14)where Zij is a design matrix for bik. Equation (11.14) has the properties that E(bik) = 0, cov(bik) = Gk, and cov(bik, ɛijk) = 0. The multiplicative random variable for subject i on response level k (k = 1, …, K) has the expectation
E(Φijk|bik)=exp(ZijGkZ′ij+σ2ɛijk2),
 (11.15)
(11.15)and variance
var(Φijk|bik)=exp[2(ZijGkZ′ij+σ2ɛijk)−exp(ZijGkZ′ij+σ2ɛijk)].
As in the mixed-effects binary logit model, the random intercept multinomial logit regression can be regarded as a special case of the random coefficient multinomial logit model, with Zij and bik each containing only one element.
Given multiple modes in Y and the complexity of the multinomial logit regression, the use of the random coefficient multinomial logit regression can sometimes encounter technical problems in practice. First, given the multivariate nature of a multinomial distribution, specification of a random coefficient regression further complicates the statistical inference, with the variance–covariance structure expanding to a block matrix. As a result, numeric problems routinely arise in the application of the random coefficient multinomial logit model. Second, although the random intercept regression model specifies a CS covariance structure across time points, the value of the score function, in lieu of the within-subjects random error, relies on the mean logit, thereby being time-dependent. Therefore, specifying both variance components as time-varying functions is often unnecessary in the application of the mixed-effects multinomial logit model.
If ˆΦijk and Xij are replaced with E(Φijk)
and Xij are replaced with E(Φijk) and X0, respectively, Equation (11.13) predicts the marginal probability for a group of subjects with covariates valued at X0, with individual probabilities within the group randomly scattered around the marginalized probability. The relationship between the subject-specific and the marginal probabilities has been well documented in the literature of nonlinear longitudinal data analysis (Diggle et al., 2002; Molenberghs and Verbeke, 2010) and is discussed in Chapter 10. Because the expected value of ˆΦijk is greater than unity, it is inappropriate to overlook this retransformed random variable in a prediction of a marginal probability unless σ2bik=σ2ɛijk=0
and X0, respectively, Equation (11.13) predicts the marginal probability for a group of subjects with covariates valued at X0, with individual probabilities within the group randomly scattered around the marginalized probability. The relationship between the subject-specific and the marginal probabilities has been well documented in the literature of nonlinear longitudinal data analysis (Diggle et al., 2002; Molenberghs and Verbeke, 2010) and is discussed in Chapter 10. Because the expected value of ˆΦijk is greater than unity, it is inappropriate to overlook this retransformed random variable in a prediction of a marginal probability unless σ2bik=σ2ɛijk=0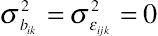 (Molenberghs and Verbeke, 2010). The specification of the marginal probability function based on the conditional perspective is useful for the derivation of interpretable results, nonlinear predictions, and demonstration of longitudinal trajectories of the response probabilities in the application of the mixed-effects multinomial logit model, as will be displayed later in the chapter.
(Molenberghs and Verbeke, 2010). The specification of the marginal probability function based on the conditional perspective is useful for the derivation of interpretable results, nonlinear predictions, and demonstration of longitudinal trajectories of the response probabilities in the application of the mixed-effects multinomial logit model, as will be displayed later in the chapter.
11.3. Estimation of fixed and random effects
Let θ be the vector of parameters with elements β and V(O) . Then, for subject i, the likelihood function in the mixed-effects multinomial logit model can be written as a joint probability, given by
. Then, for subject i, the likelihood function in the mixed-effects multinomial logit model can be written as a joint probability, given by
L(Yi|θ)=∏nij=1∏K+1k=1(Pijk)Yijk,
 (11.17)
(11.17)where Yik is 1 if the ith observation falls in response level k at time point j and is 0 if otherwise, and Yi is the ni × 1 response vector for subject i containing elements Yik. For k = 1, …, K, Pijk is defined by Equation (11.11) or Equation (11.14), depending on the specification of the between-subjects random effects, random intercept, or random coefficient. The estimation of Pk+1 relies on the estimates of other probabilities in the same set, given by ˆPK+1=1−ˆP1−...−ˆPK .
.
Taking log values on both sides of Equation (11.17) gives rise to
l(Yi|θ)=∑nij=1∑K+1k=1 Yijklog(Pijk).
 (11.18)
(11.18)Maximizing the previously mentioned function over all individuals requires that this log-likelihood function be differentiated with respect to β and the random term V(O). With the specification of the between-subjects random effects in θ, the estimation of the specified parameters on the multinomial response data can be performed with integration over the random-effects, as described generally in Chapter 8.
Let g be the logit link function and g−1 be its inverse function. Based on Bayesian inference, the expectation of Pijk in Equation (11.13) can be expressed as
E(Pijk|θ)=∫g−1[X′ijβk+log(Φijk)] dF (Φij),
where the error distributional function F is the cumulative density function, and Φij is a vector of multiplicative random variables containing elements {Φij1,...,ΦijK}′
is a vector of multiplicative random variables containing elements {Φij1,...,ΦijK}′ . In this integration, the differential term is written as dF(Φij) instead of dF(Φijk) because the prediction of the probability Pijk involves all logit components. The term Vi(e) is not particularly specified in θ because within-subject random errors are considered to be embedded in the fixed effects in the multinomial logit regression model, thereby being integrated out (Amemiya, 1985; Zeger et al., 1988). If both σ2bik
. In this integration, the differential term is written as dF(Φij) instead of dF(Φijk) because the prediction of the probability Pijk involves all logit components. The term Vi(e) is not particularly specified in θ because within-subject random errors are considered to be embedded in the fixed effects in the multinomial logit regression model, thereby being integrated out (Amemiya, 1985; Zeger et al., 1988). If both σ2bik and σ2ɛijk are sizable, the predicted probability ˆPijk
and σ2ɛijk are sizable, the predicted probability ˆPijk can deviate markedly from the estimator g−1(X′ijˆβk)
can deviate markedly from the estimator g−1(X′ijˆβk) . Because F is not a cumulative normal function, ˆPijk
. Because F is not a cumulative normal function, ˆPijk is often not g−1(X′ijˆβk), thereby indicating the importance of retransforming the random components in the mixed-effects multinomial logit model. Whether E(Pijk|θ)>g−1(X′ijˆβk)
is often not g−1(X′ijˆβk), thereby indicating the importance of retransforming the random components in the mixed-effects multinomial logit model. Whether E(Pijk|θ)>g−1(X′ijˆβk)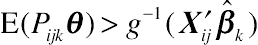 or E(Pijk|θ)<g−1(X′ijˆβk)
or E(Pijk|θ)<g−1(X′ijˆβk) depends on the relative size of Φijk in Φij.
depends on the relative size of Φijk in Φij.
. In this integration, the differential term is written as dF(Φij) instead of dF(Φijk) because the prediction of the probability Pijk involves all logit components. The term Vi(e) is not particularly specified in θ because within-subject random errors are considered to be embedded in the fixed effects in the multinomial logit regression model, thereby being integrated out (Amemiya, 1985; Zeger et al., 1988). If both σ2bikLet N be the total number of subjects in a random sample at baseline. The maximum likelihood (ML) estimates of θ can then be obtained by solving the following equation:
∂ l∂ θ=∑Ni=1g−1(Yi)[∂ g(Yi)∂ θ]=0.
 (11.20)
(11.20)As defined, the first partial derivatives of the log-likelihood are the score function.
As a standard step of the NR algorithm, the negative of the expected second partial derivative of the log-likelihood yields the Fisher information matrix, denoted I(θ) and defined, in the construct of the mixed-effects multinomial logit model, as
I(θ)=E(−∂2 l∂ θ∂ θ′)=∑Ni=1g−2(Yi)∂ g(Yi)∂ θ[∂ g(Y)∂ θ]′.
 (11.21)
(11.21)According to large-sample theory, the inverse of the observed information matrix approximates the variance–covariance matrix for the specified parameter estimates in the multinomial logit model, from which the variance of the within-subject random errors can be approximated and evaluated by using the mean logit function approach. It follows that hypothesis testing on linear combinations of the model parameters can be performed by computing the generalized Wald statistic, distributed approximately as chi-square under the null hypothesis that β = 0 and V(O) = 0 (Hedeker and Gibbons, 2006).
As indicated in Chapter 8, there are a variety of approximation approaches for GLMMs proposed to derive Bayes-type estimators of θ given F (Breslow and Clayton, 1993; Breslow and Lin, 1995; Goldstein et al., 1998; Hedeker and Gibbons, 2006; McCulloch et al., 2008; Pinheiro and Bates, 1995; Stiratelli et al., 1984; Zeger and Karim, 1991). In approximating the integral of the likelihood over the random effects, Gaussian quadrature is regarded as advantageous over the penalized quasi-likelihood (PQL), marginal quasi-likelihood (MQL), and other approximation methods for deriving robust estimates of the random effects and the goodness-of-fit statistics (Molenberghs and Verbeke, 2010; SAS, 2012), as indicated in Chapters 8 and 10. A multiple-point Gaussian quadrature rule provides an approximation of the definite integral of a distributional function, usually stated as a weighted sum of functional values at specified points within the domain of integration. When the mixed-effects multinomial logit model includes a large number of random effect terms, however, numeric integration methods can be inaccurate. In these situations, the application of the simulation-based techniques, such as the Markov Chain Monte Carlo approach (MCMC, described in Chapter 8), may be more appropriate (McCulloch et al., 2008).
11.4. Approximation of variance–covariance matrix on probabilities
In predicting longitudinal trajectories of a set of response probabilities, the standard errors of nonlinear predictions should be approximated for evaluating the quality of the predicted values. As in the case of the mixed-effects binary logit model, the delta method can be applied to approximate the standard errors of the predicted probabilities (Diggle et al., 2002; Littell et al., 2006; Liu and Engel, 2012; Molenberghs and Verbeke, 2010; SAS, 2012).
Let ˆL be a random vector of the predicted logit components (ˆL=ˆL1,ˆL2,...,ˆLK)′
be a random vector of the predicted logit components (ˆL=ˆL1,ˆL2,...,ˆLK)′ from Equation (11.12) with mean η and variance–covariance matrix V(ˆL)
from Equation (11.12) with mean η and variance–covariance matrix V(ˆL) , and ˆP=g−1(ˆL)
, and ˆP=g−1(ˆL) is a transform of ˆL, as defined by Equation (11.13), where g is the logit link function and g−1 is its inverse function. For large samples, the first-order Taylor series expansion of g−1(ˆL)
is a transform of ˆL, as defined by Equation (11.13), where g is the logit link function and g−1 is its inverse function. For large samples, the first-order Taylor series expansion of g−1(ˆL) yields approximation of mean
yields approximation of mean
E[g−1(ˆL)]≈g−1(η),
and the variance–covariance matrix ˆV(ˆP)
V[g−1(ˆL)]≈[∂ g−1(ˆL)∂ ˆL|ˆL=η]′Σ(ˆL)[∂g−1(ˆL)∂ˆL|ˆL=η],
 (11.23)
(11.23)where
∂ g−1(ˆL)∂ ˆL=[∂g−11(ˆL)∂ˆL,∂g−12(ˆL)∂ˆL,...],

and
Σ(ˆL)=(var(ˆL1) cov(ˆL1,ˆL2) ⋅⋅⋅ cov(ˆL1,ˆLK) var(ˆL2) ⋅⋅⋅ cov(ˆL2,ˆLK) ⋱ var(ˆLK)).

In Equation (11.23), the matrix V[g−1(ˆL)] is the approximate of the variance–covariance matrix V(P) for large samples. The square roots of the diagonal elements in this variance–covariance matrix yield the standard errors of the predicted probabilities contained in the vector ˆP
is the approximate of the variance–covariance matrix V(P) for large samples. The square roots of the diagonal elements in this variance–covariance matrix yield the standard errors of the predicted probabilities contained in the vector ˆP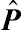 given ˆβ and ˆV(ˆO)
given ˆβ and ˆV(ˆO) . As a result, the confidence interval for the predicted probability ˆPijk can be easily computed.
. As a result, the confidence interval for the predicted probability ˆPijk can be easily computed.
is the approximate of the variance–covariance matrix V(P) for large samples. The square roots of the diagonal elements in this variance–covariance matrix yield the standard errors of the predicted probabilities contained in the vector ˆPThe delta method depends on the validity of the Taylor series approximation, and therefore, some caution must be exercised before its adequacy is verified with simulation. In the context of the multinomial logit model, the application of the Taylor series expansion is well justified to approximate P and V(P) because g−1(ˆL) is a smooth nonlinear function of ˆL. Consequently, the previous procedure usually provides a robust, one-on-one standard error estimator (Stuart and Ord, 1994). As indicated in Chapter 8, bootstrapping is sometimes applied to estimate the standard errors of nonlinear predictions. The bootstrap procedure, however, generates less efficient, robust approximates than a retransformation approach with known elements in Σ(ˆL) for the mixed-effects multinomial logit model because it is based on the assumption that the off-diagonal elements in V(ˆL) are all zero (Follmann, 1994). If the elements in V(ˆL) are unobtainable empirically, some covariance structure in the multinomial distribution needs to be assumed for the application of the bootstrap.
for the mixed-effects multinomial logit model because it is based on the assumption that the off-diagonal elements in V(ˆL) are all zero (Follmann, 1994). If the elements in V(ˆL) are unobtainable empirically, some covariance structure in the multinomial distribution needs to be assumed for the application of the bootstrap.
Because a subject’s probability is not empirically observable at a specific time point, the multinomial logit function does not have observed values on the logit components. Consequently, the variance–covariance matrix for the predicted logit is not empirically obtainable. Nevertheless, an approximation approach can be used to obtain an estimate of the matrix with K logit components by extending the perspective described in Chapter 10. First, fit a mixed-effects multinomial logit model with all covariates rescaled to be centered at some selected values. Second, use the squared standard error of each intercept estimate plus the corresponding variance of the between-subjects random effect as the variance for each of the K logit components. Third, take the off-diagonal elements in ˆV(ˆL) as the estimate of covariance between each pair of the logit intercept estimates. The rationale for this approximation is that if covariates are rescaled to be centered at specified values, the intercepts represent the group-specific means of the logit components, and therefore, the local variance–covariance matrix for the estimated intercepts plus the corresponding between-subjects random effects can be considered the approximates of the variance–covariance matrix for the mean logit function. While it is computationally tedious, in Section 11.6 a detailed procedure of this approximation method will be described empirically.
as the estimate of covariance between each pair of the logit intercept estimates. The rationale for this approximation is that if covariates are rescaled to be centered at specified values, the intercepts represent the group-specific means of the logit components, and therefore, the local variance–covariance matrix for the estimated intercepts plus the corresponding between-subjects random effects can be considered the approximates of the variance–covariance matrix for the mean logit function. While it is computationally tedious, in Section 11.6 a detailed procedure of this approximation method will be described empirically.
11.5. Conditional effects of covariates on probability scale
One challenge about the application of the mixed-effects multinomial logit model is the interpretation of the analytic results. In epidemiologic studies, it is not uncommon to display the regression coefficients or the odds ratios for interpreting the analytic results of the multinomial logit model. The logit coefficients and the odds ratios, however, only provide a limited profile of the covariates’ effects on the multinomial response. In the presence of more than two response levels, the regression coefficient of a covariate in the multinomial logit model does not necessarily bear any relationship with changes in the probabilities themselves (Greene, 2003; Liao, 1994; Liu et al., 1995), let alone the addition of the between-subjects random effects.
As applied for the mixed-effects binary logit model, the discrete probability change approach (Long, 1997) can be applied to compute the conditional effect of a given covariate on the probabilities of a multinomial response. For illustrative convenience, in the following presentation, the subscripts ij in the notation of probability Pijk are again temporarily removed from the mathematical expressions. That is, Pijk is replaced with Pk|X0 , indicating the probability of falling in the kth response level for a typical subject with covariate vector X0 that includes the value of time at time point j.
, indicating the probability of falling in the kth response level for a typical subject with covariate vector X0 that includes the value of time at time point j.
Consider the continuous covariate first. Let X0 be the vector containing the selected values of a set of covariates, including a time factor, and X0r represents the vector containing the selected values of the covariates except for a specific continuous variable Xm. It follows that (ˆPk|X0) represents the marginalized estimate of (ˆPk|X)
represents the marginalized estimate of (ˆPk|X) when all the covariates are scaled at some purposefully selected values, with the value of Xm scaled as its sample mean. Likewise, let (ˆPk|ˉXm+1,X0r)
when all the covariates are scaled at some purposefully selected values, with the value of Xm scaled as its sample mean. Likewise, let (ˆPk|ˉXm+1,X0r)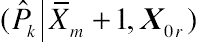 be another marginalized estimate of (ˆPk|X) when Xm is scaled at one unit greater than its sample mean and other covariates are fixed at previously selected values. Then, the difference between (ˆPk|ˉXm+1,X0r) and (ˆPk|X0) is defined as the conditional effect of covariate Xm on the probability of the response level k marginalized at the selected values of the covariates. Such a conditional effect is denoted by ∆ˆPkm
be another marginalized estimate of (ˆPk|X) when Xm is scaled at one unit greater than its sample mean and other covariates are fixed at previously selected values. Then, the difference between (ˆPk|ˉXm+1,X0r) and (ˆPk|X0) is defined as the conditional effect of covariate Xm on the probability of the response level k marginalized at the selected values of the covariates. Such a conditional effect is denoted by ∆ˆPkm , given by
, given by
∆ˆPkm=exp[ˆβkm(ˉXm+1)+X′0r ˆβkr]ˆΦk1+∑Kl=1exp[ˆβlm(ˉXm+1)+X′0r ˆβlr]ˆΦl−exp(X′0 ˆβk)ˆΦk1+∑Kl=1exp(X′0 ˆβl)ˆΦl,
 (11.24)
(11.24)where ˆβkm is the regression coefficient of Xm on the kth response level, and ˆβkr
is the regression coefficient of Xm on the kth response level, and ˆβkr is the (M − 1) × 1 vector of the unknown regression parameters for the covariates contained in X0r.
is the (M − 1) × 1 vector of the unknown regression parameters for the covariates contained in X0r.
If the index variable Xm is a dichotomous variable, the 0–1 change in that covariate should be specified. Accordingly, the conditional effect of Xm on the probability of the response level k is written as  (11.25)
(11.25)
(11.25)Given the mathematical constraints that a set of the probabilities for (K + 1) response categories always sum up to unity and the corresponding set of a covariate’s conditional effects must sum up to zero, the conditional effect of a covariate on the probability of the (K + 1)th level is defined as ∆ˆPK+1,xm=−(∆ˆP1xj+....+∆ˆPKxj) . In view of the restrictive conditions on the multinomial response, all the conditional effects of a given covariate on a set of probabilities should be considered statistically significant if any one of them is statistically significant, other covariates being equal (Liu and Engel, 2012). In other words, if the conditional effect of the covariate on one of the K log odds is statistically significant, the face values for the entire set of the conditional effects should be accepted.
. In view of the restrictive conditions on the multinomial response, all the conditional effects of a given covariate on a set of probabilities should be considered statistically significant if any one of them is statistically significant, other covariates being equal (Liu and Engel, 2012). In other words, if the conditional effect of the covariate on one of the K log odds is statistically significant, the face values for the entire set of the conditional effects should be accepted.
As indicated in Chapters 8 and 10, this discrete probability change approach differs conceptually from the so-called marginal effect that represents the slope of a probability function and actually has no bound in value (Petersen, 1985). The advantage of using the discrete conditional effect in the multinomial logit model is due to its consistence with the traditional interpretation of the regression coefficient, especially when qualitative factors taking more than two values are used as covariates.
It must be emphasized again that a statistically significant logit coefficient of a given covariate in mixed-effects logit models does not necessarily translate into a statistically significant effect on the probability scale. This statistical property is particularly the case in the mixed-effects multinomial logit model with the specification of multiple random effect dimensions on K response levels. Even the effect signs on the two scales can be different (Liu and Engel, 2012). Therefore, significance tests for the covariate effects on the logit and the probability scales need to be performed separately. In the construct of the mixed-effects multinomial logit model, the standard errors of the regression coefficients provide dispersions of the population-averaged fixed effects, and therefore, they can yield misleading conclusions concerning the covariates’ effects on the multinomial response. Indeed, statistical testing for the effects of covariates must be based on the conditional effects on the probability scale.
Specifically, statistical significance of the conditional effect on the probability scale can be tested by using the Wald chi-square statistic, denoted by χ2W,k (Klein and Moeschberger, 2003; Liu, 2012), as also indicated in Chapter 10. In the context of mixed-effects multinomial logit models, let ˆPk0
(Klein and Moeschberger, 2003; Liu, 2012), as also indicated in Chapter 10. In the context of mixed-effects multinomial logit models, let ˆPk0 represent (ˆPk|X0) and ˆPk1
represent (ˆPk|X0) and ˆPk1 stand for (ˆPk|ˉXm+1,X0r)
stand for (ˆPk|ˉXm+1,X0r) . The following equation is then defined from the delta method:
. The following equation is then defined from the delta method:
χ2W,k≈(ˆPk1−ˆPk0)2ˆV(ˆPk0)+ˆV(ˆPk1)−2cov(ˆPk0ˆPk1), k=1,...,K,
 (11.26)
(11.26)As extended from the binary to the multinomial response, Equation (11.26) bears a tremendous resemblance to Equation (10.29). Also analogous to the binary perspective, Equation (11.26) can be simplified as the two predicted probabilities, ˆPk0 and ˆPk1, are computed from the same parameter estimates and where all but one covariate have exactly the same values. Therefore, the two random variables Pk0 and PK1 should follow the same probability distribution. Consequently, Equation (11.26) can reduce to
χ2W,k≈(ˆPk1−ˆPk0)2ˆV(ˆPk0)+ˆV(ˆPk1)−2√ˆV(ˆPk0)ˆV(ˆPk1).
 (11.27)
(11.27)This Wald statistic is distributed asymptotically as chi-square with one degree of freedom under the null hypothesis that (ˆPk1−ˆPk0)=0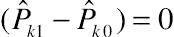 . The evaluation of ∆ˆPK+1
. The evaluation of ∆ˆPK+1 , the residual effect in the same probability set, depends on the test results of the nonreference conditional effects. That is, if any nonreference conditional effect is significant, ∆ˆPK+1 should be considered statistically significant; if all of the nonreference conditional effects are statistically insignificant, ∆ˆPK+1 is not statistically significant.
, the residual effect in the same probability set, depends on the test results of the nonreference conditional effects. That is, if any nonreference conditional effect is significant, ∆ˆPK+1 should be considered statistically significant; if all of the nonreference conditional effects are statistically insignificant, ∆ˆPK+1 is not statistically significant.
In the construct of multinomial logit models, either mixed- or fixed-effects, the conditional odds ratio of a given covariate does not provide useful information with the specification of more than two response levels. Given the multinomial response data, the sum of any two probabilities in the response set is not unity, and therefore, one cannot evaluate whether a given odds ratio indicates a positive or a negative effect of the covariate on a response level. For example, if the two probabilities in the response set both change positively with a one-unit increase in the covariate but the first score increases less sharply than the other, the corresponding odds ratio would be smaller than one. Likewise, if the two probabilities both change negatively with a one-unit increase in the covariate but the first one decreases less sharply than the other, the corresponding odds ratio would be greater than one. Given the difficulty in its interpretation, the conditional odds ratio statistic in the mixed-effects multinomial logit model is not useful and therefore is not specified in this chapter.
11.6. Empirical illustration: marital status and longitudinal trajectories of disability and mortality among older Americans
As summarized in Chapter 10, the application of the mixed-effects binary logit model on the health probability may encounter certain specification problems, particularly in the analysis of longitudinal data for older persons. Without accounting for the selection effect in the description of longitudinal trajectories of a health probability, the results from the mixed-effects binary logit model can result in incorrect parameter estimates and prediction bias. In such situations, the factor causing the selection of individuals should be considered in mixed-effects modeling. In the present illustration, I apply the mixed-effects multinomial logit model to reanalyze the effect of marital status on the probability of disability among older Americans, using mortality as a competing outcome state. The purpose of creating a multinomial response variable is to account for the selection effect due to mortality in the analysis. The retransformation method is used to derive unbiased nonlinear predictions of the competing health probabilities. Two random components are specified in the application of the retransformation method: between-subjects and within-subject. With the approximate variance–covariance matrix for a set of mean multinomial logit components, the delta method is applied to compute the variances of the predicted probabilities.
11.6.1. Data, measures, and models
Data and variables used for this illustration are the same as those specified in Chapter 10, except for the specification of a multinomial response variable. The new multinomial outcome variable is health state, named HEALTH_ST in the analysis and measured by the difficulty level in performing activities of daily living (ADL) and mortality between two successive waves. An individual is defined as functionally disabled if he or she has any degree of difficulty in performing any one of the five ADL activities. Death between two successive waves is specified as a competing risk. As a result, at each follow-up wave, three health states are identified: not functionally disabled (Health_st = 3), functionally disabled (Health_st = 1), and dead in the time interval (Health_st = 2). In the application of the mixed-effects multinomial logit model, the state not functionally disabled (ADL_COUNT = 0) is used as the reference level. The probability of being in a given health state for subject i at time point j is denoted by Pijk, where k = 1, 2, 3. With the analytic focus placed on the description of longitudinal trajectories of three health probabilities, the main explanatory variable is time, scaled as the number of years elapsed since the time of the 1998 AHEAD survey. Therefore, the time factor is specified as T = 0, 2, 4, 6, 8, 10 for the six waves from 1998 to 2008, respectively. According to the results of a preliminary data analysis, only the linear component of the time factor is considered. Marital status is another main explanatory variable, measured as a dichotomous variable with 1 = currently married and 0 = currently not married. In the estimating process, the three centered variables, AGE_MEAN, EDUC_MEAN, and FEMALE_MEAN, continue to be used as the control variables. An interaction term between time and marital status is included in the analysis for capturing the possible convergence over time of the effects of marital status.
For analytic convenience and illustrative simplicity, the random intercept multinomial logit model is applied, so that the effects of the covariates on the multinomial logit components are assumed to be fixed. The SAS PROC NLMIXED procedure, given its tremendous flexibility to model nonlinear longitudinal data, is applied to compute both the fixed and the random effects for the random intercept multinomial logit model (Molenberghs and Verbeke, 2010). The adaptive Gaussian quadrature is applied to approximate the integral of the likelihood over the random effects given its advantage over other methods in the derivation of robust estimates of the random effects and the model fit statistics (Molenberghs and Verbeke, 2010). With the specification of the between-subjects random effects for the intercept, the variable TIME is treated as a continuous variable. Within-subject random errors are specified in this analysis, and therefore, the present random intercept multinomial logit model does not follow a CS pattern in the total variance–covariance matrix. In other words, as the within-subject random component depends on the mean, the joint variance varies over time. Some of the random effects in covariates, though not specified, are expected to be accounted for by the specification of the within-subject variance component.
To compare statistical efficiency and robustness of different predicting approaches on longitudinal trajectories of the health probabilities, a full random intercept multinomial logit model is created first, which includes all the specified covariates and the two random components. It is assumed that the subject-specific and the marginal probabilities are exactly predicted by the full model, and so is the corresponding variance–covariance matrix. Next, a reduced-form random intercept multinomial logit model is specified by removing the variable EDUC_MEAN. This procedure is analogous to the corresponding specifications in Chapter 10. As education yields a statistically significant effect on the multinomial response in the presence of other model parameters, there is definitely additional clustering in the multinomial health data after its removal. By assuming the full model to be exact, the statistical capacity of the reduced-form mixed-effect model to handle the random effects can be evaluated and compared.
There are four goals in the present analysis. The first goal is to examine whether the retransformation method can capture the random effects after a theoretically important, statistically significant predictor is removed, as relative to the results from the full random intercept multinomial logit model. The second goal is to assess whether the retransformation method predicts longitudinal trajectories of the health probabilities significantly better than the empirical BLUP. The third goal is to display how the fixed-effects multinomial logit model, which does not specify a term for the random effects, results in severely biased nonlinear predictions and the corresponding dispersion statistics. The last goal is to monitor whether the specification of mortality as a competing risk alters the pattern of change over time in the probability of disability among older Americans, as compared to the pattern predicted from the mixed-effects binary logit model (presented in Chapter 10). The empirical BLUP and the retransformation method are based on the same random intercept multinomial logit model, eliminating education from statistical inference and estimation. Therefore, three multinomial logit models are created in this illustration: the full random intercept multinomial logit model, the reduced-form random intercept multinomial logit model, removing education from the regression, and the reduced-form fixed-effects multinomial logit model.
11.6.2. Analytic steps with SAS programs
As the application of the PROC NLMIXED procedure in the SAS system requires the robust starting values of specified parameters, the PROC GLIMMIX procedure is used first to produce an initial set of parameter estimates, which are then borrowed as the robust starting values of both the fixed and the random effects to apply the PROC NLMIXED procedure. The following SAS program specifies this GLIMMIX model.
SAS Program 11.1:

In SAS Program 11.1, the outcome variable HEALTH_ST is created first given the aforementioned specification (1 = functionally disabled, 2 = dead between two successive waves, and 3 = functionally independent). Next, a multinomial logit model is constructed with the specification of a random intercept term. The options NOITPRINT and NOCLPRINT tell SAS not to print the “Iteration History” and “Class Level Information” tables. The METHOD = QUAD(QPOINTS = 1) option specifies the use of the adaptive Gaussian quadrature with a single quadrature point in each dimension of the integral within a GLMM framework. The CLASS statement specifies the classification variables used in this model, consisting of the dependent variable HEALTH_ST and a subject’s identification number HHIDPN. The predesigned residual variance–covariance structures, such as AR(1) and SP(POW), are not specified for a multinomial distribution in the PROC GLIMMIX procedure. As the probabilities for a multinomial response are not observable, variability in the response cannot be captured effectively to generate a robust variance–covariance structure. Consequently, for the mixed-effects multinomial logit model, the correlation between repeated measurements of the multinomial response for the same subject is modeled by means of the specified random effects.
In the MODEL statement, the dependent variable and the fixed effects are specified. Six covariates, described earlier, are considered in the model. The option S (or SOLUTION) requests the solution for the fixed-effects parameters. The DIST = MULTINOMIAL option specifies the distribution of the dependent variable to be multinomial. Correspondingly, the option LINK = GLOGIT specifies the link function in this specific GLMM to be generalized logit. Additionally, the COVB option asks SAS to produce the approximate variance–covariance matrix of the fixed-effects estimates, and DDFM = BW specifies the residual degrees of freedom to be divided into between-subjects and within-subjects components.
The RANDOM statement defines the Z matrix of the mixed model, as mentioned previously. In this illustration, Z contains only one element for each logit component, and correspondingly, the G matrix only includes the logit intercepts. The option SUBJECT = HHIDPN identifies the subjects in this random intercept multinomial logit model. Similarly, the GROUP = HEALTH_ST option identifies three groups by which to vary the covariance parameters.
Next, given the parameter estimates from the PROC GLIMMIX procedure, not presented, the starting values of parameters can be specified in the PROC NLMIXED procedure. The following SAS program presents code for the full random intercept multinomial logit model with time centered at four (T = time – 4, the third time point), and all other covariates centered at sample means.
SAS Program 11.2:

In the PROC NLMIXED statement, the MTHOD = GAUSS option calls for the application of the adaptive Gaussian quadrature, COV asks SAS to print the approximate covariance matrix for the parameter estimates needed for computing the standard errors of nonlinear predictions on the multinomial response, and QPOINTS = 3 tells SAS that three quadrature points be used in each dimension of the random effects. The PARMS statement specifies the starting values of the parameter estimates on two logit components, log(P1/P3) and log(P2/P3), obtained from the PROC GLIMMIX procedure. With the specification of starting values for both the fixed and the random effects, the PROC NLMIXED procedure estimates the regression coefficients of the covariates on the two logit components. The error terms u0010 and u0015 indicate the random effects on the two logit components, each of which is assumed to be multivariate normal with zero expectation. The specifications of “le-6” and “−le15” are used to approximate a range of log(P) values between minus infinity to zero. If the PARMS statement is not given, the NLMIXED procedure assigns the default value of 1.0. As indicated in Chapter 10, if the starting values are too distant from the final estimates, numerical integration techniques will not perform well for a nonlinear regression model. Additionally, without the RANDOM statement to specify the random terms u0010 and u0015 in the linear predictors, the parameter estimates and the corresponding standard errors will be identical to those from the PROC LOGISTIC or the PROC CATMOD procedure with the specification of the multinomial response.
The reduced-form BLUP and the retransformation method are based on the same random intercept multinomial logit model, eliminating variable EDUC_MEAN from statistical inference and estimation. While the BLUP predicts the probabilities for each observation (Littell et al., 2006), the group mean of the BLUPs, the so-called empirical BLUP, can be estimated by creating a scoring dataset specifying the multinomial outcome variable as missing and the independent variables as zero, with the covariates being centered at selected values corresponding to a specific population group. In the scoring data, the random effects per individual should be present, and therefore, the mean of the BLUPs with y = missing and X’s = 0 derives the predicted health probabilities for a group or an average person taking selected values of the covariates.
Below is the SAS program for the reduced-form random intercept multinomial logit model with time centered at four and the other covariates rescaled to be centered at sample means. The part for creating the scoring dataset is presented first.
SAS Program 11.3a:

In SAS Program 11.3a, a scoring dataset is created, and it is then combined with the main data through the DATA step. As a result, in the temporary dataset TP4 each subject has seven data points, six actual and one hypothetical. As the variable “t” is centered at four, the “t = 0” statement actually specifies the time factor in the scoring dataset as TIME = 4 (the third data point). As can be recognized, SAS Program 11.3a is identical to SAS Program 10.3a except the specification of a different outcome variable, HEALTH_ST.
With the creation of the scoring dataset and its combination with the main data, the reduced-form random intercept multinomial logit model can be constructed, as displayed in the following SAS program.
SAS Program 11.3b:

In the PROC NLMIXED procedure, the syntax is analogous to SAS Program 11.2 except for the removal of covariate EDUC_MEAN and the addition of the PREDICT statements to compute the BLUPs for each subject in the scoring dataset. As there are three nonlinear predictions for P1, P2, and P3, respectively, three PREDICT steps are specified to predict three probabilities by using the fixed parameter estimates and the empirical Bayes estimates of the between-subjects random effects. The predicting results are then placed in three output datasets with the OUT = options (OUT1, OUT2, OUT3), and as a result, the means and the standard errors of three empirical BLUP predictions (PRED1, PRED2, PRED3) can be computed by the application of the PROC MEANS procedure.
The reduced-form fixed-effects multinomial logit model can be created by modifying SAS Program 11.3, removing the RANDOM and the PREDICT statements. Without the specification of the random intercepts, the empirical BLUP per individual cannot be produced, and therefore, the call for the PROC MEANS procedure is redundant. Below is the SAS program for this model.
SAS Program 11.4:

The previous random intercept multinomial logit models are specified just for analytic convenience and illustrative simplicity. The presentations shown in the illustration do not depend on the validity of those ad hoc models; any other more flexible mixed-effects multinomial logit models would lead to the same results concerning the statistical efficiency and coverage of the retransformation method. If a random coefficient multinomial logit model is applied, the variance–covariance structure becomes a block covariance matrix, thereby further increasing statistical complexity and the computational burden on the multinomial response. In the course of preparing this illustration, a random coefficient multinomial logit model is also created and analyzed by extending the random intercept perspective described earlier. For the reader’s reference, the model specifications and the corresponding SAS program for this random coefficient multinomial logit model are presented in Appendix D.
11.6.3. Analytic results and nonlinear predictions
Table 11.1 displays the analytic results of the three multinomial logit models described earlier. As indicated, the regression coefficients of covariates on the logit components do not provide interpretable information on the multinomial response. Therefore, in reading Table 11.1, the reader’s focus should be placed on the statistical significance of the parameter estimates and the differences in the estimates from the three models.
Table 11.1
Results of Three Multinomial Logit Models on Health States in Older Americans (N = 2000)
| Explanatory Variable and Effect Type | Log (P1/P3) | Log (P2/P3) | ||
| Parameter Est. | Standard Error | Parameter Est. | Standard Error | |
| Full Mixed-Effects Multinomial Logit Model | ||||
| Fixed effects | ||||
| Intercept | −0.938*** | 0.033 | −1.964*** | 0.069 |
| Time (centered at four) | 0.152*** | 0.009 | 0.355*** | 0.024 |
| Married_mean | −0.455*** | 0.072 | 0.170 | 0.110 |
| Time × Married_mean | 0.028 | 0.019 | −0.066** | 0.027 |
| Age_mean | 0.041*** | 0.006 | 0.183*** | 0.012 |
| Educ_mean | −0.078*** | 0.009 | −0.092*** | 0.013 |
| Female_mean | 0.358*** | 0.073 | −0.409*** | 0.103 |
| Random effects | ||||
| Intercept | 0.165*** | 0.030 | 0.413** | 0.184 |
| Reduced Mixed-Effects Multinomial Logit Model | ||||
| Fixed effects | ||||
| Intercept | −0.939*** | 0.033 | −1.965*** | 0.069 |
| Time (centered at four) | 0.143*** | 0.009 | 0.349*** | 0.025 |
| Married_mean | −0.456*** | 0.071 | 0.169 | 0.110 |
| Time × Married_mean | 0.030 | 0.019 | −0.066** | 0.027 |
| Age_mean | 0.057*** | 0.006 | 0.189*** | 0.012 |
| Female_mean | 0.357*** | 0.072 | −0.409*** | 0.102 |
| Random effects | ||||
| Intercept | 0.166*** | 0.029 | 0.413** | 0.188 |
| Reduced Fixed-Effects Multinomial Logit Model | ||||
| Fixed effects | ||||
| Intercept | −0.970*** | 0.031 | −1.961*** | 0.051 |
| Time (centered at four) | 0.132*** | 0.010 | 0.441*** | 0.014 |
| Married_mean | −0.460*** | 0.071 | 0.170 | 0.104 |
| Time × Married_mean | 0.030 | 0.021 | −0.070*** | 0.026 |
| Age_mean | 0.117*** | 0.006 | 0.226*** | 0.008 |
| Female_mean | 0.360*** | 0.072 | −0.410*** | 0.088 |

* 0.05 < p < 0.10; **0.01 < p < 0.05; ***p < 0.01.
Of the fixed effects displayed in Table 11.1, the regression coefficients of marital status on the second logit and the interaction between time and marital status on the first logit are not significant individually. Even so, given the statistical criterion about the fixed effects on a set of logit components, all the regression coefficients are viewed as statistically significant with α = 0.05. Therefore, the three multinomial logit models have the same test results on the logit coefficients. The regression coefficients of time on both logit components are positive and statistically significant. Marital status is negatively linked to the first logit component but is positively associated with the second. The regression coefficient of the interaction between time and marital status is positive on the first and is negative on the second logit component, other covariates being equal. All the three control variables yield very strong effects on the multinomial logit components. Caution must apply, however, in attempting to interpret the fixed effects substantively.
In the two random intercept multinomial logit models, the full and the reduced, the between-subjects random effects on the two logit components are 0.17 and 0.41, respectively, both statistically significant. The strong random effects indicate the importance of specifying the random effects in modeling the multinomial longitudinal data.
The analytic results derived from the reduced-form random intercept multinomial logit model are very close, some even identical, to those from the full model, both the point and the standard error estimates. Additionally, the reduced fixed-effects multinomial logit model yields close estimates of the fixed effects to those from the two mixed-effects multinomial logit models. In the application of GLMM-type models, such a similarity is not surprising given the desirable property that the asymptotic process √n(ˆβ−β0), where β0 is the true parameter vector, tends to converge in probability to a normal vector with mean 0 and the covariance matrix I−1(ˆβ,t) for large samples, even in the presence of strong clustering in Y (Davidian and Giltinan, 1995; Liang and Zeger, 1986; Zeger et al., 1988; Liu and Engel, 2012). It does not mean, however, that the fixed-effects multinomial logit model can yield robust and consistent estimators for nonlinear predictions of the probabilities in the longitudinal setting, as will be shown in the succeeding texts.
for large samples, even in the presence of strong clustering in Y (Davidian and Giltinan, 1995; Liang and Zeger, 1986; Zeger et al., 1988; Liu and Engel, 2012). It does not mean, however, that the fixed-effects multinomial logit model can yield robust and consistent estimators for nonlinear predictions of the probabilities in the longitudinal setting, as will be shown in the succeeding texts.
The probability of each health state at each time point and the corresponding variance can be estimated by applying Equations (11.22) and (11.23), respectively. In the context of this illustration, four partial derivatives of two predicted probabilities are identified with respect to two logit components. For ˆP1 , we have
, we have
∂ˆP1∂ˆL1={[1+∑2k=1exp(ˆLk)]2}−1exp(ˆL1)[1+exp(ˆL2)]=B11,
 (11.28a)
(11.28a)∂ˆP1∂ˆL2={[1+∑2k=1exp(ˆLk)]2}−1[−exp(ˆL1)exp(ˆL2)]=B12.
 (11.28b)
(11.28b)Likewise, the corresponding partial derivatives for ˆP2 are
are
∂ˆP2∂ˆL1={[1+∑2k=1exp(ˆLk)]2}−1[−exp(ˆL)exp(ˆL2)]=B21,
 (11.28c)
(11.28c)∂ˆP2∂ˆL2={[1+∑2k=1exp(ˆLk)]2}−1exp(ˆL2)[1+exp(ˆL1)]=B22.
 (11.28d)
(11.28d)Let
[∂g−1(ˆL)∂ˆL| L=μ]=B,

where
B=(B11 B12B21 B22).

The variance–covariance matrix for the predicted probabilities ˆP1 and ˆP2 in this analysis can then be approximated by the following sandwich estimator:
V(ˆP)≈BΣ(ˆL)B′,
where
Σ(ˆL)=(σ2•1 σ12σ21 σ2•2).

In the retransformation method, the total variance is defined as σ2•k= σ2bk+σ2ek , where k = 1, 2, consisting of two random components: between-subjects and within-subject. In the empirical BLUP, on the other hand, only σ2bk
, where k = 1, 2, consisting of two random components: between-subjects and within-subject. In the empirical BLUP, on the other hand, only σ2bk is included in predicting the probabilities (Littell et al., 2006).
is included in predicting the probabilities (Littell et al., 2006).
To highlight disparities in different predicting methods, four sets of the probabilities are predicted on the three health states at six time points, using analytic results from the full random intercept multinomial logit model, the retransformation method, the empirical BLUP, and the fixed-effects multinomial logit model, respectively. Table 11.2 presents the sets of the predicted probabilities and the corresponding standard errors at six time points.
Table 11.2
Predicted Probabilities of Disability and Death at Six Time Points
| Health State | Time Point | |||||
| T0 (1998) | T1 (2000) | T2 (2002) | T3 (2004) | T4 (2006) | T5 (2008) | |
| Predicted Probability Generated From the Full Model | ||||||
| Disabled | 0.256 | 0.259 | 0.266 | 0.268 | 0.271 | 0.260 |
| (0.066) | (0.068) | (0.082) | (0.084) | (0.087) | (0.072) | |
| Dead | – | 0.108 | 0.108 | 0.112 | 0.114 | 0.112 |
| (0.064) | (0.063) | (0.065) | (0.068) | (0.066) | ||
| Predicted Probability Generated From the Retransformation Approach | ||||||
| Disabled | 0.257 | 0.258 | 0.266 | 0.268 | 0.271 | 0.260 |
| (0.068) | (0.070) | (0.082) | (0.084) | (0.087) | (0.072) | |
| Dead | – | 0.108 | 0.108 | 0.112 | 0.114 | 0.112 |
| (0.063) | (0.063) | (0.065) | (0.068) | (0.066) | ||
| Predicted Probability Generated From BLUP | ||||||
| Disabled | 0.248 | 0.253 | 0.259 | 0.259 | 0.246 | 0.249 |
| (0.023) | (0.025) | (0.035) | (0.037) | (0.039) | (0.027) | |
| Dead | – | 0.089 | 0.095 | 0.102 | 0.108 | 0.109 |
| (0.020) | (0.020) | (0.022) | (0.023) | (0.020) | ||
| Predicted Probability Generated From the Fixed-Effects Approach | ||||||
| Disabled | 0.251 | 0.250 | 0.250 | 0.250 | 0.250 | 0.253 |
| (0.008) | (0.007) | (0.006) | (0.007) | (0.009) | (0.009) | |
| Dead | – | 0.093 | 0.093 | 0.093 | 0.093 | 0.094 |
| (0.005) | (0.004) | (0.004) | (0.006) | (0.010) | ||

Note: The predicted probability of “not disabled” and its standard error depend on the results for the probabilities of the other two health states, therefore they are not displayed in the table.
AHEAD Longitudinal Survey (N = 2000).
In Table 11.2, the probability of disability is shown to stabilize over time at the baseline level, reflecting the result of a selection of the fittest process among this very old population (in 1998, the youngest member of the AHEAD cohort was age 75 years). Therefore, after including mortality as a competing risk in the mixed-effects logit modeling, the increasing trend over time in the probability of disability shown in Chapter 10 vanishes. This stable pattern of change agrees with the time trend of health often observed in older populations. While individually disability tends to get intensified over age, collectively survivors are those who are more physically fit than those deceased, thereby altering the population health composition dynamically. This pattern of disparity between individual aging and population health is particularly observable in the oldest old. Here, selection of individuals offsets the effect of population aging. Therefore, in studies for older persons, it is imperative to account for the selection effect in the analysis of longitudinal qualitative data. In Table 11.2, the mortality rate is also shown to be constant throughout the entire observation period, perhaps due to the same selection effect.
Given the relatively small size of the standard errors for the probabilities of disability and mortality, all the predicted probabilities displayed in Table 11.2 are considered statistically significant. The retransformation method, after one theoretically important, statistically significant predictor is removed, yields very close predictions, both the point estimates and the standard error approximates, to those from the full random intercept multinomial logit model. Therefore, in the construct of the mixed-effects multinomial logit model, the retransformation method is shown to have statistically adequate capacity for handling unobserved heterogeneity in nonlinear predictions. The empirical BLUP provides fairly close predictions at the early time points; in the last three time points, however, the predicted probabilities deviate markedly from those of the first two approaches. Furthermore, the empirical BLUP, not accounting for inherent within-subject variability, results in the severely underestimated standard errors of the nonlinear predictions. The fixed-effects multinomial logit model obviously generates the least reliable nonlinear predictions with massive deviations from the predicting results of the three mixed-effects approaches. Perhaps more significantly, the fixed-effects approach severely underestimates the standard errors of the predicted probabilities, much more seriously than the empirical BLUP. The results of the previous comparison provide very strong evidence that even though they tend to yield unbiased estimates of the fixed parameters and the corresponding standard errors, the fixed-effects nonlinear regression models does not possess the capability to analyze multinomial longitudinal data.
11.6.4. Conditional effects of marital status
As indicated earlier, the retransformation method is based on the specification of the mean logit function with the covariates rescaled to be centered at selected values. As a result, the procedure for computing the conditional effects of marital status on the health probabilities includes a large quantity of SAS programs and spreadsheets, much more so than what was applied for the mixed-effects binary logit model. Given the importance of computing the conditional effects in the analysis of multinomial longitudinal data, in this illustration I display the procedure for computing the conditional effects of marital status on the health probabilities at the fourth time point, used as an example. The time factor is specified as the number of years elapsed since the time of the 1998 survey, the fourth time point is specified as TIME = 6. Accordingly, the value of the centered time variable at this time point is specified as t = TIME – 6 = 0. The reduced-form random intercept multinomial logit model is applied to yield parameter estimates for the computation. The following SAS program displays a PROC NLMIXED procedure for fitting the reduced-form random intercept multinomial logit model, in which the centered time “t,” MARRIED, the interaction between “t” and MARRIED, AGE_MEAN, and FEMALE_MEAN are the covariates.
SAS Program 11.5:

In SAS Program 11.5, first the time variable is rescaled to be centered at six, thereby specifying the value of “t” at the fourth time point as zero. This PROC NLMIXED program is basically identical to SAS Program 11.3b, except for the replacement of MARRIED_MEAN with MARRIED. Given three response levels, two logit components are specified, log(P1/P3) and log(P2/P3), with each logit component being expressed as a linear function of the five covariates. This NLMIXED procedure yields the following analytic results.
SAS Program Output 11.1:
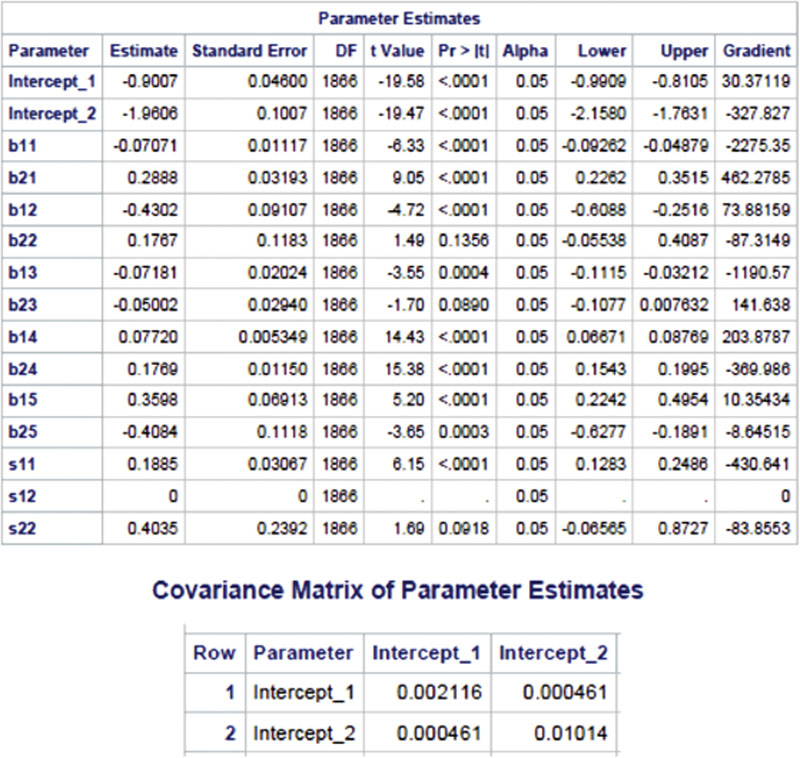
In SAS Program Output 11.1, the first table, “Parameter Estimates,” displays the estimates of the fixed and the random effects on the two logit components. For each parameter type, there are two estimates corresponding to the two logit components: log(P1/P2) and log(P2/P3), respectively. These results are consistent with those previously reported, thereby not being further interpreted. The second table, “Covariance Matrix of Parameter Estimates,” displays the local variance–covariance matrix of the intercepts on the two logit components needed to compute the variances and the covariance of the conditional effects of marital status on the health probabilities.
As indicated earlier, in the construct of the multinomial logit model, the regression coefficients of a covariate are not intuitive because they do not necessarily correspond to changes in a set of probabilities. Therefore, the estimated regression coefficients of marital status on the logit components need to be retransformed to the conditional effects on the probability scale to aid in the interpretation of the analytic results. With variable MARRIED being a dichotomous variable, Equations (11.25) and (11.27) are applied to generate the retransforms. First, using Equation (11.25) and the estimated regression coefficients reported in SAS Program Output 11.1, the baseline probability of disability and the death rate indicate the estimates for those currently not married (MARRIED = 0). In computing the probabilities at the fourth time (TIME = 6), the values of the three control variables need be held at sample means at the time point, and therefore, all five covariates are scaled at zero in the nonlinear predictions. Consequently, only the fixed and the random estimates for the intercepts need to be included for computing the two probabilities for those currently not married. Below is the computation of the two nonreference probabilities.
(ˆP10|time=6)=exp(−0.901)exp[(0.189+0.002)/2]1+exp(−0.901)exp[(0.189+0.002)/2]+exp(−1.961)exp[(0.404+0.010)/2]=0.254,
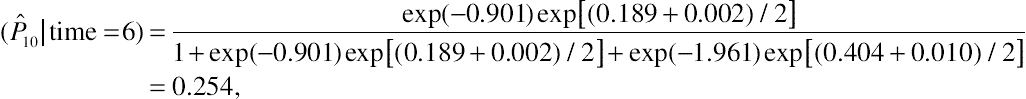
(ˆP20|time=6)=exp(−1.961)exp[(0.404+0.010)/2]1+exp(−0.901)exp[(0.189+0.002)/2]+exp(−1.961)exp[(0.404+0.010)/2]=0.109,

where (ˆP10|time=6) is the predicted probability of disability at the fourth time, and (ˆP20|time=6)
is the predicted probability of disability at the fourth time, and (ˆP20|time=6) is the death rate between the third and the fourth time points, for those currently not married. By definition, (ˆP30|time=6)
is the death rate between the third and the fourth time points, for those currently not married. By definition, (ˆP30|time=6) , the probability of functional independence at the fourth time for those currently not married, is the residual to the sum of the two nonreference predictions, given by (ˆP30|time=6)=1−0.254−0.109=0.637
, the probability of functional independence at the fourth time for those currently not married, is the residual to the sum of the two nonreference predictions, given by (ˆP30|time=6)=1−0.254−0.109=0.637 .
.
Using Equations (11.28) and (11.29), the 2 × 2 variance–covariance matrix of the two predicted probabilities for those not currently married can then be computed. First, by using the analytic results reported in SAS Program Output 11.1 and Equation (11.28), the four elements in the B matrix are given by B11 = 0.200, B12 = B21 = –0.029, and B22 = 0.095, respectively. Let V(ˆP0|time=6) denote the variance–covariance matrix for the predicted probabilities ˆP1 and ˆP2 at the fourth time point (time = 6) for those currently not married. Then, given the estimated variance–covariance matrix for the predicted multinomial logit components, the variance–covariance matrix for ˆP1 and ˆP2 at the fourth time point can be approximated by using Equation (11.29), given by
denote the variance–covariance matrix for the predicted probabilities ˆP1 and ˆP2 at the fourth time point (time = 6) for those currently not married. Then, given the estimated variance–covariance matrix for the predicted multinomial logit components, the variance–covariance matrix for ˆP1 and ˆP2 at the fourth time point can be approximated by using Equation (11.29), given by
V(ˆP0|time=6)≈(0.200 −0.029−0.029 0.095)(0.189+0.002 0.0010.001 0.404+0.010)(0.200 −0.029−0.029 0.095)′=(0.008 −0.002−0.002 0.004).

The diagonal elements in the final matrix are the variance approximates for the two predicted probabilities at the fourth time for those currently not married, namely var(ˆP10|time=6)=0.008 and var(ˆP20|time=6)=0.004
and var(ˆP20|time=6)=0.004 . Correspondingly, the square root of each variance estimate yields the approximate of the standard error for the predicted probability.
. Correspondingly, the square root of each variance estimate yields the approximate of the standard error for the predicted probability.
The computation for those currently married can be performed in the same fashion. First, a random intercept multinomial logit model is created by replacing the covariate MARRIED with a new variable UNMARRIED with 0 = currently married and 1 = currently not married. The SAS program for this model is exactly the same as SAS Program 11.5 except for the inclusion of UNMARRIED instead of MARRIED in covariates, and therefore, the program is not presented.
For those currently married, the predicted probability of disability at the fourth time is denoted by (ˆP11|time=6) and the death rate between the third and the fourth time points is denoted by (ˆP21|time=6)
and the death rate between the third and the fourth time points is denoted by (ˆP21|time=6)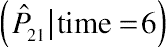 . Following the same computational steps described earlier, the two nonreference health probabilities for those currently married are predicted as 0.262 and 0.111, respectively. As the residual estimate, the predicted probability of functional independence for those currently married at the fourth time is given by (ˆP31|time=6)=1−0.262−0.111=0.626
. Following the same computational steps described earlier, the two nonreference health probabilities for those currently married are predicted as 0.262 and 0.111, respectively. As the residual estimate, the predicted probability of functional independence for those currently married at the fourth time is given by (ˆP31|time=6)=1−0.262−0.111=0.626 . The variance estimates for the two nonreference predictions are 0.007 and 0.004, respectively. With the similarity of the computational steps described earlier, details about the computation for those currently married are not displayed. The reader might want to practice how the predicted probabilities and the V(ˆP1|time=6)
. The variance estimates for the two nonreference predictions are 0.007 and 0.004, respectively. With the similarity of the computational steps described earlier, details about the computation for those currently married are not displayed. The reader might want to practice how the predicted probabilities and the V(ˆP1|time=6) matrix are derived by following the computational steps for those currently not married.
matrix are derived by following the computational steps for those currently not married.
Applying Equation (11.25), the conditional effects of marital status on the probability of disability and death rate at the fourth time are given by
∆ˆP1,married=ˆP11−ˆP10=0.262−0.276=−0.014,
∆ˆP2,married=ˆP21−ˆP20=0.111−0.107=0.004,
∆ˆP3,married=−(∆ˆP1,married+∆ˆP2,married)=−(−0.014+0.004)=0.010.
Statistical significance of the conditional effects of marital status on the two nonreference predicted probabilities can be tested by using Equation (11.27). Specifically, the Wald chi-square statistics for the two conditional effects of marital status are computed as
χ2W,∆ˆP1, married=(0.262−0.276)20.008+0.007−2×√0.008×0.007=2.963,χ2W,∆ˆP2,married=(0.111−0.107)20.004+0.004−2×√0.004×0.004=2.576.

Each Wald statistic is distributed asymptotically as a chi-square with one degree of freedom under the null hypothesis. Therefore, given the Wald chi-square statistics, both the conditional effects of marital status are not statistically significant given α = 0.05. The evaluation of ∆ˆP3 , the residual effect, depends on the test results for the two nonreference conditional effects. Given the constraint that a set of conditional effects must sum up to zero, all three conditional effects of marital status at the fourth time point are considered statistically insignificant.
, the residual effect, depends on the test results for the two nonreference conditional effects. Given the constraint that a set of conditional effects must sum up to zero, all three conditional effects of marital status at the fourth time point are considered statistically insignificant.
By applying the aforementioned computational procedure, the conditional effects of marital status and the corresponding variances at other time points can be predicted and computed. Table 11.3 displays the conditional effects of marital status on the probabilities of the two nonreference health states at all six time points.
Table 11.3
Conditional Effects of Current Marriage on Probabilities of Two Health States AHEAD Longitudinal Survey (N = 2000)
| Functional Status | Time Point | |||||
| T0 (1998) | T1 (2000) | T2 (2002) | T3 (2004) | T4 (2006) | T5 (2008) | |
| Disabled | −0.001 | 0.000 | 0.002 | −0.013 | −0.012 | −0.003 |
| (0.030) | (0.143) | (0.017) | (2.963) | (1.032) | (9.655) | |
| Dead | – | 0.000 | 0.002 | −0.013 | −0.012 | −0.003 |
| (0.230) | (0.698) | (2.576) | (1.096) | (0.500) | ||

Note: The conditional effects of marital status on the probability of functional independence depend on the testing results of the conditional effects on the probabilities of the two nonreference health states.
Table 11.3 displays that those currently married are slightly less likely than those currently not married to be functionally disabled and die. None of these conditional effects, except the one on the probability of disability at the sixth time, is statistically significant. Even that conditional effect, though statistically significant, is ignorable in analysis as it takes a value of −0.003, indicating a 0.3% difference between those currently married and those currently not married. Indeed, at the very old ages, survivors are those who are the most physically fit in the selection process, and as a result, group differences in health probabilities would gradually fade away, eventually displaying a homogeneous pattern.
The results shown in Table 11.3 provide very strong evidence that in longitudinal analysis on the multinomial response data, a strong fixed effect of a covariate on the logit scale does not necessarily translate into a strong, statistically meaningful impact on the probability scale. This is thought to be because the fixed effects on the logit scale are population-averaged without accounting for between-subjects variability, and in retransforming the fixed effects to the conditional effects on the probability scale, both between-subjects and within-subject variability is included, thereby substantially increasing the value of variance for the retransforms. Therefore, in the interpretation of the covariates’ effects on the multinomial longitudinal data, reliance on the fixed effects can result in misleading conclusions.
11.6.5. Graphical analysis on nonlinear predictions
To graphically display the statistical efficiency and coverage of different predicting approaches, Fig. 11.1 plots three sets of longitudinal trajectories on the probability of disability and the corresponding 95% confidence limits, with all covariates other than time fixed at time-specific sample means. These three sets of trajectories are derived from the retransformation method, the empirical BLUP, and the fixed-effects multinomial logit model, respectively. Each of these trajectory sets is compared to a solid growth curve and a shaded area representing an unbiased 95% confidence region from the full random intercept multinomial logit model.

Figure 11.1 Time Trends in the Predicted Probability of Disability Derived from Four Models
(a) Retransformation versus Full; (b) BLUP versus Full; (c) Fixed Effects versus Full.
(a) Retransformation versus Full; (b) BLUP versus Full; (c) Fixed Effects versus Full.
In Panel a of Fig. 11.1, which compares the predicted pattern of change in the predicted probability of disability between the retransformation method and the full model, the two trajectory lines almost coincide in much of the observation period, thereby demonstrating the high efficiency and coverage of the retransformation method after a substantively important, statistically significant predictor is removed. The predicted trajectory curve in Panel b, obtained from the empirical BLUP, appears fairly close to the solid line; nevertheless, the two 95% confidence limit lines are much contracted as relative to the shaded area, highlighting the limited capability of the empirical BLUP to handle retransformation bias in nonlinear predictions. Panel c displays the predicted growth curve from the fixed-effects multinomial logit model, in which tremendous bias can be easily identified. In most time points, the dispersion of the predicted probability of disability is amiss: even the upper confidence limit of the probability is below the solid line.
Figure 11.2 plots three longitudinal trajectories of mortality and the corresponding 95% confidence limits, obtained from the retransformation method, the BLUP, and the fixed-effects multinomial logit model, respectively. The solid line and the shaded area in each panel are the growth curve and the 95% confidence region from the full random effects multinomial logit model, which are assumed to be exactly predicted for the convenience of evaluating the capacities of the three predicting methods. Panel a displays how well the retransformation method predicts the trajectory of the old-age mortality and the corresponding confidence limits, after one theoretically important, statistically significant predictor is removed. As shown in Panel b, the empirical BLUP predicts mortality fairly nicely, particularly at later time points, but the 95% confidence limits are considerably underestimated. In Panel c, the predicted trajectory curve of mortality is incorrect, with the two 95% confidence limits very narrowly scattered around the mean.

Figure 11.2 Longitudinal Trajectories of Mortality Derived from Four Models
(a) Retransformation versus Full; (b) BLUP versus Full; (c) Fixed Effects versus Full.
(a) Retransformation versus Full; (b) BLUP versus Full; (c) Fixed Effects versus Full.
With inclusion of mortality as a competing risk, the pattern of change in the probability of disability differs tremendously from the pattern predicted by applying the mixed-effects binary logit model. As the mortality curve approximates a parallel line, the probability of disability does not display a distinctive pattern of change over time. Such an alteration in the predicted time trend provides very strong evidence that in the analysis of binary longitudinal health data among older persons, it is essential to take mortality as a competing risk; otherwise, longitudinal trajectories of health probabilities might be confounded tremendously by selection bias.
11.7. Summary
As the regression coefficients of covariates in the multinomial logit model are not interpretable substantively, a supplementary procedure is to use the fixed-effect estimates to predict the probabilities marginalized at certain covariate values. This application, however, can entail serious prediction bias due to misspecification of the predictive distribution of the random components. For the mixed-effects multinomial logit model, the random components cannot be overlooked in nonlinear predictions of the marginal probabilities. If a given random component in the model is truly normally distributed, the multivariate normality on the logit scale must be retransformed to a multivariate lognormal distribution to correctly predict the response probabilities. With such retransformation, the expectation of the lognormal distribution for the multiplicative random variable is not unity but some quantity greater than one unless both the between-subjects and the within-subject random components are zero for all individuals. Additionally, without retransforming the distribution of the random components, the variance of the predicted probabilities will be much underestimated, thereby affecting the quality of significance tests on nonlinear predictions. The BLUP approach, widely applied in longitudinal data analysis, accounts for a portion of between-subjects variability in nonlinear predictions of the response probabilities. This predicting method, however, overlooks not only the dispersion of the random effect prediction but also the within-subject random errors that may exist inherently even with the specification of the between-subjects random effects. The retransformation method accounts for both between-subjects and within-subjects variability simultaneously in the construct of the mixed-effects multinomial logit model.
I would like to emphasize that from the standpoint of Bayesian inference, the posterior predictive distribution of the random components in the mixed-effects multinomial logit model is not normality but lognormality. Correspondingly, the expectation of this predictive distribution for the random effects is greater than one. In the previous illustration, I compare three sets of the predicted probabilities for three health states at six time points, obtained from three predicting approaches – the retransformation method, the empirical BLUP, and the fixed-effects model – as relative to the predictions from a specified full model. In particular, I examine how each of these methods behaves in nonlinear predictions after an important predictor variable is removed from the estimating process. The results of the empirical illustration display that failure to retransform the random effects adequately in the mixed-effects multinomial logit model results in biased longitudinal trajectories of health probabilities and considerable underestimation of the corresponding standard errors, even though the estimated regression coefficients of covariates tend to be unbiased. These biases in nonlinear predictions, in turn, can exert substantial influences on the significance tests for the effects of covariates on the predicted probabilities.
It is also shown in the illustration that after the statistically significant fixed effects of marital status on the logit scale are converted into the conditional effects on the probabilities, each of the effect estimates has a much widened dispersion on the probability scale. Consequently, at older ages, those currently married and currently not married do not display statistically significant, substantively notable differences in health probabilities at any of the time points, except for one. This loss of statistical significance is because the fixed effects are population-averaged, and therefore, the subject-specific variability is disregarded; once the random effects are introduced in prediction of the health probabilities, the inherent variability in the predictions is much increased, thereby lowering the value of the chi-square statistic. Consequently, the difference between two predicted probabilities of a given health state becomes much less likely to be statistically meaningful.
..................Content has been hidden....................
You can't read the all page of ebook, please click here login for view all page.