
Chapter 13
Latent growth, latent growth mixture, and group-based models
Abstract
Chapter 13 provides an account of the latent growth modeling techniques. To familiarize the reader with latent growth methodology, I first provide a brief overview of structural equation modeling (SEM), based on which various latent growth models were developed. Next, I delineate the specification and statistical inference of the latent growth model (LGM). It is emphasized that in many ways, LGM is an SEM expression of linear mixed modeling in the context of longitudinal analysis. The latent growth mixture model (LGMM) is an extension of LGM with introducing latent classes in the model specification and statistical inference for modeling the developmental trajectory of individuals. The group-based model provides an alternative approach to identify distinctive growth patterns with the assumption that repeated measurements of the response are assumed to be serially uncorrelated given the specification of a finite number of latent groups. An empirical example is provided to illustrate the application of the latent growth model in SAS.
Keywords
Group-based model
indicator variable
latent factor
latent growth mixture model
latent growth model
structural equation modeling
As various longitudinal models display the process of development or growth within a hierarchical or a random coefficient framework, specialists of multilevel modeling refer to such analytic techniques as growth models or GM (Goldstein, 1987; Raudenbush and Bryk, 2002; Singer, 1998). More recently, some scientists have introduced such growth models to the domain of structural equation modeling (SEM), estimating growth trajectories by redefining the random intercept and the time coefficient as two latent factors (McArdle, 1988; McArdle and Epstein, 1987; McArdle and Hamagami, 1992; Meredith and Tisak, 1990). In statistics, latent factors are defined as variables that are not directly observed but are referred from other variables that are observed, thereby corresponding to the implication of the random effects. Such a statistical perspective is referred to as the latent growth model (LGM). This model includes the estimation of growth functions with the fixed and the random components, describing the average rate of change for a population of interest as well as variability in individual longitudinal courses over time (Meredith and Tisak, 1990).
A more recent development of latent growth modeling is the latent growth mixture model (LGMM). This approach is featured by the specification of latent classes that can be identified and estimated as subpopulations given observed data (Muthén, 2001; Muthén and Shedden, 1999). In LGMM, the distribution of the observed data is modeled by means of mixed growth trajectories, and therefore, each subpopulation has its own model parameter values. Given the specified heterogeneous classes, the distribution of the observed outcomes is viewed as a mixture distribution (Muthén, 2001). When individual variability is assumed to only occur between groups, the LGMM reduces to the latent growth curve model (LGCM), in which each observation is subject to a probability of belonging to each latent class (Muthén, 2001). Equivalent to LGCM, a recent simplification of LGMM is the group-based model. This model was initiated by Land and Nagin (1996) and Nagin and Land (1993) in criminological studies, and later formalized by Nagin (1999, 2005). The group-based model is considered equivalent to LGCM as it reflects variations in individual growth patterns and defines distinctive trajectory groups by their size and trajectory shape. Compared to the more complex LGMM, the group-based model can be more easily manipulated (Jones and Nagin, 2007; Jones et al., 2001).
In this chapter, I introduce some of the LGMs. To familiarize the reader with latent growth methodology, I first provide a brief overview of SEM based on which LGM and LGMM were developed. Next, I delineate general specifications and statistical inferences for, in the order of their publication years, the LGM, the LGMM, and the group-based model. An empirical example is provided to illustrate the application of the LGM in SAS. Lastly, the chapter concludes with comments and discussions on these statistical models.
13.1. Overview of structural equation modeling
SEM is a statistical technique that combines path analysis and factor analysis to estimate parameters in a well-specified causal model. With the specification of latent factors, SEM generally consists of two components in model specification and statistical inference. The first is the measurement component, which indicates how well the observed variables measure conceptual constructs or latent factors, and the second is the structural component, which specifies causal links between factors or variables. A causal diagram describes a causal model in which boxes are routinely used to indicate the observed variables and circles or ovals designate the latent factors. Causal relationships are denoted by lines and arrows. A typical structural equation model includes multiple equations containing the random variables, the structural parameters, and sometimes, the nonrandom variables. In SEM, the response variable in a given equation is referred to as the endogenous variable, which can appear as an explanatory variable in another, in which it is referred to as the exogenous variable. Sometimes, two variables are allowed to impact one another reciprocally, as indicated in the causal diagram by bidirectional arrows. For each response or endogenous variable, there is one structural equation, but an endogenous variable may appear as an explanatory variable in one or more of other structural equations.
There are three types of random variables in SEM: latent, observed, and disturbance/error. Latent random variables, also referred to as factors, are statistically pure because they are specified in a way as to be free of measurement error (Bollen, 1989). The latent factors represent concepts, either directly or indirectly observable, loading information on the error-prone observed variables. The structural parameters describe the causal relationships between the unobserved variables, between the observed variables, or between the unobserved and the observed variables.
The construction of a structural equation model starts with the specification of a latent variable model or a structural model that summarizes the relationships between latent variables or factors. A typical latent variable model is usually written as
where η is a  vector of the latent endogenous random variables, ξ is a
vector of the latent endogenous random variables, ξ is a  vector of the exogenous random variables, and ζ is a vector of the random errors representing omitted causes of the endogenous variables along with measurement error in the endogenous variables. Following the tradition of factor analysis, η and ξ are specified as the standardized random variables, thereby leading to E(η) = E(ξ) = 0. It is also assumed that ζ is homoscedastic, nonautocorrelated, and independent of ξ, and therefore, E(ζ) = 0 and cov(ζi, ζi ́) = 0 for i ≠ í.
vector of the exogenous random variables, and ζ is a vector of the random errors representing omitted causes of the endogenous variables along with measurement error in the endogenous variables. Following the tradition of factor analysis, η and ξ are specified as the standardized random variables, thereby leading to E(η) = E(ξ) = 0. It is also assumed that ζ is homoscedastic, nonautocorrelated, and independent of ξ, and therefore, E(ζ) = 0 and cov(ζi, ζi ́) = 0 for i ≠ í.
In the  coefficient matrix for the latent endogenous variables, denoted by
coefficient matrix for the latent endogenous variables, denoted by  , the main diagonal is always zero because a latent variable cannot be the cause of itself. The latent variable model assumes that (
, the main diagonal is always zero because a latent variable cannot be the cause of itself. The latent variable model assumes that ( ) is nonsingular, so that ()−1 exists. The Γ matrix, a
) is nonsingular, so that ()−1 exists. The Γ matrix, a  coefficient matrix for the latent exogenous variables, represents the direct effects of the exogenous variables on the endogenous latent variables. If ξ affects all elements in η, Γ contains no zero elements.
coefficient matrix for the latent exogenous variables, represents the direct effects of the exogenous variables on the endogenous latent variables. If ξ affects all elements in η, Γ contains no zero elements.
There are two covariance matrices generally specified in the latent variable model. Specifically, a  matrix
matrix  denotes the covariance matrix of ξ (the latent exogenous variables), whereas a matrix
denotes the covariance matrix of ξ (the latent exogenous variables), whereas a matrix  represents the variance–covariance matrix of ζ (latent errors). As generally defined, the elements of the main diagonal of are variances of the elements in η, with the off-diagonal elements being the covariance indices of elements in ζ.
represents the variance–covariance matrix of ζ (latent errors). As generally defined, the elements of the main diagonal of are variances of the elements in η, with the off-diagonal elements being the covariance indices of elements in ζ.
The measurement model specifies the relationships between the latent variables and the observed, or indicator, variables, executed and evaluated by means of confirmatory factor analysis. Let X be a M × 1 vector of the observed variables of ξ (the exogenous latent variables) and Y represent a r × 1 vector of the observed variables of η (the endogenous latent variables). In the matrix form, the measurement model of SEM is then given by
where the term ΛX is an  coefficient matrix relating X to ξ, and ΛY is a
coefficient matrix relating X to ξ, and ΛY is a  coefficient matrix relating y to η. In the tradition of factor analysis, ΛX and ΛY are also referred to as factor loadings relating X to ξ and relating Y to η, respectively. Similarly, the term δ is an M × 1 vector of measurement errors for X, and ɛ is an r × 1 vector of measurement errors for Y. In a standard SEM measurement model, each observed variable is allowed to load only on one factor, and therefore, its measurement error is not correlated with measurement errors of the other observed, or indicator, variables. With this specification, SEM sets up the assumptions that E(δ) = E(ɛ) = cov(δ, ɛ) = cov(δ, η) = cov(ɛ, η) = cov(δ, ξ) = cov(ɛ, ξ) = 0.
coefficient matrix relating y to η. In the tradition of factor analysis, ΛX and ΛY are also referred to as factor loadings relating X to ξ and relating Y to η, respectively. Similarly, the term δ is an M × 1 vector of measurement errors for X, and ɛ is an r × 1 vector of measurement errors for Y. In a standard SEM measurement model, each observed variable is allowed to load only on one factor, and therefore, its measurement error is not correlated with measurement errors of the other observed, or indicator, variables. With this specification, SEM sets up the assumptions that E(δ) = E(ɛ) = cov(δ, ɛ) = cov(δ, η) = cov(ɛ, η) = cov(δ, ξ) = cov(ɛ, ξ) = 0.
In the measurement model, there are two covariance matrices of measurement errors, generally denoted by  and
and 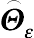 . Specifically, the term is an M × M matrix containing the error variance (diagonal) and covariance indices (off-diagonal) for X, and is a r × r matrix containing the error variance (diagonal) and covariance indices (off-diagonal) for Y. and can be specified either as diagonal matrices if the errors are assumed to be uncorrelated or as full matrices if the errors are assumed to be correlated. In the analysis of longitudinal data with SEM, as will be presented in the successive texts, these error terms are generally specified as correlated to handle intraindividual correlation.
. Specifically, the term is an M × M matrix containing the error variance (diagonal) and covariance indices (off-diagonal) for X, and is a r × r matrix containing the error variance (diagonal) and covariance indices (off-diagonal) for Y. and can be specified either as diagonal matrices if the errors are assumed to be uncorrelated or as full matrices if the errors are assumed to be correlated. In the analysis of longitudinal data with SEM, as will be presented in the successive texts, these error terms are generally specified as correlated to handle intraindividual correlation.
In the previous three basic SEM equations, there are eight parameter matrices to estimate: , Γ, Λx, Λy, , , , and . SEM is a statistical technique for formulating and estimating a set of model parameters contained in these eight matrices. The parameters can be specified either as fixed or as free, and only the free parameters need to be estimated from an SEM model. For example, the diagonal elements in the matrix are set at zero (a variable cannot be the cause of itself), and therefore, they are the fixed parameters. When all the specified variables in an SEM model, observed or latent, are standardized, each of the four covariance matrices becomes a correlation matrix, in which the diagonal elements take the value of one and the off-diagonal elements are correlation coefficients.
The estimating procedure for SEM is unique. Rather than minimizing the differences between the fitted and the observed response variables, SEM minimizes the differences between the sample variance–covariance indices and the variance–covariance estimates from the model. Given this unique approach, the specification of the covariance structure plays a crucial role in model specification, statistical inference, and the estimation of SEM parameters (Bollen, 1989). From the statistical standpoint, SEM is a perspective decomposing covariance indices and correlations in terms of the model parameters. For example, let Σx be the covariance matrix for X and ΣX be the expected value of XX́. With the equation X = Λxξ + δ, XX́ can then be expressed as
 (13.4)
(13.4)Corresponding, the expectation of XX́ is
 (13.5)
(13.5)In Equation (13.5), the covariance matrix of X, denoted by Σx, is decomposed into the elements in Λx, , and . The variance and covariance indices for YÝ and XÝ, respectively, can be decomposed by using the same approach. Such decomposition creates a foundation on further inferences on the estimation of the model parameters and hypothesis testing on the parameter estimates. Let Σ denote the population covariance matrix and Σ(θ) be a function of free parameters θ in a causal model, where
 (13.6)
(13.6)and

Then, the basic null hypothesis in SEM is given by
Given the previous null hypothesis, the goal of model estimation and model fit in SEM is to identify model parameters θ to yield Σ(θ) so that [Σ - Σ(θ)] can be minimized. As both Σ and Σ(θ) are unknown,  is actually minimized in SEM where S is the sample variance–covariance matrix,
is actually minimized in SEM where S is the sample variance–covariance matrix,  is a matrix containing the estimates of free parameters, and
is a matrix containing the estimates of free parameters, and  is the model-based variance–covariance matrix. While there are many fitting approaches for minimizing differences between S and , the most commonly used method in SEM is the maximum likelihood function, given by
is the model-based variance–covariance matrix. While there are many fitting approaches for minimizing differences between S and , the most commonly used method in SEM is the maximum likelihood function, given by
 (13.8)
(13.8)where ( ) is the number of the observed variables considered in an SEM model. As an efficient, robust, and consistent SEM estimator, the ML fitting function
) is the number of the observed variables considered in an SEM model. As an efficient, robust, and consistent SEM estimator, the ML fitting function  is asymptotically distributed as χ2 for large samples with asymptotic multivariate normality. If an SEM model is correctly specified, should be very close to S, thereby yielding efficient, consistent, and robust parameter estimates.
is asymptotically distributed as χ2 for large samples with asymptotic multivariate normality. If an SEM model is correctly specified, should be very close to S, thereby yielding efficient, consistent, and robust parameter estimates.
The earlier specifications summarize the basic theory of a linear SEM. More recently, there are new developments of the SEM methodology in the analysis of categorical outcome data, adjustment of nonnormality, and missing data. With a massive body of specifications, estimating procedures, various supplementary techniques to handle identification problems, and other techniques in SEM, it is impossible to describe the entire set of this methodology in this text. For details concerning the basic SEM, the advances, and its applications with a variety of statistical software packages, the interested reader is referred to Arbuckle (2006), Bentler (1995), Bollen (1989), Jöreskog et al. (1999), Muthén and Muthén (2008), and Wang and Wang (2012).
13.2. Latent growth model
The LGM adapts repeated measurements of the response into the SEM system (McArdle, 1988; McArdle and Epstein, 1987; Meredith and Tisak, 1990). As briefly indicated earlier, LGM views the intercept and the slope of time as two latent factors representing the initial level of the outcome measurement (intercept) and the rate of change in the outcome growth trajectory (slope), respectively. Repeated measurements of the outcome variable for subject i, denoted by  , are specified as multiple indicators of the two latent factors, and consequently, the factor loadings on the slope factor determine the form of longitudinal trajectories in y. Given such a specification, the LGM is also referred to as the latent curve model (Meredith and Tisak, 1990) or the LGCM (Muthén, 2004). As an SEM-type method, the LGM is based on the mean vector and the covariance matrix like the general SEM.
, are specified as multiple indicators of the two latent factors, and consequently, the factor loadings on the slope factor determine the form of longitudinal trajectories in y. Given such a specification, the LGM is also referred to as the latent curve model (Meredith and Tisak, 1990) or the LGCM (Muthén, 2004). As an SEM-type method, the LGM is based on the mean vector and the covariance matrix like the general SEM.
The focus of LGM is placed upon an average development over time and individual variability around this average. Let all vectors of Yi be combined into Y as applied previously. It follows that η is defined as a 2 × 1 block vector of the latent components consisting of the intercept component, denoted by η0, and the linear slope component, denoted by η1. The basic LGM with a linear slope component is
where ɛ is a block vector of measurement errors,  is a 2 × 1 block vector of the expected values of η, and ζ contains random variables configuring individual developments. In this LGM, the specification of the latent intercept and slope factors is much like the specification of the random effects for the intercept and the slope of time in linear mixed models (Raudenbush and Bryk, 2002). In the longitudinal setting, the two specified latent factors inherently account for intraindividual correlation, just like the specification of the random effects in mixed-effects modeling. Therefore, LGM possesses decent capability to yield statistically efficient, consistent, and robust parameter estimates in longitudinal data analysis. In some sense, LGM can be understood as an adaptation of linear mixed models to an SEM framework.
is a 2 × 1 block vector of the expected values of η, and ζ contains random variables configuring individual developments. In this LGM, the specification of the latent intercept and slope factors is much like the specification of the random effects for the intercept and the slope of time in linear mixed models (Raudenbush and Bryk, 2002). In the longitudinal setting, the two specified latent factors inherently account for intraindividual correlation, just like the specification of the random effects in mixed-effects modeling. Therefore, LGM possesses decent capability to yield statistically efficient, consistent, and robust parameter estimates in longitudinal data analysis. In some sense, LGM can be understood as an adaptation of linear mixed models to an SEM framework.
The original LGM assumes the slope component to be the same for all individuals, with population heterogeneity in longitudinal trajectories being primarily reflected by variations in the scale of the univariate pattern (Bollen and Curran, 2006; McArdle and Hamagami, 1992). Such a model without including any covariates is referred to as the unconditional LGM. Empirically, some variables might influence trajectories of the outcome variable, and therefore, covariates often need to be considered in specifying a LGM. In the LGM framework, covariates can be introduced into the model specification and statistical inference as the predictors on , thereby adding level-2 equations in the specification of the latent intercept and slope factors. With the inclusion of the observed covariates, the expected values of η can be predicted by using the estimated latent factor-scoring coefficients. As a result, Equation (13.11) can be rewritten as
where  denotes the factor-scoring coefficients that can be estimated by applying the scoring technique in factor analysis. Such a covariate coefficient reflects the expected change in the response variable with a one-unit increase in a specific covariate, other covariates being equal. Therefore, the elements in can be interpreted in the same fashion as for the regression coefficients in linear mixed models. The X matrix can include one or two predictor variables of interest and several theoretically relevant control variables that might be centered at sample means for analytic convenience. Given the specification of model covariates to influence the latent factor parameters, the LGM with a linear slope component can be rewritten as
denotes the factor-scoring coefficients that can be estimated by applying the scoring technique in factor analysis. Such a covariate coefficient reflects the expected change in the response variable with a one-unit increase in a specific covariate, other covariates being equal. Therefore, the elements in can be interpreted in the same fashion as for the regression coefficients in linear mixed models. The X matrix can include one or two predictor variables of interest and several theoretically relevant control variables that might be centered at sample means for analytic convenience. Given the specification of model covariates to influence the latent factor parameters, the LGM with a linear slope component can be rewritten as
It can be readily recognized that the previous LGM specification bears a tremendous resemblance to that of linear mixed models in many ways. As indicated earlier, the two latent factors are akin to the random effects for the intercept and the slope of time, respectively. Notice that in the previous two equations, the X matrix only contains the exogenous predictors of the latent curve parameters, and therefore, the time factor cannot be incorporated.
The matrix Λ in LGM is analogous to Z, the design matrix in mixed-effects models, given by

The covariance matrices of ɛ and η = (η0, η1)′ are specified as
and

respectively. As following the tradition of SEM, LGM assumes E(ɛ) = E(ζ) = 0 and  . Correspondingly, the expectation and the covariance matrix of the observed outcome variables y are given by
. Correspondingly, the expectation and the covariance matrix of the observed outcome variables y are given by
where 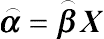 if covariates are specified.
if covariates are specified.
The previous LGM consists of the first two polynomial functions, but the model can be extended to a nonlinear trajectory by using higher-order polynomial terms. In many ways, LGM is similar to the standard SEM, with the common advantage that the measurement error is isolated by the estimation of error variances.
Given the assumption of multivariate normality for y, the latent and the error components are assumed to be normally distributed. The distribution of the observations of n × 1 vector y then can be defined as
where
Let τ be a vector containing all free parameters in , , and  such that
such that  . It follows that the parameters contained in τ can be estimated by applying the maximum likelihood approach. For this estimator, the log-likelihood function can be written as
. It follows that the parameters contained in τ can be estimated by applying the maximum likelihood approach. For this estimator, the log-likelihood function can be written as
 (13.16)
(13.16)where

The earlier theory-based model is then compared with an unrestricted model that has a log-likelihood function
 (13.17)
(13.17)The fit function of the likelihood ratio of log L and log Lu is
 (13.18)
(13.18)Minimizing the previous likelihood ratio fitting function yields the ML estimates for parameter vector τ. Asymptotic standard errors of the parameter estimates can be approximated by the square roots of the diagonal elements in the inverse of the observed Fisher information matrix with respect to τ. Like the standard SEM, the ML fitting function for LGM  is asymptotically distributed as χ2 for large samples given asymptotic multivariate normality. The hypothesis test can be performed accordingly.
is asymptotically distributed as χ2 for large samples given asymptotic multivariate normality. The hypothesis test can be performed accordingly.
For empirical practices, estimation of the model parameters can be performed by using a variety of SEM programs, such as LISREAL (Jöreskog et al., 1999), EQS (Bentler, 1995), Amos (Arbuckle, 2006), Mplus (Muthén and Muthén, 2008), and the PROC CALIS procedure in SAS. As it accounts for the correlation of the initial status and the growth rate as well as their relations with time-varying and time-independent covariates, this method has seen widespread applications in behavioral and social sciences, particularly in psychological research.
13.3. Latent growth mixture model
The LGM is based on the assumption that all individuals in a given population follow the same pattern of change (using jargon in latent growth modeling, it is referred to as the growth pattern). With this restrictive hypothesis, a single growth trajectory can adequately approximate an entire population. In many situations, LGM is thought to be unrealistic because heterogeneous growth patterns often exist in longitudinal trajectories of the response. Ignoring such unobserved heterogeneity can result in biased parameter estimates and erroneous predictions. The LGMM, is an SEM technique that relaxes the single population hypothesis by assuming two or more subpopulations with distinctive patterns of growth but unknown beforehand (Muthén and Muthén, 2000). Statistically, LGMM views the overall distribution of observations as a mixture of heterogeneous distributions for a finite number of subpopulations, as briefly indicated in Chapter 7.
Technically, LGMM is simply an extension of LGM. First, a linear LGM model is specified for each subpopulation k where k = 1, 2,…, K, written as
where
and
The earlier two equations display that differences in growth patterns over K latent classes are accounted for by variations in the expectation vector of latent components  , the covariance matrix of latent components
, the covariance matrix of latent components  , and the covariance matrix of measurement errors
, and the covariance matrix of measurement errors  . The differences in define the level and the pattern of variations in longitudinal trajectories of y across different classes. As specified for LGM, when covariates are included in LGMM,
. The differences in define the level and the pattern of variations in longitudinal trajectories of y across different classes. As specified for LGM, when covariates are included in LGMM,  , where
, where 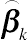 denotes the factor-scoring coefficients of the covariates contained in X specified for latent class k.
denotes the factor-scoring coefficients of the covariates contained in X specified for latent class k.
Compared to LGM, there is an added dimension of model parameters to the estimates of LGMM – the proportions of K latent classes in a given population, denoted by  , which need to be accounted for in statistical inference and the estimating process. Specifically, there are K − 1 additional free parameters to be estimated given the restriction
, which need to be accounted for in statistical inference and the estimating process. Specifically, there are K − 1 additional free parameters to be estimated given the restriction

With the addition of the estimating steps for the number of latent classes, the specification of LGMM can start by letting  and
and  to make the model estimable and identifiable. That is, for analytic simplicity, equal covariance matrices may be assumed first for all latent classes. Sometimes, the researcher can fix the insignificant parameter estimates to zero to reduce the number of free parameters for a complex structural equation model. Furthermore, there are some statistical techniques to determine the optimal number of latent classes, as will be described in Section 13.4.
to make the model estimable and identifiable. That is, for analytic simplicity, equal covariance matrices may be assumed first for all latent classes. Sometimes, the researcher can fix the insignificant parameter estimates to zero to reduce the number of free parameters for a complex structural equation model. Furthermore, there are some statistical techniques to determine the optimal number of latent classes, as will be described in Section 13.4.
LGMM uses the maximum likelihood approach to estimate free parameters by means of an EM algorithm (Muthén and Shedden, 1999). Specifically, the estimation consists of two steps: the estimation of the parameters related to the LGM and the estimation of the proportions of the specified latent classes. The log-likelihood function of the observed data for LGMM is
 (13.21)
(13.21)
 (13.22)
(13.22)The density function for class k is defined by
where

Let  be the class information vector for subject i where
be the class information vector for subject i where  if subject i belongs to class k and
if subject i belongs to class k and  if otherwise. The conditional density function for subject i is then given by
if otherwise. The conditional density function for subject i is then given by
be the class information vector for subject i where
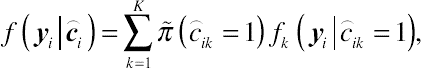 (13.24)
(13.24)where

When the class information  is known, the complete-data log-likelihood expands to the following log-likelihood expression:
is known, the complete-data log-likelihood expands to the following log-likelihood expression:
 (13.25)
(13.25)Clearly, Equation (13.26) consists of two independent components in maximization of the complete-data log-likelihood: the sum of the weighted K class probabilities  and the sum of the weighted K density function
and the sum of the weighted K density function  (Muthén and Shedden, 1999). Therefore, LGMM is essentially an empirical Bayes model.
(Muthén and Shedden, 1999). Therefore, LGMM is essentially an empirical Bayes model.
When maximization of the log-likelihood is performed with the EM algorithm, the latent class information is considered missing. As indicated in Chapter 4, the EM algorithm consists of the expectation step (E-step) and the maximization step (M-step). In the LGMM context, with E-step, the expected probabilities of the observations belonging to each latent class are computed given starting values of the parameters, and the posterior probabilities are then used in the M-step that maximizes the expected values specified in Equation (13.26). As a standard application, the iteration of the E- and the M-steps continues until the convergence criterion is met, thereby deriving the ML estimates of the  parameters. As the basic theory and the estimating procedure of EM are described extensively in Chapter 4, I will not further elaborate on the specifications and statistical inference of the EM algorithm.
parameters. As the basic theory and the estimating procedure of EM are described extensively in Chapter 4, I will not further elaborate on the specifications and statistical inference of the EM algorithm.
The general LGMM algorithm can be extended to analyze categorical outcome variables with repeated measurements and longitudinal transitions between latent classes. Model covariates in LGMM may include both the continuous and the categorical variables with different link functions. The reader interested in more details about LGMM is referred to Muthén (2001), Muthén and Muthén (2008), Muthén and Shedden (1999), and Wang and Wang (2012).
13.4. Group-based model
The LGMM is a statistical perspective that is to the extreme of GEEs in terms of model specifications and statistical inferences. While GEEs are meant to derive population-averaged effects without specifying the between-subjects random effects, the LGMM is intended to model every detail in longitudinal processes. While GEEs can potentially lead to serious bias in nonlinear predictions, as discussed in Chapter 9, excessive elaboration in statistical modeling does not necessarily usher in an unbiased model (Box, 1976; Liu, 2012). A recent effort to simplify the complex LGMM is the development of the group-based model.
The development of the group-based model is enlightened by a nonparametric model on the distribution of unobserved heterogeneity developed by Heckman and Singer (1984). According to Heckman and Singer, any continuous distribution with finite end points can be approximated by a finite number of “points of support.” For any given number of such points, this approach specifies two sets of the parameter estimates: the first set identifies the location on the x-axis of each point of support (the discrete realization of a continuous distribution), and the second set measures the proportion of the population at each point of support. Based on the rationale of this nonparametric perspective, the group-based model identifies distinctive growth trajectories from empirical data. Empirically, the group-based model can be applied to a wide range of applied fields, especially in social and behavioral sciences. More recently, the group-based model is used to model disability trajectories (Dodge et al., 2006; Gill et al., 2010; Liang et al., 2010; Zimmer et al., 2012).
Like LGMM, the group-based model assumes that individual differences in growth trajectories are summarized by K different polynomial functions of age or time. Let  be the longitudinal sequence of outcome measurements for subject i over ni time points, denote the probability of group membership for group k (k = 1,…, K), and pk (yi) represent the conditional probability of yi given membership for group k. It follows that the probability to observe the longitudinal sequence of the response measurement for subject i is given by
be the longitudinal sequence of outcome measurements for subject i over ni time points, denote the probability of group membership for group k (k = 1,…, K), and pk (yi) represent the conditional probability of yi given membership for group k. It follows that the probability to observe the longitudinal sequence of the response measurement for subject i is given by
be the longitudinal sequence of outcome measurements for subject i over ni time points,
 (13.26)
(13.26)In Equation (13.27), the unconditional p(yi) is expressed as the weighted average of the probabilities of yi across K groups, with used as weight. For the specific group k, pk (yi) is the probability density function (p.d.f.) of yij given membership k, assuming conditional independence of sequential realizations of the elements in yi over ni time points. That is, in the group-based model, repeated measurements of the response are assumed to be serially uncorrelated with the specification of a finite number of latent groups (Nagin, 2005). Therefore, pk (yi) is given by
 (13.27)
(13.27)The conditional independence hypothesis in the group-based model highlights its major difference from the LGM and LGMM approaches. According to Nagin (2005), the specification of pk (yij) accounts for dependence, thereby reflecting information of unobserved heterogeneity across population members, just like the assumption of conditional independence given the specification of the random effects in linear mixed models.
The distributional function of pk (yij) depends on the type of the outcome data. Three outcome data types are particularly specified in the group-based model: for numeric outcome measures, the distribution is defined as normally distributed or a censored normal distribution. For count outcome data, it is assumed to follow the Poisson distribution or zero-inflated Poisson (ZIP) distribution if the value of 0 does not reflect the true score. Lastly, for binary data it is defined as the binary logistic distribution. For each outcome data type, a corresponding likelihood function is specified to derive the parameter estimates. As the likelihood function for each data type follows the standard procedure in the literature of applied statistics or of econometrics, I do not elaborate detailed inferences in this text. The interested reader is referred to Land and Nagin (1996), Nagin (1999, 2005), and Nagin and Land (1993).
In the group-based model, pk (yij) is specified as a polynomial function of time. A set of parameters estimated for the polynomial function determines the shape of growth trajectories, analogous to the description in Chapter 3. This specification indicates that time is treated as a continuous variable and the combination of the polynomial components can take a variety of trajectory shapes.
The group membership probability, , is expressed in terms of a multinomial function, written as
 (13.28)
(13.28)where θk is a set of base parameters, estimated from a multinomial logit model without covariates. By definition, the values of across K groups sum up to unity, and therefore, K − 1, rather than K sets of model parameters, need to be estimated, with one contrast group set as zero.
With the specification of a finite mixture perspective, a critical issue in the group-based model is to identify the optimal number of latent classes. After various polynomial time functions are tested and determined for a number of specified trajectory groups, a set of models with different numbers of groups must be estimated and compared statistically to identify the model with the optimal number of groups. In this comparison, the likelihood ratio statistic is not appropriate because the degrees of freedom in various polynomial functions are considered to be indeterminate. The BIC, described in Chapter 4, is recommended for the model comparison, with a value of BIC that is close to zero indicating a better model fit in the construct of the group-based model. A Bayes-type statistic, referred to as the Bayes factor, is recommended to measure the posterior odds between two models, based on which the better one can be determined. According to Nagin (2005), a Bayes factor of one implies that the two models are equally likely to be the correct model, whereas a Bayes factor of ten implies that one model is ten times more likely than the other.
The change in BIC between two models may be used to approximate the log of the Bayes factor. This score of change is interpreted as a scale of evidence with the following standard: 0–2: not worth mentioning; 2–5: positive; 6–10: strong; and >10: very strong. As computation of the Bayes factor is usually very difficult, Nagin (1999, 2005) recommends the use of a simplified statistic for the selection of a model with the optimal number of latent classes, referred to as the “probability of correct model.” Consequently, with a number of different models being considered, the optimal number of K can be adequately determined. For details about the Bayes factor and the computation of the probability of correct model, the reader is referred to Jones et al. (2001) and Nagin (1999, 2005).
After the correct model with an optimal number of groups is identified, the posterior probabilities of group membership for each subject can be estimated, along with the population proportion () that conforms most closely to each trajectory group. As the trajectory groups are unobserved, a subject’s actual group membership is not known with certainty. Instead, the probability that each subject in the sample belongs to a specific group can be estimated by
 (13.29)
(13.29)where 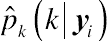 is the estimated probability of subject i’s membership in group k given yi, and
is the estimated probability of subject i’s membership in group k given yi, and  is the estimate of the population proportion in group k. If a group-based model is correctly specified, the estimated population proportion should be close to the sample group membership percentage.
is the estimate of the population proportion in group k. If a group-based model is correctly specified, the estimated population proportion should be close to the sample group membership percentage.
The relationship between the probability of group membership and covariates can be specified by the multinomial logit model if K > 2, given by
 (13.30)
(13.30)where the covariate vector X is used to predict the probability of group membership. As the exact membership is unknown, in the previous specification subjects are not categorized into trajectory groups; rather, is linked to covariates jointly with the estimation of trajectories. Correspondingly, Equation (13.31) can be substituted into Equation (13.27), the individual-level likelihood function in the group-based model, written as
 (13.31)
(13.31)Maximizing the log form of the previous likelihood over all subjects yields the estimates of parameter vector θk, measuring the effects of X for each . Hypothesis testing on the parameter estimates, including local tests with respect to the effects of covariate on the multinomial outcomes, can be performed with the standard procedures described previously. For each subject, group membership probabilities can be predicted by applying the standard procedure described in Chapter 11 (Section 11.1). The corresponding variance–covariance matrix and confidence intervals are obtainable either by applying the delta method or by applying the bootstrap technique as recommended by Nagin (2005).
Notice that in Equation (13.32), the likelihood function does not include a term for exact membership because the “exact” probabilities cannot easily translate into the “exact” responses. While the classical multinomial logit modeling is based on a set of exact responses, in the group-based model the multinomial function is specified to model the response probabilities. Statistically, the probability of membership for a specific group simply represents a predicted propensity score given values of the covariates. In reality, it is possible that an individual with a very high propensity score for one group actually belongs to another with a low likelihood (Nagin, 2005). Only when the value of a propensity score approaches unity can an individual’s group membership be exactly identified.
Empirically, a SAS PROC TRAJ algorithm, an independently designed SAS program not formally included in the SAS–STAT software, can be used to fit a variety of group-based models, including the group-based normal, the group-based censored normal, the group-based logistic regression, and the group-based Poisson models. The reader interested in using this SAS programming algorithm is referred to Jones and Nagin (2007) and Jones et al. (2001).
13.5. Empirical illustration: effect of marital status on ADL count among older Americans revisited
In this illustration, I reanalyze the relationship between marital status and disability severity among older Americans by using the latent growth technique. The LGM, described in Section 13.2, is selected for the illustration, particularly since the LGMM and the group-based model are both the extensions of the original LGM work developed by McArdle (1988), McArdle and Epstein (1987), Meredith and Tisak (1990). The longitudinal data from the AHEAD survey are used for this illustration with 2000 selected cases. As described previously, data of six equally spaced time points are used, starting with the 1998 wave (1998, 2000, 2002, 2004, 2006, and 2008). The outcome variable is the health-related difficulty in performing five ADLs (dress, bath/shower, eat, walk across time, get in/out of bed), which is measured at six time points and named ADL_COUNT in the analysis. As specified, the ADL count at each time ranges from 0 to 5.
In performing the LGM, repeated measurements of the ADL count for each subject are specified as multiple indicators of the two latent factors. As a result, repeated measurements of ADL_COUNT are structured as multivariate, and correspondingly, the data used for the present analysis are organized into a multivariate or a wide table format. As defined, the factor loadings on the intercept factor determine the initial level of the trajectory of the ADL count and those on the slope factor determine the shape of the trajectory. The inclusion of a main effect predictor on both the latent curve factors reflects an interaction between the covariate and time, as indicated in Bollen and Curran (2006). In this analysis, marital status is specified as the main exogenous predictor of the latent curve parameters, and therefore, this indicator variable is assumed to load on both the intercept and the slope latent factors. To make an adjustment in accordance with the multivariate data structure, the dichotomous variable, MARRIED, is fixed at baseline, with 1 = married in 1998 and 0 = else. The three centered variables, Age_mean, Educ_mean, and Female_mean, are included in the LGM as the additional exogenous predictors, assumed to be related to the intercept factor but not to the slope latent factor.
The previous model specifications on the relationships between the exogenous and the endogenous factors correspond to those specified for the linear mixed model of the preceding illustrations. The resulting structural equations are written as

where F_INT and F_TIME are the two latent factors representing the initial ADL count (intercept) and the rate of change in this response variable (slope), respectively, assumed to be bivariate normal. The error term ej is assumed to vary over time. In the second and the third equations, the  denote the factor-scoring coefficients of the observed exogenous variables. The two random variables
denote the factor-scoring coefficients of the observed exogenous variables. The two random variables  and
and  , defined in Section 13.2, are used to configure individual developments.
, defined in Section 13.2, are used to configure individual developments.
A variety of SEM programs can be applied to generate analytic results of the previous LGM, such as LISREAL, EQS, Amos, Mplus, and the PROC CALIS procedure in SAS. To be consistent with the computer programming approach throughout the other chapters of this text, the SAS PROC CALIS procedure is selected for the earlier LGM. Unfortunately, there is no option in this procedure to yield predictions directly on repeated measurements of the outcome variable. This problem, however, can be resolved by computing the latent scores first with the use of the scoring technique in factor analysis, and then employing the results of this step to compute the ADL_COUNT predictions at the six time points. The first step, computation of the scoring coefficients, is performed by the following SAS program.
SAS Program 13.1a:. . . . . .

. . . . . . In SAS Program 13.1a, I first create the temporary data file TP1 from the original AHEAD dataset containing 2000 selected cases (AHEADALL_2000). In this data step, the three centered exogenous variables are constructed. Next, I conduct the LGM on the multivariate AHEAD data by invoking the PROC CALIS procedure. In the PROC CALIS statement, the METHOD = ML option tells SAS to apply the maximum likelihood approach for parameter estimation given the normality hypothesis. The MAXITER = 1000 option specifies the maximum number of iterations to be 1000 in the optimization process. The option NOSTAND is given to suppress printing of standardized results. Lastly, the OUTSTAT = STAT option creates an output dataset, named STAT, containing the latent factor scoring regression coefficients, from which the latent variables can be predicted by using the PROC SCORE procedure.
In the PROC CALIS procedure, the LINEQS statement is used for model specifications, equivalent to the MODEL statement in the PROC MIXED procedure. The variables R4ADLA to R9ADLA are the original outcome measurements of the ADL_COUNT at the six time points, contained in the original AHEAD dataset. The f_INT and f_TIME variables are the latent factors representing the random intercept and the random slope of time, respectively. The f_prefix is required in the LINEQS statement to indicate a latent variable. As the default, in the LINEQS statement, the fixed intercepts for the endogenous variables need to be set at zero by the 0* Intercept specification; otherwise, the LGM might be over-parameterized, thereby deriving erroneous parameter estimates.
As the repeated measurements of the ADL count are equally spaced, integer values 0–5 are assigned to indicate the six time points – T1, T2, T3, T4, T5, and T6, respectively – in the equations of the LINEQS statement. As indicated earlier, the intercept latent factor loads on all four exogenous variables, whereas the slope factor only loads on marital status, specified in the two level-2 equations in SAS Program 13.1a. In the two predicting equations, d1 and d2 represent the two random variables and , respectively. The variances of the two latent variables are specified in the VARIANCE statement, whereas the covariance between d1 and d2 is specified in the COV statement. The error variances for e1 to e6 are also specified in the VARIANCE statement, with six unconstrained, time-dependent variance parameters. If error variances are specified to be common, the specification of the error variances should be written as e1−e6 = 6* EVAR, assuming an equal error variance across time.
With the specification of the structural equations, the temporary data file STAT2 is created from the output file STAT to compute the latent scores for each subject. The PROC SCORE procedure in SAS multiplies values from two datasets, one containing raw data (DATA = TP2) and the other containing the factor-scoring coefficients (SCORE = STAT2). As a result of this multiplication, a new SAS dataset, FOUT3, is created, containing linear combinations of the coefficients and the raw data values as well as the predicted values of the f_INT and f_TIME factors for each subject.
SAS Program 13.1a produces a large amount of output, with the main results being displayed below. The presentation of these results starts with the basic information of the LGM.
SAS Program Output 13.1a:

In SAS Program Output 13.1a, the raw dataset is identified as TP2, the model type is structural equation modeling, and the analysis is about the means and the covariance indices. In the Variables in the Model table, the specified endogenous and exogenous variables are listed. Out of 2000 cases included in the original data, only 557 cases are used in the application of the LGM. Obviously, due to the involvement of latent factors, the application of the PROC CALIS procedure does not include the cases whose ADL_COUNT value is missing at any time point. Consequently, only the sample with complete information of the ADL repeated measurements is used. In missing data analysis, the approach to remove all cases with missing data is referred to as the complete case analysis or list-wise deletion, with its validity corresponding to the MCAR hypothesis (this method will be formally described and discussed in Chapter 14). In the application of LGM, as is also the case for other longitudinal models, this approach often causes serious problems in the estimation of model parameters (Allison, 2003; Little and Rubin, 2002). In this analysis, the sample containing only the cases with complete information is perhaps not representative of older Americans, thereby very likely to yield unreliable parameter estimates and erroneous model-based predictions. With the focus of this illustration placed on the application of a statistical technique, the correction of such bias is currently not of concern.
It must be indicated, however, that in actual empirical analyses, there are options to handle missing data in the application of the LGM. For example, the direct maximum likelihood approach can handle missing data under the MAR hypothesis (Allison, 2003; Bollen and Curran, 2006; McArdle and Hamagami, 1992; Muthén and Muthén, 2008). In this approach, given the multivariate normality hypothesis, the likelihood function is computed for each case by using only the variables available to the case. Sometimes, the EM algorithm, described extensively in Chapter 4, is applied (Muthén and Muthén, 2008). Another popular MAR perspective to handle missing data in the LGM is to apply multiple imputation techniques prior to a formal analysis (Schafer, 1997; Rubin, 1987). This flexible statistical approach generates multiple datasets from the observed data for missing items given the MAR hypothesis and then is used to derive parameter estimates as the averages over the set of analyses.
When the MAR hypothesis on missing data does not hold, there are also some statistical techniques available for MNAR in growth modeling (Enders, 2011; Little, 2009; Muthén et al., 1987, 2011), including selection and pattern mixture models. A number of SEM statistical programs, such as Mplus, implement these techniques to handle such missing data mechanisms.
Next, the information about the model fit is presented. There are a number of fit statistics produced from the PROC CALIS procedure, with all indices leading to the same conclusion regarding the model fit. Therefore, for illustrative simplicity, only the chi-square value in the fit summary table is displayed.
SAS Program Output 13.1b:

In the previous summary, the chi-square value is 214.80 (df = 35, p < 0.0001), statistically significant. As indicated earlier, SEM generates parameter estimates by minimizing the differences between the sample variances–covariance matrix and the model-based variance–covariance estimates. Therefore, with regard to the present SEM-type model, the chi-square value reported earlier indicates a poor model fit. More complex structural equation specifications need to be proposed to generate an acceptable model fit. Given the focus on an empirical illustration for the practice of LGM, however, this issue is currently not of direct concern, and therefore, I opt to proceed with the presentation of the table for the ML estimates of the factor-scoring coefficients, as shown below.
SAS Program Output 13.1c:

In SAS Program Output 13.1c, the nonrandom factor-scoring coefficients of the exogenous variables are displayed. The mean intercept values to predict the f_INT and f_TIME factors are 0.1951 (t = 4.4087) and 0.1137 (t = 6.8769), respectively, both statistically significant. The factor-scoring regression coefficients of marital status on the latent intercept and the slope factors are 0.0186 (t = 0.3094) and −0.0232 (t = −1.0734), respectively, both not statistically significant. The results for the three centered exogenous variables are consistent with those from the corresponding linear mixed model. The variance and covariance estimates are displayed in the following two tables.
SAS Program Output 13.1d:


In SAS Program Output 13.1d, the variance estimate of the latent factor f_INT, equivalent to the variance estimate of the random intercept term in linear mixed models, is 0.3103 (t = 11.9645). Likewise, the variance estimate of the latent factor f_TIME, equivalent to the variance estimate of the random effect for time in linear mixed models, is 0.0413 (t = 10.4048). Also shown in the first table are the unstrained, time-dependent error variances and the variance estimates of the four exogenous variables. All variance estimates are statistically significant. The covariance of the intercept and the slope factors is −0.0372 (t = 4.6266), displaying a statistically significant, negative correlation between the initial level and the individual rate of development in an older person’s ADL count.
Given the analytic results from SAS Program 13.1a, repeated measurements of the ADL_COUNT can be readily predicted for the subjects with complete information. Correspondingly, the growth curves of the ADL_COUNT can also be plotted and displayed. The following is the SAS program for this step.
SAS Program 13.1b:. . . . . .

In the DATA TP3 step, I first compute the expected values for the intercept and the slope of time by the analytic results reported in SAS Program Output 13.1c, which can be regarded as the fixed components to predict the ADL count. The three centered exogenous variables are not included in this computation as their values should be held at zero (sample means) in the predicting process. Next, the ADL_COUNT values are predicted by the fixed and the random components of the two latent factors. The predicted values of ADL_COUNT at the six time points are named ADL0, ADL1, ADL2, ADL3, ADL4, and ADL5, respectively. In the DATA TP4 step, the multivariate data are reorganized into the univariate format to derive growth curves. As applied previously, the PROC SGPLOT procedure is applied to generate the intraindividual growth curves. The resulting plot is displayed in Fig. 13.1.

Figure 13.1 Intraindividual Growth Curves of ADL Count: LGM
Figure 13.1 displays that generally the ADL count among older Americans increases over time, other variables being equal. The pattern of change over time, however, is widely dispersed and looks vague, and without the classification of subjects by marital status, there is no grounds to assess the effect of marital status on an older person’s disability severity. Therefore, Fig. 13.1 does not provide much information about the issue under assessment. One approach is to plot the growth curves separately for those married and those unmarried in 1998, as applied previously. The following SAS program is used for the derivation of the two plots.
SAS Program 13.2:. . . . . .

SAS Program 13.2 simply runs the same PROC SGPLOT procedure as SAS Program 13.1b except for the classification of subjects into two marital status groups with the WHERE MARRIED_98 = 0 and the WHERE MARRIED_98 = 1 statements. Figures 13.2 and 13.3 display the results.

Figure 13.2 Intraindividual Growth Curves of ADL Count for Those Unmarried in 1998: LGM

Figure 13.3 Intraindividual Growth Curves of ADL Count for Those Married in 1998: LGM
The previous two figures present the individual growth curves for those married and not married in 1998, respectively. Each plot displays a generally increasing pattern of change over time in the ADL count, similar to that shown in Fig. 13.1. The differences in the changing pattern between the two figures are vague, and therefore, no constructive conclusions can be made. It may be more useful to display the population-averaged time plot of trend for the two marital status groups. The following SAS program is constructed to generate the population-averaged ADL counts for the two population groups.
SAS Program 13.3:

In SAS Program 13.3, the PROC SQL procedure updates the temporary SAS data file TP4. In this procedure, I compute the predicted mean of the ADL count, named ADL_PRED, for each marital status group and at each time point by using the GROUP BY TIME, MARRIED_98 clause. The mean ADL count is also computed by the PROC MEANS procedure. In the PROC SGPLOT procedure, the option GROUP = MARRIED_98 asks SAS to plot a population-averaged growth curve for each marital status group. Table 13.1 displays the predicted mean of the ADL count for the two marital status groups at six time points.
Table 13.1
Predicted Mean Values of ADL Count at Six Time Points from LGM for Those Married and Not Married in 1998
| Time (T j ) | Married in 1998 | Not Married in 1998 | ||
| Prediction | Standard Error | Prediction | Standard Error | |
| 0 | 0.1880 | 0.4359 | 0.2318 | 0.5905 |
| 1 | 0.2682 | 0.4333 | 0.3590 | 0.5589 |
| 2 | 0.3484 | 0.4799 | 0.4863 | 0.5924 |
| 3 | 0.4285 | 0.5637 | 0.6135 | 0.6815 |
| 4 | 0.5087 | 0.6708 | 0.7408 | 0.8081 |
| 5 | 0.5888 | 0.7919 | 0.8680 | 0.9573 |

Table 13.1 presents that the predicted mean of the ADL count increases steadily over time, consistent for both marital status groups. At each time point, the ADL count is expected to be substantially higher among those not married in 1998 than those married in the same year, other variables being equal. These predictions at each time point, however, are distinctively lower than those from the corresponding linear mixed model, with much elevated standard errors (see Chapter 5). The poor quality of these predictions is due to the fact that the subjects with complete information of the ADL_COUNT throughout the entire observation period are those who have survived to respond at all five follow-up time points. These completers are supposed to have lower disability severity scores than those deceased or missing during the period, as previously evidenced. Consequently, the predicted ADL count is severely under-predicted by using the case deletion approach in the LGM application. As the missing-data mechanism in this dataset is very likely to be MNAR, some statistical methods in the literature of longitudinal data analysis might need to be considered to handle MNAR. In Chapter 14, a number of methods on MNAR will be described, some of which can be borrowed for the application of LGM.
SAS Program 13.3 also derives the plot of two population-averaged growth curves for the two marital status groups, displayed in Fig. 13.4.

Figure 13.4 Time Plots of Predicted ADL Means for Currently Married and Currently Not Married: LGM
Compared to the corresponding growth curves from linear mixed models, presented previously, Fig. 13.4 displays two growth curves with much underestimated ADL_COUNT values. Interestingly, the pattern of change over time appears very close to the time trend from linear mixed models and so are the differences between the two subpopulations with a considerable separation between the two curves. As the latent slope factor is assumed to load on marital status, the two population-averaged growth curves are associated with different rates of change, with the mean ADL count among those married in 1998 increasing at a slower pace than their unmarried counterparts. Therefore, the case deletion approach applied in this analysis affects the estimation of the absolute scores of the ADL count but not the effect of marital status on trajectories. It may be worth mentioning that if strong unobserved heterogeneity is found to exist in the LGM results, the use of the latent growth mixture or the group-based model may be more appropriate to generate more reliable longitudinal trajectories of the ADL count.
13.6. Summary
The classical mixed-effects regression models, described in the preceding chapters, specify a variety of conditional models to describe longitudinal processes given model covariates and the specified random effects. These models are often expressed in terms of the marginal means by using Bayesian inference. Some scientists attempt to model such margins by specifying the random intercept and the random coefficient of time as latent factors in the SEM framework. In the literature of longitudinal data analysis, this innovative method is referred to as the LGM. Since its advent, LGM has been widely applied in behavioral and social science, particularly in psychological research. In empirical studies, the LGM methodology can be applied to describe the pattern of change over a period of time and the between-subjects variability.
In many ways, LGM is analogous to linear mixed modeling, though developed in the SEM framework (Raudenbush and Bryk, 2002). Both systems possess the capacity to handle intraindividual correlation, thereby deriving statistically efficient and robust analytic results in longitudinal data analysis. Although the original specification only concerns the initial level and the growth rate components, LGM is applicable for the analysis of the relationship between growth parameters and covariates. While linear mixed models estimate covariates’ effects in a classical, straightforward fashion, in LGM covariates are specified as the indicator variables loading on the two primary latent factors. With this extension, the LGM can be applied to analyze the effect of a predictor variable on the developmental trajectory of individuals. Due to the specification of latent factors, the LGM only uses cases with complete information of repeated measurements, while linear mixed models are more flexible by including all cases in the analysis. This issue can be resolved by applying some modern techniques in missing data analysis, both for the MAR and for the MNAR hypotheses.
The LGMM extends LGM by introducing latent classes in the model specification and statistical inference to model the developmental trajectory of individuals. This method assumes the inherent heterogeneity in a continuous distribution of the random effects, thereby resulting in additional parameters in an already complex statistical model. With such a proposition, there is sometimes a tendency to cause over-fitting in the estimating process, particularly when theoretically relevant covariates are included in the model. In many situations, when the large-sample behavior follows with the specification of latent intercept, the slope factor, and covariates, adding latent classes in statistical inference seems unnecessary. Statistically, if the initial level factor, the rate of change component, and the specified covariates can fundamentally explain variability in longitudinal trajectories of the response, there is no sufficient space remaining for further parameterization in residuals. Statistical modeling, both generally and with specific regard to longitudinal data analysis, is a process of abstraction, rather than a course of reflecting every detail in the response. If a parsimonious model with only a few parameters generates the same statistical power and the same substantive implications as a more complicated one, the former method is the signature of a good model and the latter a mediocre one (Box, 1976).
In some special situations, however, the application of LGMM is effective to capture exceptionally strong, unobserved heterogeneity that cannot be appropriately handled by just including covariates in linear mixed models or LGM (Jung and Wickrama, 2008; Muthén and Muthén, 2000). There are some prominent paradigms in this regard. Among older persons, a high proportion of missing cases are those deceased in a period of time, who are generally more physically frail and functionally dependent than survivors. In the presence of a strong selection effect, the multivariate normality hypothesis in linear mixed models, or LGM, can be violated. In such situations, the application of the LGMM may be more suitable than that of LGM to address exceptionally strong unobserved heterogeneity in modeling the growth curves.
Whereas LGMM is designed to account for individual variability about the mean of a mixture of population trends, the group-based model provides an alternative approach for identifying distinctive growth patterns (Nagin, 1999). There are some significant differences between LGMM and the group-based model in modeling the growth curves. First, in LGMM, the random effects are specified as following a continuous probability distribution based on large-sample theory; in contrast, the group-based model assumes the random effects to be multinomial by identification of a number of data points (Nagin, 2005). Heckman and Singer (1984) contend that this simplification is equally effective to handle heterogeneous duration patterns as the conventional approach. Second, the group-based model does not categorize individuals into a finite number of latent groups; instead, the model is designed to generate propensity scores of latent groups for each subject. As the elements absorbed into each class are statistically defined without exact substantive meanings, this specification sometimes causes difficulty in interpreting the effects of covariates on the trajectory of individuals. Only when one of the propensity score estimates is very close to unity, while the others are close to zero, can the regression coefficients be adequately interpreted. In criminological studies, where the group-based model was initiated for use, the propensity score estimates often display a clear-cut pattern, with one of the scores for each subject having a value very close to one. In these analyses, the researcher can confidently identify the class to which a subject belongs, thereby deriving important information with policy implications.
It must be emphasized that various methods in longitudinal data analysis are complementary, not competing, to each other. Which model is applied, with or without latent classes, mixed-effects or latent growth, should depend on the research questions the researcher seeks to answer. Recently, researchers in psychological science have shown an increasing interest in applying the latent growth methods to conducting longitudinal data analysis. Such a growing interest is partly due to the fact that many observed variables in psychological data are associated with serious measurement errors and specification of the theoretically relevant latent factors can considerably reduce bias in the analytic results. In biomedical and demographic sciences, the vast majority of observed variables are well defined and appropriately measured, and therefore, specification of the latent factors is unnecessary. Consequently, in those fields, the application of various mixed-effects models, described in the preceding chapters, is traditionally the mainstream in longitudinal data analysis.
..................Content has been hidden....................
You can't read the all page of ebook, please click here login for view all page.