
Chapter 2
Traditional methods of longitudinal data analysis
Abstract
In Chapter 2, I review a number of classical methods traditionally applied in longitudinal data analysis. First, several descriptive approaches are delineated, including time plots of trend, the paired t-tests, and effect sizes and their confidence intervals. Meta-analysis is also described, with the remaining issues in this technique being discussed. An illustration is provided for displaying how to apply those descriptive methods empirically. It is emphasized that due to the existence of lurking variables, the descriptive approaches cannot be used to generate final conclusions on an event of interest. Next, the basic specification of analysis of variance (ANOVA), assuming independence of observations, is presented, which is followed by the description of repeated measures ANOVA, with an empirical illustration on the method provided. Lastly, based on the general specification of multivariate analysis of variance (MANOVA), the repeated measures MANOVA is delineated. The limitations of the classical methods in longitudinal data analysis are discussed.
Keywords
Conditional independence
effect size
meta-analysis
repeated measures ANOVA
repeated measures MANOVA
time plots of trend
In longitudinal analysis, traditional methods and techniques are used to summarize the main features of raw longitudinal data without sophisticated adjustments on complex data structures and accounting for missing observations. Other than numbers, tables, plots, and some other simple statistics, the traditional approaches include the paired t-test on outcome scores at two time points, effect size (generally denoted by d), the analysis of variance (ANOVA) on repeated measures and the repeated measures multivariate analysis of variance (MANOVA). Although they are generally regarded as simplistic perspectives for longitudinal data analysis, these traditional approaches are sometimes applied to generate conclusions in biomedical and epidemiologic studies. In randomized controlled clinical trials, for example, results directly from a paired t-test are commonly used for summarizing final conclusions, particularly since in many of those studies, sample sizes are too small to consider a large number of parameters and the effects in longitudinal processes are partially accounted for in the process of randomization.
In this chapter, I introduce several popular traditional methods used in descriptive approaches including time plots of trends, the paired t-tests, and effect sizes and their confidence intervals. An empirical example is provided to illustrate how to use descriptive methods empirically. ANOVA is also provided with an empirical illustration. This is followed by the repeated measures MANOVA in longitudinal data analysis including more than one response variable. Lastly, a summary of these traditional methods is provided discussing their respective merits and limitations.
2.1. Descriptive approaches
Time plots of trends, paired two-time t-tests, effect sizes and the computation of confidence intervals around the effect size estimates are all descriptive statistics that can easily be calculated by hand. However, they do not consider correction for potential bias from missing observations.
2.1.1. Time plots of trends
In longitudinal data analysis, time plots have been frequently used to display the evolution of the response score along the time line. As the most basic, direct approach to delineate the pattern of change over time, time plots scale the outcome measurement at the ordinate of a graph as against the abscissa for a number of predesigned time points. A plot constructed this way displays how an outcome measurement changes over time, thereby providing information about trajectories or trends in the response.
There are two basic perspectives in terms of this simple technique that can be applied in empirical analyses. One describes the pattern of change over time for individuals, displaying development in the response measurement for each subject. The resulting longitudinal trajectories or curvatures of individuals give rise to a time plot of individual-based transitions, generally referred to as intraindividual growth patterns. Deviations in various intraindividual growth curves graphically display between-subjects variability in the response measurements. To compare general patterns of subject-specific growth across two or more population groups, the intraindividual time plots can be created separately by stratifying a discrete covariate, such as treatment, age group, gender, or race/ethnicity. Presentation of such subject-specific time plots is particularly valuable in the many disciplines where the principal concern of research is to identify particular individuals with unique values of the response measurement or those with high risk of experiencing a dynamic event. The fields in this category include, but are not limited to medicine, public health, biology, psychology, and criminology, in which the application of the intraindividual time plots approach is thereby popular.
The second time plots perspective is the description of time trends for a population. In this procedure, the researcher calculates the average of the response measurements at each of the predesigned time points and then presents the mean scores in a time plot. The resulting plot for the sequence of means over time describes the pattern of change in the mean response score for the entire population of interest. One can also compute the standard errors and corresponding confidence intervals, and then display these supplementary statistics simultaneously in the time plot. This population trend approach is useful in disciplines where the primary interest of research is in the entire population or a population subgroup, rather than in particular individuals. In social science, for example, the research interests are often in the pattern of change over time for a specific population, and the randomly selected individuals are simply elements for displaying population trends. In these disciplines, the pattern of change over time in the mean response and its dispersion are more informative than subject-specific trajectories. Furthermore, if the sample size is large, which is generally the case in observational studies, too many subject-specific growth curves will make a time plot extremely congested and thereby not help the researcher to generalize a pattern of change. By using time plots of trends for a specific population, the researcher can summarize and evaluate the general features of the measurement change over time, thus deriving useful information with policy implications. The researcher can also consider plotting the population trends for several population groups in a single graph, from which group differences in the pattern of change over time can be compared.
There are some distinctive differences between the intraindividual change and the population trends approaches. The population trend approach permits individuals in a given group to vary over time as some exit to another group, death, or out-of-scope residence, and newcomers enter. The population trend and the intraindividual change approaches answer different questions and address different scientific or policy goals; the two perspectives, however, are intertwined as aggregate change springs from individual ones (Verbrugge and Liu, 2014). In Section 2.1.4, we will provide an empirical example where two time plots, one presenting subject-specific transitions and one exhibiting the mean response measurements for two population groups, will be displayed.
The reader might want to bear in mind that by using raw longitudinal data, there are some restrictions concerning plotting of the time trend. The time plots described in this chapter are the most primitive, first-step approaches to describe longitudinal data. When missing data are substantial, many intraindividual curves are incomplete, and a time plot of population trends may be associated with tremendous bias. Second, the pattern of change over time shown in a time plot can be confounded by some other covariates thereby possibly reflecting a spurious association. Third, there is generally strong covariance among repeated measurements, both within a particular subject and for a population group. Without appropriately handling these restrictions, time plots of trends can be deceptive and misleading (Fitzmaurice et al., 2004). More sophisticated statistical methods are required to correctly plot time trends after adjusting for bias incurred from the above mentioned restrictions. More refined time plots will be displayed in the succeeding chapters, with each associated with a specific mixed-effects model.
2.1.2. Paired t-test
The time plots of trends provide a graphical approach to visually check the pattern of change over time in the response measurement. The statistical importance of such plots, however, needs to be verified analytically given some statistical criteria. The simplest method of the numeric checks on statistical significance of time trends is the paired t-test, also referred to as pre–post paired t-test in the biomedical literature. The t-test is a statistical test on a specific value that follows a Student’s t distribution if the null hypothesis is supported. There are a variety of t-tests used in different circumstances, such as a one-sample location test, unpaired or independent two-sample test, the paired or dependent two-sample test, and the test on the slope of a regression line. Given the focus on descriptive approaches, the latter category is not described in this chapter.
In statistics, the t-test statistic is an extension of the familiar z-score test, but used in hypothesis testing when population variances are unknown. The t-score takes the form t = z/s, where z is the z-score following a standard normal distribution under the null hypothesis and s is the sample standard deviation. The squared s, s2, follows a chi-square distribution with given degrees of freedom. Once a t value is obtained, a p-value can be readily determined using a table of Students’ t-distribution based on the appropriate degrees of freedom. If the calculated p-value is below α, the prespecified critical level of p, the null hypothesis about the value is rejected. The exact formulas for a test statistic differ on different data structures. In the longitudinal setting, a t-test is used to test the null hypothesis that the difference in the mean score between two time points has a mean value of zero. In biomedical research, a typical example is the repeated measurements of a patient’s blood pressure before and after a treatment. As the repeated measurements for the same subject are correlated, paired t-test should be applied on the pre- and posttest scores with the corresponding degrees of freedom defined as N/2 − 1 where N is the total number of observations at two times.
Let ˉYpre and ˉYpost
and ˉYpost be the mean scores of the response before and after a medical treatment for a sample of N patients. If the researcher wants to test whether the two mean scores are different, the null and the alternative hypotheses should be written as H0:ˉYpost=ˉYpre
be the mean scores of the response before and after a medical treatment for a sample of N patients. If the researcher wants to test whether the two mean scores are different, the null and the alternative hypotheses should be written as H0:ˉYpost=ˉYpre and H1:ˉYpost≠ˉYpre
and H1:ˉYpost≠ˉYpre , respectively, for a two-tail test. Suppose that the variances of the pre- and posttest mean scores are equal with the same sample size. The equation of the paired t-test is
, respectively, for a two-tail test. Suppose that the variances of the pre- and posttest mean scores are equal with the same sample size. The equation of the paired t-test is
t=ˉYpost−ˉYpresD/√N,
 (2.1)
(2.1)where sD is the sample standard deviation of the differences between all pre- and posttest pairs, and the denominator on the right of the equation is the corresponding standard error. The above statistic asymptotically follows a Student’s t distribution. Consequently, the corresponding p-value can be readily obtained from the distribution, generating results for testing the H0 hypothesis. If the t score is associated with a p-value smaller than α, the null hypothesis about the difference between ˉYpre and ˉYpost should be rejected; otherwise, the null hypothesis is accepted.
If the variances of the pre- and posttest mean scores are unequal and/or with different sample sizes, the following equation of the paired t-test can be used:
t=ˉYpost−ˉYpre√s2preNpre+s2postNpost,
 (2.2)
(2.2)where s2pre and s2post
and s2post are the sample variances of the pre- and posttest scores, respectively, and Npre, Npost are the sample sizes at the two time points. Equation (2.2) permits the researcher to use summary statistics for analyzing paired samples with data missing in one or the other samples. This convenient estimator using summary statistics, however, is based on the assumption that Ypre and Ypost for each subject are independent.
are the sample variances of the pre- and posttest scores, respectively, and Npre, Npost are the sample sizes at the two time points. Equation (2.2) permits the researcher to use summary statistics for analyzing paired samples with data missing in one or the other samples. This convenient estimator using summary statistics, however, is based on the assumption that Ypre and Ypost for each subject are independent.
In summary, the paired t-test provides a robust statistical test to determine the equality or difference of two means measured at two time points. It requires normality of the sample means and a scaled chi-square distribution for sample variances, with the two distributions assumed to be statistically independent. Based on the central limit theorem, the sample means usually tend to a normal distribution in probability even if the data are not normally distributed, as long as the sample size is large. When the longitudinal data deviates markedly from normality and/or the sample size is small, the paired t-test should be replaced by the Wilcoxon rank test for paired samples. If longitudinal data includes a large number of follow-up time points, the application of the paired t-test is not plausible to test a series of paired mean differences.
2.1.3. Effect size between two means and its confidence interval
The t-test statistic provides information of statistical significance based on the null hypothesis and the specified level of alpha. In the longitudinal setting, it compares the means at two time points to determine whether the value of the difference has a significant probability of being greater than zero. The binary conclusion from the significance test indicates that the difference between the two means is nonsignificant (null hypothesis is true) or significantly different from zero (null hypothesis is false). The t-test, however, does not address the magnitude of the effect once the null hypothesis is rejected. If the researcher wants to determine the degree to which the two means differ, calculation of an effect size is recommended to display the magnitude of the pre–post effect. In fact, the reporting of an effect size has become a requirement in many biomedical journals given the limitation of the significance test in describing the magnitude of the effect.
There is a variety of effect size estimators applied in different situations. In this section, I summarize general specifications of effect size and its application in describing longitudinal data. As the computation of an effect size involves the standard deviation of the sample data, rather than the standard error, I also introduce the meta-analysis and the methods for computing the confidence interval around an effect size estimate.
2.1.3.1. General specification of effect size
As a statistical index displaying the degree of departures from the null hypothesis, the effect size statistic is viewed as a complement to the significance test statistics such as the t-test. Although the significance test provides information on the probability of obtaining the given value based on alpha, the effect size index provides information on the practical significance (in biomedical studies, it is referred to as clinical significance). In other words, an effect size enables the researcher to interpret the meaning of the effect from the practical standpoint based on defined thresholds. Furthermore, effect sizes are standardized thereby permitting direct comparison between/among effect estimates of different metric units like the use of Z-scores. Given their practical focus and capacity to compare results across studies, the computation and presentation of effect sizes is popular in medical and psychological research. There are estimators for various types of data. In this text, effect size is portrayed as a descriptive, complementary means of describing longitudinal data. Therefore, I focus on the computation of an effect size on the distance of a measurement between two time points.
I start with Cohen’s, (Cohen, 1988, 1992) mathematical notation of effect size. Let ˉYpre and ˉYpost be the mean scores of a measurement before and after a medical treatment for a sample of N patients. Cohen defines d as the difference between the two means divided by a standard deviation statistic, given by
dC=ˉYpost−ˉYpreσ,
 (2.3)
(2.3)where dC is Cohen’s d, and σ is the standard deviation for either population, assuming the statistic to be equal for the two populations (Cohen, 1988). Here, Cohen’s d measures the standardized mean difference between two population groups.
Because the population statistic σ is usually unknown, especially in observational studies, it may be more practical to replace σ with the sample standard deviation s for expressing an effect size (Glass, 1976; Hedges, 1981). Additionally, the sample standard deviations of the means for samples at two time points are often unequal due to missing observations in follow-ups, and therefore, it is important to specify how the sample standard deviation s for the mean difference is estimated. Glass (1976) proposes the use of the standard deviation for the second mean to estimate an effect size. In the case of a pre–post clinical trial, the Glass’s effect size is given by
dG=ˉYpost−ˉYprespost,
 (2.4)
(2.4)where dG is Glass’s d, and spost is the sample standard deviation at the second time point. His argument depends on the fact that in clinical trials, the sample standard deviations of different groups generally differ, and the use of the post statistics is more appropriate.
Hedges (1981) suggests the use of a pooled standard deviation to calculate an effect size, given by
dH=ˉYpost−ˉYprespooled,
 (2.5)
(2.5)where dH is Hedges’s d, and the pooled standard deviation spooled can be estimated by
spooled=√(Npre−1)s2pre+(Npost−1)s2postNpre+Npost−2.
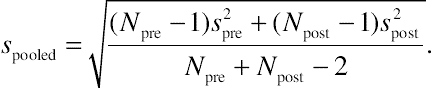 (2.6)
(2.6)The terms s2pre, s2post are sample variances for ˉYpre and ˉYpost, respectively, given by
s2pre=1Npre−1∑nprei=1(Ypre,i−ˉYpre)2,
 (2.7)
(2.7)s2post=1Npost−1∑nposti′=1(Ypost,i′−ˉYpost)2.
 (2.8)
(2.8)Hedges (1981) and Hedges and Olkin (1985) consider dH to be a better estimator than dG because the bias and variance of dH are both smaller than the bias and variance of the corresponding dG. Hedges and Olkin (1985) also developed some more advanced estimators for calculating effect sizes in cases of categorical variables, regression coefficients, odds ratios, as well as on stochastic processes in the distance between two means. Given the focus of this book, those additional techniques are not further described. The interested reader is referred to Cohen (1988), Glass (1976), Hedges (1981), and Hedges and Olkin (1985) for more comprehensive discussions on effect sizes.
The above equations of effect size display a major difference between the effect size and the t-test statistics, although the two appear close in form. The denominator in the equation of the t-test statistic has the component √N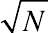 , suggesting that the significance level is enhanced with an increase in the sample size. By contrast, effect size estimators typically are not affected by the sample size, thus eliminating the scale difference. In the longitudinal setting, the effect size index is a statistic displaying the degree of the absolute deviation between scores measured at two time points. A higher effect size estimate indicates a greater standardized “effect” while a lower value indicates a lesser one. For example, an effect size of 0.5 indicates that the effect is a half standard deviation greater, while an effect size of 1.0 indicates that the effect is a full standard deviation greater. As originally developed, the effect size index has no attached probability, and therefore, it cannot be statistically significant or insignificant (Robey, 2004). Cohen (1988) categorized small, medium, and large effect sizes, with threshold values of the three categories set as d = 0.20, d = 0.50, and d = 0.80, respectively. Notably, in some special situations or in some other fields, the same value of an effect size statistic can imply a different degree of deviation between two means. Therefore, considerable caution must be applied in classifying effect sizes into several arbitrary levels, since they can mean different strengths of association in various disciplines (Robey, 2004), particularly in psychosocial studies.
, suggesting that the significance level is enhanced with an increase in the sample size. By contrast, effect size estimators typically are not affected by the sample size, thus eliminating the scale difference. In the longitudinal setting, the effect size index is a statistic displaying the degree of the absolute deviation between scores measured at two time points. A higher effect size estimate indicates a greater standardized “effect” while a lower value indicates a lesser one. For example, an effect size of 0.5 indicates that the effect is a half standard deviation greater, while an effect size of 1.0 indicates that the effect is a full standard deviation greater. As originally developed, the effect size index has no attached probability, and therefore, it cannot be statistically significant or insignificant (Robey, 2004). Cohen (1988) categorized small, medium, and large effect sizes, with threshold values of the three categories set as d = 0.20, d = 0.50, and d = 0.80, respectively. Notably, in some special situations or in some other fields, the same value of an effect size statistic can imply a different degree of deviation between two means. Therefore, considerable caution must be applied in classifying effect sizes into several arbitrary levels, since they can mean different strengths of association in various disciplines (Robey, 2004), particularly in psychosocial studies.
2.1.3.2. Meta-analysis on an estimated effect size
The computation of an effect size posits a random sample as the hypothetical population so that the effect size estimate is an absolute value without being linked to a specific probability distribution. This specification has triggered some skepticism about its justification. As obtained from a single population sample, the calculated effect size does not produce a precise estimate because the value of its estimate can differ markedly using another sample. Therefore, when deriving an effect size, it is more informative to examine a series of studies on the same measurement to estimate the true effect size more accurately. A simple, convenient method in this regard is to combine results from different studies on a common measurement, referred to as meta-analysis.
Meta-analysis, originally coined by Glass (1976), refers to the quantitative methods for combining evidence across a series of studies on a common measurement. This approach usually relies on summary statistics obtained from primary analyses of a series of carefully selected studies. Essentially, a meta-analysis is an analysis of the results from several analyses (Glass, 1976; Hedges and Olkin, 1985). Using this approach allows the estimate of an effect size to be derived as a weighted average of the common measurement, with weights related to the sample sizes of individual studies. If the series of studies are well selected, meta-analysis can derive a more precise effect size estimate than a single dataset.
In clinical experimental studies, the researcher can conduct a meta-analysis by using several clinical trials of a common medical treatment, and then combining the results from these trials to estimate an effect size. The individual-based data can be used to derive the effect size statistic. However, the more popular meta-analytic approach is to identify studies using a common outcome measurement and then utilizing the aggregate results data to generate a summary measure (a weighted average of a series of reported effect sizes). This approach requires a thorough and systematic search of the literature on a specific topic, and the selection of specific studies based on preidentified quality criteria.
For example, to conduct a meta-analysis on the impact of a medical treatment on PTSD, the researcher first needs to identify all related studies on the subject, then examine whether each study meets the necessary criteria for inclusion. This procedure requires randomization, blindness, and representativeness of patients. Based on these quality checks, studies can be selected that satisfy the criteria and the investigator can obtain the pre–post effect size of the treatment (in practice, Hedges’s d is recommended) for each selected study. Finally, the summary effect size statistic can be computed as a weighted average, given by
ˉdH=∑Gg=1wgdH,g,
 (2.9)
(2.9)where ˉdH is the summary measure of the effect size statistic, dH,g is Hedges’s d for study g (g = 1, …, G), and wg is the weight for study g that can be obtained from the inverse variance of the effect size estimator for each study. In the pre–post setting, wg can be calculated by
is the summary measure of the effect size statistic, dH,g is Hedges’s d for study g (g = 1, …, G), and wg is the weight for study g that can be obtained from the inverse variance of the effect size estimator for each study. In the pre–post setting, wg can be calculated by
wg=1s2g∑Gl=1(1s2l).
 (2.10)
(2.10)In the above equation, studies with larger sample sizes have greater weights than those with smaller sample sizes in derivation of the summary effect size statistic.
In practice, meta-analysis can be used as an alternative to significance testing, thereby providing supplementary information concerning a pre–post effect for guiding further data collection and analysis. This approach has several obvious advantages. First, the researcher can widen the generality of an effect size from a sample estimate to a larger population parameter. Provided that the studies are correctly selected, including more data points improves the precision of the effect size estimate. Second, the effect size estimates from a number of single studies are combined within an integrated framework, and consequently, sampling errors and the resulting inconsistencies can be evaluated. Third, meta-analyses provide information about the dispersion of a summarized effect size, thereby facilitating hypothesis testing on the summary statistic. More recently, some scientists have advanced meta-analysis by aggregating published prediction models from different studies (Debray et al., 2012, 2013).
Regardless of the aforementioned strengths, meta-analysis is a rough statistical approach to estimate effect sizes and is subject to several serious limitations. Most notably, it is difficult to find studies that have exactly the same design, sampling strategy, and representativeness of the sample. A weighted average from samples with different designs and levels of representativeness can result in an erroneous summary estimate. Another important problem is that of publication bias. Much of the meta-analysis literature relies on published studies and available analytic results, which can result in strong selection bias in a weighted average. In the fields of medicine and psychology, study results displaying negative results or insignificant findings are much less likely to be accepted by scientific journals for publication. As many study results failing to show significant results presumably still lie in researchers’ file drawers, this publication bias is vividly referred to as the “file drawer” problem (Rosenthal, 1979). To date, there has been no sufficiently satisfactory solution for correcting this type of bias. If the studies included are nonrandomly selected based on publication bias, the distribution of effect sizes will be skewed, resulting in a biased weighted average of effect sizes.
2.1.3.3. Computation of confidence intervals for effect size from a single study
Recently, there are compelling calls in biomedical fields for reporting confidence intervals built around a point estimate of effect size (Bird, 2002; Robey, 2004; Wilkinson and APA Task Force on Statistical Inference, 1999). It is contended that although the use of the effect size statistic is meant to estimate the magnitude of an effect for demonstrating the strength of association, it is not sufficient to just report the point estimate for a complete interpretation of that effect. The report of the American Psychological Association (APA) Task Force on Statistical Inference recommended that confidence intervals should be given for any effect size involving principal outcomes (Wilkinson and APA Task Force on Statistical Inference, 1999, p. 599). From the statistical standpoint, confidence intervals can be computed from a single study that corresponds to the tradition for assessing the dispersion of a point estimate.
Computation of a confidence interval for an effect size estimate is based on the selection of the distribution containing the necessary critical value (Cumming and Finch, 2001). For example, an effect size relating to a t-test has a distribution of t; an effect size relating to an F-test follows the distribution of F. As effect sizes are used to examine departures from the null hypothesis, the required distribution for a valid confidence interval usually relies on the noncentral distribution of the underlying test statistic. For within-study effect sizes, however, an optimal confidence interval around a point effect estimate can be approximated by using the central distribution for large samples (Hedges and Olkin, 1985; Robey, 2004).
In this section, a simplified approach is described for constructing a confidence interval around a point estimate of the pre–post effect size obtained from a single study, given an equal sample size for the pre–post pair (Robey, 2004). Specifically, this simple construction requires nine steps, as summarized by Robey (2004).
Step 1. Specify a priori criterion for Type I error tolerance (the probability of rejecting a true null hypothesis), referred to as α. In empirical analyses, α is regularly set at 0.05 for each contrast. The bandwidth of the corresponding confidence interval is then 1 − α/2 or 0.975 in the case of α = 0.05.
Step 2. For an effect size statistic obtained from a single study, find the critical value in the central distribution of t for α and the number of error degrees of freedom, referred to as CC (Bird, 2002). The value of CC can be obtained from the SAS software given the value of α and the number of the degrees of freedom.
Step 3. Compute the standard error for the pre–post contrast in terms of the effect size. The calculation can be easily accomplished by a hand-calculation given the standard formula, given by
sed=√s2d0.5(Npre+Npost),
 (2.11)
(2.11)where s2d is the variance for the pre–post contrast in the effect size, which can be obtained from the pair-wise differences given an equal sample size.
is the variance for the pre–post contrast in the effect size, which can be obtained from the pair-wise differences given an equal sample size.
Step 4. Compute the value of the pooled standard deviation, spooled, either by using the pooled standard deviation (see Subsection 2.1.3.1) or by using the following simplified equation:
spooled=√s2pre+s2post2.
 (2.12)
(2.12)Step 5. Compute the upper limit for the confidence interval (RUL) of the difference in the raw pre–post scores, using the CC value from a t distribution, given by
RUL=ˉYpost−ˉYpre+CC(sed).
Step 6. Likewise, the lower limit for the confidence interval (RUL) of the difference in the raw pre–post scores is
RLL=ˉYpost−ˉYpre−CC(sed).
Step 7. Compute the point estimate of effect size by using one of the estimators described in Subsection 2.1.3.1 (Cohen’s, Glass’s, or Hedges’s d).
Step 8. Compute the upper limit for the confidence interval about the effect size estimate (SUL), written as
SUL=RULspooled.
 (2.15)
(2.15)Step 9. Likewise, the lower limit for the confidence interval about the effect size d (SLL) is
SLL=RLLspooled.
 (2.16)
(2.16)As indicated earlier, these steps describe a simplified procedure given an equal size for the pre and the post samples. The computational procedure for unequal sample sizes is not covered in this book given the focus on paired differences. For the between-studies effect size estimate, obtained from using the weighted average approach, the confidence interval needs to be computed through complex iterative processes. Given the focus of this text, those more advanced techniques are not elaborated.
2.1.4. Empirical illustration: descriptive analysis on the effectiveness of acupuncture treatment in reduction of PTSD symptom severity
In this illustration, I display the application of the aforementioned descriptive approaches using data of the Randomized Controlled Clinical Trial on the Effectiveness of Acupuncture Treatment on PTSD. This trial is described extensively in Chapter 1, and in the following it will be referred to as the DHCC Acupuncture Treatment study. Specifically, an empirical example is provided on the pattern of change over time in PTSD symptom severity for a group of active-duty military personnel diagnosed with PTSD. The PTSD Checklist (PCL) score (Civilian Version) is used as the outcome variable for PTSD symptom severity, measured at four time points. PCL is a 17-item summary measure that assesses the symptoms of PTSD in the Diagnostic and Statistical Manual for Mental Disorders (fourth ed., DSM-IV), yielding a total score ranging from 17 to 85. Given summarization, PCL score is named PCL_SUM in the analysis. The time factor, four levels and named TIME, is specified as: 0 = baseline survey, 1 = 4-week follow-up, 2 = 8-week follow-up, 3 = 12-week follow-up. The treatment variable is named TREAT, with 1 = receiving acupuncture treatment and 0 = else, used in this illustration to stratify the data. The null hypothesis is that PCL_SUM does not change over time in either treatment group. As the first step, time plots of trends are displayed on PCL_SUM. Then I assess whether PCL_SUM changes over time and differs between the two treatment groups. First, a subject-specific time plot on PCL_SUM is created for each treatment group, with the SAS program given below.
SAS Program 2.1:

As shown above, the DATA step creates a temporary dataset TP1 from the permanent dataset ACUALL_EDIT_COMPLETE. The SAS PROC SGPLOT procedure is applied to generate the subject-specific plot by scaling the y-axis for the outcome variable (PCL_SUM) and the x-axis for time. In the two SAS PROC SGPLOT steps, the WHERE = 1 and WHERE = 0 statements tell SAS that two sets of time plots are produced, one for those receiving acupuncture treatment and one for those in the control group. The option GROUP = ID informs SAS that PCL_SUM is plotted against time for each subject. The resulting plot from SAS Program 2.1 is presented below.
In Fig. 2.1a and b, the key under the plot links each growth curve to a specific subject. Figure 2.1a displays declines in PCL_SUM for the majority of the patients receiving acupuncture treatment, thereby revealing effectiveness of the treatment on the reduction in PTSD symptom severity. In contrast, the changing pattern of PCL_SUM for the control group, shown in Fig. 2.1b, is vague, not presenting any notable patterns of change for most patients in this group. Overall, these subject-specific time plots do not provide sufficient information concerning the effectiveness of the acupuncture treatment on PTSD symptom severity, and therefore, it may be useful to create population-averaged time plots for exhibiting the general pattern of change over time for both treatment groups.


Figure 2.1 (a) Subject-specific time plot on PCL score for treatment group. (b) Subject-specific time plot on PCL score for control group.
To create such a population trend plot, the mean score of PCL_SUM needs to be computed first for each treatment group and at each time point, and then a time-dependent trajectory of the mean PCL_SUM score can be generated for each treatment group. The following is the SAS program to create the time plots of the population-averaged trends.
SAS Program 2.2:

In SAS Program 2.2, a temporary SAS data file NEW is created from the dataset TP1. The PROC SQL procedure creates the mean PCL_SUM score, named PCL_MEAN, for each treatment group and at each time point by using the GROUP BY TIME, TREAT clause, and then the mean PCL_SUM scores are saved into the temporary data file NEW for further analysis. Also in this SAS program, the option GROUP = ID in SAS Program 2.1 is replaced with GROUP = TREAT telling SAS that a plot is generated for each treatment group. The resulting graph is shown in Fig. 2.2.

Figure 2.2 Time Plot of Mean PCL Scores for Treatment and Control Groups
Figure 2.2 plots the time trends in PCL_MEAN for the acupuncture treatment and the control groups. The two PCL curves across four time points highlight the strong impact acupuncture treatment has on PTSD symptom severity. During the first month after treatment, patients receiving acupuncture treatment are shown to experience a much sharper decline in PCL_MEAN than do their counterparts in the control group. This reduced mean severity score then stabilizes throughout the rest of the observation period.
Next, the paired t-test is applied to test statistical significance for three pre–post contrasts – time 0 versus time 1, time 2, and time 3, respectively. The operational objective is to test whether or not the change in PCL_MEAN differs significantly between baseline and each of the follow-ups in each treatment group. Given this focus, the paired t-test is conducted separately for the acupuncture treatment and the control groups. Given dependence of the pre- and posttest PCL_SUM scores, Equation (2.1) is used assuming paired differences to be normally distributed. The SAS program for the first pre–post time contrast is given below.
SAS Program 2.3:


In SAS Program 2.3, two temporary datasets from the complete longitudinal data (a long table) are created, TP21, and TP22, containing data at baseline and at the 4-week follow-up. The variable PCL_SUM is renamed as PCL_SUM0 in TP21 and as PCL_ SUM1 in TP22, respectively. The two temporary datasets are then merged to create a subject-specific temporary dataset TP2 (a wide table). In performing the PROC TTEST procedure, two paired t-tests are specified, one for the acupuncture treatment and one for the control groups. The WHERE TREAT = statement determines which treatment group is analyzed. The PAIRED statement informs SAS to test whether the mean change between PCL_SUM0 and PCL_SUM1 is significantly different from zero. The output file resulting from SAS Program 2.3 is reported below.
SAS Program Output 2.1:

In SAS Program Output 2.1, the first panel displays the test results for those receiving acupuncture treatment whereas the second panel displays the results for the control group. In each panel, the summary statistics of the difference in the PCL_SUM score are displayed, including mean difference, standard deviation (SD), standard error (SE), maximum and minimum values, and the 95% confidence bounds. The paired sample sizes are 23 for the acupuncture treatment group and 27 for the control group. Given α = 0.05, the results of the paired t-tests indicate that the first pre–post difference in PCL_SUM is statistically significant among those receiving acupuncture treatment (t = 7.64, p < 0.0001), but not significant for those in the control group (t = 1.86, p = 0.0742). SAS Program 2.3 also produces some additional graphs and scattered plots for each treatment group, not presented in this text. Means and standard deviations, the statistics needed to estimate effect sizes and their confidence intervals (CI), can be readily obtained by applying a simple univariate analysis in SAS (the procedure is not presented given its simplicity). With all the required statistics and estimates available, the Hedges’s d and the associated 95% confidence interval can be computed for the first pre–post contrast using the procedure described in Section 2.1.3.3. These effect size estimators are used to examine the clinical significance of differences in PCL_SUM between the first two time points.
The t-tests and computation of effect sizes for the other two pre–post contrasts on PCL_SUM can be conducted in the same fashion. The output files for all three paired t-tests are fairly sizable, and therefore, the results for the three contrasts are summarized in Table 2.1.
Table 2.1
Means, Standard Deviations, Standard Errors, t Scores, and Effect Sizes of PCL_Sum For Three Pre–Post Contrasts: DHCC Acupuncture Treatment Study (N = 55)
| Health Indicator and Other Statistics | Time Pair | ||
| Time 0 Vs. Time 1 | Time 0 Vs. Time 2 | Time 0 Vs. Time 3 | |
| For Patients Receiving Acupuncture Treatment (N = 28) | |||
| PCL at baseline (SD) | 56.78 (11.66) | 56.50 (11.73) | 55.00 (11.57) |
| PCL at follow-up (SD) | 38.78 (11.83) | 37.78 (15.39) | 38.37 (16.20) |
| Pre–post difference (SE) | 18.00 (2.36) | 18.72 (2.94) | 16.63 (2.65) |
| t value (p-value) | 7.64 (<0.01) | 6.36 (<0.01) | 6.28 (<0.01) |
| Hedges’s d (95% CI) | 1.53 (1.12, 1.95) | 1.37 (0.93, 1.81) | 1.18 (0.77, 1.59) |
| For Patients in the Control Group (N = 27) | |||
| PCL at baseline (SD) | 55.44 (12.15) | 56.30 (12.73) | 54.63 (12.57) |
| PCL at follow-up (SD) | 51.48 (12.40) | 53.83 (15.01) | 45.75 (14.12) |
| Pre–post difference (SE) | 3.96 (2.13) | 2.48 (2.33) | 8.88 (2.69) |
| t value (p-value) | 1.86 (0.07) | 1.06 (0.30) | 3.29 (<0.01) |
| Hedges’s d (95% CI) | 0.32 (−0.05, 0.70) | 0.18 (−0.16, 0.52) | 0.66 (0.25, 1.08) |

Table 2.1 displays the results of three paired t-tests on the statistical and clinical significances of differences in PCL_SUM between the baseline survey and each of the three follow-ups, as stratified by the two treatment groups. The mean PCL score of patients receiving acupuncture treatment drops from 56.78 at baseline to 38.78 at the 4-week follow-up, a 31.7% reduction. At the 8-week and the 12-week follow-ups, the mean PCL scores are fairly stable, with 37.78 at the 8-week follow-up and 38.37 at the 12-week follow-up. All three t statistics are statistically significant (p < 0.01). Additionally, in the acupuncture treatment group the effect sizes for the three contrasts are all above 1 (1.53, 1.37, and 1.18, respectively) with fairly narrow confidence intervals, thereby highlighting a high level of clinical significance. In contrast, declines in the PCL score among those in the control group are much less meaningful, reflected by considerably smaller absolute values of pre–post differences, statistical insignificance of two of the t scores, and much lower effect sizes with wider confidence intervals.
2.2. Repeated measures ANOVA
In the paired t-tests, differences in the response measurements are statistically tested and assessed between baseline and each of the follow-ups. If a discrete covariate is considered, the test will be further divided into more separate steps due to stratification by the covariate’s levels. Statistically, such a simplistic approach is inefficient and even incorrect. Consider, for example, the case in which the paired t-test is applied to analyze some longitudinal outcome data measured at five time points and involving a discrete covariate with three levels. Then 30 separate paired t-tests are needed for all possible pre–post contrasts. This procedure can cause tremendous statistical instability with a much elevated chance of mistakenly rejecting the null hypothesis (Type-I error) because the overall significance level α becomes much larger than the prespecified value. A more correct approach in this situation is to assess all the contrasts, both between time points and within times, using an integrated statistical perspective. Traditionally, repeated measures analysis of variance, or simply repeated measures ANOVA, has been applied in the analysis of longitudinal data involving more than two time points and when covariates are considered.
In this section, the basic specification of ANOVA, assuming independence of observations, is described first. Next, the description of ANOVA is extended to the context of repeated measurements, with one factor and with two factors. Lastly, I illustrate the application of the two-factor repeated measures ANOVA using longitudinal data from the DHCC Acupuncture Treatment Study.
2.2.1. Specifications of one-factor ANOVA
The ANOVA is a methodology to statistically assess differences between the means of two or more population samples. I begin the description of ANOVA with a one-factor model. By saying one factor, I mean a single covariate such as medical treatment, gender, and marital status. Time as a factor will be indicated later. Suppose that a single factor consists of K levels and the population mean of a given response measurement for each level is denoted by μ1, μ2, ···, μK, respectively. The null and alternative hypotheses for performing an ANOVA analysis are then given by
H0:μ1=μ2,=⋯=μKH1: not all μ's are equal.

The above hypotheses are meant to test whether there is a difference in the measurement across all K levels of the factor. Given a predetermined value of α, various ANOVA methods are designed to test the hypotheses within an integrated statistical procedure.
The classical ANOVA has several restrictive assumptions. First, it requires population samples to be obtained independently. Second, the observations from the population at each level must follow a normal distribution. Third, the normally distributed observations at various levels need to have a common variance σ2. Given these restrictions, transformation of data (e.g., log transformation) is sometimes needed to satisfy normality and constant variance. Finally, an ANOVA also requires the outcome measurement to be an interval variable and the factor to be a classification variable.
The application of the classical one-factor ANOVA is based on the breakdown of the total variations of sample data into two sources of variation – within-sample variations and between-sample variations. Conventionally, the within-sample variations are measured as the standard deviation within each sample and the between-sample variations are the standard deviation across sample means. In the one-factor ANOVA, the total and the two sources of variations are measured as sums of squares, denoted by SS, written as SS(total) = SS(between) + SS(within). As the between-sample variation component reflects variations due to the single factor, SS(between) is also referred to as SS(factor). Likewise, SS(within) can be called SS(error) since the within-sample variation component represents random errors. Specifically, SS(factor) is mathematically defined as
SS(factor)=N1(ˉY1−ˉY)2+N2(ˉY2−ˉY)2+⋯+NK(ˉYK−ˉY)2,
where N1, N2, ···, NK are sample sizes for each of the K levels for the factor, respectively, ˉY1,ˉY2,⋯,ˉYK are the corresponding sample means, and ˉY
are the corresponding sample means, and ˉY is the grand mean of the entire sample.
is the grand mean of the entire sample.
Similarly, SS(error) is specified as
SS(error)=∑(Y1−ˉY1)2+∑(Y2−ˉY2)2+⋯+∑(YK−ˉYK)2,
where Y1,Y2,⋯,YK are subject-specific measures within each of the K groups.
are subject-specific measures within each of the K groups.
The SS(total) is the sum of SS(factor) and SS(error), mathematically defined as
SS(total)=∑(Y−ˉY)2.
Given the one-factor ANOVA, the procedure for testing the null and alternative hypotheses is to calculate two “average” sums of squares for SS(factor) and SS(error), referred to as the mean square factor or MS(factor) and the mean square error or MS(error), respectively:
MS(factor)=SS(factor)K−1,
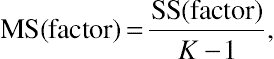 (2.20)
(2.20)MS(error)=SS(error)N−K,
 (2.21)
(2.21)where the terms K − 1 and N − K are the degrees of freedom for MS(factor) and MS(error), respectively. Given an equal variance across all factorial levels, MS(error) is commonly used as an estimate of σ2, assuming all levels to have the equal sample size.
The test statistic for testing H0:μ1=μ2,=⋯=μK versus the alternative hypothesis is the ratio of MS(factor) over MS(error), which follows an F-distribution, given by
versus the alternative hypothesis is the ratio of MS(factor) over MS(error), which follows an F-distribution, given by
F=SS(factor)MS(error).
 (2.22)
(2.22)Given the calculated F value, the corresponding p-value can be obtained from the distribution with two degrees of freedom (df) terms, available in the table of F-distribution in all textbooks of statistics. If the F statistic is associated with a p-value smaller than α, the null hypothesis should be rejected; otherwise, the null hypothesis is accepted. For large samples, the F test for testing differences among mean scores is statistically robust even when the distributions of populations are somewhat nonnormal.
2.2.2. One-factor repeated measures ANOVA
The specification of the classical one-factor ANOVA described above is based on the assumption that observations are independent. In many situations, this restrictive hypothesis is violated due to correlation of some observations in the presence of a lurking factor affecting the measured results. As indicated in Chapter 1, in longitudinal data, repeated measurements are generally correlated within subjects given an individual’s genetic predisposition, physical attributes, and other biological and social characteristics. For correcting the potential impact of the lurking factor, statisticians have developed a stratification technique, referred to as the randomized block design, to analyze correlated data more efficiently. This design divides an underlying sample into relatively homogeneous subgroups or blocks. If correlation among observations truly exists, the blocking design can yield a more reliable estimate for a factor’s effect as compared to statistical methods with the independent observations hypothesis (Lindsey, 1999).
Consider the example given in Section 2.1.4. As the variability of observations within each subject is obviously less than the variability between subjects, subjects can be taken as a blocking factor before testing the statistical significance of the pattern of change in the dependent variable PCL_SUM. Consequently, the patient sample can be divided into 55 blocks (subjects) with each block having four observations if there are no missing observations. In this design, observations are no longer assumed to be mutually independent but tend to be correlated within a given subject. The PCL_SUM scores can then be compared across time within each subject, with the extraneous variability of the subject’s effect removed from the error sum of squares.
When ANOVA is combined with the aforementioned blocking design to analyze repeated measurements, the technique is called the repeated measures ANOVA. The one-factor repeated measures ANOVA decomposes the total sum of squares into three, rather than two, SS components, given by
SS(total)=SS(time factor)+SS(blocks)+SS(error),
where SS(blocks) measures the variation due to blocks, and time is used now as the factor in the context of repeated measurements.
By definition, the amount of SS(total) is identical to that derived from the classical ANOVA assuming independence of observations, as specified in Equation (2.19). If means across all blocks are equal and variability due to block is zero, the randomized block design is not necessary. If the block effect is sizable, as is generally the case in longitudinal data, the error sum of squares will be considerably decreased compared to the amount generated from the classical ANOVA. It follows then that the use of the block design is effective, and SS(factor), or SS(time) in the context of repeated measurements, needs to be respecified, written as
SS(time)=N[(ˉY1−ˉY)2+(ˉY2−ˉY)2+⋯+(ˉYn−ˉY)2],
where the factor is specified as time j (j = 1, …, n), and N refers to sample size assuming no missing observations.
Similarly, SS(blocks), or SS(subjects), is given by
SS(subjects)=n[(ˉY1−ˉY)2+(ˉY2−ˉY)2+⋯+(ˉYN−ˉY)2].
The SS(error) is now the residual to the total sum of squares after accounting for the other two components, namely SS(error) = SS(total) − SS(time) − SS(subjects). The degrees of freedom for the three SS components and SS(total) are given as: n − 1 for the time factor, N − 1 for subjects, (n − 1)(N − 1) for error, and Nn − 1 or N − 1 for the total. Correspondingly, the three mean square statistics – MS(time), MS(subjects), and MS(error) – are:
MS(time)=SS(time)n−1,
 (2.26)
(2.26)MS(subjects)=SS(subjects)N−1,
 (2.27)
(2.27)MS(error)=SS(error)[(n−1)](N−1).
 (2.28)
(2.28)Like the classical ANOVA, in repeated measures ANOVA, testing of the null hypothesis H0:μ1=μ2,=⋯=μn versus the alternative hypothesis is based on the ratio of MS(time) over MS(error), which follows an F-distribution and is specified by Equation (2.22). Given the F-value, the p-value can be obtained from the distribution with two degree of freedom terms: n − 1 for time and (n − 1)(N − 1) for error. The null and the alternative hypotheses can subsequently be statistically tested. The amount of MS(error) is usually smaller than the results derived from the classical ANOVA because SS(subjects) absorbs some variations in the observed measurements thereby reducing MS(error) given a fixed MS(total) value. As a result, the F-value is increased, elevating the likelihood that the null hypothesis is to be rejected.
versus the alternative hypothesis is based on the ratio of MS(time) over MS(error), which follows an F-distribution and is specified by Equation (2.22). Given the F-value, the p-value can be obtained from the distribution with two degree of freedom terms: n − 1 for time and (n − 1)(N − 1) for error. The null and the alternative hypotheses can subsequently be statistically tested. The amount of MS(error) is usually smaller than the results derived from the classical ANOVA because SS(subjects) absorbs some variations in the observed measurements thereby reducing MS(error) given a fixed MS(total) value. As a result, the F-value is increased, elevating the likelihood that the null hypothesis is to be rejected.
The ANOVA assumes a common variance σ2 across all levels, or all time points in the context of longitudinal data. Consequently, MS(error) can be viewed as the estimate of σ2, denoted by s2, with the square root of MS(error) representing the sample standard error s. Therefore, using the randomized block design, the confidence interval for the difference between two sample means, ˉYj and ˉYj′
and ˉYj′ where j≠j′
where j≠j′ , can be computed from MS(error). Mathematically, the confidence interval for (ˉYj−ˉYj′)
, can be computed from MS(error). Mathematically, the confidence interval for (ˉYj−ˉYj′) with coverage probability (1 − α) satisfies the following condition:
with coverage probability (1 − α) satisfies the following condition:
Pr{[(ˉYj−ˉYj′)−˜w]≤(ˉYj−ˉYj′)≤[(ˉYj−ˉYj′)+˜w]}=1−α,
where ˜w is the confidence width determined by α, which can be approximated by
is the confidence width determined by α, which can be approximated by
˜w=tα/2,df×√MS(error)(2N),

and df is the degree of freedom for the t statistic; namely, df = (n − 1)(N − 1).
In this one-factor repeated measures ANOVA, the F-test is applied to test the effect due to subjects given the null and the alternative hypotheses that Hsubjects0:μ1=μ2,=⋯=μN and Hsubjects1
and Hsubjects1 : not all subject means are equal. The F-value is calculated by
: not all subject means are equal. The F-value is calculated by
Fsubjects=MS(subjects)MS(error),
 (2.30)
(2.30)where the associated degrees of freedom for the numerator and denominator are specified earlier.
When the repeated measures ANOVA is applied for analyzing longitudinal data, time must be specified as a classification factor, and all time points need to be fixed across all subjects. Also, like the classical ANOVA, the application of repeated measures ANOVA assumes no missing observations. This is an unrealistic assumption in longitudinal data analysis because there are almost always dropouts due to various reasons, particularly in observational surveys where spacing between two time points is usually wide. With missing observations, the repeated measures ANOVA technique adopts the simplest and the most direct method by removing all cases with missing data. If the number of dropouts is substantial and nonrandom, considerable bias occurs to both point estimates and the corresponding standard errors.
Like the classical ANOVA, the repeated measures ANOVA is meant to compare group means, and individual growth patterns are not of direct concern. Given this focus, the subject’s sign i (i = 1, …, N) is not written out in the above ANOVA equations. This model, however, can be conveniently expressed as a special case of general linear modeling on individuals, given by
Yij=μ+bi+τj+ɛij,
where Yij is the measurement for subject i at time point j, μ is the grand mean indicated earlier, bi is the subject i’s deviation from μ assumed to be constant over time, τj is the time point’s deviation from μ also assumed to be the same across all subjects, and ɛij is the random error for subject i at time point j. By definition, the sum of τj across all time points equals zero. The term bi is defined as the between-subjects random effect assumed to be distributed as N(0,σ2b) . Likewise, ɛij is the within-subject random error distributed as N(0,σ2ɛ)
. Likewise, ɛij is the within-subject random error distributed as N(0,σ2ɛ) . It follows that the one-factor repeated-measures ANOVA specifies two components of effects – the fixed effect of time and the random effect of subjects, thereby engendering the original form of a mixed-effects model. In fact, various mixed-effects linear models, which will be described in the succeeding chapters, can be regarded as extensions of Equation (2.31).
. It follows that the one-factor repeated-measures ANOVA specifies two components of effects – the fixed effect of time and the random effect of subjects, thereby engendering the original form of a mixed-effects model. In fact, various mixed-effects linear models, which will be described in the succeeding chapters, can be regarded as extensions of Equation (2.31).
2.2.3. Specifications of two-factor repeated measures ANOVA
The above description concerning the randomized block design deals with the case including only a single time factor. In longitudinal data analysis, researchers are often interested in examining one or more additional factors. In the illustration described in Section 2.1.4, subjects are randomized into two treatment groups and are followed across four fixed time points. Therefore, in that study, treatment is the second factor. The repeated measures ANOVA is well suited to analyze the data involving two factors (e.g., time and acupuncture treatment), referred to as two-way repeated measures ANOVA or, using agricultural jargon, “split-plots” ANOVA.
The two-way repeated-measures ANOVA is simply an extension of the one-way perspective. Let time be Factor A taking n observation points and the added factor be Factor B with K levels (e.g., treatments). In this two-factor analysis, the interest resides in assessing whether each of the two factors has a statistically significant effect on the measurement Y. Sometimes, the researcher’s interest is also in testing whether the relationship between time and the dependent variable Y depends on Factor B or vice versa. In statistics, such an interactive effect between two factors is referred to as an interaction. Consider the example of the DHCC Acupuncture Treatment study: the pattern of change over time in PCL_SUM differs between the acupuncture treatment and the control groups.
Given the above specifications, the two-way repeated measures ANOVA is actually a statistical model that decomposes the total sum of squares into five SS components:
SS(total)=SS(A)+SS(B)+SS(AB)+SS(subjects)+SS(error),
where SS(A) measures the variation due to Factor A (time), SS(B) measures the variation due to Factor B, and SS(AB) measures the variation due to the interaction between Factors A and B. As the amount of SS(total) is identical to that of the one-factor repeated measures ANOVA, the addition of Factor B reduces the amount of SS(error) unless its effect on Y is zero.
The computation of various SS components in the two-way repeated measures ANOVA follows a similar procedure to that of the one-way perspective. First, SS(A), the sum of squares for the time factor, is given by
SS(A)=N[(ˉY1.−ˉY)2+(ˉY2.−ˉY)2+⋯+(ˉYn.−ˉY)2],
where, given two factors, ˉY1.,ˉY2.,⋯,ˉYn. are marginal means of Y at each of the n time points across all K levels, and the subscript “.” indicates margins across all levels of another factor (given this specification, the grand mean ˉY can be expressed as ˉY..
are marginal means of Y at each of the n time points across all K levels, and the subscript “.” indicates margins across all levels of another factor (given this specification, the grand mean ˉY can be expressed as ˉY.. ).
).
Likewise, SS(B), the sum of squares for the second factor, can be written as
SS(B)=n[(ˉY.1−ˉY)2+(ˉY.2−ˉY)2+⋯+(ˉY.K−ˉY)2],
where, ˉY.1,ˉY.2,⋯,ˉY.K are marginal means of Y at each of the K levels across all n time points.
are marginal means of Y at each of the K levels across all n time points.
The SS amount due to the interaction is computed by summing up the squared errors for all n × K cells. After some simplification, it can be written as
SS(AB)=∑nj=1∑Kk=1Nj(ˉYjk−ˉYj.−ˉY.k+ˉY)2.
 (2.35)
(2.35)Likewise, the SS(subjects) component in the two-way repeated measures ANOVA is
SS(subjects)=n∑Kk=1∑Nki=1(ˉY.k−ˉY)2.
 (2.36)
(2.36)The SS(error) is residual to the total sum of squares after taking into account the other two components, given as SS(error) = SS(total) − SS(A) − SS(B) − SS(AB) − SS(subjects). The degrees of freedom for the five SS components are n − 1 for factor A (time), K − 1 for Factor B, (n − 1)(K − 1) for the interaction between A and B, N − K for subjects, and (N − K) (n − 1) for error. The degree of freedom for total variance remains to be N − 1 or Nn − 1.
Given the above specifications, there are five mean square statistics – MS(A), MS(B), MS(AB), MS(blocks), and MS(error), given by
MS(A)=SS(A)n−1,
 (2.37)
(2.37)MS(B)=SS(B)K−1,
 (2.38)
(2.38)MS(AB)=SS(AB)(n−1)(K−1),
 (2.39)
(2.39)MS(subjects)=SS(subjects)N−K,
 (2.40)
(2.40)MS(error)=SS(error)(N−K)(n−1).
 (2.41)
(2.41)Accordingly, four F tests can be performed on the effects of Factor A, Factor B, the interaction between Factors A and B, and block (subject), respectively, given the corresponding null and the alternative hypotheses. For example, the F-test statistic for factor B is
Ffactor B=MS(B)MS(error).
 (2.42)
(2.42)The other three F-tests can be conducted in the same fashion. Given the F statistics, the p-value can be obtained from the distribution with two degrees of freedom for each. Equation (2.30) can then be applied to approximate the confidence interval for the difference in the response measurement between two means given the value of MS(error) and its degrees of freedom.
As is in the case of the one-factor model, the two-factor repeated measures ANOVA can be expressed in terms of a general linear model using Yij as the dependent variable, given by
Yij=μ+τj+λk+(τλ)jk+bi(k)+ɛijk,
where λk is the effect of group k, (τλ)jk measures the effect of the interaction between time point j and group k, bi(k) indicates the subject’s random effect nested in group k, and ɛijk is the random error for subject i at time point j. As deviations of group means from the grand mean, μ, the sums of τj’s, lk’s, and (τl)jk’s are all zero, respectively. Again, bi is defined as the between-subjects random effect assumed to be distributed as N(0,σ2b) , and ɛij is the within-subjects random disturbances distributed as N(0,σ2ɛ)
, and ɛij is the within-subjects random disturbances distributed as N(0,σ2ɛ) . The two-factor repeated-measures ANOVA specifies two effect components, the fixed effects of the two factors and the random effect of subjects; accordingly, the variance of the response measurement consists of two components – between-subjects variance σ2b
. The two-factor repeated-measures ANOVA specifies two effect components, the fixed effects of the two factors and the random effect of subjects; accordingly, the variance of the response measurement consists of two components – between-subjects variance σ2b and within-subject variance σ2ɛ
and within-subject variance σ2ɛ .
.
Given the extended specification in Equation (2.43), the null hypothesis can be created and tested for each time-related contrast in the repeated measures ANOVA. In statistics, this detailed test on each contrast is referred to as local tests, widely applied in biomedical research. For example, repeated measures ANOVA can be used to test the null hypothesis that the measurement does not differ between the treatment and the control groups at each time point. There are some other specific statistical properties associated with the repeated measures linear regression models, which will be described and discussed when linear mixed-effect models are discussed in some of the succeeding chapters.
In longitudinal data analysis, repeated measures ANOVA, both one-factor and two-factors, has several distinctive limitations. First, the assumption of constant variance across all time points does not apply to many longitudinal datasets, particularly in the presence of sizable missing observations. In longitudinal data, both variance and covariance tend to change over time. Second, the ANOVA models are restricted to the use of discrete covariates, and therefore, continuous processes in the effects of some covariates cannot be analyzed. Third, repeated measures ANOVA is applicable only for longitudinal data with fixed time points across all subjects, and those measured on different occasions (e.g., delayed entry or delayed follow-up) have to be excluded from the analysis. Such unbalanced design causes considerable problems in the estimation of the expected mean squares to perform the F-test. Lastly, repeated measures ANOVA is restricted only to interval response measurements, and therefore, its application is limited to the analysis of repeated measurements with a normal distribution. These restrictions thus call for the advancement of more flexible and powerful statistical methods in longitudinal data analysis, as will be described in the succeeding chapters.
2.2.4. Empirical illustration: a two-factor repeated measures ANOVA – the effectiveness of acupuncture treatment on PCL revisited
In Section 2.1.4, I presented an empirical example by applying the descriptive approaches to analyze the longitudinal data of the DHCC Acupuncture Treatment study. As indicated earlier, simplistic approaches, such as paired t-tests, are not statistically efficient or correct in longitudinal data analysis, particularly when covariates are considered. To derive statistically efficient and substantively constructive results, the researcher needs to assess all the contrasts, both between time points and within times, given an integrated statistical procedure. In the present illustration, I reanalyze the pattern of change over time in PCL_SUM for two treatment groups, using the same dataset. Specifications for the time and treatment factors remain the same (TIME: 0 = baseline survey, 1 = 4-week follow-up, 2 = 8-week follow-up, 3 = 12-week follow-up; TREAT: 1 = receiving acupuncture treatment, 0 = else). As required by the application of an ANOVA model, the dependent variable, PCL_SUM, is a continuous variable, and the two covariates, TIME and TREAT, are specified as classification factors. As routinely defined in longitudinal data analysis, TIME is regarded as a within-subject factor as its change reflects an intraindividual course, and TREAT is defined as a between-subjects factor because the change in its value usually cannot occur to the same subject.
As PCL_SUM is measured repeatedly and two factors are considered, the two-factor repeated measures ANOVA is applied in this analysis. In addition to the original hypothesis that PCL_SUM does not change over time in either treatment group, two null hypotheses are added in the present illustration: that there is no interactive effect between TIME and TREAT on PCL_SUM and there is no subject effect given the specification of two covariates. As the application of repeated measures ANOVA is based on the multivariate data structure (the wide table), the temporary dataset TP2, created when performing paired t-test, continues to be used. Below is the SAS program for the analysis.
SAS Program 2.4:

In SAS Program 2.4, the PROC GLM procedure is used to conduct repeated measures ANOVA as ANOVA is a special case of general linear models. The CLASS TREAT statement specifies TREAT as a classification factor as required by ANOVA. In the MODEL statement, the NOUNI option suppresses the individual ANOVA tables that are not useful for a repeated measures analysis. The REPEATED statement informs SAS to test the hypotheses on within-subject factors (in this case, TIME). SAS Program 2.4 derives a fairly sizable output, much being not useful, and therefore, the main results are summarized in the following ANOVA table (Table 2.2).
Table 2.2
Repeated Measures ANOVA Table on PCL_SUM: DHCC Acupunctural Treatment Study (N = 37)
| Source | df | SS | MS | F | p-Value |
| Time | 3 | 3,563.98 | 1,187.99 | 18.92 | <0.01 |
| Treat | 1 | 3,779.64 | 3,779.61 | 6.16 | 0.02 |
| Time × Treat | 3 | 1,580.87 | 526.96 | 8.39 | <0.01 |
| Subject | 35 | 21,465.67 | 613.30 | 9.77 | <0.01 |
| Error | 105 | 6,591.44 | 62.78 | ||
| Total | 147 | 36,981.60 |

In Table 2.2, the F value for each SS component suggests that all the null hypotheses specified above should be rejected. Literally speaking, in the longitudinal data of the DHCC Acupuncture Treatment study, the main effects of time (TIME) and acupuncture treatment (TREAT) on PCL_SUM are both statistically significant, and the impact the treatment has on the PCL score varies significantly over time (TIME × TREAT). Importantly, there is a very strong subject’s effect (SUBJECT) on variations in PCL_SUM, indicating that the application of the classical ANOVA, which assumes independence of observations, is not appropriate to analyze this longitudinal data.
As emphasized in Section 2.2.3, there are distinctive restrictions in the application of repeated measures ANOVA. In the next chapter, the same data will be reanalyzed using a mixed-effects regression model, a more statistically flexible and powerful technique in analyzing normal longitudinal data.
2.3. Repeated measures MANOVA
Multivariate analysis of variance, or MANOVA, is essentially an ANOVA model on a combination of dependent variables. The MANOVA procedure for repeated measures first creates a new dependent variable from repeated measurements by maximizing measurement differences between/among groups. Next, the repeated measures ANOVA technique is applied to test a set of null and alternative hypotheses on the combined dependent variable. In situations where missing observations are rare, this multivariate approach, which treats each time-specific measurement as a distinctive dependent variable, is useful in longitudinal data analysis. In biomedical research, repeated measures MANOVA can be applied to test the hypothesis that the mean scores of a specific health measurement do not differ between patients receiving a medical treatment and those who do not at all follow-up time points.
In this section, I first describe the general specifications of MANOVA to familiarize the reader with the theory and the data structure for the application of MANOVA. Next, I illustrate the adaptations of MANOVA into the context of repeated measurements. An empirical example is provided to display the application of a two-factor repeated measures MANOVA model, using longitudinal data of the DHCC Acupuncture Treatment study.
2.3.1. General MANOVA
MANOVA is generally used to determine whether a set of response measurements differ among various population groups. The statistical tests are the extensions of those specified for ANOVA. Specifically, MANOVA tests the statistical significance of a particular main effect or an interaction on each of the response measurement, as well as the significance of the overall effect. Additionally, MANOVA can be used to assess the strength of association between the set of dependent variables considered in a given analysis.
Like ANOVA, there are several restrictions in the application of MANOVA. First, each response measurement or the dependent variable should follow normality within population groups. Second, MANOVA assumes linear relationships for all pairs of dependent variables, all pairs of covariates, and all dependent-covariate pairs. Third, multiple dependent variables are assumed to have equal variance across all covariates. Lastly, covariances among the dependent variables are assumed to be homogeneous across all the specified crossing cells. These assumptions need to be carefully checked and statistically tested before a MANOVA can be performed effectively.
The application of MANOVA requires the specification of two or more dependent variables, and one or more classification variables as covariates. For analytic convenience, the general MANOVA is presented with two dependent variables and two classification factors as covariates. Let Y be a N × 2 matrix of Y scores (N subjects by two dependent variables), m is 1 × 2 vector of grand means for Y, and X1 and X1 denote Factor A and Factor B, respectively, with n and K levels, respectively. As there are two dependent variables, sums of squares (SS in ANOVA) are expressed in terms of matrices, referred to as the S matrices. The total sums of squares in MANOVA, denoted Stotal, is partitioned into the between-group and the within-group components, written as
Stotal=Sbet+Swithin,
where Sbet and Swithin are the between-group and within-group S matrices, respectively.
Given the above specifications, the formalization of the general MANOVA is just a matter of tedious decomposition. With two covariates on two dependent variables, the between-group component Sbet can be partitioned into variance for each covariate and the interaction between the factors, given by
Sbet=Njk∑nj−1∑Kk=1(ˉYjk−ˉY)2= Nj∑nj−1(ˉYj−ˉY)2+∑Kk=1(ˉYk−ˉY)2+[Njk∑nj−1∑Kk=1(ˉYjk−ˉY)2−Nj∑nj−1(ˉYj−ˉY)2−∑Kk=1(ˉYk−ˉY)2].
 (2.45)
(2.45)There are three components on the right side of Equation (2.45), which are S matrices associated with n levels of X1, with K levels of X2, and with the combinations of X1 and X2, respectively. Thus, Sbet can be rewritten as
Sbet=SX1+SX2+SX1X2.
In this specific MANOVA model, the within-group S matrix is
Swithin=∑i∑j∑k(Yijk−ˉYjk)(Yijk−ˉYjk)′.
 (2.47)
(2.47)Given the consideration of two factors and their interaction on the combination of dependent variables, the amount of the S component due to error is decreased compared to a MANOVA model incorporating only one covariate. The complete partition equation is given by
Stotal=∑i∑j∑k(Yijk−ˉY)(Yijk−ˉY)′= Nj∑j(ˉYj−ˉY)(ˉYj−ˉY)′+∑Kk=1(ˉYk−ˉY)(ˉYk−ˉY)′+[Njk∑nj−1∑Kk=1(ˉYjk−ˉY)(ˉYjk−ˉY)′−Nj∑nj−1(ˉYj−ˉY)(ˉYj−ˉY)′−∑Kk=1(ˉYk−ˉY)(ˉYk−ˉY)′]+∑i∑j∑k(Yijk−ˉYjk)(Yijk−ˉYjk)′,
 (2.48)
(2.48)or
Stotal=SX1+SX2+SX1X2+ Swithin.
It can be seen from Equation (2.49) that although mathematically more complex, the general MANOVA model resembles ANOVA in terms of the way to partition total variance into a variety of components.
The application of MANOVA has several advantages over ANOVA. First, this multivariate model yields a more reliable level of Type I errors on multiple response measurements than a set of separate ANOVA models, thereby potentially resulting in much larger F-values. Second, the use of MANOVA is statistically more efficient than ANOVA in discovering the factors that are truly important, particularly since multiple dependent variables are analyzed within an integrated statistical procedure. Nevertheless, there are some distinctive disadvantages about MANOVA. Given a much more complex design, the analytic results obtained from MANOVA are sometimes ambiguous, particularly concerning which covariate affects each of the dependent variables thereby forcing the researcher to make additional, subjective assumptions. Second, one degree of freedom is lost for each added dependent variable; as a result, the gain of power from decreased SS error may be offset to some unanticipated extent. Third, the assumption about normality is violated in the presence of outliers. Therefore, if they are present in the application of MANOVA, the outliers must be transformed or simply removed.
2.3.2. Hypothesis testing on effects in MANOVA
In MANOVA, Wilks’ lambda distribution is regularly used as a preferable statistic to perform the multivariate hypothesis test. In statistics, this distribution is a multivariate generalization of the univariate F-distribution described in Section 2.2. In multivariate data, the variance matrix is a determinant, found for each cross-products S matrix (mathematically, a determinant is a quantity obtained by the addition of products of the elements of a square matrix according to a given rule). Wilks’ lambda is used to form ratios of determinants for testing the main effects and the interactions. For a given S component, the equation for the Wilks’ lambda statistic, denoted Λ, is
Λ=|Swithin||Seffect+ Swithin|,
 (2.50)
(2.50)where Seffect is a specific S effect component (main effect or interaction), and Swithin is also referred to as Serror.
Given the Wilks’ lambda statistic, the approximated F statistic can be computed with two degrees of freedom associated with the S components, given by
Approximate F(df1,df2)=(1−˜y˜y)(df2df2),
 (2.51)
(2.51)where
˜y=˜s√Λ,
and, let M be the number of independent variables,
˜s=√M2(dfeffect)2−4M2+(dfeffect)2−5.
 (2.53)
(2.53)The two degrees of freedom in Equation (2.51) are defined as
df1=M(dfeffect),
where dfeffect is associated with a specific S component (e.g., if X1 has four levels, the degrees of freedom for its effect is 3), and
df2=˜s[(dferror)−(M−dferror+12)]−[M(dferror)−22].

From Wilks’ Lambda, a measure of strength of association can also be derived for performing the multivariate hypothesis test, given by
˜η2=1−Λ,
where ˜η2 indicates the variance accounted for by the best linear combination of dependent variables because Λ is the variance not accounted for by the combined measurements. Empirically, however, the value of ˜η2 can be greater than one in MANOVA given its multivariate nature. Therefore, a recommended alternative, when ˜s>1
indicates the variance accounted for by the best linear combination of dependent variables because Λ is the variance not accounted for by the combined measurements. Empirically, however, the value of ˜η2 can be greater than one in MANOVA given its multivariate nature. Therefore, a recommended alternative, when ˜s>1 , is
, is
partial ˜η2=1−˜s√Λ.
In addition to Wilks’ Lambda, there are some other multivariate test statistics for MANOVA, such as Hotelling’s trace criterion, Pillai’s criterion, and Roy’s greatest root criterion. The Hotelling’s trace test statistic, denoted by ˜T , is a pooled ratio of effect variance over error variance, given by
, is a pooled ratio of effect variance over error variance, given by
˜T=trace(SeffectSwithin),
 (2.56)
(2.56)where trace is a term used in linear algebra, defined as the sum of the elements on the main diagonal of a square matrix.
Similarly, Pillai’s trace statistic, denoted ˜P , pools effect variances:
, pools effect variances:
˜P=trace(SeffectSeffect+Swithin).
 (2.57)
(2.57)The fourth multivariate test statistic, Roy’s greatest root criterion, uses the largest eigenvalue of Seffect/Swithin. Among the four multivariate F test statistics, Pillai’s trace statistic is widely considered the most robust and powerful perspective that provides the most conservative F-statistic.
When an effect has only two levels (like treatment in the prior empirical example), the F tests for Wilks’ Lambda and other multivariate statistics are identical. In other situations, the F values differ slightly, and there is some controversy concerning which statistic provides more reliable results, particularly when the different values cross the critical level. Tabachnick and Fidell (2007) provide some valuable discussions for the respective strengths and weaknesses of these statistics.
2.3.3. Repeated measures MANOVA
The classical MANOVA is statistically efficient only when correlation between multiple dependent variables is minor. In longitudinal data analysis, this restriction is usually not realistic because within-subject observations are generally more related than between subjects. Therefore, if the researcher is interested in using MANOVA to analyze longitudinal data, the classical MANOVA approach described in Section 2.3.1 needs to be further advanced by accounting for intraindividual correlation. The repeated measures MANOVA model is described extensively in Bock (1975; Chapter 7) and Hedeker and Gibbons (2006; Chapter 3).
For an introduction, consider the case of two dependent variables with an additional factor with K levels other than time that takes n levels. Let Yik be a (1 × 2n)´ vector for subject i in group k (i = 1, …, Nk) at n time points. For repeated measures MANOVA, Yik can be expressed in term of a general linear model, given by
Yik=τ+λk+ɛik,
where τ is the (1 × 2n)´ vector for two sets of measurement means at n time points, lk is the vector of effect for group k with the same size, and ɛik is the vector for random errors assumed to be distributed as N(0,∑) in each of the population groups.
With further adjustments, Equation (2.58) is based on the assumption of a constant error variance–covariance matrix Σ for all K groups. In longitudinal data analysis, this assumption does not hold because the repeated measurements are usually correlated. The classical repeated measures MANOVA handles this issue by decomposing the time effect into n − 1 orthogonal polynomials for each dependent variable assuming equal spacing across all time points (Bock, 1975). In statistics, an orthogonal polynomial sequence is a family of polynomials such that any two different polynomials in the sequence are orthogonal to each other under some inner product. For example, given four time points in a longitudinal dataset, a (4 − 1) × 4 matrix can be created for linear, quadratic, and cubic polynomial contrast (the row of the matrix, 4 − 1 = 3) on each dependent variable. This matrix specifies the orthogonal polynomial coefficients for the three contrast components. These orthogonal polynomials reflect the degree of change over time in the response measurement and indicate the relative importance of each polynomial component. By including this orthogonal polynomial matrix in Equation (2.58), the repeated measurements become conditionally independent thereby deriving statistically efficient variance components for F tests. The orthogonal polynomial contrasts given equal spacing can be found in Pearson and Hartley (1976; Table 47). Appendix A provides a more detailed description of this transformation approach.
Given the use of orthogonal polynomial transformation, an (n × 2) × (n × 2) matrix of orthogonal polynomials may be specified for two dependent variables, denoted P, with the first row for each variable component being the constant term and the following rows for the linear, quadratic, and cubic. The mean vector τ can then be transformed into an orthogonalized mean vector τ* = Pτ, where τ* is a (1 × 2n)´ vector of transformed means at n time points for two dependent variables. Multiplying both sides of Equation (2.58) gives rise to
PYik=Pτ+Pλk+Pɛik=τ*+λ*k+ɛ*ik,
 (2.59)
(2.59)where ɛ*ik∼N(0,PΣP′)=N(0,Σ*) .
.
After the orthogonal transformation, the total sums of squares in the repeated measures MANOVA, denoted by S*total , is written as
, is written as
S*total=PStotalP′=P[∑i∑j∑k(Yijk−ˉY)(Yijk−ˉY)′]P′.
 (2.60)
(2.60)Let Stime be the S matrix for the effect of time and Sgroup be the S matrix for the effect of group, and S*time , S*group
, S*group are the corresponding sums of squares after orthogonal transformation. The two S matrix components in repeated measures MANOVA are then given by
are the corresponding sums of squares after orthogonal transformation. The two S matrix components in repeated measures MANOVA are then given by
S*time=PStimeP′=NP[ j∑j(ˉYj−ˉY)(ˉYj−ˉY)′]P′,
 (2.61)
(2.61)S*group=PSgroupP′=P[∑Kk=1(ˉYk−ˉY)(ˉYk−ˉY)′]P′.
 (2.62)
(2.62)Likewise, the S matrix for error after orthogonal transformation, denoted S*within , is
, is
S*within=PSwithinP′=P(S*total−S*time−S*group)P′.
The above S matrices, all symmetric, provide multivariate information about between-subjects variability. The multivariate hypothesis tests on various S components can be performed by using the four multivariate test statistics described in Section 2.3.2 – Wilks’ Lambda, Hotelling’s trace criterion, Pillai’s criterion, and Roy’s greatest root criterion. The availability of these matrices is also sufficient to derive the univariate repeated measures ANOVA results by extracting the diagonal elements from the respective S matrices. Specifically, SS(Time), the univariate total sum of squares due to time, can be obtained from the sum of the diagonal elements in S*time except the first one; SS(Group), the total sum of squares due to group, is simply the first element in S*group
except the first one; SS(Group), the total sum of squares due to group, is simply the first element in S*group ; and SS(Time × Group) is the sum of the rest of the diagonal elements in S*group. Similarly, SS(subjects), the univariate sum of squares due to subjects, is the first element in the matrix S*within, and the rest of the diagonal elements in this S* matrix for error are then summed up to make SS(error). Given these ANOVA-type statistics, the degree of freedom for each SS component is identical to those specified for the two-factor repeated measures ANOVA. As a result, the univariate MS and F statistics can be obtained from using the ANOVA procedure described in Section 2.2.3.
; and SS(Time × Group) is the sum of the rest of the diagonal elements in S*group. Similarly, SS(subjects), the univariate sum of squares due to subjects, is the first element in the matrix S*within, and the rest of the diagonal elements in this S* matrix for error are then summed up to make SS(error). Given these ANOVA-type statistics, the degree of freedom for each SS component is identical to those specified for the two-factor repeated measures ANOVA. As a result, the univariate MS and F statistics can be obtained from using the ANOVA procedure described in Section 2.2.3.
Notably, there are strong restrictions to applying repeated measures MANOVA in longitudinal data analysis. In addition to the common issues shared in all ANOVA models, the most serious concern, given the multivariate nature of repeated measures MANOVA, is that subjects with any missing observations must be removed from the analysis. Consequently, removal of too many cases from an analysis can result in biased variance estimates.
2.3.4. Empirical illustration: a two-factor repeated measures MANOVA on the effectiveness of acupuncture treatment on two psychiatric disorders
In Section 2.2.4, an empirical example was provided on how to apply repeated measures ANOVA for analyzing the effect of acupuncture treatment on the PCL score and its changing pattern over time. In the present illustration, I consider an additional response variable – the Beck Depression Inventory-II score, or BDI-II – with a doubly multivariate repeated measures design. The BDI-II is a psychometrically sound 21-item self-report measurement, with value ranging from 0 to 63. A higher BDI-II score indicates enhanced severity of depression. This second dependent variable is named BDI_SUM in the analysis. As the longitudinal data now involves multivariate repeated measures for two dependent variables, PCL_SUM and BDI_SUM, a two-factor repeated measures MANOVA model is created, with the independent factors still being TIME and TREAT (TIME: 0 = baseline survey, 1 = 4-week follow-up, 2 = 8-week follow-up, 3 = 12-week follow-up; TREAT: 1 = receiving acupuncture treatment, 0 = else). The MANOVA analysis is intended to test the null hypotheses that both PCL_SUM and BDI_SUM do not change over time and neither do they differ between the two treatment groups. It is also assumed that there is no interactive effect on repeated measurements of both dependent variables between TIME and TREAT, and that there is no subject’s effect given the specification of two covariates.
As BDI_SUM is considered as an additional dependent variable, its repeated measurements at four time points need to be included in the creation of the temporary dataset TP2. Below is the SAS program for this step.
SAS Program 2.5a:

Given the recreation of TP2, the MANOVA analysis is then conducted with two dependent variables measured at four time points for each subject. The SAS PROC GLM procedure with the REPEATED statement is used again. The following program displays the detailed statements.
SAS Program 2.5b:

In SAS Program 2.5b, the MODEL statement specifies two sets of multivariate repeated measures as dependent variables, PCL_SUM0 − PCL_SUM3 and BDI_SUM0 − BDI_SUM3. On the right of the equation mark, only TREAT is explicitly given as a covariate. As specified in repeated measures MANOVA, the effect of TIME is reflected in the main effects of the repeated measurements, and likewise, the interaction between TIME and TREAT is summarized by variations of TIME’s effect between two treatment groups. In the REPEATED statement, the option RESPONSE 2 tells SAS that there are two response variables. The IDENTITY option is applied to generate an identity transformation corresponding to the associated factor. Similarly, the option TIME 4 specifies the number of repeated measurements for each dependent variable. The SAS PROC GLM procedure also has the capability to test statistical significance for specified contrasts in repeated measures MANOVA; such a testing step will be described later when linear mixed models are described.
SAS Program 2.5b derives multivariate tests for the main effects of TIME and TREAT and their interactions across responses. The overall information of the doubly multivariate repeated measures design is displayed first, as shown below.
SAS Program Output 2.2a:

SAS Program Output 2.2a displays that the factor TREAT has two levels with the values 0 or 1. More than half of the observations are not included in the analysis because MANOVA removes all subjects with missing observations (the problems arising from this removal will be discussed in the Section 2.4).
Next, the repeated measures level information is displayed.
SAS Program Output 2.2b:

The above table presents that the response variable is 1 for the PCL_SUM repeated measurements and 2 for the BDI_SUM scores. As indicated earlier, there are four levels for TIME. The multivariate tests for the overall effect of acupuncture treatment across the two responses are presented next, referred to as Response*Treat Effect in the MANOVA table.
SAS Program Output 2.2c:

From SAS Program Output 2.2c, the main effect of acupuncture treatment is marginally significant across the two responses. Because an interaction between TREAT and TIME is specified, the statistical significance of the main effect for acupuncture treatment will be further assessed after checking the significance of that interaction. If an underlying factor only includes two levels, like the case of TREAT, the four multivariate test statistics take exactly the same F-value, thereby generating the identical conclusion about the test.
Below I display the results of the multivariate tests for the overall time effect across two responses, referred to as Response*Time Effect in the MANOVA table.
SAS Program Output 2.2d:

As shown above, the time effect is statistically significant across the two responses with a p-value that is lower than 0.0001. Again, all four multivariate test statistics are identical given two levels of the treatment factor.
The multivariate test results for the TREAT-by-TIME interaction across two responses, referred to in the MANOVA table as Response*Treat*Time test, are presented as follows.
SAS Program Output 2.2e:

As illustrated, the overall effect of the TREAT-by-TIME interaction is statistically significant across the two responses, with p-value below 0.01. Given the statistical significance of the interaction term, the main effect of acupuncture treatment should therefore be regarded as statistically significant, although its p-value is greater than 0.05.
The multivariate test results for within-subjects effect, referred to as the Response effect in the MANOVA table, are reported as follows.
SAS Program Output 2.2f:

Thus, within-subject random errors are also statistically significant across the two responses. The p-value associated with the residuals is below 0.0001.
Finally, SAS Program 2.5b generates an ANOVA-type table that reports the results of hypothesis test of the between-subjects effects, given below.
SAS Program Output 2.2g:

The above table indicates that after including the factors TREAT and TIME, there is only a fairly minor subject effect across the two responses as the associated p-value is slightly above 0.05.
SAS Program 2.5b does not generate a transformation matrix P. If the detailed values of this matrix are needed, the researcher should use a MANOVA statement and specify the SUMMARY option.
2.4. Summary
This chapter describes a number of classical approaches that have been historically popular in longitudinal data analysis. I provided an overview on the descriptive methods including time plots of trends, paired t-tests, and effect sizes and meta-analysis. Although useful for the description of raw longitudinal data and capable of providing insights into the pattern of change over time for an event, these methods only have the capability to provide tentative analytic results. Methodologically, due to the existence of one or more lurking or confounding variables, a seemingly longitudinal pattern may actually result from a spurious association, a relationship in which two factors have no actual causal connection but appear correlated. There are some exceptions in biomedical studies, as illustrated in some of the randomized controlled clinical trials in which the potential confounding effects are partially taken into account in the process of randomization.
In this chapter, repeated measures ANOVA and repeated measures MANOVA are also described, applied traditionally to analyze the single and multiple dependent response variables with repeated measurements. The limitations of using these methods have been well documented and are briefly discussed above. As special cases of general linear models, both ANOVA and MANOVA can be fitted by using least squares estimating techniques with inclusion of predictor variables thereby addressing some of the concerns reserved for descriptive approaches. Nevertheless, the estimating procedures for both models are very sensitive to outliers and heterogeneous variances. MANOVA has the added disadvantage that the model can only be used for balanced data, and subjects with missing observations have to be removed from further analysis. As many assumptions for their applications are usually unrealistic given the nature of longitudinal data, both ANOVA and MANOVA perspectives have gradually become much less applied in longitudinal data analysis than the more powerful, more flexible mixed-effects models. At present, the value of various ANOVA models resides primarily in providing a foundation for the specification of linear mixed models, as will become clearer in succeeding chapters.
..................Content has been hidden....................
You can't read the all page of ebook, please click here login for view all page.