
With a bit of context established for how microformats fit into the
overall web space, let’s now turn to some practical applications of XFN,
which is by far the most popular microformat you’re likely to encounter.
As you already know, XFN is a means of identifying relationships to other people by
including a few keywords in the rel
attribute of an anchor tag. XFN is commonly used in blogs, and
particularly in “blogroll” plug-ins such as those offered by
WordPress.[10] Consider the following HTML content, shown in Example 2-1, that might be present in a blogroll.
Example 2-1. Example XFN markup
<div>
<a href="http://example.org/matthew" rel="me">Matthew</a>
<a href="http://example.com/users/jc" rel="friend met">J.C.</a>
<a href="http://example.com/users/abe" rel="friend met co-worker">Abe</a>
<a href="http://example.net/~baseeret" rel="spouse met">Baseeret</a>
<a href="http://example.net/~lindsaybelle" rel="child met">Lindsay Belle</a>
</div>From reading the content in the rel tags, it’s hopefully pretty obvious what the
relationships are between the various people. Namely, some guy named
Matthew has a couple of friends, a spouse, and a child. He works with one
of these friends and has met everyone in “real life” (which wouldn’t be
the case for a strictly online associate). Apart from using a well-defined vocabulary, that’s
about all there is to XFN. The good news is that it’s deceptively simple,
yet incredibly powerful when employed at a large enough scale because it
is deliberately authored structured information. Unless you run across
some content that’s just drastically out of date—as in two best friends
becoming archenemies but just forgot to update their blogrolls
accordingly—XFN gives you a very accurate indicator as to how two people
are connected. Given that most blogging platforms support XFN, there’s
quite a bit of information that can be discovered. The bad news is that
XFN doesn’t really tell you anything beyond those basics, so you have to
use other sources of information and techniques to discover anything
beyond conclusions, such as, “Matthew and Baseeret are married and have a
child named Lindsay Belle.” But you have to start somewhere, right?
Let’s whip up a simple script for harvesting XFN data similar to the service offered by rubhub, a social search engine that crawls and indexes a large number of websites using XFN. You might also want to check out one of the many online XFN tools if you want to explore the full specification before moving on to the next section.
Let’s get social by mining some XFN data and building out a social
graph from it. Given that XFN can be embedded into any conceivable web
page, the bad news is that we’re about to do some web scraping. The good
news, however, is that it’s probably the most trivial web scraping
you’ll ever do, and the BeautifulSoup
package absolutely minimizes the burden. The code in Example 2-2 uses Ajaxian, a popular blog about
modern-day web development, as the basis of the graph. Do yourself a
favor and easy_install BeautifulSoup before trying to run
it.
Example 2-2. Scraping XFN content from a web page (microformats__xfn_scrape.py)
# -*- coding: utf-8 -*-
import sys
import urllib2
import HTMLParser
from BeautifulSoup import BeautifulSoup
# Try http://ajaxian.com/
URL = sys.argv[1]
XFN_TAGS = set([
'colleague',
'sweetheart',
'parent',
'co-resident',
'co-worker',
'muse',
'neighbor',
'sibling',
'kin',
'child',
'date',
'spouse',
'me',
'acquaintance',
'met',
'crush',
'contact',
'friend',
])
try:
page = urllib2.urlopen(URL)
except urllib2.URLError:
print 'Failed to fetch ' + item
try:
soup = BeautifulSoup(page)
except HTMLParser.HTMLParseError:
print 'Failed to parse ' + item
anchorTags = soup.findAll('a')
for a in anchorTags:
if a.has_key('rel'):
if len(set(a['rel'].split()) & XFN_TAGS) > 0:
tags = a['rel'].split()
print a.contents[0], a['href'], tagsWarning
As of Version 3.1.x, BeautifulSoup switched to using HTMLParser
instead of the SGMLParser,
and as a result, a common complaint is that BeautifulSoup seems a
little less robust than in the 3.0.x release branch. The author of
BeautifulSoup recommends a
number of options, with the most obvious choice being to
simply use the 3.0.x version if 3.1.x isn’t robust enough for your
needs. Alternatively, you can catch the HTMLParseError,
as shown in Example 2-2, and discard
the content.
Running the code against a URL that includes XFN information returns the name, type of relationship, and a URL for each of a person’s friends. Sample output follows:
Dion Almaer http://www.almaer.com/blog/ [u'me']
Ben Galbraith http://weblogs.java.net/blog/javaben/ [u'co-worker']
Rey Bango http://reybango.com/ [u'friend']
Michael Mahemoff http://softwareas.com/ [u'friend']
Chris Cornutt http://blog.phpdeveloper.org/ [u'friend']
Rob Sanheim http://www.robsanheim.com/ [u'friend']
Dietrich Kappe http://blogs.pathf.com/agileajax/ [u'friend']
Chris Heilmann http://wait-till-i.com/ [u'friend']
Brad Neuberg http://codinginparadise.org/about/ [u'friend']
Assuming that the URL for each friend includes XFN or other useful information, it’s straightforward enough to follow the links and build out more social graph information in a systematic way. That approach is exactly what the next code example does: it builds out a graph in a breadth-first manner, which is to say that it does something like what is described in Example 2-3 in pseudocode.
Example 2-3. Pseudocode for a breadth-first search
Create an empty graph
Create an empty queue to keep track of nodes that need to be processed
Add the starting point to the graph as the root node
Add the root node to a queue for processing
Repeat until some maximum depth is reached or the queue is empty:
Remove a node from the queue
For each of the node's neighbors:
If the neighbor hasn't already been processed:
Add it to the queue
Add it to the graph
Create an edge in the graph that connects the node and its neighborNote that this approach to building out a graph has the advantage of naturally creating edges between nodes in both directions, if such edges exist, without any additional bookkeeping required. This is useful for social situations since it naturally lends itself to identifying mutual friends without any additional logic. The refinement of the code from Example 2-2 presented in Example 2-4 takes a breadth-first approach to building up a NetworkX graph by following hyperlinks if they appear to have XFN data encoded in them. Running the example code for even the shallow depth of two can return quite a large graph, depending on the popularity of XFN within the niche community of friends at hand, as can be seen by generating an image file of the graph and inspecting it or running various graph metrics on it (see Figure 2-1).
Note
Windows users may want to review Visualizing Tweet Graphs for an explanation of why
the workaround for nx.drawing.write_dot is necessary in
Example 2-4.
Example 2-4. Using a breadth-first search to crawl XFN links (microformats__xfn_crawl.py)
# -*- coding: utf-8 -*-
import sys
import os
import urllib2
from BeautifulSoup import BeautifulSoup
import HTMLParser
import networkx as nx
ROOT_URL = sys.argv[1]
if len(sys.argv) > 2:
MAX_DEPTH = int(sys.argv[2])
else:
MAX_DEPTH = 1
XFN_TAGS = set([
'colleague',
'sweetheart',
'parent',
'co-resident',
'co-worker',
'muse',
'neighbor',
'sibling',
'kin',
'child',
'date',
'spouse',
'me',
'acquaintance',
'met',
'crush',
'contact',
'friend',
])
OUT = "graph.dot"
depth = 0
g = nx.DiGraph()
next_queue = [ROOT_URL]
while depth < MAX_DEPTH:
depth += 1
(queue, next_queue) = (next_queue, [])
for item in queue:
try:
page = urllib2.urlopen(item)
except urllib2.URLError:
print 'Failed to fetch ' + item
continue
try:
soup = BeautifulSoup(page)
except HTMLParser.HTMLParseError:
print 'Failed to parse ' + item
continue
anchorTags = soup.findAll('a')
if not g.has_node(item):
g.add_node(item)
for a in anchorTags:
if a.has_key('rel'):
if len(set(a['rel'].split()) & XFN_TAGS) > 0:
friend_url = a['href']
g.add_edge(item, friend_url)
g[item][friend_url]['label'] = a['rel'].encode('utf-8')
g.node[friend_url]['label'] = a.contents[0].encode('utf-8')
next_queue.append(friend_url)
# Further analysis of the graph could be accomplished here
if not os.path.isdir('out'):
os.mkdir('out')
try:
nx.drawing.write_dot(g, os.path.join('out', OUT))
except ImportError, e:
# Help for Windows users:
# Not a general purpose method, but representative of
# the same output write_dot would provide for this graph
# if installed and easy to implement
dot = []
for (n1, n2) in g.edges():
dot.append('"%s" [label="%s"]' % (n2, g.node[n2]['label']))
dot.append('"%s" -> "%s" [label="%s"]' % (n1, n2, g[n1][n2]['label']))
f = open(os.path.join('out', OUT), 'w')
f.write('''strict digraph {
%s
}''' % (';
'.join(dot), ))
f.close()
# *nix users could produce an image file with a good layout
# as follows from a terminal:
# $ circo -Tpng -Ograph graph.dot
# Windows users could use the same options with circo.exe
# or use the GVedit desktop applicationNote
The use of the attribute label for the nodes and edges in the
DiGraph isn’t arbitrary. Attributes
included in nodes and edges are serialized into the DOT language, and
Graphviz tools recognize label as
a
special attribute.
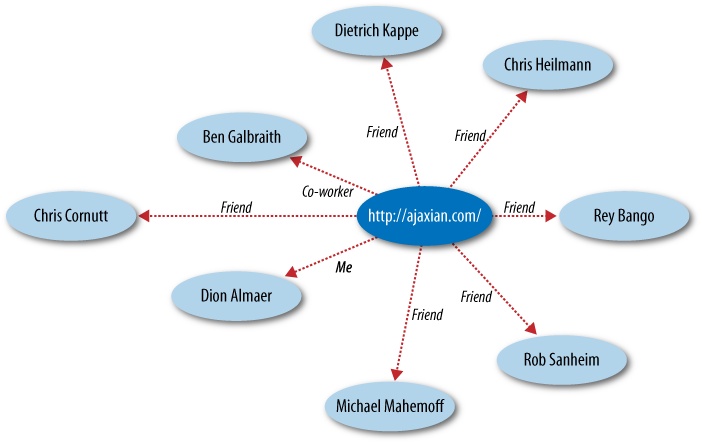
Despite its simplicity, the graph is very interesting. It connects eight people, with a gentleman by the name of Dion Almaer being the common thread. Note, however, that crawling out one or more levels might introduce other nodes in the graph that are connected to everyone else. From the graph alone, it’s unclear whether Dion might have a closer relationship with Ben Galbraith than the other folks because of the difference between “co-worker” and “friend” relationships, but we could nonetheless crawl Ben’s XFN information, if he has provided any at the destination identified by his hyperlink, and search for other co-worker tags to build out a social network of who works with whom. See Chapter 6 for more on mining data as it relates to colleagues and coworkers.
We generally won’t take quite this long of a pause to analyze the approach, but given that this example is the first real algorithm we’ve written, and that this isn’t the last we’ll see of it in this book, it’s worthwhile to examine it more closely. In general, there are two criteria for examination that you should always consider for an algorithm: efficiency and effectiveness. Or, to put it another way: performance and quality.
Standard performance analysis of any algorithm generally involves examining its worst-case time and space complexity—in other words, the amount of time it would take the program to execute, and the amount of memory required for execution over a very large data set. The breadth-first approach we’ve taken is essentially a breadth-first search, except that we’re not actually searching for anything in particular because there are no exit criteria beyond expanding the graph out either to a maximum depth or until we run out of nodes. If we were searching for something specific instead of just crawling links indefinitely, that would be considered an actual breadth-first search. In practice, however, almost all searches impose some kind of exit criteria because of the limitations of finite computing resources. Thus, a more common variation of a breadth-first search is called a bounded breadth-first search, which imposes a limit on the maximum depth of the search just as we do in this example.
For a breadth-first search (or breadth-first crawl), both the time and space complexity can be bounded in the worst case by bd, where b is the branching factor of the graph and d is the depth. If you sketch out an example on paper and think about it, this analysis makes a lot of sense. If every node in a graph had five neighbors, and you only went out to a depth of one, you’d end up with six nodes in all: the root node and its five neighbors. If all five of those neighbors had five neighbors too, and you expanded out another level, you’d end up with 31 nodes in all: the root node, the root node’s five neighbors, and five neighbors for each of the root node’s neighbors. Such analysis may seem pedantic, but in the emerging era of big data, being able to perform at least a crude level of analysis based on what you know of the data set is more important than ever. Table 2-2 provides an overview of how bd grows for a few sizes of b and d.
Table 2-2. Example branching factor calculations for graphs of varying depths
| Branching factor | Nodes for depth = 1 | Nodes for depth = 2 | Nodes for depth = 3 | Nodes for depth = 4 | Nodes for depth = 5 |
|---|---|---|---|---|---|
| 2 | 3 | 7 | 15 | 31 | 63 |
| 3 | 4 | 13 | 40 | 121 | 364 |
| 4 | 5 | 21 | 85 | 341 | 1365 |
| 5 | 6 | 31 | 156 | 781 | 3906 |
| 6 | 7 | 43 | 259 | 1555 | 9331 |
While the previous comments pertain primarily to the theoretical
bounds of the algorithm, one final consideration worth noting is the
practical performance of the algorithm for a data set of a fixed size.
Mild profiling of the code would reveal that it is primarily
I/O bound from the standpoint that the vast
majority of time is spent waiting for the urlopen method to return content to be
processed. A later example, Threading Together Conversations, introduces and
demonstrates the use of a thread pool to increase
performance in exchange for a modicum of complexity.
A final consideration in analysis is the overall quality of the
results. From the standpoint of quality analysis, basic visual
inspection of the graph output reveals that there actually is a graph
that connects people. Mission accomplished? Yes, but there’s always
room for improvement. One consideration is that slight variations in
URLs result in multiple nodes potentially appearing in the graph for
the same person. For example, if Matthew is referenced in one
hyperlink with the URL
http://example.com/~matthew but as
http://www.example.com/~matthew in another URL,
those two nodes will remain distinct in the graph even though they
most likely point to the same resource on the Web. Fortunately, XFN
defines a special rel="me"
value that can be used for identity
consolidation. Google’s Social Graph
API takes this very approach to connect a user’s various
profiles, and there exist many
examples of services that use rel="me" to allow
users to connect profiles across multiple external sites. Another
(much lesser) issue in resolving URLs is the use or omission of a
trailing slash at the end. Most well-designed sites will automatically
redirect one to the other, so this detail is mostly a
nonissue.
Fortunately, others have also recognized these kinds of problems and decided to do something about them. SocialGraph Node Mapper is an interesting open source project that standardizes URLs relative to trailing slashes, the presence of “www”, etc., but it also recognizes that various social networking sites might expose different URLs that all link back to the same person. For example, http://blog.example.com/matthew and http://status.example.com?user=matthew might resolve to the same person for a given social networking site.