
This chapter introduces some fundamental tools and techniques for analyzing your mail—a classic data staple of the Internet that despite all of the advances in social networking will still be around for ages to come—to answer questions such as:
Who sends out the most mail?
Is there a particular time of the day (or day of the week) when the sender is most likely to get a response to a question?
Which people send the most messages among one another?
What are the subjects of the liveliest discussion threads?
Although social media sites are racking up petabytes of near-real-time social data, there is still the significant drawback that, unlike email, social networking data is centrally managed by a service provider who gets to create the rules about exactly how you can access it and what you can and can’t do with it.[12] Mail data, on the other hand, is largely decentralized and is scattered across the Web in the form of rich mailing list discussions about a litany of interesting topics. Although it’s true that service providers such as Google and Yahoo! restrict your use of mailing list data if you retrieve it using their services, there are slightly less formidable ways to mine the content that have a higher probability of success: you can easily collect data yourself by subscribing to a list and waiting for the box to start filling up, ask the list owner to provide you with an archive, etc. Another interesting consideration is that unlike social media sites, enterprises generally have full control of their mailboxes and may want to perform aggregate analyses and identify certain kinds of trends.
As you might have guessed, it’s not always easy (if possible at all) to find realistic social data sets for purposes of illustration, but fortunately, this chapter has some of the most realistic data imaginable: the public Enron data set.
In case you haven’t come across an mbox file before, it’s basically
just a large text file of concatenated mail messages that are easily
accessible by text-based tools. The beginning of each message is signaled
by a special From_ line formatted to
the pattern "From [email protected] Fri Dec 25
00:06:42 2009", where the date/time stamp is asctime,
a standardized fixed-width representation of a timestamp.
Note
The mbox format is very common, and most mail clients provide an “export” or “save as” option to export data to this format regardless of the underlying implementation.
In an mbox file, the boundary between messages is determined by a From_ line preceded (except for the first occurrence) by exactly two new lines. Example 3-1 is a small slice from a fictitious mbox containing two messages.
Example 3-1. A slice of a sample mbox file
From [email protected] Fri Dec 25 00:06:42 2009 Message-ID: <[email protected]> References: <[email protected]> In-Reply-To: <[email protected]> Date: Fri, 25 Dec 2001 00:06:42 -0000 (GMT) From: St. Nick <[email protected]> To: [email protected] Subject: RE: FWD: Tonight Mime-Version: 1.0 Content-Type: text/plain; charset=us-ascii Content-Transfer-Encoding: 7bit Sounds good. See you at the usual location. Thanks, -S -----Original Message----- From: Rudolph Sent: Friday, December 25, 2009 12:04 AM To: Claus, Santa Subject: FWD: Tonight Santa - Running a bit late. Will come grab you shortly. Standby. Rudy Begin forwarded message: > Last batch of toys was just loaded onto sleigh. > > Please proceed per the norm. > > Regards, > Buddy > > -- > Buddy the Elf > Chief Elf > Workshop Operations > North Pole > [email protected] From [email protected] Fri Dec 25 00:03:34 2009 Message-ID: <[email protected]> Date: Fri, 25 Dec 2001 00:03:34 -0000 (GMT) From: Buddy <[email protected]> To: [email protected] Subject: Tonight Mime-Version: 1.0 Content-Type: text/plain; charset=us-ascii Content-Transfer-Encoding: 7bit Last batch of toys was just loaded onto sleigh. Please proceed per the norm. Regards, Buddy -- Buddy the Elf Chief Elf Workshop Operations North Pole [email protected]
In Example 3-1 we see two messages, although there is evidence of at least one other message that might exist in the mbox. Chronologically, the first message is authored by a fellow named Buddy and was sent out to [email protected] to announce that the toys had just been loaded. The other message in the mbox is a reply from Santa to Rudolph. Not shown in the sample mbox is an intermediate message in which Rudolph forwarded Buddy’s message to Santa with the note about how he is running late. Although we could infer these things by reading the text of the messages themselves, we also have important clues by way of the Message-ID, References, and In-Reply-To headers. These headers are pretty intuitive and provide the basis for algorithms that display threaded discussions and things of that nature. We’ll look at a well-known algorithm that uses these fields to thread messages a bit later, but the gist is that each message has a unique message ID, contains a reference to the exact message that is being replied to in the case of it being a reply, and can reference multiple other messages in the reply chain, which are part of the larger discussion thread at hand.
Note
Beyond using some Python modules to do the dirty work for us, we won’t journey into discussions concerning the nuances of email messages such as multipart content, MIME, 7-bit content transfer encoding, etc. You won’t have to look very hard to find a number of excellent references that cover these topics in depth if you’re interested in taking a closer look.
These headers are vitally important. Even with this simple example,
you can already see how things can get messy when you’re parsing the
actual body of a message: Rudolph’s client quoted forwarded content with
> characters, while the mail client
Santa used to reply apparently didn’t quote anything, but instead included
a human-readable message header. Trying to parse out the exact flow of a
conversation from mailbox data can be a very tricky business, if not
completely impossible, because of the ambiguity involved. Most mail
clients have an option to display extended mail headers beyond the ones
you normally see, if you’re interested in a technique a little more
accessible than digging into raw storage when you want to view this kind
of information. Example 3-2
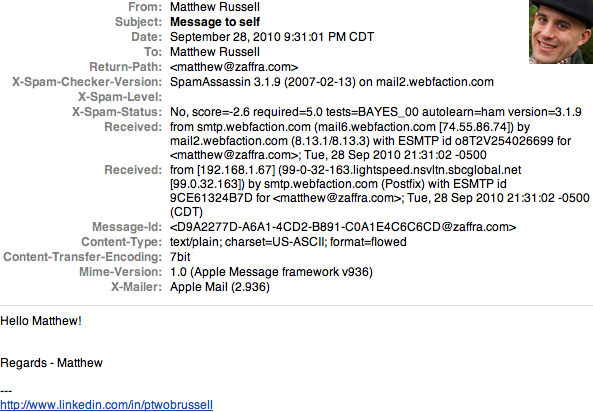
illustrates the message flow from Example 3-1, and Figure 3-1
shows sample headers as displayed by Apple Mail.
Example 3-2. Message flow from Example 3-1
Fri, 25 Dec 2001 00:03:34 -0000 (GMT) - Buddy sends a message to the workshop
Friday, December 25, 2009 12:04 AM - Rudolph forwards Buddy's message to Santa
with an additional note
Fri, 25 Dec 2001 00:06:42 -0000 (GMT) - Santa replies to RudolphLucky for us, there’s a lot you can do without having to essentially reimplement a mail client. Besides, if all you wanted to do was browse the mailbox, you’d simply import it into a mail client and browse away, right? Although it’s a rote exercise, it’s worth taking a moment to explore whether your mail client has an option to import/export data in the mbox format so that you can use the tools in this chapter to slice and dice it.
Python offers some basic tools for parsing mbox data, and the script in Example 3-3 introduces a basic technique for converting mbox data to an array of JSON objects.
Warning
Note that Example 3-3 includes the
decode('utf-8', 'ignore') function in
several places. When working with text-based data such as email or web
pages, it’s not at all uncommon to run into the infamous UnicodeDecodeError because of funky character
encodings, and it’s not always obvious what’s going on or how to fix the
problem. The short answer is that you can run the decode function on any string value and pass
it a second argument that specifies what to do in the event of a
UnicodeDecodeError. The default value
is 'strict', which results in the exception being raised,
but you can use 'ignore' or 'replace' instead,
depending on your needs.
Example 3-3. Converting an mbox to a more convenient JSON structure (mailboxes__jsonify_mbox.py)
# -*- coding: utf-8 -*-
import sys
import mailbox
import email
import quopri
from BeautifulSoup import BeautifulSoup
try:
import jsonlib2 as json # much faster then Python 2.6.x's stdlib
except ImportError:
import json
MBOX = sys.argv[1]
def cleanContent(msg):
# Decode message from "quoted printable" format
msg = quopri.decodestring(msg)
# Strip out HTML tags, if any are present
soup = BeautifulSoup(msg)
return ''.join(soup.findAll(text=True))
def jsonifyMessage(msg):
json_msg = {'parts': []}
for (k, v) in msg.items():
json_msg[k] = v.decode('utf-8', 'ignore')
# The To, CC, and Bcc fields, if present, could have multiple items
# Note that not all of these fields are necessarily defined
for k in ['To', 'Cc', 'Bcc']:
if not json_msg.get(k):
continue
json_msg[k] = json_msg[k].replace('
', '').replace(' ', '').replace('
'
, '').replace(' ', '').decode('utf-8', 'ignore').split(',')
try:
for part in msg.walk():
json_part = {}
if part.get_content_maintype() == 'multipart':
continue
json_part['contentType'] = part.get_content_type()
content = part.get_payload(decode=False).decode('utf-8', 'ignore')
json_part['content'] = cleanContent(content)
json_msg['parts'].append(json_part)
except Exception, e:
sys.stderr.write('Skipping message - error encountered (%s)' % (str(e), ))
finally:
return json_msg
# Note: opening in binary mode is recommended
mbox = mailbox.UnixMailbox(open(MBOX, 'rb'), email.message_from_file)
json_msgs = []
while 1:
msg = mbox.next()
if msg is None:
break
json_msgs.append(jsonifyMessage(msg))
print json.dumps(json_msgs, indent=4)Warning
As of Python 2.6.x, third-party C-based modules such as jsonlib2 (available via
easy_install) are significantly faster than the standard
library’s module, but Python 2.7 ships with an
update that’s on par with modules such as jsonlib2. For the purposes of illustration,
the difference between using the standard library versus jsonlib2 for reasonably large JSON
structures (north of 100 MB) can be on the order of tens of
seconds.
This short script does a pretty decent job of parsing out the most
pertinent information from an email and builds out a portable JSON object.
There’s more that we could do, but it addresses some of the most common
issues, including a primitive mechanism for decoding quoted-printable
text and stripping out any HTML tags. The quopri
module is used to handle the quoted-printable format, an encoding that is used
to transfer 8-bit content over a 7-bit channel.[13] Abbreviated sample output from Example 3-3 follows in Example 3-4.
Example 3-4. Sample JSON output as produced by Example 3-3 from the sample mbox in Example 3-1
[
{
"From": "St. Nick <[email protected]>",
"Content-Transfer-Encoding": "7bit",
"To": [
"[email protected]"
],
"parts": [
{
"content": "Sounds good. See you at the usual location.
Thanks,...",
"contentType": "text/plain"
}
],
"References": "<[email protected]>",
"Mime-Version": "1.0",
"In-Reply-To": "<[email protected]>",
"Date": "Fri, 25 Dec 2001 00:06:42 -0000 (GMT)",
"Message-ID": "<[email protected]>",
"Content-Type": "text/plain; charset=us-ascii",
"Subject": "RE: FWD: Tonight"
},
{
"From": "Buddy <[email protected]>",
"Content-Transfer-Encoding": "7bit",
"To": [
"[email protected]"
],
"parts": [
{
"content": "Last batch of toys was just loaded onto sleigh.
...",
"contentType": "text/plain"
}
],
"Mime-Version": "1.0",
"Date": "Fri, 25 Dec 2001 00:03:34 -0000 (GMT)",
"Message-ID": "<[email protected]>",
"Content-Type": "text/plain; charset=us-ascii",
"Subject": "Tonight"
}
]With your newly found skills to parse mail data into an accessible format, the urge to start analyzing it is only natural. The remainder of this chapter will use the publicly available Enron mail data, available as mbox downloads. The enron.mbox.gz file is an mbox constructed from messages appearing in “inbox” folders from the original Enron corpus, while the enron.mbox.json.gz file is that same data converted to JSON with the script shown in Example 3-3. Although not shown as an example, you can download the script that performed the conversion of raw Enron data to the mbox format with the mailboxes__convert_enron_inbox_to_mbox.py script. Note that if you search online, you’ll find that the closest thing to the official Enron data available at http://www.cs.cmu.edu/~enron/ is available in a nonstandard format that’s a little more suited to research and includes calendaring information, notes, etc. The script that was used to convert the portions of this data set explicitly marked as “Inbox data” into the mbox format is available at http://github.com/ptwobrussell/Mining-the-Social-Web/blob/master/python_code/mailboxes__convert_enron_inbox_to_mbox.py. The remainder of this chapter assumes that you are using the mbox data that is provided as downloads.
[12] Quite understandably, nobody has had a good enough reason (yet) to be the first to defend against multimillion-dollar litigation cases to find out whether the terms of use imposed by some social media sites are even enforceable. Hence, the status quo (to date) has been to play by the rules and back down when approached about possible infringements.
[13] See http://en.wikipedia.org/wiki/Quoted-printable for an overview, or RFC 2045 if you are interested in the nuts and bolts.