
Note
Initial printings of this book from February 2011 through February 2012 featured Google Buzz as the backdrop for data in this chapter. This chapter has been fully revised (with as few changes made as possible) to now feature Google+ instead. Example files have been updated and renamed with the plus__ prefix, but previous buzz__ example files are still available online with the other example code.
This short chapter begins our journey into text mining,[46] and it’s something of an inflection point in this book. Earlier chapters have mostly focused on analyzing structured or semi-structured data such as records encoded as microformats, relationships among people, or specially marked #hashtags in tweets. However, this chapter begins munging and making sense of textual information in documents by introducing Information Retrieval (IR) theory fundamentals such as TF-IDF, cosine similarity, and collocation detection. As you may have already inferred from the chapter title, Google+ initially serves as our primary source of data because it’s inherently social, easy to harvest,[47] and has a lot of potential for the social web. Toward the end of this chapter, we’ll also look at what it takes to tap into your Gmail data. In the chapters ahead, we’ll investigate mining blog data and other sources of free text, as additional forms of text analytics such as entity extraction and the automatic generation of abstracts are introduced. There’s no real reason to introduce Google+ earlier in the book than blogs (the topic of Chapter 8), other than the fact that Google+ activities (notes) fill an interesting niche somewhere between Twitter and blogs, so this ordering facilitates telling a story from cover to cover. All in all, the text-mining techniques you’ll learn in any chapter of this book could just as easily be applied to any other chapter.
Wherever possible we won’t reinvent the wheel and implement analysis tools from scratch, but we will take a couple of “deep dives” when particularly foundational topics come up that are essential to an understanding of text mining. The Natural Language Toolkit (NLTK), a powerful technology that you may recall from some opening examples in Chapter 1, provides many of the tools. Its rich suites of APIs can be a bit overwhelming at first, but don’t worry: text analytics is an incredibly diverse and complex field of study, but there are lots of powerful fundamentals that can take you a long way without too significant of an investment. This chapter and the chapters after it aim to hone in on those fundamentals.
Note
A full-blown introduction to NLTK is outside the scope of this book, but you can review the full text of Natural Language Processing with Python: Analyzing Text with the Natural Language Toolkit (O’Reilly) online. Paper copies are also available at http://oreilly.com/catalog/9780596516499.
Anyone with a Gmail account can trivially create a Google+ account and start collaborating with friends. From a product standpoint, Google+ has evolved rapidly and used some of the most compelling features (and anti-features) of existing social network platforms (such as Twitter and Facebook) in carving out its own set of unique features. A full overview of Google+ isn’t in scope for this chapter, and you can easily read about it (or sign up) online to learn more. Suffice it to say that Google+ has leveraged tried and true features of existing social networks such as marking content with hashtags and maintaining a profile according to customizable privacy settings with additional novelties such as a fresh take on content sharing called “circles,” video chats called “hangouts,” and extensive integration with other Google services such as Gmail contacts and Picasa web albums.
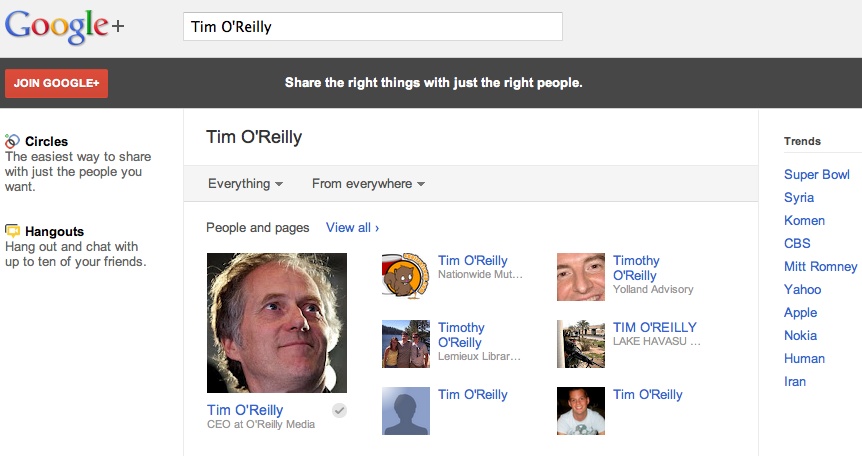
In Google+ API parlance, social interactions are framed in terms of people, activities, and comments. An activity is a note that could just as long as a blog post, but could also be void of any real textual meaning because it’s essentially just a pointer to multimedia data such as photos or videos. For the purposes of this chapter, we’ll be focusing on harvesting and analyzing Google+ activity data that is textual and intended to convey the same kind of meaning that you might encounter in a tweet, blog post, or Facebook status update. If you haven’t signed up for Google+ yet, it’s worth taking the time to do so, as well as spending a few moments to familiarize yourself with a Google+ profile. One of the easiest ways to find someone on Google+ is to just search for them at http://plus.google.com/. (Unfortunately, as of early 2012, there doesn’t appear to be a way to use somebody’s Gmail username to look up someone on Google+.) For example, searching for “Tim O’Reilly” produces the results shown in Figure 7-1, which easily surfaces his public profile page at https://plus.google.com/107033731246200681024/.
Let’s now fetch some data from Tim O’Reilly’s public profile by getting your development environment situated. In order to get started collecting Google+ data with Python, there are only a couple of prerequisites involved:
Install Google’s Python API client via
easy_install --upgrade google-api-python-client, which should take care of satisfying the various dependencies involved in interacting with the Google+ (and other Google services) APIs.Go to https://code.google.com/apis/console, and enable Google Plus API Access under the Services menu item.
Finally, take note of the API key that’s available by accessing the API Access menu item.
You should assume that the textual data exposed as Google+
activities contains markup, escaped HTML entities, etc., so a little bit
of additional filtering is needed to clean it up. Example 7-1 provides an example session
demonstrating how to fetch and distill plain text suitable for mining some
good text content out of a Google+ user’s public profile data. Although
this first example illustrates the use of CouchDB as an optional storage
medium, we’ll be making a transition away from CouchDB in this chapter in
favor of storing a JSON archive of the data, so that we can hone in on
text-mining techniques, as opposed to discussing storage considerations.
If you’re interested in a more aggressive use of CouchDB and useful
add-ons like couchdb-lucene, revisit
the earlier chapters of this book.
Example 7-1. Harvesting Google+ data (plus__get_activities.py)
# -*- coding: utf-8 -*-
import os
import sys
import httplib2
import json
import apiclient.discovery
from BeautifulSoup import BeautifulStoneSoup
from nltk import clean_html
USER_ID=sys.argv[1] # Tim O'Reilly's Google+ id is '107033731246200681024'
API_KEY=""
MAX_RESULTS = 200 # May actually get slightly more
# Helper function for removing html and converting escaped entities.
# Returns UTF-8
def cleanHtml(html):
if html == "": return ""
return BeautifulStoneSoup(clean_html(html),
convertEntities=BeautifulStoneSoup.HTML_ENTITIES).contents[0]
service = apiclient.discovery.build('plus', 'v1', http=httplib2.Http(),
developerKey=API_KEY)
activities_resource = service.activities()
request = activities_resource.list(
userId=USER_ID,
collection='public',
maxResults='100') # Max allowed per API
activities = []
while request != None and len(activities) < MAX_RESULTS:
activities_document = request.execute()
if 'items' in activities_document:
for activity in activities_document['items']:
if activity['object']['objectType'] == 'note' and
activity['object']['content'] != '':
activity['title'] = cleanHtml(activity['title'])
activity['object']['content'] = cleanHtml(activity['object']['content'])
activities.append(activity)
request = service.activities().list_next(request, activities_document)
# Store out to a local file as json data if you prefer
if not os.path.isdir('out'):
os.mkdir('out')
filename = os.path.join('out', USER_ID + '.plus')
f = open(filename, 'w')
f.write(json.dumps(activities, indent=2))
f.close()
print >> sys.stderr, str(len(activities)), "activities written to", f.name
# Or store it somewhere like CouchDB like so...
# server = couchdb.Server('http://localhost:5984')
# DB = 'plus-' + USER_ID
# db = server.create(DB)
# db.update(activities, all_or_nothing=True)
Now that you have the tools to fetch and store Google+ data, let’s start analyzing it.
[46] This book avoids splitting hairs over exactly what differences could be implied by common phrases such as “text mining,” “unstructured data analytics” (UDA), or “information retrieval,” and simply treats them as essentially the same thing.
[47] There’s also somewhat of a play on words here, since Google is so well known for its search capabilities and this chapter hones in on fundamental document-centric search techniques.