
NLTK is written such that you can explore data very easily and begin
to form some impressions without a lot of upfront investment. Before
skipping ahead, though, consider
following along with the interpreter session in Example 7-2
to get a feel for some of the powerful functionality that NLTK provides
right out of the box. Don’t forget that you can use the built-in
help function to get more information whenever you need it.
For example, help(nltk) would provide documentation on the
NLTK package. Also keep in mind that not all of the functionality from the
interpreter session is intended for incorporation into production
software, since output is written through standard output and not
capturable into a data structure such as a list. In that regard, methods
such as nltk.text.concordance are considered “demo
functionality.” Speaking of which, many of NLTK’s modules have a demo function that you can call to get some idea
of how to use the functionality they provide, and the source code for
these demos is a great starting point for learning how to use new APIs.
For example, you could run nltk.text.demo() in the interpreter to get some
additional insight into capabilities provided by the
nltk.text module. We’ll take a closer look at how some of
this demonstration functionality works over the coming pages.
Note
The examples throughout this chapter, including the following
interpreter session, use the split method to tokenize
text. Chapter 8 introduces more sophisticated
approaches for tokenization that may work better.
Example 7-2. Hacking on Google Plus data in the interpreter with NLTK. Example 7-1 produces a data archive in the out directory from where you ran the script.
>>>import nltk>>>import json>>>data = json.loads(open("out/107033731246200681024.plus").read())>>>all_content = " ".join([ a['object']['content'] for a in data ])>>>len(all_content)203026 >>>tokens = all_content.split()>>>text = nltk.Text(tokens)>>>text.concordance("open")Building index... Displaying 12 of 12 matches: . Part of what matters so much when open source, the web, and open data meet much when open source, the web, and open data meet government is that practic government to provide a platform to open and share freely downloadable GIS da s bill to prevent NIH from mandating open access to federally funded research. agencies such as the NIH to mandate open access to research that is funded by lly like + John Tolva 's piece about open government in Chicago. It ties toget orce. Analysis builds new processes. open data builds businesses." I haven't s e in. We wanted reading to remain as open as it did when printed books ruled t a stand for reading portability and open access. Offer books in multiple open open access. Offer books in multiple open formats, DRM-free, and from multiple hat story redefined free software as open source, and the world hasn't been th g behind them. Thinking deeply about open source and the internet got me think >>>text.collocations()Building collocations list AlhambraPatternsAndTextures AlhambraPatternsAndTextures; OccupyWallStreet OccupyWallStreet; PopupCrecheShops PopupCrecheShops; Wall Street; Maker Faire; Mini Maker; New York; Bay Mini; East Bay; United States; Ada Lovelace; hedge fund; Faire East; Steve Jobs; 21st century; Silicon Valley; sales tax; Jennifer Pahlka; Mike Loukides; data science >>>fdist = text.vocab()Building vocabulary index... >>>fdist["open"]11 >>>fdist["source"]5 >>>fdist["web"]6 >>>fdist["2.0"]4 >>>len(tokens)33280 >>>len(fdist.keys()) # unique tokens8598 >>>[w for w in fdist.keys()[:100]...if w.lower() not in nltk.corpus.stopwords.words('english')][u'one', u'-', u'new', u'+', u'like', u'government', u'would', u'people', u'get', u'data', u'make', u'really', u'also', u'many', u"It's", u'business', u"I'm", u"it's", u'much', u'way', u'AlhambraPatternsAndTextures', u'book', u'see', u'work', u'great', u'market']>>>[w for w in fdist.keys() if len(w) > 15 and not w.startswith("http")][u'one', u'-', u'new', u'+', u'like', u'government', u'would', u'people', u'get', u'data', u'make', u'really', u'also', u'many', u"It's", u'business', u"I'm", u"it's", u'much', u'way', u'AlhambraPatternsAndTextures', u'book', u'see', u'work', u'great', u'market'] >>> [w for w in fdist.keys() if len(w) > 15 and not w.startswith("http")] [u'AlhambraPatternsAndTextures', u'OccupyWallStreet', u'PopupCrecheShops', u'#OccupyWallStreet', u'"CurrentCapacity"', u'"DesignCapacity"', u'"LegacyBatteryInfo"', u'"unconferences,"', u'@OReillyMedia#Ebook', u'@josephjesposito', u'@netgarden(come-on,', u'@oreillymedia"deal', u'Administrationu2014which', u'Amazon-California', u'Community-generated', u'Frisch(12:00-1:00)',u'Internet-related', u'Representatives.[10]', u'Republican-controlled', u'Twitter,@_vrajesh', u"administration's", u'all-encompassing', u'augmented-reality', u'books-to-diapers-to-machetes', u'brain-wave-sensing', u'brick-and-mortar', u'codeforamerica.org', u'continuously-updated', u'crimespotting.org', u'disobedienceu2014including', u'dolphin-slaughter', u'community-driven', u'connect-the-dots', u'entertainment-sector', u'government-funded', u'informationdiet.com', u'instantaneously.', u'little-mentioned', u'micro-entrepreneurship.', u'nineteenth-century', u'opsociety.org/securedonation.htm', u'problem/solution/explanation', u'problematically,', u'reconceptualization', u'responsibility."',u'scientifically-literate', u'self-employment,', u'subscription-based', u'technology-based', u'transportation.)', u'two-dimensional,', u'unintentionally?', u'watercolor-style', u'{"Amperage"=18446744073709548064,"Flags"=4,"Capacity"=4464,"Current"=2850,"Voltage"=7362, "Cycle', u'u201cverbivocovisualu201d'] >>>len([w for w in fdist.keys() if w.startswith("http")])98 >>>for rank, word in enumerate(fdist): print rank, word, fdist[word]0 the 1815 1 of 1017 2 to 988 3 and 701 4 a 699 5 in 546 6 that 535 7 is 413 ... output truncated ...
Warning
You may need to run nltk.download('stopwords') to
download NLTK’s stopwords data if you haven’t already installed it. If
possible, it is recommended that you just run
nltk.download() to install all of the NLTK data.
The last command in the interpreter session lists the words from the frequency distribution, sorted by frequency. Not surprisingly, common words like “the,” “to,” and “of”—stopwords—are the most frequently occurring, but there’s a steep decline and the distribution has a very long tail. We’re working with a small sample of text data, but this same property will hold true for any frequency analysis of natural language. Zipf’s law, a well-known empirical law of natural language, asserts that a word’s frequency within a corpus is inversely proportional to its rank in the frequency table. What this means is that if the most frequently occurring term in a corpus accounts for N% of the total words, the second most frequently occurring term in the corpus should account for (N/2)% of the words, the third most frequent term for (N/3)% of the words, etc. When graphed, such a distribution (even for a small sample of data) shows a curve that hugs each axis, as you can see in Figure 7-2. An important observation is that most of the area in such a distribution lies in its tail, which for a corpus large enough to span a reasonable sample of a language is always quite long. If you were to plot this kind of distribution on a chart where each axis was scaled by a logarithm, the curve would approach a straight line for a representative sample size.
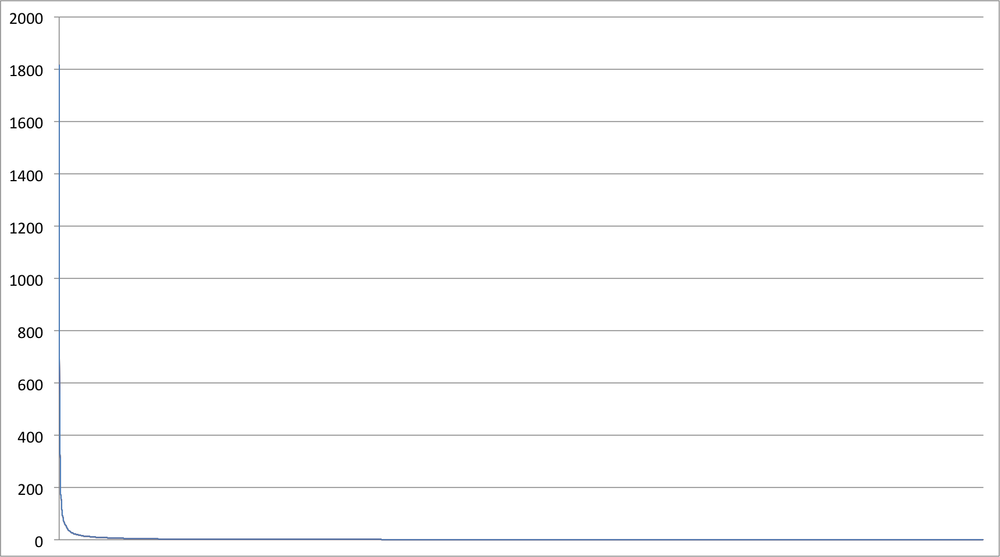
Zipf’s law gives you insight into what a frequency distribution for words appearing in a corpus should look like, and it provides some rules of thumb that can be useful in estimating frequency. For example, if you know that there are a million (non-unique) words in a corpus, and you assume that the most frequently used word (usually “the,” in English) accounts for 7% of the words,[48] you could derive the total number of logical calculations an algorithm performs if you were to consider a particular slice of the terms from the frequency distribution. Sometimes, this kind of simple arithmetic on the back of a napkin is all that it takes to sanity-check assumptions about a long-running wall-clock time, or confirm whether certain computations on a large enough data set are even tractable.
[48] The word “the” accounts for 7% of the tokens in the Brown Corpus and provides a reasonable starting point for a corpus if you don’t know anything else about it.