
One of the most fascinating aspects of data mining is that it affords you the ability to discover new knowledge from existing information. There really is something to be said for the old adage that “knowledge is power,” and it’s especially true in an age where the amount of information available is steadily growing with no indication of decline. As an interesting exercise, let’s see what we can discover about some of the latent social networks that exist in the sea of Twitter data. The basic approach we’ll take is to collect some focused data on two or more topics in a specific way by searching on a particular hashtag, and then apply some of the same metrics we coded up in the previous section (where we analyzed Tim’s tweets) to get a feel for the similarity between the networks.
Since there’s no such thing as a “stupid question,” let’s move forward in the spirit of famed economist Steven D. Levitt[33] and ask the question, “What do #TeaParty and #JustinBieber have in common?”[34]
Example 5-14 provides a simple mechanism for collecting approximately the most recent 1,500 tweets (the maximum currently returned by the search API) on a particular topic and storing them away in CouchDB. Like other listings you’ve seen earlier in this chapter, it includes simple map/reduce logic to incrementally update the tweets in the event that you’d like to run it over a longer period of time to collect a larger batch of data than the search API can give you in a short duration. You might want to investigate the streaming API for this type of task.
Example 5-14. Harvesting tweets for a given query (the_tweet__search.py)
# -*- coding: utf-8 -*-
import sys
import twitter
import couchdb
from couchdb.design import ViewDefinition
from twitter__util import makeTwitterRequest
SEARCH_TERM = sys.argv[1]
MAX_PAGES = 15
KW = {
'domain': 'search.twitter.com',
'count': 200,
'rpp': 100,
'q': SEARCH_TERM,
}
server = couchdb.Server('http://localhost:5984')
DB = 'search-%s' % (SEARCH_TERM.lower().replace('#', '').replace('@', ''), )
try:
db = server.create(DB)
except couchdb.http.PreconditionFailed, e:
# already exists, so append to it, and be mindful of duplicates
db = server[DB]
t = twitter.Twitter(domain='search.twitter.com')
for page in range(1, 16):
KW['page'] = page
tweets = makeTwitterRequest(t, t.search, **KW)
db.update(tweets['results'], all_or_nothing=True)
if len(tweets['results']) == 0:
break
print 'Fetched %i tweets' % len(tweets['results'])The following sections are based on approximately 3,000 tweets per topic and assume that you’ve run the script to collect data on #TeaParty and #JustinBieber (or any other topics that interest you).
Warning
Depending on your terminal preferences, you may need to escape
certain characters (such as the hash symbol) because of the way they
might be interpreted by your shell. For example, in Bash, you’d need
to escape a hashtag query for #TeaParty as #TeaParty to ensure that the shell
interprets the hash symbol as part of the query term, instead of as
the beginning of a comment.
One of the simplest yet probably most effective ways to characterize two different crowds is to examine the entities that appear in an aggregate pool of tweets. In addition to giving you a good idea of the other topics that each crowd is talking about, you can compare the entities that do co-occur to arrive at a very rudimentary similarity metric. Example 5-4 already provides the logic we need to perform a first pass at entity analysis. Assuming you’ve run search queries for #JustinBieber and #TeaParty, you should have two CouchDB databases called “search-justinbieber” and “search-teaparty” that you can pass in to produce your own results. Sample results for each hashtag with an entity frequency greater than 20 follow in Tables 5-3 and 5-4; Figure 5-4 displays a chart conveying the underlying frequency distributions for these tables. Because the y-axis contains such extremes, it is adjusted to be a logarithmic scale, which makes the y values easier to read.
Table 5-3. Most frequent entities appearing in tweets containing #TeaParty
| Entity | Frequency |
|---|---|
| #teaparty | 2834 |
| #tcot | 2426 |
| #p2 | 911 |
| #tlot | 781 |
| #gop | 739 |
| #ocra | 649 |
| #sgp | 567 |
| #twisters | 269 |
| #dnc | 175 |
| #tpp | 170 |
| #GOP | 150 |
| #iamthemob | 123 |
| #ucot | 120 |
| #libertarian | 112 |
| #obama | 112 |
| #vote2010 | 109 |
| #TeaParty | 106 |
| #hhrs | 104 |
| #politics | 100 |
| #immigration | 97 |
| #cspj | 96 |
| #acon | 91 |
| #dems | 82 |
| #palin | 79 |
| #topprog | 78 |
| #Obama | 74 |
| #tweetcongress | 72 |
| #jcot | 71 |
| #Teaparty | 62 |
| #rs | 60 |
| #oilspill | 59 |
| #news | 58 |
| #glennbeck | 54 |
| #FF | 47 |
| #liberty | 47 |
| @welshman007 | 45 |
| #spwbt | 44 |
| #TCOT | 43 |
| http://tinyurl.com/24h36zq | 43 |
| #rnc | 42 |
| #military | 40 |
| #palin12 | 40 |
| @Drudge_Report | 39 |
| @ALIPAC | 35 |
| #majority | 35 |
| #NoAmnesty | 35 |
| #patriottweets | 35 |
| @ResistTyranny | 34 |
| #tsot | 34 |
| http://tinyurl.com/386k5hh | 31 |
| #conservative | 30 |
| #AZ | 29 |
| #TopProg | 29 |
| @JIDF | 28 |
| @STOPOBAMA2012 | 28 |
| @TheFlaCracker | 28 |
| #palin2012 | 28 |
| @thenewdeal | 27 |
| #AFIRE | 27 |
| #Dems | 27 |
| #asamom | 26 |
| #GOPDeficit | 25 |
| #wethepeople | 25 |
| @andilinks | 24 |
| @RonPaulNews | 24 |
| #ampats | 24 |
| #cnn | 24 |
| #jews | 24 |
| @First_Patriots | 23 |
| #patriot | 23 |
| #pjtv | 23 |
| @Liliaep | 22 |
| #nvsen | 22 |
| @BrnEyeSuss | 21 |
| @crispix49 | 21 |
| @koopersmith | 21 |
| @Kriskxx | 21 |
| #Kagan | 21 |
| @blogging_tories | 20 |
| #cdnpoli | 20 |
| #fail | 20 |
| #nra | 20 |
| #roft | 20 |
Table 5-4. Most frequent entities appearing in tweets containing #JustinBieber
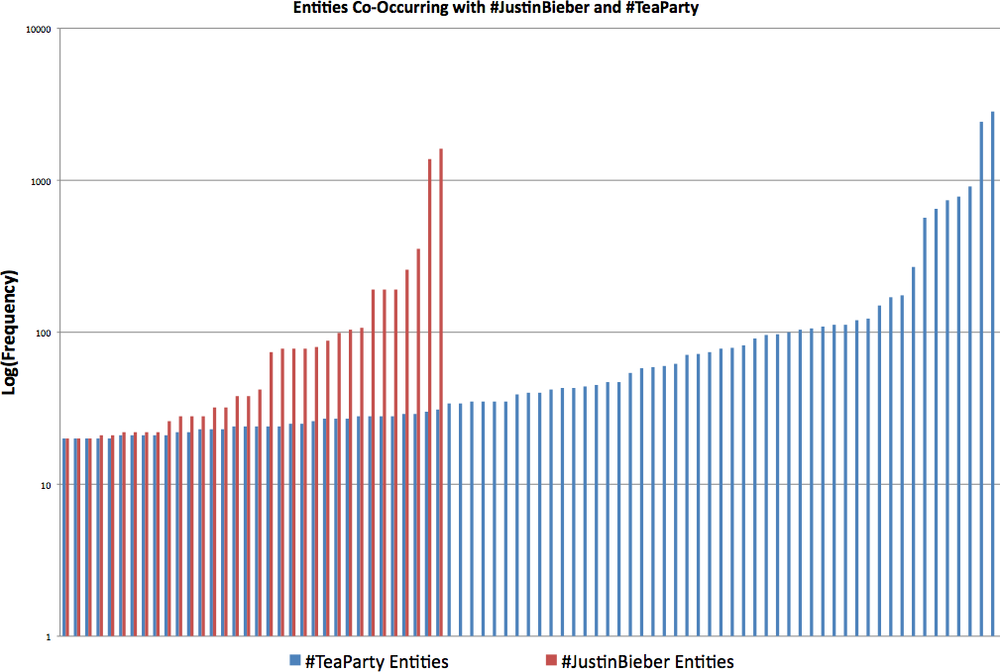
What’s immediately obvious is that the #TeaParty tweets seem to have a lot more area “under the curve” and a much longer tail[35] (if you can even call it a tail) than the #JustinBieber tweets. Thus, at a glance, it would seem that the average number of hashtags for #TeaParty tweets would be higher than for #JustinBieber tweets. The next section investigates this assumption, but before we move on, let’s make a few more observations about these results. A cursory qualitative assessment of the results seems to indicate that the information encoded into the entities themselves is richer for #TeaParty. For example, in #TeaParty entities, we see topics such as #oilspill, #Obama, #palin, #libertarian, and @Drudge_Report, among others. In contrast, many of the most frequently occurring #JustinBieber entities are simply variations of #JustinBieber, with the rest of the hashtags being somewhat scattered and unfocused. Keep in mind, however, that this isn’t all that unexpected, given that #TeaParty is a very political topic whereas #JustinBieber is associated with pop culture and entertainment.
Some other observations are that a couple of user entities (@lojadoaltivo and @ProSieben) appear in the top few results—higher than the “official” @justinbieber account itself—and that many of the entities that co-occur most often with #JustinBieber are non-English words or user entities, often associated with the entertainment industry.
Having briefly scratched the surface of a qualitative assessment, let’s now return to the question of whether there are definitively more hashtags per tweet for #TeaParty than #JustinBieber.
Example 5-13 provides a
working implementation for counting the average number of hashtags per
tweet and can be readily applied to the search-justinbieber and search-teaparty databases without any
additional work required.
Tallying the results for the two databases reveals that #JustinBieber tweets average around 1.95 hashtags per tweet, while #TeaParty tweets have around 5.15 hashtags per tweet. That’s approximately 2.5 times more hashtags for #TeaParty tweets than #JustinBieber tweets. Although this isn’t necessarily the most surprising find in the world, having firm data points on which to base further explorations or to back up conjectures is helpful: they are quantifiable results that can be tracked over time, or shared and reassessed by others.
Although the difference in this case is striking, keep in mind that the data collected is whatever Twitter handed us back as the most recent ~3,000 tweets for each topic via the search API. It isn’t necessarily statistically significant, even though it is probably a very good indicator and very well may be so. Whether they realize it or not, #TeaParty Twitterers are big believers in folksonomies: they clearly have a vested interest in ensuring that their content is easily accessible and cross-referenced via search APIs and data hackers such as ourselves.
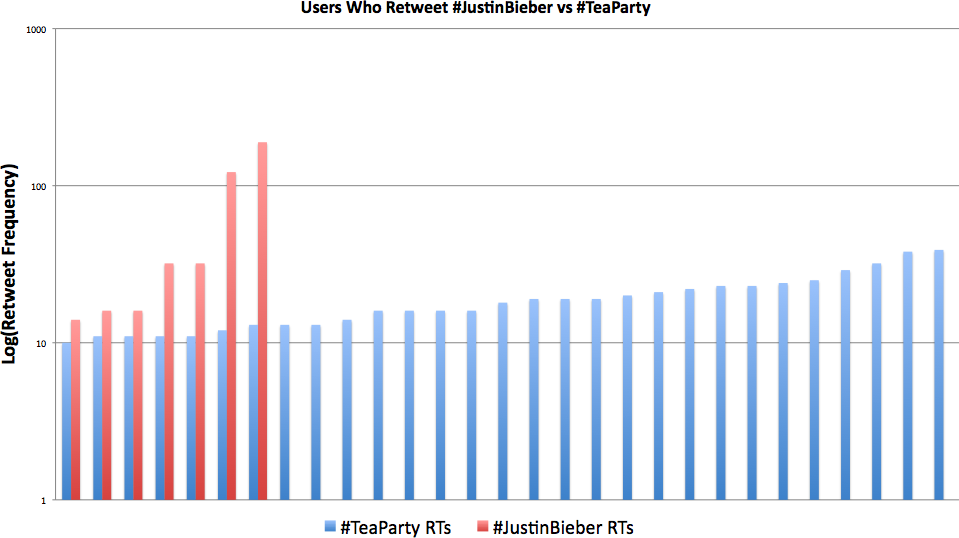
Earlier in this chapter, we made the reasonable conjecture that tweets that are retweeted with high frequency are likely to be more influential and more informative or editorial in nature than ones that are not. Tweets such as “Eating a pretzel” and “Aliens have just landed on the White House front lawn; we are all going to die! #fail #apocalypse” being extreme examples of content that is fairly unlikely and likely to be retweeted, respectively. How does #TeaParty compare to #JustinBieber for retweets? Analyzing @mentions from the working set of search results again produces interesting results. Truncated results showing which users have retweeted #TeaParty and #JustinBieber most often using a threshold with a frequency parameter of 10 appear in Tables 5-5 and 5-6.
Table 5-5. Most frequent retweeters of #TeaParty
| Entity | Frequency |
|---|---|
| @teapartyleader | 10 |
| @dhrxsol1234 | 11 |
| @HCReminder | 11 |
| @ObamaBallBuster | 11 |
| @spitfiremurphy | 11 |
| @GregWHoward | 12 |
| @BrnEyeSuss | 13 |
| @Calroofer | 13 |
| @grammy620 | 13 |
| @Herfarm | 14 |
| @andilinks | 16 |
| @c4Liberty | 16 |
| @FloridaPundit | 16 |
| @tlw3 | 16 |
| @Kriskxx | 18 |
| @crispix49 | 19 |
| @JIDF | 19 |
| @libertyideals | 19 |
| @blogging_tories | 20 |
| @Liliaep | 21 |
| @STOPOBAMA2012 | 22 |
| @First_Patriots | 23 |
| @RonPaulNews | 23 |
| @TheFlaCracker | 24 |
| @thenewdeal | 25 |
| @ResistTyranny | 29 |
| @ALIPAC | 32 |
| @Drudge_Report | 38 |
| @welshman007 | 39 |
If you do some back of the envelope analysis by running Example 5-4 on the ~3,000 tweets for each topic, you’ll discover that about 1,335 of the #TeaParty tweets are retweets, while only about 763 of the #JustinBieber tweets are retweets. That’s practically twice as many retweets for #TeaParty than #JustinBieber. You’ll also observe that #TeaParty has a much longer tail, checking in with over 400 total retweets against #JustinBieber’s 131 retweets. Regardless of statistical rigor, intuitively, those are probably pretty relevant indicators that size up the different interest groups in meaningful ways. It would seem that #TeaParty folks more consistently retweet content than #JustinBieber folks; however, of the #JustinBieber folks who do retweet content, there are clearly a few outliers who retweet much more frequently than others. Figure 5-5 displays a simple chart of the values from Tables 5-5 and 5-6. As with Figure 5-4, the y-axis is a log scale, which makes the chart a little more readable by squashing the frequency values to require less vertical space.
A final looming question that might be keeping you up at night is how much overlap exists between the entities parsed out of the #TeaParty and #JustinBieber tweets. Borrowing from some of the ideas in Chapter 4, we’re essentially asking for the logical intersection of the two sets of entities. Although we could certainly compute this by taking the time to adapt existing Python code, it might be even easier to just capture the results of the scripts we already have on hand into two files and pass those filenames as parameters into a disposable script that provides a general-purpose facility for computing the intersection of any line-delimited file. In addition to getting the job done, this approach also leaves you with artifacts that you can casually peruse and readily share with others. Assuming you are working in a *nix shell with the script count-entities-in-tweets.py, one approach for capturing the entities from the #TeaParty and #JustinBieber output of Example 5-4 and storing them in sorted order follows:
#!/bin/bashmkdir -p outfor db in teaparty justinbieber; dopython the_tweet__count_entities_in_tweets.py search-$db 0 |tail +3 | awk '{print $2}' | sort > out/$db.entitiesdone
After you’ve run this script, you can pass the two filenames into the general-purpose Python program to compute the output, as shown in Example 5-15.
Example 5-15. Computing the set intersection of lines in files (the_tweet__compute_intersection_of_lines_in_files.py)
# -*- coding: utf-8 -*-
"""
Read in 2 or more files and compute the logical intersection of the lines in them
"""
import sys
data = {}
for i in range(1, len(sys.argv)):
data[sys.argv[i]] = set(open(sys.argv[i]).readlines())
intersection = set()
keys = data.keys()
for k in range(len(keys) - 1):
intersection = data[keys[k]].intersection(data[keys[k - 1]])
msg = 'Common items shared amongst %s:' % ', '.join(keys).strip()
print msg
print '-' * len(msg)
for i in intersection:
print i.strip()The entities shared between #JustinBieber and #TeaParty are somewhat predictable, yet interesting. Example 5-16 lists the results from our sample.
Example 5-16. Sample results from Example 5-15
Common items shared amongst teaparty.entities, justinbieber.entities: --------------------------------------------------------------------- #lol #jesus #worldcup #teaparty #AZ #milk #ff #guns #WorldCup #bp #News #dancing #music #glennbeck http://www.linkati.com/q/index @addthis #nowplaying #news #WTF #fail #toomanypeople #oilspill #catholic
It shouldn’t be surprising that #WorldCup, #worldcup, and #oilspill are in the results, given that they’re pretty popular topics; however, having #teaparty, #glennbeck, #jesus, and #catholic show up on the list of shared hashtags might be somewhat of a surprise if you’re not that familiar with the TeaParty movement. Further analysis could very easily determine exactly how strong the correlations are between the two searches by accounting for how frequently certain hashtags appear in each search. One thing that’s immediately clear from these results is that none of these common entities appears in the top 20 most frequent entities associated with #JustinBieber, so that’s already an indicator that they’re out in the tail of the frequency distribution for #JustinBieber mentions. (And yes, having #WTF and #fail show up on the list at all, especially as a common thread between two diverse groups, is sort of funny. Experiencing frustration is, unfortunately, a common thread of humanity.) If you want to dig deeper, as a further exercise you might reuse Example 5-7 to enable full-text indexing on the tweets in order to search by keyword.
[33] Steven D. Levitt is the co-author of Freakonomics: A Rogue Economist Explores the Hidden Side of Everything (Harper), a book that systematically uses data to answer seemingly radical questions such as, “What do school teachers and sumo wrestlers have in common?”
[34] This question was partly inspired by the interesting Radar post, “Data science democratized”, which mentions a presentation that investigated the same question.
[35] A “long tail” or “heavy tail” refers to a feature of statistical distributions in which a significant portion (usually 50 percent or more) of the area under the curve exists within its tail. This concept is revisited as part of a brief overview of Zipf’s law in Data Hacking with NLTK.