
Chapter 9. Class Responsibilities
Woe to him who fails in his obligations.
—Irish proverb
Identifying the intrinsic responsibilities of a problem space entity and abstracting them into an object is the heart and soul of OO development in the sense that these activities are the most common things you will do in solving the customer problem. Furthermore, the way that we abstract responsibilities is probably the single most distinguishing feature of OO development compared to procedural or functional development. This is where the OO rubber meets the developmental road, so we’re going to spend some time here.
Attributes: What the Objects of a Class Should Know
Attributes define obligations for knowing something. In the static model we are interested in what an entity should know, not how it knows it. Thus it is important for the developer to maintain focus on the obligations rather than the values of what is actually known when constructing a Class diagram.
Definitions and Notation
The obligation to know a color is quite different than knowing the object is blue. This is because the obligation is an abstraction just like a class in that it captures the idea of a set, in this case a set of valid color values, more commonly referred to as a data domain.1 If you recall the definitions of abstraction in Chapter 8, the notion of color separates a property from the specific entity as an idea of the mind that stands on its own.
An attribute is an abstraction of fact associated with an individual entity. The abstraction is associated with a class, while the value is associated with a member object.
So we look at this problem space entity and note that it is a cube while that problem space entity is a dodecahedron. From several such examples (and a little help from geometry) we can abstract the notion of regular geometric shape and attach it to a class definition that defines a set of objects that have various values of this characteristic. We then define an obligation for each entity having such a characteristic to know its regular geometric shape. This notion has a simple domain of values that includes cube and dodecahedron, among others.
In Figure 9-1 we have a class Rendering with two knowledge obligations. Note that notationally we name our attributes and prefix the name with an ADT identifier. The first attribute expresses an obligation to know what regular geometric shape it is. The second expresses an obligation to know what color its surface is.
Figure 9-1. Notation example for associating ATDs with knowledge attributes

Note that there is no UML “+” or “-” qualification for public versus private. That’s because we are defining intrinsic properties of the entity. The notions of public versus private access, so popular in the OOPLs, exist to address developer problems for 3GL maintainability when accessing knowledge. Since how a property is accessed at the 3GL level is not relevant to the customer’s problem, we don’t worry about it in the OOA model.2 From another perspective, recall that we are talking about a static model here that is focused on abstracting entities. That view is intentionally quite myopic with regard to context, such as who has need of the obligation.
Not the Same as Data Storing
The cube and dodecahedron in the prior example are, themselves, abstractions of a set of properties (edge lengths and angles) that are highly constrained. This underscores the previous emphasis on logical indivisibility being a relatively major idea in OO development. In the context of regular geometric shape, they are scalar values that are not further divisible and, in this case, we capture them symbolically in the abstract values of cube and dodecahedron. This makes attributes different than data stores for a couple of reasons.
An attribute describes the nature of the knowledge, not its storage.
In 3GLs and databases values must be expressible in terms of a very limited number of storage types. This greatly restricts the notion of what a value can be. There is no such restriction for a class attribute. A class attribute can actually be implemented as an arbitrarily complex data structure as long as at the level of abstraction of the subject matter we can think of it as a scalar. Here we abstract the collection of properties that characterize regular geometric type into simple conceptual values of cube and dodecahedron.
This notion of abstraction-to-scalar is worth a couple more examples. Consider a telephone number. In most countries a telephone number is not a simple data domain. For example, in the United States a telephone number can be subdivided into {area code, exchange, number}. If it were to be stored in a relational database (RDB), it would have to be stored as separate attributes to be consistent with First Normal Form. However, we very rarely see an RDB where that is done because it would be highly inefficient.3 So most database administrators deliberately denormalize their RDB by storing it as a scalar number or string. In those rare instances when a client actually needs to extract an individual semantic element of the number, that becomes a client exercise.4 In effect, the administrator has abstracted the semantics up to a level where the telephone number as a whole is a simple domain.
State
An OO application has two views of the notion of state. One is a dynamic view that represents the state of the processing. Essentially, this view identifies where we are within the sequence of operations comprising the solution at a given moment during the execution. We will deal with this sort of state in the next part of the book. The other view of state is static and is expressed in terms of values that persist across multiple operations.
The static view of state is manifested in state variables. Thus from an OO perspective, attributes are state variables. State variables are modified when something happens to change the state of the application. Typically that will be the execution of some behavior within the subject matter, but it can be something external that is simply announced as a message to the subsystem interface. There are assumptions and constraints that pertain to such state variables.
• State variables can be accessed instantaneously at any time as long as the owning object exists.
• Access to state variables is synchronous.
• State variables are only visible within the containing subsystem.
• Access to state variables is only available when navigating valid relationship paths. (We will talk about this in detail in Chapter 10. For now all you need to know is that this is the primary way the OO paradigm constrains state variable access to avoid the traditional problems of global data.)
The first assumption needs some justification. Consider that a method takes finite time to execute, and it has to access two different attributes: x from object A and y from object B. If there is concurrent or asynchronous processing B.y might be modified after A.x is accessed but before B.y is accessed. That implies something changed between the accesses and, therefore, the values accessed may not be consistent with one another at the calling method’s scope.
The short answer is that we don’t worry about it in the OOA model because it is the transformation engine’s job (or elaboration OOD/P’s job) to ensure that the assumption is valid. The transformation engine is responsible for ensuring data and referential integrity as if access was instantaneous. That is, the application must be constructed by the transformation engine with whatever blocking of A.x and B.y from updates is necessary to ensure data integrity within the scope of the method accessing them. So that becomes the transformation engine application developer’s problem, which is a different trade union.5
Abstract Data Type
In the previous example a shape attribute within the Rendering class was defined to be an ADT, Regular Geometric Type. This is yet another term that tends to be overloaded in the computing space. Here is the definition employed in OOA/D.
An abstract data type is a developer-defined localization of knowledge that encapsulates the implementation of that knowledge so that it can be manipulated as a scalar.
This is a somewhat different spin than we usually see in the context of the type systems employed by 3GLs to implement OOA/D models. Those definitions generally substitute interface for localization, emphasize the access of the knowledge, and are more data oriented.
In the UML, the interface to a class’ properties is separate from the class definition, so the notion of “interface” has less importance to the definition of a class’ responsibilities. In addition, the idea of “localization” hints at cohesiveness, indivisibility, and abstraction for a particular problem space entity. Finally, the OOA/D view of type is more generic. That is, it is closer to the idea of set, category, or class than a formal interface with associated implications for client/service contracts.6 The crucial thing to remember is that the operative word in the phrase is abstract.
A final point regarding ADTs is that they describe data and the operations on that data. We tend to get the impression from the OO literature that the only operations on knowledge are getters and setters (i.e., accessors commonly used in OOPLs to extract or set the value of the knowledge). In fact, there is nothing to prevent an ADT from having a whole host of operations. Thus an attribute whose ADT was Matrix might have operations like transpose and invert that modify multiple individual values within the matrix. Those operations are essentially “smart” setters for the value of the ADT. The key idea, with respect to abstraction and logical indivisibility, is that such operations can be invoked on the ADT as if it were a scalar value.
When operations beyond getters and setters are provided, though, we must be careful to ensure those operations do not trash the scalar view. That is, the operations cannot, by their nature, expose any further divisibility in the knowledge to clients. In the Matrix case an operation like transpose is fine because the multivalued nature of a matrix is not exposed to the client invoking transpose. However, an operation like set element does expose a finer granularity because an element value must be supplied rather than an ADT value.
Now let’s carry this schizophrenia a step further. Suppose at the subsystem level we are interested in individual matrix elements, so we do need a set element accessor as well as transpose. This is a no-no for an ADT, so what to do? One solution is elevate the ADT to a first-class object. That is, we provide a Matrix class that has those knowledge accessors. How would we describe the Matrix class’ knowledge? We would have a separate Element class that is related to the Matrix through a one-to-many relationship. The Element class would have a set element accessor. The transpose accessor of Matrix now becomes a behavior because it must navigate the relationship and invoke set element for each Element object. That is, it needs intelligence about Matrix’ context as it collaborates with and modifies some other object’s knowledge rather than just Matrix’ own knowledge. As we shall see later in the chapter, that is the province of behavior.
ADTs and Contracts
Note that because the shape attribute in the Rendering example is limited to values that are regular geometric shapes, we have defined a constraint on what a Rendering object actually is. We have precluded Rendering objects from being fractal or amorphous. Similarly, the naming convention for the second attribute implies the constraint that the Rendering is always a solid. These constraints can be expressed in terms of DbC contracts. However, the enforceability of those contracts is quite different.
The first constraint is explicit and will limit collaborations regardless of how the developer constructs them. That formality enables the compiler or interpreter to check whether the developer screwed up by providing an invalid attribute value. But the constraint on being solid is implicit and can only be enforced by the developer in constructing the solution because it does not map directly to a 3GL type. That is, if the developer screws up it will only be manifested in an incorrect solution.
Strong Typing
If one defines attribute X as type building and attribute Y as type helicopter, then in an abstract action language an expression like X + Y is illegal. That’s because the ADTs are clearly apples and oranges; it makes no sense to add a building and a helicopter no matter how we bend the notion of addition. The fact that the objects have different ADTs indicates that they are different sorts of things.
That same distinction would apply if we defined attribute X as type money and attribute Y as type count. Money and counts are semantically quite different things even though both their values may be represented by exactly the same storage type at the machine level. So even though arithmetic addition is legal at the machine level, the ADTs are arithmetically incompatible at the OOA level because of their different ADTs. Though the notion of addition is not limited to arithmetic operations in OO development,7 it is limited to compatible ADTs.
This is an enormously powerful tool for ensuring that applications are robust. It is, in fact, one of the more important ways that state is managed in OO development. Assignments that change state variables are restricted to compatible ADTs. Perhaps more important, the context of access is restricted to expressions with compatible types. It is this sort of type enforcement that prevents circuit board schematics from appearing in the midst of one’s Reubenesque painting.
Whoa! What about an expression like X * Y, where the X attribute is defined as the estimated weekly payroll (money) and the Y attribute is defined as the number (count) of weeks in an accounting period? Surely that computation would be a valid one, right? Very astute, Grasshopper. It would be a valid computation, and that sort of thing happens quite often. The short answer is that the developer has to explicitly authorize use of specific mixed ADT expressions, which we will get to when discussing abstract action languages.
Operations and Methods: What an Object Must Do
Abstracting attributes is relatively easy compared to abstracting behavior because we already have valid parallels in the classification taxonomies that already exist in the “real world.” Static taxonomies such as the zoological phyla are relatively common, and those sorts of taxonomies are based upon the same general principle of characterization through attribute values. The difficulty in abstracting methods is that they are inherently dynamic, and there are precious few examples of behavioral taxonomies in life outside software.
In the preceding chapters we talked at length about things like peer-to-peer collaboration, logical indivisibility, and intrinsic properties of entities. Those things make the construction of OO software fundamentally different than procedural or functional development. That difference is most profound when abstracting behavior responsibilities for objects. The real goal of the I’m Done mentality in replacing the procedural Do This mentality is to facilitate defining methods, not collaborations.
Get the methods right and the collaborations take care of themselves.
If we correctly abstract the object behaviors, then organizing the sequence of messages among those behaviors to provide the overall problem solution sequence is a relatively mechanical task.8 A necessary condition of getting the methods right is to avoid thinking about context, which is what I’m Done is all about. The OO developer needs to ignore the implied sequencing in things like use cases when identifying object behavior responsibilities. To identify and specify behavior responsibilities all we need to know from the use cases are what the needed behaviors (steps) are. We connect the dots for the solution flow of control much later in the process.
As an analogy, we should be able to extract the steps in the use cases individually onto individual sticky notes, randomly scramble them, and then assign them one-ata-time to objects. When doing so we would need to know nothing about the original ordering of steps. Of course, like all analogies, we can dissect it to irrelevance. For example, use cases are usually written at a coarser granularity than individual subject matters, much less classes, so a use case step may map into multiple object responsibilities. But the key idea that we map use case steps to responsibilities independent of the sequence of steps is still valid.
The final point to make here is that all those OO notions—such as self-contained methods, intrinsic responsibilities, I’m Done, logical indivisibility, implementation hiding, separation of message and method, and whatever else was hawked since Chapter 2—all play together in defining behavior responsibilities. They all methodologically conspire to ensure that we get the behavior responsibilities right. In other words, we get the behavior responsibilities right because the plan came together.
Definitions and Notation
It’s time to provide some formal definitions, starting by repeating some from the previous chapter.
An operation is an object’s obligation to do something.
A method encapsulates the implementation of an operation as a procedure.
In other words, operation is the UML’s term for the notions of responsibility or obligation. There are two views of behavior in MBD.
Behavior responsibilities require that the object execute a suite of rules and policies that are unique to the problem in hand. These responsibilities are always associated with object state machines in MBD.
Synchronous services are behaviors that access only attributes or capture algorithmic processing defined outside the subject matter problem space.
True behavior responsibilities are described with finite state machines in MBD, a topic discussed in Chapter 15. Because designing state machines is an extensive topic that justifies in-depth discussion in Chapter 17, we will not say a lot about them here.
The reason that MBD distinguishes between these two categories of behavior is because in OO development the categories are treated differently. The term synchronous service is rooted in the fact that accessing knowledge is assumed to be a synchronous activity, while accessing solution rules and policies is assumed to be asynchronous. Basically, the notion of synchronous service reflects the idea that pure knowledge access can be far more complex than simple getters and setters of values when we are dealing with ADTs. The transform and invert operations for the earlier Matrix example are synchronous services.
The notion of synchronous services is also useful for encapsulating algorithmic code that does not affect the solution flow of control. That is, the execution of the synchronous service modifies the application state but does not make decisions about the sequencing of operations unique to the problem solution. Such encapsulation makes life easier for transformation engines (and elaboration OOD/P developers) because it limits the nature of and scope for enforcing data and referential integrity. More important, though, the separation of concerns between knowledge operations and solution sequencing tends to provide a much more robust solution in the face of future maintenance.
Note that if an algorithm is defined outside the problem context, it must be expressed in a way that is not dependent on problem specifics, in particular the local problem solution’s flow of control. The only way to do that is by having the algorithm be self-contained and by not enabling it to modify anything but data. Therefore, we can think of encapsulating such an algorithm, regardless of its complexity, as a single synchronous service to modify some pile of application knowledge. That is, it is just a “smart” setter.9
The third box in the Class is where we define operations. For the Matrix class in Figure 9-2(a) we have a standard suite of mathematical operations on a matrix. These operations are defined outside the context of any particular subject matter that might have use for a Matrix. The matrix itself is represented as a scalar knowledge value, data, of type 2DArray. The operations all execute against the entire matrix, so there is no exposure of individual elements. The implementations of those operations will necessarily have to be able to “walk” the actual array elements using well-defined mathematical algorithms. (Mathematical algorithms are defined outside the scope of any particular application problem space.)
Figure 9-2. Notation for behavior responsibilities
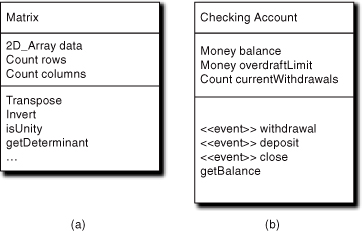
The Matrix class is a classic example of a class that is a dumb data holder where all of the behaviors are synchronous services. Though the operations are algorithmically complicated, there is nothing that the Matrix does that can directly affect the problem solution other than through the state value of data (i.e., any control flow decision will be based upon some test, such as isUnity, of the data). Nor do any of the operations represent sequences or decisions that are unique to the problem solution context where a Matrix is accessed.
For the Checking Account class we have operations for withdrawing money, depositing money, closing the account, and checking the current balance. In this case, we can easily envision situations where the first three operations involve specific rules and policies, such as computing overdraft limits, that are unique to the subject matter (a particular bank’s accounting system).
In addition, as a practical matter we know that things like deposits and withdrawals require collaborations with other objects (e.g., posting to a General Ledger, audit trails, etc.). Those collaborations imply decisions and predefined sequences that can be captured in terms of a succession of unique states of the execution itself. So it is quite likely that most of the operations of Checking Account represent true behavior responsibilities that we will associate with state machine states whose transitions reflect the valid decisions and predefined sequences. Therefore, invoking the first three operations will be done asynchronously using a state machine event, hence the stereotype <<event>> appended to each one. On the other hand, checking the balance is a pure synchronous knowledge access.
That’s all there is to the required notation. The tricky part lies in the semantics we associate with those responsibilities. Also note that there is no identification of methods. We are only concerned with the operations in the Class diagram, not the implementations of those responsibilities. So the definition of methods is left to Part III, the Dynamic model, where state machines and abstract action language are described.10
Because MBD assumes an asynchronous environment for all problem-specific behavior responsibilities, the absence of the event qualifier indicates that the operation is a synchronous knowledge access or synchronous service.
Identifying Behaviors
The actual behavior responsibilities will usually be described when a state machine is constructed for the object and that topic is deferred to the next book section. Nonetheless, we need to identify them for the Class diagram. In so doing, we don’t have to worry about state machines. The behavior responsibility still exists whether we associate it with a state machine state or not. The criteria identified in the following sections will work to ensure the responsibility is suitable for use in state machines. And those same criteria also apply to synchronous services.
Cohesion
We have already talked about how an object represents one level of logical indivisibility in a subject matter and tying the object abstraction to a problem space entity. Those things provide a context for cohesion when defining responsibilities. The cohesion of knowledge responsibilities is pretty straightforward because they usually describe the entity itself quite directly. Behavior cohesion can be a bit trickier because we often use anthropomorphization to imbue inanimate entities or concepts with behaviors that a human would do if there were no software, so we often have a choice about what object might “own” something like a use case step.
An object’s behaviors should complement each other in supporting the object’s semantics.
When looking for a place for a behavior responsibility to live, we need to think holistically about the overall role of the object in the solution. All of the object’s behavior responsibilities should play together well in supporting the object’s goal. When we find bundles of object behaviors that are logically related within the bundles but not across the bundles, that is often a symptom of poor cohesion at the object definition level. Therefore, we should revisit the object definition and see if some form of delegation is needed.
As it happens, it is much easier to detect lack of cohesion when behaviors are individually atomic. With atomic behaviors it is usually fairly easy to recognize when they are just parts of a larger responsibility. Conversely, it is usually easier to spot the odd man out, so we need some guidelines for ensuring that individual behaviors are cohesive:
• Self-containment. This is the most important criteria because it is a necessary condition for abstracting intrinsic properties of problem space entities. The operation specification should be complete and fully testable without the need for invoking any behaviors from other objects.
• Logical cohesion. This means that the operation obligation is narrowly defined. Just as good individual requirements should be a statement of a single thought, so should the definition of behavior responsibilities. If you find that your description of the responsibility during scrubbing has and or or phrases, it is likely the responsibility is not cohesive and should be broken into multiple responsibilities.
• Testable. We should be able to provide a suite of unit tests for the responsibility that will unambiguously validate its correctness.11
• Fine grained. This means that the object’s individual behavior responsibilities should not be generalized to minimize collaborations or message traffic. The more we can define solution flow of control in message flows, the more robust and maintainable the application will be. So, it is preferable to have a lot of simple collaborations that are easily recognized rather than a few complex ones that provide a rigid structure.
If you have any experience with formal requirements specification, you should notice an eerie sense of déjà vu in these criteria. If we apply the same sort of rigorous approach to defining individual object behaviors as we apply to defining individual requirements, then we have made substantial progress down the path of OO Enlightenment. The elder statesmen of OOA/D were well aware of the principles of good requirements specification, and they actively sought to provide a traceable mapping to the OOA/D.12
Design by Contract (DbC) and Abstraction of Behavior
DbC originated with Structured Development but has been highly modified by the OO paradigm. We will talk about it in detail in the next section because it provides a rigorous technique for designing flow of control within the application. As a quick summary, when an object has an obligation, there is a clear implication that in satisfying that obligation the object is providing a service to some client. This, in turn, implies that the obligation itself can be formally specified in a contract between the client and the service. Thus the client provides a specification for a service and the service has an obligation to correctly implement that specification. This was the traditional Structured view and reflected the Do This philosophy of functional decomposition.
However, these notions of client and service need clarification in the OO context, and this is the best context to provide it. The notion of client is much more generic in an OO context and does not refer to a specific collaborator that provides a specification of the behavior. That’s because the specific sender of a message shouldn’t even know the actual receiver exists. In the OO approach, we abstract the object’s responsibilities before worrying about who actually invokes those obligations. Nonetheless, the notion of a contract is very useful in thinking about object behaviors. The contract specifies what the given responsibilities are in a formal way for any client.
It might help to think of the client as one of many states that the solution passes through during its execution. Those states represent conditions that form a directed graph to determine what individual solution operation should be executed next. That determination implies that the solution itself must have specified what happens next. Thus the solution itself (or the solution designer) can be viewed as the client in the specification sense.
In OO development, DbC contracts are defined by the service, not the sender of the message.
This is easily seen in the way DbC contracts are supported in the OOPLs. Typically the OOPL provides syntax for specifying preconditions, postconditions, and invariants. Postconditions define the expected results of the behavior, and invariants define constraints on the execution. Both define a contract for what the operation must do, and they do so in a context-free manner (i.e., they can be defined with no knowledge of a particular client context). The interesting syntax is for preconditions, which define what the client must provide. Therefore, the only collaboration context relevant to an OOPL DbC contract places a constraint on the message sender rather than the other way around.
Synchronous Services
As indicated earlier, synchronous services are actually accessors of knowledge with complexity beyond getters or setters for simple attribute values. They are also used to eliminate duplication when different behavior responsibility implementations share low-level operations. In either capacity it is important to restrict what they do to make things easier for automatic code generation and to provide the robustness stemming from separation of concerns. To this end, it is useful to think of synchronous services in terms of a few very fundamental kinds of processing.
• Knowledge accessors. Essentially these are pure getters and setters for attributes. It is important that such services are restricted to only low-level operations that extract or modify the object’s knowledge. (Most AALs separate accessors further into read or write accessors.)
• Tests. These are a special form of knowledge accessors that perform some sort of test on the object’s knowledge. They always return a boolean value that is used for a flow-of-control decision. It is important that such services are restricted to testing. A test is a read-only operation in that it can extract the knowledge values to be tested but may not modify them, even by invoking a setter. Nor should a test compute a special value of knowledge; any knowledge to be tested should already exist in the form of an attribute or as an input argument to the test.
• Transforms. These are the most common sort of synchronous service. The basic idea is that the service transforms input data in the form of message data or object attributes into new values. However, transforms do not write those new values to attributes directly; that is left for separate knowledge accessors. Like a test synchronous service, a transform is a read-only operation. As a result, transforms always return values.
The line between a transform returning a value and a knowledge accessor that is a complicated getter may seem thin, but there is an important distinction. The knowledge accessor is returning an existing ADT value that is defined by the attribute itself. Its complexity lies in dealing with the implementation of that attribute. In contrast, the value a transform returns is something else than the attributes it accesses. That “something else” is different knowledge than that accessed to compute it.
Yet robustness demands that writing attributes be highly controlled, which is why we have write accessors. We preclude the transform from invoking the write accessor directly because we don’t want to hide the rules and policies for doing the attribute write.13 That is, we want those rules and policies to be exposed at the highest level of flow of control in the application rather than nesting them.
• Instantiators. These are synchronous services that instantiate or remove objects and relationships. Instantiation is a quite special operation that has important implications for referential integrity in the final implementation. To maintain our grip on sanity when developing an OOA model we need to make the assumption that objects and relationships can be instantiated safely in a synchronous fashion. Unfortunately, software implementations today are rarely this simplistic, therefore we have to provide manageable scope for such operations so that the transformation engine can enforce referential integrity efficiently. Because such management can present opportunities for things like deadlock, we need to get out of that scope as quickly as possible. That essentially means we don’t want our instantiator synchronous service to do any more than it must.
• Event generators. An event generator simply generates an event. These are about as close as MBD gets to a fundamental operation in synchronous services. While it is sometimes necessary to provide some trickiness for accessors and instantiators, that is never the case for event generators.
Most developers, especially those with R-T/E or DB experience, can buy into the need to keep instantiators simple so that data and referential integrity can be managed properly. It is a bit tougher to see why we are being so anal retentive about separating the concerns of access, testing, and transforming data. The justification is really the same for all five categories: robustness. When we do OO development, one of our primary goals is long-term maintainability. While it is futile to try to predict exactly what will change in the future, we can predict that systematically managing complexity by separating concerns in a divide-and-conquer fashion will make it easier to deal with whatever changes come down the pike. That’s what encapsulation is about. If you religiously enforce these distinctions when identifying synchronous services, you will find that your applications will tend to be much easier to modify later because change will tend to be more easily isolated.
Anthropomorphizing
This is a very useful technique for abstracting behaviors for objects. It is especially useful when attributing behavior to tangible, inanimate problem space entities. The conundrum for OO development is that such entities typically don’t actually do anything. The basic idea is to attribute human behaviors to the entity as if it were a person.14
There is a sound rationale for anthropomorphization. Software provides automation; the software exists to replace activities that people would normally do in a manual system. To replace the people, those activities need to be allocated to things rather than people. The traditional structured approach was to create a function that was a surrogate for a real person, usually called something like XxxManager. However, because the activities people perform are usually quite complex, that approach led to very large functions that needed to be broken up hierarchically by functional decomposition.
Since the OO paradigm strives to eliminate hierarchical dependencies, the OO solution was to eliminate the people surrogates completely and force the activities to be spread out over a bunch of objects that abstracted the structure of the problem domain. This very conveniently led to simple, cohesive collections of activities that could be encapsulated.
Anthropomorphizing is useful because it enables us to systematically distribute behaviors so that they can be more easily managed. It comes down to envisioning a herd of rather dense clerks with limited attention spans tasked with doing the operations needed to control various problem space entities. Because they are not very bright, we find it much easier to allocate very limited responsibilities to each of them. We then allocate each of those clerks’ tasks to an entity they control.
Clearly, we don’t think about all of that tedious allocation and indirection in the metaphor; we simply associate behavior responsibilities directly with the entity we are abstracting. Nonetheless, it can be a useful metaphor if we are having difficulty allocating behavior responsibilities and collaborations. Just imagine the dumbest conceivable clerk that could possibly control the entity, and then figure out what behaviors that clerk could handle. Then marry the entity and the clerk.
Choices in responsibility ownership are invariably rooted in anthropomorphization.
If you have any OO experience at all you have undoubtedly encountered situations where we could make a case for allocating a responsibility to either of two object abstractions. Such choices are always at least indirectly rooted in anthropomorphization. Furthermore, such choices almost always involve behavior responsibilities.
Allocating knowledge attributes is usually very easy to do once we have the right objects identified. That’s because knowledge is a static property ideally suited to characterizing inanimate qualities. Behaviors, though, are things people do, and they need to be allocated to our objects. That gives the developer a whole lot more wiggle room for making design decisions about who will own those responsibilities.
The point here is that having plausible choices about where to allocate behavior responsibilities in the design does not reflect some inherent ambiguity in OO development. It is a pure mapping problem between human behaviors being replaced and the problem space structure. Like everything else in problem space abstraction, that mapping needs to be tailored to the problem in hand, thus choices in that mapping actually represent design versatility.
Process
Identifying responsibilities is very much like identifying classes, only the scale of abstraction has been reduced. Therefore, we can do the same sort of team consensus as the Object Blitz, except we deal with one class at a time. However, this can be a bit of overkill. The team already reached a consensus about what the entity is, which provides a fairly solid base for extracting properties. On the other hand, we need a team consensus on what the responsibilities are before the dynamics can be described.
So we advocate a compromise where we do a modified Object Blitz for responsibilities but in a somewhat more informal manner.
- Perform the same stream-of-consciousness exercise as for the Class Blitz to obtain preliminary candidates for knowledge and behavior needed to solve the problem. (This assumes the team is already thoroughly familiar with the requirements.)
- Scrub the responsibilities one at a time as a team in a manner similar to the Object Blitz. As a sanity check, identify what each behavior responsibility needs to know, and make sure that knowledge is in the list.
- Create a very rough Sequence or Collaboration diagram as a team effort.15 This is a throwaway just to assist in providing a broad-brush context for collaboration. No attempt should be made to identify specific messages. Just use the arrows between objects as a placeholder for expected collaboration based on a general knowledge of the object’s subject matter.
- Walk the Collaboration diagram. This works best with subsystem use cases but can be done with just external stimulus events. The team traces a path through the Collaboration diagram. As it traces the path, the team decides which responsibilities from the list go with which objects. Record the responsibilities and collaborations on the back of the 3 × 5 card for the object from the Object Blitz.16
- Create formal descriptions of attributes and responsibilities. This is an offline activity where each team member independently develops simple text descriptions of the set of responsibilities allocated to them and revises the class description for consistency—all based on the team discussions of previous steps and the 3 × 5 cards.
- Review the model documentation. The mechanics of review are an exercise for individual shops; there is a heap of literature on the subject, so we won’t advocate any specific technique here. The basic idea is that the definitions are refined by whatever standard review process your shop has.
- Update the model descriptions. At this point we should be close to a final draft model of the classes in the subject matter. Throw away the Collaboration diagram.
During this process additional responsibilities to those in step 1 will be discovered. Attempt to resolve any disagreements about the nature of the responsibilities using OO criteria like self-containment, logical indivisibility, cohesion, and so forth. When in doubt, break up behavior responsibilities. As with the Class Blitz, we need some predefined mechanism to resolve irreconcilable differences. Ideally the customer is the ultimate arbiter because the responsibilities abstract the problem space.
Examples
Because we have not gotten to designing state machines yet, we are going to cheat a bit in these examples and pretend we don’t use state machines. This is actually not a bad strategy for an initial cut at a Class diagram. In effect, the identified operations become placeholders for the rules and policies that we associate with states when designing the individual object state machines.
We are also going to cheat with the examples and not explicitly emulate the blitz process discussed earlier. This is mainly to save space in a situation where the detailed steps are fairly clear and the end product provides pretty good inherent traceability. We’ll supply parenthetical comments to describe intermediate blitz reasoning in situations where things get tricky.
ATM
It is usually better to start with knowledge attributes for two reasons. They are usually easier to identify in the problem space, especially for tangible entities. More important, though, defining the knowledge provides a basis for defining behavior responsibilities. That’s because almost all behaviors modify the state of the application as it is recorded in attribute state variables. Therefore, if we know what state variables are being modified it becomes easier to determine who has the responsibility for modifying them.
Table 9-1 represents a cut at identifying the knowledge responsibilities of the classes identified in the last chapter for the ATM controller software.
Table 9-1. Initial Cut at Defining Knowledge Responsibilities for ATM Controller
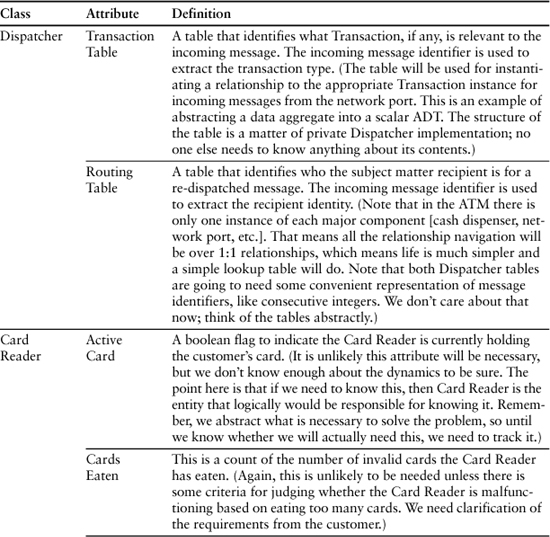

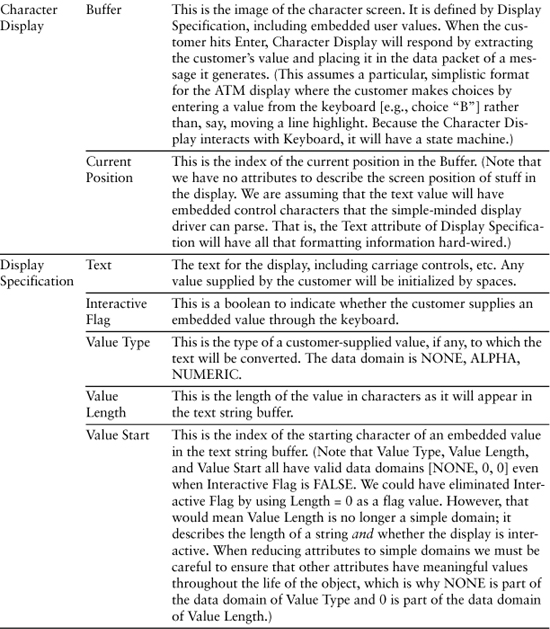
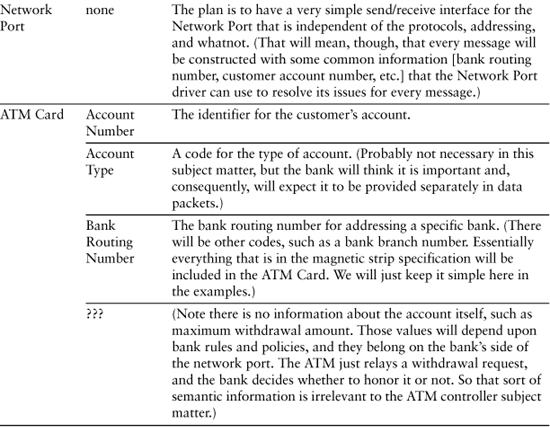

Now let’s look at what behavior responsibilities these objects might have. The exercise here is to identify what sorts of rules and policies the state machines will eventually have to support. As suggested in the Process section, it is often useful to create a very rough Sequence or Collaboration diagram to assist in identifying the responsibilities.
Figure 9-3 is a Collaboration diagram that captures the envisioned collaborations from when a new ATM card is entered into the Card Reader to when the main menu is presented. Essentially, the boxes represent objects and the connections are messages between them. All we are providing is a rough guess at how the use cases get done so we can allocate behavior responsibilities.
Figure 9-3. Collaborations involved in reading and validating a customer’s ATM card
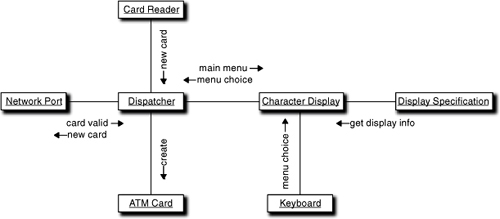
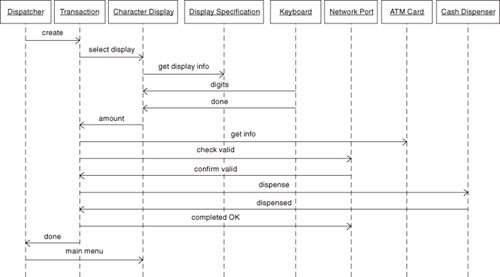
Figure 9-4 is a Sequence diagram that captures the collaborations for a withdrawal transaction.
Figure 9-4. Sequence of collaborations involved in making a withdrawal
Astute observer that you are, you will no doubt wonder where the Deposit, Withdrawal, and Transfer objects came from in Table 9-2. They are subclasses of Transaction that represent specializations. We’re not going to get to subclassing for awhile, so for now just understand that these new classes represent special cases of Transaction. They would have come into existence as soon as we started to do a rough Sequence or Collaboration diagram because not all Transactions have the same collaborations.
Table 9-2. Final Cut at ATM Controller Responsibilities
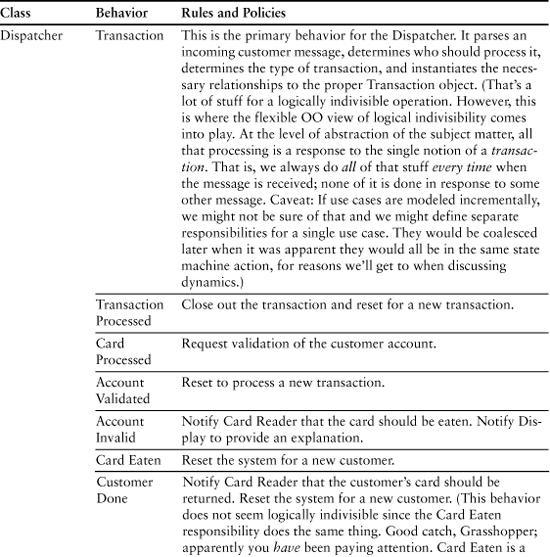
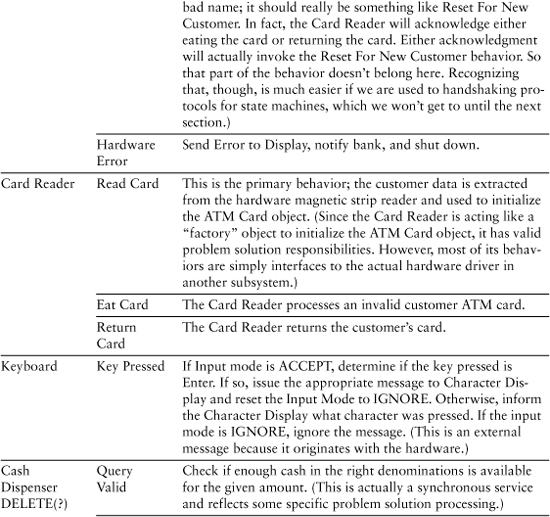
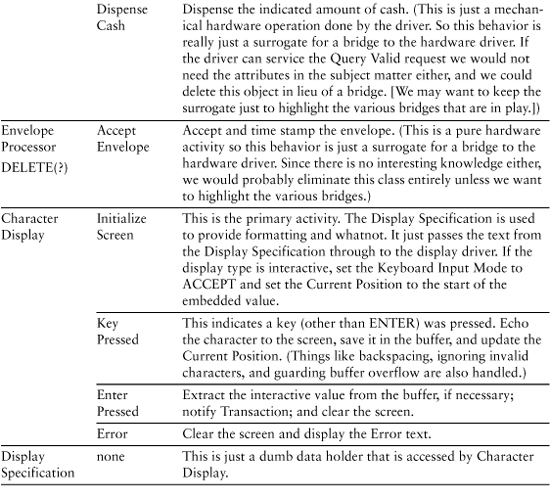
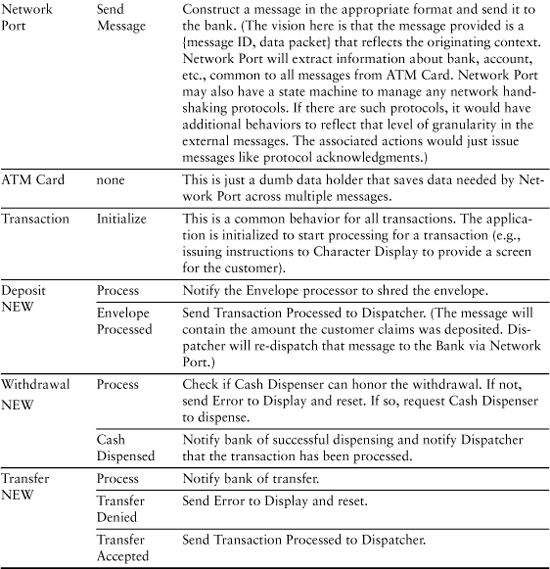
Table 9-2 presents the results of identifying the behavior responsibilities.
As you perused the behavior responsibilities for the first object, Dispatcher, your first thought was probably that some responsibilities were missing. For example, there were no responsibilities for telling the Cash Dispenser to dispense cash or telling the Envelope Processor to process a deposit. Those behaviors were delegated to other objects. Recall that Dispatcher should be cohesive, self-contained, and context-independent. The time to dispense cash or shred deposit envelopes is more logically determined in the Transaction object. That’s because there are multiple activities in a transaction, some of which are unique to the transaction. So the most logical place to coordinate that is in Transaction.
You probably noticed the activities are all pretty trivial. Many of them could probably be implemented with one to two lines of code. All the complicated stuff has been allocated to the hardware drivers, leaving the most heavy-duty behaviors to be Dispatcher’s Transaction behavior and Character Display’s Initialize Screen behavior. You are probably wondering why we need so many classes, which might seem like a lot of “overhead” to you. Why not combine some of them so we at least have a dozen or so executable statements per class?
One answer is that there is a lot more code than in the solution rules and policies. Those rules and policies are what we need to solve the customer’s problem; implementing that solution in software for a computer’s computational model is a whole other ball game. The descriptions only vaguely mention things like instantiating relationships and formatting messages. In practice there will be enough 3GL boilerplate code to fill up these classes quite nicely in an elaboration process.
The more important answer, though, is that there are a lot of rules and policies that are implicit in the static structure of this model. For example, state machines will enforce sequencing rules that are only implied in Table 9-2. Thus for a Withdrawal transaction: We initialize first; then get customer input; then locally validate (the Cash Dispenser has enough money); then globally validate (gets the bank’s authorization), then dispense cash, then notify the bank, and then clean up. Those activities are mostly generating messages to others but the sequence is critical.
Fixes Needed
You should have recognized several problems in the above responsibilities if you have ever used a bank ATM and you perused the example carefully. This is why modeling is a team effort and we have reviewers. If you didn’t peruse it carefully, go back and do so now because there are a couple of points to make about robustness that won’t sink in until you understand the nature of the problems. One useful technique is to “walk” use cases for deposit, withdrawal, and transfer through the Collaboration diagram. (The use cases can be mental; the reason this example was chosen is that it should be possible to picture oneself at an ATM doing those transactions.) These are the sorts of things you need to check.
• Is there a behavior to handle each use case step?
• Is there a behavior associated with each external message? Every external input message (from an Actor in use case terms) needs to have a designated responsibility to which the subsystem interface can dispatch the request.
• Is all the knowledge needed to perform the step available somewhere?
• Is behavior for the step self-contained and testable? A step is self-contained if all it does is modify attributes and send messages.
• Is the sequence of use case steps plausibly defined in the Collaboration diagram? We are doing static structure here so we aren’t terribly concerned that we have defined collaborations exactly right yet. However, we should be concerned with any glaring inconsistencies, such as accessing ATM card information prior to creating an ATM card instance or having multiple ATM card instances around as a transaction is executed.
• What could go wrong? The issue here is not software correctness in the sense of design-by-contract. Rather, it is about problem space applications of Murphy’s Law. We don’t worry about the details of how Character Display deals with corrections the customer makes for typos from the keyboard. But we do worry about what happens if the withdrawal amount requested is more than is available in the account, what to do if the network connection times out, and what happens if the Cash Dispenser jams.
After you have done your homework and revisited the attributes and operations, come back here and compare to the critiques provided by the book reviewers.
• Is there a behavior to handle each use case step? There is as long as we have only three use cases and nothing ever goes wrong. This is not surprising because that’s the way most software is built. We think about the obvious scenarios and how to implement them; we do the less obvious scenarios “later.” The rest of these questions are aimed at breaking that habit and forcing us to think about the less obvious scenarios from the outset.
• Is there a behavior associated with each external message? No, because the customer is not the only Actor here. Relative to this subsystem, all of the hardware drivers we identified are also Actors because they collaborate with this subject matter. To see the problem, consider how the customer selects Deposit, Withdrawal, and Transfer. On some ATMs there is a dedicated key on the keypad for basic transactions. On other ATMs the customer selects from a screen menu. Our Collaboration diagram has made an implicit assumption that there are dedicated keys for this selection. That’s fine if it is right, but the original requirements didn’t define that, and there were no bridge descriptions for the hardware drivers.
A clear error here lies in handling printing. We blithely ignored transactions like balance checks. However, whenever a deposit is made, the ATM always provides a hard copy receipt for it.17 Even if we decide we just need the bridge interface rather than a surrogate object for the printer driver, we still need a behavior that has the responsibility for encoding the balance and generating the message. And where does it get the balance it encodes?
If you are familiar with financial systems, especially in the banking industry, you will be aware that there is considerable paranoia about security.18 There is also a trend toward Just In Time servicing and whatnot. All of these things conspire so various people on the other side of the network port want a lot of information about the ATM itself. Hence there will generally be more data kept and reported. They may also want the ability for the bank to poll for things like cash on hand, status, errors, and so forth that have not been accounted for in the requirements. It is likely then that we are missing some sort of Status and/or History class that keeps track of additional information to support such queries.
• Is all the knowledge needed to perform the step available somewhere? Not quite, even for our three simple use cases. Note that for a balance transfer between accounts the customer needs to identify two accounts as well as an amount. The customer also has to define which is source and which is receiver, meaning that the display will have to support multiple values on one screen or present separate From/To screens to the customer. In the former case, Display Specification as we described it is inadequate, and for the latter case, we would need two Display Specification instances for that transaction. Either way we have some surgery to perform.
• Is the behavior of each step self-contained and testable? Yes. Though the behavior responsibilities are defined at a fairly high level of abstraction, it should be clear that they all either access knowledge synchronously (including synchronous services that are just glorified getters) or just send messages without depending upon the behaviors that respond to those messages. Therefore, we should be able to fully test any behavior without implementing anything else except knowledge attributes and their accessors.
• Is the sequence of the use case steps plausibly defined in the Collaboration diagram? Yes, except for printing and some error processing we’ll talk about shortly. That’s because we only have three quite trivial use cases in hand and there are lots of requirements, such as security and maintenance, that simply haven’t been addressed.
• What could go wrong? The short answer is everything. The error processing defined so far is woefully inadequate. The problem does not lie in things like correcting user typos; that can be handled in the details of Character Display processing for a typical ATM (e.g., backspacing to erase a character). The problems lie in things like hardware failures, power outages, and network time-outs.
In many applications these sorts of errors are unexpected so they are handled by a default exception facility provided by the transformation engine. However, in an ATM they must be handled explicitly in the problem solution. That’s because there is a synchronization problem between what the ATM hardware does and what is recorded in the bank’s database. In addition, the bank customer is interactively involved. For example, if the bank approves a withdrawal, it can’t simply post that withdrawal. Instead, it must lock the funds on the account (in case the account is accessed simultaneously) and wait for confirmation from the ATM that the cash was actually dispensed. Only then can it post the withdrawal to the general ledger in the database.
Unfortunately, lots of bad things can happen between the time the bank locks the funds and the ATM’s acknowledgment. Some are easily handled, such as cash dispenser jams where the ATM just needs to tell the bank “never mind.” But the acknowledgment can be delayed for a variety of reasons: A noisy line causes lots of packets to be re-sent, slowing things down; the network itself may crash; the ATM may have a power outage; the network as a whole may just simply be very slow today due to a denial-of-service attack on somebody; or the network may be locally slow because it is lunchtime and everyone is hitting their ATM.19 Each of these contingencies may or may not require unique handling policies and protocols on both sides of the network port.
This is a kind of straw man because we didn’t specify any requirements for handling such synchronization. However, in the real world, lots of requirements are implicit in the subject matter and business domain, so that really isn’t much of an excuse. Anyone who has dealt with distributed processing and has any notion of a bank’s paranoia over posting would realize there are some serious deficiencies in the specification of the responsibilities above, regardless of what the SRS said.
Your list of deficiencies may include things that haven’t been mentioned. Don’t lose sleep over it. We are not trying to design an ATM Controller here; we are only trying to indicate how we should try to think about that design. Space precludes a full design and a full answer to the previous questions.
Pet Care Center: Disposition
Table 9-3 and, later in the chapter, Table 9-4 represent the same drill as for the ATM example. The difference is that since you probably haven’t actually used a pet care center (unless you live in Southern California), you have no use cases to compare, so we won’t emphasize the things-to-fix gimmick. Table 9-3 lists the attributes. (The operations are listed in Table 9-4.)
Table 9-3. Pet Care Center Knowledge Attributes
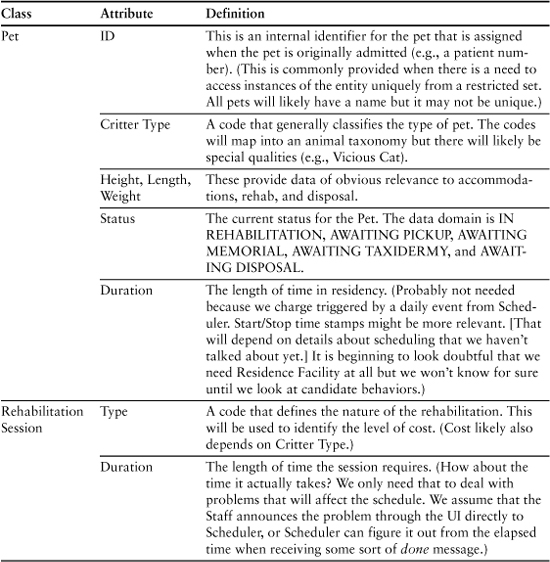
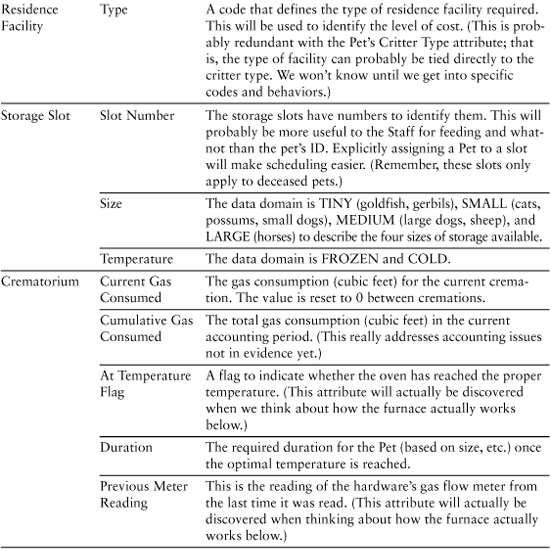
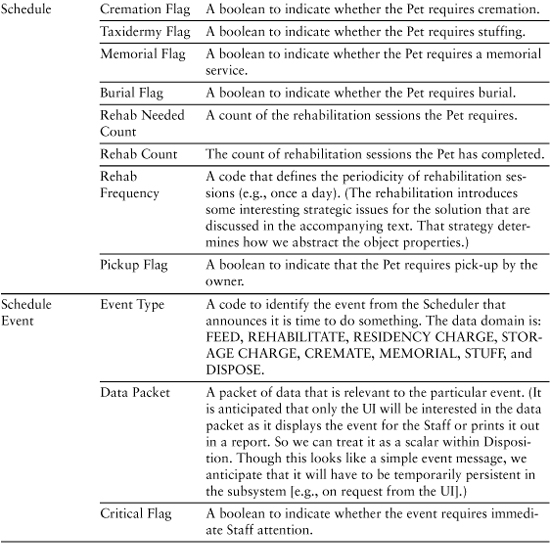
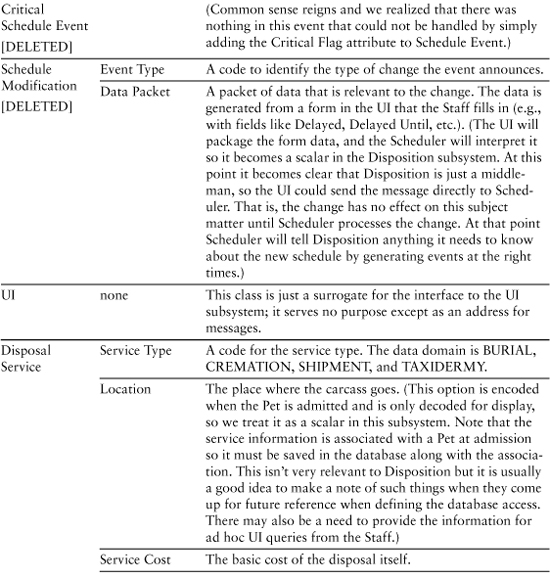

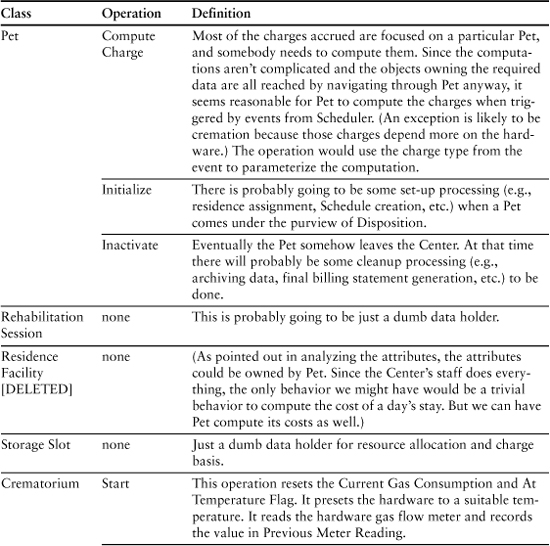
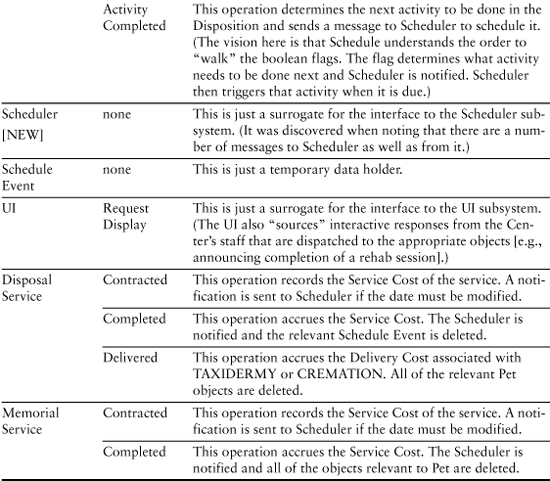
Table 9-4. Behavior Responsibilities for Pet Care Center

You may be curious about the attributes for Schedule. Recall that in the last chapter we made subtle changes to the semantics of Schedule so that it described the activities that take place while the pet is under the purview of the Disposition subsystem. The basic vision is that this Schedule object understands the sequence of activities and it understands what to do (i.e., what messages to generate) when a Scheduler event occurs.
The implication is that if this Schedule object understands the detailed sequence of activities, the Scheduler does not need to understand them as well; otherwise, we are bleeding cohesion. In other words, we have made a design decision about who “owns” the activity sequence for a particular kind of disposition. This, in turn, implies that only large-scale disposition activities are scheduled through the Scheduler subsystem. For that, the Scheduler just needs to know the elapsed time before triggering an event and the type of event to trigger.
We made that decision based on the fact that the activities are unique to the Disposition subsystem, they are fixed for a particular kind of disposition, and they are executed end to end. The important point here, though, is that decision was, itself, triggered by the need to define the attributes of Schedule. We have a lot of leeway in abstracting the problem space, so to define those attributes we needed a strategic vision of the overall problem solution. So even though we hadn’t thought very much about how the Disposition and Scheduler subsystems collaborate up to now, we needed to do so to abstract the Schedule object.
This is an example of a detailed subsystem design decision that could affect the communication bridges between the two subsystems. The schedule disposition activities semantics is quite different from trigger an event after N hours semantics; therefore, this is not something that can be handled in the bridge as a syntactic mismatch. So aren’t we trashing our application partitioning efforts?
Not really, Grasshopper. The real problem here is that we had not allocated ownership and management of the disposition activity sequence when we defined the subject matters. Put another way, we left the borders of our Scheduler subject matter blurry. Nobody is perfect, including systems engineers.
So if we had been perfect and we had drilled down just a tad more about the level of abstraction of Scheduler, we wouldn’t have a problem. All detailed schedules would be “owned” by the relevant client subsystems, and Scheduler would manage the sequencing among the various detailed schedules as if they were logically indivisible.
There are two points here. The first is that we should have been more careful in our application partitioning. Recall that we said it was the most important thing we do in developing large applications. If we had gotten the level of abstraction of Scheduler right, we wouldn’t need to rework the bridge definitions and, possibly, Scheduler itself. As it happens we deliberately “overlooked” this when defining Scheduler just so we could emphasize what happens when we don’t get things quite right.
If subsystems are developed in parallel, always work from the top of the Component diagram downward.
The second point is that such a mistake is probably not fatal. Our encapsulation and separation of concerns is still pretty good, so the Scheduler bridge definition may need some work and Scheduler’s implementation may need some work. But because Scheduler is still doing the same basic things, those changes should not be much worse than other requirements changes. More important, we are catching the problem fairly early in the design of the Disposition subsystem. If we design the Disposition subsystem before or at the same time as Scheduler, we will identity the problem before work on Scheduler goes very far. Since requirements flow from the top of the Component diagram to the bottom, it figures that we should do parallel subsystem development the same way; that is, we should develop the sibling subsystems of Disposal before the common service Scheduler.
Note the emphasis in this example on attributes that are aggregates abstracted as scalar values (i.e., Data Packet and Location). This is quite common when developing subject matters that have a relatively high level of abstraction. The main advantage of this is that it enables us to narrow the focus of our design, making the design compact and easier to understand because it is relatively uncluttered with detail.
Perhaps more important, it helps us abstract the interfaces to the subsystems, which enables us to define bridges in terms of requirements (“We will need the location data to respond to this message”) instead of data (“We need the company name, street address, city, state, country, and postal code”) or implementation (“The company name is a 50-character string, the street address is . . .”). In addition, the mapping of the data packet is isolated to whoever sends and receives the message, and the {message ID, <data packet>} paradigm is highly standardized, which enables us to apply some interesting reuse techniques.
Note also the emphasis on abstract, enumerated values for the data domains. This is also fairly common when we are trying to abstract complex entity semantics into knowledge responsibilities. Such data domains are ideally suited to preserving implementation independence while succinctly capturing complex semantics. In other words, they are well-suited to both raising the level of abstraction and extracting only views that are necessary to the problem in hand.
Now let’s look at the operations in Table 9-4.
You probably didn’t expect Crematorium to have the most complex behavior responsibilities in this subject matter. That should not be a surprise because we didn’t say anything about how a crematorium actually worked in the requirements. In fact, the previous description might well be an oversimplification. For example, are we really going to do hamsters in the same size furnace we would use for a horse?
Also, at the level of behavior of turning gas on and off, we are assuming temperature sensors that are not in evidence in this model. We blithely dismissed all that as “hardware.” But if we are thinking about timers in the analysis, wouldn’t a temperature sensor be at an equivalent level of abstraction? All this should make us nervous about whether we are handling cremation properly. We can make a case at this point to make Crematorium a subsystem in its own right, one that explicitly described how sensors, gas meters, flow valves, ignition, and timers all played together. That would be far too much detail for Disposition’s level of abstraction, so Crematorium would appear as nothing more than a surrogate interface class that accepted a Start message and issued a Done message with charges.
This would be an example of legitimate feedback to application partitioning. We find the subsystem to be more complex than we anticipated, and we need to provide a lower level of abstraction for parts of the subsystem. This results in delegation to a new service subsystem. As indicated in Chapter 6, this isn’t a major structural change because we are simply delegating a service that only talks to Disposition and its responsibilities are dictated by Disposition’s needs.
Before leaving these examples we need to address one area that has thus far appeared as magic. Specifically, where do all these object instances come from? “The stork brought them” is clearly not a satisfactory answer. The answer lies in design patterns, where the GoF20 book is a reference that every OO developer should have. Typically we will have a factory object that exists to instantiate other objects and relationships. (The Pet’s Initialize behavior might well act as a Factory for such initialization if it is pretty simple.) This is very handy because it standardizes the way applications are instantiated and enables us to isolate the rules and policies of instantiation (who) from those of the solution algorithm (what and when). In so doing it places those responsibilities in one place rather than dribbling them throughout the application.
When the idea of a Factory design pattern is combined with abstraction of invariants, we have a very powerful mechanism. It essentially enables the instances and relationships needing to be instantiated to be defined in external data that the factory object reads to do the instantiation. When dealing with invariants, it is very common for quite different problems to be solved simply by initializing different instance state data and linking instances with relationships differently. This can get quite exotic when we have tools like XML strings that can be parsed to define objects and their knowledge.
We didn’t include any factory objects in either example because in both of these examples many of the objects can be defined at start-up. If they can be initialized at start-up, then initialization is usually relegated to a synchronous service at the subsystem level that is conceptually invoked via an “initialize” message to the subsystem interface at start-up. Therefore, the synchronous service effectively becomes a factory operation in the subsystem interface. In turn, that makes it a bridge, so it is outside the subject matter (albeit intimately related to it). In addition, we didn’t include factory objects for the dynamically instantiated objects just to keep things simple.