
When IBM released version 2.1 of the Cell SDK, I took a long, hard look at the code for the 16M fast Fourier transform (FFT). I’m usually pretty good at deciphering FFTs, but this code was horrendous. It wasn’t the bit reversal or butterfly equations; the problem was data storage and communication. Each FFT stage transferred data with a bewildering series of noncontiguous list operations and stored the data in multiple buffers. I drew diagrams and flowcharts, but the code was so hard to follow that I gave up.
When SDK 3.0 arrived, everything became clear. The algorithm hadn’t changed, but the FFT code had been rewritten using the Accelerated Library Framework (ALF). Thanks to this new structure, I didn’t need diagrams to keep track of direct memory access (DMA) and buffering. More important, I knew that if I ever needed to write a 32M or 64M FFT on my own, I could apply the ALF methodology without difficulty.
ALF provides a structured framework for creating applications requiring large-scale data transfers and multibuffering. This toolset was designed to manage applications on many different kinds of processor systems, so instead of referring to the PowerPC Processor Unit (PPU) and the Synergistic Processor Units (SPUs), this chapter uses the official ALF terminology: The host stores the data and assigns tasks; the accelerators acquire the data, process it, and transfer the results back to the host.
The ALF reduces the complexity of building data-intensive applications, but it takes time to understand. There are many new concepts, functions, and data structures, and the SDK’s Hello World example is impossible for a beginner to grasp. So before we reach that point, I’ll do my best to present the ALF in an intuitive manner and I’ll start by comparing the ALF to a library we’ve already encountered: libspe.
This section explains, at a high level, what ALF is and how it works. The best way to do this, in my opinion, is to compare ALF to the SPE Management library (libspe), the subject of Chapter 7, “The SPE Runtime Management Library (libspe).” From there, the discussion focuses on how the ALF buffers memory on the accelerators.
All the multiprocessor applications in this book have relied on libspe to coordinate PPU/SPU processing, and they all work the same way: The PPU assigns object code to SPUs using contexts, runs the contexts as threads, and waits for the threads to complete. Mailbox messaging transfers small data payloads and DMA transfers large blocks of data. All data transfer and memory buffering is performed at a low level using pointers to memory.
An ALF application accomplishes the same result, but the development process is simpler thanks to the ALF runtime. This processing environment handles many of the low-level details of SPU management. For example, the code still has to identify SPU program handles, but the ALF assigns the program handles to SPUs. The code still has to identify what data the SPUs should have, but the ALF runtime manages the communication mechanisms like mailboxes and DMA.
In libspe, the central data structure is the context. With ALF, there are three central structures: tasks, task instances, and work blocks:
A task is an abstract definition of a processing job. It contains generic information about the accelerator (SPU) object code and the nature of the data that needs to be transferred to and from the accelerators.
A task instance is a task matched to a specific accelerator. One task instance per accelerator.
A work block is a concrete invocation of a task that is executed on a task instance.
An example will clarify how this works. Let’s say you want to perform eight matrix multiplications using four accelerators. The ALF task identifies the accelerator object code needed to multiply the matrices, the type of input data to be transferred to the accelerators, and the type of output data to be transferred back to host memory. A task instance is assigned to each of the accelerators, as shown in Figure C.1.
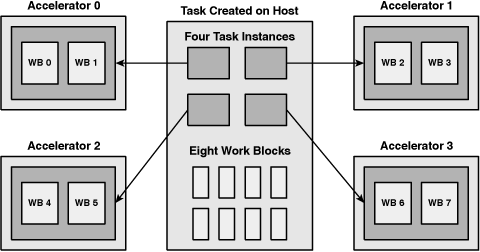
Eight work blocks are created, and each is configured with the information it needs to perform a specific matrix multiplication. That is, the first work block receives the addresses of the first two input matrices and the address where the output should be stored. The computational task doesn’t change from work block to work block; the specific data needed for the computation does. Once defined, these eight work blocks are enqueued on the task for execution.
Figure C.1 shows the eight work blocks evenly distributed among the task instances, but this isn’t always the case. By default, the ALF runtime sends each work block to whichever accelerator is available to process it. This behavior can be changed when the task is defined.
Chapter 12, “SPU Communication, Part 1: Direct Memory Access (DMA),” explains how DMA and multibuffering can be combined to create applications that process and transfer data at the same time. It’s like an on-chip assembly line: While the input buffer is filled, the data in the computation buffer is processed, and data in the output buffer is delivered to host memory. Then the buffers switch roles.
This is fine in theory, but writing Cell code to make multiple DMA transfers into multiple buffers can be difficult. Not only do you have to know what each buffer is doing for each iteration, you also have to keep track of DMA tags, array indices, and scatter/gather operations. As the amount of data increases, it becomes easier to make mistakes and harder to debug them.
The ALF runtime manages data transfers and multibuffering by dividing up accelerator memory into six main buffers of configurable size. These are shown in Figure C.2.
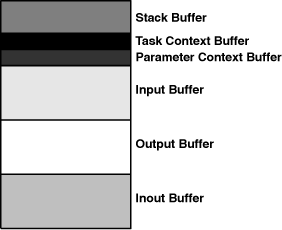
These buffers are differentiated by the type of data they hold and when/where the data is transferred:
The stack buffer holds variables used during the accelerator’s computation. No data is transferred from the host.
The task context buffer holds data specific to a given task. Transferred to the accelerators at the beginning of their operation, merged together at the end.
The parameter context buffer holds data specific to a given work block. Transferred to the accelerators before the work block starts, not transferred back to host memory.
The input buffer holds data to be processed. Transferred from host before main processing, not transferred back to host memory.
The output buffer holds processed data. Transferred to host after processing is completed.
The inout buffer holds data to be processed in-place. Transferred from host before main processing, and transferred back to host after processing is completed.
The stack buffer operates like a regular stack, and its maximum size must be configured in code. The two context buffers hold initialization data for the task and work blocks. The last three buffers contain preprocessed and postprocessed data. As a general rule of thumb, if you’d normally send data using mailboxes, send the data using an ALF context buffer. If you’d normally transfer data using DMA, use ALF’s input, output, or inout buffers.
ALF provides one set of functions to run on the host and one set to run on the accelerators. On the host, the goal is to create a task and configure it with work blocks. This section explains host development in three parts: initializing the environment, coding task descriptors and task contexts, and creating work blocks.
The ALF library, libalf, provides three basic functions that initialize ALF’s operation and provide general information. alf_init creates the ALF environment, alf_query_system_info returns information about the environment, and alf_num_instances tells the environment how many accelerators will be used by the application. In many ALF applications, these are the first three functions to be invoked.
The first initialization function creates a handle representing the entire ALF environment. Its signature is given by the following:
int alf_init(sys_config_info_CBEA_t* library_path, alf_handle_t* handle);
The first argument tells the ALF runtime where to find the computational kernel (object code) to be run by the accelerators (SPUs). The sys_config_info_CBEA_t is really just a char*, as shown here:
typedef struct {
char* library_path;
} alf_sys_config_t_CBEA_t;If this parameter is set to null, the ALF runtime searches for object code in the path identified by the ALF_LIBRARY_PATH environment variable. If this variable isn’t set, it looks for the code in the current directory. If it doesn’t find it there, it raises an error.
Note
In each of this chapter’s example projects, the PPU and SPU code files are located in the same directory. This is fine for simple applications; but for large projects, remember to separate your code and set ALF_LIBRARY_PATH appropriately.
The second parameter in alf_init is a pointer to an alf_handle_t that represents the ALF runtime and its environment. As the function executes, this structure is initialized with the data that the ALF runtime requires to function. You won’t access this structure directly, but it’s used as a parameter in many of the following ALF functions.
The function’s return value, like that of all ALF functions, indicates the function’s completion status. A value greater than or equal to 0 represents success, and any value less than 0 implies failure.
After you’ve created the ALF handle, you can use it to obtain information about the runtime environment. The alf_query_system_info function makes this possible, and its full signature is this:
int alf_query_system_info(alf_handle_t alf_handle, ALF_QUERY_SYS_INFO_T info_type, ALF_ACCEL_TYPE_T accel_type, unsigned int* result);
The first parameter is the ALF handle. The second identifies what type of information is sought, and the third identifies the accelerator type (ALF_ACCEL_TYPE_SPE for all Cell applications). The fourth parameter is a pointer to the int that holds the requested value.
ALF provides much more system visibility than libspe, whose spe_cpu_info_get only returns the number of available SPEs. Table C.1 lists the different values that can be inserted into the second parameter of alf_query_system_info.
Table C.1. ALF System Query Fields
Information | |
|---|---|
| Number of accelerators available on system |
| Host memory size in KB, up to 4TB |
| Host memory size in 4TB chunks |
| Accelerator memory size in KB, up to 4TB |
| Accelerator memory size in 4TB chunks |
| Alignment required for host addresses |
| Alignment required for accelerator addresses |
| Alignment required for data transfer lists |
| Data ordering on the host:
|
| Data ordering on the accelerator:
|
As an example, the code in Listing C.1 uses alf_system_query_info to determine the number of available accelerators, the amount of available host memory, and the alignment required for accessing accelerator memory.
Example C.1. Querying the ALF System: ppu_alf_simple.c
#include <stdio.h>
#include "alf.h"
int main(int argc, char **argv) {
/* Declare variables - info vars must be unsigned int */
alf_handle_t alf_handle;
unsigned int num_accel, host_mem, accel_align;
/* Initialize the alf handle and access system info */
alf_init(NULL, &alf_handle);
alf_query_system_info(alf_handle, ALF_QUERY_NUM_ACCEL,
ALF_ACCEL_TYPE_SPE, &num_accel);
alf_query_system_info(alf_handle, ALF_QUERY_HOST_MEM_SIZE,
ALF_ACCEL_TYPE_SPE, &host_mem);
alf_query_system_info(alf_handle,
ALF_QUERY_ACCEL_ADDR_ALIGN,
ALF_ACCEL_TYPE_SPE, &accel_align);
/* Display the results */
printf("Number of accelerators: %d
", num_accel);
printf("Host memory: %d
", host_mem);
printf("Accelerator memory alignment: %d
", accel_align);
return 0;
}On my system, the displayed output is as follows:
Number of accelerators: 6 Host memory: 217068 Accelerator memory alignment: 4
alf_query_system_info can tell you how many accelerators are available, but you still need to tell the ALF runtime how many you intend to use. This is done by calling alf_num_instances_set, whose full signature is given by the following:
int alf_num_instances_set(alf_handle_t handle, unsigned int n);
This is as simple as it looks. To make sure all the accelerators (SPUs) are used, set n equal to the number of available accelerators. In many ALF applications, you’ll see initialization code similar to the following:
alf_init(NULL, &alf_handle); alf_query_system_info(alf_handle, ALF_QUERY_NUM_ACCEL, ALF_ACCEL_TYPE_SPE, &num_accel); alf_num_instances_set(alf_handle, num_accel);
This creates the ALF handle, retrieves information about the number of available accelerators, and tells ALF that all of the accelerators be used. After calling these three functions, you’re ready to create tasks.
You don’t configure tasks directly in ALF. Instead, you create and configure a task descriptor, and use it to create a new task. The function that creates task descriptors is alf_task_desc_create. Its signature is given by the following:
int alf_task_desc_create(alf_handle_t alf_handle, ALF_ACCEL_TYPE_T accel_type, alf_task_desc_handle_t* descriptor_handle);
The second parameter is the type of accelerator (ALF_ACCEL_TYPE_SPE on the Cell), and the last parameter must be a pointer to an alf_task_desc_handle_t structure. This represents the task descriptor.
Once a descriptor is created, it has to be configured for its intended task. This entails matching values to the descriptor’s parameters. Two functions make this possible:
int alf_task_desc_set_int32(alf_task_desc_handle_t task_desc_handle, ALF_TASK_DESC_FIELD_T field, unsigned int value); int alf_task_desc_set_int64(alf_task_desc_handle_t task_desc_handle, ALF_TASK_DESC_FIELD_T field, unsigned long long value);
Both functions set the parameter identified by field equal to value. The difference between them is that the first function sets value equal to a 32-bit int, and the second sets value equal to a 64-bit long. Table C.2 lists each descriptor parameter and the required size of value.
Table C.2. Configurable Fields in the ALF Task Descriptor
Field Name | Field Size | Purpose |
|---|---|---|
| 64 bit | Library containing accelerator code |
| 64 bit | The object handle containing accelerator code |
| 64 bit | The computational kernel function |
| 64 bit | Function to prepare the input data transfer list |
| 64 bit | Function to prepare the output data transfer list |
| 64 bit | Function to configure the context |
| 64 bit | Function to merge the context |
| 32 bit | Maximum size of the accelerator stack |
| 32 bit | Size of the task context buffer |
| 32 bit | Size of the parameter context buffer |
| 32 bit | Size of the work block input buffer |
| 32 bit | Size of the work block output buffer |
| 32 bit | Size of the work block input/output buffer |
| 32 bit | Number of entries in the data transfer list |
| 32 bit | Generate transfer lists on the accelerator |
The first two fields are particularly important. The host can only access an SPU object as a shared object library (*.so). The first field names the library, and the second field names the object in the library. For example, to access obj_name in lib_name.so, you’d configure the descriptor as follows:
char library_name[] = "lib_name.so"; char spu_image_name[] = "spu_alf_text"; alf_task_desc_set_int64(task_desc, ALF_TASK_DESC_ACCEL_IMAGE_REF_L, (unsigned long long)spu_image_name); alf_task_desc_set_int64(task_desc, ALF_TASK_DESC_ACCEL_LIBRARY_REF_L, (unsigned long long)library_name);
The rest of the 64-bit fields name functions that correspond to the five stages of accelerator operation. These stages are explained in a later section.
Most of the 32-bit fields identify the maximum capacity of the six buffers described earlier. For example, the ALF_TASK_DESC_TSK_CTX_SIZE field specifies the size of the task context buffer, and ALF_TASK_DESC_WB_OUT_BUF_SIZE specifies the size of the dedicated output buffer.
The third function used to configure task descriptors is alf_task_desc_ctx_entry_add. This creates the task context that is transferred to and from the accelerators. The task context works like the control_block structure used in libspe applications: It provides accelerators with the data they need to perform their computation, such as host memory addresses where they can find preprocessed data. When the accelerators have finished their tasks, the task context holds the result that is sent to the host.
The function’s signature is given as follows:
int alf_task_desc_ctx_entry_add(alf_task_desc_handle_t task_desc_handle, ALF_DATA_TYPE_T data_type, unsigned int size);
The second parameter identifies the ALF datatype corresponding to the task context, and the third specifies how many of that datatype will be placed in the context. These data types are ALF specific and Table C.3 lists them all.
Table C.3. ALF Datatypes for Host/Accelerator Data Transfer
Datatype | Content |
|---|---|
| 16-bit signed/unsigned short |
| 32-bit signed/unsigned integer |
| 64-bit signed/unsigned long integer |
| 32-bit floating-point value |
| 64-bit floating-point value |
| 32-bit address |
| 64-bit address |
| Order-independent data |
For example, to create a task context in desc_handle containing four double values, you’d make the following function call:
alf_task_desc_ctx_entry_add(desc_handle, ALF_DATA_DOUBLE, 4);
If your task context is composed of three floats and a 64-bit address, you’d make two function calls:
alf_task_desc_ctx_entry_add(desc_handle, ALF_DATA_FLOAT, 3); alf_task_desc_ctx_entry_add(desc_handle, ALF_DATA_ADDR64, 1);
The rest of the datatypes are similarly straightforward. The last datatype, ALF_DATA_BYTE, tells the runtime that the data is independent of little-endian or big-endian ordering.
After the task descriptor is used to create a task, it’s no longer necessary. It should be deallocated with alf_task_desc_destroy(task_desc_handle).
After the task descriptor has been configured, you can use it to create a task. This is accomplished with a call to alf_task_create, which accepts six parameters:
alf_task_desc_handle_t td_handle: The task descriptor handlevoid* tsk_context: Pointer to the task contextunsigned int num_inst: Number of task instances (depends ontsk_attr)unsigned int tsk_attr: Task attributeunsigned int wb_dist: Number of work blocks per distribution unitalf_task_handle_t* task_handle: Pointer to the structure: that will represent the task
The tsk_context parameter points to the task context structure whose composition was defined by alf_task_desc_ctx_entry_add. It must have the same size as the value of the ALF_TASK_DESC_TSK_CTX_SIZE field in the task descriptor.
The next two parameters, num_inst and tsk_attr, are more complicated. As mentioned earlier, you tell the ALF runtime the total number of task instances you want with alf_num_instances_set. If tsk_attr is set to ALF_TASK_ATTR_SCHED_FIXED and num_inst is set to a lower number, however, this lower number controls how many task instances are created.
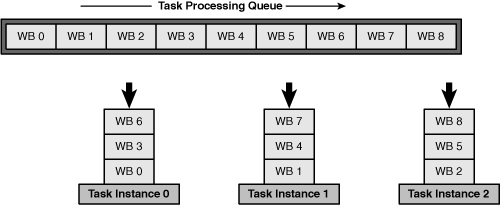
By default, the ALF runtime assigns each work block to the first task instance that can process it. But if tsk_attr is set to ALF_TASK_ATTR_SCHED_FIXED | ALF_TASK_ATTR_WB_CYCLIC, the work blocks are distributed in a round-robin manner, regardless of how time intensive they are.
For example, if a task contains nine work blocks (0–8), num_instances equals 3, and tsk_attr is set to ALF_TASK_ATTR_SCHED_FIXED | ALF_TASK_ATTR_WB_CYCLIC, blocks {0, 3, 6} are assigned to task instance 0, blocks {1, 4, 7} are assigned to task instance 1, and blocks {2, 5, 8} are assigned to task instance 2. This is shown in Figure C.3.
The last two fields of alf_task_create are straightforward: wb_dist_size tells the runtime how many work blocks are bundled together with each distribution, and task_handle represents the task itself. You probably won’t access this task structure directly. Instead, you need to create and enqueue one or more work blocks.
An ALF task serves no purpose without work blocks. Each work block represents one invocation of the task on the accelerator, and each work block executes the accelerator code identified in the task descriptor. In addition, each work block receives the same task context data.
The function that creates work blocks is alf_wb_create, and its signature is given by the following:
int alf_wb_create(alf_task_handle_t task_handle, ALF_WORK_BLOCK_TYPE_T block_type, unsigned int repeat_count, alf_wb_handle_t *wb_handle);
The first two fields contain handles to the existing task and the work block to be created. The third, block_type, controls whether the work block is single use (ALF_WB_SINGLE) or multiple use (ALF_WB_MULTI). A single-use work block runs only once before finishing, and a multiple-use work block repeats its operation in a loop.
The next parameter, repeat_count, determines how many times a multiple-use work block iterates before finishing. If the work block is single use, this parameter is ignored. Multiple-use work block operation is supported only if the task descriptor was configured with the field ALF_TASK_DESC_PARTITION_ON_ACCEL set to 1.
For example, to create a work block (wb_handle) for a task (task_handle) that will run 20 times, the function can be called as follows:
alf_wb_create(task_handle, ALF_WB_MULTI, 20, &wb_handle);
After you’ve created a work block, you can provide it with data specifically for its use. This is called the parameter context. It’s important to distinguish this from the task context. Information in a task context is distributed to all the work blocks of a given task. Information in a parameter context is specific to each work block. The size of the parameter context must be set in advance with the ALF_TASK_DESC_WB_PARM_CTX_BUF_SIZE field in the task descriptor.
The alf_wb_parm_add function adds parameters to the context. Its signature is given by the following:
int alf_wb_parm_add(alf_wb_handle_t wb_handle, void *pdata, unsigned int data_num, ALF_DATA_TYPE_T data_type, unsigned int alignment)
This is similar to alf_task_desc_ctx_entry_add; but in addition to specifying the datatype and size, this function also identifies the data itself. The second argument is a pointer to the parameter context data structure. This structure must have a size equal to sizeof(data_type) * data_num. The last parameter, alignment, can be obtained by calling alf_query_system_info with the ALF_QUERY_ACCEL_ADDR_ALIGN field.
When the ALF runtime needs to transfer large amounts of data, it creates data transfer lists, or DTLs. A DTL is similar to the DMA list discussed in Chapter 12, but in addition to transferring data, a DTL also manages how the data is buffered on the accelerator. This buffer management, in my opinion, is the most important advantage of using ALF.
The process of generating DTLs is called data partitioning, and it can be performed by the host application or the accelerator application. To tell the ALF runtime which partitioning method to use, you need to set the ALF_TASK_DESC_PARTITION_ON_ACCEL field in the task descriptor. If this is set to 1, the runtime calls data partitioning routines on the accelerator. If it’s set to 0, the host must invoke its own DTL functions.
Each DTL provides two pieces of information:
The data structure in host memory that needs to be transferred
How the data should be buffered in accelerator memory
The ALF library provides three host functions that create DTLs. Table C.4 lists each and its purpose.
The first function, alf_wb_dtl_begin, tells the runtime how and where the data should be stored in accelerator memory. Its signature is given by the following:
int alf_wb_dtl_begin(alf_wb_handle_t wb_handle, ALF_BUF_TYPE_T buffer_type, unsigned int buffer_offset);
The second parameter identifies how the data should be buffered in accelerator memory. DTL data can be transferred into an input or inout buffer, or transferred out of an inout or output buffer. Table C.5 lists the possible values for the second parameter.
Table C.5. Buffer Storage for Work Block Data (ALF_BUF_TYPE_T)
Buffer Type | Purpose |
|---|---|
| Store data in dedicated input buffer |
| Store data in dedicated output buffer |
| Store data in input section of overlap buffer |
| Store data in output section of overlap buffer |
| Store data in inout section of overlap buffer |
Which buffer type to use depends on what you intend to do with the data. For example, if the first work block of a sequence takes data into an accelerator but doesn’t transfer it out, ALF_BUF_IN is appropriate. If the last work block of a sequence delivers output from an accelerator but doesn’t bring any in, ALF_BUF_OUT is the type to use. If the work block transfers data into and out of an accelerator, ALF_BUF_OVL_INOUT should be used.
Note
Make sure to manage the buffer sizes so that they don’t take up all the accelerator memory. Buffer sizes are configured in the task descriptor using the
ALF_TASK_DESC_WB_IN_BUF_SIZE, ALF_TASK_DESC_WB_OUT_BUF_SIZE, and ALF_TASK_DESC_WB_INOUT_BUF_SIZE fields.
ALF’s method of multibuffering depends on which storage scheme you choose. If you store data in an overlap buffer and your combined buffer size (input + output + inout) is less than 120KB, the ALF runtime uses two sets of buffers to perform input-computation-output tasks. The first set of buffers starts first: It acquires data from host memory and begins computation. The second set acquires data while the first is computing, and the two sets of buffers alternate between computation and data transfer. Figure C.4 shows how this double-buffering mechanism works.

In addition to specifying the buffer type, you need to tell the ALF runtime where data should be placed inside the buffer. The last parameter of alf_wb_dtl_begin specifies how many bytes into the buffer the data should be placed. For example, to position matrix_b after matrix_a in the input section of an overlap buffer, you could use the following:
int alf_wb_dtl_begin(wb_handle, ALF_BUF_OVL_IN, sizeof(matrix_a));
The second function in the table, alf_wb_dtl_entry_add, adds entries to the DTL. Each entry usually corresponds to a single data structure. DTL entries are like DMA list elements, but simpler. The function’s signature is given by the following:
int alf_wb_dtl_entry_add (alf_wb_handle_t wb_handle, void* pdata, unsigned int data_num, ALF_DATA_TYPE_T data_type);
This is similar to the alf_wb_parm_add function described previously. pdata points to the data to be transferred, data_type identifies the datatype, and data_num tells how many of the datatype should be transferred.
The last function, alf_wb_dtl_end, completes the DTL creation process, and its only parameter is the work block handle. The following code shows how all three functions are used to transfer two large float arrays, vec_a and vec_b, into a dedicated input buffer:
alf_wb_dtl_begin(wb_handle, ALF_BUF_ IN, 0); alf_wb_dtl_entry_add(wb_handle, vec_a, 1000, ALF_DATA_FLOAT); alf_wb_dtl_entry_add(wb_handle, vec_b, 1000, ALF_DATA_FLOAT); alf_wb_dtl_end(wb_handle);
Multiple DTLs can be added to a work block as needed.
The final step in dealing with work blocks is adding them to a task’s processing queue. This is done with alf_wb_enqueue. When this function is called, the ALF runtime makes sure the work block is processed when the task executes. Its signature is given by the following:
int alf_wb_enqueue(alf_wb_handle_t wb_handle)
Once the work block is enqueued in an application, it cannot be accessed by the host again.
After the work blocks are enqueued, the task can be started. This requires two function calls: alf_task_finalize(task_handle) and alf_task_wait(task_handle, timeout). The first function prevents further work blocks from being enqueued, and the second starts the task and waits until it completes its processing.
The timeout parameter of alf_task_wait identifies how many milliseconds the host should wait before an error occurs. The function returns immediately if the value equals 0. If the value is negative, it waits for all the accelerators to finish.
The last required function is alf_exit. This deallocates all ALF resources and ends the operation of the ALF runtime. Its signature is given by the following:
int alf_exit(alf_handle_t alf_handle, ALF_EXIT_POLICY_T policy, int timeout);
The policy parameter specifies what should happen when the function executes. The three possible options are as follows:
ALF_EXIT_POLICY_FORCE: Shuts down the ALF runtime and immediately ends all tasksALF_EXIT_POLICY_WAIT: Waits for all tasks to complete and then shuts down the ALF runtimeALF_EXIT_POLICY_TRY: Returns an error if all the tasks haven’t completed
The timeout parameter of alf_exit is similar to the timeout parameter of alf_task_wait. If the value is positive, the runtime waits at most the specified number of milliseconds before exiting. If the value is 0, the function returns immediately. If timeout is less than 0, the function waits indefinitely if the policy parameter is set to ALF_EXIT_POLICY_WAIT.
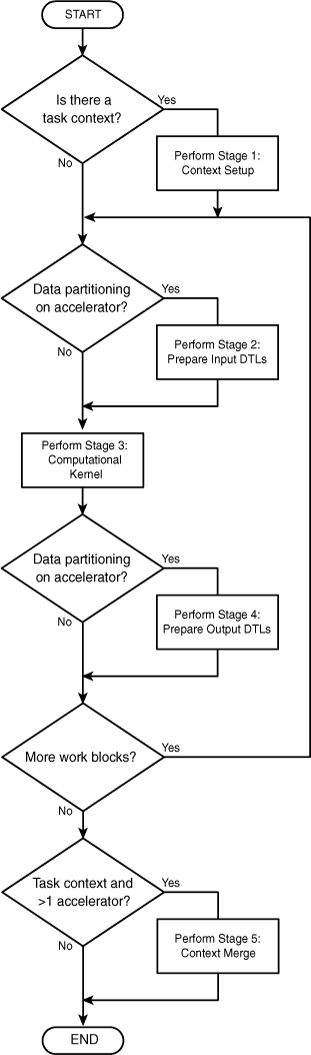
Writing code for an ALF accelerator is simpler than writing code for the host application. You don’t have to worry about tasks and work blocks and their associated life-cycle functions. You usually don’t have to deal with bizarre, barely documented data structures. However, you do have to understand one crucial point: The ALF runtime calls accelerator functions at different times according to the stage they represent. This section describes the five stages and how to write functions for them.
In most applications, the execution environment starts processing at the function called main. The ALF runtime also invokes functions according to their names, but the actual names aren’t important: It’s the processing stage corresponding to the name. The five ALF stages are as follows:
Setup task context: Allocate memory and initialize the task context data.
Create input data transfer lists: Generate the DTLs for the input data.
Process computational kernel: Process the input data into the output data.
Create output data transfer lists: Generate the DTLs for the output data.
Merge task context: Combine and postprocess the task context.
Not all the stages are necessary, but if your accelerator code performs a stage, it must have a corresponding function. The function that performs Stage 1 is executed first, and the function whose name corresponds to Stage 5 is executed last. Stage 3, the computational kernel stage, is the most important and is the only stage required by the ALF runtime. Put simply, it’s the stage where input data is processed into output data.
The rest of the stages manage data before and after the computational kernel does its work. As described in the preceding section, the host can create an optional task context that holds data to be shared between the host and accelerator. If task contexts are used, the ALF runtime expects to find accelerator functions representing Stages 1 and 5, which manage the task context before and after processing.
ALF applications use DTLs to transfer large amounts of data. As described earlier, these are similar to DMA transfer lists, but provide additional buffer management. You can generate DTLs in the host application or in the accelerator application, and the preceding section explained how this is done on the host. Stage 2 creates DTLs that bring data into the accelerator, and Stage 4 creates DTLs that send data out of the accelerator.
Stages 1 and 5, if available, are processed only once for each task. Stages 2 and 4, if available, are processed once for single-use work blocks and multiple times for multiple-use work blocks. Similarly, Stage 3 is processed once for single-use work blocks and multiple times for multiple-use work blocks. Figure C.5 displays these processing stages for single-use work blocks.
The rest of this section further explains what these stages actually do.
Before the ALF runtime can process these stages, it needs to know which functions represent them. To provide this information, you need to perform three steps:
In host code, configure the task descriptor with accelerator function names.
In accelerator code, create functions with the configured names and specified signatures.
At the end of the accelerator code, use ALF macros to export function names to host.
The first step was briefly mentioned in the previous section. Of the 64-bit fields used by alf_task_desc_set_int64 to configure task descriptors, five of them identify function names on the accelerator. These are, in order
ALF_TASK_DESC_ACCEL_CTX_SETUP_REF_L: Identifies the Stage 1 functionALF_TASK_DESC_ACCEL_INPUT_DTL_REF_L: Identifies the Stage 2 functionALF_TASK_DESC_ACCEL_KERNEL_REF_L: Identifies the Stage 3 functionALF_TASK_DESC_ACCEL_OUTUT_DTL_REF_L: Identifies the Stage 4 functionALF_TASK_DESC_ACCEL_CTX_MERGE_REF_L: Identifies the Stage 5 function
For example, to configure a task descriptor (task_desc_handle) to associate the merge function with Stage 5 (task context merge), you’d use the following code:
char ctx_setup_name[] = "merge"; alf_task_desc_set_int64(task_desc_handle, ALF_TASK_DESC_ACCEL_CTX_MERGE_REF_L, ctx_setup_name);
The second of the three steps is more involved. The ALF runtime presents each function representing a stage with a specific list of parameters. The number and types of these parameters differ from stage to stage.
A function implementing Stage 1 processes task contexts before the actual computation starts. This processing can include data allocation, type conversion, and initialization. The context setup function receives a single value that points to the context, and its signature is given by the following:
int stage1_function(void* task_context);The nature of the data forming the task context is specified in the host code with alf_task_create. If the host specifies a null argument, this stage won’t be performed.
The goal of the second stage function is to create DTLs that bring data into the accelerator. The ALF runtime calls this function as many times as the corresponding work block is invoked; if the work block is multiple use, this function will be called multiple times. The task descriptor must have ALF_TASK_DESC_PARTITION_ON_ACCEL set to 1 for this function to be called.
A function implementing this stage must have the following signature:
int stage2_function(void* task_context, void* param_context, void* dtl, unsigned int current_iter, unsigned int num_iter);The first two parameters point to the task context and parameter context. As a reminder, the task context is data associated with the entire task, and the parameter context contains data specific to each work block being processed. In both cases, the value is a void* because the contexts’ datatype and size are configured by the developer.
If the corresponding work block is multiple use, num_iter identifies the number of iterations, and current_iter identifies which iteration is being processed. If the work block is single use, num_iter is set to 1, and current_iter remains at 0.
The third parameter, dtl, points to the DTL that transfers data into the accelerator. You can’t access this structure directly, but you can configure it with macros provided by the ALF runtime. These macros have names similar to the functions that create DTLs on the host, and Table C.6 lists each and its purpose.
These macros accept the same parameters as their corresponding host DTL functions, alf_wb_dtl_begin, alf_wb_dtl_entry_add, and alf_wb_dtl_end, with two exceptions. First, the work block handle in the host functions is replaced by the dtl parameter in the Stage 2 function’s signature. Second, the ALF_ACCEL_DTL_ENTRY_ADD macro places the host address last in its parameter list.
Let’s look at an example. To create a DTL that transfers float arrays from host_addr_1 and host_addr_2 into a dedicated input buffer, you’d use the following code:
ALF_ACCEL_DTL_BEGIN(dtl, ALF_BUF_IN, 0); ALF_ACCEL_DTL_ENTRY_ADD(dtl, 100, ALF_DATA_FLOAT, host_addr_1); ALF_ACCEL_DTL_ENTRY_ADD (dtl, 100, ALF_DATA_FLOAT, host_addr_2); ALF_ACCEL_DTL_END(dtl);
Multiple DTLs can be created by allocating memory for an array of lists and setting dtl to point to the allocated memory.
Another important difference between creating DTLs on the accelerator and creating DTLs on the host is that you can’t create input entries and output entries at the same time. Stage 2 can only create DTLs that fill input and inout buffers. Stage 4 can only create DTLs that take data from output and inout buffers.
The function that implements the third stage performs the real computation of the work block. Before the ALF runtime calls this function, it processes the DTLs that bring data into accelerator buffers. The locations of these buffers are provided as parameters for the Stage 3 function, whose required signature is given as follows:
int stage3_function (void* task_context, void *parameter_context, void *input_buffer, void *output_buffer, void* inout_buffer, unsigned int current_iter, unsigned int num_iter);As shown, the computational kernel can access the task context, the parameter context, and each of the buffers. It processes this data and places the results in either the inout_buffer or the output_buffer.
As with the Stage 2 function, if the corresponding work block is multiple use, num_iter identifies the total number of iterations and current_iter identifies which iteration is being processed. If the work block is single use, num_iter is set to 1, and current_iter is set to 0.
When the computational kernel finishes, the processed data can be transferred to host memory using DTLs. This is the role of the Stage 4 function, and its signature is exactly similar to that of the Stage 2 function:
int stage4_function(void* task_context, void* param_context, void* dtl, unsigned int current_iter, unsigned int num_iter);The only difference between the Stage 4 function and the Stage 2 function is that the Stage 4 function creates DTLs only for output buffers. For example, the following code transfers 500 ints from the output buffer to address ea_1 in host memory and 100 ints from the output buffer to ea_2:
ALF_ACCEL_DTL_BEGIN(dtl, ALF_BUF_ OUT, 0); ALF_ACCEL_DTL_ENTRY_ADD(dtl, 500, ALF_DATA_INT32, ea_1); ALF_ACCEL_DTL_ENTRY_ADD (dtl, 100, ALF_DATA_INT32, ea_2); ALF_ACCEL_DTL_END(dtl);
Like the Stage 2 function, this function is called only if the task descriptor’s ALF_TASK_DESC_PARTITION_ON_ACCEL field is set to true (1).
The last of the five stages prepares a final task context to be returned to the host. This process is called a “merge” because it may involve combining results from multiple task instances. The function that implements this stage must have the following signature:
int stage5_function(void* source_context, void* target_context);
The first data structure represents the task context before the merge, and the second parameter points to the context that is returned to the host. If only one accelerator is used, the Stage 5 function isn’t called. If the host application doesn’t create a task context, neither the Stage 1 function nor the Stage 5 function is called.
You need to take one last step to tell the ALF runtime what functions correspond to the accelerator stages. In your accelerator code, you need to insert a series of macros that export your function names to the ALF runtime. The section starts with ALF_ACCEL_EXPORT_API_LIST_BEGIN and ends with ALF_ACCEL_EXPORT_API_LIST_END. Neither of these macros takes any arguments.
Inside the section, ALF_ACCEL_EXPORT_API must be inserted for each function name corresponding to a stage. This macro accepts two parameters, both of type char*. The first identifies the API as a whole, and the second contains the name of a function that needs to be exported. The first argument is usually set blank, or "".
For example, suppose your application uses a task context but doesn’t create any data transfer lists. In this case, Stages 1, 3, and 5 must be implemented. If the corresponding functions are named stage1_function, stage3_function, and stage5_function, an acceptable export definition section would be this:
ALF_ACCEL_EXPORT_API_LIST_BEGIN
ALF_ACCEL_EXPORT_API("", stage1_function);
ALF_ACCEL_EXPORT_API("", stage3_function);
ALF_ACCEL_EXPORT_API("", stage5_function);
ALF_ACCEL_EXPORT_API_LIST_ENDThis section is commonly placed at the end of the accelerator code. Keep in mind that these function names must be the same as those identified in the task descriptor.
Before I finish discussing the accelerator API, I need to explain two last functions: alf_num_instances and alf_instance_id. These provide accelerators with information about themselves and the processing environment.
The first, alf_num_instances, tells the accelerator how many task instances are being created. The second function, alf_instance_id, provides the accelerator with its rank among the task instances. This is a number between 0 and alf_num_instances - 1.
Now that you have a theoretical understanding of how host and accelerator applications work, it’s time to look at full ALF examples. The first application stores text in the task context and calls on the accelerators to display the text. The next two applications perform matrix arithmetic: the first partitions data on the host, and the second partitions data on the accelerator.
The code in Listing C.2 creates a task containing four work blocks and distributes them to two accelerators. It allocates memory for a task context and a parameter context, and then sets the contexts’ contents equal to char arrays. It tells the ALF runtime that the Stage 1 function is called context_setup, the Stage 3 function is called kernel, and the Stage 5 function is called context_merge.
Example C.2. ALF Text Transfer on the Host: ppu_alf_text.c
#include <stdio.h>
#include <string.h>
#include "alf.h"
#define NUM_ACCEL 2
int main(int argc, char **argv) {
/* ALF data structures */
alf_handle_t alf_handle;
alf_task_handle_t task_handle;
alf_task_desc_handle_t td_handle;
alf_wb_handle_t wb_handle;
/* Names of SPU objects and functions */
char library_name[] = "spu_alf_text.so";
char spu_image_name[] = "spu_alf_text";
char kernel_name[] = "kernel";
char ctx_setup_name[] = "context_setup";
char ctx_merge_name[] = "context_merge";
/* Create messages to send to accelerator */
char task_msg[] = "This is the task context";
char param_msg[32];
/* Initialize the ALF handle and # of accelerators */
alf_init(NULL, &alf_handle);
alf_num_instances_set(alf_handle, NUM_ACCEL);
/* Create and configure the task descriptor */
alf_task_desc_create(alf_handle, 0, &td_handle);
alf_task_desc_set_int64(td_handle,
ALF_TASK_DESC_ACCEL_IMAGE_REF_L,
(unsigned long long)spu_image_name);
alf_task_desc_set_int64(td_handle,
ALF_TASK_DESC_ACCEL_LIBRARY_REF_L,
(unsigned long long)library_name);
alf_task_desc_set_int64(td_handle,
ALF_TASK_DESC_ACCEL_KERNEL_REF_L,
(unsigned long long)kernel_name);
alf_task_desc_set_int64(td_handle,
ALF_TASK_DESC_ACCEL_CTX_SETUP_REF_L,
(unsigned long long)ctx_setup_name);
alf_task_desc_set_int64(td_handle,
ALF_TASK_DESC_ACCEL_CTX_MERGE_REF_L,
(unsigned long long)ctx_merge_name);
/* Configure the memory requirements
and add the task context */
alf_task_desc_set_int32(td_handle,
ALF_TASK_DESC_MAX_STACK_SIZE, 4096);
alf_task_desc_set_int32(td_handle,
ALF_TASK_DESC_TSK_CTX_SIZE, sizeof(task_msg));
alf_task_desc_set_int32(td_handle,
ALF_TASK_DESC_WB_PARM_CTX_BUF_SIZE, sizeof(param_msg));
alf_task_desc_ctx_entry_add(td_handle, ALF_DATA_BYTE,
sizeof(task_msg));
/* Create the task for cyclic work block distribution */
int ret;
if ((ret = alf_task_create(td_handle, (void*)task_msg,
NUM_ACCEL, ALF_TASK_ATTR_SCHED_FIXED |
ALF_TASK_ATTR_WB_CYCLIC, 1, &task_handle)) < 0) {
fprintf(stderr, "alf_task_create failed, ret=%d
", ret);
return 1;
}
/* Create work blocks and add the parameter context */
int i;
for (i=0; i<NUM_ACCEL*2; i++) {
sprintf(param_msg, "This is parameter context %d", i);
alf_wb_create(task_handle, ALF_WB_SINGLE, 1, &wb_handle);
alf_wb_parm_add(wb_handle, (void*)param_msg,
sizeof(param_msg), ALF_DATA_BYTE, 3);
alf_wb_enqueue(wb_handle);
}
/* Finalize the task, wait for it to finish, and exit */
alf_task_finalize(task_handle);
alf_task_wait(task_handle, -1);
alf_task_desc_destroy(td_handle);
alf_task_destroy(task_handle);
alf_exit(alf_handle, ALF_EXIT_POLICY_FORCE, 0);
/* Display the changed task context */
printf("Host: %s
",task_msg);
return 0;
}
The alf_task_create function is particularly important. It tells the runtime to distribute the work blocks cyclically across all the accelerators. Because of the many possible errors involved in creating a task, this is the only function ALF whose return value is checked.
The application creates twice as many work blocks as there are accelerators. Each work block receives a parameter context that contains a message specific to the work block. This parameter context is aligned on a 23-byte boundary.
Listing C.3 presents code to run on the accelerator. The operation is simple: The context_setup function prints a message identifying the task instance, the kernel function prints the content of the task context and the parameter context, and context_merge prints a message and changes the content of the task context.
Example C.3. ALF Text Transfer on the Accelerator: spu_alf_text.c
#include <stdio.h>
#include <string.h>
#include <spu_mfcio.h>
#include <alf_accel.h>
/* Stage 1: Preprocess */
int context_setup(void *task_ctx) {
printf("Accelerator %d of %d: Running context_setup.
",
alf_accel_instance_id(), alf_accel_num_instances());
return 0;
}
/* Stage 3: Display the task and parameter contexts */
int kernel(void* task_context, void* param_context,
void* in_buffer, void* out_buffer, void* inout_buffer,
unsigned int current_count, unsigned int total_count) {
/* Determine the ID of the accelerator and their number */
int id = alf_accel_instance_id();
int num_tasks = alf_accel_num_instances();
printf("Accelerator %d of %d: %s
",
alf_accel_instance_id(), alf_accel_num_instances(),
(char*)task_context);
printf("Accelerator %d of %d: %s
", id, num_tasks,
(char*)param_context);
return 0;
}
/* Stage 5: Postprocess, update the task context */
int context_merge(void* source_context, void* target_context) {
printf("Accelerator %d of %d: Running context_merge.
",
alf_accel_instance_id(), alf_accel_num_instances());
strcpy(target_context, "New task context.");
return 0;
}
/* Use macros to export function names */
ALF_ACCEL_EXPORT_API_LIST_BEGIN
ALF_ACCEL_EXPORT_API("", context_setup);
ALF_ACCEL_EXPORT_API("", kernel);
ALF_ACCEL_EXPORT_API("", context_merge);
ALF_ACCEL_EXPORT_API_LIST_ENDThe displayed results are as follows:
Accelerator 0 of 2: Running context_setup Accelerator 1 of 2: Running context_setup Accelerator 0 of 2: This is the task context Accelerator 0 of 2: This is parameter context 0 Accelerator 0 of 2: This is the task context Accelerator 0 of 2: This is parameter context 2 Accelerator 1 of 2: This is the task context Accelerator 1 of 2: This is parameter context 1 Accelerator 1 of 2: This is the task context Accelerator 1 of 2: This is parameter context 3 Accelerator 0 of 2: Running context_merge Host: New task context
The results may differ slightly from execution to execution, but Accelerator 0 always receives Work Blocks 0 and 2, and Accelerator 1 always receives Work Blocks 1 and 3. This is because the ALF runtime distributes the work blocks cyclically. If alf_task_create is configured to use a different method of distribution, the work blocks are not necessarily sent to all the accelerators in order.
The context_setup and kernel functions simply provide output. The kernel function displays the parameter context, which changes from work block to work block, and the task context, which always remains the same. But context_merge does more than send text to standard output; it accesses the target_context pointer and uses strcpy to transfer a new char array into the task context. When the host prints the context after the task completes, it now reads "New task context" rather than "This is the task context".
The previous application transferred information to the accelerator through task and parameter context structures, but this isn’t suitable for data-intensive applications. To transfer large amounts of data, you need DTLs. The ALF runtime uses DTLs to form DMA lists, which transfer data to and from buffers in accelerator memory.
The host_matrix and acc_matrix projects both demonstrate how DTLs work. They take two 512x512 float matrices (matrix_one and matrix_two) as input and perform the same tasks:
Compute the difference of the input matrices and store the result in
matrix_threeCompute the sum of the input matrices and store the result back into
matrix_two
The difference between the two projects is that the host_matrix application partitions data on the host, and acc_matrix partitions data on the accelerator.
Local Stores can hold 256KB at most, so the (3 matrices) × (512 rows) × (512 columns) × (4 bytes/float) = 3MB of data must be subdivided into work blocks. In the host_matrix application, the host creates 16 blocks that each process 196KB. That is, each work block adds and subtracts 32 rows per work block, and the work blocks are distributed among 4 accelerators.
Note
This application fills two output buffers with each computation step, and total buffer size (input + output + inout) is greater than 120KB. Therefore, the double-buffering mechanism is not available.
Most of the host code is similar to that in Listing C.2, but the task descriptor now has entries for the input buffer (matrix_one), the inout buffer (matrix_two), and the output buffer (matrix_three). This is shown in the following code:
/* Allocate memory for the input buffer (matrix_one) */ alf_task_desc_set_int32(td_handle, ALF_TASK_DESC_WB_IN_BUF_SIZE, N*N*sizeof(float)/NUM_BLOCKS); /* Allocate memory for the inout buffer (matrix_two) */ alf_task_desc_set_int32(td_handle, ALF_TASK_DESC_WB_INOUT_BUF_SIZE, N*N*sizeof(float)/NUM_BLOCKS); /* Allocate memory for the output buffer (matrix_three) */ alf_task_desc_set_int32(td_handle, ALF_TASK_DESC_WB_OUT_BUF_SIZE, N*N*sizeof(float)/NUM_BLOCKS);
The accelerators send and receive matrix data through three DTLs. In the host_partition application, the first DTL transfers matrix_one data from the host into the accelerator’s input buffer, the second transfers data into the overlapped inout buffer, and the third sends data to the host through the output buffer. As specified in the task descriptor, each buffer holds 32 rows of data from both matrices. This works out to 512*32 = 16,384 floats, for a total memory requirement of 64KB.
The host code creates these DTLs as part of the work block generation process, as shown in the following code:
for (i=0; i<NUM_BLOCKS; i++) {
/* Create the work block */
alf_wb_create(task_handle, ALF_WB_SINGLE, 0, &wb_handle);
/* DTL: store matrix_one in an input buffer */
alf_wb_dtl_begin(wb_handle, ALF_BUF_IN, 0);
alf_wb_dtl_entry_add(wb_handle,
&matrix_one[i*N/NUM_BLOCKS][0],
N*N/NUM_BLOCKS, ALF_DATA_FLOAT);
alf_wb_dtl_end(wb_handle);
/* DTL: store matrix_two in an inout buffer */
alf_wb_dtl_begin(wb_handle, ALF_BUF_OVL_INOUT, 0);
alf_wb_dtl_entry_add(wb_handle,
&matrix_two[i*N/NUM_BLOCKS][0],
N*N/NUM_BLOCKS, ALF_DATA_FLOAT);
alf_wb_dtl_end(wb_handle);
/* DTL: store matrix_three in an output buffer */
alf_wb_dtl_begin(wb_handle, ALF_BUF_OUT, 0);
alf_wb_dtl_entry_add(wb_handle,
&matrix_three[i*N/NUM_BLOCKS][0],
N*N/NUM_BLOCKS, ALF_DATA_FLOAT);
alf_wb_dtl_end(wb_handle);
/* Enqueue the work block in the task */
alf_wb_enqueue(wb_handle);
}The accelerator code in the host_matrix project is easy to understand. Only the computational kernel stage is implemented. This adds the values in matrix_one to those in matrix_two and stores the sums in matrix_three. Then it subtracts matrix_two values from matrix_one values and stores the differences in matrix_two.
The code in the acc_partition project performs the same matrix addition/subtraction as in the host_partition project, but with important differences. First, the task descriptor tells the ALF runtime that data partitioning is performed on the accelerator. This is accomplished with the following line:
alf_task_desc_set_int32(td_handle, ALF_TASK_DESC_PARTITION_ON_ACCEL, 1);
Each accelerator creates its own DTLs in acc_matrix, so each work block needs to know which matrix values it will be processing. The host provides this information within the parameter context. In acc_matrix, this is a struct composed of three matrix addresses and the number of floats that each block needs to process. The following code shows how the host creates and enqueues these work blocks:
/* creating wb and adding param & io buffer */
param_ctx.num_floats = num_floats;
for (i=0; i<N; i+=N/NUM_BLOCKS) {
/* Create the work block */
alf_wb_create(task_handle, ALF_WB_SINGLE, 0, &wb_handle);
/* Configure and add parameter to the work block */
param_ctx.matrix_one = (unsigned long long)&matrix_one[i][0];
param_ctx.matrix_two = (unsigned long long)&matrix_two[i][0];
param_ctx.matrix_three = (unsigned long long)&matrix_three[i][0];
alf_wb_parm_add(wb_handle, (void *)(¶m_ctx),
sizeof(param_ctx), ALF_DATA_BYTE, 0);
/* Enqueue the work block in the task */
alf_wb_enqueue(wb_handle);
}On the accelerator, the kernel function is the same as in the host_partition code. The difference is that there are two new functions: create_in_dtl and create_out_dtl. create_in_dtl builds the DTLs that transfer matrix_one, and matrix_two data from host memory into accelerator memory. create_out_dtl builds the DTL that transfers matrix_three data from accelerator memory into host memory.
The code for create_in_dtl is as follows:
int create_in_dtl(void *task_ctx,
void *param_ctx,
void *dtl,
unsigned int current_count,
unsigned int total_count)
{
/* Access the parameter context */
ctx_struct* ctx = (ctx_struct *) param_ctx;
/* Create input DTL for matrix_one */
ALF_ACCEL_DTL_BEGIN(dtl, ALF_BUF_IN, 0);
ALF_ACCEL_DTL_ENTRY_ADD(dtl, ctx->num_floats,
ALF_DATA_FLOAT, ctx->matrix_one);
ALF_ACCEL_DTL_END(dtl);
/* Create inout DTL for matrix_two */
ALF_ACCEL_DTL_BEGIN(dtl, ALF_BUF_OVL_INOUT, 0);
ALF_ACCEL_DTL_ENTRY_ADD(dtl, ctx->num_floats,
ALF_DATA_FLOAT, ctx->matrix_two);
ALF_ACCEL_DTL_END(dtl);
return 0;
}The code for create_out_dtl is similar, but there’s an important point to remember. The accelerator creates a separate output DTL for matrix_three, which holds the summed results. However, it doesn’t create an output DTL for matrix_two, which holds the differences. This is because matrix_two has been placed in the inout buffer. The contents of this buffer are automatically transferred to host memory when the computational kernel function completes.
Two aspects of ALF remain to be covered. The first aspect creates dependencies between tasks. The concept is simple: One task can start only when a second task finishes. This can be important when you need to create a sequence of tasks.
The second aspect involves task events. With event handling, the host can perform additional processing when tasks are created or when task instances finish executing on an accelerator. This is similar to libspe event handling, but the events deal with tasks and task instances rather than SPU execution.
The ALF API provides the alf_task_depends_on function to ensure that one task starts only when a second finishes. For example, if task1, task2, and task3 should be performed in strict sequence, you’d use the following code:
alf_task_depends_on (task2, task1); alf_task_depends_on (task3, task2);
The first line makes task2 dependent on task1, and the second makes task3 dependent on task2. If alf_task_wait(task3) is called, the ALF runtime waits for task1, task2, and task3 to finish in order. Note that alf_task_depends_on must be called after the tasks are created but before any of their work blocks are enqueued.
It’s important to understand that this capability can create task sequences, but not task pipelining. The difference is that, in a multistage pipeline, each stage needs to repeat itself after finishing. But ALF provides no way to make a task dependent on itself, and no way to make the work blocks of a task dependent on the work blocks of another task.
Chapter 7 explains how libspe makes it possible to handle SPU events in PPU code: Create an event handler, create events, and then register the events with the handler. Handling events in ALF is even simpler. The alf_task_event_handler_register function matches an event-handling function to an event type and a task. When the task produces the specified event, the ALF runtime invokes the event handler. alf_task_event_handler_register accepts five parameters:
alf_task_handle_t: The task handleint (*task_event_handler)(params): Pointer to the handler functionvoid*: Pointer to supplemental dataunsigned int: Size of the supplemental dataunsigned int: Event type (ALF_TASK_EVENT_TYPE_T)
The event-handling function pointed to by the second parameter is called when an event of the appropriate type occurs. An event handler must have a specific signature:
int task_event_handler(alf_task_handle_t task_handle, ALF_TASK_EVENT_TYPE_T event, void* p_data)The first parameter is the handle to the task being monitored, and the third parameter points to supplemental data supplied in alf_task_event_handler_register. The second parameter identifies what type of event or events the handler responds to. This event mask can take the values listed in Table C.7.
Table C.7. ALF Event types (ALF_TASK_EVENT_TYPE_T)
Event Type | Processing Event |
|---|---|
| Task configuration has completed. |
| The task is ready to be scheduled for execution. |
| A task instance begins executing on an accelerator. |
| One instance of the task has finished. |
| The last work block in the task has completed operation. |
| The task is destroyed. |
It’s important to see the distinction between a finalized task and a finished task. A task is finalized when all work blocks have been enqueued and no further alteration is possible. It is finished when all of its work blocks have completed their execution on the accelerators. These events deal with the status of tasks and work blocks, not the status of the accelerators.
As an example, let’s say function handler should be called just before a task (task_handle) is ready to be executed. No supplemental data is needed. First, you’d register the event handler with the following:
alf_task_event_handler_register(task_handle, &handler, NULL, 0, ALF_TASK_EVENT_READY);
Then you’d write code for handler, whose signature should be similar to this:
int handler(alf_task_handle_t task_handle, unsigned int event, void* data)
A task’s event handler must be registered before the task is finalized. In the alf_events project, alf_task_event_handler_register is called immediately after the task is created. It tells the ALF runtime that the example_handler function should be called if any of the ALF_TASK_EVENT_FINALIZED, ALF_TASK_EVENT_READY, or ALF_TASK_EVENT_FINISHED events occur.
When example_handler is invoked, it displays output depending on which event has fired. This is shown in the following code:
int example_handler(alf_task_handle_t tk_handle, unsigned int event, void* data) {
/* select event type and respond */
switch(event) {
case ALF_TASK_EVENT_FINALIZED:
printf("The task is finalized.
"); break;
case ALF_TASK_EVENT_READY:
printf("The task is ready.
"); break;
case ALF_TASK_EVENT_FINISHED:
printf("The task is finished.
"); break;
default:
printf("Invalid event.
");
}
return 0;
}The ALF runtime calls the event handler after each of the three events, and then returns to regular processing.
The ALF learning curve is steep. Besides the new concepts involved, such as tasks, work blocks, task/parameter contexts, and DTLs, there’s a wide number of functions for both host and accelerator coding. But I hope this chapter has shown that the benefits of using ALF justify the investment of time and effort.
First of all, ALF is a godsend for those of us building applications that require complex buffering and multiprocessor communication. It’s so much easier to create DTLs than regular DMA lists. DMA lists need tags, list element structures, and buffer arrays, whereas DTLs need only a host memory address and a buffer type. And with DTLs, you don’t have to worry as much about combining communication and multibuffering; once you configure a DTL to use a specific buffer type, the ALF runtime handles the rest for you.
ALF’s memory management is another incredible benefit. With ALF, after you’ve (accurately) set the maximum size of the buffers you intend to use, you don’t have to worry about mallocs or alignment or whether a given array will be overwritten by the stack. When you’ve configured a buffer for input, output, or inout operation, you can worry more about processing data than about moving it from place to place.
Last but not least, it’s much simpler to manage SPUs with ALF than it is with libspe. When you use libspe, you have to create and coordinate SPU threads on your own. ALF not only makes threads unnecessary, it provides a great deal more flexibility in assigning computational tasks to the SPUs. With libspe, the most you can do is load program handles into contexts and run the contexts. ALF makes it possible for applications to dynamically assign work blocks to SPUs, and you control the processing of each block and how data is transferred in and out.