
At a high level, this book is just a collection of instructions and recipes for converting human-readable text files into binary executables. This conversion process, called building, is the subject of this chapter. The discussion focuses on two topics:
The SDK tools (
ppu-gcc,spu-gcc,ppu-as,spu-as, etc.) that perform the build processThe makefiles that direct how the build should be performed
If you’re already familiar with the GNU Compiler Collection (GCC) and its tools, you may only want to skim this chapter. ppu-gcc and spu-gcc have the same options as regular GCC tools and are used in the same way. There’s also nothing new about the makefiles used to build Cell applications.
If you’re unacquainted with GCC or you’ve forgotten how to use it, however, follow this chapter closely. The build process for the Cell isn’t hard to understand, but there’s nothing more annoying than a mysterious ld error or misplaced library. It’s better to spend time now learning the tools than to lose time later debugging errors.
Most of the components in the Cell Software Development Kit (SDK) were created by IBM, but the basic build tools were developed by Sony. Wisely, Sony chose to base its tools on the GCC. The GCC toolchain has gained legions of developers since its release more than 20 years ago, and it’s easy to see why: It supports a broad number of processors, it’s released under the GNU Public License, and its compiling standards are as high as they come.
GCC tools have been ported to run on over 50 different processor architectures. This book is concerned with only two: the PowerPC Processor Unit (PPU) and Synergistic Processor Unit (SPU). The PPU and SPU both reside on the Cell but have different instruction sets. That is, an application compiled to run on the PPU will not be able to run on the SPU, and vice versa. For this reason, the SDK provides separate sets of tools for both architectures. This chapter discusses both sets in detail.
The eight SPUs perform the brunt of the Cell’s computation, but we can only interact with the Cell through its PPU. Therefore, this section describes the PPU development tools first and the SPU tools second. Both are based are on GCC, so the difference between the two isn’t significant.
This book generally presents material using an explanation-demonstration approach. That is, concepts are explained first and then demonstrated with example code. This works well for theory-oriented topics such as matrices and frequency transforms, but when it comes to detail-oriented topics such as GCC usage, the reverse approach is better: Start with a working example and then explain why the example works. This way, the meaning and importance of the details become clear at the start.
The example code for this book is divided into directories named after chapters. Each chapter directory is divided into project directories. A project is a set of files that combine to produce a single application. In the Chapter3 directory, ppu_project contains a source file called a.c and a directory called head_dir. a.c is a simple C source file, and its code is presented in Listing 3.1.
This source file displays the values of x and y, but doesn’t declare either. These variables are declared and initialized in header files x.h and y.h, both located in head_dir. Listings 3.2 and 3.3 show the code of both header files.
The goal of this example is to convert these three files into a single executable called a. From a developer’s standpoint, this can be performed in three ways:
The long way: Execute ppu-cpp, ppu-gcc, ppu-as, and ppu-ld as separate executables.
The short way: Execute all the executables simultaneously with
ppu-gcc.The right way: Execute the
makecommand, which executes commands listed in a makefile.
Most of this book will use make to build applications, but the long way is the most instructive and is the subject of this discussion.
Note
On a Cell-based system, the GCC executables are located in /usr/bin. On an x86-based system, the GCC executables are placed in /opt/cell/toolchain.
Figure 3.1 depicts the four steps of the PPU build process. For each operation, the text on the left shows the command to be executed, and the text on the right explains what the command accomplishes.
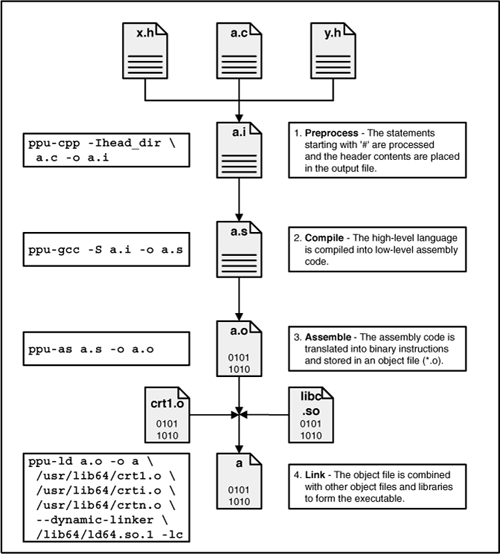
Let’s look more closely that the stages that form the development process: preprocessing, compiling, assembling, and linking.
Preprocessing is the first and simplest of the four steps. At this stage, only the lines of code starting with the pound sign (#) matter. The statements on these lines are called directives, and the most common C directives are #define and #include. When the preprocessor encounters #define followed by an identifier and replacement text, it substitutes the replacement text wherever the identifier is found. For example, if the directive is
#define NUM_ROWS 64
the preprocessor will substitute 64 wherever NUM_ROWS appears in code.
The most common directive is #include. When this directive precedes the name of a header file, the preprocessor inserts the contents of the header file into the source code. To see how this works, change to the directory containing a.c and execute the following command:
ppu-cpp -Ihead_dir a.c -o a.i
ppu-cpp is the C preprocessor for PPU code. The -o option tells it to place its output in a file called a.i. This file contains the original source code of a.c and the contents of stdio.h, x.h, and y.h.
There are three #include directives in a.c. The first surrounds the header name, stdio.h, in angular brackets, <>. This identifies stdio.h as a system header file, and by default, ppu-cpp will look through /usr/local/include, /usr/include, and /usr/lib/gcc/ppu/x.y.z/include to find it.
The x.h and y.h headers are placed inside double quotes, so by default, ppu-cpp searches only the current directory. If ppu-cpp is called with -I followed by a directory name, that directory will be included in the search. In this case, ppu-cpp is executed with -Ihead_dir, so the preprocessor will find x.h and y.h in the local head_dir directory.
The build process usually removes any files created during this stage, so you probably won’t see *.i/*.ii files in your day-to-day builds. But when you encounter bugs related to headers and #define macros, you may find it helpful to look through the preprocessor results.
After ppu-cpp finishes preprocessing, ppu-gcc compiles the result. Code compilation is a complex subject and lies beyond the scope of this book, but put simply, the compile operation analyzes the structure of the source code and translates its high-level, machine-independent instructions into low-level, processor-specific instructions. These instructions are part of the processor’s assembly language.
To see what the PPU’s assembly language looks like, enter the following command:
ppu-gcc -S a.i -o a.s
The -S option tells ppu-gcc to compile the code in a.i and perform no further steps. The -o option tells ppu-gcc to place its assembly output in a.s. If the compiler finds errors in the code structure, it will not produce a.s, but will direct error messages to the console.
If you look at the content of a.s, you’ll see a series of barely readable instructions like ld and std, followed by numbers and punctuation. Chapter 15, “SPU Assembly Language,” explains how to write assembly for the SPUs, but the rest of this book is only concerned with coding in C/C++.
Configurability is one of GCC’s chief advantages. There are many ways to tweak and constrain ppu-gcc’s operation, and Table 3.1 lists 12 of the most popular options. Most are identified by a hyphen and a letter, such as -S in the preceding example. You can see the full list of options by running man ppu-gcc.
Table 3.1. Common Compile Options for ppu-gcc
Option | Purpose |
|---|---|
| Store output in filename |
| Produce extra debugging information |
| Optimize compilation at the nth level, where n ranges from 0 to 3 |
| Set the C/C++ language standard |
| Suppress warnings |
| Provide additional warnings during compilation |
| Preprocess file, but do not compile |
| Compile, but do not assemble |
| Compile and assemble, but do not link |
| Display all commands performed during compile |
| Enable built-in GCC functions for AltiVec |
| Disable built-in GCC functions for AltiVec |
Debugging is the topic of the next chapter, but you should know that -g tells the compiler to insert debug information into the compiled result. Further, it ensures that each line of code is compiled separately. This way, you can step through the application and see the effect of each individual line of code.
When you optimize compilation with -On, you not only remove the debug information, you also tell the compiler to rearrange statements to improve performance and reduce code size. The optimization level, n, ranges from 0 to 3. The default setting is -O0, which performs no optimization at all. Higher-level optimization tasks include the following:
-Oor-O1:Merge identical constants, attempt to remove branches, optimize jumping-O2:Align loops, functions, and variables, remove null-pointer checks, reorder instructions-O3:Inline simple functions, rename registers, parse all source before compiling code
Each optimization level performs all the tasks of lower levels. Greater optimization produces faster, smaller executables, but takes more time. An IBM engineer once told me that his team uses -g for applications they intend to debug and -O3 for everything else.
The -std=standard option is useful if your code needs to meet a specific code standard. Example values include ansi, c99, and c++98. The gnu98 standard is used by default for C code, and gnu++98 is used for C++. You can suppress compiler warnings with -w, but it’s better to use -Wall, which tells ppu-gcc to generate a warning for any questionable aspect of code.
By default, ppu-gcc doesn’t just compile; it calls all the executables in the build process, from ppu-cpp to ppu-ld. In this example, the -S option tells ppu-gcc to compile, but not assemble, the code in a.i. The -c option compiles and assembles the code, but doesn’t call the linker. The -v option tells ppu-gcc to list all the commands it executes as it runs.
The last two compiler options are specific to PowerPC devices, which includes the PPU (PowerPC Processor Unit). The PPU supports AltiVec instructions for vector processing, and ppu-gcc has built-in functions for dealing with these instructions. The -maltivec option enables these built-in functions and -mno-altivec disables them. Chapter 8, “SIMD Programming on the PPU, Part 1: Vector Libraries and Functions,” discusses AltiVec coding in detail.
After the high-level code is converted into assembly instructions, the assembler translates the textual assembly code into binary machine instructions. The assembler output is placed in an object file, *.o. These object files are formatted according to the ELF (Executable and Linking Format), which is the subject of Appendix A, “Understanding ELF Files.” To create an object file from a.s, enter the following:
ppu-as a.s -o a.o
It’s much simpler to assemble code than compile it, and there are fewer options available to configure the assembly. There are no optimization levels, although -o still identifies the output file. If you enter man ppu-as, you’ll see that most of the options deal with low-level details like bit ordering and instruction set extensions. None of the example code in this book configures or constrains the operation of ppu-as.
The final stage of the build process is linking, and though you’ll rarely call the linker directly, it’s important to know what it does. ppu-ld performs two main tasks: It searches for the object code needed to construct the output file, and it either links the objects together or makes sure they can be linked together during execution.
In the example project, ppu-ld can’t create an executable with a.o alone. To see why, enter nm a.o on the command line. This command lists the symbols in a.o, and the output will look like the following:
0000 D main
U printf
0000 D x
0004 D yThe U next to printf stands for Undefined, and if you attempt to create an executable with
ppu-ld a.o -o a
you’ll receive an error because of the undefined printf reference. You’ll also receive a warning because ppu-ld can’t find the symbol (_start) that identifies where the application should start in memory.
To handle these problems, three steps need to be performed:
Link against the C library.
printfis defined in the C library, libc.so, so this library must be included in the link. To do this, use-lfollowed by the library’s abbreviated name. The abbreviated name is formed by removing lib from the start of the library name and the suffix from the end. The abbreviated name of libc.so is just c, so the required option is-lc.Identify the dynamic linker. libc.so is a dynamic library, which means its functions are linked at runtime. The dynamic linker, /lib64/ld64.so.1, handles this operation, so it must be identified with
—dynamic-linker /lib64/ld64.so.1.Link initialization files.
ppu-ldneeds special code to launch PPU applications, and this can be found in three standard initialization files: /usr/lib64/crt1.o, /usr/lib64/crti.o, and /usr/lib64/crtn.o.
Now the executable can be created with the following link command:
ppu-ld a.o /usr/lib64/crt1.o /usr/lib64/crti.o /usr/lib64/crtn.o
—dynamic-linker /lib64/ld64.so.1 -lc -o aTo run the executable, enter ./a at the command line. This displays the values of the x and y variables, declared in x.h and y.h, respectively.
By default, ppu-ld searches for libraries in /lib64, /usr/lib64, /usr/local/lib64, and /usr/powerpc-64/lib64. It looks for shared libraries (*.so) first and static libraries (*.a) second. To add another location to its search path, use -L followed by the directory name. You can also name search directories with the environment variable, LD_LIBRARY_PATH. Much of this book focuses on the SDK libraries, so it’s important to know how to identify them for the linker.
Table 3.2 lists a portion of the options available for ppu-ld. To see the full list, enter man ppu-ld at the command line.
Table 3.2. Common Link Options for ppu-ld
Option | Purpose |
|---|---|
| Link against library file named libname.so or libname.a |
| Tell the linker to search through dir to find libraries |
| Send linker output (executable, library) to file |
| Display names of input files as they’re used |
| Display steps performed in the link process |
| Specify file to be used as the dynamic linker |
| Link against static libraries only |
| Create a shared library |
| Identify a library by its shared object name |
The last two options are used when you create library files rather than executables. Appendix A gives a more thorough treatment of how these libraries are created and which linker options are needed. It also describes in detail the sections and segments that make up object files, libraries, and executables.
In the real world, developers don’t call ppu-cpp, ppu-gcc, ppu-as, and ppu-ld separately for each build. It’s much easier to let ppu-gcc manage the entire process by itself. For example, the code in ppu_project can be preprocessed, compiled, assembled, and linked with a single statement:
ppu-gcc -Ihead_dir a.c -o a
This command produces the same result as the four commands in Figure 3.1, but gets rid of the intermediate files (a.i, a.s, a.o). Also, you don’t have to specify the initialization object files (crt1.o, crti.o, and crtn.o) or the C library (libc.so). This is because ppu-gcc already knows the basic settings needed for C/C++ applications. Clearly, this is much more convenient than performing each step of the build separately.
But a complication arises: How do you set options for other tools when you’re only running ppu-gcc? For example, how can you make sure an option is directed to the linker but not the compiler? The answer is simple: Precede assembler options with -Wa and linker options with -Wl. For example, to get the linker version, enter the following:
ppu-gcc -Ihead_dir -Wl,-v a.c -o a
This directs the -v option to ppu-ld. If -Wl is removed, ppu-gcc receives the -v option and prints every step of its build process in addition to the linker version.
It’s much more convenient to enter one command rather than four, but even the ppu-gcc command can be a burden. If an application needs multiple libraries and header files from multiple locations, entering the entire ppu-gcc command for each build will quickly become tiresome.
For this reason, developers regularly use make, which executes build commands stored in a special file called a makefile. Makefiles will be described shortly, but first you need to understand how applications are built for the Cell’s Synergistic Processor Units, or SPUs.
In addition to the PPU tools, the SDK provides a set of similarly named tools for the SPU. These are spu-cpp, spu-gcc, spu-as, and spu-ld. Change to the spu-project directory in Chapter3, and you’ll find the same files as were in ppu-project.
There’s more to the similarity than just the names; the SPU tools function just like their PPU counterparts. To see what I mean, preprocess a.c with
spu-cpp -Ihead_dir a.c -o a.i
Then compile the result with
spu-gcc -S a.i -o a.s
and assemble the code with
spu-as a.s -o a.o
The SPU link operation is slightly different from that for the PPU. First, crt1.o, crti.o, and crtn.o are in /usr/spu/lib rather than /usr/lib64. Second, the link requires two libraries: libc.a (-lc) and libgloss.a (-lgloss), both in /usr/spu/lib. These libraries are mutually dependent, so their flags, -lc and -lgloss, must be surrounded by —start-group and —end-group. The complete link command is
spu-ld a.o /usr/spu/lib/crt1.o /usr/spu/lib/crti.o /usr/spu/lib/crtn.o
-o a -L/usr/spu/lib --start-group -lc -lgloss --end-groupThe entire build can also be performed with a single call to spu-gcc:
spu-gcc -Ihead_dir a.c -o a
If you enter this command, you’ll see an executable that looks exactly like the PPU executable. But the two files are really quite different. The SPU application doesn’t really execute independently; the PPU starts the SPU, sends the application to the SPU, receives the SPU’s output, and terminates the SPU’s operation. PPU/SPU interaction is an involved topic, and we’ll leave that until Chapter 7, “The SPE Runtime Management Library (libspe).”
The basic concept behind make and makefiles is simple. The make command looks for a file called Makefile in the current directory. If Makefile exists, make reads its commands and executes them. This provides many important advantages over entering commands on the command line:
A build command needs to be typed only once (inside the makefile).
Once the makefile is created, users don’t need to think about how the application is built.
Build commands can be modified and extended with small changes to the makefile instead of retyping the entire command.
Makefiles can be generalized to build different types of applications in different languages and environments, and can perform nonbuild activities such as installing and archiving.
Makefiles can be organized in a hierarchy in which a master makefile contains all possible build commands and dependent makefiles specify which commands should be run.
Let’s start with a demonstration. Log on to the Cell system and install the netpbm image manipulation library:
yum install netpbm netpbm-devel
Next, go to the /opt/cell/sdk/src directory and look at the group of compressed TAR (tape archive) files. Decompress the archives with
cat *.tar | tar xvi
A series of directories will be created, each containing example code. From within the /opt/cell/sdk/src directory, execute
make
When make starts, it finds Makefile in the current directory and executes its commands. In this case, Makefile does little except call the commands in the master file make.footer, located in /opt/cell/sdk/buildutils. All the makefiles in the SDK rely on make.footer, so it’s a good idea to glance at its contents.
If the content of make.footer looks familiar, you can skip the rest of this section. But if you’ve never seen anything like make.footer before, pay close attention; all the example code in this book requires a solid understanding of make and makefiles. Besides, once you start creating makefiles, you’ll never go back to the command line.
This section presents makefiles as they should be presented: from the simple to complex. Simple makefiles are good for specific builds, but as you incorporate more advanced features, your makefiles will be more flexible and better suited for general-purpose development.
Makefiles differ widely depending on the writer and purpose, but most consist of four types of statements:
Dependency lines: Lines that identify a file to be created (target) and the files needed for its creation (dependencies)
Shell lines: Contain the commands that build a target from its dependencies
Variable declarations: Text substitution statements that function like
#definedirectives in C/C++Comments: Lines that start with
#and provide additional information
This subsection describes each of these statements and then presents an example makefile that incorporates all of them.
When make examines the content of a makefile, it looks for two pieces of information: the name of the file it should build and the names of the files needed to build it. The file to be built is called the target, and the files needed to build the target are called dependencies.
A makefile provides this information with dependency lines. A dependency line contains the target name, a colon, and names of dependencies separated by spaces. Its basic syntax is given by
target: dependency1 dependency2 ...
For example, if you want make to build an application called app using source files src1.c, src2.c, and src3.c, the dependency line is
app: src1.c src2.c src3.c
If the target file already exists, make checks to see when the target and dependency files were last modified. If one of the dependencies is more recent than the target, make rebuilds the target. If the target is up-to-date, make takes no action.
When make is called with no arguments, it processes the first dependency line in the makefile. But if make is called with the name of a target, such as in the command make target_name, make searches for a dependency line whose target is target_name.
If a dependency can’t be found, make searches for a rule that builds the missing dependency. This way, dependency lines can be chained together and processed recursively. For example, the previous section showed how a.i is created from a.c, how a.s is created from a.i, and how a.o is created from a.s. These relationships are identified with the following dependency lines:
a.o: a.s a.s: a.i a.i: a.c
make attempts to process the first line, but when it can’t find a.s, it searches for a line whose target is a.s. The second line has a.s as a target, so make looks for its dependency a.i. a.i isn’t available either, so make tries to process the third line, in which a.i is a target. When make finds a.c, it builds a.i and uses a.i to build a.s. Finally, make uses a.s to build the original target, a.o.
Target and dependency files can be of any type: source code or object code, text or binary. All that matters is that make knows what to build and what files it needs to build it. But dependency lines don’t specify how the target should be built. For this, you need to add shell lines.
Shell lines tell make what steps to perform when building the target identified in the preceding dependency line. Shell lines contain the same type of commands as those you’d enter on a command line. In a makefile, shell lines follow dependency lines and each shell line must start with a tab.
The syntax is given by
target: dependency1 dependency2 ... command1 command2 ...
The combination of a dependency line and its following shell lines is called a rule. A complete rule tells make what target to build, what files are necessary, and what commands must be processed to build the target.
As a simple example, the previous section explained how to create the executable a with a single ppu-gcc command. In a makefile, this would be identified with the following rule:
a: a.c
ppu-gcc -Ihead_dir a.c -o aEach rule can have multiple shell lines, and the commands don’t have to take part in building the target. For example, the following rule tells make to print the working directory (pwd) before executing ppu-gcc and list the contents of the current directory (ls) afterward.
a: a.c
pwd
ppu-gcc -Ihead_dir a.c -o a
lsmake processes shell lines from top to bottom. By default, it prints each shell line as it processes it.
Before leaving this topic, one point needs to be emphasized: Start each shell line with a tab, not spaces. If you use anything other than a single tab, make will give you an incomprehensible error like the following:
*** missing separator. Stop.
You deserve better, so precede each shell command with one tab.
Variables and comments make it easier to modify and read makefiles. A makefile variable is an identifier that represents text, and these identifiers commonly consist of capital letters. Each variable declaration has the form X=Y, and wherever make encounters $(X) in the makefile, it replaces the reference with its corresponding text, Y.
Let’s say your makefile contains the following rules:
long_file_name: long_file_name.c other_file_name.o
ppu-gcc long_file_name.c other_file_name.o -o long_file_name
other_file_name.o: other_file_name.c
ppu-gcc -c other_file_name.c -o other_file_name.oYou can make this more readable by replacing each occurrence of long_file_name with $(LONG) and each occurrence of other_file_name with $(OTHER). This is done using variables, as shown in the following lines:
LONG=long_file_name
OTHER=other_file_name
$(LONG): $(LONG).c $(OTHER).o
ppu-gcc $(LONG).c $(OTHER).o -o $(LONG)
$(OTHER).o: $(OTHER).c
ppu-gcc -c $(OTHER).c -o $(OTHER).oThis variable usage does more than just increase readability. If a file’s name changes, you don’t have to modify every occurrence of its name. You just need to alter the variable declaration, and the modification will propagate throughout the file.
Makefile comments are even simpler to understand than variables. Each comment starts with a #, and the comment continues until the end of the line. This works like the C++ comment marker //. The following lines show how comments work:
CFLAGS=-O3 -Wall -v # Define the build options
PCC=ppu-gcc # Identify the build tool
# Build the output executable from input.c
output: input.c
$(PCC) $(CFLAGS) input.c -o outputMakefile syntax can be hard to read and easy to forget, so it’s a good idea to insert comments regularly. This is particularly important for large projects that require a hierarchy of makefiles.
Now that you have a basic understanding of how makefiles are written, it’s time for a simple example. The Chapter3 directory has a make_basic folder that holds the same source files as were in the ppu_project folder. It also contains the makefile presented in Listing 3.4.
Example 3.4. Basic Makefile: Makefile
# Declare variables
FILE=a
PCC=ppu-gcc
SCC=spu-gcc
HDIR=./head_dir
# Tell make to build both applications
all: ppu_$(FILE) spu_$(FILE)
# Build the PPU executable
ppu_$(FILE): $(FILE).c
$(PCC) -I$(HDIR) $(FILE).c -o ppu_$(FILE)
# Build the SPU executable
spu_$(FILE): $(FILE).c
$(SCC) -I$(HDIR) $(FILE).c -o spu_$(FILE)When you execute make, it calls ppu-gcc and spu-gcc and builds two executables: ppu_a and spu_a. Most of this makefile is straightforward, and it uses the same rules, macros, and comments as discussed earlier. But the first rule may seem odd: The target, all, isn’t a file. Even stranger, the first rule has no shell commands. This is because all is a phony target. Phony targets and other makefile aspects are discussed next.
Variables make life easier, but there are three other features that make constructing makefiles even more convenient:
Phony targets—. Targets that don’t represent actual files
Automatic variables—. Makefile variables with predefined meanings
Pattern rules—. Rules for building files based on filename patterns
This subsection explains each of these techniques and concludes with an advanced makefile example. Once you understand how these features work, you’ll have no problem grasping the makefiles in this book’s example code.
A phony target is a target that doesn’t represent an actual file. They are generally used in two situations:
To build multiple, unrelated targets with a single call to
makeTo execute commands that don’t involve building a real target
In the first usage, the phony target has multiple dependencies but no shell lines. In the second usage, the phony target has one or more shell lines, but no dependencies.
The makefile in Listing 3.4 contains the following dependency line:
all: ppu_$(FILE) spu_$(FILE)
make won’t find either of the dependencies at first, so it has to build both files as targets. With dependency lines like this, one call to make can build multiple independent targets. all is the common name for this kind of phony target, but the name isn’t important; what’s important is that the phony target is the first target in the makefile.
make is usually used to perform build tasks, but phony targets make it easy to execute unrelated commands. These targets are commonly used to remove intermediate files generated during the build process. The following rule shows how this works:
clean:
echo Remove object/assembly files
rm *.o *.sWhen make clean is executed, make will process both shell lines and remove object and assembly files in the current directory. The clean target has no dependencies because it’s not meant to be built.
In this case, a problem arises if make finds an existing file called clean; it may decide clean is up to date and not execute the target’s associated commands. For this reason, it’s a good idea to formally identify phony targets as phony. This is done by making them dependencies of a target called .PHONY. This is best explained with an example:
.PHONY: clean
clean:
echo Remove object/assembly files
rm *.o *.sThe first rule tells make that clean is a phony target. When make clean is called, make will process the shell lines without checking to see whether a file called clean exists.
When you write shell lines in a makefile, you can use predefined variables whose text depends on the rule’s target and dependencies. Table 3.3 lists each of these variables and the information they hold.
Table 3.3. Makefile Automatic Variables
Automatic Variable | Information |
|---|---|
| The name of the rule’s target |
| Name of the target, which is a member of an archive |
| Names of all dependencies, separated by spaces |
| The name of the first dependency<$I$< variable> |
| Names of all dependencies newer than the target |
| Names of all dependencies with duplicates in proper order |
Of these, the $@ and $^ variables are the most commonly used because they take away the need to rewrite names of targets and dependency files. For example, if a makefile rule is given as
foo: foo.c bar.o baz.o
$(CC) foo.c bar.o baz.o -o fooit can be replaced by
foo: foo.c bar.o baz.o
$(CC) $^ -o $@which is harder to read but easier to type. It also makes the makefile more portable, especially if the target and dependency names are also variables. This construction is used throughout the makefiles in this book’s example code.
The text representation of an automatic variable is recomputed for each rule processed, so the value of $@ changes from rule to rule. Automatic variables can only be used in the shell lines, not in the dependency lines above them.
Pattern rules are like regular rules, but the target is identified by a pattern, not a specific file. Makefile patterns use % as a wildcard, usually followed by a file suffix. For example, the pattern %.c refers to any file with the .c suffix. The following pattern rule compiles all C source files into object files with the same name (but different suffixes):
%.o: %.c
$(CC) $^ -o $@This pattern is used so frequently that you don’t need to enter it. That is, make knows that object files are created by compiling source files (.c, .cpp) with similar names. For example, an executable named app depends on foo.o and bar.o, and these object files are compiled from foo.c and bar.c. The corresponding rule might look like the following:
OBJS=foo.o bar.o
app: $(OBJS)
$(CC) $^ -o $@Notice that this rule doesn’t tell the compiler how to build foo.o and bar.o. It doesn’t have to. make will use the default compiler, named by the CC variable, to compile the source files in the current directory. To disable built-in rules, run make with the -r option.
The Chapter3 directory has a folder called make_adv, which contains the same files as those in make_basic. The difference is that the makefile in make_adv uses two phony targets, all and clean, and its shell lines are constructed with automatic variables.
Example 3.5. Advanced Makefile: Makefile
# Create variables
FILE=a
PCC=ppu-gcc
SCC=spu-gcc
# Tell make to build both applications
all: ppu_$(FILE) spu_$(FILE)
# Build the PPU executable
ppu_$(FILE): $(FILE).o
$(PCC) $^ -o $
# Build the SPU executable
spu_$(FILE): $(FILE).c
$(SCC) $^ -o $
.PHONY: clean
clean:
rm *.oThe first real dependency line identifies the object file a.o as a dependency, but this file isn’t in the current directory. Thanks to built-in pattern rules, make compiles the source file a.c into a.o automatically. make uses ppu-gcc to compile because the CC variable is set to ppu-gcc.
The clean target is identified as phony with the following dependency line:
.PHONY: clean
To remove object files after the build, enter make clean.
There are many more aspects of makefiles to explore, such as makefile directives and response files. In fact, the Free Software Foundation (FSF) development process generates makefiles automatically with its Autotools suite (automake, autoconf, libtool). But the features presented in this brief treatment will suffice for most of the Cell development tasks you encounter.
Normally, learning how to program two different processors with two different sets of tools is a difficult process. But PPU and SPU applications can be built with similar GCC-based tools, so the difficulty is significantly reduced. This chapter has described the operation of both toolsets, and if any topic wasn’t covered thoroughly, there’s plenty of freely available information about GCC available on the web.
The first part of this chapter explained each tool in the PPU development chain, from ppu-cpp to ppu-ld. This level of detail is unnecessary for practical usage, and you’ll probably never use anything besides ppu-gcc. However, compile and linking errors crop up constantly, especially when you’re building large applications with far-flung source files and libraries. When they do, you’ll be better able to understand the problems if you understand the tools.
The second part of this chapter explains the make command and makefiles. The makefile language is unintuitive and unlike any other, so writing these files may seem unwieldy at first. But once your build process consists of a single word (i.e., make), you’ll be glad you chose to place your commands in makefiles rather than the command line.