
7
Interprocess Communication Primitives in POSIX/Linux
CONTENTS
7.2 Interprocess Communication among Threads
7.2.1 Mutexes and Condition Variables
Chapters 5 and 6 have introduced the basic concepts of interprocess communication, called IPC in the following text. These mechanisms are implemented by operating systems to allow the correct execution of processes. Different operating systems define different IPC interfaces, often making the porting of applications to different platforms a hard task (Chapter 19 will address this issue). In this chapter, the interprocess communication primitives are presented for the Linux operating system, for which the Application Programming Interface (API)has been standardized in POSIX. POSIX, which stands for “Portable Operating System Interface [for Unix],” is a family of standards specified by the IEEE to define common APIs along variants of the Unix operating system, including Linux. Until recently, the POSIX API was regulated by IEEE Standard 1003.1 [42]. It was later replaced by the joint ISO/IEC/IEEE Standard 9945 [48].
In the following sections we shall see how semaphores, message queues, and other interprocess communication mechanisms are presented in Linux under two different contexts: process and thread. This is a fundamental distinction that has many implications in the way IPC is programmed and that may heavily affect performance. The first section of this chapter will describe in detail what the differences are between the two configurations, as well as the pros and cons of each solution. The following two sections will present the interprocess mechanisms for Linux threads and processes and the last section will then introduce some Linux primitives for the management of clocks and timers, an important aspect when developing programs that interact with the outside world in embedded applications.
7.1 Threads and Processes
Chapter 3 introduced the concept of process, which can be considered an independent flow of execution for a program. The operating system is able to manage multiple processes, that is, the concurrent execution of multiple programs, even if the underlying computer has a single processor. The management of multiple processes on a single processor computer relies on two main facts:
A program does not always require the processor: we have seen in Chapter 2 that, when performing an I/O operation, the processor must await the termination of the data transfer between the device and memory. In the meantime, the operating system can assign the processor to another process that is ready for computation.
Even in the case where a program does not make I/O operations, not releasing the processor, the operating system can decide to reclaim the processor and assign it to another ready program in order to guarantee the fair execution of the active processes.
The Scheduler is the component of the operating system that supervises the assignment of the processor to processes. Chapter 12 will describe in detail the various scheduling algorithms that represent a very important aspect of the system behavior since it determines how the computer reacts to external events. The transfer of processor ownership is called Context Switch, and we have already seen in Chapter 3 that there exists a set of information that needs to be saved/restored every time the processor is moved from one process to another, among which,
The saved value of the processor registers, including
the Program Counter, that is, the address of the next machine instruction to be executed by the program;
the Stack Pointer, that is, the address of the stack in memory containing the local program variables and the arguments of all the active procedures of the program at the time the scheduler reclaimes the processor.
The descriptors of the files and devices currently opened by the program.
The page table content for that program. We have seen in Chapter 2 that, when virtual memory is supported by the system, the memory usage of the program is described by a set of page table entries that specify how virtual addresses are translated into physical addresses. In this case, the context switch changes the memory mapping and avoids the new process overwriting sections of memory used by the previous one.
Process-specific data structures maintained by the operating system to manage the process.
The amount of information to be saved for the process losing the processor and to be restored for the new process can be large, and therefore many processor cycles may be spent at every context switch. Very often, most of the time spent at the context switch is due to saving and restoring the page table since the page table entries describe the possibly large number of memory pages used by the process. For the same reason, creating new processes involves the creation of a large set of data structures.
The above facts are the main reason for a new model of computation represented by threads. Conceptually, threads are not different from processes because both entities provide an independent flow of execution for programs. This means that all the problems, strategies, and solutions for managing concurrent programming apply to processes as well as to threads. There are, however, several important differences due to the amount of information that is saved by the operating system in context switches. Threads, in fact, live in the context of a process and share most process-specific information, in particular memory mapping. This means that the threads that are activated within a given process share the same memory space and the same files and devices. For this reason, threads are sometimes called “lightweight processes.” Figure 7.1 shows on the left the information forming the process context. The memory assigned to the process is divided into
Stack, containing the private (sometimes called also automatic) variables and the arguments of the currently active routines. Normally, a processor register is designated to hold the address of the top of the stack;
Text, containing the machine code of the program being executed. This area is normally only read;
Data, containing the data section of the program. Static C variables and variables declared outside the routine body are maintained in the data section;
Heap, containing the dynamically allocated data structures. Memory allocated by C malloc() routine or by the new operator in C++ belong to the heap section.
In addition to the memory used by the program, the process context is formed by the content of the registers, the descriptors for the open files and devices, and the other operating system structures maintained for that process. On the right of Figure 7.1 the set of information for a process hosting two threads is shown. Note that the Text, Data, and Heap sections are the same for both threads. Only the Stack memory is replicated for each thread, and the thread-specific context is only formed by the register contents. The current content of the processor registers in fact represents a snapshot of the program activity at the time the processor is removed by the scheduler from one thread to be assigned to another one. In particular, the stack pointer register contains the address of the thread-specific stack, and the program counter contains the address of the next instruction to be executed by the program. As the memory-mapping information is shared among the threads belonging to the same process as well as the open files and devices, the set of registers basically represents the only information to be saved in a context switch. Therefore, unless a thread from a different process is activated, the time required for a context switch between threads is much shorter compared to the time required for a context switch among processes.
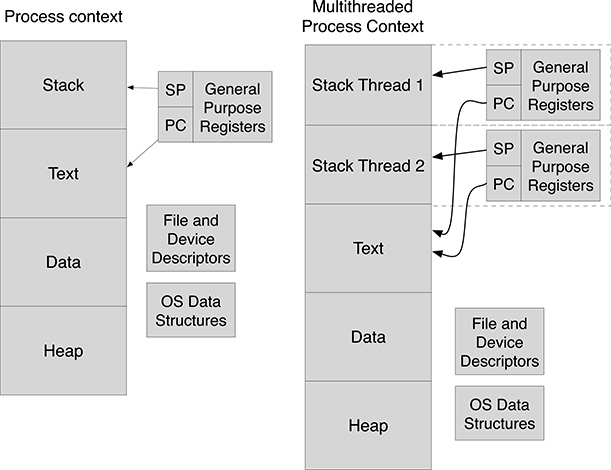
FIGURE 7.1
Process and Thread contexts.
7.1.1 Creating Threads
Historically, hardware vendors have implemented proprietary versions of threads, making it difficult for programmers to develop threaded applications that could be portable across different systems. For this reason, a standardized interface has been specified by the IEEE POSIX 1003.c standard in 1995, and an API for POSIX threads, called Pthreads, is now available on every UNIX system including Linux. The C types and routine prototypes for threads are defined in the pthread.h header file.
The most important routine is:
int pthread_create(thread_t *thread, pthread_attr_t *attr, void *(*start_routine)(void*), void *arg)
which creates and starts a new thread. Its arguments are the following:
thread: the returned identifier of the created thread to be used for subsequent operations. This is of typethread_twhich is opaque, that is, the programmer has no knowledge of its internal structure, this being only meaningful to the pthread routines that receive it as argument.attr: the attributes of the thread. Attributes are represented by the opaque typepthread_attr_t.start_routine: the routine to be executed by the thread.arg: the pointer argument passed to the routine.
All the pthread routines return a status that indicates whether the required action was successful: all functions return 0 on success and a nonzero error code on error. Since the data type for the attribute argument is opaque, it is not possible to define directly its attribute fields, and it is necessary to use specific routines for this purpose. For example, one important attribute of the thread is the size of its stack: if the stack is not large enough, there is the risk that a stack overflow occurs especially when the program is using recursion. To prepare the attribute argument specifying a given stack size, it is necessary first to initialize a pthread_attr_t parameter with default setting and then use specific routines to set the specific attributes. After having been used, the argument should be disposed. For example, the following code snippet initializes a pthread_attr parameter and then sets the stack size to 4 MByte (the default stack size on Linux is normally 1 MByte for 32 bit architectures, and 2 MByte for 64 bit architectures).
pthread_attr_t atrr; //Attribute initialization pthread_attr_init (&attr); //Set stack size to 4 MBytes pthread_attr_setstacksize(&attr, 0x00400000); ... //Use attr in thread creation ... //Dispose attribute parameter pthread_attr_destroy(&attr);
When NULL is passed as the second argument of pthread_create(), the default setting for thread arguments is used: this is the most common case in practice unless specific settings are required.
Only one pointer parameter can be passed to the thread routine. When more than one argument have to be passed, the common practice is to allocate in memory a structure containing all the information to be passed to the routine thread and then to pass the pointer to such structure.
As soon as a thread has been created, it starts execution in parallel with the process, or thread, that called pthread_create(). It is often necessary to synchronize the program with the other threads, making sure that all the created threads have finished their execution before a given point in the code is reached. For example, it is necessary to know when the threads have terminated before starting using the results computed by them. The following routine allows one to wait for the termination of a given thread specified by its thread identifier:
int pthread_join(pthread_t thread, void **value_ptr);
The second argument, when non-NULL, is the pointer to the returned value of the thread. A thread may return a value either when the code terminates with a return statement or when pthread_exit(void *value)is called. The latter is preferable especially when many threads are created and terminated because pthread_exit() frees the internal resources allocated for the thread.
Threads can either terminate spontaneously or be canceled. Extreme care is required when canceling threads because an abrupt termination may lead to inconsistent data, especially when the thread is sharing data structures. Even worse, a thread may be canceled in a critical section: If this happens, no other thread will ever be allowed to enter that section. For this reason, POSIX defines the following routines to handle thread cancelation:
int pthread_setcancelstate(int state, int *oldstate)
void pthread_cleanup_push(void (*routine)(void*), void *arg)
pthread_setcancelstate() enables or disables run time the possibility of canceling the calling thread, depending on the value of the passed state argument which can be either PTHREAD_CANCEL_ENABLE or PTHREAD_CANCEL_DISABLE. The previous cancelability state is returned in oldstate. For example, when entering a critical section, a thread may disable cancelation in order to avoid preventing that critical section to other threads. pthread_cleanup_push() allows registering a routine that is then automatically invoked upon thread cancelation. This represents another way to handle the proper release of the allocated resources in case a thread is canceled. Finally, a thread is canceled by routine:
int pthread_cancel(pthread_t thread)
By means of a proper organization of the code, it is possible to avoid using the above routines for terminating threads. For example, it is possible to let the thread routine periodically check the value of some shared flag indicating the request to kill the thread: whenever the flag becomes true, the thread routine exits, after the proper cleanup actions.
The following code example creates a number of threads to carry out the computation of the sum of all the elements of a very large square matrix. This is achieved by assigning each thread a different portion of the input matrix. After creating all the threads, the main program waits the termination of all of them and makes the final summation of all the partial results reported by the different threads. The code is listed below:
# include <pthread .h>
# include <stdio .h>
# include <stdlib .h>
# include <sys/ time.h>
# define MAX_THREADS 256
# define ROWS 10000
# define COLS 10000
/* Arguments exchanged with threads */
struct argument {
int startRow ;
int nRows ;
long partialSum;
} threadArgs[MAX_THREADS];
/* Matrix pointer : it will be dynamically allocated */
long * bigMatrix;
/* Thread routine : make the summation of all the elements of the
assigned matrix rows */
static void * threadRoutine(void *arg)
{
int i, j;
/* Type-cast passed pointer to expected structure
containing the start row, the number of rows to be summed
and the return sum argument */
struct argument * currArg = (struct argument *) arg;
long sum = 0;
for(i = 0; i < currArg -> nRows ; i++)
for(j = 0; j < COLS; j ++)
sum += bigMatrix[(currArg -> startRow + i) * COLS + j];
currArg -> partialSum = sum;
return NULL ;
}
int main(int argc, char * args [])
{
/* Array of thread identifiers */
pthread_t threads [MAX_THREADS];
long totalSum ;
int i, j, nThreads, rowsPerThread, lastThreadRows;
/* Get the number of threads from command parameter */
if(argc != 2)
{
printf (" Usage : threads <numThreads >
");
exit (0);
}
sscanf (args [1], "%d", & nThreads);
/* Allocate the matrix M * /
bigMatrix = malloc (ROWS* COLS * sizeof (long));
/* Fill the matrix with some values */
...
/* If the number of rows cannot be divided exactly by the number of
threads, let the last thread handle also the remaining rows */
rowsPerThread = ROWS / nThreads ;
if(ROWS % nThreads == 0)
lastThreadRows = rowsPerThread;
else
lastThreadRows = rowsPerThread + ROWS % nThreads ;
/* Prepare arguments for threads * /
for(i = 0; i < nThreads ; i ++)
{
/* Prepare Thread arguments */
threadArgs[i]. startRow = i* rowsPerThread;
if(i == nThreads - 1)
threadArgs[i]. nRows = lastThreadRows;
else
threadArgs[i]. nRows = rowsPerThread;
}
/* Start the threads using default thread attributes */
for(i = 0; i < nThreads ; i ++)
pthread_create(&threads [i], NULL, threadRoutine, &threadArgs[i]);
/* Wait thread termination and use the corresponding
sum value for the final summation */
totalSum = 0;
for(i = 0; i < nThreads ; i ++)
{
pthread_join(threads [i], NULL);
totalSum += threadArgs[i]. partialSum;
}
}
In the foregoing code there are several points worth examining in detail. First of all, the matrix is declared outside the body of any routine in the code. This means that the memory for it is not allocated in the Stack segment but in the Heap segment, being dynamically allocated in the main program. This segment is shared by every thread (only the stack segment is private for each thread). Since the matrix is accessed only in read mode, there is no need to consider synchronization. The examples in the next section will present applications where the shared memory is accessed for both reading and writing, and, in this case, additional mechanisms for ensuring data coherence will be required. Every thread needs two parameters: the row number of the first element of the set of rows assigned to the thread, and the number of rows to be considered. Since only one pointer argument can be passed to threads, the program creates an array of data structures in shared memory, each containing the two arguments for each thread, plus a third return argument that will contain the partial sum, and then passes the pointer of the corresponding structure to each thread. Finally, the program awaits the termination of the threads by calling in pthread_join() in a loop with as many iterations as the number of activated threads. Note that this works also when the threads terminate in an order that is different from the order pthread_join() is called. In fact, if pthread_join() is called for a thread that has already terminated, the routine will return soon with the result value passed by the thread to pthread_exit() and maintained temporarily by the system. In the program, the partial sum computed by each thread is stored in the data structure used to exchange the thread routine argument, and therefore the second parameter of pthread_join() is null, and pthread_exit() is not used in the thread routine.
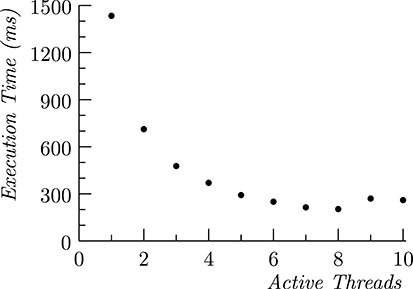
FIGURE 7.2
Execution time of the marge matrix summation for an increasing number of executor threads on an 8-core processor.
In the above example, the actions carried out by each thread are purely computational. So, with a single processor, there is no performance gain in carrying out computation either serially or in parallel because every thread requires the processor 100% of its time and therefore cannot proceed when the processor is assigned to another thread. Modern processors, however, adopt a multicore architecture, that is, host more than one computing unit in the processor, and therefore, there is a true performance gain in carrying out computation concurrently. Figure 7.2 shows the execution time for the above example at an increasing number of threads on an 8-core processor. The execution time halves passing from one to two threads, and the performance improves introducing additional threads. When more than 8 threads are used, the performance does not improve any further; rather it worsens slightly. In fact, when more threads than available cores are used in the program, there cannot be any gain in performance because the thread routine does not make any I/O operation and requires the processor (core) during all its execution. The slight degradation in performance is caused by the added overhead in the context switch due to the larger number of active threads.
The improvement in execution speed due to multithreading becomes more evident when the program being executed by threads makes I/O operations. In this case, the operating system is free to assign the processor to another thread when the current thread starts an I/O operation and needs to await its termination. For this reason, if the routines executed by threads are I/O intensive, adding new threads still improves performance because this reduces the chance that the processor idles awaiting the termination of some I/O operation. Observe that even if no I/O operation is executed by the thread code, there is a chance that the program blocks itself awaiting the completion of an I/O operation in systems supporting memory paging. When paging in memory, pages of the active memory for processes can be held in secondary memory (i.e., on disk), and are transferred (swapped in) to RAM memory whenever they are accessed by the program, possibly copying back (swapping out) other pages in memory to make room for them. Paging allows handling a memory that is larger than the RAM memory installed in the computer, at the expense of additional I/O operations for transferring memory pages from/to the disk.
Threads represent entities that are handled by the scheduler and, from this point of view, do not differ from processes. In fact, the difference between processes and threads lies only in the actions required for the context switch, which is only a subset of the process-specific information if the processing unit is exchanged among threads of the same process. The following chapters will describe in detail how a scheduler works, but here we anticipate a few concepts that will allow us to understand the pthread API for controlling thread scheduling.
We have already seen in Chapter 3 that, at any time, the set of active processes (and threads) can be partitioned in two main categories:
Ready processes, that is, processes that could use the processor as soon as it is assigned to them;
Waiting processes, that is, processes that are waiting for the completion of some I/O operation, and that could not make any useful work in the meantime.
Processes are assigned a priority: higher-priority processes are considered “more important,” and are therefore eligible for the possession of the processor even if other ready processes with lower priority are present. The scheduler organizes ready processes in queues, one for every defined priority, and assigns the processor to a process taken from the nonempty queue with the highest priority. Two main scheduling policies are defined:
First In/First Out (FIFO): The ready queue is organized as a FIFO queue, and when a process is selected to run it will execute until it terminates or enters in wait state due to a I/O operation, or a higher priority process becomes ready.
Round Robin (RR): The ready queue is still organized as a FIFO queue, but after some amount of time (often called time slice), the running process is preempted by the scheduler even if no I/O operation is performed and no higher priority process is ready, and inserted at the tail of the corresponding queue. With regard to the FIFO policy, this policy ensures that all the processes with the highest priority have a chance of being assigned processor time, at the expense, however, of more overhead due to the larger number of context switches.
Scheduling policy represents one of the elements that compose the thread’s attributes, passed to routine pthread_create(). We have already seen that the thread’s attributes are represented by an opaque type and that a set of routines are defined to set individual attributes. The following routine allows for defining the scheduling policy:
int pthread_attr_setschedpolicy(pthread_attr_t *attr, int policy);
where policy is either SCHED_FIFO, SCHED_RR, or SCHED_OTHER. SCHED_OTHER can only be used at static priority 0 and represents the standard Linux timesharing scheduler that is intended for all processes that do not require special static priority real-time mechanisms. The above scheduling policies do not represent the only possible choices and the second part of this book will introduce different techniques for scheduling processes in real-time systems.
Thread priority is finally defined for a given thread by routine:
int pthread_setschedprio(pthread_t thread, int prio);
7.1.2 Creating Processes
The API for creating Linux processes is deceptively simple, formed by one system routine with no arguments:
pid_t fork()
If we compare this with the much richer pthreads API, we might be surprised from the fact that there is no way to define a specific program to be executed and to pass any arguments to it. What fork() actually does is just to create an exact clone of the calling process by replicating the memory content of the process and the associated structures, including the current value of the processor registers. When forks() returns, two identical processes at the same point of execution are present in the system (one of the duplicated processor registers is in fact the Program Counter that holds the address of the next instruction in the program to be executed). There is only one difference between the two: the return value of routine fork() is set to 0 in the created process, and to the identifier of the new process in the original process. This allows discriminating in the code between the calling and the created process, as shown by the following code snippet:
#include <sys/types.h>
#include <unstd.h>
//Required include files
...
pid_t pid;
...
pid = fork();
if(pid == 0)
{
//Actions for the created process
}
else
{
//Actions for the calling process
}
The created process is a child process of the creating one and will proceed in parallel with the latter. As for threads, if processes are created to carry out a collaborative work, it is necessary that, at a certain point, the creator process synchronizes with its child processes. The following system routine will suspend the execution of the process until the child process, identified by the process identifier returned by fork(), has terminated.
pid_t wait(pid_t pid, int *status, int options)
Its argument status, when non-NULL, is a pointer to an integer variable that will hold the status of the child process (e.g., if the child process terminated normally or was interrupted). Argument options, when different from 0, specifies more specialized wait options.
If processes are created to carry out collaborative work, it is necessary that they share memory segments in order to exchange information. While with threads every memory segment different from the stack was shared among threads, and therefore it suffices to use static variables to exchange information, the memory allocated for the child process is by default separate from the memory used by the calling process. We have in fact seen in Chapter 2 that in operating systems supporting virtual memory (e.g., Linux), different processes access different memory pages even if using the same virtual addresses, and that this is achieved by setting the appropriate values in the Page Table at every context switch. The same mechanism can, however, be used to provide controlled access to segments of shared memory by setting appropriate values in the page table entries corresponding to the shared memory pages, as shown in Figure 2.8 in Chapter 2. The definition of a segment of shared memory is done in Linux in two steps:
A segment of shared memory of a given size is created via system routine
shmget();A region of the virtual address space of the process is “attached” to the shared memory segment via system routine
shmat().
The prototype of shmget() routine is
int shmget(key_t key, size_t size, int shmflg)
where key is the unique identifier of the shared memory segment, size is the dimension of the segment, and shmflags defines the way the segment is created or accessed. When creating a shared memory segment, it is necessary to provide an unique identifier to it so that the same segment can be referenced by different processes. Moreover, the shared memory segment has to be created only the first time shmget() is called, and the following times it is called by different processes with the same identifier, the memory segment is simply referenced. It is, however, not always possible to know in advance if the specified segment of shared memory has already been created by another process. The following code snippet shows how to handle such a situation. It shows also the use of system routine ftok() to create an identifier for shmget() starting from a numeric value, and the use of shmat() to associate a range of virtual addresses with the shared memory segment.
# include <sys/ipc.h>
# include <sys/shm.h>
# include <sys/types.h>
/* The numeric identifier of the shared memory segment
the same value must be used by all processes sharing the segment */
# define MY_SHARED_ID 1
...
key_t key; //Identifier to be passed to shmget ()
int memId ; //The id returned by shmget () to be passed to shmat ()
void * startAddr; //The start address of the shared memory segment
...
/* Creation of the key . Routine ftok () function uses the identity
of the file path passed as first argument (here /tmp is used, but it
may refer to any existing file in the system) and the least
significant 8 bits of the second argument */
key_t key = ftok ("/ tmp", MY_SHARED_ID);
/* First try to create a new memory segment . Flags define exclusive
creation, i.e . if the shared memory segment already exists, shmget ()
returns with an error */
memId = shmget (key, size, IPC_CREAT | IPC_EXCL);
if(memId == -1)
/* Exclusive creation failed, the segment was already create by
another process */
{
/* shmget () is called again without the CREATE option */
memId = shmget (key, size, 0);
}
/* If memId == - 1 here, an error occurred in the creation of
the shared memory segment */
if(memId != -1)
{
/* Routine shmat () maps the shared memory segment to a range
of virtual addresses */
startAddr = (char *) shmat (memId, NULL, 0666);
/* From now, memory region pointed by startAddr
is the shared segment */
...
In the case where the memory region is shared by a process and its children processes, it is not necessary to explicitly define shared memory identifiers. In fact, when a child process is created by fork(), it inherits the memory segments defined by the parent process. So, in order to share memory with children processes, it suffices, before calling fork(), to create and map a new shared memory segment passing constant ICP_PRIVATE as the first argument of shmget(). The memory Identifier returned by shmget() will then be passed to shmat(), which will in turn return the starting address of the shared memory. When the second argument of shmat() is NULL (the common case), the operating system is free to choose the virtual address range for the shared memory. The third argument passed to shmat() specifies in a bitmask the level of protection of the shared memory segment, and is normally expressed in octal value as shown in Table 7.1. Octal value 0666 will specify read-and-write access for all processes. The following example, performing the same computation of the example based on threads in the previous section, illustrates the use of shared memory among children processes.
TABLE 7.1
Protection bitmask

# include <stdio .h>
# include <stdlib .h>
# include <sys/time.h>
# include <sys/ipc.h>
# include <sys/shm.h>
# include <sys/wait.h>
# define MAX_PROCESSES 256
# define ROWS 10000 L
# define COLS 10000 L
/* Arguments exchanged with child processes */
struct argument {
int startRow ;
int nRows ;
long partialSum;
};
/* The shared memory contains the arguments exchanged between parent
and child processes and is pointer by processArgs */
struct argument * processArgs;
/* Matrix pointer : it will be dynamically allocated */
long * bigMatrix;
/* The current process index, incremented by the parent process before
every fork () call. */
int currProcessIdx;
/* Child process routine : make the summation of all the elements of the
assigned matrix rows. */
static void processRoutine()
{
int i, j;
long sum = 0;
/* processArgs is the pointer to the shared memory inherited by the
parent process. processArg [currProcessIdx] is the argument
structure specific to the child process */
for(i = 0; i < processArgs[currProcessIdx]. nRows ; i++)
for(j = 0; j < COLS; j ++)
sum += bigMatrix[(processArgs[currProcessIdx]. startRow + i) * COLS
+ j];
/* Report the computed sum into the argument structure */
processArgs[ currProcessIdx]. partialSum = sum;
}
int main(int argc, char * args [])
{
int memId ;
long totalSum ;
int i, j, nProcesses, rowsPerProcess, lastProcessRows;
/* Array of process identifiers used by parent process in the wait cycle */
pid_t pids [ MAX_PROCESSES];
/* Get the number of processes from command parameter */
if(argc != 2)
{
printf (" Usage : processs < numProcesses >
");
exit (0);
}
sscanf (args [1], "%d", &nProcesses);
/* Create a shared memory segment to contain the argument structures
for all child processes. Set Read/Write permission in flags argument. */
memId = shmget (IPC_PRIVATE, nProcesses * sizeof (struct argument), 0666);
if(memId == -1)
{
perror (" Error in shmget ");
exit (0);
}
/* Attach the shared memory segment. Child processes will inherit the
shared segment already attached */
processArgs = shmat (memId, NULL, 0);
if(processArgs == (void *) -1)
{
perror (" Error in shmat ");
exit (0);
}
/* Allocate the matrix M */
bigMatrix = malloc (ROWS* COLS * sizeof (long));
/* Fill the matrix with some values */
...
/* If the number of rows cannot be divided exactly by the number of
processs, let the last thread handle also the remaining rows */
rowsPerProcess = ROWS / nProcesses;
if(ROWS % nProcesses == 0)
lastProcessRows = rowsPerProcess;
else
lastProcessRows = rowsPerProcess + ROWS % nProcesses;
/* Prepare arguments for processes */
for(i = 0; i < nProcesses; i ++)
{
processArgs[i]. startRow = i* rowsPerProcess;
if(i == nProcesses - 1)
processArgs[i]. nRows = lastProcessRows;
else
processArgs[i]. nRows = rowsPerProcess;
}
/* Spawn child processes */
for(currProcessIdx = 0; currProcessIdx < nProcesses; currProcessIdx++)
{
pids[ currProcessIdx] = fork ();
if(pids [currProcessIdx] == 0)
{
/* This is the child process which inherits a private copy of all
the parent process memory except for the region pointed by
processArgs which is shared with the parent process */
processRoutine();
/* After computing partial sum the child process exits */
exit (0);
}
}
/* Wait termination of child processes and perform final summation */
totalSum = 0;
for(currProcessIdx = 0; currProcessIdx < nProcesses; currProcessIdx++)
{
/* Wait child process termination */
waitpid (pids [currProcessIdx], NULL, 0);
totalSum += processArgs[ currProcessIdx]. partialSum;
}
}
From a programming point of view, the major conceptual difference with the thread-based example is that parameters are not explicitly passed to child processes. Rather, a variable within the program (currProcessIdx) is set to the index of the child process just before calling fork() so that it can be used in the child process to select the argument structure specific to it.
The attentive reader may be concerned about the fact that, since fork() creates a clone of the calling process including the associated memory, the amount of processing at every child process creation in the above example may be very high due to the fact that the main process has allocated in memory a very large matrix. Fortunately this is not the case because the memory pages in the child process are not physically duplicated. Rather, the corresponding page table entries in the child process refer to the same physical pages of the parent process and are marked as Copy On Write. This means that, whenever the page is accessed in read mode, both the parent and the child process refer to the same physical page, and only upon a write operation is a new page in memory created and mapped to the child process. So, pages that are only read by the parent and child processes, such as the memory pages containing the program code, are not duplicated at all. In our example, the big matrix is written only before creating child processes, and therefore, the memory pages for it are never duplicated, even if they are conceptually replicated for every process. Nevertheless, process creation and context switches require more time in respect of threads because more information, including the page table, has to be saved and restored at every context switch.
Routines shmget() and shmat(), now incorporated into POSIX, derive from the System V interface, one of the two major “flavors” of UNIX, the other being Berkeley Unix (BSD). POSIX defines also a different interface for creating named shared memory objects, that is, the routine sem_open(). The arguments passed to sem_open() specify the systemwide name of the shared memory object and the associated access mode and protection. In this case, routine mmap(), which has been encountered in Chapter 2 for mapping I/O into memory, is used to map the shared memory object onto a range of process-specific virtual addresses.
7.2 Interprocess Communication among Threads
In the previous example, the threads and processes were either reading the shared memory or writing it at disjoint addresses (the shared arguments containing the partial sums computed by threads/processes). For this reason, there was no need to ensure synchronization because the shared information was correctly managed regardless of the possible interleaving in read actions by means of threads/processes. We have seen in Chapter 5 that, in the more general case in which shared data are also written by threads/processes, using shared memory alone does not guarantee against possible errors due to the interleaved access to the shared data structures. Therefore, it is necessary to provide some sort of mutual exclusion in order to protect critical data structures against concurrent access. The POSIX pthread interface provides two mechanisms to manage synchronization among threads: Mutexes and Condition Variables.
7.2.1 Mutexes and Condition Variables
Mutex is an abbreviation for “mutual exclusion,” and mutex variables are used for protecting shared data when multiple writes occur by letting at the most one thread at a time execute critical sections of code in which shared data structures are modified. A mutex variable acts like a “lock” protecting access to a shared data resource. Only one thread can lock (or own) a mutex variable at any given time. Thus, even if several threads try to lock a mutex concurrently, only one thread will succeed, and no other thread can own that mutex until the owning thread unlocks it. The operating system will put any thread trying to lock an already locked mutex in wait state, and such threads will be made ready as soon as the mutex is unlocked. If more than one thread is waiting for the same mutex, they will compete for it, and only one will acquire the lock this turn.
Mutex variables are declared to be of type pthread_mutex_t and must be initialized before being used, using the following function:
pthread_mutex_init(pthread_mutex_t *mutex, pthread_mutex_attr_t *attr)
where the first argument is the pointer of the mutex variable, and the second one, when different from 0, is a pointer of a variable holding the attributes for the mutex. Such attributes will be explained later in this book, so, for the moment, we will use the default attributes. Once initialized, a thread can lock and unlock the mutex via routines
pthread_mutex_lock(pthread_mutex_t *mutex) pthread_mutex_unlock(pthread_mutex_t *mutex)
Routine pthread_mutex_lock() is blocking, that is, the calling thread is possibly put in wait state. Sometimes it is more convenient just to check the status of the mutex and, if the mutex is already locked, return immediately with an error rather than returning only when the thread has acquired the lock. The following routine does exactly this:
int pthread_mutex_trylock(pthread_mutex_t *mutex)
Finally, a mutex should be destroyed, that is, the associated resources released, when it is no more used:
pthread_mutex_destroy(pthread_mutex_t *mutex)
Recalling the producer/consumer example of Chapter 5, we can see that mutexes are well fit to ensure mutual exclusion for the segments of code that update the circular buffer and change the index accordingly. In addition to using critical sections when retrieving an element from the circular buffer and when inserting a new one, consumers need also to wait until at least one element is available in the buffer, and producers have to wait until the buffer is not full. This kind of synchronization is different from mutual exclusion because it requires waiting for a given condition to occur. This is achieved by pthread condition variables acting as monitors. Once a condition variable has been declared and initialized, the following operations can be performed: wait and signal. The former will suspend the calling thread until some other thread executes a signal operation for that condition variable. The signal operation will have no effect if no thread is waiting for that condition variable; otherwise, it will wake only one waiting thread. In the producer/consumer program, two condition variables will be defined: one to signal the fact that the circular buffer is not full, and the other to signal that the circular buffer is not empty. The producer performs a wait operation over the first condition variable whenever it finds the buffer full, and the consumer will execute a signal operation over that condition variable after consuming one element of the buffer. A similar sequence occurs when the consumer finds the buffer empty.
The prototypes of the pthread routines for initializing, waiting, signaling, and destroying condition variables are respectively:
int pthread_cond_init(pthread_cond_t *condVar, pthread_condattr_t *attr) int pthread_cond_wait(pthread_cond_t *cond , pthread_mutex_t *mutex) int pthread_cond_signal(pthread_cond_t *cond) int pthread_cond_destroy(pthread_cond_t *cond)
The attr argument passed to pthread_cond_init() will specify whether the condition variable can be shared also among threads belonging to different processes. When NULL is passed as second argument, the condition variable is shared only by threads belonging to the same process. The first argument of pthread_cond_wait() and pthread_cond_signal() is the condition variable, and the second argument of pthread_cond_wait() is a mutex variable that must be locked at the time pthread_cond_wait() is called. This argument may seem somewhat confusing, but it reflects the normal way condition variables are used. Consider the producer/consumer example, and in particular, the moment in which the consumer waits, in a critical section, for the condition variable indicating that the circular buffer is not empty. If the mutex used for the critical section were not released prior to issuing a wait operation, the program would deadlock since no other thread could enter that critical section. If it were released prior to calling pthread_cond_wait(), it may happen that, just after finding the circular buffer empty and before issuing the wait operation, another producer adds an element to the buffer and issues a signal operation on that condition variable, which does nothing since no thread is still waiting for it. Soon after, the consumer issues a wait request, suspending itself even if the buffer is not empty. It is therefore necessary to issue the wait at the same time the mutex is unlocked, and this is the reason for the second argument of pthread_cond_wait(), which will atomically unlock the mutex and suspend the thread, and will lock again the mutex just before returning to the caller program when the thread is awakened.
The following program shows the usage of mutexes and condition variables when a producer thread puts integer data in a shared circular buffer, which are then read by a set of consumer threads. The number of consumer threads is passed as an argument to the program. A mutex is defined to protect insertion and removal of elements into/from the circular buffer, and two condition variables are used to signal the availability of data and room in the circular buffer.
# include <pthread .h>
# include <stdio .h>
# include <stdlib .h>
# include <sys/time.h>
/* The mutex used to protect shared data */
pthread_mutex_t mutex ;
/* Condition variables to signal availability
of room and data in the buffer */
pthread_cond_t roomAvailable, dataAvailable;
# define BUFFER_SIZE 128
/* Shared data */
int buffer [ BUFFER_SIZE];
/* readIdx is the index in the buffer of the next item to be retrieved */
int readIdx = 0;
/* writeIdx is the index in the buffer of the next item to be inserted */
int writeIdx = 0;
/* Buffer empty condition corresponds to readIdx == writeIdx . Buffer full
condition corresponds to (writeIdx + 1)%BUFFER SIZE == readIdx */
/* Consumer Code : the passed argument is not used */
static void * consumer (void * arg)
{
int item ;
while (1)
{
/* Enter critical section */
pthread_mutex_lock(&mutex);
/* If the buffer is empty, wait for new data */
while (readIdx == writeIdx)
{
pthread_cond_wait(&dataAvailable, &mutex);
}
/* At this point data are available
Get the item from the buffer */
item = buffer [ readIdx ];
readIdx = (readIdx + 1)% BUFFER_SIZE;
/* Signal availability of room in the buffer */
pthread_cond_signal(&roomAvailable);
/* Exit critical section */
pthread_mutex_unlock(&mutex);
/* Consume the item and take actions (e.g. return)*/
...
}
return NULL ;
}
/* Producer code. Passed argument is not used */
static void * producer (void * arg)
{
int item = 0;
while (1)
{
/* Produce a new item and take actions (e.g. return) */
...
/* Enter critical section */
pthread_mutex_lock(&mutex);
/* Wait for room availability */
while ((writeIdx + 1)% BUFFER_SIZE == readIdx)
{
pthread_cond_wait(&roomAvailable, &mutex)
}
/* At this point room is available
Put the item in the buffer */
buffer [ writeIdx ] = item;
writeIdx = (writeIdx + 1)% BUFFER_SIZE;
/* Signal data avilability */
pthread_cond_signal(&dataAvailable)
/* Exit critical section */
pthread_mutex_unlock(&mutex);
}
return NULL ;
}
int main(int argc, char * args [])
{
pthread_t threads [MAX_THREADS];
int nConsumers;
int i;
/* The number of consumer is passed as argument */
if(argc != 2)
{
printf (" Usage : prod_cons <numConsumers >
");
exit (0);
}
sscanf (args [1], "%d", &nConsumers);
/* Initialize mutex and condition variables */
pthread_mutex_init(&mutex, NULL)
pthread_cond_init(&dataAvailable, NULL)
pthread_cond_init(&roomAvailable, NULL)
/* Create producer thread */
pthread_create(&threads [0], NULL, producer, NULL);
/* Create consumer threads */
for(i = 0; i < nConsumers; i ++)
pthread_create(& threads [i + 1], NULL, consumer, NULL);
/* Wait termination of all threads */
for(i = 0; i < nConsumers + 1; i++)
{
pthread_join(threads [i], NULL);
}
return 0;
}
No check on the returned status of pthread routines is carried out in the above program to reduce the length of the listed code. Be conscious, however, that a good programming practice is to check every time the status of the called functions, and this is true in particular for the system routines used to synchronize threads and processes. A trivial error, such as passing a wrong argument making the routine fail synchronization, may not produce an evident symptom in program execution, but potentially raises race conditions that are very difficult to diagnose.
In the above program, both the consumers and the producer, once entered in the critical section, check the availability of data and room, respectively, possibly issuing a wait operation on the corresponding condition variable. Observe that, in the code, the check is repeated once pthread_cond_wait() returns, being the check within a while loop. This is the correct way of using pthread_cond_wait() because pthread library does not guarantee that the waiting process cannot be awakened by spurious events, requiring therefore the repeat of the check for the condition before proceeding. Even if spurious events were not generated, using an if statement in place of the while statement, that is, not checking the condition after exiting the wait operation, leads to a race condition in the above program when the following sequence occurs: (1) a consumer finds the buffer empty and waits; (2) a producer puts a new data item and signals the condition variable; (3) another consumer thread enters the critical section and consumes the data item before the first consumer gains processor ownership; (4) the first consumer awakes and reads the data item when the buffer is empty.
Mutexes and condition variables are provided by pthread library for thread synchronization and cover, in principle, all the required synchronization mechanisms in practice. We shall see in the next section that there are several other synchronization primitives to be used for processes that can be used for threads as well. Nevertheless, it is good programming practice to use pthread primitives when programming with threads. Library pthreads is in fact implemented not only in Linux but also in other operating systems, so a program using only pthreads primitive is more easily portable across different platforms than a program using Linux-specific synchronization primitives.
7.3 Interprocess Communication among Processes
7.3.1 Semaphores
Linux semaphores are counting semaphores and are widely used to synchronize processes. When a semaphore has been created and an initial value assigned, two operations can be performed on it: sem_wait() and sem_post(). Operation sem_wait() will decrement the value of the semaphore: if the semaphore’s value is greater than zero, then the decrement proceeds and the function returns immediately. If the semaphore currently has the value zero, then the call blocks until it becomes possible to perform the decrement, that is, the semaphore value rises above zero. Operation sem_post() increments the semaphore. If the semaphore’s value consequently becomes greater than zero, then another process or thread may be blocked in a sem_wait() call. In this case, it will be woken up and will proceed in decrementing the semaphore’s value. Semaphores can be used to achieve the same functionality of pthread mutexes and condition variables. To protect a critical section, it suffices to initialize a semaphore with an initial value equal to one: sem_wait() and sem_post() will be called by each process just before entering and exiting the critical section, respectively. To achieve the signaling mechanism carried out by condition variables, the semaphore will be created with a value equal to zero. When sem_wait() is called the the first time prior to sem_post(), the calling process will suspend until another process will call sem_post(). There is, however, a subtle difference between posting a semaphore and signaling a condition variable: when the latter is signaled, if no thread is waiting for it, nothing happens, and if a thread calls pthread_cond_wait() for that condition variable soon after, it will suspend anyway. Conversely, posting a semaphore will permanently increase its value until one process will perform a wait operation on it. So, if no process is waiting for the semaphore at the time it is posted, the first process that waits on it afterward will not be stopped.
There are two kinds of semaphores in Linux: named semaphores and unnamed semaphores. Named semaphores, as the name suggests, are associated with a name (character string) and are created by the following routine:
sem_t *sem_open(const char *name, int oflag, mode_t mode, unsigned int value)
where the first argument specifies the semaphore’s name. The second argument defines associated flags that specify, among other information, if the semaphore has to be created if not yet existing. The third argument specifies the associated access protection (as seen for shared memory), and the last argument specifies the initial value of the semaphore in the case where this has been created. sem_open() will return the address of a sem_t structure to be passed to sem_wait() and sem_post(). Named semaphores are used when they are shared by different processes, using then their associated name to identify the right semaphores. When the communicating processes are all children of the same process, unnamed semaphores are preferable because it is not necessary to define names that may collide with other semaphores used by different processes. Unnamed semaphores are created by the following routine:
int sem_init(sem_t *sem, int pshared, unsigned int value)
sem_init() will always create a new semaphore whose data structure will be allocated in the sem_t variable passed as first argument. The second argument specifies whether the semaphore will be shared by different processes and will be set to 0 only if the semaphore is to be accessed by threads belonging to the same process. If the semaphore is shared among processes, the sem_t variable to host the semaphore data structures must be allocated in shared memory. Lastly, the third argument specifies the initial value of the semaphore.
The following example is an implementation of our well-known producer/consumer application where the producer and the consumers execute on different processes and use unnamed semaphores to manage the critical section and to handle producer/consumer synchronization. In particular, the initial value of the semaphore (mutexSem) used to manage the critical section is set to one, thus ensuring that only one process at a time can enter the critical section by issuing first a P() (sem_wait()) and then a V() (sem_post()) operation. The other two semaphores (dataAvailableSem and roomAvailableSem)will contain the current number of available data slots and free ones, respectively. Initially there will be no data slots and BUFFER_SIZE free slots and therefore the initial values of dataAvailableSem and roomAvailableSem will be 0 and BUFFER_SIZE, respectively.
# include <stdio .h>
# include <stdlib .h>
# include <sys/ipc .h>
# include <sys/shm .h>
# include <sys/ wait .h>
# include <semaphore .h>
# define MAX_PROCESSES 256
# define BUFFER_SIZE 128
/* Shared Buffer, indexes and semaphores are held in shared memory
readIdx is the index in the buffer of the next item to be retrieved
writeIdx is the index in the buffer of the next item to be inserted
Buffer empty condition corresponds to readIdx == writeIdx
Buffer full condition corresponds to
(writeIdx + 1)%BUFFER_SIZE == readIdx)
Semaphores used for synchronization :
mutexSem is used to protect the critical section
dataAvailableSem is used to wait for data avilability
roomAvailableSem is used to wait for room abailable in the buffer */
struct BufferData {
int readIdx ;
int writeIdx ;
int buffer [BUFFER_SIZE];
sem_t mutexSem ;
sem_t dataAvailableSem;
sem_t roomAvailableSem;
};
struct BufferData * sharedBuf;
/* Consumer routine */
static void consumer ()
{
int item ;
while (1)
{
/* Wait for availability of at least one data slot */
sem_wait (&sharedBuf -> dataAvailableSem);
/* Enter critical section */
sem_wait (&sharedBuf -> mutexSem);
/* Get data item /
item = sharedBuf -> buffer [ sharedBuf -> readIdx ];
/* Update read index */
sharedBuf -> readIdx = (sharedBuf -> readIdx + 1)% BUFFER_SIZE;
/* Signal that a new empty slot is available */
sem_post (&sharedBuf -> roomAvailableSem);
/* Exit critical section */
sem_post (&sharedBuf -> mutexSem);
/* Consume data item and take actions (e.g return)*/
...
}
}
/* producer routine */
static void producer ()
{
int item = 0;
while (1)
{
/* Produce data item and take actions (e.g . return)* /
...
/* Wait for availability of at least one empty slot */
sem_wait (&sharedBuf -> roomAvailableSem);
/* Enter critical section */
sem_wait (&sharedBuf -> mutexSem);
/* Write data item */
sharedBuf -> buffer [ sharedBuf -> writeIdx ] = item;
/* Update write index */
sharedBuf -> writeIdx = (sharedBuf -> writeIdx + 1)% BUFFER_SIZE;
/* Signal that a new data slot is available */
sem_post (&sharedBuf -> dataAvailableSem);
/* Exit critical section */
sem_post (&sharedBuf -> mutexSem);
}
}
/* Main program: the passed argument specifies the number
of consumers */
int main(int argc, char * args [])
{
int memId ;
int i, nConsumers;
pid_t pids [MAX_PROCESSES];
if(argc != 2)
{
printf (" Usage : prodcons <numProcesses >
");
exit (0);
}
sscanf (args [1], "%d", &nConsumers);
/* Set-up shared memory */
memId = shmget (IPC_PRIVATE, sizeof (struct BufferData), SHM_R | SHM_W);
if(memId == -1)
{
perror (" Error in shmget ");
exit (0);
}
sharedBuf = shmat (memId, NULL, 0);
if(sharedBuf == (void *) -1)
{
perror (" Error in shmat ");
exit (0);
}
/* Initialize buffer indexes */
sharedBuf -> readIdx = 0;
sharedBuf -> writeIdx = 0;
/* Initialize semaphores. Initial value is 1 for mutexSem,
0 for dataAvailableSem (no filled slots initially available)
and BUFFER_SIZE for roomAvailableSem (all slots are
initially free). The second argument specifies
that the semaphore is shared among processes */
sem_init (&sharedBuf -> mutexSem, 1, 1);
sem_init (&sharedBuf -> dataAvailableSem, 1, 0);
sem_init (&sharedBuf -> roomAvailableSem, 1, BUFFER_SIZE);
/* Launch producer process */
pids [0] = fork ();
if(pids [0] == 0)
{
/* Child process */
producer ();
exit (0);
}
/* Launch consumer processes */
for(i = 0; i < nConsumers; i ++)
{
pids[i + 1] = fork ();
if(pids [i+1] == 0)
{
consumer ();
exit (0);
}
}
/* Wait process termination */
for(i = 0; i <= nConsumers; i++)
{
waitpid (pids [i], NULL, 0);
}
return 0;
}
Observe that, in the above example, there is no check performed on read and write indexes to state whether data or free room are available. This check is in fact implicit in the P (semWait()) and V (semPost()) operations carried out on dataAvailableSem and roomAvailableSem semaphores.
7.3.2 Message Queues
In the previous section, the exchange of information between the producer and consumers has been managed using shared memory and semaphores. In POSIX it is possible to use another IPC mechanism: message queues. Message queues allow different processes to exchange information by inserting and extracting data elements into and from FIFO queues that are managed by the operating system. A message queue is created in a very similar way as shared memory segments are created by shmget(), that is, either passing a unique identifier so that different processes can connect to the same message queue, or by defining the IPC_PRIVATE option in the case where the message queue is to be shared among the parent and children processes. In fact, when a child process is created by fork(), it inherits the message queue references of the parent process. A new message queue is created by routine:
int msgget(key_t key, int msgflg)
whose first argument, if not IPC_PRIVATE, is the message queue unique identifier, and the second argument specifies, among others, the access protection to the message queue, specified as a bitmask as for the shared memory. The returned value is the message queue identifier to be used in the following routines. New data items are inserted in the message queue by the following routine:
int msgsnd(int msqid, const void *msgp, size_t msgsz, int msgflg)
where the first argument is the message queue identifier. The second argument is a pointer to the data structure to be passed, whose length is specified in the third argument. Such a structure defines, as its first long element, a user-provided message type that can be used to select the messages to be received. The last argument may define several options, such as specifying whether the process is put in wait state in the case the message queue is full, or if the routine returns immediately with an error in this case. Message reception is performed by the following routine:
ssize_t msgrcv(int msqid, void *msgp, size_t msgsz, long msgtyp, int msgflg);
whose arguments are the same for of the previous routine, except for msgtyp, which, if different from 0, specifies the type of message to be received. Unless differently specified, msgrcv() will put the process in wait state if a message of the specified type is not present in the queue. The following example uses message queues to exchange data items between a producer and a set of consumers processes.
# include <stdio .h>
# include <stdlib .h>
# include <sys/ipc.h>
# include <sys/ wait.h>
# include <sys/msg.h>
# define MAX_PROCESSES 256
/* The type of message */
# define PRODCONS_TYPE 1
/* Message structure definition */
struct msgbuf {
long mtype ;
int item ;
};
/* Message queue id */
int msgId ;
/* Consumer routine */
static void consumer ()
{
int retSize ;
struct msgbuf msg;
int item ;
while (1)
{
/* Receive the message . msgrcv returns the size of the received message */
retSize = msgrcv (msgId, &msg, sizeof (int), PRODCONS_TYPE, 0);
if(retSize == -1) //If Message reception failed
{
perror (" error msgrcv ");
exit (0);
}
item = msg. item;
/* Consume data item */
...
}
}
/* Consumer routine */
static void producer ()
{
int item = 0;
struct msgbuf msg;
msg. mtype = PRODCONS_TYPE;
while (1)
{
/* produce data item */
...
msg. item = item;
msgsnd (msgId, &msg, sizeof (int), 0);
}
}
/* Main program. The number of consumer
is passed as argument * /
int main(int argc, char * args [])
{
int i, nConsumers;
pid_t pids [MAX_PROCESSES];
if(argc != 2)
{
printf (" Usage : prodcons <nConsumers >
");
exit (0);
}
sscanf (args [1], "%d", &nConsumers);
/* Initialize message queue */
msgId = msgget (IPC_PRIVATE, 0666);
if(msgId == -1)
{
perror (" msgget ");
exit (0);
}
/* Launch producer process */
pids [0] = fork ();
if(pids [0] == 0)
{
/* Child process */
producer ();
exit (0);
}
/* Launch consumer processes */
for(i = 0; i < nConsumers; i ++)
{
pids[i + 1] = fork ();
if(pids [i+1] == 0)
{
consumer ();
exit (0);
}
}
/* Wait process termination */
for(i = 0; i <= nConsumers; i++)
{
waitpid (pids [i], NULL, 0);
}
return 0;
}
The above program is much simpler than the previous ones because there is no need to worry about synchronization: everything is managed by the operating system! Several factors however limit in practice the applicability of message queues, among which is the fact that they consume more system resources than simpler mechanisms such as semaphores.
Routines msgget(), msgsnd(), and msgrcv(), now in the POSIX standard, originally belonged to the System V interface. POSIX defines also a different interface for named message queues, that is, routines mq_open() to create a message queue, and mq_send() and mq_receive() to send and receive messages over a message queue, respectively. As for the shared memory object creation, the definition of the message queue name is more immediate: the name is directly passed to mq_open(), without the need for using ftok() to create the identifier to be passed to the message queue creation routine. On the other side, msgget() (as well as shmget()) allows creating unnamed message queues, that are shared by the process and its children with no risk of conflicts with other similar resources with the same name.
7.3.3 Signals
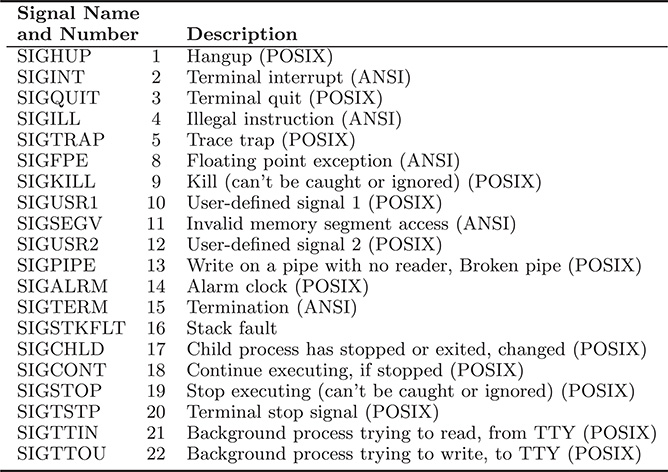
The synchronization mechanisms we have seen so far provide the necessary components, which, if correctly used, allow building concurrent and distributed systems. However sometime it is necessary to handle the occurrence of signals, that is, asynchronous event requiring some kind of action in response. In POSIX and ANSI, a set of signals is defined, summarized by table 7.2, and the corresponding action can be specified using the following routine:
signal(int signum, void (*handler)(int))
where the first argument is the event number, and the second one is the address of the event handler routine, which will be executed asynchronously when an event of the specified type is sent to the process.
A typical use of routine signal() is for “trapping” the SIG_INT event that is generated by the <ctrl> C key. In this case, instead of an abrupt program termination, it is possible to let a cleanup routine be executed, for example closing the files which have been opened by the process and making sure that their content is not corrupted. Another possible utilization of event handlers is in association with timers, as explained in the next section. Care is necessary in programming event handlers since they are executed asynchronously. Since events may occur at any time during the execution of the process, no assumption can be made on the current status of the data structures managed by programs at the time a signal is received. For the same reason, it is necessary that event handlers call only “safe” system routines, that is, system routines that are guaranteed to execute correctly regardless of the current system state (luckily, most pthread and Linux system routines are safe).
TABLE 7.2
Some signal events defined in Linux
7.4 Clocks and Timers
Sometimes it is necessary to manage time in program. For example, a control cycle in an embedded system may be repeated every time period, or an action has to finish within a given timeout. Two classes of routines are available for handling time: wait routines and timers. Wait routines, when called, force the suspension of the calling thread or process for the specified time. Traditionally, programmers have used routine sleep() whose argument specifies the number of seconds the caller has to wait before resuming execution. More accurate wait time definition is achieved by routine
int nanosleep(const struct timespec *req, struct timespec *rem);
The first argument defines the wait time, and its type is specified as follows:
struct timespec {
time_t tv_sec; /* seconds */
long tv_nsec; /* nanoseconds */
};
The second argument, if not NULL, is a pointer to a struct timespec argument that will report the remaining time in the case nanosleep() returned (with an error) before the specified time. This happens in the case where a signal has been delivered to the process that issued nanosleep(). Observe that, even if it is possible to specify the wait time with nanosecond precision, the actual wait time will be rounded to a much larger period, normally ranging from 10 to 20 ms. The reason lies in the mechanism used by the operating system to manage wait operations: when a process or a thread calls nanosleep(), it is put in wait state, thus losing control of the processor, and a new descriptor will be added to a linked list of descriptors of processes/threads, recording, among other information, the wake time. At every tick, that is, every time the processor is interrupted by the system clock, such list is checked, and the processes/threads for which the wait period has expired are awakened. So, the granularity in the wait period is dictated by the clock interrupt rate, which is normally around 50–60 Hz. Observe that, even if it is not possible to let processes/threads wait with microsecond precision, it is possible to get the current time with much more precision because every computer has internal counters that are updated at very high frequencies, often at the processor clock frequency. For this reason, the time returned by routine gettimeofday(), used in chapter 2, is a very accurate measurement of the current time.
The other class of time-related routines creates timers, which allows an action to be executed after a given amount of time. Linux routine timer_create() will set up an internal timer, and upon the expiration of the timer, a signal will be sent to the calling process. An event handler will then be associated with the event via routine signal() in order to execute the required actions upon the timer expiration.
7.5 Threads or Processes?
We have seen that in Linux there are two classes of entities able to execute programs. Processes have been implemented first in the history of UNIX and Linux. Threads have been introduced later as a lightweight version of processes, and are preferable to processes for two main reasons
1. Efficiency: context switch in threads belonging to the same process is fast when compared with context switch between processes, mainly because the page table information needs not to be updated because all threads in a process share the same memory space;
Simplified programming model: sharing memory among threads is trivial, it suffices to use static variables. Mutexes and Condition Variables then provide all the required synchronization mechanisms.
At this point the reader may wonder why any more processes need to be used when developing a concurrent application. After all, a single big process, hosting all the threads that cooperate in carrying out the required functionality, may definitely appear as the best choice. Indeed, very often this is the case, but threads have a weak aspect that sometimes cannot be acceptable, that is, the lack of protection. As threads share the same memory, except for stacks, a wrong memory access performed by one thread may corrupt the data structure of other threads. We have already seen that this fact would be impossible among processes since their memories are guaranteed to be insulated by the operating system, which builds a “fence” around them by properly setting the processes’ page tables. Therefore, if some code to be executed is not trusted, that is, there is any likelihood that errors could arise during execution, the protection provided by the process model is mandatory. An example is given by Web Servers, which are typically concurrent programs because they must be able to serve multiple clients at the same time. Serving an HTTP connection may, however, also imply the execution of external code (i.e., not belonging to the Web Server application), for example, when CGI scripts are activated. If the Web Server were implemented using threads, the failure of a CGI script potentially crashes the whole server. Conversely, if the Web Server is implemented as a multiprocess application, failure of a CGI script will abort the client connection, but the other connections remain unaffected.
7.6 Summary
This chapter has presented the Linux implementation of the concepts introduced in Chapters 3 and 5. Firstly, the difference between Linux processes and threads has been described, leading to a different memory model and two different sets of interprocess communication primitives. The main difference between threads and processes lies in the way memory is managed; since threads live in the context of a process, they share the same address space of the hosting process, duplicating only the stack segment containing local variables and the call frames. This means in practice that static variables, that are not located in the stack, are shared by all the threads cerated by a given process (or thread). Conversely, shared memory segments must be created in order to exchange memory data among different processes.
Threads can be programmed using library pthread, and they represent a complete model for concurrency, defining mutexes and condition variables for synchronization. Inteprocess communication is carried out by semaphores and message queues, which can be used for threads, too. Several implementations of the producer-consumer example, introduced in Chapter 3, have been presented using different synchronization primitives.