
The prefix super in the moniker supercomputer may, to the ill-informed, conjure up images of the electronic supervillain HAL 9000 in Arthur C. Clarke's classic movie 2001: A Space Odyssey or the benevolent superhero Clark Kent, aka Superman, who inhabits the DC comic universe. However, the tag supercomputer is, in fact, associated with a non-fictional entity that has no ill-will towards humans - at least not at this moment in time. Supercomputing and supercomputers are the subject matter of this book.
In this chapter, we introduce the reader to the basics of supercomputing, or more precisely, parallel processing. Parallel processing is a computational technique that is currently enjoying widespread usage at many research institutions, including universities and government laboratories, where machines routinely carry out computation in the teraflops (1 billion floating point operations per second) and petaflops (1,000 teraflops) domain. Parallel processing significantly reduces the time needed to analyze and/or solve complex and difficult mathematical and scientific problems, such as weather prediction, where a daunting myriad of physical atmospheric conditions must be considered and processed simultaneously in order to obtain generally accurate weather forecasting.
Supercomputing is also employed in analyzing the extreme physical conditions extant at the origin of the much-discussed Big Bang event, in studying the dynamics of galaxy formation, and in simulating and analyzing the complex physics of atomic and thermonuclear explosions - data that is crucial to the military for maintaining and designing even more powerful weapons of mass destruction - holy crap!! This doesn't bode well for humanity. Anyway, these are just a few examples of tasks germane to parallel processing. Following are images of events that are being studied/simulated by scientist employing supercomputers:

The enhanced processing speed, so central to parallel computing, is achieved by assigning chunks of data to different processors in a computer network, where the processors then concurrently execute similar, specifically designed code logic on their share of the data. The partial solution from each processor is then gathered to produce a final result. You will indeed be exploring this technique later when you run example codes on your PC, and then on your Pi2 or Pi3 supercomputer.
The computational time compression associated with parallel computing is typically on the order of a few minutes or hours, rather than weeks, months, or years. The sharing of tasks among processors is facilitated by a communication protocol for programming parallel computers called Message Passing Interface (MPI). The MPI standard, which came to fruition between the 1980s and early 1990s, was finally ratified in 2012 by the MPI Forum, which has over 40 participating organizations.
You can visit https://computing.llnl.gov/tutorials/mpi/ for a brief history and tutorial on MPI, and https://computing.llnl.gov/tutorials/parallel_comp/ for parallel computing. You can also visit http://mpitutorial.com/tutorials/ for additional information and a tutorial on MPI programming.
In this chapter, you will learn about the following topics:
- John von Neumann's stored-program computer architecture
- Flynn's classical taxonomy
- Historical perspective on supercomputing and supercomputers
- Serial processing techniques
- Parallel processing techniques
- The need for greater processing speed
- Additional analytical perspective on the need for greater processing speed
Dr. John von Neumann:

John von Neumann circa the 1940s
Any discussion concerning computers must include the contributions of the famed Hungarian mathematician/genius Dr. John von Neumann. He was the first to stipulate, in his famous 1945 paper, the general requirements for an electronic computer. This device was called a stored-program computer, since the data and program instructions are kept in electronic memory. The specification was a departure from earlier designs where computers were programmed via hard wiring. Von Neumann's basic design has endured to this day, as practically all modern-day processors exhibit some vestiges of this design architecture (see the following figure):
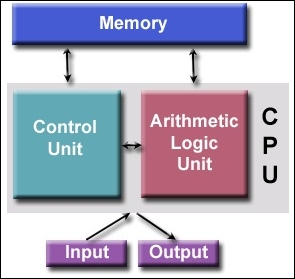
Von Neumann architecture
Von Neumann's design basic components are tabulated as follows:
- The four main elements:
- A memory component
- A controller unit
- A logic unit for doing arithmetic
- An input and output port
- A means for storing data and program instructions termed read/write random access memory
- The data is information utilized by the program
- The program instructions consist of coded data that guides the computer to complete a task
- Controller Unit acquires information from memory, deciphers the information, and then sequentially synchronizes processes to achieve the programmed task
- Basic arithmetic operations occur in the Arithmetic Logic Unit
- Input and Output ports allow access to the Central Processing Unit (CPU) by a human operator
- Additional information can be obtained at https://en.wikipedia.org/wiki/John_von_Neumann
So, how does this architecture relates to parallel processors/supercomputers? You might ask. Well, supercomputers consist of nodes, which are, in fact, individual computers. These computers contain processors with the same architectural elements described previously.