
Using your PC as a one-node supercomputer is quite easy, and can be quite a fun exercise as you command the cores in the processor to do your digital bidding. From here on, it will be assumed that the reader has a working knowledge of the C language. So, the first step on your digital journey will be to write and run a simple C code to compute π. This code will perform numeric integration (using 300,000 iterations) on an x function representation of π. You will then convert this code's logic into its MPI version, run it on one core of the processor, and then gradually bring online the remaining cores. You will observe progressively improving processing speed as you activate successive cores. Let's start with the simple π equation:
This equation is one of many that are available for obtaining an approximate value of π. In later sections, we will explore a few more complex and famous equations that will give your supercomputer a more rigorous digital workout. The following code is the requisite serial C code representation of the equation depicted previously:
C_PI.c:
#include <math.h> // math library
#include <stdio.h>// Standard Input/Output library
int main(void)
{
long num_rects = 300000;//1000000000;
long i;
double x,height,width,area;
double sum;
width = 1.0/(double)num_rects; // width of a segment
sum = 0;
for(i = 0; i < num_rects; i++)
{
x = (i+0.5) * width; // x: distance to center of
i(th) segment
height = 4/(1.0 + x*x);
sum += height; // sum of individual segment heights
}
// approximate area of segment (Pi value)
area = width * sum;
printf("n");
printf(" Calculated Pi = %.16fn", area);
printf(" M_PI = %.16fn", M_PI);
printf("Relative error = %.16fn", fabs(area - M_PI));
return 0;
}
This code was written using the vim editor in the Linux terminal environment (click on the black monitor icon to open the terminal window). First, change the directory to the Desktop folder by entering the command cd Desktop. Now create a blank C filename C_PI.c (feel free to name your code anything you desire within the terminal window) by entering the command vim C_PI.c. Press i to initiate editing. Type or copy in the code as shown previously. Save the file by entering Esc :wq, which returns you to the $ prompt.
Finally, run the code using the time mpiexec C_PI command. The code will generate the output depicted in the following run. You may see four similar outputs, each emanating from a core in the four-core processor:
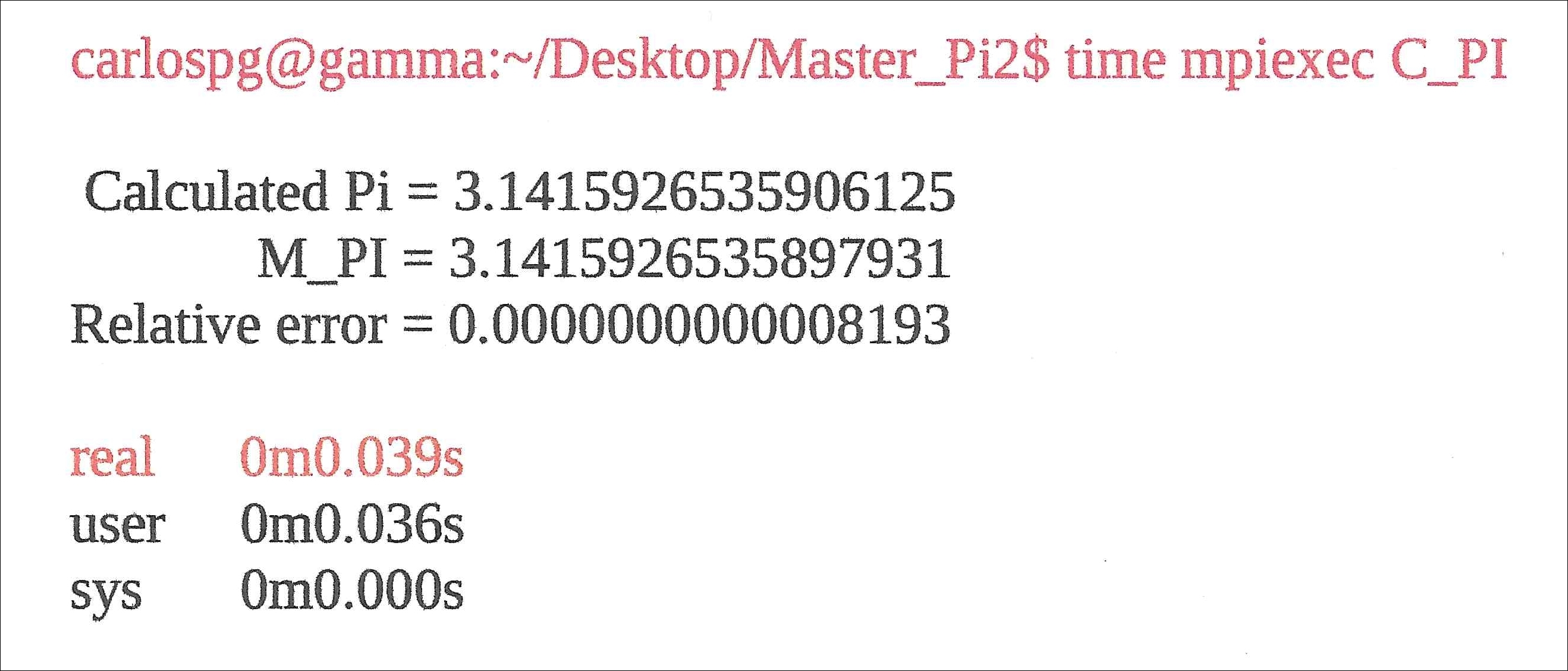
Feel free to modify the code by changing the value of num_rects (whose current value is 300,000), and observe the change in the accuracy of the calculation. The code's calculation time should change accordingly. Note that this calculation ran on only one core. The calculation or task was not shared/divided among the four cores. The run time of (0m0.039s), highlighted in red, is a function of the relatively fast 4 GHz processor. Your processor may have a slower speed, and hence the computation time may be somewhat elevated. We now proceed to that much vaunted MPI protocol.