We will now investigate four widely used math equations. Three of these equations are the trigonometric functions; sine, cosine, and tangent, and one is the natural log function. We will parallelize the Taylor series expansion of the trigonometric, and the natural log functions.
The form of the preceding equations lends themselves to easy parallelization, and hence we will be using the programming structure you previously experimented with. We will initially start with the serial representation of the functions, and then proceed to modify/convert said functions to their MPI versions. The unrestrained Pi supercomputer will quickly demolish these equations while using only a few processors. In fact, using the entire super cluster would be overkill in most of the following exercises - much like bringing a heavy machine gun to a fist fight, as they say, but the exercises serve to strengthen the reader's MPI programming skills - albeit employing only a small portion of the extensive MPI library. So, let's now proceed to have more fun programming our machine.
In this chapter, you will learn:
- How to write and run the serial Taylor series expansion
sine(x)function - How to write and run the MPI Taylor series expansion
sine(x)function - How to write and run the serial Taylor series expansion
cosine(x)function - How to write and run the MPI Taylor series expansion
cosine(x)function - How to write and run a
combinationserial Taylor series expansiontangent(x)function - How to write and run the
combinationMPI Taylor series expansiontangent(x)function - How to write and run the serial Taylor series expansion
ln(x)function - How to write and run the MPI Taylor series expansion
ln(x)function
Note
The codes were initially developed and debugged on the author's main PC. The .c files were subsequently SFTP over to the master node on his Pi3 super cluster where the codes were then compiled in the export gamma folder. The following runs were generated using only 16 of 64 processors on the author's Pi3 supercomputer. Proceed to doing the upcoming exercises.
Start with the following Taylor series sine(x) function:
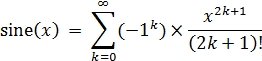
On the master node, write, compile, and run this serial sine(x) code (see the following screenshot, which shows serial sine(x) code) to get a feel of the program:
/*********************************
* Serial sine(x) code. *
* *
* Taylor series representation *
* of the trigonometric sine(x). *
* *
* Author: Carlos R. Morrison *
* *
* Date: 1/10/2017 *
*********************************/
#include <math.h>
#include <stdio.h>
int main(void)
{
unsigned int j;
unsigned long int k;
long long int B,D;
int num_loops = 17;
float y;
double x;
double sum0=0,A,C,E;
/******************************************************/
printf("
");
printf("Enter angle(deg.):
");
printf("
");
scanf("%f",&y);
if(y <= 180.0)
{
x = y*(M_PI/180.0);
}
else
x = -(360.0-y)*(M_PI/180.0);
/******************************************************/
sum0 = 0;
for(k = 0; k < num_loops; k++)
{
A = (double)pow(-1,k);// (-1^k)
B = 2*k+1;
C = (double)pow(x,B);// x^(2k+1)
D = 1;
for(j=1; j <= B; j++)// (2k+1)!
{
D *= j;
}
E = (A*C)/(double)D;
sum0 += E;
}// End of for(k = 0; k < num_loops; k++)
printf("
");
printf(" %.1f deg. = %.3f rads
", y, x);
printf("Sine(%.1f) = %.4f
", y, sum0);
return 0;
}
Next, write, compile, and run the MPI version of the preceding serial sine(x) code (see the following MPI sine(x) code), using one processor from each of the 16 nodes:
/*********************************
* MPI sine(x) code. *
* *
* Taylor series representation *
* of the trigonometric sine(x). *
* *
* Author: Carlos R. Morrison *
* *
* Date: 1/10/2017 *
*********************************/
#include <mpi.h> // (Open)MPI library
#include <math.h> // math library
#include <stdio.h>// Standard Input/Output library
int main(int argc, char*argv[])
{
long long int total_iter,B,D;
int n = 17,rank,length,numprocs,i,j;
unsigned long int k;
double sum,sum0,rank_integral,A,C,E;
float y,x;
char hostname[MPI_MAX_PROCESSOR_NAME];
MPI_Init(&argc, &argv); // initiates MPI
MPI_Comm_size(MPI_COMM_WORLD, &numprocs); // acquire number of processes
MPI_Comm_rank(MPI_COMM_WORLD, &rank); // acquire current process id
MPI_Get_processor_name(hostname, &length); // acquire hostname
if (rank == 0)
{
printf("
");
printf("#######################################################");
printf("
");
printf("*** Number of processes: %d
",numprocs);
printf("*** processing capacity: %.1f GHz.
",numprocs*1.2);
printf("
");
printf("Master node name: %s
", hostname);
printf("
");
printf("Enter angle(deg.):
");
printf("
");
scanf("%f",&y);
if(y <= 180.0)
{
x = y*(M_PI/180.0);
}
else
x = -(360.0-y)*(M_PI/180.0);
}
// broadcast to all processes, the number of segments you want
MPI_Bcast(&n, 1, MPI_INT, 0, MPI_COMM_WORLD);
MPI_Bcast(&x, 1, MPI_INT, 0, MPI_COMM_WORLD);
// this loop increments the maximum number of iterations, thus providing
// additional work for testing computational speed of the processors
// for(total_iter = 1; total_iter < n; total_iter++)
{
sum0 = 0.0;
// for(i = rank + 1; i <= total_iter; i += numprocs)
for(i = rank + 1; i <= n; i += numprocs)
{
k = (i-1);
A = (double)pow(-1,k);// (-1^k)
B = 2*k+1;
C = (double)pow(x,B);// x^(2k+1)
D = 1;
for(j=1; j <= B; j++)// (2k+1)!
{
D *= j;
}
E = (A*C)/(double)D;
sum0 += E;
}
rank_integral = sum0;// Partial sum for a given rank
// collect and add the partial sum0 values from all processes
MPI_Reduce(&rank_integral, &sum, 1, MPI_DOUBLE,MPI_SUM, 0,
MPI_COMM_WORLD);
}// End of for(total_iter = 1; total_iter < n; total_iter++)
if(rank == 0)
{
printf("
");
printf(" %.1f deg. = %.3f rads
", y, x);
printf("Sine(%.3f) = %.3f
", x, sum);
}
// clean up, done with MPI
MPI_Finalize();
return 0;
}// End of int main(int argc, char*argv[])
Let's have a look at the MPI sine(x) run:
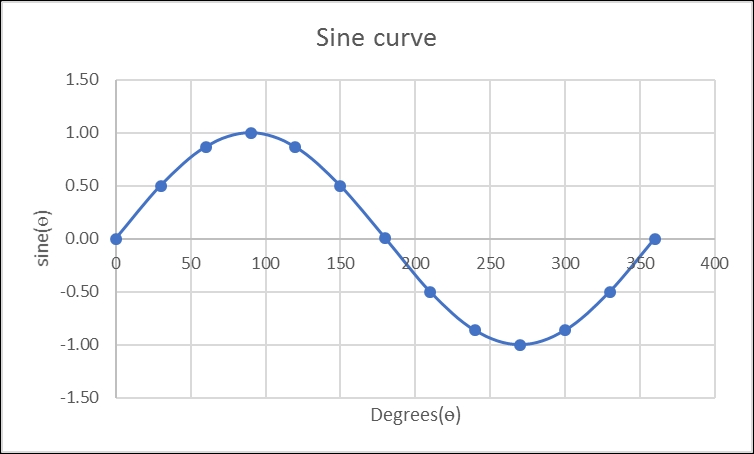
alpha@Mst0:/beta/gamma $ time mpiexec -H Mst0,Slv1,Slv2,Slv3,Slv4,Slv5,Slv6,Slv7,Slv8, Slv9,Slv10,Slv11,Slv12,Slv13,Slv14,Slv15 MPI_sine ####################################################### *** Number of processes: 16 *** processing capacity: 19.2 GHz. Master node name: Mst0 Enter angle(deg.): 0 0.0 deg. = 0.000 rads Sine(0.000) = 0.000 real 0m10.404s user 0m1.290s sys 0m0.280s alpha@Mst0:/beta/gamma $ time mpiexec -H Mst0,Slv1,Slv2,Slv3,Slv4,Slv5,Slv6,Slv7,Slv8, Slv9,Slv10,Slv11,Slv12,Slv13,Slv14,Slv15 MPI_sine ####################################################### *** Number of processes: 16 *** processing capacity: 19.2 GHz. Master node name: Mst0 Enter angle(deg.): 30 30.0 deg. = 0.524 rads Sine(0.524) = 0.500 real 0m11.621s user 0m1.270s sys 0m0.330s alpha@Mst0:/beta/gamma $ time mpiexec -H Mst0,Slv1,Slv2,Slv3,Slv4,Slv5,Slv6,Slv7,Slv8, Slv9,Slv10,Slv11,Slv12,Slv13,Slv14,Slv15 MPI_sine ####################################################### *** Number of processes: 16 *** processing capacity: 19.2 GHz. Master node name: Mst0 Enter angle(deg.): 60 60.0 deg. = 1.047 rads Sine(1.047) = 0.866 real 0m6.494s user 0m1.230s sys 0m0.340s alpha@Mst0:/beta/gamma $ time mpiexec -H Mst0,Slv1,Slv2,Slv3,Slv4,Slv5,Slv6,Slv7,Slv8, Slv9,Slv10,Slv11,Slv12,Slv13,Slv14,Slv15 MPI_sine ####################################################### *** Number of processes: 16 *** processing capacity: 19.2 GHz. Master node name: Mst0 Enter angle(deg.): 90 90.0 deg. = 1.571 rads Sine(1.571) = 1.000 real 0m10.090s user 0m1.200s sys 0m0.380s alpha@Mst0:/beta/gamma $ time mpiexec -H Mst0,Slv1,Slv2,Slv3,Slv4,Slv5,Slv6,Slv7,Slv8, Slv9,Slv10,Slv11,Slv12,Slv13,Slv14,Slv15 MPI_sine ####################################################### *** Number of processes: 16 *** processing capacity: 19.2 GHz. Master node name: Mst0 Enter angle(deg.): 120 120.0 deg. = 2.094 rads Sine(2.094) = 0.866 real 0m4.674s user 0m1.220s sys 0m0.370s alpha@Mst0:/beta/gamma $ time mpiexec -H Mst0,Slv1,Slv2,Slv3,Slv4,Slv5,Slv6,Slv7,Slv8, Slv9,Slv10,Slv11,Slv12,Slv13,Slv14,Slv15 MPI_sine ####################################################### *** Number of processes: 16 *** processing capacity: 19.2 GHz. Master node name: Mst0 Enter angle(deg.): 150 150.0 deg. = 2.618 rads Sine(2.618) = 0.500 real 0m6.942s user 0m1.240s sys 0m0.360s alpha@Mst0:/beta/gamma $ time mpiexec -H Mst0,Slv1,Slv2,Slv3,Slv4,Slv5,Slv6,Slv7,Slv8, Slv9,Slv10,Slv11,Slv12,Slv13,Slv14,Slv15 MPI_sine ####################################################### *** Number of processes: 16 *** processing capacity: 19.2 GHz. Master node name: Mst0 Enter angle(deg.): 180 180.0 deg. = 3.142 rads Sine(3.142) = 0.007 real 0m7.757s user 0m1.190s sys 0m0.370s alpha@Mst0:/beta/gamma $ time mpiexec -H Mst0,Slv1,Slv2,Slv3,Slv4,Slv5,Slv6,Slv7,Slv8, Slv9,Slv10,Slv11,Slv12,Slv13,Slv14,Slv15 MPI_sine ####################################################### *** Number of processes: 16 *** processing capacity: 19.2 GHz. Master node name: Mst0 Enter angle(deg.): 210 210.0 deg. = -2.618 rads Sine(-2.618) = -0.500 real 0m9.312s user 0m1.280s sys 0m0.480s alpha@Mst0:/beta/gamma $ time mpiexec -H Mst0,Slv1,Slv2,Slv3,Slv4,Slv5,Slv6,Slv7,Slv8, Slv9,Slv10,Slv11,Slv12,Slv13,Slv14,Slv15 MPI_sine ####################################################### *** Number of processes: 16 *** processing capacity: 19.2 GHz. Master node name: Mst0 Enter angle(deg.): 240 240.0 deg. = -2.094 rads Sine(-2.094) = -0.866 real 0m7.053s user 0m1.300s sys 0m0.320s alpha@Mst0:/beta/gamma $ time mpiexec -H Mst0,Slv1,Slv2,Slv3,Slv4,Slv5,Slv6,Slv7,Slv8, Slv9,Slv10,Slv11,Slv12,Slv13,Slv14,Slv15 MPI_sine ####################################################### *** Number of processes: 16 *** processing capacity: 19.2 GHz. Master node name: Mst0 Enter angle(deg.): 270 270.0 deg. = -1.571 rads Sine(-1.571) = -1.000 real 0m9.521s user 0m1.220s sys 0m0.340s alpha@Mst0:/beta/gamma $ time mpiexec -H Mst0,Slv1,Slv2,Slv3,Slv4,Slv5,Slv6,Slv7,Slv8, Slv9,Slv10,Slv11,Slv12,Slv13,Slv14,Slv15 MPI_sine ####################################################### *** Number of processes: 16 *** processing capacity: 19.2 GHz. Master node name: Mst0 Enter angle(deg.): 300 300.0 deg. = -1.047 rads Sine(-1.047) = -0.866 real 0m20.375s user 0m1.260s sys 0m0.330s alpha@Mst0:/beta/gamma $ time mpiexec -H Mst0,Slv1,Slv2,Slv3,Slv4,Slv5,Slv6,Slv7,Slv8, Slv9,Slv10,Slv11,Slv12,Slv13,Slv14,Slv15 MPI_sine ####################################################### *** Number of processes: 16 *** processing capacity: 19.2 GHz. Master node name: Mst0 Enter angle(deg.): 330 330.0 deg. = -0.524 rads Sine(-0.524) = -0.500 real 0m7.629s user 0m1.440s sys 0m0.350s alpha@Mst0:/beta/gamma $ time mpiexec -H Mst0,Slv1,Slv2,Slv3,Slv4,Slv5,Slv6,Slv7,Slv8, Slv9,Slv10,Slv11,Slv12,Slv13,Slv14,Slv15 MPI_sine ####################################################### *** Number of processes: 16 *** processing capacity: 19.2 GHz. Master node name: Mst0 Enter angle(deg.): 360 360.0 deg. = -0.000 rads Sine(-0.000) = 0.000 real 0m11.463s user 0m1.260s sys 0m0.290s
The following figure is a plot of the MPI sine(x) run: