
The Taylor series formula for the ln(x) function is as follows:
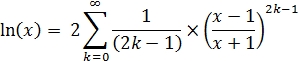
Write, compile, and run this Serial ln(x) code (see the following screenshot, which shows Serial ln(x) code) to get a feel of the program:
/*********************************
* Serial ln(x) code. *
* *
* Taylor series representation *
* of the trigonometric ln(x). *
* *
* Author: Carlos R. Morrison *
* *
* Date: 1/10/2017 *
*********************************/
#include <math.h>
#include <stdio.h>
int main(void)
{
Unsigned int n;
Unsigned long int k;
double A,B,C;
double sum=0;
long int num_loops;
float x,y;
/******************************************************/
printf("
");
printf("
");
printf("Enter the number of iterations:
");
printf("
");
scanf("%d",&n);
printf("
");
Z:printf("Enter x value:
");
printf("
");
scanf("%f",&y);
if(y > 0.0)
{
x = y;
}
else
{
printf("
");
printf("Bad input!! Please try another value
");
printf("
");
goto Z;
}
/******************************************************/
sum = 0;
for(k = 1; k < n; k++)
{
A = 1.0/(double)(2*k-1);
B = pow(((x-1)/(x+1)),(2*k-1));
C = A*B;
sum += C;
}
printf("
");
printf("ln(%.1f) = %.16f
", y, 2.0*sum);
printf("
");
return 0;
}
Next, write, compile, and run the MPI version of the preceding serial ln(x) code (see MPI ln(x) code below), using one processor from each of the 16 nodes.
/*********************************
* MPI ln(x) code. *
* *
* Taylor series representation *
* of the trigonometric ln(x). *
* *
* Author: Carlos R. Morrison *
* *
* Date: 1/10/2017 *
*********************************/
#include <mpi.h>
#include <math.h>
#include <stdio.h>
int main(int argc, char*argv[])
{
/******************************************************/
long long int total_iter;
Unsigned int n;
Unsigned long int k;
int rank,length,numprocs,i;
float x,y;
double sum,sum0,A,C,B,rank_sum;
char hostname[MPI_MAX_PROCESSOR_NAME];
MPI_Init(&argc, &argv); // initiates MPI
MPI_Comm_size(MPI_COMM_WORLD, &numprocs); // acquire number of processes
MPI_Comm_rank(MPI_COMM_WORLD, &rank); // acquire current process id
MPI_Get_processor_name(hostname, &length); // acquire hostname
/******************************************************/
if(rank == 0)
{
printf("
");
printf("#######################################################");
printf("
");
printf("*** Number of processes: %d
",numprocs);
printf("*** processing capacity: %.1f GHz.
",numprocs*1.2);
printf("
");
printf("Master node name: %s
", hostname);
printf("
");
printf("
");
printf("Enter the number of iterations:
");
printf("
");
scanf("%d",&n);
printf("
");
Z:printf("Enter x value:
");
printf("
");
scanf("%f",&y);
if(y > 0.0)
{
x = y;
}
else
{
printf("
");
printf("Bad input!! Please try another value
");
printf("
");
goto Z;
}
}// End of if(rank == 0)
// broadcast to all processes, the number of segments you want
MPI_Bcast(&n, 1, MPI_INT, 0, MPI_COMM_WORLD);
MPI_Bcast(&x, 1, MPI_INT, 0, MPI_COMM_WORLD);
//this loop increments the maximum number of iterations, thus providing
//additional work for testing computational speed of the processors
//for(total_iter = 1; total_iter < n; total_iter++)
{
sum0 = 0.0;
// for(i = rank + 1; i <= total_iter; i += numprocs)
for(i = rank + 1; i <= n; i += numprocs)
{
k = i;
A = 1.0/(double)(2*k-1);
B = pow(((x-1)/(x+1)),(2*k-1));
C = A*B;
sum0 += C;
}
rank_sum = sum0;// Partial sum for a given rank
// collect and add the partial sum0 values from all processes
MPI_Reduce(&rank_sum, &sum, 1, MPI_DOUBLE,MPI_SUM, 0, MPI_COMM_WORLD);
}// End of for(total_iter = 1; total_iter < n; total_iter++)
if(rank == 0)
{
printf("
");
printf("ln(%.1f) = %.16f
", y, 2.0*sum);
printf("
");
}
//clean up, done with MPI
MPI_Finalize();
return 0;
}// End of int main(int argc, char*argv[])
Let's look at the MPI ln(x) run:
alpha@Mst0:/beta/gamma $ time mpiexec -H Mst0,Slv1,Slv2,Slv3,Slv4,Slv5,Slv6,Slv7,Slv8, Slv9,Slv10,Slv11,Slv12,Slv13,Slv14,Slv15 MPI_ln ####################################################### *** Number of processes: 16 *** processing capacity: 19.2 GHz. Master node name: Mst0 Enter the number of iterations: 500000 Enter x value: 0.5 ln(0.5) = -0.6931472029116872 real 0m16.654s user 0m1.300s sys 0m0.300s alpha@Mst0:/beta/gamma $ time mpiexec -H Mst0,Slv1,Slv2,Slv3,Slv4,Slv5,Slv6,Slv7,Slv8, Slv9,Slv10,Slv11,Slv12,Slv13,Slv14,Slv15 MPI_ln ####################################################### *** Number of processes: 16 *** processing capacity: 19.2 GHz. Master node name: Mst0 Enter the number of iterations: 500000 Enter x value: 1.0 ln(1.0) = 0.0000000000000000 real 0m12.230s user 0m1.220s sys 0m0.370s alpha@Mst0:/beta/gamma $ time mpiexec -H Mst0,Slv1,Slv2,Slv3,Slv4,Slv5,Slv6,Slv7,Slv8, Slv9,Slv10,Slv11,Slv12,Slv13,Slv14,Slv15 MPI_ln ####################################################### *** Number of processes: 16 *** processing capacity: 19.2 GHz. Master node name: Mst0 Enter the number of iterations: 500000 Enter x value: 3 ln(3.0) = 1.0986122886681096 real 0m14.623s user 0m1.350s sys 0m0.230s alpha@Mst0:/beta/gamma $ time mpiexec -H Mst0,Slv1,Slv2,Slv3,Slv4,Slv5,Slv6,Slv7,Slv8, Slv9,Slv10,Slv11,Slv12,Slv13,Slv14,Slv15 MPI_ln ####################################################### *** Number of processes: 16 *** processing capacity: 19.2 GHz. Master node name: Mst0 Enter the number of iterations: 500000 Enter x value: 5 ln(5.0) = 1.6094379839596757 real 0m15.789s user 0m1.350s sys 0m0.310s alpha@Mst0:/beta/gamma $ time mpiexec -H Mst0,Slv1,Slv2,Slv3,Slv4,Slv5,Slv6,Slv7,Slv8, Slv9,Slv10,Slv11,Slv12,Slv13,Slv14,Slv15 MPI_ln ####################################################### *** Number of processes: 16 *** processing capacity: 19.2 GHz. Master node name: Mst0 Enter the number of iterations: 500000 Enter x value: 7 ln(7.0) = 1.9459101490553135 real 0m13.423s user 0m1.450s sys 0m0.370s alpha@Mst0:/beta/gamma $ time mpiexec -H Mst0,Slv1,Slv2,Slv3,Slv4,Slv5,Slv6,Slv7,Slv8, Slv9,Slv10,Slv11,Slv12,Slv13,Slv14,Slv15 MPI_ln ####################################################### *** Number of processes: 16 *** processing capacity: 19.2 GHz. Master node name: Mst0 Enter the number of iterations: 500000 Enter x value: 10 ln(10.0) = 2.3025850602114915 real 0m13.351s user 0m1.300s sys 0m0.420s alpha@Mst0:/beta/gamma $ time mpiexec -H Mst0,Slv1,Slv2,Slv3,Slv4,Slv5,Slv6,Slv7,Slv8, Slv9,Slv10,Slv11,Slv12,Slv13,Slv14,Slv15 MPI_ln ####################################################### *** Number of processes: 16 *** processing capacity: 19.2 GHz. Master node name: Mst0 Enter the number of iterations: 500000 Enter x value: 15 ln(15.0) = 2.7080502011022105 real 0m15.841s user 0m1.280s sys 0m0.410s alpha@Mst0:/beta/gamma $ time mpiexec -H Mst0,Slv1,Slv2,Slv3,Slv4,Slv5,Slv6,Slv7,Slv8,Slv9, Slv10,Slv11,Slv12,Slv13,Slv14,Slv15 MPI_ln ####################################################### *** Number of processes: 16 *** processing capacity: 19.2 GHz. Master node name: Mst0 Enter the number of iterations: 500000 Enter x value: 20 ln(20.0) = 2.9957323361388699 real 0m15.444s user 0m1.250s sys 0m0.370s alpha@Mst0:/beta/gamma $ time mpiexec -H Mst0,Slv1,Slv2,Slv3,Slv4,Slv5,Slv6,Slv7,Slv8, Slv9,Slv10,Slv11,Slv12,Slv13,Slv14,Slv15 MPI_ln ####################################################### *** Number of processes: 16 *** processing capacity: 19.2 GHz. Master node name: Mst0 Enter the number of iterations: 500000 Enter x value: 25 ln(25.0) = 3.2188758868570337 real 0m18.145s user 0m1.330s sys 0m0.280s alpha@Mst0:/beta/gamma $ time mpiexec -H Mst0,Slv1,Slv2,Slv3,Slv4,Slv5,Slv6,Slv7,Slv8, Slv9,Slv10,Slv11,Slv12,Slv13,Slv14,Slv15 MPI_ln ####################################################### *** Number of processes: 16 *** processing capacity: 19.2 GHz. Master node name: Mst0 Enter the number of iterations: 500000 Enter x value: 30 ln(30.0) = 3.4011974124578881 real 0m15.000s user 0m1.270s sys 0m0.360s
The following figure is a plot of the MPI ln(x) run:

..................Content has been hidden....................
You can't read the all page of ebook, please click here login for view all page.