
CHAPTER 8
Security Solutions for Infrastructure Management
In this chapter you will learn:
• Common network architectures and their security implications
• How to manage assets and changes
• Technologies and policies used to identify, authenticate, and authorize users
• Different types of encryption and when to use them
You can’t build a great building on a weak foundation.
—Gordon B. Hinckley
In Part I of this book, we looked at how adversaries operate against our systems. We now turn our attention to the architectural foundations of the systems they’ll be attacking and we are defending. Though we would all agree that it is difficult to protect something we don’t understand, a remarkable number of security professionals are not fully aware of all that is in and on their networks. This situation is further complicated by the fact that a rapidly shrinking number of organizations have anything resembling a physical perimeter. Most modern computing environments involve a mix of local and remote resources, some physical and some virtual, with many of them moving to various forms of cloud computing platforms.
As a cybersecurity analyst, you don’t need to be an expert in all of the various technologies that make up your network. However, you do need to have a working knowledge of them, with an emphasis on those that impact security the most. You should be tracking not only these technologies, but also the manner in which they are implemented in your environment and, just as importantly, the way in which changes to assets and their configurations impact security. For example, many organizations that have carefully deployed strong defenses are experiencing them gradually eroding because of seemingly inconsequential configuration changes. The solution is to have good processes and programs around tracking your assets and deliberately managing changes in their configurations.
In addition to having a solid grip on your network architecture and an understanding of the importance of (and how to do) asset and change management, you also need to deepen your knowledge of how to identify, authenticate, and authorize system users. This is true regardless of where users are located, what resources they’re trying to use, and what they intend to do with them. A central topic in this regard is cryptography, so we’ll spend a good amount of time reviewing the concepts that make it work.
Cloud vs. On-Premises Solutions
As we saw in Chapter 6, cloud computing refers to an extensive range of services enabled by high-performance, distributed computing. They generally require only a network connection to the service provider, which handles most of the computation and storage. By contrast, on-premises solutions involve hardware and software that are physically located within the organization. Although there has been much debate about which approach is intrinsically more secure, in reality the answer is complicated.
With most cloud solutions, service providers are responsible for some (or even most) of the security controls. They do this at scale, which means they make extensive use of automation to secure their infrastructure. If you go with well-known cloud providers, they’ll probably have really good security teams and controls. Depending on the capabilities in your own staff, this may make it easier for you to achieve a better cybersecurity posture. Your team still has an important role to play, but the burden can be largely shifted to your provider.
It is important to keep in mind that some critical cloud security controls are different from those you’d use in on-premises environments. This means that you can’t completely rely on your service provider to handle every control. For example, misconfigurations account for the lion’s share of compromises in cloud environments. Misconfigured permissions, in particular, are behind most of the incidents you’ve heard or read about in the news. This vulnerability is exacerbated by some organizations’ failure to encrypt sensitive data in the cloud. The underlying problem for both these commonly exploited vulnerabilities is not that the cloud is insecure, but that the customer was using the cloud insecurely.
On the other hand, there are situations in which your organization may need or want to keep systems on premises. This makes a lot of sense when you’re dealing with cyber-physical systems (such as industrial control systems) or certain kinds of extremely sensitive data (such as national intelligence), or when you have the sunk costs (incurred costs that cannot be recovered) of an existing infrastructure and a well-resourced cybersecurity team. In these cases, your team will shoulder the entire burden of security unless you outsource some of that.
Most organizations are moving to cloud-based solutions primarily because of costs. Wherever your assets are stored, the security solutions you need for infrastructure management are fundamentally similar and yet different in subtle but important ways. The rest of this chapter will cover the infrastructure concepts you’ll need to know as a cybersecurity analyst.
Network Architecture
A network architecture refers to the nodes on a computer network and the manner in which they are connected to one another. There is no universal way to depict this, but it is common to, at least, draw the various subnetworks and the network devices (such as routers, firewalls) that connect them. It is also better to list the individual devices included in each subnet, at least for valuable resources such as servers, switches, and network appliances. The most mature organizations draw on their asset management systems to provide a rich amount of detail as well as helpful visualizations.
A network architecture should be prescriptive in that it should determine the way things shall be. It should not just be an exercise in documenting where things are but in placing them deliberately in certain places. Think of a network architecture as a military commander arraying her forces in defensive positions in preparation for an enemy assault. She wouldn’t go to her subordinates and ask where they want to be. Instead, she’d study the best available intelligence about the enemy capabilities and objectives, combine that with an understanding of her own mission and functions, and then place her forces intentionally.
In most cases, network architectures are hybrid constructs incorporating physical, software-defined, virtual, and cloud assets. Figure 8-1 shows a high-level example of a typical hybrid architecture. The following sections describe each of the architectures in use by many organizations.
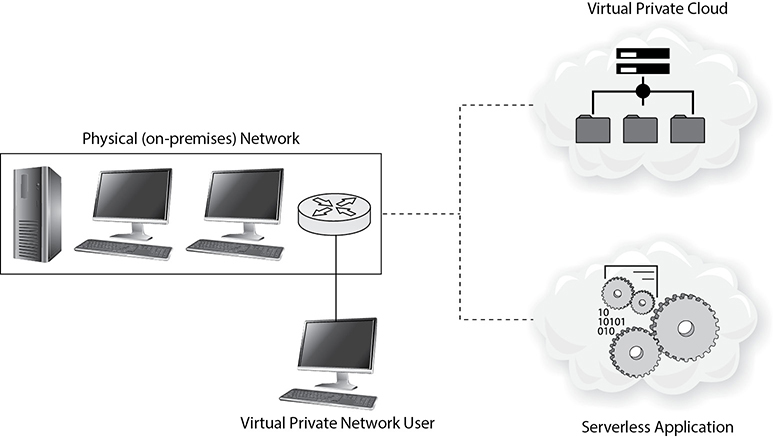
Figure 8-1 Hybrid network architecture
Physical Network
The most traditional network architecture is a physical one. In a physical network architecture, we describe the manner in which physical devices such as workstations, servers, firewalls, and routers relate to one another. Along the way, we decide what traffic is allowed from where to where and develop the policies that will control those flows. These policies are then implemented in the devices themselves, for example as firewall rules or access control lists (ACLs) in routers. Most organizations use a physical network architecture, or perhaps more than one. While physical network architectures are well known to everybody who’s ever taken a networking course at any level, they are limited in that they typically require static changes to individual devices to adapt to changing conditions.
Software-Defined Network
Software-defined networking (SDN) is a network architecture in which software applications are responsible for deciding how best to route data (the control layer) and then for actually moving those packets around (the data layer). This is in contrast to a physical network architecture in which each device needs to be configured by remotely connecting to it and giving it a fixed set of rules with which to make routing or switching decisions. Figure 8-2 shows how these two SDN layers enable networked applications to communicate with each other.
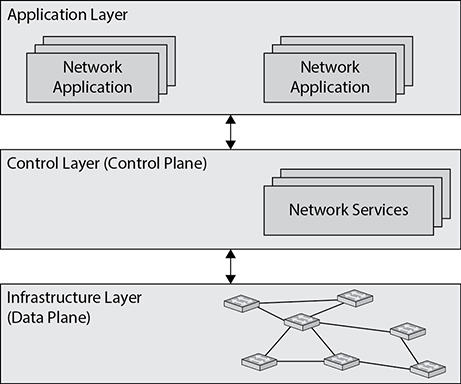
Figure 8-2 Overview of a software-defined networking architecture
One of the most powerful aspects of SDN is that it decouples data forwarding functions (the data plane) from decision-making functions (the control plane), allowing for holistic and adaptive control of how data moves around the network. In an SDN architecture, SDN is used to describe how nodes communicate with each other.
Virtual Private Cloud Network
One of the benefits of using cloud computing is that resources such as CPUs, memory, and networking are shared by multiple customers, which means we pay only for what we use, and we get to add resources seamlessly whenever we need them. The (security) challenge comes when we consider what those resources are doing when we are not using them: they’re being used by someone else. Although cloud computing service providers go to great lengths to secure their customers’ computing, shared resources can introduce a level of risk. For this reason, most enterprises that decide to host significant or sensitive parts of their assets on the cloud want more security than that.
A virtual private cloud (VPC) is a private set of resources within a public cloud environment. Any systems within the VPC can communicate with other systems as though they were all in the same physical or software-defined network architecture, though VPCs are hosted in the cloud. The “virtual” part differentiates this approach from a private cloud, in which the hardware resources are owned by the enterprise (not by a cloud service provider) and are typically in a private data center.
So if we want to compare a public cloud to a VPC or to a physical or SDN architecture, we could say that the public cloud is like living in an apartment with (generally) well-behaved roommates who are not always home (giving you the illusion of having the place to yourself). A VPC would be like living in a condo where nobody else has a key and you know you can have the place to yourself while enjoying the convenience of having someone else take care of the common areas, maintenance, and so on. A physical or SDN architecture would be like buying a lot and building your own house away from the neighbors.
Virtual Private Network
A virtual private network (VPN) provides a secure tunnel between two endpoints over some shared medium. This enables your users, for instance, to take their mobile devices to another country and connect to your network with the same amount of security they’d have if they were working in the same building. A VPN is most commonly created on demand between an endpoint and a network device (typically a router or VPN concentrator). VPNs can also be persistently established between network devices to create a VPN backbone between corporate locations such as branch offices and corporate headquarters.
VPNs are important architectural components, especially when supporting remote workers. Without VPNs, your staff would not be protected by any security controls that do not reside in their devices. For example, a user surfing the Web directly could more easily be compromised if she is not protected by your network security appliances. If she connects to your VPN, her traffic could go through the same controls that protect anyone who was in the office.
Perhaps the biggest drawback of using VPNs is that the appliances that terminate remote user connections can become bottlenecks and slow things down. A common way to mitigate this is to use the VPN only for some of the user traffic. A VPN split tunnel is a configuration in which the VPN client sends some traffic to the corporate gateway and enables other traffic to flow directly into the Internet. This configuration would be helpful if you were a remote worker and wanted to access your protected corporate systems but still print on the printer in your home office. The split tunnel could be configured to send all traffic to the gateway except that intended for the printer. Conversely, the tunnel could be configured to send only traffic to the gateway that is destined for corporate URLs and leave everything else (including the printer) outside the tunnel. The first scenario still enables your corporate security stack to protect you as you surf the Web, while the second case does not. Which is best is typically a complex decision, but, generally speaking, it is more secure not to use split tunneling, and if you must, to very selectively whitelist the destinations you’ll allow outside the tunnel.
Serverless Network
In a serverless network architecture (sorry, no acronym here), a relatively smart client (think single-page web application with a bunch of JavaScript or an applet) needs some specific functions provided by a cloud resource. Because of the focus on providing functions in the cloud, serverless architectures are sometimes called Function as a Service (FaaS) models.
A comparison may be helpful here. Suppose you have an online store that sells widgets. In a traditional client/server model, all the processing and data storage would be taken care of by one (or maybe two) servers hosted by your company. Whether you sell hundreds of widgets per hour or one every few weeks, you still need the server(s) standing by, waiting for orders, and this gets expensive in a hurry. Now, suppose you implement a serverless architecture in which your customers download a mobile app, which would be a fairly thick client with processing and storage functions. Whenever customers want to browse or search your catalog of widgets, their apps call functions on a cloud service, and those functions return the appropriate data, which is then further processed and rendered by the app. If they want to place a purchase, their app invokes a different set of functions that place the order and charge a credit card. Now you have no need to host web, application, or data servers; you just break it down into functions that are hosted by a cloud service provider, sit back, and rake in the money.
Virtualization
Virtualization is the creation and use of computer and network resources to allow for varied instances of operating systems and applications on an ad hoc basis. Virtualization technologies have revolutionized IT operations because they have vastly reduced the hardware needed to provide a wide array of service and network functions. Virtualization’s continued use has enabled large enterprises to achieve a great deal of agility in their IT operations without adding significant overhead. For the average user, virtualization has proven to be a low-cost way to gain exposure to new software and training. Although virtualization has been around since the early days of the Internet, it didn’t gain a foothold in enterprise and home computing until the 2000s.
Hypervisors
As previously described, virtualization is achieved by creating large pools of logical storage, CPUs, memory, networking, and applications that reside on a common physical platform. This is most commonly done using software called a hypervisor, which manages the physical hardware and performs the functions necessary to share those resources across multiple virtual instances. In short, one physical box can “host” a range of varied computer systems, or guests, thanks to clever hardware and software management.
Hypervisors are classified as either Type 1 or Type 2. Type-1 hypervisors are also referred to as bare-metal hypervisors, because the hypervisor software runs directly on the host computer hardware. Type-1 hypervisors have direct access to all hardware and manage guest operating systems. Today’s more popular Type-1 hypervisors include VMware ESXi, Microsoft Hyper-V, and Kernel-based Virtual Machine (KVM). Type-2 hypervisors are run from within an already existing operating system. These hypervisors act just like any other piece of software written for an operating system and enable guest operating systems to share the resources that the hypervisor has access to. Popular Type-2 hypervisors include VMware Workstation Player, Oracle VM VirtualBox, and Parallels Desktop.
Virtual Desktop Infrastructure
Traditionally, users log into a local workstation running an operating system that presents them resources available in the local host and, optionally, on remote systems. Virtual desktop infrastructure (VDI) separates the physical devices that the users are touching from the systems hosting the desktops, applications, and data. VDI comes in many flavors, but in the most common ones, the user’s device is treated as a thin client whose only job is to render an environment that exists on a remote system and relay user inputs to that system. A popular example of this is Microsoft Remote Desktop Protocol (RDP), which enables a Windows workstation to connect remotely to another workstation desktop and display that desktop locally. Another example is the Desktop as a Service (DaaS) cloud computing solution, in which the desktop, applications, and data are all hosted in a cloud service provider’s system to which the user can connect from a multitude of end devices.
VDI is particularly helpful in regulated environments because of the ease with which it supports data retention, configuration management, and incident response. If a user’s system is compromised, it can quickly be isolated for remediation or investigation, while a clean desktop is almost instantly spawned and presented to the user, reducing the downtime to seconds. VDI is also attractive when the workforce is highly mobile and may log in from a multitude of physical devices in different locations. Obviously, this approach is highly dependent on network connectivity. For this reason, organizations need to consider carefully their own network speed and latency when deciding how (or whether) to implement it.
Containerization
As virtualization software matured, a new branch called containers emerged. Whereas operating systems sit on top of hypervisors and share the resources provided by the bare metal, containers sit on top of operating systems and share the resources provided by the host OS. Instead of abstracting the hardware for guest operating systems, container software abstracts the kernel of the operating system for the applications running above it. This allows for low overhead in running many applications and improved speed in deploying instances, because a whole virtual machine doesn’t have to be started for every application. Rather, the application, services, processes, libraries, and any other dependencies can be wrapped up into one unit. Additionally, each container operates in a sandbox, with the only means to interact being through the user interface or application programming interface (API) calls. Containers have enabled rapid development operations, because developers can test their code more quickly, changing only the components necessary in the container and then redeploying.
Network Segmentation
Network segmentation is the practice of breaking up networks into smaller subnetworks. The subnetworks are accessible to one another through switches and routers in on-premises networks, or through VPCs and security groups in the cloud. Segmentation enables network administrators to implement granular controls over the manner in which traffic is allowed to flow from one subnetwork to another. Some of the goals of network segmentation are to thwart the adversary’s efforts, improve traffic management, and prevent spillover of sensitive data. Beginning at the physical layer of the network, segmentation can be implemented all the way up to the application layer.
Virtual Local Area Networks
Perhaps the most common method of providing separation at the link layer of the network is the use of virtual local area networks (VLANs). VLANs are enabled by network switches by applying a tag to each frame received at a port. This tag contains the VLAN identifier for that frame, based on the endpoint that sent it. The switch reads the tag to determine the port to which the frame should be forwarded. At the destination port, the tag is removed, and then the frame is sent to the destination host.
Properly configured, a VLAN enables various hosts to be part of the same network even if they are not physically connected to the same network equipment. Alternatively, a single switch could support multiple VLANs, greatly improving design and management of the network. Segmentation can also occur at the application level, preventing applications and services from interacting with others that may run on the same hardware. Keep in mind that segmenting a network at one layer doesn’t carry over to the higher layers. In other words, simply implementing VLANs is not enough if you also desire to segment based on the application protocol.
Physical Segmentation
Though the use of VLANs for internal network segmentation is the norm nowadays, some organizations still use physical segmentation. For example, many networks are segmented from the rest of the Internet using a firewall. Internally, they may also use traditional switching instead of VLANs. In this model, every port on a given switch belongs to the same subnetwork. If you want to move a host to a different subnetwork, you must physically change the connection to a switch in the different subnet. If you are using wireless LANs, you could run into interesting problems if your access points are not all connected to the same switch. For this reason, physical network segmentation makes most sense when dealing with cyber-physical systems that don’t (and shouldn’t) move around, such as those in industrial controls systems. It also makes sense when you want to keep things a bit simpler. Today, many organizations use a mixture of both virtual and physical segmentation.
Jump Boxes
To facilitate outside connections to segmented parts of the network, administrators sometimes designate a specially configured machine called a jump box, or jump server. As the name suggests, these computers serve as jumping off points for external users to access protected parts of a network. The idea is to keep special users from logging into a particularly important host using the same workstation they use for everything else. If that daily-use workstation were to become compromised, it could be used by an attacker to reach the sensitive nodes. If, on the other hand, these users are required to use a specially hardened jump box for these remote connections, it would be much more difficult for the attacker to reach the crown jewels.
A great benefit of jump boxes is that they serve as a chokepoint for outside users who want to gain access to a protected network. Accordingly, jump boxes often have high levels of activity logging enabled for auditing or forensic purposes. Figure 8-3 shows a very simple configuration of a jump box in a network environment. Notice the placement of the jump box in relation to the firewall device on the network. Although it may improve overall security to designate a sole point of access to the network, it’s critical that the jump box is carefully monitored, because a compromise of this server may allow access to the rest of the network. This means disabling any services or applications that are not necessary, using strict ACLs, keeping up-to-date with software patches, and using multifactor authentication where possible.
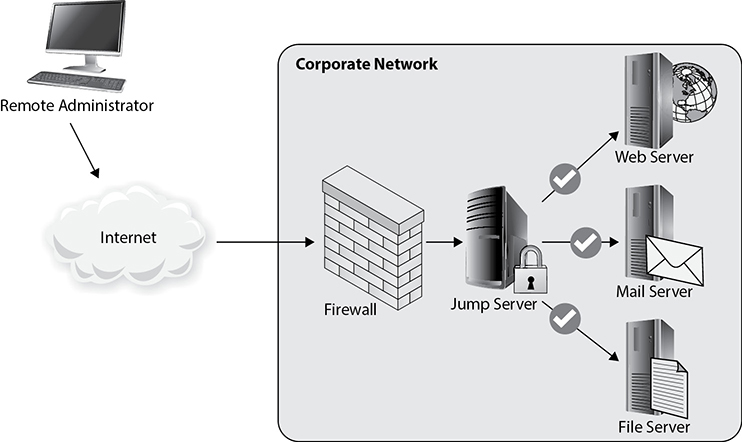
Figure 8-3 Network diagram of a simple jump box arrangement

EXAM TIP You will likely see jump boxes on the exam in the context of privileged account users (for example, system admins) using them to remotely log into sensitive hosts.
System Isolation
Even if the systems reside within the same subnetwork or VLAN, some systems should be communicating only with certain other systems, and it becomes apparent that something is amiss if you see loads of traffic outside of the expect norms. One way to ensure that hosts in your network are talking only to the machines they’re supposed to is to enforce system isolation. This can be achieved by implementing additional policies on network devices in addition to your segmentation plan. System isolation can begin with physically separating special machines or groups of machines with an air gap, which is a physical separation of these systems from outside connections. There are clearly tradeoffs in that these machines will not be able to communicate with the rest of the world. However, if they have only one specific job that doesn’t require external connectivity, it may make sense to separate them entirely. If a connection is required, you may be able to use ACLs to enforce policy. Like a firewall, an ACL allows or denies certain access, and it does this depending on a set of rules applicable to the layer it is operating on, usually at the network or file-system level. Although the practice of system isolation takes a bit of forethought, the return on investment for the time spent to set it up is huge.
Honeypots and Honeynets
Believe it or not, sometimes admins will design systems to attract attackers. Honeypots are a favorite tool for admins to learn more about adversaries’ goals by intentionally exposing a machine that appears to be a highly valuable, and sometimes unprotected, target. Although the honeypot may seem legitimate to the attacker, it is actually isolated from the normal network, and all its activity is being monitored and logged. This offers several benefits from a defensive point of view. By convincing an attacker to focus his efforts against the honeypot machine, an administrator can gain insight in the attacker’s tactics, techniques, and procedures (TTPs). This can be used to predict behavior or aid in identifying the attacker via historical data. Furthermore, honeypots may delay an attacker or force him to exhaust his resources in fruitless tasks.
Honeypots have been in use for several decades, but they have been difficult or costly to deploy because they often meant dedicating actual hardware to face attackers, thus reducing what could be used for production purposes. Furthermore, to engage an attacker for any significant amount of time, the honeypot needs to look like a real (and, ideally, valuable) network node, which means putting some thought into what software and data to put on it. This all takes lots of time and isn’t practical for very large deployments. Virtualization has come to the rescue and addresses many of the challenges associated with administering these machines because the technology scales easily and rapidly.
With a honeynet, the idea is that if some is good, then more is better. A honeynet is an entire network designed to attract attackers. The benefits of its use are the same as with honeypots, but these networks are designed to look like real network environments, complete with real operating systems, applications, services, and associated network traffic. You can think of honeynets as a highly interactive set of honeypots, providing realistic feedback as the real network would.
For both honeypots and honeynets, the services are not actually used in production, so there shouldn’t be any reason for legitimate interaction with the servers. You can therefore assume that any prolonged interaction with these services implies malicious intent. It follows that traffic from external hosts on the honeynet is the real deal and not as likely to be a false positive as in the real network. As with individual honeypots, all honeynet activity is monitored, recorded, and sometimes adjusted based on the desire of the administrators. Virtualization has also improved the performance of honeynets, allowing for varied network configurations on the same bare metal.
Asset Management
An asset is, by definition, anything of worth to an organization, including people, partners, equipment, facilities, reputation, and information. Though every asset needs to be protected, we restrict our discussion in this chapter to information technology assets, which include hardware, software, and the data that they store, process, and communicate. These assets, of course, exist in a context: They are acquired or created at a particular point in time through a specific process and (usually) for a purpose. They move through an organization, sometimes adding value and sometimes waiting to be useful. Eventually, they outlive their utility and must be disposed of appropriately, sometimes being replaced by a new asset. This is the asset lifecycle.
The process by which we manage an asset at every stage of its lifecycle is called IT Asset Management (ITAM). Effective ITAM provides a wealth of information that is critical to defending our information systems. For example, it lets us know the location, configuration, and user(s) of each computer. It enables us to know where each copy of a vulnerable software application exists so we can quickly patch it. Finally, it can tell us where every file containing sensitive data is stored so we can keep it from leaking out of our systems.
Asset Inventory
You cannot protect what you don’t know you have. Though inventorying assets is not what most of us would consider glamorous work, it is nevertheless a critical aspect of managing vulnerabilities in your information systems. In fact, this aspect of security is so important that it is prominently featured at the top of the list of Center for Internet Security (CIS) critical security controls (CIS Controls). CIS Control 1 is the inventory and control of authorized and unauthorized hardware assets, and CIS Control 2 deals with the software running on those devices.
Developing and maintaining an accurate asset inventory can be remarkably difficult. It is not simply about knowing how many computers you have, but also includes what software is installed in them, how they are configured, and to whom they are assigned. You also need to track software licenses (even the ones that are not in use), cloud assets, and sensitive data, just to name a few. If you didn’t inherit an accurate inventory from the last security professional at your organization, you’re probably going to have to discover those assets through some combination of physical and logical inspections. Even after you know what you have, you’ll need to track changes to these assets, such as software application updates or a computer reassignment.
Asset Tagging
Asset tagging is the practice of placing a uniquely identifiable label on an asset, ideally as part of its acquisition or creation process. For example, when you order a new computer, it should be tagged and added to the inventory immediately upon receipt, even before it is configured for use. If, in the next step, the asset will go to the IT department for imaging, the inventory will show that it is assigned to the staff member responsible for that. This person will configure the device and, you guessed it, update the inventory to show the baseline that was applied to it. When the asset is issued to its intended user, that person will be able to acknowledge receipt of it by checking the tag number. The asset tag enables anyone in the organization to check which particular piece of equipment they’re looking at.
Though some organizations still use visual inspection for checking asset tags, automated asset management tools make this process a lot more efficient. For this, you need tags that are machine-readable, which come in three main forms: barcode, Quick Response (QR) code, and radio frequency identification (RFID). Some tags implement multiple forms, so a tag could have both a barcode and an RFID chip, for example. You will obviously also need a reader that is integrated with your inventory management system so you can scan a tag and see the data pertaining to the corresponding asset.
An advantage of using RFID tags is that you could place readers in key places to alert when an asset is being moved. This geofencing works similarly to anti-theft systems in retail stores. Because it tracks asset movement, geofencing can be used to discourage people from taking company assets out of the building or even from moving those assets from one room (or area) to another within the same building. For example, if a tagged smart-board on wheels is supposed to stay in the conference room, you could place a RFID reader by the door that would sound an alarm if someone tried to roll the board outside the room.
Change Management
You can see that a tremendous amount of effort goes into managing the recommended actions following a vulnerability scan. Although implementing every recommendation may seem like a good idea on the surface, we cannot do this all at once. Without a systematic approach to managing all the necessary security changes, we risk putting ourselves in a worse place than when we began. The purpose of establishing formal communication and change management procedures is to ensure that the right changes are made the first time, that services remain available, and that resources are used efficiently throughout the changes.
In the context of cybersecurity, change management is the process of identifying, analyzing, and implementing changes to information systems in a way that addresses both business and security requirements. This is not an IT or cybersecurity function but one that should involve the entire organization and requires executive leadership and support from all business areas. There are usually (at least) three key roles in this process:
• Requestor The person or unit that requests the change and needs to make the business case for it
• Review board A group of representatives from various units in the organization that is responsible for determining whether the change is worth making and, if so, what its priority is
• Owner The individual or unit that is responsible for implementing and documenting the change, which may or may not be the requestor
Routine change requests should be addressed by the board on a regularly scheduled basis. Many boards meet monthly but have procedures in place to handle emergency requests that can’t wait until the next meeting. Each change is validated and analyzed for risk so that any required security controls (and their related costs) are considered in the final decision. If the change is approved, an owner is assigned to see it through completion.
Identity and Access Management
Before users are able to access resources, they must first prove they are who they claim to be and that they have been given the necessary rights or privileges to perform the actions they are requesting. Even after these steps are completed successfully and a user can access and use network resources, that user’s activities must be tracked, and accountability must be enforced for whatever actions they take. Identification describes a method by which a subject (user, program, or process) claims to have a specific identity (username, account number, or e-mail address). Authentication is the process by which a system verifies the identity of the subject, usually by requiring a piece of information that only the claimed identity should have. This piece could be a password, passphrase, cryptographic key, personal identification number (PIN), anatomical attribute, or token. Together, the identification and authentication information (for example, username and password) make up the subject’s credentials. Credentials are compared to information that has been previously stored for this subject. If the credentials match the stored information, the subject is authenticated. The system can then perform authorization, which is a check against some type of policy to verify that this user has indeed been authorized to access the requested resource and perform the requested actions.
Identity and access management (IAM) is a broad term that encompasses the use of different technologies and policies to identify, authenticate, and authorize users through automated means. It usually includes user account management, access control, credential management, single sign-on (SSO) functionality, rights and permissions management for user accounts, and the auditing and monitoring of all of these items. IAM enables organizations to create and manage digital identities’ lifecycles (create, maintain, terminate) in a timely and automated fashion.
Privilege Management
Over time, as users change roles or move from one department to another, they often are assigned more and more access rights and permissions. This is commonly referred to as authorization creep. This can pose a large risk for a company, because too many users may have too much privileged access to company assets. In immature organizations, it may be considered easier for network administrators to grant users more access than less; then a user would not later ask for authorization changes that would require more work to be done on her profile as her role changed. It can also be difficult to know the exact access levels different individuals require. This is why privilege management is a critical security function that should be regularly performed and audited. Enforcing least privilege on user accounts should be an ongoing job, which means each user’s permissions should be reviewed regularly to ensure the company is not putting itself at risk.
This is particularly true of administrator or other privileged accounts, because these allow users (legitimate or otherwise) to do things such as create new accounts (even other privileged ones), run processes remotely on other computers, and install or uninstall software. Because of the power privileged accounts have, they are frequently among the first targets for an attacker.
Here are some best practices for managing privileged accounts:
• Minimize the number of privileged accounts.
• Ensure that each administrator has a unique account (that is, no shared accounts).
• Elevate user privileges only when necessary, after which time the user should return to regular account privileges.
• Maintain an accurate, up-to-date account inventory.
• Monitor and log all privileged actions.
• Enforce multifactor authentication.
Sooner or later every account gets deprovisioned. For users, this is usually part of the termination procedures. For system accounts, this could happen because you got rid of a system or because some configuration change rendered an account unnecessary. If this is the case, you must ensure that this is included in your standard change management process. Whatever the type of account or the reason for getting rid of it, it is important that you document the change so you no longer track that account for reviewing purposes.
Multifactor Authentication
Authentication is still largely based on credentials consisting of a username and a password. If a password is the only factor used in authenticating the account, this approach is considered single-factor authentication. Multifactor authentication (MFA) just means that more than one authentication factor is used. Two-factor authentication (2FA) is perhaps the most common form of authentication and usually relies on a code that is valid for only a short time, which is provided to the user by another system. For example, when logging into your bank from a new computer, you may enter your username and password and then be required to provide a six-digit code. This code is provided by a separate application (such as Google Authenticator) and changes every 30 seconds. Some organizations will text a similar verification code to a user’s mobile phone (though this approach is no longer considered secure) if, for example, you’ve forgotten your password and need to create a new one. For even more security, three-factor authentication (3FA), such as a smart card, PIN, and retinal scan, is used, particularly in government scenarios.
Single Sign-On
Employees typically need to access many different computers, communications services, web applications, and other resources throughout the course of a day to complete their tasks. This could require the employees to remember multiple credentials for these different resources. Single sign-on (SSO) enables users to authenticate only once and then be able to access all their authorized resources regardless of where they are.
Using SSO offers benefits both to the user and the administrator sides. Users need to remember only a single password or PIN, which reduces the fatigue associated with managing multiple passwords. Additionally, they’ll save time by not having to reenter credentials for every service desired. For the administrator, using SSO means fewer calls from users who forget their passwords. Figure 8-4 shows the flow of an SSO request in Google using the Security Assertion Markup Language (SAML) standard, a widely used method of implementing SSO.
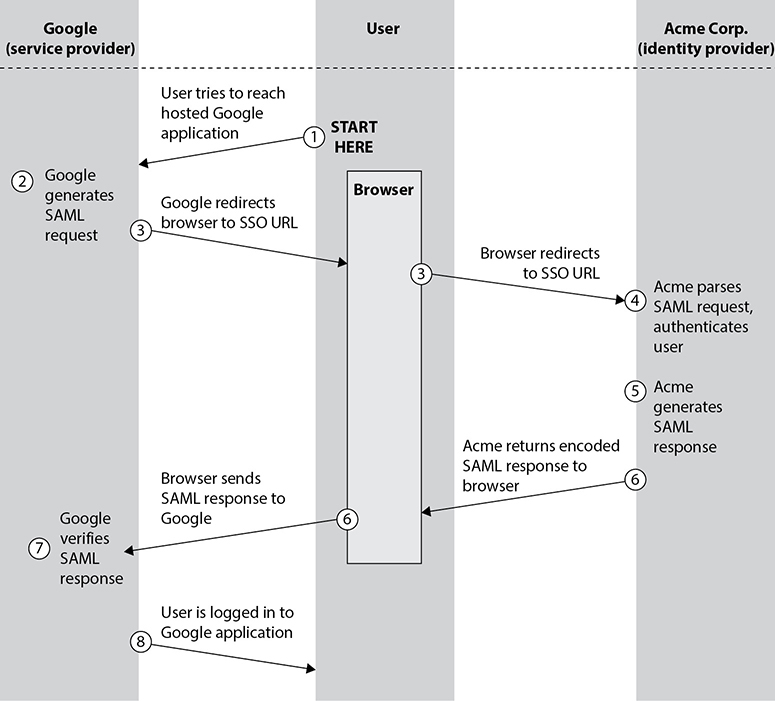
Figure 8-4 Single sign-on flow for a user-initiated request for identity verification
SAML provides access and authorization decisions using a system to exchange information between a user, the identity provider (IDP) such as Acme Corp., and the service provider (SP) such as Google. When a user requests access to a resource on the SP, the SP creates a request for identity verification for IDP. The IDP will provide feedback about the user, and the SP can make its decision on an access control based on its own internal rules and the positive or negative response from the IDP. If access is granted, a token is generated in lieu of the actual credentials and passed on to the SP.
Although SSO improves the user experience in accessing multiple systems, it does have a significant drawback in the potential increase in impact if the credentials are compromised. Using an SSO platform thus requires a greater focus on the protection of the user credentials. This is where including multiple factors and context-based solutions can provide strong protection against malicious activity. Furthermore, as SSO centralizes the authentication mechanism, that system becomes a critical asset and thus a target for attacks. Compromise of the SSO system, or loss of availability, means loss of access to the entire organization’s suite of applications that rely on the SSO system.
Identity Federation
Federated identity is the concept of using a person’s digital identity credentials to gain access to various services, often across organizations. Where SSO can be implemented either within a single organization or among multiple ones, federation applies only to the latter case. The user’s identity credentials are provided by a broker known as the federated identity manager. When verifying her identity, the user needs only to authenticate with the identity manager; the application that’s requesting the identity information also needs to trust the manager. Many popular platforms, such as Google, Amazon, and Twitter, take advantage of their large memberships to provide federated identity services for third-party websites, saving their users from having to create separate accounts for each site.
OpenID
OpenID is an open standard for user authentication by third parties. It is a lot like SAML, except that a user’s credentials are maintained not by the user’s company, but by a third party. Why is this useful? By relying on specialized identity providers (IDPs) such as Amazon, Google, or Steam, developers of Internet services (such as websites) don’t need to develop their own authentication systems. Instead, they are free to use any IDP or group of IDPs that conforms to the OpenID standard. All that is required is that all parties use the same standard and that everyone trusts the IDP(s).
OpenID, currently in version 2.0, defines three roles:
• End user The user who wants to be authenticated in order to use a resource
• Relying party The server that owns the resource that the end user is trying to access
• OpenID provider The IDP (such as Google) on which the end user already has an account and which will authenticate the user to the relying party
You have probably encountered OpenID if you’ve tried to access a website and were presented with the option to log in using your Google identity credentials. (Oftentimes you see an option for Google and one for Facebook in the same window, but Facebook uses its own protocol, Facebook Connect.) In a typical use case, depicted in Figure 8-5, a user wants to visit a protected website. The user’s agent (typically a web browser) requests the protected resource from the relying party. The relying party connects to the OpenID provider and creates a shared secret for this transaction. The server then redirects the user agent to the OpenID provider for authentication. Upon authentication by the provider, the user agent receives a redirect (containing an authentication token, also known as the user’s OpenID) to the relying party. The authentication token contains a field signed with the shared secret, so the relying party is assured that the user is authenticated.

Figure 8-5 OpenID process flow
Role-Based Access Control
What if you have a tremendous number of resources that you don’t want to manage on a case-by-case basis? Role-based access control (RBAC) enables you to grant permissions based on a user’s role, or group. The focus for RBAC is at the role level, where the administrators define what the role can do. Users are able to do only what their role permissions allow them to do, so there is no need for an explicit denial to a resource for a given role. Ideally, there are a small number of roles in a system, regardless of the total number of users, so managing them becomes much easier with RBAC.
Let’s say, for example, that we need a research and development analyst role. We develop this role not only to enable an individual to have access to all product and testing data, but also, and more importantly, to outline the tasks and operations that the role can carry out on this data. When the analyst role makes a request to access the new testing results on the file server, in the background the operating system reviews the role’s access levels before allowing this operation to take place.

NOTE Introducing roles also introduces the difference between rights being assigned explicitly and implicitly. If rights and permissions are assigned explicitly, they are assigned directly to a specific individual. If they are assigned implicitly, they are assigned to a role or group and the user inherits those attributes.
Attribute-Based Access Control
Attribute-based access control (ABAC) uses attributes of any part of a system to define allowable access. These attributes can belong to subjects, objects, actions, or contexts. Here are some possible attributes you could use to describe your ABAC policies:
• Subjects Clearance, position title, department, years with the company, training certification on a specific platform, member of a project team, location
• Objects Classification, files pertaining to a particular project, HR records, location, security system component
• Actions Review, approve, comment, archive, configure, restart
• Context Time of day, project status (open/closed), fiscal year, ongoing audit
As you can see, ABAC provides the most granularity of any of the access control models. It would be possible, for example, to define and enforce a policy that allows only directors to comment on (but not edit) files pertaining to a project that is currently being audited. This specificity is a two-edged sword, however, since it can lead to an excessive number of policies that could interact with each other in ways that are difficult to predict.
Mandatory Access Control
For environments that require additional levels of scrutiny for data access, such as those in military or intelligence organizations, the mandatory access control (MAC) model is sometimes used. As the name implies, MAC requires explicit authorization for a given user on a given object. The MAC model uses additional labels for multilevel security—Unclassified, Confidential, Secret, and Top Secret—that are applied to both the subject and object. When a user attempts to access a file, a comparison is made between the security labels on the file, called the classification level, and the security level of the subject, called the clearance level. Only users who have the appropriate security labels in their own profiles can access files at the equivalent level, and verifying this “need to know” is the main strength of MAC. Additionally, the administrator can restrict further propagation of the resource, even from the content creator.
Manual Review
Auditing and analysis of login events is critical for a successful incident investigation. All modern operating systems have a way to log successful and unsuccessful access attempts. Figure 8-6 shows the contents of an auth.log file indicating all enabled logging activity on a Linux server. Although it may be tempting to focus on the failed attempts, you should also pay attention to the successful logins, especially in relation to those failed attempts. The chance that the person logging in from 4.4.4.12 is an administrator who made a mistake the first couple of times is reasonable. However, when you combine this information with the knowledge that this device has just recently performed a suspicious network scan, you can assume that an innocent mistake is probably unlikely.

Figure 8-6 Snapshot of the auth.log entry in a Linux system
EXAM TIP When dealing with logs, consider the time zone difference for each device. Some may report in the time zone you operate in, some may use GMT, and others may be off altogether.
Event logs are similar to syslogs in the detail they provide about a system and connected components. Windows enables administrators to view all of a system’s event logs with the Event Viewer utility. This makes it much easier to browse through the thousands of entries related to system activity, as shown in Figure 8-7. It’s an essential tool for understanding the behavior of complex systems such as Windows—and particularly important for servers, which aren’t designed to always provide feedback through the user interface.

Figure 8-7 The Event Viewer main screen in Windows 10
In recent Windows operating systems, successful login events have an event ID of 4624, whereas login failure events have an ID of 4625, with error codes to specify the exact reason for the failure. In the Windows 10 Event Viewer, you can specify exactly which types of event you’d like to get more detail on using the Create Custom View command available from the Action pull-down menu. The resulting dialog is shown in Figure 8-8.
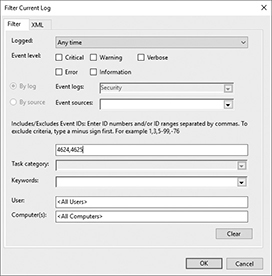
Figure 8-8 The Event Viewer dialog for filtering log information
Cloud Access Security Broker
Before the emergence of diverse cloud computing solutions, it was a lot simpler for us to control access to our information systems, monitor their performance, and log events in them. Doing this became even more difficult with the shift toward using mobile (and potentially personal) devices to access corporate resources. How do you keep track of what’s happening when a dozen different cloud services are in use by your organization? A cloud access security broker (CASB) sits between each user and each cloud service, monitoring all activity, enforcing policies, and alerting you when something seems to be wrong.
We generally talk of four pillars to CASBs.
• Visibility This is the ability to see who is doing what, where. Are your users connecting to unauthorized resources (such as cloud storage that is not controlled by your organization)? Are they constrained to services and data that they are authorized to use?
• Threat protection This pillar detects (and, ideally, blocks) malware, insider threats, and compromised accounts. In this regard, features in this pillar look a lot like those of an intrusion detection or protection system but for your cloud services.
• Compliance If you are in a regulated environment (and, let’s face it, with data laws like the GDPR, most of us are), you want to ensure that any data in the cloud is monitored for compliance with appropriate regulations concerning who can access it, how, and when.
• Data security Whether or not you are in a regulated environment, you likely have an abundance of data that needs protection in the cloud. This includes intellectual property, customer information, and future product releases.
Monitoring and Logging
It goes without saying that you need to keep an eye out for a lot of “stuff” in your environment. Otherwise, how would you know that one of your web servers crashed or that your DNS server has an extremely high CPU utilization? Monitoring is the practice of ensuring that your information systems remain available and are operating within expected performance envelopes. Though primarily an IT function, monitoring can provide early warnings to cybersecurity analysts when systems are under attack or have been compromised.
Real user monitoring (RUM) is a passive way to monitor the interactions of real users with applications or systems. It uses agents to capture metrics such as delay, jitter, and errors from the user’s perspective. Although RUM captures the actual user experience fairly accurately, it tends to produce noisy data (such as incomplete transactions due to users changing their minds or losing mobile connectivity) and thus may require more back-end analysis. It also lacks the elements of predictability and regularity, which could mean that a problem won’t be detected during low utilization periods.
An alternative approach to monitoring relies on synthetic interactions with the systems under observation. For example, you could write a simple script that periodically queries your DNS server and records the time it takes for it to respond. You could compare response times over time to determine what is normal and then generate an alert when the performance is suspiciously slow (or when there is no response at all). An advantage of this approach over RUM is that you can precisely control the manner and frequency of your observations. A disadvantage is that you are typically limited in terms of the complexity of the transactions. Whereas a real user can interact with your systems in a virtually infinite number of ways, the synthetic transactions will be significantly fewer and less complex.
What if you find something out of the norm while monitoring one of your systems? This is where you turn to logs. Logging is the practice of managing the log data produced by your systems. It involves determining what log data is generated by which systems, where it is sent (and how), and what happens to it once it is aggregated there. It starts with configuring your systems to record the data that will be useful to you in determining whether your systems are free of compromise. For example, you probably want to track login attempts, access to sensitive data, and use of privileged accounts, to name a few. Once you decide what to store, you will need a secure place to aggregate all this data so you can analyze it. Since adversaries will want to interfere with this process, you will have to take extra care to make it difficult to alter or delete the log data.
Turning these reams of raw data into actionable information is the goal of log analysis. In analysis, your first task is to normalize of the data, which involves translating the multitude of data formats you get from all over your environment into a common format. Normalization can be done by an agent on the sending system or by the receiving aggregator. Once the data is in the right format, your log analysis tool will typically do one or more of the following: pattern recognition, classification, and prediction.
Pattern recognition compares the log data to known good or bad patterns to find interesting events. This could be as simple as a large number of failed login attempts followed by a successful one, or it could involve detecting user activity at an odd time of day (for that user). Classification involves determining whether an observation belongs to a given class of events. For instance, you may want to differentiate peer-to-peer traffic from all other network activity to detect lateral movement by an adversary. Log analysis can also involve predictive analytics, which is the process of making a number of related observations and then predicting what the next observation ought to be. A simple example of this would be to observe the first two steps of a TCP three-way handshake (a SYN message followed by a SYN-ACK) and predict that the next interaction between these two hosts will be an ACK message. If you don’t see that message, your prediction failed, and this may mean something is not right.
Encryption
Encryption is a method of transforming readable data, called plaintext, into a form that appears to be random and unreadable, which is called ciphertext. Plaintext is in a form that can be understood either by a person (such as a document) or by a computer (such as executable code). Once plaintext is transformed into ciphertext, neither human nor machine can use it until it is decrypted. Encryption enables the transmission of confidential information over insecure channels without unauthorized disclosure. The science behind encryption and decryption is called cryptography, and a system that encrypts and/or decrypts data is called a cryptosystem.
Although there can be several pieces to a cryptosystem, the two main pieces are the algorithms and the keys. Algorithms used in cryptography are complex mathematical formulas that dictate the rules of how the plaintext will be turned into ciphertext, and vice versa. A key is a string of random bits that will be used by the algorithm to add to the randomness of the encryption process. For two entities to be able to communicate using cryptography, they must use the same algorithm and, depending on the approach, the same or a complementary key. Let’s dig into that last bit by exploring the two approaches to cryptography: symmetric and asymmetric.
Symmetric Cryptography
In a cryptosystem that uses symmetric cryptography, the sender and receiver use two instances of the same key for encryption and decryption, as shown in Figure 8-9. So the key has dual functionality, in that it can carry out both encryption and decryption processes. It turns out this approach is extremely fast and hard to break, even when using relatively small (such as 256-bit) keys. What’s the catch? Well, if the secret key is compromised, all messages ever encrypted with that key can be decrypted and read by an intruder. Furthermore, if you want to separately share secret messages with multiple people, you’ll need a different secret key for each, and you’ll need to figure out a way to get that key to each person with whom you want to communicate securely. This is sometimes referred to as the key distribution problem.

Figure 8-9 When using symmetric algorithms, the sender and receiver use the same key for encryption and decryption functions.
Asymmetric Cryptography
Another approach is to use different keys for encryption and decryption, or asymmetric cryptography. The key pairs are mathematically related to each other in a way that enables anything that is encrypted by one to be decrypted by the other. The relationship, however, is complex enough that you can’t figure out what the other key is by analyzing the first one. In asymmetric cryptosystems, a user keeps one key (the private key) secret and publishes the complimentary key (the public key). So, if Bob wants to send Alice an encrypted message, he uses her public key and knows that only she can decrypt it. This is shown in Figure 8-10. What happens if someone attempts to use the same asymmetric key to encrypt and decrypt a message? They get gibberish.

Figure 8-10 When using asymmetric algorithms, the sender encrypts a message with the recipient’s public key, and the recipient decrypts it using a private key.
So what happens if Alice sends a message encrypted with her private key? Then anyone with her public key can decrypt it. Although this doesn’t make much sense in terms of confidentiality, it assures every recipient that it was really Alice who sent it and that it wasn’t modified by anyone else in transit. This is the premise behind digital signatures.
Digital Signatures
Digital signatures are short sequences of data that prove that a larger data sequence (say, an e-mail message or a file) was created by a given person and has not been modified by anyone else after being signed. Suppose Alice wants to digitally sign an e-mail message. She first takes a hash of it and encrypts that hash with her private key. She then appends the resulting encrypted hash to her (possibly unencrypted) e-mail. If Bob receives the message and wants to ensure that Alice really sent it, he would decrypt the hash using Alice’s public key and then compare the decrypted hash with a hash he computes on his own. If the two hashes match, Bob knows that Alice really sent the message and nobody else changed it along the way.
NOTE In practice, digital signatures are handled by e-mail applications, so all the hashing and decryption are done automatically, not by you.
Symmetric vs. Asymmetric Cryptography
The biggest differences between symmetric and asymmetric cryptosystems boil down to key length and encryption/decryption time. Symmetric cryptography relies on keys that are random sequences of characters, and these can be fairly short (256 bits), but it would still require years for an attacker to conduct an effective brute-force attack against them. By contrast, asymmetric key pairs are not random with regard to each other (remember, they are related by a complex math formula), so they are easier to brute-force at a given key size compared to symmetric keys. For this reason, asymmetric keys have to be significantly longer to achieve the same level of security. The current NIST recommendation is that asymmetric key pairs be at least 2048 (and preferably 3072) bits in length.
The other big difference between these two approaches to cryptography is that symmetric cryptosystems (partly because they deal with smaller keys) are significantly faster than asymmetric ones. So, at this point, you may be wondering, why use asymmetric encryption at all if it is slower and requires bigger keys? The answer goes back to the key distribution problem we mentioned earlier. In practice, when transmitting information securely, we almost always use asymmetric cryptography to exchange secret keys between the parties involved, and then switch to symmetric cryptography for the actual transfer of information.
Certificate Management
When we discussed asymmetric key encryption, we talked about publishing one of the keys, but how exactly does that happen? If we allow anyone to push out a public key claiming to be Alice, then how do we know it really is her key and not an impostor’s key? There are two ways in which the security community has tackled this problem. The first is through the use of a web of trust, which is a network of users who can vouch for each other and for other users wanting to join in. The advantage of this approach is that it is decentralized and free. It is a common approach for those who use Pretty Good Privacy (PGP) encryption.
Most businesses, however, prefer a more formal process for verifying identities associated with public keys, even if it costs more. What they need are trusted brokers who can vouch for the identity of a party using a particular key. These brokers are known as certificate authorities (CAs), and their job is to verify someone’s identity and then digitally sign that public key, packaging it into a digital certificate or a public key certificate.
A digital certificate is a file that contains information about the certificate owner, the CA who issued it, the public key, its validity timeframe, and the CA’s signature of the certificate itself. The de facto standard for digital certificates is X.509 and is defined by the Internet Engineering Task Force (IETF) in its RFC 5280.
When a CA issues a digital certificate, it has a specific validity period. When that time elapses, the certificate is no longer valid and the owner needs to get a new one. It is possible for the certificate to become invalid before it expires, however. For example, we stressed earlier the importance of keeping the private key protected, but what if it is compromised? In that case, the owner would have to invalidate the corresponding digital certificate and get a new one. Meanwhile, the public key in question may still be in use by others, so how do we notify the world to stop using it? A certificate revocation list (CRL), which is maintained by a revocation authority (RA) is the authoritative reference for certificates that are no longer trustworthy.
Digital certificate management involves the various actions undertaken by a certificate owner, its CA, and its RA to ensure that valid certificates are available and invalid ones are not used. From an organizational perspective, it is focused on acquiring certificates from a CA, deploying them to the appropriate systems, protecting the private keys, transitioning systems to a new certificate before the old ones expire, and reporting compromised (or otherwise no longer valid) certificates to the RA. It can also entail consulting a CRL to ensure that the continued validity of certificates belonging to other entities with whom the organization does business.

CAUTION Many organizations disable CRL checks because they can slow down essential business process. This decision introduces serious risks and should not be taken lightly.
Active Defense
Traditionally, defensive operations involve preparing for an attack by securing resources as best we can, waiting for attackers to make a move, and then trying to block them or, failing that, ejecting them from the defended environment. Active defense consists of adaptive measures aimed at increasing the amount of effort attackers need to exert to be successful, while reducing the effort for the defenders. Think of it as the difference between a boxer who stands still in the ring with fists raised and a good stance, and a boxer who uses footwork, slipping and bobbing to make it harder for an opponent to effectively land a punch.
One of the most well-known approaches to active defense is moving target defense (MTD). MTD makes it harder for an attacker to understand the layout of the defender’s systems by frequently (or even constantly) changing the attack surface (such as IP addresses on critical resources). For example, suppose an attacker is conducting active reconnaissance, finds an interesting server at a certain IP address, and makes a note to come back and look for vulnerabilities when the scan is over. A few minutes later, he interrogates that address and finds it is no longer in use. Where did the server go? The defender was employing an MTD scheme in which the addresses are changed every few minutes. The attacker has to go back to square one and try to figure out where the server is, but, by the time he does this, the server will be moved again.
Another approach, which is sometimes bundled with MTD, is the use of honeypots or honeynets, as we discussed earlier in the chapter. Here, the idea is to make an attacker waste her time interacting with an environment that is simply a decoy. Because the honeypot is not a real system, the mere fact that someone is using it can alert the defenders to an attacker’s presence and even enable them to observe the attacker and further confuse her.
Chapter Review
The typical enterprise IT environment is both complex and dynamic. Both of these features provide opportunities for attackers to compromise our information systems unless we understand our infrastructures and carefully manage changes within them. Two of the most important concepts we covered in this chapter are asset management, by which we keep track of all the components of our networks, and change management, which enables us to ensure that changes to these assets do not compromise our security. Another very important concept we covered is identity and access management, which involves the manner in which users are allowed to interact with our assets. It is critical that we carefully control these interactions to simultaneously enable organizational business functions while ensuring the protection of our assets.
Questions
1. Your boss is considering an initiative to move all services to the cloud as a cost-savings measure but is concerned about security. Your company has experienced two consecutive quarters of decreasing revenues. Some of your best talent got jittery and found jobs elsewhere, and you were forced to downsize. Faced with a financial downturn, your lifecycle IT refresh keeps getting pushed back. What do you recommend to your boss?
A. Don’t move to the cloud because it’s really not any cheaper.
B. Wait until after the lifecycle refresh and then move to the cloud.
C. Move to the cloud; it will save money and could help lessen your team’s burden.
D. Don’t move to the cloud, because you don’t have the needed additional staff.
2. Which architecture would you choose if you were particularly interested in adaptive control of how data moves around the network?
A. Software-defined
B. Physical
C. Serverless
D. Virtual private network
3. Best practices for managing privileged accounts include all of the following except which?
A. Maintain an accurate, up-to-date account inventory.
B. Monitor and log all privileged actions.
C. Ensure that you have only a single privileged account.
D. Enforce multifactor authentication.
4. Which of the following is the best reason to implement active defense measures?
A. Hacking back is the best way to stop attackers.
B. They make it harder for the attacker and easier for the defender to achieve objectives.
C. An organization lacks the resources to implement honeynets.
D. Active defense measures are a better alternative to moving target defense (MTD).
Use the following scenario to answer Questions 5–8:
You just started a new job at a small online retailer. The company has never before had a cybersecurity analyst, and the IT staff has been taking care of security. You are surprised to learn that users are allowed to use Remote Desktop Protocol (RDP) connections from outside the network directly into their workstations. You tell your boss that you’d like to put in a change request to prevent RDP and are told there is no change management process. Your boss trusts your judgement and tells you to go ahead and make the change.
5. What would be the best way to proceed with the RDP change?
A. Your boss approved it, so just go for it.
B. Encourage everyone to use a virtual private network (VPN) for RDP.
C. Take no further action until a change management process is established.
D. Use this request as impetus to create a change management board.
6. You are given three months to implement a solution that allows selected users to access their desktops from their home computers. You start by blocking RDP at the firewall. Which of the following would not be your next step?
A. Require users to use VPN.
B. Require users to log in through a jump box.
C. Require users to log in through a honeypot.
D. Deploy a virtual desktop infrastructure for your users.
7. To improve user authentication, particularly when users remotely access their desktops, which of the following technologies would be most helpful?
A. Asymmetric cryptography
B. Symmetric cryptography
C. Cloud access security broker
D. Active defense
8. As you continue your remote desktop project, you realize that there are a lot of privileged accounts in your company. Which of the following actions should you take?
A. Minimize the number of accounts by having system administrators share one account and log all activity on it.
B. Deploy a single sign-on solution that requires multifactor authentication.
C. Allow everyone to have administrative access but deploy OpenID for federated authentication.
D. Minimize the number of accounts, ensure that there is no sharing of credentials, and require multifactor authentication.
Answers
1. C. A cloud migration makes sense particularly when your IT infrastructure is not new (that is, it will soon need a costly refresh) and/or your team is not up to the task of securing the on-premises systems.
2. A. A software-defined network architecture provides the most adaptability when it comes to managing traffic flows. You could also accomplish this in some VPCs, but that would not be as flexible and was not an option.
3. C. Though you certainly want to minimize the number of privileged accounts, having only one means one of two things are certain to happen: either you’ll have multiple people sharing the same account, or you’ll be locked out of making any changes to your environment if the account holder is not willing or able to do the job.
4. B. The main objective of active defense measures is to make it harder for the attacker and easier for the defender to achieve objectives. Two examples of this approach are moving target defense and honeynets.
5. D. The lack of a change management process is a serious shortcoming in your organization. Because your boss is allowing you to deal with the RDP risk, you could use this effort to jumpstart the change management process. B and C do nothing to mitigate the risk. Answer option A deals with the risk but doesn’t fix the change management problem, so it’s not the best answer.
6. C. A honeypot is a system deployed to attract attackers and should have no real business purpose. Each of the other three answers could reasonably be used to enable external access to sensitive internal resources.
7. A. Digital certificates, which employ asymmetric cryptography, can be used to ensure that both endpoints of a communications channel are who they claim to be and can thus help strengthen authentication. A CASB could help, but only for cloud computing assets.
8. D. Minimizing the number of privileged accounts, ensuring that there is no sharing of credentials, and requiring MFA are three of the best practices for privileged account management.