
CHAPTER 9
Software Assurance Best Practices
In this chapter you will learn:
• How to develop and implement a software development lifecycle
• General principles for secure software development
• Best practices for secure coding
• How to ensure the security of software
Give me six hours to chop down a tree and I will spend the first four sharpening the axe.
—Abraham Lincoln
When you’re developing software, most of the effort goes into either planning and design (in good teams) or debugging and fixes (in other teams). You are very unlikely to be working as a software developer if your principal role in your organization is cybersecurity analyst. You are, however, almost certainly going to be on the receiving end of the consequences for software that is developed in an insecure manner. Quite simply, a developer’s skills, priorities, and incentives are very different from those of their security teammates. It is in everyone’s best interest, then, to bridge the gap between these communities, which is why CompTIA included the objectives we cover here in the CySA+ exam.
Platforms and Software Architectures
In the last chapter, we discussed network architectures as the way in which we arrange and connect network devices to support our organizations. Here, we turn our attention to software architectures, which are the descriptions of the software components of an application and of the manner in which they interface with one another, with other applications, and with end users. The easiest way to get started is to consider the three fundamental tasks that any nontrivial application must do: interact with someone (whether it’s a human or another application) to get or give data, do something useful with that data, and finally store (at least some) data.
Figure 9-1 shows a very high-level architecture. User interaction is handled by what is commonly called the presentation layer. This layer also interacts with the business logic of the application, which is where all of the real work gets done. Finally, if the application needs to store data persistently (and most business applications do), the data layer (sometimes called the data access layer) interacts with wherever it is that the data will be stored. This could be a file system or a database management system, for example.
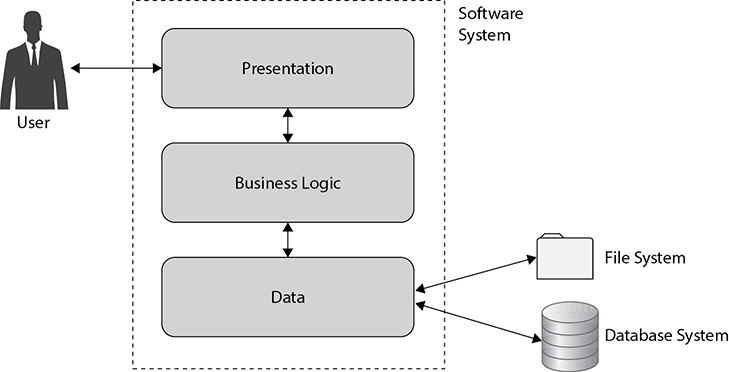
Figure 9-1 A high-level software architecture
All three tasks—giving or getting data, doing something useful with data, and storing data—can be performed within the same computing device or platform, called a standalone application. This type of architecture is becoming increasingly rare, but the venerable calculator and notepad applications that are installed by default with most operating systems are good examples. Office productivity suites with word processing and spreadsheet applications used to be good examples of this class of software. Nowadays, however, many of those applications have moved some or all of their tasks to the cloud.

NOTE An application could have some cloud (or otherwise remote) functionality and still be considered standalone as long as that functionality is not essential for the application to work.
Distributed applications perform their core tasks on different, connected computing platforms. Multiplayer online games, network file systems, and cloud-based office productivity suites are obvious examples of distributed software. This is the most popular approach to architecting software, and its use is projected to continue to grow. Technically, this type of architecture consists of multiple related software systems that are typically called either distributed applications or distributed systems.
Even applications you may have thought of as standalone have at least some distributed functionality. For example, automatic software updates, which are prevalent in newer applications, make use of network connectivity to check for, download, and install patches and updates. While this is generally a good security feature, it could be subverted by a sophisticated adversary to compromise systems. This happened in 2019, for example, when ASUS, one of the world’s largest computer manufacturers, had its trusted automatic software update tool compromised in what’s been dubbed Operation ShadowHammer. The attackers used this tool to distribute and install backdoors on thousands of computers around the world, though they were particularly interested in only a few hundred specific target devices.
Client/Server
A client/server system, which is a kind of distributed application, requires that two (or more) separate applications interact with each other across a network connection in order for users to benefit from them. One application, the client, makes requests (and receives responses) from a server that is otherwise passively waiting for someone to call on it. Perhaps the most common example of a client/server application is your web browser, which is designed to connect to a web server. Sure, you could just use your browser to read local documents, but that’s not really the way it’s meant to be used. Most of us use our browsers to connect two tiers: a client and a server, which is why we might call it a two-tier architecture.
Generally, client/server systems are known as n-tier architectures, where n is a numerical variable that can assume any value; most of the time, only the development team would know the number of tiers in the architecture (which could change over time), even if it looks like just two to the user. Consider the example of browsing the Web, which is probably a two-tier architecture if you are reading a static web page on a small web server. If, on the other hand, you are browsing a typical commercial site, you will probably be going through many more tiers, like the four-tier system shown in Figure 9-2. In this example, a client (tier 1) connects to a web server (tier 2) that provides the static HTML, CSS, and some images. The dynamic content, however, is pulled by the web server from an application server (tier 3) that in turn gets the necessary data from a back-end database (tier 4).

Figure 9-2 A four-tier client/server system
Web Application
You know that a client/server system is a specific kind of distributed system. A web application, in turn, is a specific type of client/server system that is accessed through a web browser over a network connection, like the one shown in Figure 9-2. Examples of common web applications are web mail, online stores, and online banking.
Web applications are typically exposed to the most threats, because their very nature requires that they be accessible to anyone with an Internet connection. While some applications are deployed in a private network such as an intranet to reduce their exposure, many others are directly accessible from anywhere in the world. For this reason, we need to pay particular attention to ensuring that these applications are developed securely (we will cover secure coding later in this chapter), configured properly (we covered configuration management in the previous chapter), and monitored closely.
Mobile
Mobile devices such as smartphones and tablets run specialized operating systems and therefore require that applications be specifically developed for those systems. The vast majority of mobile devices in use today run either Apple iOS or Google Android systems. Applications (or apps) developed for one will not work on the other, so even if an app is available on both platforms, the actual software is likely to be different. This means that one version could have vulnerabilities that are not present in the other.
Most mobile apps used by businesses are actually distributed systems. Even if some of the data is stored on the local device, the app probably makes use of remote services to get, process, or store data, and these connections need to be protected. Another concern is that some data is almost certainly being stored locally, so it could possibly be accessed by another (malicious) app on the same device or by someone who gains physical access to the device. Additionally, authentication on the mobile device may not be as robust as on a traditional computer system. Many users rely on simple PINs to unlock their devices, for example, and these can be guessed or observed by an attacker who is nearby.
Embedded
An embedded system is a self-contained computer system (that is, it has its own processor, memory, and input/output devices) designed for a very specific purpose. An embedded device is part of (or embedded into) some other mechanical or electrical device or system. Embedded systems are typically cheap, rugged, and small, and they use very little power. They are usually built around microcontrollers, which are specialized devices that consist of a CPU, memory, and peripheral control interfaces. Microcontrollers have a very basic operating system, if they have one at all. A digital thermometer is an example of a very simple embedded system, and other examples of embedded systems include traffic lights and factory assembly line controllers. As you can see from these examples, embedded systems are frequently used to sense and/or act on a physical environment. For this reason, they are sometimes called cyber-physical systems.
The main challenge in securing embedded systems is that of ensuring the security of the software that drives them. Many vendors build their embedded systems around commercially available microprocessors, but they use their own proprietary code that is difficult, if not impossible, for a customer to audit. Depending on the risk tolerance of your organization, this may be acceptable as long as the embedded systems are standalone. The problem, however, is that these systems are increasingly shipping with some sort of network connectivity. For example, some organizations have discovered that some of their embedded devices have “phone home” features that are not documented. In some cases, this has resulted in potentially sensitive information being transmitted unencrypted to the manufacturer. If a full audit of the embedded device security is not possible, at a very minimum you should ensure that you see what data flows in and out of it across any network.
Another security issue presented by many embedded systems concerns the ability to update and patch them securely. Many embedded devices are deployed in environments where they have no Internet connectivity. Even if this is not the case and the devices can check for updates, establishing secure communications or verifying digitally signed code, both of which require processor-intensive cryptography, may not be possible on a cheap device.
System on a Chip
If you take the core elements of an embedded system (processor, memory, I/O) and put it all in a single integrated circuit, or chip, you would have a system on a chip (SoC). Sometimes, SoCs are used to build embedded devices, but you can see them just as frequently in smartphones, or in Internet of Things (IoT) devices. The beauty of a SoC is that, because all the components are miniaturized into the same chip, these devices tend to be very fast and consume less power than modular computers. This lack of modularity, by the way, is precisely the main drawback of SoCs: you can’t just replace components because they’re all stuck in the same chip.
Firmware
Whether you have a very simple SoC with no operating system running your household thermometer or a big server running your enterprise website, when you switch it on, some sort of software needs to be loaded into the CPU and executed so that your device can do something useful. Firmware is software that is stored in read-only, nonvolatile memory in a device and is executed when the device is powered on. Some devices’ functionality is simple enough that they require only firmware to store their entire code base. More complex systems use firmware to load and perform power-on tests and then load and run the operating system from a secondary storage device. One way or another, virtually every computing device needs firmware to function.
So how do you update or patch firmware if it is read-only? If you have real read-only memory (ROM), there is no way (short of replacing the physical ROM chip) of doing this. However, most devices we come across use electronically erasable programmable ROM (EEPROM), which is a memory chip that can be wiped and overwritten. This enables device manufacturers to push out patches and updates to firmware as needed. Devices whose firmware is not updatable can present security risks if a vulnerability is ever found. At that point, your only choice is to isolate the vulnerable devices or replace them.
Service-Oriented Architecture
Up to this point, we have taken a platform-centric perspective on software architectures. In describing client/server, web application, mobile, and embedded systems software, we’ve focused on which platform executes the code. Another way to look at software architecture is to focus on the functionality or services being provided and not care where it is hosted, as long as it is available.
A service-oriented architecture (SOA) describes a system as a set of interconnected but self-contained components that communicate with each other and with their clients through standardized protocols. These protocols, called application program interfaces (APIs), establish a “language” that enables a component to make a request from another component and then interpret that second component’s response. The requests that are defined by these APIs correspond to discrete business functions (such as estimate shipping costs to a postal code) that can be useful by themselves or can be assembled into more complex business processes. An SOA has three key characteristics: self-contained components, a standardized protocol (API) for requests/responses, and components that implement business functions.
SOAs are commonly built using web services standards that rely on HTTP as a standard communication protocol. Examples of these are the Simple Object Access Protocol (SOAP) and the representational state transfer (REST) and microservices architectures.
Simple Object Access Protocol
One of the first SOAs to become widely adopted is the Simple Object Access Protocol, a messaging protocol that uses XML over HTTP to enable clients to invoke processes on a remote host in a platform-agnostic way. SOAP enables you to have Linux and Windows machines working together as part of the same web service, for example. SOAP consists of three main components: Firstly, there is a message envelope that defines the messages that are allowed and how they are to be processed by the recipient. The second component of the protocol is a set of encoding rules used to define data types. Lastly, SOAP includes conventions on what remote procedures can be called and how to interpret their responses.
One of the key features of SOAP is that the message envelope allows the requestor to describe the actions that it expects from the various nodes that respond. This feature allows for things like routing tables that could specify the sequence and manner in which a series of SOAP nodes will take action on a given message. This can make it possible to finely control access as well as efficiently recover from failures along the way. This richness of features, however, comes at a cost: SOAP is not as simple as its name would imply. In fact, SOAP systems tend to be fairly complex and cumbersome, which is why many web service developers prefer more lightweight options like REST.
Representational State Transfer
REST architectures are among the most common in web services today. REST (or RESTful, as they’re more commonly called) systems leverage the statelessness and standard operations of HTTP to focus on performance and reliability. Unlike SOAP, which is a standard protocol, REST is considered an architectural style. As such, it has no official definition. Instead, there is a pretty broad consensus on what it means to be RESTful, which includes the following features:
• The standard unit of information is a resource, which is uniquely identified through a uniform resource identifier (URI), such as an HTTP universal resource locator (URL).
• The system must implement a client/server architecture.
• The system must be stateless, which means that each request includes all the information needed to generate a response (that is, the server doesn’t need to “remember” any past transactions involving the client).
• Responses must state whether or not they are cacheable by an intermediary such as a web proxy.
• The system must have a uniform interface that enables parts of it to be swapped or upgraded without breaking the whole thing.
Microservices
Another example of an SOA with which you should be acquainted is the microservice. Like REST, microservices are considered an architectural style rather than a standard, but there is broad consensus that they consist of small, decentralized, individually deployable services built around business capabilities. They also tend to be loosely coupled, which means there aren’t a lot of dependencies between the individual services. As a result, they are quick to develop, test, and deploy and can be exchanged without breaking the larger system.
The decentralization of microservices can present a security challenge. How can you track adversarial behaviors through a system of microservices, where each service does one discrete task? The answer is log aggregation. Whereas microservices are decentralized, we want to log them in a centralized fashion so we can look for patterns that span multiple services and can point to malicious intent. Admittedly, you will need automation and perhaps data analytics or artificial intelligence to find these malicious events, but you won’t have a chance at spotting them unless you aggregate the logs.
Security Assertions Markup Language
Technically, the Security Assertion Markup Language (SAML) is just that, a markup language standard. However, it is widely used to implement a specific kind of SOA for authentication and authorization services. We already saw an example of SAML in the last chapter when we were discussing single sign-on (SSO).
As a refresher, SAML defines two key roles: the Service Provider (SP) and the Identity Provider (IdP). A user who wants to access a service—say, a cloud-based sales application—requests access from the SP. The SP redirects the user to the IdP for authentication. The IdP authenticates the user and, assuming it is successful, redirects back to the SP. This last redirect includes a SAML assertion, which is a security statement (typically) from an IdP that SPs use to make access control decisions. SAML assertions can specify conditions (such as don’t allow access before/after a certain time), user attributes (such as roles or group memberships), and the IdP’s X.509 certificate if the assertion is digitally signed.
NOTE Web browser redirects are essential to SAML working properly.
The Software Development Lifecycle
There are many approaches to building software, but they all follow some sort of predictable pattern called a software development lifecycle (SDLC). It starts with identifying an unmet need and ends with retiring the software, usually so that a new system can take its place. Whether you use formal or agile methodologies, you still have to identify and track the user or organizational needs; design, build, and test a solution; put that solution into a production environment; keep it running until it is no longer needed; and, finally, dispose of it without breaking anything else. In the sections that follow, we present the generic categories of effort within this lifecycle, though your organization may call these by other names. Along the way, we’ll highlight how this all fits into the CySA+ exam.

EXAM TIP You do not need to memorize the phases of the SDLC, but you do need to know how a cybersecurity analyst would contribute to the development effort at different points in it.
Requirements
All software development should start with the identification of the requirements that the finished product must satisfy. Even if those requirements are not explicitly listed in a formal document, they will exist somewhere before the first line of code is written. Generally speaking, there are two types of requirements: functional requirements that describe what the software must do, and nonfunctional requirements that describe how the software must do these things or what the software must be like. Left to their own devices, many software developers will focus their attention on the functionality and only begrudgingly (if at all) pay attention to the rest.
Functional Requirements
A functional requirement defines a function of a system in terms of inputs, processing, and outputs. For example, a software system may receive telemetry data from a temperature sensor, compare it to other data from that sensor, and display a graph showing how the values have changed for the day. This requirement is not encumbered with any specific constraints or limitations, which is the role of nonfunctional requirements.
Nonfunctional Requirements
A nonfunctional requirement defines a characteristic, constraint, or limitation of the system. Nonfunctional requirements are the main input to architectural designs for software systems. An example of a nonfunctional requirement, following the previous temperature scenario, would be that the system must be sensitive to temperature differences of one-tenth of a degree Fahrenheit and greater. Nonfunctional requirements are sometimes called quality requirements.
Security Requirements
The class of requirements in which we are most interested deals with security. A security requirement defines the behaviors and characteristics a system must possess to achieve and maintain an acceptable level of security by itself and in its interactions with other systems. Accordingly, this class includes both functional and nonfunctional aspects of the finished product.
Development
Once all the requirements have been identified, the development team starts developing or building the software system. The first step in this phase is to design an architecture that will address the nonfunctional requirements. Recall that nonfunctional requirements describe the characteristics of the system. On this architecture, the detailed code modules that address the features or functionality of the system are designed so that they satisfy the functional requirements. After the architecture and features are designed, software engineers start writing, integrating, and testing the code.
Testing is a critical part of developing secure code. Four types of testing are usually involved: The first is unit testing, which ensures that specific blocks (or units) of code behave as expected. This is frequently automated and involves a range of inputs that are reasonable, absurd, and at the boundary between these two extremes. The next level of testing is integration testing and involves ensuring that the outputs that one unit provides to another as inputs don’t reveal any flaws. After integration testing, a product is usually ready for system testing, which is sort of like integration testing but for the entire system. Assuming everything is okay so far, we know that the product is built right (system verification). The final question to answer is whether we built the right product (system validation), and this is something only the intended user can determine. To take care of this final check, products go through a formal acceptance testing, at which point the customer certifies that the software meets the needs for which it was developed. At the end of the development phase, the system has passed all unit, integration, and system tests and is ready to be rolled out onto a production network.
Implementation
The implementation phase is the point at which frictions between the development and operations teams can start to become real problems, unless these two groups have been integrated beforehand. The challenges in this transitory phase include ensuring that the software will run properly on the target hardware systems, that it will integrate properly with other systems (for example, Active Directory), that it won’t adversely affect the performance of any other system on the network, and that it doesn’t compromise the security of the overall information system. If the organization used DevOps or DevSecOps (which we’ll describe shortly), most of the thorny issues will have been identified and addressed by this stage, which means implementation becomes simply an issue of provisioning and final checks.
Operation and Maintenance
By most estimates, operation and maintenance (O&M) of software systems represents around 75 percent of the total cost of ownership (TCO). Somewhere between 20 and 35 percent of O&M costs are related to correcting vulnerabilities and other flaws that were not discovered during development. If you multiply these two figures together, you can see that typically organizations spend between 15 and 26 percent of the TCO for a software system fixing defects. This is the main driver for spending extra time in the design, secure development, and testing of the system before it goes into O&M. By this phase, the IT operations team has ownership of the software and is trying to keep it running in support of the business, while the software developers have usually moved on to the next project and see requests for fixes as distractions from their main efforts. This should highlight, once again, the need for secure software development before it ever touches a production network.
DevOps and DevSecOps
Historically, the software development and quality assurance teams would work together, but in isolation from the IT operations teams who would ultimately have to deal with the end product. Many problems have stemmed from poor collaboration between these two during the development process. It is not rare to have the IT team berating the developers because a feature push causes the former group to have to stay late, work on a weekend, or simply drop everything they were doing in order to “fix” something that the developers “broke.” This friction makes a lot of sense when you consider that each team is incentivized by different outcomes. Developers want to push out finished code, usually under strict schedules. The IT staff, on the other hand, wants to keep the IT infrastructure operating effectively. A good way to solve this friction is to have both developers and operations staff (hence the term DevOps) work together throughout the software development process. DevOps is the practice of incorporating development, IT, and quality assurance (QA) staff into software development projects to align their incentives and enable frequent, efficient, and reliable releases of software products. Recently, the cybersecurity team is also being included in this multifunctional team, leading to the increasing use of the term DevSecOps, as shown in Figure 9-3.

Figure 9-3 The functions involved in DevOps and in DevSecOps
Software Assessment Methods
So far, we’ve focused on the practices that would normally be performed by the software development or quality assurance team. As the project transitions from development to implementation, the IT operations and security teams typically perform additional security tests to ensure the confidentiality, integrity, and availability not only of the new software, but of the larger ecosystem once the new program is introduced. If an organization is using DevSecOps, some or most of these security tests could be performed as the software is being developed, because security personnel would be part of that phase as well. Otherwise, the development team gives the software to the security team for testing, and these individuals will almost certainly find flaws that will start a back-and-forth cycle that could delay final implementation.
User Acceptance Testing
Every software system is built to satisfy the needs of a set of users. Accordingly, the system is not deemed acceptable (or finished) until the users or their representatives declare that all the features have been implemented in ways that are acceptable to them. Depending on the development methodology used, user acceptance testing could happen before the end of the development phase or before the end of the implementation phase. Many organizations today use agile development methodologies that stress user involvement during the development process. This means that user acceptance testing may not be a formal event but rather a continuous engagement where representative users actively interact with the system.
Stress Testing
Another type of testing that also attempts to break software systems does so by creating conditions that the system would not reasonably be expected to encounter during normal conditions. Stress testing places extreme demands that are well beyond the planning thresholds of the software to determine how robust it is. The focus here is on attempting to compromise the availability of the system by creating a denial-of-service (DoS) condition.
The most common type of stress testing attempts to give the system too much of something (for example, simultaneous connections or data). During development, the team will build the software so that it handles a certain volume of activity or data. This volume may be specified as a nonfunctional requirement, or it may be arbitrarily determined by the team based on their experience. Typically, this value is determined by measuring or predicting the maximum load that the system is likely to be presented. To stress-test the system with regard to this value, the team would simply exceed it under different conditions and see what happens. The most common way to conduct these tests is by using scripts that generate thousands of simulated connections or by uploading exceptionally high volumes of data (either as many large files or fewer huge ones).
Not all stress tests are about overwhelming the software; it is also possible to underwhelm it. This type of stress testing provides the system with too little of something (for example, network bandwidth, CPU cycles, or memory). The idea here is to see how the system deals with a threat called resource starvation, in which an attacker intentionally causes the system to consume resources until none are left. A robust system would gracefully degrade its capabilities during an event like this but wouldn’t fail altogether. Insufficient-resource tests are also useful to determine the absolute minimum configuration necessary for nominal system performance.
Security Regression Testing
Software is almost never written securely on the first attempt. Organizations with mature development processes will take steps like the ones we’ve discussed in this chapter to detect and fix software flaws and vulnerabilities before the system is put into production. Invariably, errors will be found, leading to fixes. The catch is that fixing a vulnerability may very well inadvertently break some other function of the system or even create a new set of vulnerabilities. Security regression testing is the formal process by which code that has been modified is tested to ensure that no features and security characteristics were compromised by the modifications. Obviously, regression testing is only as effective as the standardized suite of tests that were developed for it. If the tests provide insufficient coverage, regression testing may not reveal new flaws that may have been introduced during the corrective process.
Code Reviews
One of the best practices for quality assurance and secure coding is the code review, which is a systematic examination of the instructions included in a piece of software, performed by someone other than the author of the code. This approach is a hallmark of mature software development processes. In fact, in many organizations, developers are not allowed to push out their software modules until someone else has signed off on them after doing code reviews. Think of this as proofreading an important document before you send it to an important person. If you try to proofread it yourself, you will probably not catch all those embarrassing typos and grammatical errors as easily as if someone else were to check it.
Code reviews go way beyond checking for typos, though that is certainly one element of it. It all starts with a set of coding standards developed by the organization that wrote the software. Reviewers could be an internal team, an outsourced developer, or a commercial vendor. Obviously, code reviews of off-the-shelf commercial software are extremely rare unless the software is open source or you happen to be a major government agency. Still, each development shop will have a style guide or documented coding standards that cover everything from how to indent the code to when and how to use existing code libraries. Therefore, a preliminary step to the code review is to ensure that the author followed the team’s standards. In addition to helping the maintainability of the software, this step gives the code reviewer a preview of the magnitude of work ahead; a sloppy coder will probably have a lot of other, harder-to-find defects in his code, and each of those defects is a potential security vulnerability.
Static Analysis Tools
We discussed static and dynamic analysis in Chapter 4 in the context of assessing software for vulnerabilities. That was an after-the-fact test to find defects in any software, whether it was developed in house or acquired from someone else. But what if we apply the same techniques as we develop the code instead of waiting until it is completed? Most mature software development organizations integrate static analysis tools into their software development process. When a developer finishes writing a software module and submits it to the code repository, a suite of tests that includes static analysis tools is run against it. If the module doesn’t pass these tests, the submission is rejected and the developer has to fix whatever vulnerabilities were found. By integrating automated static analysis into the code submission process, we can greatly reduce the number of vulnerabilities in our software.
Dynamic Analysis Tools
Another way in which software developers reduce vulnerabilities is by integrating dynamic analysis tools into their development process. As we discussed in Chapter 4, dynamic program analysis is the examination of a program while it is being executed. There are many approaches to this. Some tools enable you to stop the program after each line of code is executed, or at user-defined checkpoints, much like a debugger. Others will map out the possible execution flows, determine which inputs would cause different branches to be followed, and then run the program with those inputs to see what happens. This last approach is usually infeasible for large programs because they may have too many possible flows to examine in a reasonable (or even an unreasonable) amount of time.
Code coverage is the measure of how much of a program is examined by a particular set of tests. While it may not be possible to examine every possible flow through a large application, we want to maximize the percentage of the program that is evaluated at a particular level of effort. Most programs don’t need more than 75 percent code coverage to be considered well-tested. Above that point, the new bugs that may be uncovered come at a much higher cost than the developers can or want to pay. However, for mission- or safety-critical systems, especially ones with a smaller code base, 100 percent code coverage may be appropriate or even required.
EXAM TIP When taking the exam, keep in mind the differences between the two approaches: static program analysis does not require code execution; dynamic program analysis requires running it.
Formal Methods of Verifying Critical Software
When you need to be absolutely sure that a program will exactly do specific things and won’t do any others, static and dynamic analysis may not be enough. Formal methods are mathematical approaches to specifying, developing, and verifying software. On the low end of the spectrum of these approaches, we have formal specifications, which are ways to describe the software requirements in very rigorous terms. Often, a formal specification looks like something out of an algebra textbook. This enables the developers to ensure consistency and completeness of the requirements, which cuts down on unexpected outputs. If you ever come across formal methods, this is what you will probably see.
Still, for some safety-critical systems (such as a medical infusion pump), it’s not enough to formally specify them. In these cases, you want to be able to prove that they won’t behave unexpectedly under any conditions. For this, the entire software development process is extremely rigorous. Beyond the formal specification, every property of the system is mathematically proven during the design and then verified after implementation. This level of rigor guarantees that the program will behave exactly as intended, but it comes with a huge cost. For this reason, only specific mission-critical components of larger software systems are normally developed using formal methods.
Secure Coding Best Practices
Perhaps the most important concept behind software development is that of quality. Quality can be defined as fitness for purpose—in other words, how good something is at whatever it is meant to do. A quality car will be good for transportation. We don’t have to worry about it breaking down or failing to protect its occupants in a crash or being easy for a thief to steal. When we need to go somewhere, we simply get in the car and count on it safely taking us to wherever we need to go. Similarly, we don’t have to worry about quality software crashing, corrupting our data under unforeseen circumstances, or being easy for someone to subvert. Sadly, many developers still think of functionality first (or only) when thinking about quality. When we look at things holistically, we should see that quality is the most important concept in developing secure software.
This, of course, is not a new problem. Secure software development has been a challenge for a few decades. Unsurprisingly, there is an established body of best practices to minimize the flaws and vulnerabilities in our code. You should be familiar with what some of the best-known advocates for secure coding recommend.
Input Validation
If there is one universal rule to developing secure software, it is this: don’t ever trust any input entered by a user. This is not just an issue of protecting our systems against malicious attackers; it is equally applicable to innocent user errors. The best approach to validating inputs is to perform context-sensitive whitelisting. In other words, consider what is supposed to be happening within the software system at the specific points in which the input is elicited from the user, and then allow only the values that are appropriate. For example, if you are getting a credit card number from a user, you would allow only 16 consecutive numeric characters to be entered. Anything else would be disallowed.
Perhaps one of the most well-known examples of adversarial exploitation of improper user input validation is Structured Query Language (SQL) injection (SQLi). SQL is a language developed by IBM to query information in a database management system (DBMS). Because user credentials for web applications are commonly stored in a DBMS, many web apps will use SQL to authenticate their users. A typical insecure SQL query to accomplish this in PHP is shown here:

Absent any validation of the user inputs, the user could provide the username attacker' or 1=1 -- and pawned (or anything or nothing) for the password, which would result in the following query string:
![]()
If the DBMS for this web app is MySQL, that system will interpret anything after two dashes as a comment, which will be ignored. This means that the value in the password field is irrelevant, because it will never be evaluated by the database. The username can be anything (or empty), but because the logical condition 1=1 is always true, the query will return all the registered users. Because the number of users is greater than zero, the attacker will be authenticated.
Clearly, we need to validate inputs such as these, but should we do it on the client side or the server side? Client-side validation is often implemented through JavaScript and embedded within the code for the page containing the form. The advantage of this approach is that errors are caught at the point of entry, and the form is not submitted to the server until all values are validated. The disadvantage is that client-side validation is easily negated using commonly available and easy-to-use tools. The preferred approach is to do client-side validation to enhance the user experience of benign users, but double-check everything on the server side to ensure protection against malicious actors.
Output Encoding
Sometimes user inputs are displayed directly on a web page. If you’ve ever posted anything on social media or left a product review at a vendor’s site, then you’ve provided input (your post or review) that a web application incorporated into an HTML document (the updated page). But what happens if your input includes HTML tags? This could be useful if you wanted to use boldface by stating you are <b>very</b> happy about your purchase. (The <b> tag in HTML denotes boldface.) It could just as easily be problematic if you included a <script> tag with some malicious JavaScript. The web browser will happily interpret benign and malicious HTML just the same.
Output encoding is a technique that converts user inputs into safe representations that a web browser cannot interpret as HTML. So, going back to our previous example, when you enter <b>very</b> in a purchase review, the HTML tags are “escaped” or rendered in a way that prevents the browser from interpreting them as valid HTML. This is the most important control to prevent cross-site scripting (XSS) attacks.
Session Management
As you may know, HTTP is a stateless protocol. This means that every web server is a bit of an amnesiac; it doesn’t remember you from one request to another. A common way around this is to use cookies to sort of “remind” the server of who you are so that, even if you haven’t authenticated, you can go from page to page on an online retail store and have the web application remember what you may have added to your shopping cart. Every time you request a resource (such as a web page or an image), your browser sends along a cookie so the web application can tell you apart from thousands of other visitors. The cookie is simply a text file that usually contains some sort of unique identifier for you. This identifier is typically known as the session ID.
A HTTP session is sequence of requests and responses associated with the same user, while session management is the process of securely handling these sessions. The word “securely” is critical because, absent security, sessions can easily be hijacked. Let’s go back to the previous example of writing a session ID on a cookie to track a given user. That cookie is sent along with every request, so anyone who can sniff it off the network can impersonate the legitimate session user. All they would have to do is wait for you to send a request, intercept it, get the session ID from the cookie, and then send their own request to the server, pretending to be you.
Secure session management revolves around two basic principles: use HTTPS whenever a session is active, and ensure that session IDs are not easy to guess. HTTPS is essential whenever any sensitive information is exchanged, and this is particularly true of a session ID. Even if attackers can’t break your secure connection to steal your ID, they could still try to guess it. Suppose a web application assigns session IDs sequentially. You send a request and see that your session ID is 1000. You clear your cache and cookies and interact with the application again, noticing that your new session ID is 1002. It would be reasonable to assume that there is another active session with an ID of 1001, so you rewrite your cookie to have that value and send another request to the web application. Voilà! You just took over someone else’s session. Secure session management involves using IDs that are hard to guess (such as pseudo-random), long enough to prevent brute-force attacks, and generic so that they are not based on any identifiable information.
Authentication
Most software systems, particularly distributed ones, require user authentication. Sadly, this is an area that is often given insufficient attention during the development process. Many programmers seem to think that authentication is pretty easy, and a surprising number of them prefer to implement their own. The problem with weak authentication mechanisms in distributed software systems is that they can turn the platform into an easy foothold into the trusted network for the attacker. Additionally, because many people reuse passwords in multiple systems, obtaining credentials on one (poorly built or protected) system often leads to unauthorized access to others. If at all possible, we should avoid building our own authentication and rely instead on one of the approaches to SSO we’ve discussed before.
Regardless of whether you roll your own or use someone else’s, here are some of the best practices for authentication in software systems:
• Use multifactor authentication (MFA) whenever possible.
• Enforce strong passwords with minimum lengths (to thwart brute-force attacks) as well as maximum lengths (to protect against long password DoS attacks).
• Never store or transmit passwords in plaintext anywhere (and use the appropriate cryptographic techniques to protect them).
• Implement failed-login account lockouts if at all possible (but beware of this making you vulnerable to account DoS attacks).
• Log all authentication attempts and ensure that the logs are periodically reviewed (or, better yet, generate appropriate alerts).
NOTE We discussed authentication in general and SSO in particular in Chapter 8.
Data Protection
Passwords are not the only data that we need to protect in our software systems. Depending on their functions, these applications can contain personal data, financial information, or trade secrets. Generally speaking, data exists in one of three states: at rest, in motion, or in use. These states and their interrelations are shown in Figure 9-4.
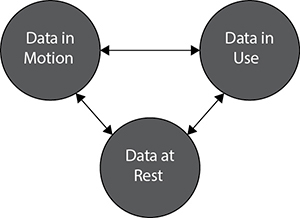
Figure 9-4 The states of data
Data at Rest
Information in a software system spends most of its time waiting to be used. The term data at rest refers to data that resides in external or auxiliary storage devices, such as hard disk drives (HDDs), solid-state drives (SSDs), optical discs (CDs/DVDs), or even on magnetic tape. A challenge with protecting data in this state is that it is vulnerable not only to threat actors attempting to reach it over our systems and networks, but also to anyone who can gain physical access to the device. The best approach to protecting data at rest is to encrypt it. Every major operating system provides encryption means for individual files or entire volumes in a way that is almost completely transparent to the user. Similarly, every major database management system enables you to encrypt data deemed sensitive, such as passwords and credit card numbers.
Data in Motion
Data in motion is data that is moving between computing nodes over a data network such as the Internet. This is perhaps the riskiest time for our data—when it leaves the confines of our protected enclaves and ventures into that Wild West that is the Internet. The single best protection for our data while it is in motion (whether within or without our protected networks) is strong encryption such as that offered by Transport Layer Security (TLS) version 1.1 and later or IPSec, both of which support multiple cipher suites (though some of these are not as strong as others). By and large, TLS relies on digital certificates (we talked about those in the last chapter) to certify the identity of one or both endpoints. Another approach to protecting our data in motion is to use trusted channels between critical nodes. Virtual private networks (VPNs) are frequently used to provide secure connections between remote users and corporate resources. VPNs are also used to securely connect campuses or other nodes that are physically distant from each other. The trusted channels we thus create enable secure communications over shared or untrusted network infrastructure.
Data in Use
Data in use refers to data residing in primary storage devices, such as volatile memory (such as RAM), memory caches, or CPU registers. Typically, data remains in primary storage for relatively short periods of time while a process is using it. Note, however, that anything stored in volatile memory could persist there for extended periods (until power is shut down) in some cases. The point is that data in use is being touched by the CPU and will eventually go back to being data at rest or end up being deleted. Many people think this state is safe, but the Meltdown, Spectre, and BranchScope attacks that came to light in 2018 show how a clever attacker can exploit hardware features in most modern CPUs. Meltdown, which affects Intel and ARM microprocessors, works by exploiting the manner in which memory mapping occurs. Since cache memory is a lot faster than main memory, most modern CPUs include ways to keep frequently used data in the faster cache. Spectre and BranchScope, on the other hand, take advantage of a feature called speculative execution, which is meant to improve the performance of a process by guessing what future instructions will be, based on data available in the present. All three of these attacks go after data in use.
So, how do we protect our data in use? For now, it boils down to ensuring that our software is tested against these types of attacks. Obviously, this is a tricky proposition, since it is very difficult to identify and test for every possible software flaw. In the near future, whole-memory encryption will mitigate the risks described in this section, particularly when coupled with the storage of keys in CPU registers instead of in RAM. Until these changes are widely available, however, we must remain vigilant to the threats against our data while it is in use.
Parameterized Queries
A common threat against web applications is the SQL injection (SQLi) class of attacks. We already covered them in Chapter 7, but by way of review, SQLi enables an attacker to insert arbitrary code into a SQL query. This typically starts by inserting an escape character (such as a closing quote around a literal value), terminating the query that the application developer intended to execute based on the user input, and then inserting a new and malicious SQL command. The key to SQLi working is the insertion of user inputs directly into an SQL query. Think of it as cutting and pasting the input into the actual query that gets executed by the database.
A parameterized query (also known as a prepared statement) is a programming technique that treats user inputs as parameters to a function instead of substrings in a literal query. This means that the programmer can specify what values are expected (for example, a number, a date, a username) and validate that they conform to whatever limits are reasonable (such as a value range, a maximum length for a username) before integrating them into a query that will be executed. Properly implemented, parameterized queries are the best defense against SQLi attacks. They also highlight the importance of validating user inputs and program parameters.
Chapter Review
Although you may not spend much time (if at all) developing software, as a security analyst you will certainly have to deal with the consequences of any insecure coding practices. Your best bet is to be familiar with the processes and issues and be part of the solution. Simply attending the meetings, asking questions, and sharing your thoughts could be the keys to avoiding a catastrophic compromise that results from programmers who didn’t realize the potential consequences of their (otherwise reasonable) decisions. Ideally, you are part of a cohesive DevSecOps team that consistently develops high-quality code. If this is not the case, maybe you can start your organization down this path.
As for the CySA+ exam, you should have an awareness of the major issues with developing secure code. You will be expected to know how a cybersecurity analyst can proactively or, if need be, reactively address vulnerabilities in custom software systems. Some of the key concepts here are the security tests you can run such as web app vulnerability scans, stress tests, and fuzzing. You may be asked about the SDLC, but you don’t have to be an expert in it.
Questions
1. The practice of testing user input to reduce the impact of malformed user requests is referred to as what?
A. Input validation
B. Static code analysis
C. Manual inspection
D. Stress testing
2. Which phase in the software development lifecycle often highlights friction between developers and business units due to integration and performance issues?
A. Implementation
B. Design
C. Planning
D. Maintenance
3. To reduce the amount of data that must be examined and interpreted by a web application, what method can be used to catch errors before submission?
A. Server-side validation
B. Proxy validation
C. Client-side validation
D. Stress validation
4. What key process is often used to determine the usability and suitability of newly developed software before implementation across an organization?
A. User acceptance testing
B. Parameter validation
C. Regression testing
D. Data filtering
5. Which of the following is not a key characteristic of a Service Oriented Architecture (SOA)?
A. Self-contained components
B. Platform-centric architectures
C. Standardized protocol for requests/responses
D. Components that implement business functions
Use the following scenario and illustration to answer Questions 6–10:
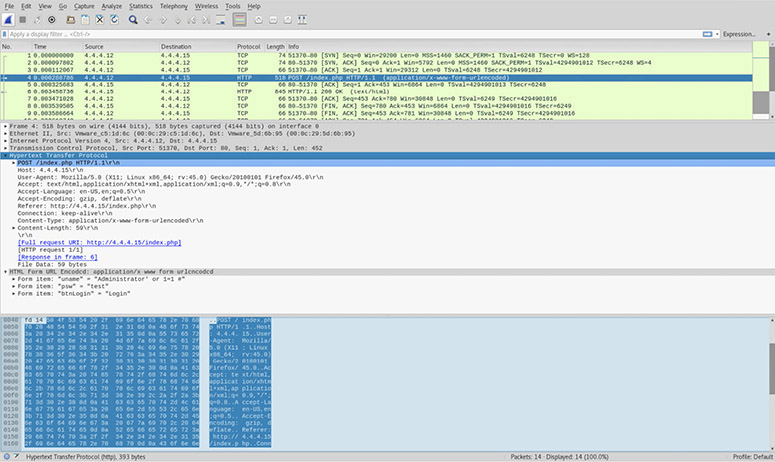
Your accounting department’s administrator has reached out to your team because one of the department’s analysts has discovered a discrepancy in the accounting reports. Some of the department’s paper documents do not match the stored versions, leading them to believe the database has been tampered with. This database is for internal access only, and you can assume that it hasn’t been accessed from outside the corporate network. The administrator tells you that the database software was written several years ago by one individual and that they haven’t been able to update the system since the initial rollout. You are also provided traffic capture data by the local admin to assist with the analysis.
6. After hearing the description of how the software was developed by one person, what process do you know would have improved the software without needing to run it?
A. Runtime analysis
B. Just-in-time analysis
C. Stress testing
D. Code review
7. Based on the traffic-capture data, what is the most likely method used to gain unauthorized access to the web application?
A. Regression
B. Replay attack
C. SQL injection
D. Request forgery
8. What practice may have prevented this particular type attack from being successful?
A. Network segmentation
B. SSL
C. Two-factor authentication
D. Input validation
9. To prevent input from being interpreted as actual commands, what method should the developer have used?
A. Regression testing
B. Generic error messages
C. Session tokens
D. Parameterized queries
10. You have updated the server software and want to test it actively for new flaws. Which method is the least suitable for your requirement?
A. User acceptance testing
B. Static code analysis
C. Stress testing
D. Web app vulnerability scanning
Answers
1. A. Input validation is an approach to protecting systems from abnormal user input by testing the data provided against appropriate values.
2. A. Implementation is all about seeing how the software works in its production environment. Although problems are bound to surface, the most productive organizations have mature mechanisms for feedback for improvement.
3. C. Client-side validation checks are performed on data in the user browser or application before the data is sent to the server. This practice is used alongside server-side validation to improve security and to reduce the load on the server.
4. A. User acceptance testing is a method to determine whether a piece of software meets specifications and is suitable for the business processes.
5. B. Service Oriented Architectures (SOAs) are, in many ways, the opposite of platform-centric ones. This is because SOA components can be replaced without impacting the services offered. One day you could be running Service A in the cloud and the next day on an embedded device, but as long as you provide an identical service, nobody would notice.
6. D. Code review is the systematic examination of software by someone not involved in the initial development process. This ensures an unbiased perspective and promotes adherence to coding and security standards.
7. C. SQL injection is a technique of manipulating input to gain control of a web application’s database server. Notice that the attacker submitted a uname value of "Administrator' or 1=1 #". The second part of the statement (1=1) always evaluates to true, so this is a way to trick a vulnerable system into giving up administrative access. It is effective and powerful, and often facilitates data manipulation or theft.
8. D. Input validation is the practice of constraining and sanitizing input data. This is an effective defense against all types of injection attacks by checking the type, length, format, and range of data against known good types.
9. D. Using parameterized queries is a developer practice for easily differentiating between code and user-provided input.
10. B. All methods except for static code analysis are considered active types of assessments.