
CHAPTER 19
The Importance of Data Privacy and Protection
In this chapter you will learn:
• The difference between privacy and security
• About common data types and laws governing their protection
• How nontechnical controls protect data
• How technical controls protect data
When it comes to privacy and accountability, people always demand the former for themselves and the latter for everyone else.
—David Brin
As security practitioners, we should all have a good understanding of privacy and our obligations with regard to it. After all, we frequently have privileged access to information that could easily be used to infringe on the privacy of others in our organizations, even if done unintentionally. Overstepping that line could very well result in the erosion of the trust in us that enables us to do our jobs protecting our teammates. Worse, it could result in significant financial fines or even jail time. In this chapter, we introduce you to some of the key privacy concepts you need to understand not only for the CySA+ certification, but for the rest of your cybersecurity career.
Privacy vs. Security
Firstly, we should differentiate these two interrelated, but distinct, terms. Privacy indicates the amount of control to which an individual is entitled over how others view, share, or use the individual’s personal information. Privacy is a difficult thing to achieve, because it is difficult for most of us to know who has what piece of information about us where, and what they’re doing with it. You may agree to share your name, address, phone number, and credit card information with a vendor, but it’s difficult to know who, exactly, is able to view or use this information. Reputable vendors will have privacy policies that detail what they will (and won’t) do with your data, but there is always a possibility that a data breach lands your personal information on the Dark Web.
Security is the protection of information assets against unauthorized access, modification, or destruction. Going back to the vendor example, the vendor could (and should) protect your privacy by using appropriate security controls, such as vulnerability management, access controls, and encryption of data at rest and in transit. It is generally easy to have security without privacy but almost impossible to have privacy without security.
It is important to note that security can provide privacy, but it can also limit it. Encrypting all our customers’ information certainly provides a measure of privacy for them. On the other hand, if our security policy specifies that all data processed or stored on a corporate information system belongs to the company, and then we implement tools to monitor the activities of our employees, we are definitely reducing their privacy in the workplace.
Types of Data
It’s worth highlighting that our discussion in this chapter centers on the compliance and assessment implications of data privacy and protection. In other words, we are mostly concerned with data types for which existing laws or regulations impose organizational requirements. Here are four types of data that fit this constraint:
• Personal data Any information relating to a natural person (as opposed to a corporation), including name, identification number, address, and phone number
• Personal health data Individually identifiable information relating to the past, present, or future health status of an individual
• Financial data Individually identifiable information relating to the transactions, assets, and liabilities of an individual
• Copyrighted data Data protected under copyright law
Legal Requirements for Data
No single statute or law specifies an organization’s legal requirements with regard to data security and privacy for protected data. Instead, multiple local, national, and international laws, when taken together, dictate what we should do with the data that is entrusted to our care. If this sounds confusing or difficult to address, there is hope. Most laws speak of “reasonable” measures that ought to be taken but don’t define what these should be. Legal developments over the last several years point toward a legal standard for “reasonableness” that hinges on assessing risk and then implementing controls that reduce that risk to levels that are acceptable to the organization. It is about process, more so than about specific controls. Still, there are certain laws with which you should be aware.
In the following sections, we provide notable examples of laws that govern each of the four types of data: personal, health, financial, and copyrighted. It is important to remember that this list is not meant to be all-inclusive. It is simply intended as a start point for understanding legal and regulatory requirements on these types of data.
General Data Protection Regulation
The General Data Protection Regulation (GDPR) is perhaps the most important privacy law affecting organizations around the world today. It affects any organization holding personal data on a European Union (EU) citizen and requires, among other things, that these organizations not use the data without the subject’s consent, that they delete the data when a subject requests them to do so, and that they report a data breach within 72 hours of becoming aware of it. A key provision of the GDPR is that data be retained only as long as it is necessary for its intended purpose, and no longer.
Health Insurance Portability and Accountability Act
In the United States, the Health Insurance Portability and Accountability Act (HIPAA) is a federal law that covers the storage, use, and transmission of personal medical information and healthcare data. It outlines how security should be managed for any facility that creates, accesses, shares, or destroys medical information. HIPAA mandates steep federal penalties for noncompliance. If medical information is used in a way that violates the privacy standards dictated by HIPAA, even by mistake, monetary penalties of at least $100 per violation are enforced, up to $1.5 million per year, per standard. If protected health information is obtained or disclosed knowingly, the fines can be as much as $50,000 per violation, plus one year in prison. If the information is obtained or disclosed under false pretenses, the fine can be up to $250,000, with ten years in prison if there is intent to sell or use the information for commercial advantage, personal gain, or malicious harm. This is serious business.
Payment Card Industry Data Security Standard
The Payment Card Industry Data Security Standard (PCI DSS) is a private-sector industry initiative, not a law. Noncompliance with or violations of the PCI DSS may result in financial penalties or possible revocation of merchant status within the credit card industry, but not jail time. The PCI DSS applies to any entity that processes, transmits, stores, or accepts credit card data. Varying levels of compliance and penalties exist and depend on the size of the customer and the volume of transactions. However, credit cards are used by tens of millions of people and are accepted almost anywhere, which means just about every business in the world is affected by the PCI DSS.
US Copyright Law
US copyright law is discussed in Chapters 1–8 and 10–12 of Title 17 of the United States Code. But it is all builds on the Copyright Act of 1976, which provides the basic framework for the current law. Copyright law protects the right of the creator of an original work to control the public distribution, reproduction, display, and adaptation of that original work. The laws cover many categories of work: pictorial, graphic, musical, dramatic, literary, pantomime, motion picture, sculptural, sound recording, and architectural. A person’s creation is provided copyright protection for the duration of his or her life, plus 70 years. If a copyrighted work was created jointly by multiple authors, the 70 years start counting after the death of the last surviving creator.
Nontechnical Controls
Security controls are measures that counter specific risks by reducing their probability of occurring. For this reason, they are also called countermeasures. There are two general types of controls that apply to data: technical and nontechnical. The difference between the two hinges on whether or not the control depends on hardware or software to function properly. A nontechnical control is not implemented through technical means such as hardware or software. Instead, these controls are normally implemented through policies and procedures. They are sometimes called administrative or soft controls. Let’s see some examples of these.
Data Ownership
Who “owns” the data? Data ownership refers both to having possession of the data and to having responsibility over it. For example, you are the owner of your own personal data. When you provide some of it to a vendor, such as Equifax, that entity has a legal responsibility to safeguard it for you. That company also becomes an owner of the data you shared with it.
For purposes of the CySA+ exam, the data owner (information owner) is usually a member of management who is in charge of a specific business unit, and who is ultimately responsible for the protection and use of a specific subset of information. The data owner has due care responsibilities and thus will be held responsible for any negligent act that results in the corruption or disclosure of the data. The data owner decides upon the classification of the data she is responsible for and alters that classification if the business need arises. This person is also responsible for ensuring that the necessary security controls are in place, defining security requirements per classification and backup requirements, approving any disclosure activities, ensuring that proper access rights are being used, and defining user access criteria.

EXAM TIP If you’re asked about the data owner in a company, look for the response that mentions a manager or executive in charge of whatever part of the business uses the data.
The formal assignment of data ownership is an important nontechnical control because it establishes responsibility with an individual. This is an important first step we must take before we can classify the data, which is the next control we’ll discuss.
Data Classification
Classification indicates that something belongs to a certain class. We could say, for example, that your personnel file belongs to the class named “private,” and that your company’s marketing brochure for the latest appliance belongs to the class “public.” Right away, you would have a sense that your personnel file has more value to your company than the brochure. The rationale behind assigning values to different assets and data is that this enables a company to gauge the amount of resources that should go toward protecting each data class, because not all assets and data have the same value to a company.
Information can be classified by sensitivity, criticality, or both. Either way, the classification aims to quantify how much loss an organization would likely suffer if the information was lost. The sensitivity of information is commensurate with the losses to an organization if that information was revealed to unauthorized individuals. This kind of compromise made headlines in 2017, for example, with the Equifax data breach. The compromise of personal data on 147 million people ended up costing the company approximately $1.4 billion.
The criticality of information, on the other hand, is an indicator of how the loss of the information would impact the fundamental business processes of the organization. In other words, critical information is essential for the organization to continue operations. For example, in September 2019, Danish hearing-aid manufacturer Demant suffered a devastating ransomware attack that forced it to shut down its entire IT infrastructure. The incident ended up costing the company in excess of $80 million, with a good portion of that amount stemming from lost sales and the inability to service its end users.
Data Confidentiality
Once we’ve classified our data, even if it’s simply “confidential” and “everything else,” we can make informed decisions about what we share with whom. We’ll talk more about how we restrict sharing data using technical controls later in this chapter (in the section “Technical Controls”), but we must not forget that protected information can be communicated verbally. For example, when we tell someone something “in confidence,” we expect the other person to share it only with authorized individuals, or with nobody. But how can we ensure that others keep their end of that deal? If we have an existing contract with that party, it may (and really should) include a confidentiality clause that limits what each party can share with whom. Apart from that, the most common means of enforcing confidentiality is the nondisclosure agreement.
Nondisclosure Agreement
A nondisclosure agreement (NDA) is a legally binding document that restricts the manner in which two (or more) parties share information about each other with any other entity. Suppose you want to work with a vendor who could provide you a service or product that you need for your organization. You want to figure out how much this is going to cost you, but in order to give you an accurate cost, the vendor needs confidential information about your organization. The best way forward would be to enter into an NDA with the vendor so you can share your sensitive information, knowing the vendor could not divulge it to anyone else. If they did, they’d be held liable in civil court.
Another angle to an NDA extends beyond willful disclosure. The party receiving the sensitive information from another is required to apply the same security controls to it that they would use with similar information of their own. In other words, if you reveal confidential information to someone or some entity, that person or entity must protect it just as they would their own confidential information. If they suffer a breach and it turns out in the ensuing investigation that they didn’t protect your information in this manner, they would be liable for any losses you suffer. This is why you should always establish an NDA before sharing sensitive information.
Data Sovereignty
Suppose you are a citizen of Country A, a nation with very stringent data privacy laws. One day, you sign up for a free webmail account with a company based in Country B. Could the government of Country B now compel your webmail provider to hand over all your messages? Well, that depends on which country is sovereign over your data. Data sovereignty is the notion that the country in which data is collected has supreme legal authority over it. Clearly, if Country A decided to establish its data sovereignty, Country B could well be within its rights to disregard such claims. However, if companies based in Country B want to do business in Country A, they must abide by its laws or face penalties. This is the principle behind the GDPR, the EU law that claims sovereignty over data on citizens of the block of countries for which it applies.
Data sovereignty is a particularly tricky concept when it comes to cloud services. One of the benefits of storing data in the cloud is that your data and services are free to move around, sort of like real clouds in the sky. If the computing resources in one country are saturated or otherwise unavailable, your service provider can seamlessly move you to a different set of physical resources, perhaps in a different country. Now, what if that country doesn’t respect your country’s claims of data sovereignty? The answer is complicated. Some countries that claim data sovereignty prefer to avoid the whole mess by requiring cloud service providers to use only in-country assets to provide services to their citizens. This is one of the key drivers for major cloud providers to invest in data centers in countries that otherwise might seem like odd choices for this.
Data Minimization
Besides data sovereignty, another key principle in the GDPR has to do with how much data you can collect and use. Data minimization is the principle that you can acquire and retain only the minimum amount of data required to satisfy the specific purpose for which the owner has authorized use of that data. For example, suppose that we run an online shoe store. If you want to buy a pair of shoes, we could reasonably be expected to ask you all sorts of personal questions, such as your name, address, payment information, and shoe size. Now suppose we want to keep our options open in case we ever want to start selling clothing, so we gather and retain your body dimensions. We would then be violating the principle of data minimization. If this were a provision of a privacy law such as the GDPR (which it is), we could be fined for doing this.
Data minimization may seem like an undue limitation on our pursuit of business opportunities, but it starts to make a lot of sense when you consider the impacts of a data breach. If I’ve been gathering all sorts of personal information about you and our systems are breached, then your exposure could be huge. If we had stuck to the minimal set of data that we needed to do our job of selling you shoes, your exposure would be smaller.
Data Purpose Limitation
Purpose limitation, another key principle of the GDPR, states that data may be used only for the purpose for which it was collected and not for any other incompatible purpose. Going back to the example of an online shoe store, suppose that we start analyzing your shoe purchasing behaviors to infer other traits about you. For example, you buy running shoes more frequently than the average shopper, so we assume that you are an avid runner. Because runners tend to be healthy individuals, we share this information with a partner in the health insurance business. They pursue you as a prospect, land your business, and we make a healthy referral fee. In this example, we would’ve violated the principle of purpose limitation because you authorized us to use your personal information to sell you shoes, and we used it to refer you to a healthcare insurer.
Data Retention
Data retention is the deliberate preservation and protection of digital data in order to satisfy business or legal requirements. It has nothing to do with haphazardly not deleting files. Instead, this intentional effort is aimed at ensuring that your business processes run smoothly and that you are able to satisfy any regulatory or legal requests for information.
If you are legally responsible for maintaining the security of a set of data, it might make sense that you’d want to get rid of it as soon as possible to reduce your personal risk. Or you might prefer to hold on to data as long as possible in hopes that it will be useful at some future point in time. There is no universal agreement on how long an organization should retain data. Legal and regulatory requirements (where they exist) vary among countries and business sectors. What is universal is the need to ensure that your organization has and follows a documented data retention policy. Doing otherwise is flirting with disaster, particularly when dealing with pending or ongoing litigation. It is not enough, of course, simply to have a policy in place; you must ensure that it is being followed, and you must document this through regular audits.

NOTE When outsourcing data storage, you must specify in the contract language how long the storage provider will retain your data after you stop doing business with them and what process they will use to eradicate your data from their systems.
Data Retention Standards
At their core, data retention standards answer three fundamental questions:
• What data do we keep?
• How long do we keep this data?
• Where do we keep this data?
Most security professionals understand the first two questions—the “what” and the “how long” are easy. After all, many of us are accustomed to keeping tax records for three years in case we get audited. The last question, however, surprises more than a few of us. The twist is that the question is not so much about the location per se, but rather the manner in which the data is kept at that location. To be useful to us, retained data must be easy to locate and retrieve.
Think about it this way: Suppose your organization had a business transaction with Acme Corporation, in which you learned that Acme was involved in the sale of a particular service to a client in another country. Two years later, you receive a third-party subpoena asking for any information you may have regarding that sale. You know you retained all your data for three years, but you have no idea where the relevant data may be located. Was it an e-mail, a recording of a phone conversation, the minutes from a meeting, or something else? Where would you go looking for it?
In order for retained data to be useful, it must be accessible in a timely manner. It really does us no good to have data that takes an inordinate (and perhaps prohibitive) amount of effort to query. To ensure this accessibility, you’ll find it helpful to specify, at a minimum, the following requirements as part of your data retention standards:
• Taxonomy A taxonomy is a scheme for classifying data. This classification can be made using a variety of categories, including functional (such as human resources, product development), chronological (such as 2018, 2019, and so on), organizational (such as executives, union employees), or any combination of these or other categories.
• Normalization Retained data will come in a variety of formats, including word processing documents, database records, flat files, images, PDF files, video, and so on. Simply storing the data in its original format will not suffice in any but the most trivial cases. Instead, you need to develop tagging schemas that will make the data searchable. As part of this step, it is useful to eliminate duplicates.
• Indexing Retained data must be searchable if you must be able to pull out specific items of interest in a reasonable timeframe. The most common approach to making data searchable is to build indexes for it. Many archiving systems implement this feature, but others do not. Any indexing approach must support the likely future queries on the archived data.
Ideally, archiving occurs in a centralized, regimented, and homogenous manner. We all know, however, that this is seldom the case. We may have to compromise to arrive at solutions that meet our minimum requirements within our resource constraints. Still, as we plan and implement our retention standards, we must remain focused on how we will efficiently access archived data many months or years.
Technical Controls
A technical control is a security control or countermeasure implemented through the use of an IT asset. This asset is usually, but not always, some sort of software that is configured in a particular way so as to mitigate a specific set of risks. This linkage between controls and the risks they are meant to mitigate is important, because we need to understand the context in which specific controls were implemented. Let us now discuss some examples of technical controls intended for data protection and privacy.
Access Controls
One of the best ways to protect data is to control who has access to it. Many types of technical access controls enable a user to access a system and the resources within that system. A technical access control may be a username and password combination, a Kerberos implementation, biometrics, public key infrastructure (PKI), RADIUS, TACACS+, or authentication using a smart card through a reader connected to a system. These technologies verify the user is who he says he is by using different types of authentication methods. Once a user is properly authenticated, he can be authorized and allowed access to protected data.
Encryption
Encryption, which we discussed in some detail in Chapter 8, can be used to control logical access to information by protecting it as it passes throughout a network and resides on computers. Encryption ensures that the information is received by the correct entity and that it is not modified during transmission. This is an example of a technical control that can preserve the confidentiality and integrity of protected data and enforce specific paths for communication to take place.
Sharing Data While Preserving Privacy
Sometimes, things are not black and white when it comes to who gets to see private data. Suppose you have a customer service representative whose job involves answering questions about customers’ orders. That person should have some way of ensuring that she and the customer are talking about the same order or which payment card that was used for it. She needs access to some of the private data, but does she need access to all of it? There are a number of approaches to providing limited access to just enough data for someone to do their job while simultaneously protecting most of the private information. These approaches include data masking, deidentification, and tokenization.
Data Masking
Data masking is the process of covering or replacing parts of sensitive data with data that is not sensitive. It is a simple and effective approach to preventing someone from viewing confidential information. A very common example of this is how password fields show dots or asterisks for each character you type in them. The idea is to prevent anyone around you from seeing what you’re typing on the screen. Another common use of data masking is for payment card information. Our customer service representative could be allowed to view only the last four digits of the credit card used to place an order, with the other twelve digits replaced (or masked) with x’s. This would preserve the privacy of the customer’s sensitive information while allowing her to do her job.
Deidentification
Sometimes, you need access to a lot of private information in a way that does not reveal to whom that information belongs. For example, you may be running a clinical study on the effectiveness of a vaccine. You’ll need to know a lot of private information about each subject of the test, including medical history, age, and personal habits involving alcohol and tobacco. You wouldn’t, however, need to know their identities.
Deidentification is the process of making it impossible (or at least very hard) to determine the individual to whom a specific data record belongs. It is one of the main approaches to data privacy protection, particularly in healthcare applications, and is sometimes called data anonymization. A common way to deidentify a record is to remove its identifier fields (such as name and Social Security number). The problem with this approach, however, is that there is no way to know if two records belong to the same individual, which means you couldn’t track changes over time. Another approach is to assign a pseudorandom identifier to each individual so that all related records share that identifier. This is called tokenization, and it has its pros and cons, as we discuss in the next section.
A challenge with deidentification is that if sufficient data is available about some individuals, that data can be correlated to data from other sources to deanonymize them. This is particularly true with the abundance of personal data being shared in today’s highly connected society.
Tokenization
Tokenization is the replacement of sensitive data with a nonsensitive equivalent value that has no value to an adversary. This replacement value, or token, enables the party doing the tokenization to map it back to the original (sensitive) value. Figure 19-1 shows how this works in a near-field communication (NFC) payment context. Note that tokenization requires a token service that is trusted by all parties involved.

Figure 19-1 How mobile payment tokenization works (source: https://commons.wikimedia.org/wiki/File:How_mobile_payment_tokenization_works.png)
{kind=link}
At a glance, tokenization may look like data masking, but this is not the case. Data masking is mostly used for sanitizing data that is being displayed. It does not enable someone who has only the masked version of the data to map it back to the original version. Tokenization is all about mapping the two versions to each other so that untrusted parties can act on sensitive data without having direct access to that data.
Digital Rights Management
Digital rights management (DRM) refers to a set of technologies that is applied to controlling access to copyrighted data. The technologies themselves don’t need to be developed exclusively for this purpose. It is the use of a technology that makes it DRM, not its design. In fact, many of the DRM technologies in use today are standard cryptographic ones. For example, when you buy a Software as a Service (SaaS) license for, say, Office 365, Microsoft uses standard user authentication and authorization technologies to ensure that you install and run only the allowed number of copies of the software. Without these checks during the installation (and periodically thereafter), most of the features will stop working after a period of time. A potential problem with this approach is that the end user’s device may not have Internet connectivity.
An approach to DRM that does not require Internet connectivity is the use of product keys. When you install your application, the key you enter is checked against a proprietary algorithm, and if it matches, the installation is activated. It may be tempting to equate this approach to symmetric key encryption, but in reality, the algorithms employed are not always up to cryptographic standards. Since the user has access to both the key and the executable code of the algorithm, the latter can be reverse-engineered with a bit of effort. This could enable a malicious user to develop a product-key generator with which to bypass DRM effectively. A common way around this threat is to require a one-time online activation of the key.
DRM technologies are also used to protect documents. Adobe, Amazon, and Apple, for example, all have their own approaches to limiting the number of copies of an electronic book (e-book) that you can download and read.
Watermarking
One approach to DRM is the use of digital watermarking. Watermarking is the practice of embedding specific data into a file for the purpose of identifying its characteristics (such as its origin or owner). Suppose, for example, that you buy a sensitive and very expensive report from us, and we want to ensure you don’t post it on the Internet for anyone to download. We could embed in it a hidden mark (a set of data) that identifies the owner and provides other useful information such as the date of purchase. If we come across the report, we know where to look to find the watermark, and we can check it to ensure that the correct owner is using it properly. If you share the file with other parties, we can find all the instances of that shared file and then come after you through legal channels for compensation.
The example just covered is one in which the watermark is invisible. So how can we hide it in a file? One approach is steganography, which is the practice of hiding data inside other data. Suppose you have a small image that measures 100 pixels by 100 pixels. Each pixel uses 8 bits for each of the colors red, blue, and green (RBG). Since 8 bits enable you to represent values from 0 to 255, you would represent a bright red pixel as the value 255,0,0 (red = 255, blue = 0, green = 0). Our eyes cannot notice the difference between the version of red that results from 255,0,0 and the one that results from 254,1,1. In other words, we can safely use the last (or least significant) bit each of the three colors of each pixel to our hearts’ content. Three bits times 1000 pixels in the image in our example comes up to 3000 bits, or 375 bytes. This is more than enough space to write the hidden message “Copyright 2020 by McGraw Hill, licensed to John Doe on December 1, 2020” with plenty of room to spare.
EXAM TIP When answering questions about steganography, keep in mind that it can be used for watermarking but not every watermark uses steganography.
This example is helpful for illustration purposes but is not practical for watermarking. One problem with it is that the watermark can be damaged or destroyed if the image is modified by cropping it, enhancing the colors, or even compressing it. The robustness of a watermark is a measure of its resistance to attacks, whether those are deliberate or not. A good watermark would still be detectable even if someone is actively trying to get rid of it. Another problem with our example is the fact that we want to watermark more than just images. The approach we described would not work for portable data format (PDF) files, for example.
NOTE Watermarks will not stop someone from illegally copying and distributing files; they just help the owner track, identify, and prosecute the perpetrator.
Geographic Access Requirements
Another approach to DRM is geoblocking, which is the practice of limiting the locations in which the content is available. For instance, movie studios are very deliberate about the way in which they release their films in order to optimize their profits. If a new release is available around the world at the same time, the studio’s bottom line may very well suffer. To prevent this, they often restrict the countries in which the movie is viewable at any point in time. Geoblocking can also be necessary when you license the content from someone else and the terms of the licensing agreement restrict where you can share it. Another reason to apply geoblocking could be to ensure that you comply with local laws governing what content may not be shown in a given country.
Geoblocking can be implemented either on a local device or on a remote media server. A local implementation requires special software or firmware to verify that the content is consumable in that location. You see this in e-book readers, media players, and satellite receivers. It is also common to have the server make the check before allowing the downloading of restricted media. This could also take advantage of location services on mobile devices but is most frequently done by checking the geographic location corresponding to the IP address of the client.
Geoblocking can be bypassed in a number of ways but is most frequently done by using virtual private network (VPN) providers that enable you to choose the exit point for your connection. As long as you choose an exit point in an allowed region or country, you may be able to fool the server into allowing you to proceed. Another approach is to route your traffic through a proxy server in the appropriate region. Content owners counter these attempts by disallowing VPN or proxy traffic.
Data Loss Prevention
Data loss prevention (DLP) comprises the actions that organizations take to prevent unauthorized external parties from gaining access to sensitive data. That definition has some key terms you should know. First, the data has to be considered sensitive, and we spent a good chunk of the beginning of this chapter discussing its meaning. We can’t keep every single datum safely locked away inside our systems, so we focus our attention, efforts, and funds on the truly important data. Second, DLP is concerned with external parties. If somebody in the accounting department, for example, gains access to internal research and development data, that is a problem, but technically it is not considered a data leak. Finally, the external party gaining access to our sensitive data must be unauthorized to do so. If former business partners have some of our sensitive data that they were authorized to get at the time they were employed, that is not considered a data leak. Although this emphasis on semantics may seem excessive, it is necessary to approach this tremendous threat to our organizations properly.
There is no one-size-fits-all approach to DLP, but there are tried-and-true principles that can be helpful. One important principle is the integration of DLP with our risk-management processes. This enables us to balance out the totality of risks we face and favor controls that mitigate those risks in multiple areas simultaneously. Not only is this helpful in making the most of our resources, but it also keeps us from making decisions in one silo with little or no regard to their impacts on other silos. In the sections that follow, we will look at key elements of any approach to DLP.
Data Inventories
A good first step is to find and characterize all the data in your organization before you even look at DLP solutions. If you’ve implemented the data classification nontechnical control we covered earlier in this chapter, you may already know what data is most important to your organization. Once you figure this out, you can start looking for that data across your servers, workstations, mobile devices, cloud computing platforms, and anywhere else it may live. Once you get a handle on your high-value data and where it resides, you can gradually expand the scope of your search to include less valuable, but still sensitive, data. As you keep expanding the scope of your search, you will reach a point of diminishing returns in which the data you are inventorying is not worth the time you spend looking for it.
Data Flows
Data that stays put is usually of little use to anyone. Most data will move according to specific business processes through specific network pathways. Understanding data flows at this intersection between business and IT is critical to implementing DLP. Many organizations put their DLP sensors at the perimeter of their networks, thinking that is where the leakages would occur. But if these sensors are placed in that location only, a large number of leaks may not be detected or stopped. Additionally, as we will discuss shortly when we cover network DLP, perimeter sensors can often be bypassed by sophisticated attackers.
Implementation, Testing, and Tuning
Assuming we’ve done our administrative homework and have a good understanding of our true DLP requirements, we can evaluate products. Once we select a DLP solution, the next interrelated tasks are integration, testing, and tuning. Obviously, we want to ensure that bringing the new toolset online won’t disrupt any of our existing systems or processes, but testing needs to cover a lot more than that. The most critical elements when testing any DLP solution are to verify that it allows authorized data processing and to ensure that it prevents unauthorized data processing.
Finally, we must remember that everything changes. The solution that is exquisitely implemented, finely tuned, and effective immediately is probably going to be ineffective in the near future if we don’t continuously maintain and improve it. Apart from the efficacy of the tool itself, our organizations change as people, products, and services come and go. The ensuing cultural and environmental changes will also change the effectiveness of our DLP solutions. And, obviously, if we fail to realize that users are installing rogue access points, using thumb drives without restriction, or clicking malicious links, then it is just a matter of time before our expensive DLP solution will be circumvented.
Network DLP
Network DLP (NDLP) applies data protection policies to data in motion. NDLP products are normally implemented as appliances that are deployed at the perimeter of an organization’s networks. They can also be deployed at the boundaries of internal subnetworks and could be deployed as modules within a modular security appliance. Figure 19-2 shows how an NDLP solution might be deployed with a single appliance at the edge of the network and communicating with a DLP policy server.
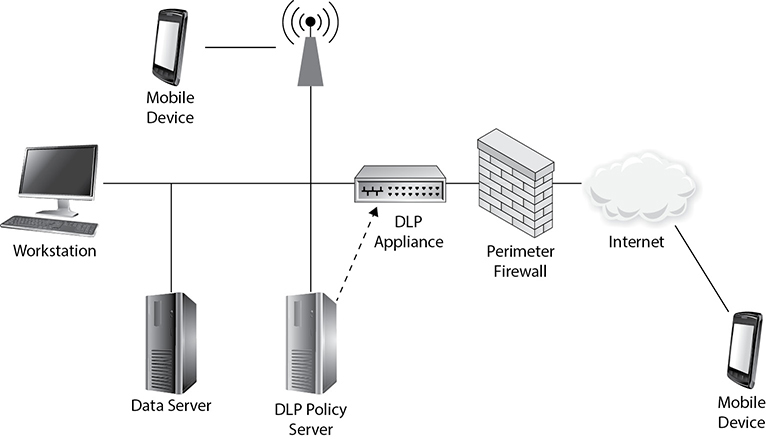
Figure 19-2 Network DLP
Endpoint DLP
Endpoint DLP (EDLP) applies protection policies to data at rest and data in use. EDLP is implemented in software running on each protected endpoint. This software, usually called a DLP agent, communicates with the DLP policy server to update policies and report events. Figure 19-3 illustrates an EDLP implementation.

Figure 19-3 Endpoint DLP
EDLP provides a degree of protection that is normally not possible with NDLP. The reason is that the data is observable at the point of creation. When a user enters personally identifiable information (PII) on the device during an interview with a client, for example, the EDLP agent detects the new sensitive data and immediately applies the pertinent protection policies to it. Even if the data is encrypted on the device when it is at rest, it will have to be decrypted whenever it is in use, which allows for EDLP inspection and monitoring. Finally, if the user attempts to copy the data to a non-networked device such as a thumb drive, or if it is improperly deleted, EDLP will pick up on these possible policy violations. None of these examples would be possible using NDLP.
Hybrid DLP
Another approach to DLP is to deploy both NDLP and EDLP across the enterprise. Obviously, this approach is the costliest and most complex. For organizations that can afford it, however, it offers the best coverage. Figure 19-4 shows how a hybrid NDLP/EDLP deployment might look.
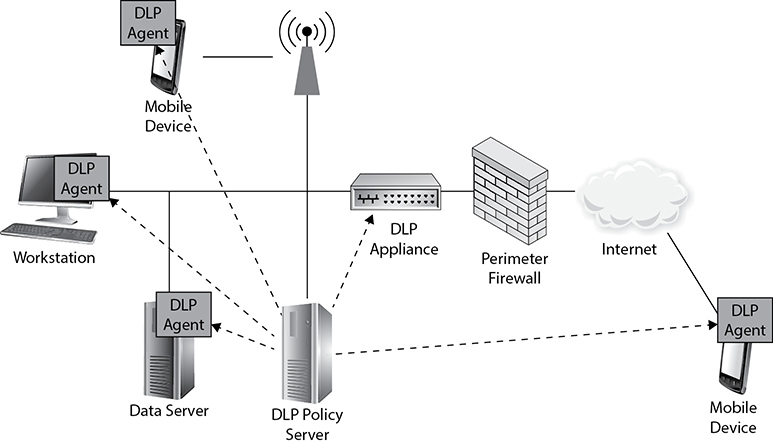
Figure 19-4 Hybrid DLP
Chapter Review
Protecting sensitive data, particularly when it involves the privacy of individuals, is critical to any organization. This protection will probably require the coordination of different controls, both technical and nontechnical. Rather than trying to protect all information equally, our organizations need classification standards that help us identify, handle, and protect data according to its sensitivity and criticality. A key element of our approach must be the protection of privacy of personal data. For various legal, regulatory, and operational reasons, we want to limit what data we acquire, who has access to it (and for what purpose), and how long we retain it.
Questions
1. Which of the following is the most important criterion in determining the classification of data?
A. The level of damage that could be caused if the data were disclosed
B. The likelihood that the data will be accidentally or maliciously disclosed
C. Regulatory requirements in jurisdictions within which the organization is not operating
D. The cost of implementing controls for the data
2. Information classification is most closely related to which of the following?
A. The source of the information
B. The information’s destination
C. The information’s value
D. The information’s age
3. The data owner is most often described by all of the following except which one?
A. Manager in charge of a business unit
B. Ultimately responsible for the protection of the data
C. Financially liable for the loss of the data
D. Ultimately responsible for the use of the data
4. Which of the following is not addressed by data retention standards?
A. What data to keep
B. For whom data is kept
C. How long data is kept
D. Where data is kept
5. What approach should you consider if you need to allow a business partner to reference specific credit card transactions without gaining access to the credit card numbers involved?
A. Tokenization
B. Data minimization
C. Nondisclosure agreement (NDA)
D. Deidentification
6. You want to license a series of action films from a third party and stream them to your customers, but you know that some scenes violate acceptable standards in some countries. What technical control would best enable you to avoid violating those countries’ standards?
A. Data sovereignty
B. Watermarking
C. Geoblocking
D. Data minimization
7. When considering the implementation of a data loss prevention solution, which of the following would be least helpful?
A. Inventorying your data
B. Establishing data classification standards
C. Performing data flow analyses
D. Implementing data retention standards
Answers
1. A. There are many criteria for classifying information, but it is most important to focus on the value of the data or the potential loss from its disclosure. The likelihood of disclosure, irrelevant jurisdictions, and cost considerations should not be central to the classification process.
2. C. Information classification is very strongly related to the information’s value and/or risk. For instance, trade secrets that are the key to a business’s success are highly valuable, which will lead to that data having a higher classification level. Similarly, information that could severely damage a company’s reputation presents a high level of risk and is similarly classified at a higher level.
3. C. The data owner is not usually financially liable for the loss of data. The data owner is typically the manager in charge of a specific business unit and is ultimately responsible for the protection and use of a specific subset of information. In most situations, this person is not financially liable for the loss of his or her data.
4. B. The data retention policy should address what data to keep, where to keep it, how to store it, and for how long to keep it. The policy is not concerned with “for whom” the data is kept.
5. A. Tokenization is the replacement of sensitive data with a nonsensitive equivalent value that enables you to map it back to the original (sensitive) value.
6. C. A geoblocking solution placed on your streaming servers would enable you to limit the locations in which the content is available.
7. D. Although data retention standards are critically important nontechnical controls for any organization, they are not particularly helpful in implementing a data loss prevention solution. The other three activities listed, on the other hand, are all necessary for this.