
CHAPTER 17
Analyze Potential Indicators of Compromise
In this chapter you will learn:
• How to diagnose incidents by examining network symptoms
• How to diagnose incidents by examining host symptoms
• How to diagnose incidents by examining application symptoms
Diagnosis is not the end, but the beginning of practice.
—Martin H. Fischer
The English word “diagnosis” comes from the Greek word diagignōskein, which literally means “to know thoroughly.” Diagnosis, then, implies the ability to see through the myriad of irrelevant facts, honing in on the relevant ones, and arriving at the true root cause of a problem. Unlike portrayals in Hollywood, in the real world, security incidents don’t involve malware in bold-red font, conveniently highlighted for our benefit. Instead, our adversaries go to great lengths to hide behind the massive amount of benign activity in our systems, oftentimes leading us down blind alleys to distract us from their real methods and intentions. The CySA+ exam, like the real world, will offer you plenty of misleading choices, so it’s important that you stay focused on the important symptoms and ignore the rest.
Network-Related Indicators
We start our discussion as you will likely start hunting for many of your adversaries—from the outside in. Our network sensors often give us the first indicators that something is amiss. Armed with this information, we can interrogate hosts and the processes running on them. In the discussions that follow, we assume that you have architected your network with a variety of sensors whose outputs we will use to describe possible attack symptoms.
Bandwidth Utilization
Bandwidth, in computing, is defined as the rate at which data can be transferred through a medium, and it is usually measured in bits per second. Networks are designed to support organizational requirements at peak usage times, but they usually have excess capacity during nonpeak periods. Each network will have its own pattern of utilization with fairly predictable ebbs and flows. Attackers can use these characteristics in two ways: Patient attackers can hide data exfiltration during periods of peak use by using a low-and-slow approach that can make them exceptionally difficult to detect by just looking at network traffic. Most attackers, however, will attempt to download sensitive information quickly and thus generate distinctive signals.
Figure 17-1 shows a suspicious pattern of NetFlow activity. Though one host (10.0.0.6) is clearly consuming more bandwidth than the others, this fact alone can have a multitude of benign explanations. It is apparent from the figure that the host is running a web server, which is serving other hosts in its own subnet. What makes it odd is that the traffic going to the one host in a different subnet is two orders of magnitude greater than anything else in the report. Furthermore, it’s puzzling that a web server is connecting on a high port to a remote web server. When looking at bandwidth consumption as an indicator of compromise, you should look not only at the amount of traffic, but also at the endpoints and directionality of the connection.

Figure 17-1 NetFlow report showing suspicious bandwidth use
Beaconing
Another way in which attackers often tip their hands is by using a common approach for maintaining contact with compromised hosts. Most firewalls are configured to be very careful about inbound connection requests but more permissive about outbound ones. The most frequently used malware command and control (C2) schemes have the compromised host periodically send a message or beacon out to a C2 node. Beaconing is a periodical outbound connection between a compromised computer and an external controller. This beaconing behavior can be detected by its two common characteristics: periodicity and destination. Though some strains of malware randomize the period of the beacons, the destination address, or both, most have a predictable pattern.
Detecting beacons by simple visual examination is extremely difficult, because the connections are usually brief (maybe a handful of packets in either direction) and easily get lost in the chatter of a typical network node. It is easier to do an endpoint analysis and see how regularly a given host communicates with any other hosts. To do this, you would have to sort your traffic logs first by internal source address, then by destination address, and finally by time. Then the typical beacon will jump out and become apparent.

NOTE Some legitimate connections will look like beacons on your network. An example from our personal experience is certain high-end software, which periodically checks with a license server to ensure that it is licensed to be used.
Irregular Peer-to-Peer Communication
Most network traffic follows the familiar client/server paradigm in which a (relatively) small number of well-known servers provide services to a larger number of computers that are not typically servers themselves. Obviously, there are exceptions, such as n-tier architectures in which a front-end server communicates with back-end servers. Still, the paradigm explains the nature of most network traffic, at least within our organizational enclaves. It is a rare thing in a well-architected corporate network for two peer workstations to be communicating with each other. This sort of peer-to-peer communication is usually suspicious and can indicate a compromised host.
Sophisticated attackers will oftentimes dig deeper into your network once they compromise their initial entry point. Whether the first host they own is the workstation of a hapless employee who clicked a malicious link or an ill-configured externally facing server, it is rarely the ultimate target for the attacker. Lateral movement is the process by which an attacker compromises additional hosts within a network after having established a foothold in one. The most common method of achieving this is by leveraging the trusted tools built into the hosts. All they need is a valid username and password to use tools such as Server Message Block (SMB) and PsExec in Windows or Secure Shell (SSH) in Linux. The required credentials can be obtained in a variety of ways, including cached/stored credentials on a compromised host, password guessing, and pass-the-hash attacks on certain Windows domains. Here is a list of things to look for:
• Unprivileged accounts connecting to other hosts Unless a well-known (to you) process is being followed (for example, hosts sharing printers), any regular user connection to a peer host is likely to indicate a compromise and should be investigated.
• Privileged accounts connecting from regular hosts It is possible for a system or domain administrator to be working at someone else’s computer (for example, fixing a user problem) and needing to connect to another resource using privileged credentials, but this should be rare. These connections should get your attention.
• Repeated failed remote logins Many attacks will attempt lateral movement by simply guessing passwords for remote calls. Any incidences of repeated failed login attempts should be promptly investigated, particularly if they are followed by a successful login.
Detecting the irregular peer-to-peer communications described here can be extremely difficult because all you would see are legitimate users using trusted tools to connect to other computers within your network. Context matters, however, and the question to ask as an analyst should be this: Does this user account have any legitimate reason to be connecting from this host to this other resource?
Rogue Devices on the Network
One of the best things you can do to build and maintain secure networks is to know what’s on them. Hardware and software asset management is the bedrock upon which the rest of your security efforts are built. If you don’t know what hosts belong on your network, you won’t be able to determine when an unauthorized one connects. Unfortunately, this lack of asset awareness is the case in many organizations, which makes it easy for attackers to join their devices to target networks and compromise them.
An attacker can connect in two main ways: physically through a network plug and wirelessly. Though you would think that it would be pretty easy to detect a shady character sitting in your lobby with a laptop plugged into a wall socket, the real threat here is with employees who connect their own wireless access points to the network to provide their own devices with wireless access where there may have been none before. Rare as this is, it is damaging enough to require a mention it here. The likelier scenario is for an attacker to connect wirelessly.
In either case, you need a way to tell when a new host is connected. The best approach, of course, is to deploy Network Access Control (NAC) to ensure that each device is authenticated, potentially scanned, and then joined to the appropriate network. NAC solutions abound and give you fine-grained controls with which to implement your policies. They also provide you with centralized logs that can be used to detect attempted connections by rogue devices.
If you don’t have NAC in your environment, your next best bet is to have all logs from your access points (APs) sent to a central store in which you can look for physical (Media Access Control [MAC]) addresses that you haven’t seen before. This process, obviously, is a lot more tedious and less effective. The easiest way for an attacker to get around this surveillance is to change the MAC address to one that is used by a legitimate user. The challenge, of course, is that this could cause problems if that user is also on the network using the same MAC address, but an attacker could simply wait until the user is gone before attempting impersonation.
Scan Sweeps
Some attackers, particularly those more interested in volume than stealth, will use scan sweeps to map out an environment after compromising their first host in it. They may download and run a tool like nmap, or they can use a custom script or even a feature of a hacking toolkit they bought on the Dark Web. Whatever the attacker’s approach, the symptoms on the network are mostly the same: one host generating an abnormally large number of connection attempts (but typically no full connections) to a multitude of endpoints. Scan sweeps may use Transport Control Protocol (TCP), User Datagram Protocol (UDP), Internet Control Message Protocol (ICMP), or Address Resolution Protocol (ARP), depending upon how reliable the attacker wants the results to be and how undetectable they want to be, since some scan types are more reliable than others and some are nosier than others.
A good way to detect scan sweeps is by paying attention to ARP messages. ARP is the means by which interfaces determine the address of the next hop toward the ultimate destination of a packet. An ARP request is simply a node broadcasting to every other node in its LAN the question, “Who is responsible for traffic to this IP address?” If the IP address belongs to another host on the same LAN, that host responds by providing its own MAC or physical address. At that point, the source host will send an IP packet encapsulated in a point-to-point Ethernet frame to the interface address from the responder. If, on the other hand, the IP address belongs to a different LAN, the default gateway (that is, IP router) will respond by saying it is responsible for it.
When an attacker attempts a scan sweep of a network, the scanner will generate a large number of ARP queries, as shown on Figure 17-2. In this example, most of the requests will go unanswered, because there are only a handful of hosts on the network segment, though the subnet mask is for 255 addresses. This behavior is almost always indicative of a scan sweep, and, unless it is being done by an authorized security staff member, it should be investigated. The catch, of course, is to ensure that you have a sensor in every subnet that is monitoring ARP messages.

Figure 17-2 ARP queries associated with a scan sweep
Common Protocol over a Nonstandard Port
Assigned by the Internet Assigned Numbers Authority (IANA), network ports are communication endpoints that are used to serve specific services. Computers read ports as a 16-bit integer, resulting in a range from 0 to 65535. Although such a range of port options presents many possibilities for communications, only a handful of these ports are commonly used, which are referred to as standard ports. Standard web traffic, for example, uses port 80 for HTTP and 443 for HTTPS, while the Simple Mail Transfer Protocol (SMTP) uses port 25.
There are a few reasons why we may encounter a common protocol over a nonstandard port. Firewalls make many of their decisions based primarily on which ports network traffic is attempting to operate on. Blocking unwanted traffic by targeting the port it usually operates on might be a way to reduce the possibility of malicious or unauthorized traffic. One common example of this practice is the transmission of web traffic over port 8080 instead of the standard port 80. Port 8080 is considered a nonstandard port, because it is used for a purpose other than its default assignment. In some cases, 8080 is indicative of the use of a web proxy. In other cases, developers use port 8080 on personally hosted web servers.
Attackers also know that certain ports are allowed across many networks to ensure that critical services can operate. Domain Name System (DNS), for example, is a foundational protocol that uses port 53 to communicate resolution information via UDP and TCP. As a result, port 53 is almost always allowed on a network. On the TCP side, 443 is used for HTTPS communications and, assuming that it’s encrypted, traffic running over 443 will not be inspected at many organizations. In both cases, attackers rely on the assumed lack of visibility on traffic running over these ports to send any received malware C2 information or even perform wholesale data exfiltration. This is an effective way to hide malicious traffic over standard ports.
Host-Related Indicators
After noticing unusual network behaviors such as those we discussed in the previous sections (or after getting an alert from an intrusion detection/protection system or other sensor), your next step is to look at the suspicious host to see if there is a benign explanation for the anomalous behavior. It is important that you follow the evidence and not jump to conclusions, because it is often difficult to get a clear picture of an intrusion simply by examining network traffic or behaviors.
Capacity Consumption
We have already seen how the various indicators of threat activity can consume network resources. In many cases, attacker behavior will also create spikes in capacity consumption on the host, whether it is memory, CPU cycles, disk space, or local bandwidth. Part of your job as an analyst is to think proactively about where and when these spikes would occur based on your own risk assessment or threat model, and then provide the capability to monitor resources so that you can detect the spikes. Many tools can assist with establishing your network and system baselines over time. The CySA+ exam will not test you on the proactive aspect of this process, but you will be expected to know how to identify these anomalies in a scenario. You are likely to be presented an image like Figure 17-3 and will be asked questions about the resources being consumed and what they may be indicative of. The figure, by the way, is of a Windows 10 system that is mostly idle and not compromised.

Figure 17-3 Windows 10 Resource Monitor
When faced with unexplained capacity consumption, you should refer to the steps we described for analyzing processes, memory, network connections, and file systems. The unusual utilization will be a signal, but your response depends on which specific resource is being used. The following are a few examples of warning signs related to abnormal consumption of various types of system resources.
Memory:
• Consistently low available memory despite low system usage
• Periods of high memory consumption despite no active user interaction or scheduled tasks
Drive Capacity:
• Sudden drop in available free space during a period of increased network activity
Processor:
• Prolonged periods of high processor consumption
• Unusually high processor consumption from unfamiliar tasks
Network:
• Periods of extremely high network throughput despite no active user interaction or scheduled tasks
NOTE Some malware, such as a rootkit, will alter its behavior or the system itself so as not to show signs of its existence in utilities such as Resource Monitor and Task Manager.
Unauthorized Software
The most blatant artifact since the beginning of digital forensics is the illicit binary executable file. Once an adversary saves malware to disk, it is pretty clear that the system has been compromised. There are at least two reasons why threat actors still rely widely on this technique (as opposed to the newer memory-only or fileless malware): convenience and effectiveness. The truth is that it is oftentimes possible to move the file into its target unimpeded, because many defensive systems rely on signature detection approaches that can easily be thwarted through code obfuscation. Even behavioral detection systems (those that look at what the code does) are constantly playing catch-up to new evasion techniques developed by the attackers.
Having bypassed the antimalware systems (if any) on the target, this software will continue to do its work until you find it and stop it. This task is made orders of magnitude easier if you have a list of authorized programs that each computer is allowed to run. Depending on your organization’s policy over what software can be executed, the mere presence of some kinds of software may be an indicator that a security control was circumvented.
Whitelisting
As we covered in Chapter 12, software whitelisting is the process of ensuring that only known-good software is allowed to execute on a system. The much more common alternative is software blacklisting, when we prevent known-bad (or suspected-bad) software from running. Whitelisting is very effective at reducing the attack surface for organizations that implement it. However, it is also deeply unpopular with the rank-and-file user, because any new application needs to be approved through the IT and security departments, which delays the acquisition process. Even if you don’t (or can’t) implement software whitelisting, you absolutely should have an accurate list of the software that is installed in every computer. This software asset inventory is important not only to detect unauthorized (and potentially harmful) software more easily, but also for license auditability and upgrade-planning purposes. Together with a hardware inventory, these two are the most essential steps for ensuring the security of your networks.
Malicious Processes
Someone once said, “Malware can hide, but it has to run.” When you’re responding to an incident, one of your very first tasks should be to examine the running processes. Every operating system provides a tool to do this, but you must be wary of trusting these tools too much, because the attacker may be using a rootkit that would hide his activities from these tools. Still, most incidents do not involve such sophisticated concealment, so running top or ps in Linux or looking at the Processes tab of the Windows Task Manager (and showing processes from all users) can be very helpful.

EXAM TIP For many of us, we first look at the processes running on a system before we decide whether to capture its volatile memory. In the exam, it is always preferable to capture memory first and then look at running processes. We reverse the order here for pedagogical reasons.
On a typical system, the list of running processes will likely number a few dozen or so. Many of these will have names like svchost.exe and lsass.exe for Windows or kthreadd and watchdog for Linux. Unless you know what is normal, you will struggle to find suspicious processes. A solution to this challenge is to baseline the hosts in your environment and make note of the processes you normally see in a healthy system. This will enable you to rapidly filter out the (probably) good and focus on what’s left. As you do this, keep in mind that attackers will commonly use names that are similar to those of benign processes, particularly if you’re quickly scanning a list. Common examples include adding an s at the end of svchost.exe, or replacing the first letter of lsass.exe with a numeral 1. Obviously, any such change should automatically be investigated.
Another way in which processes can reveal their nefarious nature is by the resources they utilize, such as network sockets, CPU cycles, and memory. It is exceptionally rare for malware not to have a network socket of some sort at some point. Some of the less-sophisticated ones will even leave these connections up for very long periods of time. So if you have a process with a name you’ve never seen before and it is connected to an external host, you may want to dig a bit deeper. An easy way to see which sockets belong to which processes is to use the netstat command. Unfortunately, each operating system implements this tool in a subtly different way, so you need to use the right parameters, as shown here:
• Windows: netstat -ano
• macOS: netstat -v
• Linux: netstat -nap
Another resource of interest is the processor. If a malicious process is particularly busy (for example, cracking passwords or encrypting data for exfiltration), it will be using a substantial amount of CPU cycles, which will show up on the Windows Task Manager or, if you’re using Linux, with the top or ps utilities. In the Linux environment, top is particularly useful because it is interactive, enabling a user to view, sort, and act on processes from the same pane without the need for piping or additional utilities. Figure 17-4 shows the output of the utility. By default, the visible columns are process ID, process owner, details about memory and processor consumption, and running time for the processes. Using various keyboard commands, you can sort the columns to identify abnormal processes more easily.

Figure 17-4 Output from the top task manager utility in Ubuntu Linux
Memory Contents
Everything you can discern about a computer through the techniques discussed in the previous section can also be used on a copy of its volatile memory. The difference, of course, is that a volatile memory analysis tool will not lie, even if the attacker used a rootkit on the original system. The reason why you probably won’t go around doing full memory captures of every computer involved in an incident response is that it takes time to capture them and even longer to analyze them.
NOTE There are tools used by threat actors that reside only in memory and that have no components stored on the file system. These sophisticated tools all but require incident responders to rely on memory forensics to understand them.
You will need a special tool to dump the contents of memory to disk, and you probably don’t want that dump to go to the suspected computer’s hard drive. Your best bet is to have a removable hard drive at the ready. Ensure that the device has enough capacity for the largest amount of memory on any system you could be called to investigate, and be sure to wipe its contents before you use it. Finally, install on it one of the many free applications available for memory capture. Among our favorites are AccessData’s FTK Imager (which can also acquire file systems) for Windows systems and Hal Pomeranz’s Linux Memory Grabber for those operating systems.
Once you have a memory image, you will need to use an analysis suite to understand it, because the layout and contents of memory are large, complex, and variable. They follow predictable patterns, but these are complicated enough to render manual analysis futile. Among the most popular tools for memory forensics is the open source Volatility Framework, which can analyze Windows, Linux, and macOS memory images and runs on any of those three platforms. Having taken an image of the memory from the suspected computer, you will be able to open it in Volatility and perform the same tasks we described in the previous section (albeit in a more trustworthy manner), plus you can conduct a myriad of new analyses that are beyond the scope of this book.
EXAM TIP You do not need to understand how to perform memory forensics for the exam; you only need to know why memory dumps are valuable to incident response.
Unauthorized Changes
A common technique for an attacker to maintain access to compromised systems is to replace system libraries, such as dynamic-link libraries (DLLs) in Windows systems, with malicious ones. These stand-ins provide all the functionality of the originals, but they also add whatever the attacker needs. Replacing these files requires elevated privileges, but an adversary can accomplish this in a variety of ways. Once the switch is made, it becomes difficult to detect unless you’ve taken some preparatory actions.
In Windows systems, some built-in features are helpful in detecting unauthorized changes to files or sensitive parts of the system, such as the registry. One of these is automatic logging of access or changes to files in sensitive folders. This feature, called object access auditing, can be applied globally or selectively as a group policy. The explanation of the full range of options is shown in Figure 17-5. Once the feature is in place, Windows will generate an event whenever anyone reads, modifies, creates, or deletes a file in the audited space. For example, modifying an audited file would generate an event with code 5136 (a directory service object was modified) and record the user responsible for the change as well as the time and what the change was. Linux has an equivalent audit system that provides similar features. Obviously, you want to be selective about using this, because you could generate thousands if not millions of alerts if you are too gratuitous about it.
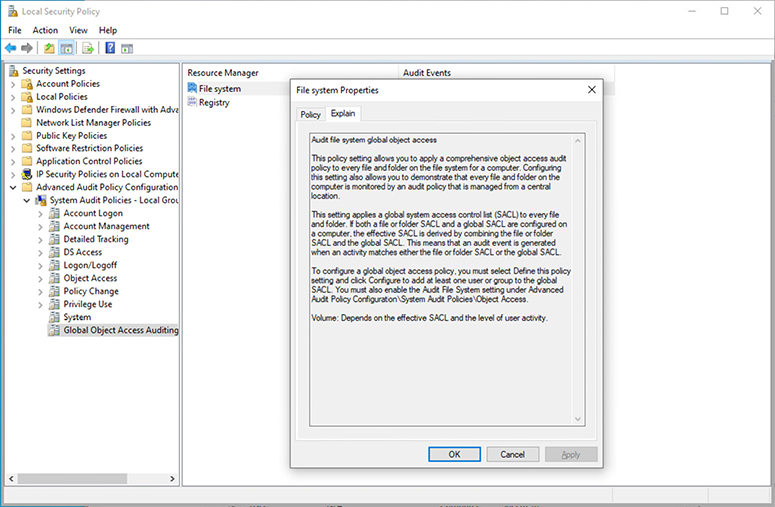
Figure 17-5 Windows 10 local security policy audit options for the file system
Another way to detect changes to important files is to hash them and store the resulting values in a safe location. This would be useful only for files that are never supposed to change in any way at all, so you would have to be selective. Still, for most if not all of your libraries and key programs, this approach works well. You would still have to check the hashes manually over time to ensure they haven’t changed, but this is a simple process to script and schedule on any system. If you need a more comprehensive solution to file integrity monitoring, commercial organizations such as Tripwire offer solutions in this space.
File System
A file system is the set of processes and data structures that an operating system uses to manage data in persistent storage devices such as hard disk drives. These systems have traditionally been (and continue to be) the focal point of incident responses because of the richness of the relevant artifacts that can be found in them. It is extremely difficult for adversaries to compromise a computer and not leave evidence of their actions on the file system.
NOTE The word artifact is frequently used in forensics, and, though there is no standard definition for it in this context, it generally denotes a digital object of interest to a forensic investigation.
Unauthorized Privileges
Regardless of the type or purpose of the attack, the adversaries will almost certainly attempt to gain elevated privileges. Sometimes, the exploit itself will provide access to a privileged account such as system (in Windows) or root (in Linux). Some remote execution vulnerabilities, when exploited, place the adversary in a privileged context. More commonly, however, the attacker will have to take some action to get to that status. These actions can be detected and often leave artifacts as evidence.
Privilege escalation is the process by which a user who has limited access to a system elevates that access in order to acquire unauthorized privileges. Note that this could easily apply to an authorized user of the system gaining unauthorized privileges, just as much as it applies to a remote attacker. The means by which this escalation occurs are very system dependent, but they tend to fall into three categories: acquiring privileged credentials, exploiting software flaws, and exploiting misconfigurations. The credentials can be obtained by social engineering or password guessing, but gaining access in this way would be anomalous in that a user would be connecting from or to computers that are not typical for that person. Detecting the exploitation of software flaws requires an awareness of the flaws and monitoring systems that are vulnerable until they can be patched. Obviously, this would not normally be detectable in the event of a zero-day exploit.
Once elevated privileges are detected, your response depends on the situation. The simplest approach is to disable the suspected account globally and place any hosts that have an active session for that user into an isolated VLAN until you can respond. The risk there, however, is that if the account user is legitimate, you may have interfered with a teammate performing an important function for the company, which could have financial impacts. A more nuanced approach would be to monitor all the activities on the account to determine whether they are malicious or benign. This approach can reduce the risk of a false positive, but it risks allowing an attacker to remain active on the system and potentially cause more harm. Absent any other information, you should prioritize the protection of your information assets and contain the suspicious user and systems.
Data Exfiltration
Apart from writing malware to your file systems and modifying files in them for malicious purposes, adversaries will also want to steal data as part of certain attacks. The data that would be valuable to others is usually predictable by the defenders. If you worked in advanced research and development (R&D), your project files would probably be interesting to uninvited guests. Similarly, if you worked in banking, your financial files would be lucrative targets. The point is that we can and should identify the sensitivity of our data before an incident so that we can design controls to mitigate risks to them.
A common approach to exfiltrating data is to consolidate it first in a staging location within the target network. Adversaries don’t want to duplicate efforts or exfiltration streams because such duplication would also make them easier to detect. Instead, they will typically coordinate activities within a compromised network. This means that even if multiple agents are searching for sensitive files in different subnets, they will tend to copy those files at the coordination hub at which they are staged, prepared, and relayed to an external repository. Unfortunately, these internal flows will usually be difficult to detect because they may resemble legitimate functions of the organization. (A notable exception is described in the section “Irregular Peer-to-Peer Communication” earlier in this chapter.)
Detecting the flow from the staging base outward can be easier if the amount of data is large or if the adversaries are not taking their time. The exfiltration will attempt to mimic an acceptable transfer such as a web or e-mail connection, which will typically be encrypted. The important aspect of this to remember is that the connection will look legitimate, but its volume and endpoint will not. Even if a user is in the habit of uploading large files to a remote server for legitimate reasons, the pattern will be broken unless the attackers also compromise that habitually used server and use it as a relay. This case would be exceptionally rare unless you were facing a determined nation-state actor. What you should do, then, is to set automated alarms that trigger on large transfers, particularly if they are directed to an unusual destination. NetFlow analysis is helpful in this regard.
For a more robust solution, some commercial entities sell data loss prevention (DLP) solutions, which rely on tamper-resistant labels on files and networks that track them as they are moved within and out of the network. DLP requires data inventories and a data classification system in addition to technical controls. DLP is not explicitly covered in the CySA+ exam, but if data exfiltration is a concern for you or your organization, you should research solutions in this space.
Registry Change or Anomaly
Registry changes can stand out as obvious indicators because they can lead to significant changes in a system’s behavior. The Windows registry is a local database where the system stores all kinds of configuration information. Malware authors want to maintain persistence, or survival of a system restart, whenever possible, and making changes the registry is a common way to achieve lasting presence on a system with minimal effort. Following are a few examples of commonly modified registry keys that attackers use to maintain persistence on Windows machines.
Automatic startup of services or programs:
• HKEY_LOCAL_MACHINESoftwareMicrosoftWindowsCurrentVersionRun
• HKEY_LOCAL_MACHINESoftwareMicrosoftWindowsCurrentVersionRunOnce
• HKEY_LOCAL_MACHINESoftwareMicrosoftWindowsCurrentVersionRunServicesOnce
• HKEY_LOCAL_MACHINESoftwareMicrosoftWindowsCurrentVersionRunServices
• HKEY_LOCAL_MACHINESoftwareMicrosoftWindowsCurrentVersionPoliciesExplorerRun
Setting startup folders:
• HKEY_LOCAL_MACHINESoftwareMicrosoftWindowsCurrentVersionExplorerShell Folders
• HKEY_LOCAL_MACHINESoftware
• MicrosoftWindowsCurrentVersionExplorerUser Shell Folders
Unauthorized Scheduled Task
A common way for malware to maintain persistence is to employ the user’s own operating system’s scheduling functionality to run programs or scripts periodically. While this feature is very useful for legitimate power users, it’s been used successfully by malware authors for years to maintain persistence and spread viruses. As far as tools, the Windows Task Scheduler is the go-to for those operating the Microsoft OS. The scheduling application is fairly straightforward to operate and provides an overview of the functionality and rundown of the current scheduled tasks for that machine, as shown in Figure 17-6.
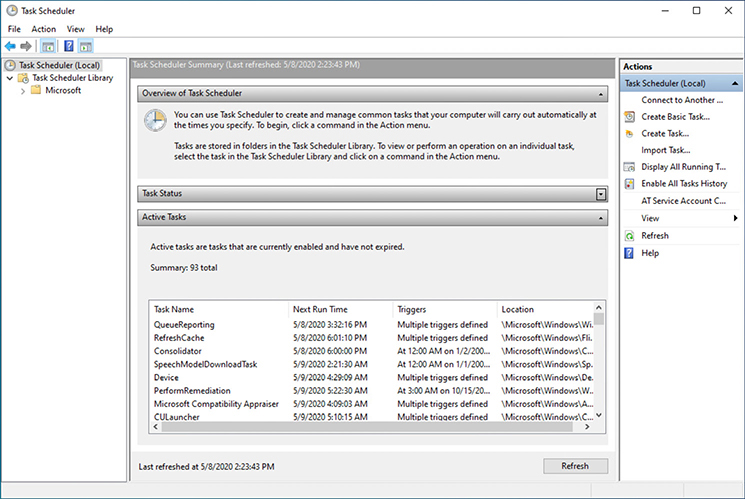
Figure 17-6 Windows 10 Task Scheduler
For Linux, options such as cron, anacron, and the at command have been used for decades to give users fine-grained control over when certain commands would be executed. The cron program can be invoked using the crontab –e command to view and edit what commands or shell scripts are queued up for execution. Entries can be made directly to the crontab (cron table) from this point using your preferred text editor. Figure 17-7 shows the overview and basic syntax of entries to the table.

Figure 17-7 The cron table in Ubuntu Linux
In the macOS environment, persistence mechanisms use native features such as LaunchAgent, LaunchDaemon, cron, Login Items, and kernel extensions (or kexts). Contents of the System/Library/LaunchDaemons/ directory are shown in Figure 17-8. The entries are stored as a plist, or property list.

Figure 17-8 Contents of the System/Library/LaunchDaemons/ directory containing system daemons
Application-Related Indicators
Though most of your work will take place at the network and host levels, you may find it sometimes necessary to examine application symptoms as part of an incident response. By “application,” we mean user-level as opposed to system-level features or services. In other words, we are referring to software such as Microsoft Office and not web or e-mail services.
Anomalous Activity
Perhaps the most common symptom of possible infections is unusual behavior in the infected application. Web browsers have long been a focus of attackers not only because of their pervasiveness, but also their complexity. To provide the plethora of features that we have grown accustomed to, browsers are huge, complicated, and often vulnerable applications. Our increasing reliance on plug-ins and the ability to upload as well as download rich content only complicates matters. It is little wonder that these popular applications are some of the most commonly exploited. The first sign of trouble is usually anomalous behavior such as frozen pages, rapidly changing uniform resource locators (URLs) in the address bar, or the need to restart the browser. Because web browsers are common entry points for attacks, these symptoms are likely indicative of the early stages of a compromise.
Other commonly leveraged applications are e-mail clients. Two popular tactics used by adversaries are to send e-mail messages with links to malicious sites and to send infected attachments. The first case was covered in the preceding paragraph, because it is the web browser that would connect to the malicious web resource. In the second case, the application associated with the attachment will be the likely target for the exploit. For example, if the infected file is a Microsoft Word document, it will be Word that is potentially exploited. The e-mail client, as in the link case, will simply be a conduit. Typical anomalous behaviors in the targeted application include unresponsiveness (or taking a particularly long time to load), windows that flash on the screen for a fraction of a second, and pop-up windows that ask the user to confirm a given action (for example, allowing macros in an Office document).
A challenge with diagnosing anomalous behaviors in user applications is that they often mimic benign software flaws. We have all experienced applications that take way too long to load even though there is no ongoing attack. Still, the best approach may be to move the host immediately to an isolated VLAN and start observing it for outbound connection attempts until the incident response team can further assess it.
Introduction of New Accounts
Regardless of the method of infection, the attacker will almost always attempt to elevate the privileges of the exploited account or create a new one altogether. We already addressed the first case, so let’s now consider what the second might look like. The new account created by the attackers will ideally be a privileged domain account. This is not always possible in the early stages of an attack, so it is not uncommon to see new local administrator accounts or regular domain accounts being added. The attacker’s purpose is twofold: to install and run tools required to establish persistence on the local host, and to provide an alternate and more normal-looking persistence mechanism in a domain account. In either case, you may want to reset the password on the account and immediately log off the user (if a session is ongoing). Next, monitor the account for attempted logins to ascertain the source of the attempts. Unless the account is local, it is not advisable simply to isolate the host, because the attacker could then attempt a connection to almost any other computer.
Unexpected Output
Among the most common application outputs that are indicative of a compromise are pop-up messages of various kinds. Unexpected User Account Control (UAC) pop-ups in Windows, like the one shown in Figure 17-9, are almost certainly malicious if the user is engaged in routine activities and not installing new software. Similarly, when the user is not taking any actions, certificate warnings and navigation confirmation dialogs are inherently suspicious.

Figure 17-9 User Account Control pop-up for unsigned software
Unexpected Outbound Communication
Perhaps the most telling and common application behavior that indicates a compromise is the unexpected outbound connection. We already spoke about why this is so common in attacks during our discussion of network symptoms. It bears repeating that it is exceptionally rare for a compromise not to involve an outbound connection attempt by the infected host. The challenge in detecting these is that it is normally not possible for a network sensor to tell whether that outbound connection to port 443 was initiated by Internet Explorer or by Notepad. The first case may be benign, but the latter is definitely suspicious. Because most malicious connections will attempt to masquerade as legitimate web or e-mail traffic, you will almost certainly need a host-based sensor or intrusion detection system (IDS) to pick up this kind of behavior. Assuming you have this capability, the best response may be to automatically block any connection attempt from an application that has not been whitelisted for network connections.
Another challenge is that an increasing number of applications are relying on network connectivity, oftentimes over ports 80 or 443, for a variety of purposes. It is also likely that an application that did not previously communicate like this may start doing so as the result of a software update.
EXAM TIP The fact that an application suddenly starts making unusual outbound connections, absent any other evidence, is not necessarily malicious. During exam simulations, for example, look for indicators of new (authorized) installations or software updates to assess benign behavior.
Service Interruption
Services that start, stop, restart, or crash are always worthy of further investigation. For example, if a user notices that the antimalware icon in the status bar suddenly disappears, this could indicate that an attacker disabled this protection. Similarly, error messages stating that a legitimate application cannot connect to a remote resource may be the result of resource allocation issues induced by malicious software on the host. An examination of the resource manager and log files will help you determine whether or not these symptoms are indicative of malicious activities.
Memory Overflows
Another resource that is often disrupted by exploits or malware is main memory. This is because memory is an extremely complex environment, and malicious activities are prone to disrupt the delicate arrangement of elements in that space. If an attacker is off by even a byte when writing to memory, it could cause memory errors that terminate processes and display some sort of message indicating this condition to the user. This type of symptom is particularly likely if the exploit is based on stack or buffer overflow vulnerabilities. Fortunately, these messages sometimes indicate that the attack failed. Your best bet is to play it safe and take a memory dump so you can analyze the root cause of the problem.
Application Logs
Operating system application logs are a rich source of details about an application’s performance. They are a useful data source for detection efforts if they’re continuously piped to security information and event management (SIEM) software or a key part of an auditing program in the case of business-critical applications. Application logs are also very important for response efforts, since details of application records can give insight into how an event may have unfolded.
Parsing logs can be quite a challenge and will require some consideration to do it correctly. First is the issue of log volume. Software developers will provide the types of activity they want to record logs from and provide that to the system to be viewed using tools such as the Event Viewer. However, some developers want to record everything that’s happening with an application, and for a security team, this could mean more noise than signal. As the logs grow larger, it becomes far more difficult to identify relevant events. The second issue is that logs don’t provide actionable output by themselves. Events are provided in standard formats that reflect only what happened, and they never offer intent or an explanation of why it may have occurred. It would be misguided simply to attribute every failed login attempt to malicious activity. An analyst, therefore, must understand the particular role a log plays in telling the story of what may have occurred.
Chapter Review
Like bloodhounds in a hunt, incident responders must follow the strongest scents to track their prey. The analogy is particularly apt, because you too will sometimes lose the scent and have to wander a bit before reacquiring it. Starting from the network level and working your way to the host and then individual applications, you must be prepared for ambiguous indicators, flimsy evidence, and occasional dead ends. The most important consideration in both the real world and the CySA+ exam is to look at the aggregated evidence before reaching any conclusions. As you go through this investigative process, keep in mind Occam’s razor: the simplest explanation is usually the correct one.
Questions
1. The practice of permitting only known-benign software to run is referred to as what?
A. Blacklisting
B. Whitelisting
C. Blackhatting
D. Vulnerability scanning
2. Which of the following is not considered part of the lateral movement process?
A. Internal reconnaissance
B. Privilege escalation
C. Exfiltration
D. Pivoting attacks
3. What is a common technique that attackers use to establish persistence in a network?
A. Buffer overflows
B. Adding new user accounts
C. Deleting all administrator accounts
D. Registry editing
4. Which one of the following storage devices is considered to be the most volatile?
A. Random-access memory
B. Read-only memory
C. Cloud storage
D. Solid-state drive
5. Which of the following is not an area to investigate when looking for indicators of threat activity?
A. Network speed
B. Memory usage
C. CPU cycles
D. Disk space
6. What is a useful method to curb the use of rogue devices on a network?
A. SSID
B. FLAC
C. WPA
D. NAC
Use the following scenario to answer Questions 7–10:
You receive a call from the head of the R&D division because one of her engineers recently discovered images and promotional information of a product that looks remarkably like one that your company has been working on for months. As she read more about the device, it became clear to the R&D head that this is, in fact, the same product that was supposed to have been kept under wraps in-house. She suspects that the product plans have been stolen. When inspecting the traffic from the R&D workstations, you notice a few patterns in the outbound traffic. The machines all regularly contact a domain registered to a design software company, exchanging a few bytes of information at a time. However, all of the R&D machines communicate regularly to a print server on the same LAN belonging to Logistics, sending several hundred megabytes in regular intervals.
7. What is the most likely explanation for the outbound communications from all the R&D workstations to the design company?
A. Command and control instructions
B. Exfiltration of large design files
C. License verification
D. Streaming video
8. What device does it make sense to check next to discover the source of the leak?
A. The DNS server
B. The printer server belonging to Logistics
C. The mail server
D. The local backup of the R&D systems
9. Why is this device an ideal choice as a source of the leak?
A. This device may not arouse suspicion because of its normal purpose on the network.
B. This device has regular communications outside of the corporate network.
C. This device can emulate many systems easily.
D. This device normally has massive storage resources.
10. What is the term for the periodic communications observed by the R&D workstations?
A. Fingerprinting
B. Chatter
C. Footprinting
D. Beaconing
Answers
1. B. Whitelisting is the process of ensuring that only known-good software can execute on a system. Rather than preventing known-bad software from running, this technique enables only approved software to run in the first place.
2. C. Lateral movement is the process by which attackers compromise additional hosts within a network after having established a foothold in one. This is often achieved by leveraging the trust between hosts to conduct internal reconnaissance, privilege escalation, and pivoting attacks. These actions may all be used to facilitate an attacker’s end goal, such as data exfiltration, or the removal of sensitive information from the victim network.
3. B. A clever way that attackers use for permanence is to add administrative accounts or groups and then work from those new accounts to conduct additional attacks.
4. A. Random-access memory (RAM) is the most volatile type of storage listed. RAM requires power to keep its data, and once power is removed, it loses its content very quickly.
5. A. Spikes in memory CPU cycles, disk space, or network usage (not necessarily network speed) may be indicative of threat activity. It’s important that you understand what the normal levels of usage are so that you can more easily identify abnormal activity.
6. D. Network access control (NAC) is a method to ensure that each device is authenticated, scanned, and joined to the correct network. NAC solutions often give you fine-grained controls for policy enforcement.
7. C. Some types of software, particularly those for high-end design, will periodically check licensing using the network connection.
8. B. A common approach to removing data from the network without being detected is first to consolidate it in a staging location within the target network. As you note the size of the transfers to the print server, it makes sense for you to check to see if it is serving as a staging location and communicating out of the network.
9. A. This device is a good choice because an administrator would not normally think to check it. However, because a print server normally has no reason to reach outside of the network, it should alert you to investigate further.
10. D. Beaconing is a periodic outbound connection between a compromised computer and an external controller. This beaconing behavior can be detected by its two common characteristics: periodicity and destination. Beaconing is not always malicious, but it warrants further exploration.