
CHAPTER 14
Automation Concepts and Technologies
In this chapter you will learn:
• The role of automation technologies in modern security operations
• Best practices for employing orchestration technologies
• Best practices for building automation workflows and playbooks
• Tips for automating data enrichment at scale
No one can whistle a symphony. It takes an orchestra to play it.
—H. E. Luccock
Security processes can be tedious and repetitive. Whether you’re testing software functionality for vulnerabilities or responding to frequently occurring incidents, you’ll find a certain level of automation to be helpful, particularly for activities that do not require a great amount of analyst intervention. The goal is not to move the entire security process to full automation, but rather to create the conditions that enable the analyst to focus brainpower on complex activities. Vulnerability management analysts can automate repeated security testing cases, for example, and instead focus their energies on exploring the in-depth weaknesses in critical services and validating complex logic flaws. Even the best analysts make mistakes, and although they work their best to secure systems, they do introduce limitations and occasional inconsistencies that may lead to catastrophic results. As systems get more and more complex, the number of steps required to perform a remediation may scale accordingly, meaning that the sheer number of actions needed to secure a system correctly grows, as do the demands on an analyst’s attention.
To assist with this, there are several automation concepts that we’ll cover. Automation, in the context of security operations, refers to the application of technologies that leverage standards and protocols to perform specific, common security functions for a fixed period or indefinitely. One of the primary driving forces in high efficiency productions systems such as lean manufacturing and the famously effective Toyota Production System is the principle of jidoka. Loosely translated as “automation with a human touch,” jidoka enables machines to identify flaws in their own operations or enables operators in a manufacturing environment to quickly flag suspicious mechanical behaviors. This principle has allowed for operators to be freed from continuously controlling machines, leaving the machines free to operate autonomously until they reach an error condition, at which point a human has the opportunity to exercise judgement to diagnose and remediate the issue. Most importantly, at least for efficiency, is that jidoka frees the human worker to concentrate on other tasks while the machines run. We can apply jidoka concepts to security to take advantage of standardization, consistent processes, and automation to reduce the cognitive burden on an analyst. Using specifications on how to interface with various systems across the network, along with using automated alerting and report delivery mechanisms, we can see massive increases in efficiency while experiencing fewer mistakes and employee turnover as a result of burnout. Additionally, the use of specifications and standards means that troubleshooting becomes more effective, more accurate, and less costly, while allowing for easy auditing of systems.
Workflow Orchestration
Automation proves itself as a crucial tool for security teams to address threats in a timely manner, while also providing some relief for analysts in avoiding repetitive tasks. However, to be truly effective, automation is often confined to systems using the same protocol. Although many analysts, including the authors, find success using scripting languages such as Python to interact with various system interfaces, there are challenges with managing these interactions at scale and across homogenous environments. Keeping tabs with how actions are initiated and under what conditions, and what reporting should be provided, gets especially tricky as new systems and technologies are added to the picture. Orchestration is the step beyond automation that aims to provide an instrumentation and management layer for systems automation. Good security orchestration solutions not only connect various tools seamlessly, but they do so in a manner that enables the tools to talk to one another and provide feedback to the orchestration system without requiring major adjustments to the tools themselves. This is often achieved by making use of the tools’ application programming interfaces (APIs).
Security Orchestration, Automation, and Response Platforms
As teams begin to integrate and automate their suites of security tools, they invariably come up against the limitations of specialized scripting and in-house expertise. Getting disparate security systems to work nicely together to respond to suspicious activity is not a trivial task, so a market for security orchestration, automation, and response (SOAR) tools has emerged to meet this need. Described by IT research firm Gartner as “technologies that enable organizations to collect security threats data and alerts from different sources, where incident analysis and triage can be performed leveraging a combination of human and machine power to help define, prioritize and drive standardized incident response activities according to a standard workflow,” SOAR tools enable teams to automate frequent tasks within a particular technology as well as coordinate actions from different systems using repeatable workflows. Like SIEM platforms, SOAR solutions often include comprehensive dashboard and reporting capabilities; in many cases, they work alongside security information and event management (SIEM) solutions to help security teams maximize analyst productivity.
Recently acquired by Splunk and renamed Splunk Phantom, the orchestration platform formerly known as Phantom Cyber is one of the most comprehensive SOAR platforms in the industry. Coupled with a customizable dashboard functionality, the Phantom platform aims to address two of the major challenges facing security teams: back-end integration and front-end presentation. Offered in both commercial and community versions, Phantom provides out-of-the-box integration with hundreds of data sources, instances, and devices by way of apps. Figure 14-1 shows a snapshot of a few popular apps and the supported actions related to those technologies. It’s also possible to create custom app integrations with third-party services and APIs.

Figure 14-1 A portion of Splunk Phantom’s supported apps
As far as dashboard options, Phantom provides a multitude of metrics to help you gain a better understanding of both system and analyst performance, as shown in Figure 14-2. Analysts can get a sense of what kinds of events are in the pipeline, what playbooks are used most often, and the return on investment (ROI) associated with these events and actions. ROI, measured in both time and dollars saved, can be particularly powerful for a team in communicating the value of investment in orchestration platforms and training.

Figure 14-2 A portion of the Splunk Phantom dashboard
Orchestration Playbooks
Playbooks are workflows that help you visualize and execute processes across your security footprint in accordance with your orchestration rules. Also referred to as runbooks, these steps can be fully automated, or they can require human intervention at any point along the process. Much like a recipe, the playbooks prescribe the steps to be taken in a formulaic, often highly scalable, manner. In viewing their security process like an algorithm, security teams can eliminate much of the need for a manual intervention, save for the most critical decision points.
There are a few key components that all playbooks must have to be complete. The first is the initiating condition, or the rules that must be triggered to begin the steps within the rest of the playbook. Often, this is the presence of artifacts that meet whatever your organization defines as a security incident. Sometimes, the condition may be preventative in nature and be initiated on some schedule. This initial condition may set off a series of actions across many security devices, each of which would normally take a bit of human interaction. This step alone significantly reduces the investment in analyst resources, an investment that may not always lead to anything actionable.
Next are the process steps that the playbook will invoke by interacting with the various technologies across the organization. In many cases, security orchestration solutions have software libraries that enable the platform to interact seamlessly with technology. For some of the more popular orchestration solutions, these libraries are written in coordination with the service provider to ensure maximum compatibility. For the analyst, this means minimal configuration on the front end, while in other cases, libraries may need to be initially set up manually within the orchestration software.
Finally, an end state must be defined for the playbook. Whether this comes in the form of an action to remediate or an e-mailed report, ensuring that a well-defined outcome is reached is important for the long-term viability of the playbook. It may well be the case that the outcome for one playbook is the initiating activity for another. This is the concept of chaining, in which multiple playbook actions originate from a single initiating condition. This final stage of a playbook’s operation will often include some kind of reporting and auditing functionality. While these products may not be directly applicable to the remediation effort itself, they are incredibly valuable for improving overall orchestration performance as well as meeting any regulatory requirements that your organization may have.
Orchestration is not only a tremendous time-saver, but it also facilitates a diversity of actions, such as technical and nontechnical, to be included in an overall security strategy. For example, a process such as an e-mail phishing investigation will benefit from a number of orchestration-enabled tasks. Enriching e-mail addresses and suspicious links by pulling data from threat intelligence data sets, and then forwarding those domains to a blacklisting service should they have a negative verdict, are tasks well suited for automation. Furthermore, trend reports can be generated over time and sent automatically to a training and communications team for use in improving user training. These kinds of tasks replace what may normally be a few hours of cutting, pasting, and formatting. When these tasks are chained within an orchestration tool, an initial signal about a suspicious e-mail can begin several processes without the need of any manual intervention from the security team, as shown in Figure 14-3.
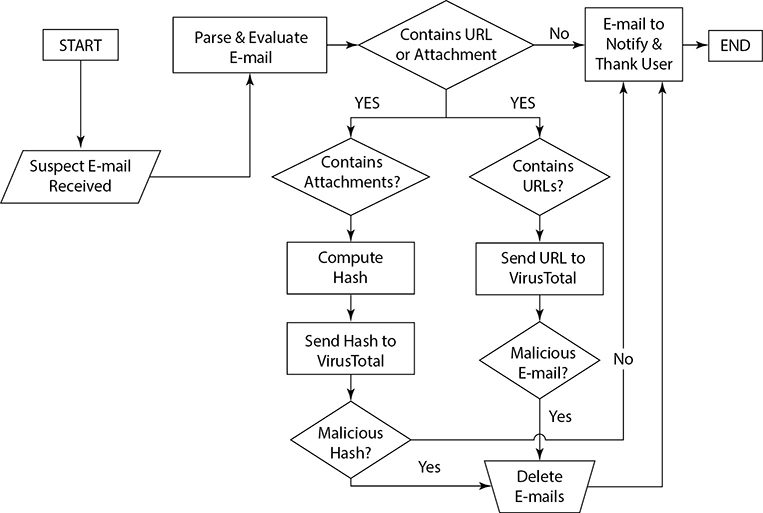
Figure 14-3 Example playbook for automated processing of suspected phishing e-mail
Many modern SOAR platforms include the ability to design playbooks both textually and visually. Using the previous phishing workflow, you can see an example of the visual breakout of a playbook related to phishing in Figure 14-4. Named phishing_investigate_and_respond, this playbook extracts various artifacts from suspected phishing messages and uses them as input in querying enrichment sources, or data sources, that can give additional context to the artifacts Any attachments, for example, are submitted to file reputation providers for a verdict, while URLs, domains, and IP addresses are passed to sources that can provide details on those aspects.
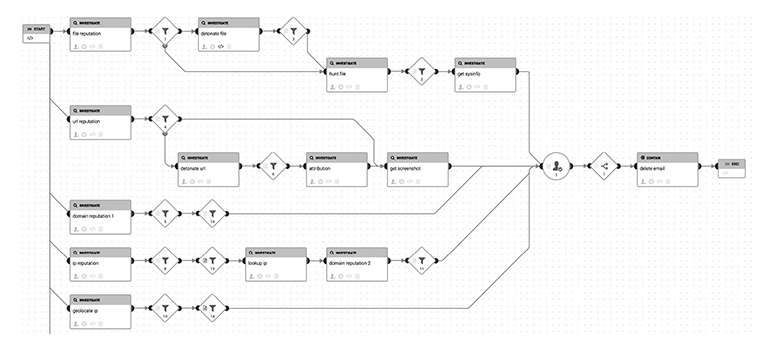
Figure 14-4 Splunk Phantom visual playbook editor
Depending on how the playbooks are configured, they may call upon one or more apps to interact with data sources or devices. Playbook design becomes crucially important as event volume increases to ensure that the processes remain resilient while not overly consuming outside resources, such as API calls.
In some situations, your organization may require that a human take action because of the potential for adverse impact in the case of a false positive. Imagine for a moment that your organization has a highly synchronized identity management system, and a number of playbooks are related to account takeover actions. If one of these is written to perform a fully automated account reset, to include session logouts, password and token resets, and two-factor authentication (2FA) reset, it could cause catastrophic effects if initiated on a low-quality signal, such as the presence of suspicious language in an e-mail. A full account reset, therefore, is an action for which a fully automated action may be the best; it makes sense to check and double-check that the action is warranted, however. Another action that may benefit from human interaction is blocking of domains. Depending on your organization’s network access policies, you may want to fully domain block or prompt an analyst for review. Domains, as you may recall, often have associated reputations. This reputation can change over time, or it may be the case that a domain has earned a malicious reputation as a result of a temporary loss of control but has since recovered. Considering these possibilities, it may be prudent to require analyst input into the blocking process, as shown in Figure 14-5. Phantom’s editor allows for prompts to team members for approval.

Figure 14-5 Splunk Phantom visual playbook editor showing a human prompt for action
Data Enrichment
A major part of any security analyst’s day is to track down and investigate suspicious activity. Investigation into the source and meaning behind observables is a core skill of any detection analyst, incident responder, threat hunter, or threat intelligence analyst. Enrichments are the actions that lead to additional insights into data, and they involve a set of tasks that can be a draw on resources. Often repetitive, enrichment is a perfect candidate for automation. Any way that we can make it easier for analysts to initiate an enrichment request means more time for them to focus on really challenging tasks. Depending on how automation is set up, enrichment may even occur as the initial is delivered, meaning that the analyst sees the original signal coupled with useful context to make a far more informed decision. This practice leads not only to far lower response times, but it also reduces the chance for human error, since there are fewer areas for a human to interact directly in the process.
Scripting
The command line has traditionally been the fastest way for analysts to interface directly with a platform’s core operations. Security team members and systems administrators have been building custom scripts to perform management tasks for as long as the command line interface (CLI) has been around. In its simplest form, this has come in the form of a cron job, a task that leverages the time-based scheduling utility cron in Linux/Unix environments. This tool enables users to run commands or scripts at specified intervals. As one of the most useful OS tools, cron is often used by systems administrators to perform maintenance-related tasks, but it can be employed by any knowledgeable user to schedule recurring tasks. The cron service runs in the background and constantly checks the contents of the cron table, or crontab, located at /etc/crontab, or in the /etc/cron.*/ directories for upcoming jobs. The crontab is a configuration file that lists the commands to be run, along with their schedule. Administrators can maintain a system-wide crontab or enable individual users to maintain their own individual crontab files using the following syntax:

Another common method of automating across the network is using the Secure Shell (SSH) protocol to issue commands via the CLI. It’s possible to initiate SSH connections with scripting to perform any number of actions, but this method is prone to inconsistency and error. Copying files is also possible, using a secure connection with the scp command. Short for secure copy, this command enables copying to and from remote servers using SSH connections. The following command is an example of how scp can be used to connect to a remote server and retrieve a file named log.txt from remote server server2.example.com using user1 credentials:
![]()
Python Scripting
Python has emerged as one of the most popular languages for security analysts in part because of its scripting potential. As a fast, multiplatform language, it has experienced rapid adoption and expansion with a vast collection of libraries, modules, and documentation specifically focused on computer security. It’s also a language that’s designed to be somewhat human-readable and to perform with the fewest lines of code possible. Getting into Python scripting is easy and well worth the investment for any security analyst. Let’s consider a simple case of trying to extract IP addresses from a large log file provided by a security device. The contents of this fictional log file are displayed here:


With a few lines and the commonly used regular expression library re, we can quickly create a Python script capable of identifying just the IP addresses. The simple script we’ve written is shown next. It takes a file input, identified here as suspicious_traffic.log, and uses the regular expression Python library to search quickly through the contents for strings that resemble the structure of an IP address:

Using this script, we can generate a list of just the IP addresses, as shown next. We can ship this list directly to another service, such as IP reputation, in an automated fashion, or add it to a blacklist.

PowerShell Scripting
PowerShell is an automation framework developed by Microsoft that includes both a command shell and support for advanced scripting. Normally used by systems administrators to maintain and configure systems, PowerShell can also be used by security teams to obtain a great deal of information from endpoints and servers that is useful for tasks such as incident response, detection, and vulnerability management.
Application Programming Interface Integration
APIs have ushered in several major improvements in how computers talk to each other at scale. APIs are becoming the primary mechanism for both standard user interactions and systems administration for a number of reasons. First, APIs simplify how systems integrate with each other, because they provide a standard language to communicate while maintaining strong security and control over the system owner’s data. APIs are also efficient, since providing API access often means that the content and the mechanism to distribute the content can be created once using accepted standards and formats and published to those with access. This means that the data is able to be accessed by a broader audience that just those with knowledge about the supporting technologies behind the data. Thus, APIs are often used to distribute data effectively to a variety of consumers without the need to provide special instructions and without negatively impacting the requestor’s workflow. Finally, APIs provide a way for machines to communicate at high volume in a scalable and repeatable fashion, which is ideal for automation.
As API usage has increased across the Web, two popular ways to exchange information emerged to dominate Internet-based machine-to-machine communications. The first is the Simple Object Access Protocol (SOAP). APIs designed with SOAP use Extensible Markup Language (XML) as the message format transmitting through HTTP or SMTP. The second is Representational State Transfer (REST). We’ll take a deeper look into REST here, because it is the style you’ll most likely interface with on a regular basis and it offers flexibility and a greater variety of data formats.
Representational State Transfer
Representational State Transfer is a term coined by computer scientist Dr. Roy Fielding, one of the principal authors of the HTTP specification. In his 2000 doctoral dissertation, Dr. Fielding described his designs of software architecture that provided interoperability between computers across networks. Web services that use the REST convention are referred to as RESTful APIs. Though many think of REST as a protocol, it is, in fact, an architectural style and thus has no rigid rules. REST interactions are characterized by six principles, however:
• Client/server The REST architecture style follows a model in which a client queries a server for particular resources, communicated over HTTP.
• Stateless No client information is stored on the server, and each client must contain all of the information necessary for the server to interpret the request.
• Cacheable In some cases, it may not be necessary for the client to query the server for a request that has already occurred. If marked as such, a client may store a server’s response for reuse later on.
• Uniform interface Simplicity is a guiding principle for the architectural style and is realized with several constraints:
• Identification of resources Requests identify resources (most often using URLs), which are separate from what is returned from the servers (represented as HTML, XML, or JSON)
• Manipulation of resources through representations A client should have enough information to modify a representation of a resource.
• Self-descriptive messages Responses should contain enough information about how to interpret them.
• Hypermedia as the engine of application state There is no need for the REST client to have special knowledge about how to interact with the server, because hypermedia, most often HTTP, is the means of information exchange.
• Layered system A client will not be able to tell if it’s connected directly to the end server, an intermediary along the way, proxies, or load balancers. This means that security can be strongly applied based on system restrictions and that the server may respond in whatever manner it deems most efficient.
• Code on demand (optional) REST enables client functionality to be extended by enabling servers to respond to applets or scripts that can be executed client-side.
RESTful APIs use a portion of the HTTP response message to provide feedback to a requestor about the results of the response. Status codes fall under one of the five categories listed here:

Furthermore, you may be able to recover more detailed error messages depending on what API service is being used. VirusTotal, for example, provides the following detailed breakout of error codes that can be used to troubleshoot problematic interactions:



TIP The CySA+ does not require you to have in-depth knowledge of HTTP response and error codes, but understanding how to use them in troubleshooting automation is important. Knowing where to adjust your code based on the HTTP responses is a critical skill for API automation.
Automating API Calls
Many tools can assist you with crafting an API call and then converting it to code for use in other systems or as a subordinate function in custom software and scripting. Postman, Insomnia, and Swagger Codegen are three popular API clients that can assist with generating API calls for automation. We’ll use the VirusTotal API and Insomnia to show some of the most common capabilities of these API clients. According to the VirusTotal documentation, the API endpoint associated with domain enrichment requires a GET HTTP method. In many cases, you can copy the commands provided via the API documentation or use the code that follows in your API client:

This curl request automatically gets parsed in the client. After the appropriate credentials are added via an API key, OAuth credentials, login/password pair, bearer token, or other means, the request is ready to send. Figure 14-6 shows a complete request sent to the VirusTotal domain enrichment endpoint. You’ll notice the HTTP 200 response, indicating that the exchange was successful.

Figure 14-6 Request sent to the VirusTotal domain enrichment API endpoint via API client
The full contents of the HTTP response are under the Preview tab in this client, as shown in Figure 14-7. In this case, 92 verdicts are returned for the domain google, with 83 being “harmless” and 9 being “undetected.”

Figure 14-7 Preview of the API response in the Insomnia API client
Once you’re satisfied with the exchange between client and server, you can export this request to many popular programming languages or scripting formats. Insomnia comes with built-in ability to generate client code in several languages, some with multiple library options. Figure 14-8 shows the client code for both Python using the requests library and the PowerShell Invoke–WebRequest cmdlet (pronounced “command-let”). This can be used as-is or added to existing code to extend functionality.

Figure 14-8 Two examples of API client code–generation features
Automated Malware Signature Creation
YARA, the popular tool used by defenders to identify and classify malware samples, provides a simple but powerful way to perform rule-based detection of malicious files. As we covered in Chapter 12, each YARA description, or rule, is constructed with two parts: the strings definition and the condition. The YARA structure makes it easy to define malware using well-understood Boolean expressions, particularly at scale. Dr. Florian Roth wrote a simple yet powerful YARA rule generation software called yarGen, which facilitates the creation of YARA rules for malware by searching for the strings found in malware files, while ignoring those that also appear in benign files. The utility ships with a database that helps you get started by simply calling the script and specifying the directory of interest. In this case, we’ve populated a directory with EICAR (European Institute for Computer Antivirus Research) test files, a set of files used to test antimalware software without your having to use the real thing. Working from the yarGen directory, we call the program with the command python yarGen.py -m <location of the EICAR directory>. The resulting operation is shown in Figure 14-9.

Figure 14-9 Usage of the yarGen YARA rule generation utility
After a few moments, yarGen generates a file called yargen_rules.yar, which contains YARA rules generated for any malicious filed found in that directory (see Figure 14-10). These generated rules contain meta, strings, and condition fields and can be directly imported by any software that can use YARA rules for immediate deployment.
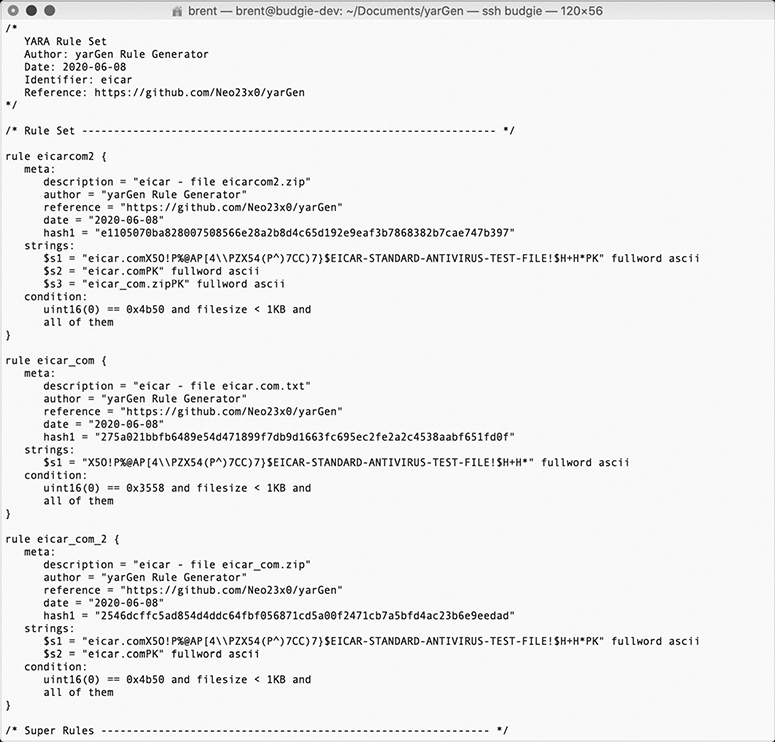
Figure 14-10 Contents of the yarGen-generated YARA rules
Outside of YARA rules, a notable open source project called BASS is designed to generate antivirus signatures automatically from existing samples. Maintained by Talos, Cisco’s threat intelligence and research group, BASS’s creation was developed as a way to generate more efficient pattern-based signatures. Given the sheer scale of sample volume the Talos research team sees—in excess of 1.5 million unique samples per day—they were in need of a way to avoid maintaining massive databases of hash-based signatures while keeping a low memory profile and remaining performant. The BASS solution, which is Python-based and implemented using a series of Docker containers, is a framework for generating pattern-based signatures, keeping all the benefits of hash-based solutions without requiring a massive increase in resources as it scales.
Threat Feed Combination
In Chapter 2, we covered various types of threat data that can be used to support incident response, vulnerability management, risk management, reverse engineering, and detection efforts. The sheer number of observables, indicators, and context continuously pulled from internal and external sources often requires an abstraction layer to normalize and manage so much data. Since it’s often not possible to affect the format in which feeds arrive, analysts spend a lot of time formatting and tuning feeds to make them most relevant to the operational environment. As you may recall, understanding what an indicator may mean to your network, given the right context, cannot always be automated, but a good deal of the processing and normalization that occurs before analysis can be handled by automation. This includes pulling in threat feeds via APIs and extracting unstructured threat data from public sources, and then parsing that raw data to uncover information relevant to your network. Getting the data stored in a manner that be easily referenced by security teams is not a trivial task, but with proper automation, it will take a great deal of strain off of analysts.
Putting new threat intelligence into operations can often be a manual and time-consuming process. These activities, which include searching for new indicators across various systems, are especially well-suited for automation. Once the threat data is analyzed, analysts can share threat intelligence products automatically to response teams and lead enforcement of new rules across the entire network. Improvements such as changes to firewall rules can many times be managed by the team’s SIEM and SOAR platforms.
Machine Learning
Machine learning (ML) is the field of computer science that, when applied to security operations, can uncover previously unseen patterns and assist in decision-making without being specially configured for it. A particularly exciting aspect of ML techniques is that they improve automatically through experience. As more data is provided to the model, the more accurately it will be able to detect patterns automatically. When applied to security, ML usually falls into one of a few major applications. First are algorithms to look at past network data to predict future activity. These techniques are currently being used to process high volumes of data and identify patterns to make predictions about most likely changes in network traffic and adversary behaviors. With mathematical techniques at its core, ML techniques are often effective at mining information to discover patterns and assigning information into categories.
Another area where ML techniques thrive is in malware and botnet detection. As security techniques move away from signature-based techniques to those driven by behavior pattern recognition, ML is an especially useful tool. Even as attackers use polymorphism to avoid detection, ML remains effective, as it looks for behavior that deviates from the intended operation of the software. Spotting unusual activity, whether it’s related to how a host is communicating, how data is being moved, or how a process is behaving, is something that fraud and detection teams are focused on improving on a daily basis.
Despite all of the promise, there is no silver bullet ML algorithm that is effective against every type of security challenge. Models that are developed for specific purposes routinely outperform general algorithms, but they are still not nearly as effective as the human decision-making process. With respect to automation, however, ML brings additional techniques to reduce the amount of noise that an analyst is initially faced with when embarking on the hunt for a potential security event.
Use of Automation Protocols and Standards
The use of automation to realize industry best practices and standards has been in practice for years in the commercial and government spaces. As an early developer of hardening standards, the Defense Information Systems Agency (DISA) has made significant investments in the promotion of these standards through products such as the Security Technical Implementation Guides (STIGs). STIGs, as we covered in Chapter 3, are meant to drive security strategies as well as prescribe technical measures for improving the security of networks and endpoints. Although STIGs describe how to minimize exposure and improve network resilience through proper configuration, patch management, and network design, they don’t necessarily define methods to ensure that this can be done automatically and at scale. This is where automation standards come into play.
Security Content Automation Protocol
We introduced the Security Content Automation Protocol (SCAP) in Chapter 3 as a framework that uses specific standards for the assessment and reporting of vulnerabilities of the technologies in an organization. The current technical specification of SCAP, version 1.3, is covered by NIST SP 800-126 Revision 3. SCAP 1.3 comprises twelve component specifications in five categories:
• Languages The collection of standard vocabularies and conventions for expressing security policy, technical check techniques, and assessment results
• Extensible Configuration Checklist Description Format (XCCDF)
• Open Vulnerability and Assessment Language (OVAL)
• Open Checklist Interactive Language (OCIL)
• Reporting formats The necessary constructs to express collected information in standardized formats
• Asset Reporting Format (ARF)
• Asset Identification (AID)
• Identification schemes The means to identify key concepts such as software products, vulnerabilities, and configuration items using standardized identifier formats, and to associate individual identifiers with additional data pertaining to the subject of the identifier
• Common Platform Enumeration (CPE)
• Software Identification (SWID) Tags
• Common Configuration Enumeration (CCE)
• Common Vulnerabilities and Exposures (CVE)
• Measurement and scoring systems Evaluation of specific characteristics of a security weakness and any scoring that reflects their relative severity
• Common Vulnerability Scoring System (CVSS)
• Common Configuration Scoring System (CCSS)
• Integrity An SCAP integrity specification that helps to preserve the integrity of SCAP content and results
• Trust Model for Security Automation Data (TMSAD)
OpenSCAP
A great public resource is the OpenSCAP project, a community-driven effort that provides a wide variety of hardening guides and configuration baselines. The policies are presented in a manner accessible by organizations of all types and sizes. Even better, the content provided is customizable to address the specific needs or your environment.
To demonstrate a vulnerability scan, we’ll use the oscap command-line tool provided by the OpenSCAP Base on a Red Hat 7 test system. The first step in evaluating a system is to download the definitions file, which will be used to scan the system for known vulnerabilities caused by missing patches. The Center for Internet Security (CIS) maintains an OVAL database (https://oval.cisecurity.org/repository) organized by platform. Alternatively, you can go directly to operating systems developers such as Red Hat and Canonical to retrieve the definitions file. For our demonstration, we’re using both the Extensible Configuration Checklist Description Format (XCCDF) definitions provided by Red Hat and begin the scan using the command that follows. We’ll specify the output to be a human-readable report using the --report option and a machine-readable report using the --results option. Both files will include details about what was tested, the test results, along with some recommendations for mitigation if applicable. Where available, Common Vulnerabilities and Exposures (CVE) identifiers are linked with the National Vulnerability Database (NVD) where additional information such as CVE description, Common Vulnerability Scoring System (CVSS) score, and CVSS vector are stored. Red Hat provides a complete overview of oscap usage on its site: https://access.redhat.com/documentation/en-us/red_hat_enterprise_linux/6/html/security_guide/sect-using_oscap.
![]()
The utility will take a few moments to run and will provide the requested output on screen as well as written to the XML and HTML files created using the --report option. Figure 14-11 shows the on-screen output, while Figure 14-12 shows the HTML report created.
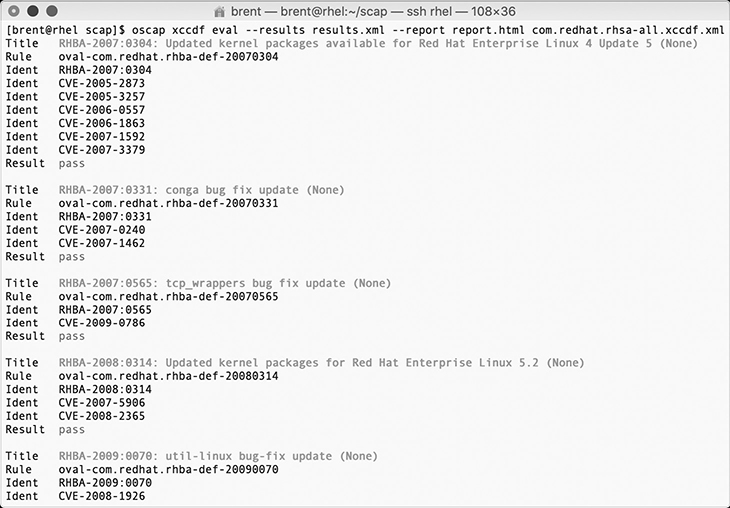
Figure 14-11 Execution and immediate output of the oscap utility run on a Red Hat 7 system

Figure 14-12 Excerpt of the HTML report summary after execution of the oscap utility
As part of the report, oscap provide details on the categories of rules along with their results. This test located three failures, as indicated in Figure 14-13. At minimum, oscap provides the name of the rule, a description of the vulnerability, and the severity.

Figure 14-13 Excerpt of the HTML report after execution of the oscap utility, highlighting the failed rules
Results from this test can be used to initiate a manual review of affected systems, or with the use of scripting or a SOAR platform, they can be queued for automated actions such as the quarantine of affected systems.
Software Engineering
Many of the techniques we’ve discussed so far, while incredibly effective, have a difficult time keeping pace with the rate of modern software engineering. With companies frequently looking to push changes to their internal and customer-facing solutions, there just isn’t time to test these new versions with the same completeness and rigor every time. The solution is to integrate security directly into the software development process, driven by smart automation technologies. Using DevOps or DevSecOps, various security tasks for software development such as static code analysis and fuzzing can be automated. Additionally, with the help of cloud technologies, consistent development environments can be guaranteed as they are provisioned on the fly. Security’s ideal place has always been as an integral part of the software development lifecycle, and not simply as an afterthought. This is the core principle of DevSecOps: it’s about built-in security that is important at the beginning of an app’s lifecycle and remains so throughout its deployment and up through its eventual deprecation.
Continuous Integration
Continuous integration is the practice of merging the various changes in code made by contributors back to the main branch, or effort, of a code base as early and often as possible. Changes can be quickly validated and pushed to production because versioning and management of merging is done smartly by platforms such as git. Along with the automated building and running of various quality tests against these builds, software security tests can be performed. Continuous integration ensures that the software remains at a high level of usability and security, thanks to automation, much of which is hidden from the developer as applications are checked and validated.
Continuous Delivery
Continuous delivery activities follow continuous integration and consist of tasks related to getting the software out of the development system and to the end user. This usually means testing so that the software is released in a timely manner after final validation occurs. Security can be automated in this stage as well, occurring alongside the release cycle that your software follows. In practice, this may mean that software is continuously tested for correctness and that findings are automatically included as input into the next development cycle.
Continuous Deployment
Continuous deployment follows continuous delivery and ensures that changes made previously in the cycle are incorporated and released to end users automatically, save for failed tests. Although continuous deployment is a great way to accelerate the feedback loop with your users, it doesn’t fit well with traditional software assessment techniques, since software can potentially be in front of end users just minutes after it is compiled. Security will serve as a very visible bottleneck only if it is not integrated seamlessly. Automated security activities that usually occur at deployment include runtime security and compliance checks, disabling of unnecessary services and ports, removal of development tools, enablement of security mechanisms, and enforcement of audit and logging policies.
Chapter Review
At its core, security operations and management are centered on securing systems by shoring up defenses throughout the entire lifecycle of the organization’s processes. As we’ve covered throughout the book, it takes a well-planned approach to identify and deploy technical, managerial, and operational steps that are repeatable and scalable to adjust with the organization’s evolution. Alongside the challenge of pivoting to accommodate ever-changing operational environments and threat models is the need to be able to reliably perform the same processes time and time again. Detection, for example, suffers tremendously if monitoring rules are not applied consistently and quickly enough to identify suspicious behavior confidently over time.
Questions
1. Which of the following is not an example of an identification scheme in SCAP 1.3?
A. Common Platform Enumeration (CPE)
B. Common Data Enumeration (CDE)
C. Software Identification (SWID) Tags
D. Common Vulnerabilities and Exposures (CVE)
2. What describes the first event of a playbook process that triggers the rest of the steps?
A. Reporting
B. Process steps
C. End-state
D. Initiating condition
3. In the REST architecture style, which of the following is not one of the commonly returned data types in server responses?
A. XML
B. SCAP
C. HTML
D. JSON
4. Which HTTP status code indicates some kind of client error?
A. 100
B. 202
C. 301
D. 403
5. Which of the following utilities, found in most versions of Linux, is useful for scheduling recurring tasks?
A. cron
B. whois
C. scp
D. oscap
6. Which of the following hypothesis types is developed to address the inherently dynamic nature of a network and its changing qualities?
A. The playbook may result in additional work for the analyst.
B. The playbook may cause a significant impact to the end user in the case of a false positive.
C. The playbook actions may change over time and require human tuning.
D. Orchestration systems require that a human be present during the full duration of its operation.
7. DevSecOps is used an approach for integration security in which stages of software engineering cycles?
A. Continuous integration
B. Continuous delivery
C. Continuous deployment
D. All of the above
8. What is the name of the framework that supports automated configuration and vulnerability checking based on specific standards?
A. STIG
B. SCAP
C. XCCDF
D. BASS
Answers
1. B. Common Data Enumeration (CDE) is not part of SCAP 1.3, identification schemes, which include Common Platform Enumeration (CPE), Software Identification (SWID) Tags, Common Configuration Enumeration (CCE), and Common Vulnerabilities and Exposures (CVE).
2. D. The initiating condition can be defined as the rules that must be completed to trigger the remaining steps in the playbook.
3. B. SCAP is not a data type. Although REST does not mandate a data type, the most commonly returned response data types are XML, HTML, and JSON.
4. D. HTTP status codes (RFC 7231) in the 400 range indicate a client error. In this case, 403 (Forbidden) indicates that the server understood the request but is refusing to fulfill it because of insufficient privileges.
5. A. cron is a standard Linux/Unix utility that is used to schedule commands or scripts for automatic execution at specific intervals.
6. B. In some situations, such as a full account reset, your organization may require that a human take action because of the potential for adverse impacts in the case of a false positive.
7. D. DevSecOps is about integrating automated security functionality at all stages in the lifecycle of application development.
8. B. The Security Content Automation Protocol (SCAP) is a framework that uses specific standards for the assessment and reporting of vulnerabilities of the technologies in an organization.