
Chapter 5
Wait-Free Synchronization
5.1 Introduction
The synchronization mechanisms that we have discussed so far are based on locking data structures during concurrent accesses. The lock-based synchronization mechanisms are inappropriate in fault tolerance and real-time applications. When we use lock-based synchronization, if a process fails inside the critical section, then all other processes cannot perform their own operations. Even if no process ever fails, lock-based synchronization is bad for real-time systems. Consider a thread serving a request with a short deadline. If another thread is inside the critical section and is slow, then this thread may have to wait and therefore miss its deadline. Using locks also require the programmer to worry about deadlocks. In this chapter, we introduce synchronization mechanisms that do not use locks and are therefore called lock-free. If lock-free synchronization also guarantees that each operation finishes in a bounded number of steps, then it is called wait-free.
To illustrate lock-free synchronization, we will implement various concurrent objects. The implementation of a concurrent object may use other simpler concurrent objects. One dimension of simplicity of an object is based on whether it allows multiple readers or writers. We use SR, MR, SW, and MW to denote single reader, multiple reader, single writer, and multiple writer, respectively. The other dimension is the consistency condition satisfied by the register. For a single-writer register, Lamport has defined the notions of safe, regular, and atomic registers.
In this chapter, we discuss these notions and show various lock-free and wait-free constructions of concurrent objects.
5.2 Safe, Regular, and Atomic Registers
A register is safe if a read that does not overlap with the write returns the most recent value. If the read overlaps with the write, then it can return any value.
For an example of safe and unsafe register histories, consider the histories shown in Figure 5.1. History (a) is unsafe because the read returns the value 4 but the most recent value written to the register is 3, which had completed before the read started. History (b) is also unsafe. Even though read returns a value that had been written before, it is not the most recent value. History (c) is safe because W(x, 3) and W(x, 4) are concurrent and therefore W(x, 4) could have taken effect before W(x, 3). Histories (d) and (e) are safe because the read operation overlaps a write operation and therefore can return any value.
A register is regular if it is safe and when the read overlaps with one or more writes, it returns either the value of the most recent write that preceded the read or the value of one of the overlapping writes. Consider histories shown in Figure 5.2. History (a) is regular because the read operation returns the value 3, which is the most recent write that preceded the read operation. History (b) is also regular because the read operation returns the value 4, which is the value written by a concurrent write operation. History (c) is not regular (although it is safe) because the value it returns does not match either the most recent completed write or a concurrent write. History (d) is also regular. It illustrates that there may be more than one concurrent writes with the read operation.
A register is atomic if its histories are linearizable. Clearly, atomicity implies regularity, which in turn implies safety. Consider the histories shown in Figure 5.3. History (a) is regular but not atomic. It is regular because both the reads are valid. It is not atomic because the second read returns a value older than the one returned by the first read. History (b) is atomic. It corresponds to the linearization in which the W(x, 3) operation took effect after the first R(x) operation. History (c) is atomic. It corresponds to the linearization in which the W(x, 3) operation took effect after the W(x, 4) operation, and the read operation by the third process occurred after W(x, 4) and before W(x, 3). History (d) is not atomic. Since the first read returned 3, W(x, 3) happens before W(x, 4) in any linearization. Since the second read is after both of the writes have finished, it can return only 4.
Surprisingly, it is possible to build a multiple-reader multiple-writer (MRMW) atomic multivalued register from single-reader single-writer (SRSW) safe boolean registers. This can be achieved by the following chain of constructions:
1. SRSW safe boolean register to SRSW regular boolean register
2. SRSW regular boolean register to SRSW regular multivalued register
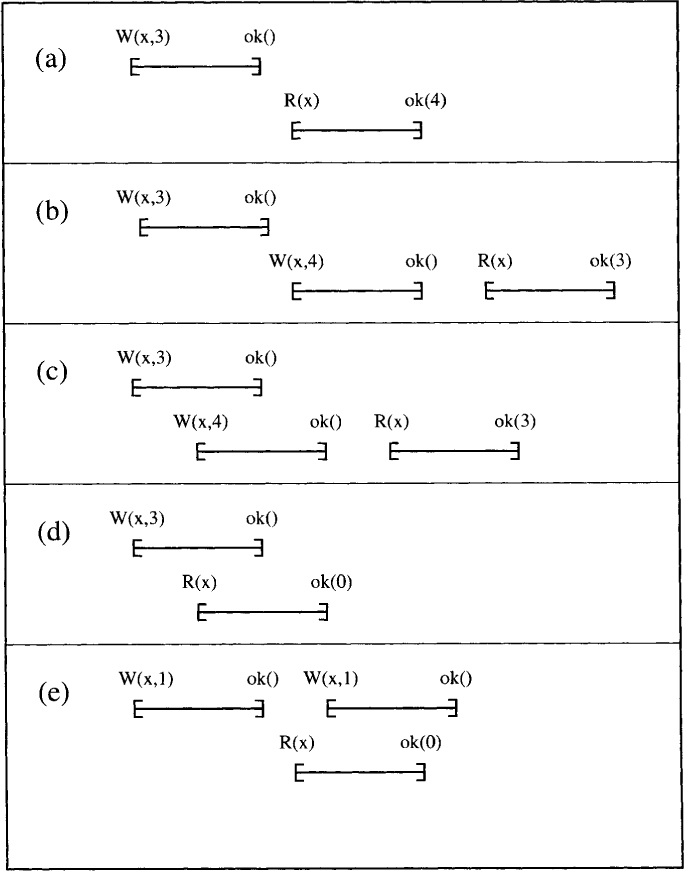
Figure 5.1: Safe and unsafe read-write registers
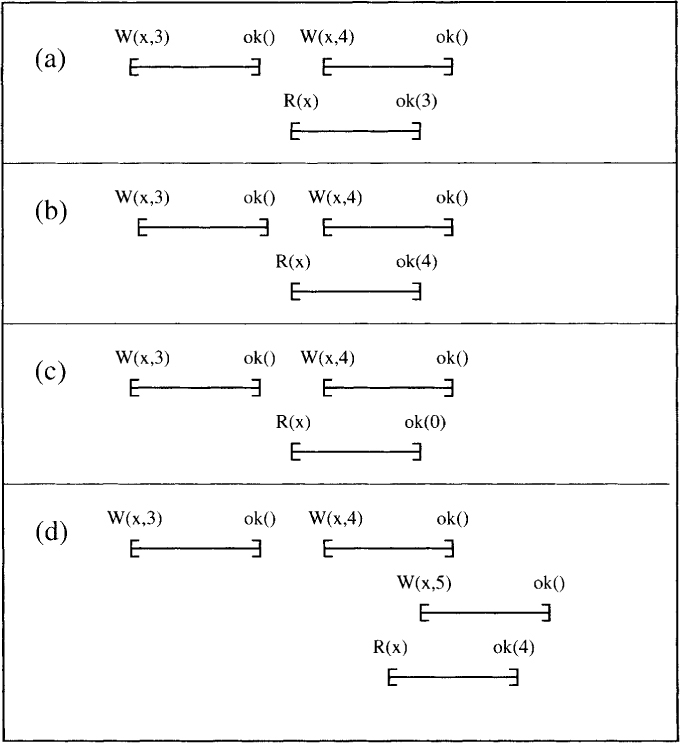
Figure 5.2: Concurrent histories illustrating regularity
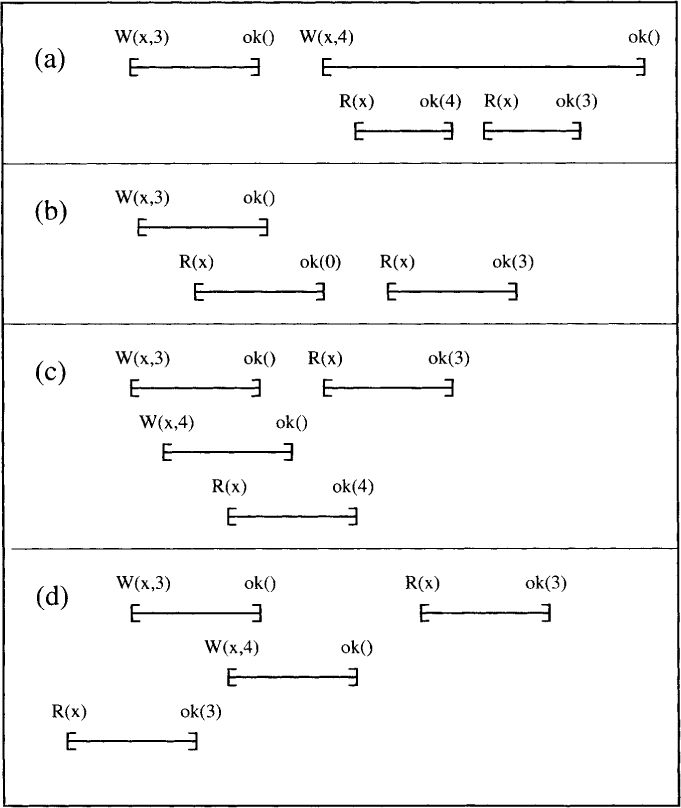
Figure 5.3: Atomic and nonatomic registers
3. SRSW regular register to SRSW atomic register
4. SRSW atomic register to MRSW atomic register
5. MRSW atomic register to MRMW atomic register
We show some of these constructions next.
5.3 Regular SRSW Register
We abstract a register as an object of a class with two methods, getValue and setValue, used for reading and writing, respectively. Assume that we have a safe single-reader single-writer boolean register. Since we have a single reader and a single writer, we need to worry about the semantics of getValue and setValue only when they overlap. In the presence of concurrency, we require that the value that is written not become corrupted. The value that is read can be arbitrary. If another getValue is performed after the write has finished, and there is no other setValue in progress, then the value returned should be the value written by the last setValue. We will use the following Java code as an abstraction for a SRSW safe boolean register.
class SafeBoolean {
boolean value ;
public boolean getValue () {
return value ;
}
public void setvalue (boolean b) {
value = b;
}
}
Note that this register is not regular exactly for one scenario—if setValue and getValue are invoked concurrently, the value being written is the same as the previous value and getValue returns a different value. This scenario is shown in Figure 5.1(e).
To make our register regular, we avoid accessing the shared register when the previous value of the register is the same as the new value that is being written. The construction of a regular SRSW register from a safe SRSW register in given in Figure 5.4.
Line 8 ensures that the writer does not access value if the previous value prev is the same as the value being written, b. Thus an overlapping read will return the correct value. If the new value is different, then the read can return arbitrary value from {true, false}, but that is still acceptable because one of them is the previous value and the other is the new value. This construction exploits the fact that the value is binary and will not work for multivalued registers.

Figure 5.4: Construction of a regular boolean register
5.4 SRSW Multivalued Register
We skip the construction from a SRSW regular boolean register to a SRSW atomic (linearizable) boolean register. Now assume that we have a SRSW atomic boolean register. This register maintains a single bit and guarantees that in spite of concurrent accesses by a single reader and a single writer, it will result only in linearizable concurrent histories. We now show that, using such registers, we can implement a multivalued SRSW register. The implementation shown in Figure 5.5 is useful only when maxVal is small because it uses an array of maxVal SRSW boolean registers to allow values in the range 0. . .maxVal-1.
The idea is that the reader should return the index of the first, true bit. The straightforward solution of the writer updating the array in the forward direction until it reaches the required index and the reader also scanning in the forward direction for the first true bit does not work. It can happen that the reader does not find any true bit. Come up with an execution to show this! So the first idea we will use is that the writer will first, set the required bit to true and then traverse the array in the backward direction, setting all previous bits to false. We now describe the setValue method in Figure 5.5. To write the value x, the writer makes the xth bit true at line 19 and then makes all the previous values false at lines 20-21. The reader scans for the true bit in the forward direction at line 12. With this strategy, the reader is guaranteed to find at least one bit to be true. Further, this bit would correspond to the most recent write before the read or one of the concurrent writes. Therefore, this will result in at least a regular register.

Figure 5.5: Construction of a multivalued register
However, a single scan by the reader does not result in a linearizable implementation. To see this, assume that the initial value of the register is 5 and the writer first writes the value 1 and then the value 4. These steps will result in
1. Writer sets A[1] to true.
2. Writer sets A[4] to true.
3. Writer sets A[1] to false.
Now assume that concurrent with these two writes, a reader performs two read operations. Since the initial value of A[1] is false, the first read may read A[4] as the first bit to be true. This can happen as follows. The reader reads A[1], A[2], and A[3] as false. Before the reader reads A[4], the writer sets A[1] to true and subsequently A[4] to true. The reader now reads A[4] as true. The second read may happen between steps 2 and 3, resulting in the second read returning 1. The resulting concurrent history is not linearizable because there is an inversion of old and new values. If the first read returned the value 4 then the second read cannot return an older value 1.
In our implementation, the reader first does a forward scan and then does a backward scan at line 14 to find the first bit that is true. Two scans are sufficient to guarantee linearizability.
5.5 MRSW Register
We now build a MRSW register from SRSW registers. Assume that there are n readers and one writer. The simplest strategy would be to have an array of n SRSW registers, V[n], one for each of the readers. The writer would write to all n registers, and the reader r can read from its own register V[r]. This does not result in a linearizable implementation. Assume that initially all registers are 5, the initial value of the MRSW register, and that the writer is writing the value 3. Concurrent to this write, two reads occur one after another. Assume that the first read is by the reader i and the second read is by the reader j, where i is less than j. It is then possible for the first read to get the new value 3 because the writer had updated V[i] and the second read to get the old value 5 because the writer had not updated V[j] by then. This contradicts linearizability.
To solve this problem, we require a reader to read not only the value written by the writer but also all the values read by other readers so far to ensure that a reader returns the most recent value. How does the reader determine the most recent value? We use a sequence number associated with each value. The writer maintains the sequence number and writes this sequence number with any value that it writes. Thus we view our SRSW register as consisting of two fields: the value and ts (for timestamp).
Now that our values are timestamped, we can build a MRSW register from SRSW registers using the algorithm shown in Figure 5.6.
Since we can only use SRSW objects, we are forced to keep O(n2) Comm registers for informing readers what other readers have read. Comm[i] [j] is used by the reader i to inform the value it read to the reader j.
The reader simply reads its own register and also what other readers have read and returns the latest value. It reads its own register at line 18 in the local variable tsv (timestamped value). It compares the timestamp of this value with the timestamps of values read by other readers at line 22. After line 23, the reader has the latest value that is read by any reader. It informs other readers of this value at lines 26-28.
The writer simply increments the sequence number at line 33 and writes the value in all n registers at lines 34-35.
5.6 MRMW Register
The construction of an MRMW register from MRSW registers is simpler than the previous construction. We use n MRSW registers for n writers. Each writer writes in its own register. The only problem for the reader to solve is which of the write it should choose for reading. We use the idea of sequence numbers as in the previous implementation. The reader chooses the value with the highest sequence number. There is only one problem with this approach. Previously, there was a single writer and therefore we could guarantee that all writes had different sequence numbers. Now we have multiple writers choosing their numbers possibly concurrently. How do we assign unique sequence number to each write? We use the approach of the Bakery algorithm. The algorithm is shown in Figure 5.7. In the method setValue, we require a writer to read all the sequence numbers and then choose its sequence number to be larger than the maximum sequence number it read. Then, to avoid the problem of two concurrent writers coming up with the same sequence number, we attach the process identifier w with the sequence number. Now two writes with the same sequence number can be ordered on the basis of process ids. Furthermore, we have the following guarantee: If one write completely precedes another write, then the sequence number associated with the first write will be smaller than that with the second write. The reader reads all the values written by various writers and chooses the one with the largest timestamp.

Figure 5.6: Construction of a multireader register

Figure 5.7: Construction of a multiwriter register
5.7 Atomic Snapshots
All our algorithms so far handled single values. Consider an array of values that we want to read in an atomic fashion using an operation readArray. We will assume that there is a single reader and a single writer but while the array is being read, the writes to individual locations may be going on concurrently. Intuitively, we would like our readArray operation to behave as if it took place instantaneously.
A simple scan of the array does not work. Assume that the array has three locations initially all with value 0 and that a readArray operation and concurrently two writes take place one after the other. The first write updates the first location to 1 and the second write updates the second location to 1. A simple scan may return the value of array as [0,1,0]. However, the array went through the transitions [0,0,0] to [1,0,0], and then to [1, 1,0]. Thus, the value returned by readArray is not consistent with linearizability. A construction that provides a readArray operation with consistent values in spite of concurrent writes with it is called an atomic snapshot operation. Such an operation can be used in getting a checkpoint for fault-tolerance applications.
We first present a lock-free construction of atomic snapshots shown in Figure 5.8. This construction is extremely simple. First, to determine whether a location in the array has changed, we append each value with the sequence number. Now, the readArray operation reads the array twice. If none of the sequence numbers changed, then we know that there exists a time interval in which the array did not change. Hence the copy read is consistent. This construction is not wait-free because if a conflict is detected, the readArray operation has to start all over again. There is no upper bound on the number of times this may have to be done.

Figure 5.8: Lock-free atomic snapshot algorithm
This construction is not wait-free because a readArray operation may be “starved” by the update operation. We do not go into detail here, but this and many other lock-free constructions can be turned into wait-free constructions by using the notion of “helping” moves. The main idea is that a thread tries to help pending operations. For example, if the thread wanting to perform an update operation helps another concurrent, thread that is trying to do a readArray operation, then we call it a “helping” move. Thus one of the ingredients in constructing a wait-free atomic snapshot would require the update operation to also scan the array.
5.8 Consensus
So far we have given many wait-free (or lock-free) constructions of a concurrent object using other simpler concurrent objects. The question that naturally arises is whether it is always possible to build a concurrent object from simpler concurrent objects. We mentioned that it is possible to construct a wait-free algorithm for an atomicSnapshot object that allows atomic reads of multiple locations in an array and atomic write to a single location. What if we wanted to build an object that allowed both reads and writes to multiple locations in an atomic manner? Such a construction is not possible using atomic read-write registers. Another question that arises concerns the existence of universal objects, that is, whether there are concurrent objects powerful enough to implement all other concurrent objects.
It turns out that consensus is a fundamental problem useful for analyzing such problems. The consensus problem requires a given set of processes to agree on an input value. For example, in a concurrent linked list if multiple threads attempt to insert a node, then all the processes have to agree on which node is inserted first.
The consensus problem is abstracted as follows. Each process has a value input to it that it can propose. For simplicity, we will restrict the range of input values to a single bit. The processes are required to run a protocol so that they decide on a common value. Thus, any object that implements consensus supports the interface shown in Figure 5.9.

Figure 5.9: Consensus Interface
The requirements on any object implementing consensus are as follows:
• Agreement: Two correct processes cannot decide different values.
• Validity: The value decided by a correct process must be one of the proposed values.
• Wait-free: Each correct process decides the value after a finite number of steps. This should be true without any assumption on relative speeds of processes.
A concurrent object O is defined to have a consensus number equal to the largest number of processes that can useO to solve the consensus problem. IfOcan be used to solve consensus for any number of processes, then its consensus number is ∞ and the object O is called the universal object.
Now if we could show that some concurrent object O has consensus number m and another concurrent object has consensus number m' > m, then it is clear that there can be no wait-free implementation of O' using O. Surprisingly, the converse is true as well: If O' has consensus number m' ≤ m, then O’ can be implemented using O.
We begin by showing that linearizable (or atomic) registers have consensus number 1. Clearly, an atomic register can be used to solve the consensus problem for a single process. The process simply decides its own value. Therefore, the consensus number is at least 1. Now we show that there does not exist any protocol to solve the consensus using atomic registers.
The argument for nonexistence of a consensus protocol hinges on the concepts of a bivalent state and a critical state. A protocol is in a bivalent state if both the values are possible as decision values starting from that global state. A bivalent state is a critical state if all possible moves from that state result in nonbivalent states. Any initial state in which processes have different proposed values is bivalent because there exist at least two runs from that state that result in different decision values. In the first run, the process with input 0 gets to execute and all other processes are very slow. Because of wait freedom, this process must decide, and it can decide only on 0 to ensure validity. A similar run exists for a process with its input as 1.
Starting from a bivalent initial state, and letting any process move that keeps the state as bivalent, we must hit a critical state; otherwise, the protocol can run forever. We show that even in a two-process system, atomic registers cannot be used to go to nonbivalent states in a consistent manner. We perform a case analysis of events that can be done by two processes, say, P and Q in a critical state S.
Let e be the event at P and event f be at Q be such that e(S) has a decision value different from that of f(S). We now do a case analysis (shown in Figure 5.10):
• Case 1: e and f are on different registers. In this case, both ef and fe are possible in the critical state S. Further, the state ef(S) is identical to fe(S) and therefore cannot have different decision values. But we assumed that f(S) and e(S) have different decision values, which implies that e(f(S)) and f(e(S)) have different decision values because decision values cannot change.
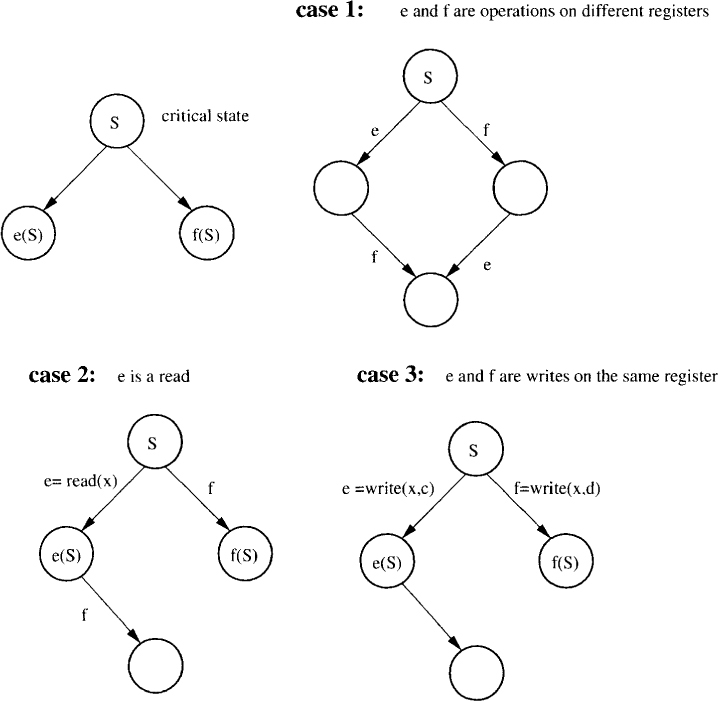
Figure 5.10: Impossibility of wait-free consensus with atomic read write registers
• Case 2: Either e or f is a read. Assume that e is a read. Then the state of Q does not change when P does e. Therefore, the decision value for Q from f(S) and e(S), if it ran alone, would be the same; a contradiction.
• Case 3: Both e and f are writes on the same register. Again the states f(S) and f(e(S)) are identical for Q and should result in the same decision value.
This implies that there is no consensus protocol for two processes that uses just atomic registers. Therefore, the consensus number for atomic registers is 1.
Now let us look at a concurrent object that can do both read and write in one operation. Let us define a TestAndSet object as one that provides the test and set instruction discussed in Chapter 2. The semantics of the object is shown in Figure 5.11.

Figure 5.11: TestAndSet class
We now show that two threads can indeed use this object to achieve consensus. The algorithm is given in Figure 5.12.
By analyzing the testAndSet operations on the critical state, one can show that the TestAndSet registers cannot be used to solve the consensus problem on three processes (see Problem 5.1).
Finally, we show universal objects. One such universal object is CompSwap (Compare and Swap). The semantics of this object is shown in Figure 5.13. Note that such objects are generally provided by the hardware and we have shown the Java code only to specify how the object behaves. Their actual implementation does no use any locks. Therefore, CompSwap can be used for wait-free synchronization. An object of type CompSwap can hold a value myValue. It supports a single operation compSwapOp that takes two arguments: prevValue and newValue. It replaces the value of the object only if the old value of the object matches the preValue.

Figure 5.12: Consensus using TestAndSet object

Figure 5.13:CompSwap object
Processes use a CompSwap object x for consensus as follows. It is assumed to have the initial value of –1. Each process tries to update x with its own pid. They use the initial value –1 as prevValue. It is clear that only the first process will have the right prevValue. All other processes will get the pid of the first process when they perform this operation. The program to implement consensus is shown in Figure 5.14.

Figure 5.14: Consensus using CompSwap object
We now describe another universal object called the load-linked and store-conditional (LLSC) register. An LLSC object contains an object pointer p of the following type.
public class ObjPointer {
public Object obj ;
public int version;
}
It provides two atomic operations. The load-linked operation allows a thread to load the value of a pointer to an object. The store-conditional operation allows the pointer to an object to be updated if the pointer has not changed since the last load-linked operation. Thus the semantics of LLSC are shown in Figure 5.15. With each object, we also keep its version number. The method load_linked reads the value of the pointer p in the variable local. The method store_conditional takes an object newObj and a pointer local as its parameters. It updates LLSC object only if the pointer local is identical to p.
The program for implementing consensus using LLSC is left as an exercise.
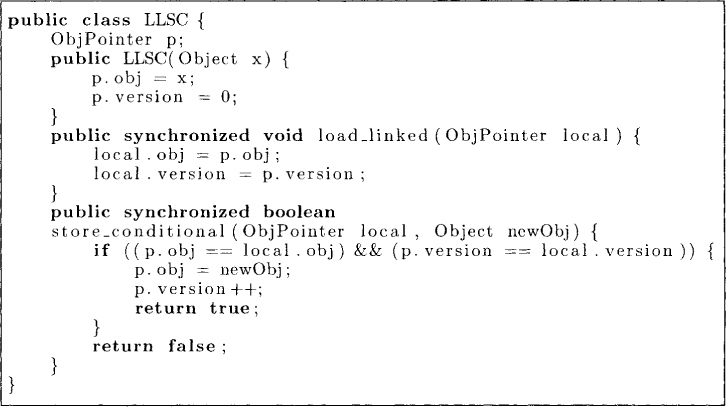
Figure 5.15: Load-Linked and Store-Conditional object
5.9 Universal Constructions
Now that we have seen universal objects, let us show that they can indeed be used to build all other concurrent objects. We first show a construction for a concurrent queue that allows multiple processes to enqueue and dequeue concurrently. Our construction will almost be mechanical. We first begin with a sequential implementation of a queue shown in Figure 5.16.
Now we use LLSC to implement a concurrent queue using a pointer-swinging technique. In the object pointer swinging technique any thread that wishes to perform an operation on an object goes through the following steps:
1. The thread makes a copy of that object.
2. It performs its operation on the copy of the object instead of the original object.

Figure 5.16: Sequential queue
3. It swings the pointer of the object to the copy if the original pointer has not changed. This is done atomically.
4. If the original pointer has changed, then some other thread has succeeded in performing its operation. This thread starts all over again.
Using these ideas, we can now implement a concurrent queue class as shown in Figure 5.17. To Enqueue an item (of type string), we first save the pointer to the queue x in the variable local at line 10. Line 11 makes a local copy new_queue of the queue x accessed using local pointer. It then inserts data in new_queue at line 12. Line 13 returns true if no other thread has changed x. If store_conditional returns false, then this thread tries again by going to the line 9. The method Dequeue is similar.

Figure 5.17: Concurrent queue
While the above mentioned technique can be applied for lock-free construction of any concurrent object, it may be inefficient in practice for large objects because every operation requires a copy. There are more efficient algorithms for large concurrent objects. However, these algorithms are different for different data structures and will not be covered in this book.
5.10 Problems
5.1. Show that TestAndSet cannot be used to solve the consensus problem for three processes. (Hint: Show that TestAndSet by two processes in any order results in the same state and the third process cannot distinguish between the two cases.)
5.2. Consider a concurrent FIFO queue class that allows two threads to concurrently dequeue. Show that the consensus number of such an object is 2. (Hint: Assume that queue is initialized with two values 0 and 1. Whichever process dequeues 0 wins.)
5.3. Consider a concurrent object of type Swap that holds an integer. It supports a single method swapOp(int v) that sets the value with v and returns the old value. Show that Swap has consensus number 2.
5.4. Show that LLSC is a universal object.
*5.5. Give a lock-free construction of queue that does not make a copy of the entire queue for enqueue and dequeue.
5.11 Bibliographic Remarks
The notion of safe, regular, and atomic registers was first proposed by Lamport [Lam86] who also gave many of the constructions provided here. The notions of consensus number and universal objects are due to Herlihy [Her88]. The reader should also consult [AW98] (chapters 10 and 15).