
Chapter 42. Annotation
Data about program elements, such as classes and methods, which can be processed during compilation or execution.

We are used to classifying the data in our programs and making rules about how they work. Customers can be grouped by region and have payment rules. Often, it is useful to make these kinds of rules about elements of the program itself. Languages usually provide some built-in mechanisms to do this, such as access controls that allow us to mark classes and methods as public or private.
However, there are often things we would like to mark that go beyond what a language supports, or even should reasonably support. We might want to restrict the values that an integer field might take, mark methods that should be run as part of testing, or indicate that a class can safely be serialized.
An Annotation is a piece of information about a program element. We can take this information and manipulate it during runtime, or indeed during compile time if the environment supports this. Annotations thus provide a mechanism to extend the programming language.
I’ve used the term Annotation here, as that is the term used in the Java programming language. A similar syntax predated this in .NET, but its term “attribute” is too widely used for other concepts, so I prefer to follow the Java terminology. However, the concept here is more broad than the syntax, and the same benefits can be achieved without this kind of special syntax.
42.1 How It Works
There are two topics in using Annotations: defining them and processing them. Although both depend on facilities that vary from language to language, definition and processing are relatively independent of each other, in that the same processing technique can be used for Annotations defined in different ways.
To fit in with our general model of DSLs, the defining syntax represents how the Annotations work as an internal DSL. In each case, they develop a Semantic Model by attaching data to the runtime model of a program that’s built into a language. Later processing steps correspond to the running of the Semantic Model; as with any DSL, these can involve model execution and code generation.
42.1.1 Defining an Annotation
The most obvious way to define an Annotation is to use specially designed syntax that some languages have. So, in Java we can mark a test method like this:
@test public void softwareAlwaysWorks()
or, in C#, like this:
[Test] public void SoftwareAlwaysWorks()
Both languages allow parameters to their annotations, so you can do something like:

Using a purpose-designed syntax is the most obvious, and often the easiest, way to put together annotations. However, there are other techniques that you can use.
One of the most natural ways to specify an Annotation is to use class methods. Let’s consider a case where we want to add a valid range annotation that indicates a specific legal range for a field. Let’s say we want to limit a patient’s height between 1 and 120 (inches) and weight between 1 and 1000 (pounds). (Usually we’d use a Quantity here, but we’ll use an integer to keep it simple.) We specify these ranges in Ruby like this:
valid_range :height, 1..120
valid_range :weight, 1..1000
In order to make this work, we define a class method called valid_range. This method takes two arguments, the name of the field and the range to limit that field to. The class method can then do whatever it likes with this data. It can just add the bare data into a structure, mirroring what the built-in syntax does, or it can directly create and store validator objects.
Using class methods like this can be almost as easy as using purpose-designed syntax. The biggest issue is that the class method call needs the name of the program element it’s annotating. This leads to some extra verbiage, but also gives the programmer the freedom to separate the annotations from the annotated declarations. That is a big payoff for languages that make this easy—there’s little need to provide a special annotation syntax.
Using class methods like this does raise some issues to keep in mind. For the annotations to be stored, they need to be executed. The Ruby example above is executed when the code is loaded. Some languages may need additional mechanics to ensure this is done. The simplest way to store annotation data is with class variables, but many languages share class variables across a class and its subclasses, which wouldn’t mess up this example but could lead to problems in other cases.
I’ve described this technique in object-oriented terms, but you can do basically the same thing with any language that allows you to easily represent its elements. So, you could define a Lisp structure that tagged function names with data. That structure could live anywhere as long as it could be found by later processing.
A common technique used in statically typed languages is a marker interface. This involves defining an interface with no methods and implementing it. The presence of the interface effectively tags the class for later processing. This technique only works on classes, not methods or fields.
Naming conventions provide a simple form of annotation. This was what was done in many xUnit implementations—test methods were tagged by the convention of having their name begin with test. For simple annotations, this can work rather well, but you’re limited in that multiple annotations are difficult to support and parameters are practically impossible.
In all these cases, the annotations are processed by the built-in language constructs to build up a Semantic Model. In addition to the usual internal DSL limitations—the syntax of the DSL is limited by the syntax of the host language—there is a further limitation for Annotations. With Annotations, the Semantic Model has to be based on the fundamental representation of the program itself. In an object-oriented program, the foundational representation is that of classes, fields, and methods. The Semantic Model of the Annotations is a decoration of that structure—you can’t practically build a completely separate and independent Semantic Model.
42.1.2 Processing Annotations
Annotations are defined in the source code but are available for processing at later stages—typically during compilation, program loading, or during regular runtime operation.
Processing during regular operation is probably the most common case. This involves using the annotations to control some aspect of an object’s behavior. A simple example of this is running test methods in xUnit-style testing frameworks. These tools allow tests to be defined as methods in test classes. Not all methods are test methods, so some annotation scheme is used to identify the tests. A test runner program finds these test methods and runs them.
Database mapping can work in a similar way. Here, a database mapping program interrogates the attributes to find how the fields in the program map to persistent storage structures. It then uses this information to map data.
This kind of processing can be done both at program load and when the processing is used. Validation annotations, such as those shown above, can be partially processed during program startup to create validator objects which are attached to classes. These validators can then be used to validate objects during the execution of the program.
These runtime uses of Annotations correspond to the general approach of model execution of DSLs. As with any DSL, there is also the alternative of code generation. If you have a dynamic language, this code generation can be done during runtime—usually during program load. It can take the form of generating new classes, or adding methods to existing classes.
For compiled languages, generating code at runtime is usually more complicated. It can be possible to run the compiler at runtime and link modules dynamically, but this can be awkward to set up. Another option is when the language provides hooks in its compiler to process annotations—as this is currently done in Java.
Of course code can be generated before compilation. So for the validation example, we could generate a validation method either in the host class or as a separate object. This code would then be part of the program as it compiles. Such intimate intermixing of written and generated code can be confusing, however.
Bytecode postprocessing offers another route for compiled programs. In this approach, we let the compiler compile the program, and after compilation we manipulate the bytecode to add generated steps.
Processing can occur in multiple places with multiple definitions of the processing. If we are building a web application and need to define validations on fields, we’d like to run those validations in multiple places. For best responsiveness, we want to run them in the browser using Javascript. But we can never rely on that, as the user can always get around them, so we also need to run the validations on the server. Using Annotation, we can create a runtime check for the server and generate Javascript to validate in the browser without duplicating code. Both checks can be fully derived from a single Annotation.
42.2 When to Use It
The wide-scale use of Annotations is still relatively new in mainstream programming languages. We are still learning when best to use them.
The key feature of Annotations is that they allow you to separate definition from processing. The validation example is a good illustration of this. If we want to ensure the valid range of a field, then an obvious way to do this is as part of the setting method. The problem with this is that it combines the definition of the constraint with when that constraint is enforced—in this case, forcing the validation to occur when changing a value.
There are many cases when it’s useful to check constraints at other times, perhaps allowing a user to fill a form but only validating when that form is submitted. To get a validate-on-submit behavior, you might have an overall validate method on an object—but, again, you define the constraints at the same time when they are checked.
Separating the two allows you to check constraints at different times, perhaps even applying different subsets of constraints at different times. It can also make the code clearer by letting the definitions of the constraints stand alone, so a programmer can see the constraint definition not cluttered by the mechanics of running the checks.
So the strength of Annotations lies where it makes sense to separate definition and processing. You might want to do this because you want processing to change independently of definition, or because you want to make definition easier to understand by letting it stand alone.
The downside of using Annotations is that it is more awkward to follow both definition and processing. If you need to understand them together, then Annotations force you to look in two disconnected places. The processing code is also generic, which may make it even harder to follow.
A corollary to this is that the definition of an Annotation should be declarative and not involve any logic flow. Furthermore, it shouldn’t imply any ties to when the processing logic occurs, or any ordering of processing Annotations attached to the same or different program elements.
42.3 Custom Syntax with Runtime Processing (Java)
For our first code example of annotations, I’ll use the most obvious case: a language that has a custom syntax for annotations—in this case Java, which added them with version 1.5 (or 5, or whatever number they are using these days).
Here’s how to specify a valid range for an integer value:

To make this work, I need to define an annotation type like this:
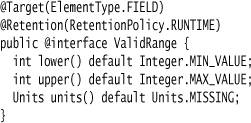
In Java’s annotation system, the annotation type itself is effectively an object that has only fields, which must be literals or other annotations.
As a result of this, all the processing of annotations is done elsewhere. I’ll trigger validation processing by having objects validate themselves.
(This is a side note to the topic at hand, but I think it’s important to point out that having an object validate itself in this way is not always the correct strategy. When you validate something, you always do so for a context, and that context is usually some action involving that object. The validation approach I’m using here implies validation is correct for all contexts where you use this code. Sometimes this is the case, but often it isn’t.)
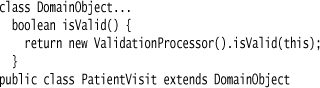
All the domain object method does is delegate to the validation processor.
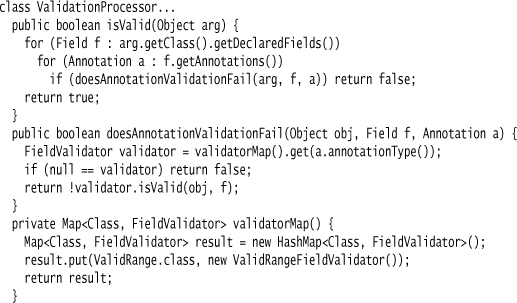
The validation processor scans the target object class for annotations, figures out which ones are validations, gets hold of a specific validator object for each annotation, and runs that validator against the object.
Most of this code only needs to be run once, as annotations don’t change at runtime. I’ll leave it up to you to find a more efficient way of running this setup code, if you promise to only do it if you know it’s a performance bottleneck.
The link between annotation and a processing class is made by a dictionary built in validatorMap(). If you have a scheme where annotations can contain code, then the annotation could implement the isValid method itself. I could also include the name of the validator class in the annotation as one of its fields. I didn’t do this because I generally prefer, at least in Java, to make annotations independent of the processing mechanism.
I then have the validator object check the range.

42.4 Using a Class Method (Ruby)
Ruby is an example of a language where there’s no custom annotation syntax, yet where annotations are widely used. In Ruby, we define annotations with a class method called directly within the body of the class.
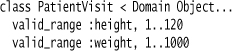
(For the Ruby examples, I’m using integers rather than quantities to keep the examples simpler. Feel free to spank me if you ever see me doing this with production code.)
Code like this, directly in the body of the class, is run when the class is loaded, so it works well for this kind of initialization:

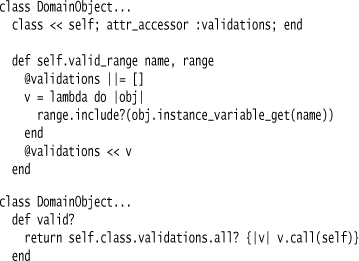
The implementation here is pretty straightforward. I store the validators using a class variable. I need to make this class variable a hash indexed by the actual class, as a class variable’s value is shared across all subclasses.
Whenever valid_range is called, it begins by initializing the hash’s value to an empty array if necessary. It then creates a closure, taking a single argument, that carries out the validation and adds it to the array.
I’ll also give each object a method to validate itself.

Using a class variable with a hash to store differing values per class is really a way of implementing a class instance variable. I can do this directly in Ruby like this:
class DomainObject...
class << self; attr_accessor :validations; end
42.5 Dynamic Code Generation (Ruby)
One of the nice things about working with a dynamic language is the ability to add to the code at runtime. I can use this to show a further enhancement with processing Annotations. In this case, I want to not just provide an overall method to validate an object, but also provide methods to validate individual fields. Thus, using our patient visit example, I want to have not just a valid? method, but also the field-specific methods valid_height? and valid_weight? on my patient visit class. I want these methods to be automatically generated, so that any field that has a validation annotation will automatically get the field-specific validation method.
The nice thing about this is that I don’t need to modify the annotation calls in the patient visit class; they can remain the same as the simpler case.

I use the class instance variable approach to storing the validators. The difference is that instead of storing my validators as simple closures, I make field validator classes that take the field name and a closure as arguments.
class DomainObject...
class << self; attr_accessor :validations; end
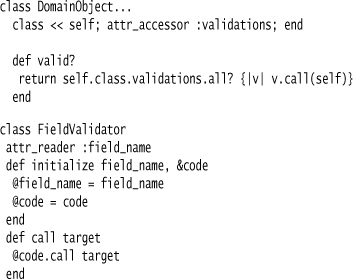
If I use the object validation method, all the validators run the same as before. The extra step is this method:

This method tests to see if it has already been defined. If not, we use define_method to add a new method to the patient visit class. This method selects those validations that apply to the given field and runs just those. (I have to wrap the call to define_method inside class_eval because define_method is actually a private method. I could avoid this by using class_eval with a string.)