
Chapter 24. Tree Construction
The parser creates and returns a syntax tree representation of the source text that is manipulated later by tree-walking code.
24.1 How It Works
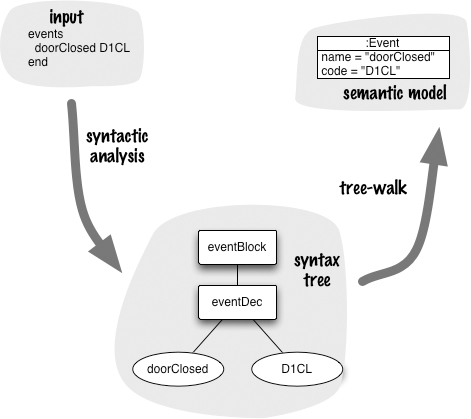
Any parser using Syntax-Directed Translation builds up a syntax tree while it’s doing the parsing. It builds the tree up on the stack, pruning the branches when it’s done with them. With Tree Construction, we create parser actions that build up a syntax tree in memory during the parse. Once the parse is complete, we have a syntax tree for the DSL script. We can then carry out further manipulations based on that syntax tree. If we are using a Semantic Model, we run code that walks our syntax tree and populates the Semantic Model.
The syntax tree that we create in memory doesn’t need to correspond directly to the actual parse tree that the parser creates as it goes—indeed, it usually doesn’t. Instead, we build what’s called an abstract syntax tree. An abstract syntax tree (AST) is a simplification of the parse tree which provides a better tree representation of the input language.
Let’s explore this with a short example. I’ll use a declaration of events for my state machine example.

I will parse it with this grammar:

to produce the parse tree in Figure 24.1.
Figure 24.1 Parse tree for the event input
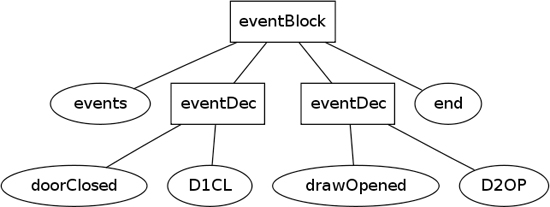
If you look at this tree, you should realize that the events and end nodes are unnecessary. The words were needed in the input text in order to mark the boundaries of the event declarations, but once we’ve parsed them into a tree structure we no longer need them—they are just cluttering up the data structure. Instead, we could represent the input with the syntax tree in Figure 24.2.
Figure 24.2 An AST for the event input
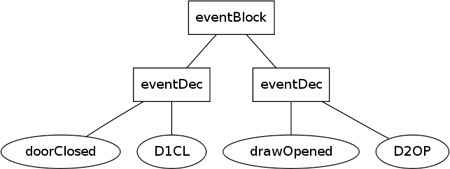
This tree is not a faithful representation of the input, but it’s what we need if we’re going to process the events. It’s an abstraction of the input that’s better suited for our purpose. Obviously, different ASTs might be needed for different reasons; if we only wanted to list the event codes, we could drop the name and eventDec nodes as well and just keep the codes—that would be a different AST for a different purpose.
At this point I should clarify my terminological distinctions. I use the term syntax tree to describe a hierarchic data structure that’s formed by parsing some input. I use “syntax tree” as a general term: parse tree and AST are particular kinds of syntax trees. A parse tree is a syntax tree that corresponds directly to input text, while an AST makes some simplifications of the input based on usage.
In order to build up a syntax tree, you can use code actions in your BNF. In particular, the ability of code actions to return values for a node comes in very handy with this approach—each code action assembles the representation of its node in the resulting syntax tree.
Some Parser Generators go further, offering a DSL for specifying the syntax tree. In ANTLR, for instance, we could create the AST above using a rule like this:
eventDec : name=ID code=ID -> ^(EVENT_DEC $name $code);
The → operator introduces the tree construction rule. The body of the rule is a list where the first element is the node type (EVENT_DEC) followed by the child nodes, which in this case are the tokens for the name and code.
Using a DSL for Tree Construction can greatly simplify building up an AST. Often, Parser Generators that support this will give you the parse tree if you don’t supply any tree construction rules, but you almost never want the parse tree. It’s usually preferable to simplify it into an AST using these rules.
An AST built in this way will consist of generic objects that hold the data of for the tree. In the above example, the eventDec is a generic tree node with name and code as children. Both the name and code are generic tokens. If you build up the tree yourself with code actions, you could create real objects here—such as a true event object with the name and code as fields. I prefer to have a generic AST and then use second-stage processing to transform that into a Semantic Model. I’d rather have two simple transformations than one complicated one.
24.2 When to Use It
Both Tree Construction and Embedded Translation are useful approaches to populating a Semantic Model while parsing. Embedded Translation does the transformation in a single step, while Tree Construction uses two steps with the AST as an intermediate model. The argument for using Tree Construction is that it breaks down a single transformation into two, simpler transformations. Whether this is worth the effort of dealing with an intermediate model depends very much on the complexity of the transformation. The more complex the transformation is, the more useful an intermediate model can be.
A particular driver of complexity is the need to make several passes through the DSL script. Things like forward references can be a bit more awkward to use if you are doing all the processing in a single step. With Tree Construction it’s easy to walk the tree many times as part of later processing.
Another factor that encourages you to use Tree Construction is if your Parser Generator provides tools allowing you to build an AST really easily. Some Parser Generators give you no choice—you have to use Tree Construction. Most give you the option to use Embedded Translation, but if the Parser Generator makes it really easy to build an AST, that makes Tree Construction a more attractive option.
Tree Construction is likely to consume more memory than alternative approaches, as it needs to store the AST. In most cases, however, this won’t make any appreciable difference. (Although that certainly used to be a big factor in earlier days.)
You can process the same AST in several different ways to populate different Semantic Models if you need them, and reuse the parser. This may be handy, but if the parsers’ tree construction is easy then it may be simpler to use different ASTs for different purposes. It may also be better to transform to a single Semantic Model and then use that as a basis to transform to other representations.
24.3 Using ANTLR’s Tree Construction Syntax (Java and ANTLR)
I’ll use the state machine DSL from the opening chapter, specifically with Miss Grant’s controller. Here’s the specific text that I’ll be using for the example.
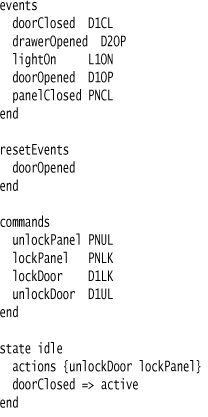
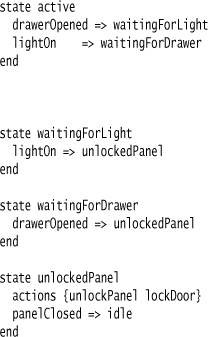
24.3.1 Tokenizing
Tokenizing for this is very simple. We have a few keywords (events, end, etc.) and a bunch of identifiers. ANTLR allows us to put the keywords as literal text in the grammar rules, which is generally easier to read. So we only need lexer rules for identifiers.
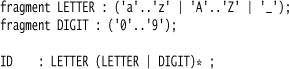
Strictly, the lexing rules for names and codes are different—names can be any length but codes must be four uppercase letters. So we could define different lexer rules for them. However, in this case it gets tricky. The string ABC1 is a valid code, but also a valid name. If we see ABC1 in the DSL program, we can tell which it is by its context: state ABC1 is different from event unlockDoor ABC1. The parser will also be able to use the context to tell the difference, but the lexer can’t. So the best option here is to use the same token for both of them and let the parser sort it out. This means that the parser won’t generate an error for five-letter codes—we have to sort that out in our own semantic processing.
We also need lexer rules to strip out the whitespace.
WHITE_SPACE : (’ ’ |’ ’ | ’
’ | ’
’)+ {skip();} ;
COMMENT : ’#’ ~’
’* ’
’ {skip();};
In this case, whitespace includes newlines. I have laid the DSL out in a fashion that suggests that there are meaningful line endings which end statements in the DSL, but as you can now see this isn’t true. All whitespace, including the line endings, is removed. This allows me to format the DSL code in any fashion I like. This is a notable contrast to Delimiter-Directed Translation. Indeed it’s worth remarking that there are no statement separators at all, unlike most general-purpose languages that need something like a newline or a semicolon to end statements. Often, DSLs can get away with no statement separators because the statements are very limited. Things like infix expressions will force you to use statement separators, but for many DSLs you can do without them. As with most things, don’t put them in until you actually need them.
For this example, I’m skipping the whitespace which means that it’s lost completely to the parser. This is reasonable as the parser doesn’t need it—all it needs are the meaningful tokens. However, there is a case where whitespace ends up being handy again—when things go wrong. To give good error reports, you need line numbers and column numbers; to provide these, you need to keep the whitespace. ANTLR allows you to do this by sending whitespace tokens on a different channel, with syntax like WS : ('
' | '
' | ' ' | ' ')+ {$channel=HIDDEN}. This sends the whitespace through on a hidden channel so it can be used for error handling but doesn’t affect the parsing rules.
24.3.2 Parsing
The lexing rules work the same in ANTLR whether you are using Tree Construction or not—it’s the parser that operates differently. In order to use Tree Construction, we need to tell ANTLR to produce an AST.

Having told ANTLR to produce an AST, I’m also telling it to populate that AST with nodes of a particular type: MfTree. This is a subclass of the generic ANTLR CommonTree class that allows me to add some behavior that I prefer to have on my tree nodes. The naming here is a little confusing. The class represents a node and its children, so you can either think of it as a node or as a (sub)tree. ANTLR’s naming calls it a tree, so I’ve followed that in my code, although I think of it as a node in the tree.
Now we’ll move onto the grammar rules. I’ll begin with the top-level rule that defines the structure of the whole DSL file.
machine : eventList resetEventList? commandList? state*;
This rule lists the main clauses in sequence. If I don’t give ANTLR any tree construction rules, it will just return a node for each term on the right-hand side in sequence. Usually this isn’t what we want, but it does work right here.
Taking the terms in order, the first one gets into events.
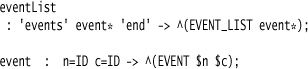
There are a few new things to talk about with these two rules. One is that these rules introduce ANTLR’s syntax for tree construction, which is the code following “→” in each rule.
The eventList rule uses two string constants—this is us putting the keyword tokens directly into the parser rules without making separate lexer rules for them.
The tree construction rules allow us to say what goes in the AST. In both cases here, we use ^(list...) to create and return a new node in the AST. The first item in the parenthesized list is the token type of the node. In this case we’ve made a new token type. All items following the token type are the other nodes in the tree. For the event list, we just put all the events as siblings in the list. For the event, we name tokens in the BNF and reference them in the tree construction to show how they are placed.
The EVENT_LIST and EVENT tokens are special tokens that I’ve created as part of parsing—they weren’t tokens produced by the lexer. When I create tokens like this I need to declare them in the grammar file.

Figure 24.3 AST for Miss Grant’s event list

The commands are treated in the same way, and the reset events are a simple list.

The states are a bit more involved, but they use the same basic approach.

Each time, what I’m doing is collecting together appropriate clumps of the DSL and putting them under a node that describes what that clump represents. The result is an AST that is very similar to the parse tree, but not exactly the same. My aim is to keep my tree construction rules very simple and my syntax tree easy to walk.
24.3.3 Populating the Semantic Model
Once the parser has made a tree, the next step is to walk this tree and populate the Semantic Model. The Semantic Model is the same state machine model that I used in the introduction. The interface for building it is pretty simple, so I won’t go into it here.
I create a loader class to populate the Semantic Model.
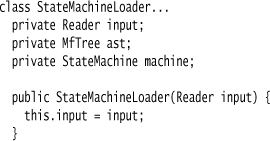
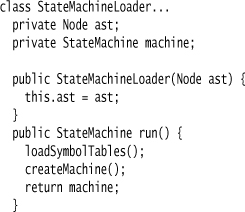
I use the loader as a command class. Here is its run method that indicates the sequence of steps I use to carry out the translation:

To explain that in English, I first use the ANTLR-generated parser to parse the input stream and create an AST. Then I navigate through the AST to build Symbol Tables. Finally, I assemble the objects into a state machine.
The first step is just the incantations to get ANTLR to build the AST.

MyNodeAdaptor is a second step in telling ANTLR to create the AST with MfTree rather than CommonTree.
The next step is to build the symbol table. This involves navigating the AST to find all the events, commands, and states and load them into maps so we can look them up easily to make the links when we create the state machine.

Here’s the code for the events:
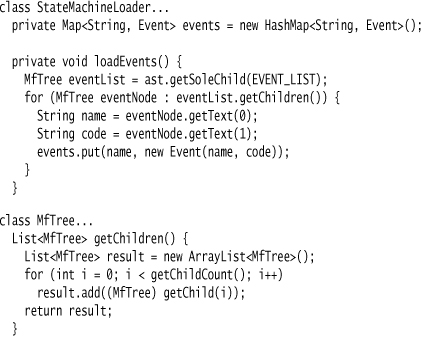

The node types are defined in the generated code in the parser. When I use them in the loader, I can use a static import to make them easy to refer to.
The commands are loaded in a similar way—I’m sure you can guess what the code for that looks like. I load the states in a similar way, but at this point I only have the name in the state objects.
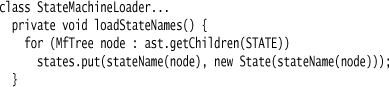
I have to do something like this because the states are used in forward references. In the DSL, I can mention a state in a transition before I declare the state.
This is a case where tree construction works very nicely—there’s no problem in taking as many passes through the AST as I need to wire things up.
The final step is to actually create the state machine.

The start state is the first declared state.

Now we can wire up the transitions and actions for all the states.

And finally we add the reset events, which the state machine API expects us to do at the end.

24.4 Tree Construction Using Code Actions (Java and ANTLR)
ANTLR’s syntax for Tree Construction is the easiest way to do it, but many Parser Generators lack a similar feature. In these cases, you can still do Tree Construction, but you have to form the tree yourself with code actions. With this example, I’ll demonstrate how to do this. I’ll use ANTLR for this example to save introducing another Parser Generator, but I should stress that I’d never use this technique in ANTLR itself, as the special syntax is much easier to do.
The first thing to decide is how to represent the tree. I use a simple node class.

My nodes here are not statically typed—I use the same class for state nodes as for event nodes. An alternative is to have different kinds of nodes for different classes.
I have a small tree constructor class that wraps ANTLR’s generated parser to produce the AST.

I need an enum to declare my node types. I put this in the tree constructor and statically import it to the other classes that need it.

The grammar rules in the parser all follow the same basic format. The rule for events illustrates this nicely and simply.
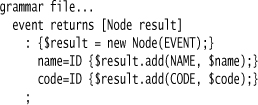
Each rule declares a node as its return type. The first line of the rule creates that result node. As I recognize each token that’s part of the rule, I simply add it as a child.
Higher-level rules repeat the pattern.

The only difference is that I add the nodes from subrules using $e.result so that ANTLR will pick out the return type of the rule properly.
There’s a nonobvious idiom on the line labeled add event. Notice how I have to put the event clause and the code action inside parentheses and have the Kleene star operator apply to the parenthesized group. I do this to ensure that the code action is run once for each event.
I added methods on the node to make it easy to add child nodes with simple code.

Normally, I use an Embedment Helper with a grammar file. This case is an exception, since the code for building the AST is so simple that calls to a helper wouldn’t be any easier to work with.
The top-level machine rule continues this basic structure.

The commands and reset events are loaded the same way as the events.

Another difference from the grammar with the specific syntax is that I’ve made special node types for the name and code, which makes the tree-walking code a bit clearer later on.
The final code to show is the parsing of the states.

The grammar file code is very regular—indeed rather boring. Boring code usually means that you need another abstraction, which is exactly what the special tree construction syntax provides.
The second part of the code is to walk the tree and create the state machine. This is pretty much the same code as the earlier example, the only difference coming from the fact that the nodes I have are slightly different from the previous example.
I begin with loading up the symbol tables.

I’ve shown the code to loading events, the other classes are similar.

I added a method to the node class to get the text for a single child of a type. This feels rather like a dictionary lookup but using the same tree data structure.

With the symbols nicely organized, I can then create the state machine.

The last step is loading the reset events.
