
Chapter 49. Dependency Network
A list of tasks linked by dependency relationships. To run a task, you invoke its dependencies, running those tasks as prerequisites.
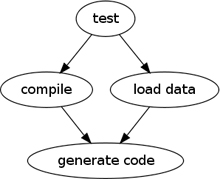
Building a software system is a common predicament for software developers. At various points, there are various things that you may want to do: just compile the program, or run tests. If you want to run tests, you need to make sure your compilation is up-to-date first. In order to compile, you need to ensure you’ve carried out some code generation.
A Dependency Network organizes functionality into a directed acyclic graph (DAG) of tasks and their dependencies on other tasks. In the case above, we would say that the test task is dependent upon the compilation task, and the compilation task is dependent upon the code generation task. When you request a task, we first find any tasks it depends on and ensure they are executed first, if needed. We can navigate through a dependency network to ensure that all the prerequisite tasks necessary for the requested task are executed. We can also make sure that even if a task crops up more than once through different dependency paths, it’s still executed only once.
49.1 How It Works
In the opening example above, I presented a task-oriented description where the network is a set of tasks with dependencies between them. An alternative way is a product-oriented style where we focus on the products we want to create and the dependencies between them. I’ll illustrate the difference by considering the case where we carry out a build by doing some code generation and then compiling. In the task-oriented approach, we would say that we have a code generation task and a compilation task, with the compilation task depending on the code generation task. In the product-oriented style, we would say that we have an executable which is created by a compilation process, and some generated source files that are created by code generation. We then state the dependencies by saying that the code-generated source files are a prerequisite to building the executable. The difference between these two may seem oversubtle at the moment, but hopefully will get clearer as I continue.
The way a dependency network is run is by requesting that we either run a task (process-oriented) or build a product (product-oriented). We typically refer to this requested product or task as the target. The system then finds all the prerequisites of the target and continues finding the prerequisites of the prerequisites of the . . . until it has a full list of all the transitive prerequisites that need to be run or built. It invokes each task, using the dependency relationships to ensure that no task is invoked before its prerequisites. An important property of this is that no task is executed more than once, even if traversing the network means you run into the same item several times.
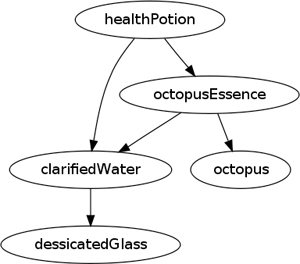
To talk about this, I’ll introduce a slightly larger example that will also allow me to get away from the ever-present example of software builds. Let’s consider a production facility for magical potions. Each potion has ingredients, which are substances that often need to be made themselves from other substances. So, in order to create a health potion, we need clarified water and octopus essence (I’m ignoring quantities here). To create the octopus essence, we need an octopus and clarified water. To create the clarified water, we need dessicated glass. We can state the links between these products (I’m using a product-oriented approach here) as a series of dependencies:
• healthPotion => clarifiedWater, octopusEssence
• octopusEssence => clarifiedWater, octopus
• clarifedWater => dessicatedGlass
In this case, we want to ensure that the task to produce clarified water is only run once when we request a health potion—even though there are multiple dependencies running into it.
Figure 49.1 A graph showing the dependency links between substances needed for a health potion
It’s often easy to think of physical things in this way—for example, consider the clarified water product to be something that fits in a metal bucket. The same notion, however, also makes sense for information products. In this case, we could build a production plan that includes information about what’s needed to produce each substance. We don’t want to make a production plan for clarified water unless we need to—it’s a lot of computing resources when you’re running your programs on a hamster-powered auto-abacus.
With dependency networks, there are two main errors that can come up. The most serious error is a missed prerequisite—something we ought to have built but didn’t. This is a serious error which can result in an erroneous answer; it’s also nasty because it can be hard to spot—everything looks like it works correctly but the data is all wrong because we didn’t get a prerequisite. The other error is an unnecessary build, such as calculating the production plan for clarified water twice. In most cases, this only results in a slower execution, as the tasks are often idempotent. It can cause more serious errors if they aren’t.
A common feature of a Dependency Network, particularly the product-oriented case, is that each product keeps a track of when it was last updated. This can further help to reduce unnecessary builds. When we request a product to be built, it only actually executes the process if the output product’s last-modified date is earlier than any of the prerequisites. For this to work, the prerequisites need to be invoked first so they can rebuild if necessary.
I’m making a distinction here between invoking a task and executing it. Every transitive prerequisite is invoked, but a prerequisite is only executed if it’s necessary. So, if we invoke octopusEssence, it invokes octopus and clarifiedWater (which, in turn, invokes dessicatedGlass). Once all the invocations have finished, octopusEssence compares the last-modified dates of the clarifiedWater and octopus production plans and only executes itself if either of those prerequisites is later than octopusEssence’s production plan’s last-modified date.
In a task-oriented network, we often don’t use last-modified dates. Instead, each task keeps track of whether it’s already executed during this target request and only executes on the first invocation.
The fact that it’s easier to work with persistent last-modified dates is a strong reason to prefer the product-oriented style to the task-oriented. You can use last-modified information in a task-oriented system, but to do this, each task has to handle this responsibility itself. Using product-orientation with last-modified dates allows the network to decide on execution. This capability doesn’t come for free; it only works if the output will always be the same if none of the prerequisites change. Thus everything that could make a change to the output needs to be declared in prerequisites.
The task/product distinction surfaces in build automation systems. The traditional Unix Make command is product-oriented (the products are files), while the Java system, Ant, is task-oriented. One potential issue with product-oriented systems is that there isn’t always a natural product. Running tests is a good example of this. In this case, you need to make something like a test report that keeps track of things. Sometimes, the outputs are only there to fit in with the dependency system; a good example of such a pseudo-output is a touch file—an empty file that’s only there for its last-modified date.
49.2 When to Use It
A Dependency Network works for problems where you can divide the computation up into tasks with well-defined inputs and outputs. The ability of a Dependency Network to only execute tasks that are needed makes it suitable for resource-intensive tasks, or tasks which take an effort to get going—such as remote operations.
As with any alternative model, Dependency Network is often tricky to debug when things go wrong. It’s therefore important to log invocations and executions so you can see what’s going on. Coupled with the desire to only execute when needed, this leads me to a recommendation to prefer relatively coarse-grained tasks for the network.
49.3 Analyzing Potions (C#)
It’s not often that you see examples of the manufacturing of magical potions in software texts, so I thought it was time to shed a little light on the business challenges of such enterprises. My domain experts tell me that in the very competitive world of potion manufacture, there is regular tweaking of the recipes. This leads to a problem, as there are various analyses they need to make of the potions to maintain quality control, but these analyses are expensive and time consuming. Consequently, you cannot redo the analysis every time you make a potion; instead, you only redo it every time you change the recipe. Furthermore, every substance in the manufacturing chain can cause changes to characteristics downstream, so if I analyze an upstream substance, I need to ensure I have up-to-date analyses on all the downstream substances that use its output.
So, let’s take the example of a basic health potion. Its inputs include clarified water, which itself has an input of dessicated glass. If I need to analyze the MacGuffin Profile for a recipe of health potion, I need to see the profile for its input (the clarified water). If I’m still on the same recipe for clarified water that I used last week, then I don’t need to redo the clarified water analysis. However, if the recipe for dessicated glass has changed since I last did that analysis, then I will need to redo the work.
This is a Dependency Network. Each substance has its inputs as prerequisites for determining its profile. If any prerequisite of a substance has an out-of-date profile, we need to reanalyze its profile first, and then reanalyze the requested substance’s profile.
I’ll examine specifying this Dependency Network as an internal DSL in C#. Here is the sample script:
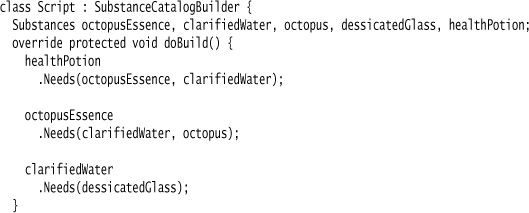
The script uses Object Scoping and Class Symbol Table. I’ll talk about parsing it later; first, let’s have a look at the Semantic Model.
49.3.1 Semantic Model
The data structure of the Semantic Model is simple: a graph structure of substances.

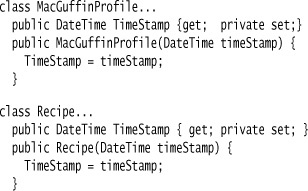
Each substance has a recipe and a MacGuffin profile. All we really need to know is that they have a date. (If I told you more, killing would only be the start of what I’d have to do to you.)
The Dependency Network behavior occurs whenever I ask for the profile. First, the invocation is passed back along with the inputs, so that every transitive input to the substance is invoked. Then, each one checks to see if it is no longer up-to-date and recalculates if necessary.

By calling invoke on its inputs before doing its own check, I ensure that each input substance is up-to-date before checking itself. If a substance appears more than once in the input chain, it will be invoked many times, but it only calculates its profile once. This is essential, since the profiling service call is expensive, particularly to the kittens.
The check for being up-to-date relies on the timestamps of profiles and recipes.

49.3.2 The Parser
The parser is a straightforward form of Class Symbol Table. Here is the script again:
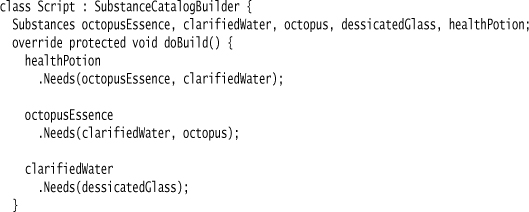
The script is contained in a class. The fields in the class are various substances. I use Object Scoping to allow the script class to make bare function calls. The parent class carries out the build, returning a list of substances.

The first step in the build is to populate the fields with instances of substance builders. The substance builders have the odd name of Substances so that the DSL reads better.
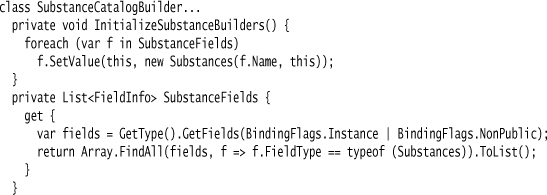
Each substance builder holds a substance and the fluent methods to populate it. In this case, the substance’s properties are read-write, so I can build up the values as I go along.