
Chapter 25. Embedded Translation
Embed output production code into the parser, so that the output is produced gradually as the parse runs.

In Syntax-Directed Translation, a pure parser merely creates an internal parse tree, so you need to do more to populate a Semantic Model.
Embedded Translation populates the Semantic Model by embedding code into the parser that populates the Semantic Model at appropriate points in the parse.
25.1 How It Works
Syntactic analyzers are all about recognizing syntactic structures. Using Embedded Translation, we place code to populate a Semantic Model into the parser, so that we gradually populate the Semantic Model as we carry out the parse. Most of the time, this implies that the model population code is placed where a clause of the input language is recognized, although in practice you may place hunks of population code at various points.
When using Embedded Translation with Parser Generators, you usually see Foreign Code incorporating the population code. Most Parser Generators provide a facility to use Foreign Code; the only one I’ve used that doesn’t is intended to work with Tree Construction.
One thing that can cause a problem with Embedded Translation is that actions with side effects can often be executed in unexpected places, depending on exactly how rules are recognized by the parsing algorithm. This isn’t an issue you get with Tree Construction since Tree Construction only produces a subtree return value. If you find yourself getting into a tangle with Embedded Translation side effects, that’s a sign that you should switch to Tree Construction.
25.2 When to Use It
The biggest appeal of Embedded Translation is that it provides a simple way to handle both syntactic analysis and model population in one pass. With Tree Construction, you both provide code to build up the AST and write a populator that walks the tree. Particularly for simple cases, which many DSLs are, this two-stage process can be more trouble than it’s worth.
The facilities of your Parser Generator have an impact on your choice. The better the tree-building features of your Parser Generator the more appealing Tree Construction becomes.
One of the biggest problems with Embedded Translation is that it can encourage complex grammar files, usually due to a poor use of Foreign Code. If you are disciplined in using Foreign Code well, this is less likely to be a problem—but a strength of Tree Construction is that it helps to enforce the discipline.
Embedded Translation fits in with a single-pass parse, as all the work is done during syntactic analysis. This means that things like forward references, which are tricky on a single pass, are also tricky with Embedded Translation. To handle them, you often need Context Variable, which can further complicate parsing.
The upshot of all this is that the simpler the language and parser, the more appealing is Embedded Translation.
25.3 Miss Grant’s Controller (Java and ANTLR)
I’ll take the same example I used for Tree Construction, with the same tools (Java and ANTLR), but this time handle the parse with Embedded Translation. First of all, this only changes the syntactic analysis—the tokenizing is the same. I won’t repeat the tokenizing discussion here; you can pop over to that section (“Tokenizing,” p. 285) if you need a refresher.
Another similarity between the two examples is the core BNF grammar. Most of the time, the BNF rules don’t vary if you use different parsing patterns; what changes is the supporting code around the BNF. While Tree Construction uses ANTLR’s facilities for declaring ASTs, Embedded Translation uses Foreign Code to put in Java snippets to populate the Semantic Model directly.
Embedded Translation involves putting arbitrary general-purpose code into a grammar file. As in most cases where embedding one language into another is necessary, I like to use an Embedment Helper. I’ve read many grammar files and I find that this pattern helps keep the grammar clear—it isn’t buried in the translation code. I do this by declaring a helper in my grammar.

The top level of the grammar defines the state machine file.
machine : eventList resetEventList commandList state*;
It shows the same sequence of declarations.
To see some real translation going on, let’s look at the handling for the event list:
eventList : 'events' event* 'end';
event : name=ID code=ID {helper.addEvent($name, $code);};
Here we see the typical nature of using Embedded Translation. Much of the grammar file remains plain, but at appropriate points we introduce general-purpose code to perform the translation. Since I’m using an Embedment Helper, all I do is call a single method on that helper.

The call creates a new event object and places it in the symbol table, which is a collection of dictionaries on the loader. The call to the helper passes in the tokens for the name and code. ANTLR uses assignment syntax to mark elements of the grammar so the embedded code can refer to them. The placement of the embedded code indicates when it runs—in this case, the embedded code is run after both child nodes have been recognized.
The commands are done in exactly the same way. The states, however, introduce a couple of interesting issues: hierarchic context and forward references.
I’ll start with hierarchic context. The issue here is that the various elements of a state—actions and transitions—occur within the state definition, so when we want to process an action we need to know in which state it is declared.
Earlier on, I drew an analogy to Embedded Translation being rather like processing XML with SAX. This is somewhat true, in that the embedded code just works with one rule at a time. But it’s also misleading, because Parser Generators can give you much more context during the execution of the code so you don’t need to keep it around yourself so much.
In ANTLR, you can pass parameters into rules in order to push down this kind of context.
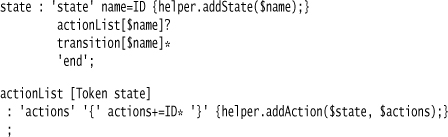
Here the state token is passed into the rule for recognizing an action. This way the embedded translation code can pass in both the state token and the command tokens (the “*” indicates they are a list). This provides the right context for the helper.
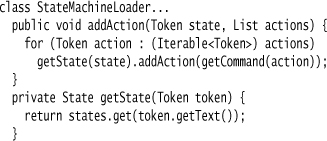
The second issue is that the transition declarations involve forward references to states that haven’t been declared yet. In many DSLs, you can arrange things so that no item refers to an identifier that hasn’t yet been declared, but the state model can’t do this, resulting in forward references. Tree Construction allows us to process the AST in multiple passes, so we can make one pass to pick up the declarations and another pass to populate the states. With multiple passes, forward references aren’t a problem since they are resolved on later passes through the AST. With Embedded Translation, we don’t have that option.
Our solution here is to use an “obtain” (the term I use for find-or-create) operation on both the references and declarations. Essentially, this means that whenever we mention a state, we implicitly declare it if it doesn’t already exist.

One of the consequences of this approach is that if we misspell a state in our transition, we will just get a blank state as the transition target. If we’re happy with that, we can leave it. It’s common, however, to check declarations against usage, in which case we need to keep track of the states created by use and ensure that they are all declared too.
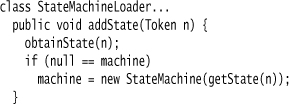
Our language defines the start state as the first state mentioned in the program. This kind of context isn’t handled by the Parser Generator particularly well, so we need to resort to what is effectively a context variable.
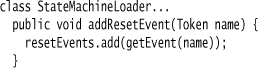
Handling the reset events is pretty trivial—we just add them to a separate list.

The single-pass nature of the parser also complicates reset events: They can be defined before we get the first state, and thus before we have a machine to put them on. So I keep them in a field to add them at the end.
The run method of the loader shows the overall sequence of tasks: lexing, running the generated parser, and finishing the model population with the reset events.

It’s not unusual to have code like this following the syntactic analysis—this is also where any semantic analysis would happen.