
Chapter 19. BNF
Formally define the syntax of a programming language.

19.1 How It Works
BNF (and EBNF) is a way of writing grammars to define the syntax of a language. BNF (or Backus-Naur Form, to give it its full name) was invented to describe the Algol language in the 60s. Since then, BNF grammars have been widely used both for explanation and to drive Syntax-Directed Translation.
You’ve almost certainly come across BNF when learning about a new language—or rather, you’ve sort-of come across it. In a wonderful display of irony, BNF, a language for defining syntax, does not itself have a standard syntax. Pretty much any time you run into a BNF grammar, it will have both obvious and subtle differences from any other BNF grammars you’ve seen before. As a result, it’s not really fair to call BNF a language; rather, I think of it as a family of languages. When people talk about patterns, they say that with a pattern, you see it differently every time—BNF is very much like that.
Despite the fact that both syntax and semantics of BNF varies so much, there are common elements. The primary commonality is the notion of describing a language through a sequence of production rules. As an example, consider contacts like this:

A grammar for this might look something like this:
![]()
Here the grammar consists of two production rules. Each production rule has a name and a body. The body describes how you can decompose the rule into a sequence of elements. These elements may be other rules or terminals. A terminal is something that isn’t another rule, such as the literals contact and }. If you’re using a BNF grammar with Syntax-Directed Translation, your terminals will usually be the token types that come out of the lexer. (I haven’t decomposed the rules any further. Email addresses, in particular, can get surprisingly complicated [RFC 5322].)
I mentioned earlier that BNF appears in lots of syntactic forms. The one above is that used by the ANTLR Parser Generator. Here’s the same grammar in a form much closer to the original Algol BNF:
![]()
In this case, the rules are quoted in angle brackets, the literal text is unquoted, rules are terminated with a newline rather than a semicolon, and “::=” is used as the separator between the rule’s name and its body. You’ll see all of these elements varied in different BNFs, so don’t get hung up on the syntax. In this book, I generally use the BNF syntax used by ANTLR, since I also use ANTLR for any examples that involve Parser Generators. Parser Generators typically use this style, rather than the Algol style.
Now I’ll extend the problem by considering contacts that can have either an email address or a telephone number. So, in addition to my original example, we might also get:
contact rparsons {
tel: 312-373-1000
}
I can extend my grammar to recognize this by using an alternative.
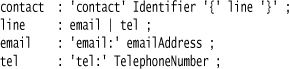
The alternative here is the | in the line rule. It says that I can decompose the line into either email or tel.
One more thing I’ll do is extract the identifier into a username rule.
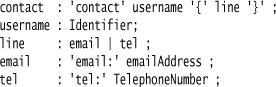
The username rule only resolves to a single identifier, but it’s worth doing to more clearly show the intent of the grammar—similarly to extracting a simple method in imperative code.
The use of the alternative is pretty limited in this context; it only allows me to have one email or one telephone. As it turns out, alternatives actually unleash an enormous amount of expressive power, but rather than explore that, I’ll move on to multiplicity symbols next.
19.1.1 Multiplicity Symbols (Kleene Operators)
A serious contact management application wouldn’t give me only one email or telephone as a point of contact. While I won’t go too close to what a real contact management application should provide, I will take a step closer. I’ll say a contact must have a user name, may have a full name, must have at least one email address, and may have some telephone numbers. Here’s a grammar for that:
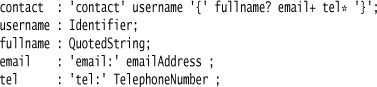
You’ll probably recognize the multiplicity symbols as those used in regular expressions (they are often called Kleene operators). Using multiplicity symbols like this makes it much easier to understand grammars.
When you see multiplicity symbols, you’ll also often see a grouping construct that allows you to combine several elements to apply a multiplicity rule. So I could write the above grammar like this, inlining the subrules:

I wouldn’t suggest doing this, because the subrules capture intent and make the grammar much more readable. But there are occasions where a subrule adds clutter and grouping operators work out better.
This example also shows how longer BNF rules are usually formatted. Most BNFs ignore line endings, so putting each logical piece of the rule on its own line can make a complicated rule clearer. In this case, it’s usually easier to put the semicolon on its own line to mark the end. This is the kind of format I’ve seen most often, and I do prefer this style once the rule becomes too complicated to fit easily on a single line.
Adding multiplicity symbols is usually what makes the difference between EBNF (extended BNF) and basic BNF. However, the terminology here has its usual muddle. When people say “BNF” they may mean basic BNF (i.e., not EBNF) or something more broadly BNFish (including EBNF). In this book, when I refer to a BNF without multiplicity symbols, I’ll say “basic BNF”; when I say “BNF” I’m including any BNF-like language, including EBNF-like languages.
The multiplicity symbols I’ve shown here are the most common ones you’re likely to see, certainly with Parser Generators. However, there’s another form that uses brackets instead:
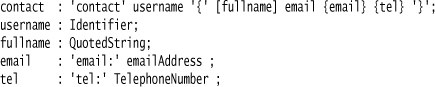
The brackets replace ? with [..] and * with {..}. There’s no replacement for +, so you replace foo+ with foo {foo}. This bracketing style is quite common in grammars intended for human consumption, and it is the style used in the ISO standard for EBNF (ISO/IEC 14977); however, most Parser Generators prefer the regexp form. I’ll use the regexp form in my examples.
19.1.2 Some Other Useful Operators
There are a few other operators that I should mention, as I use them in examples in this book and you’ll probably run into them elsewhere.
Since I use ANTLR a lot in the this book for my grammars, I use the ~ operator of ANTLR, which I refer to as the up-to operator. The up-to operator matches everything up to the element following the ~. So if you want to match all characters up to but not including a close brace, you can use the pattern ~'}'. If you don’t have this operator, the equivalent regular expression is something like [^}]*.
Most approaches to Syntax-Directed Translation separate lexical analysis from syntactic analysis. You can define lexical analysis in a production-rule style too, but there are usually subtle but important differences as to what kinds of operators and combinations are allowed. Lexical rules are more likely to be close to regular expressions, if only because regular expressions are often used for lexical analysis since they use a finite-state machine rather than a parser’s pushdown machine (see “Regular, Context-Free, and Context-Sensitive Grammars,” p. 96).
An important operator in lexical analysis is the range operator “..” used to identify a range of characters, such as lower-case letters 'a'..'z'. A common rule for identifiers is:

This allows identifiers that start with a lowercase or uppercase letter, followed by letters, numbers, or underscores. Ranges only make sense in lexical rules, not syntactic rules. They are traditionally also rather ASCII-centric, which makes it difficult to support identifiers in languages other than English.
19.1.3 Parsing Expression Grammars
Most BNF grammars you’ll run into are context-free grammars (CFG). However, there’s a recent style of grammar called a parsing expression grammar (PEG). The biggest difference between a PEG and a CFG is that PEGs have ordered alternatives. In a CFG, you write:
contact : email | tel;
which means that a contact can be an email or a telephone number. The order in which you write the two alternatives doesn’t affect the interpretation. In most cases, this is fine, but occasionally having unordered alternatives leads to ambiguities.
Consider a case where you want to recognize an appropriate sequence of ten digits as a US telephone number, but want to capture other sequences as just an unstructured telephone number. You could try a grammar like this:

But this grammar is ambiguous when it gets input like “312–373 1000”, because both the us_number and raw_number rules can match it. An ordered alternative forces the rules to be tried in order and whichever rule matches first is the one that’s used. A common syntax for an ordered alternative is /, so the tel rule would then read:
tel: us_number / raw_number ;
(I should mention that although ANTLR uses unordered alternatives, they act more like ordered ones. For this kind of ambiguity, ANTLR will report a warning and go with the first alternative that matches.)
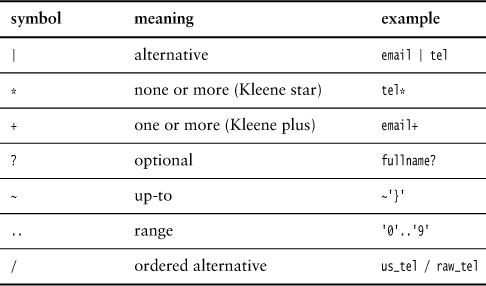
19.1.4 Converting EBNF to Basic BNF
The multiplicity symbols make BNF much easier to follow. However, they don’t increase the expressive power of BNF. An EBNF grammar using multiplicity symbols can be replaced with an equivalent basic BNF grammar. From time to time, this is important because some Parser Generators use basic BNF for their grammar.
I’ll use the contact grammar as an example. Here it is again:
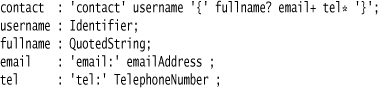
The key to the transformation is using alternatives. So, starting with the optional part, I can replace any foo? ; with foo | ; (that is, foo or nothing).
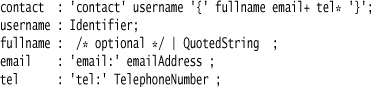
You’ll notice that I’ve added a comment to make it clearer what I’m doing. Different tools use different comment syntaxes, of course, but I’ll follow the C convention here. I don’t like to use comments if I can replace them with something in the language I’m using, but if I can’t, I use them without hesitation—as in this case.
If the parent clause is simple, you can fold the alternative into the parent. So a : b? c would transform to a: c | b c. If you have several optional elements, however, you get into a combinatorial explosion, which, like most explosions, isn’t something that’s fun to be in the middle of.
To transform repetition, again the trick is to use alternatives, in this case with recursion. It’s quite common for rules to be recursive—that is, to use the rule itself in its body. With this, you can replace x : y*; with x : y x |;. Using this on the telephone number, we get:
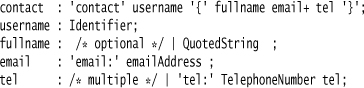
This is the basic way of handling recursion. To do a recursive algorithm, you need to consider two cases: the terminal case and the next case, where the next case includes the recursive call. In this situation, we have an alternative for each case: the terminal case is nothing, and the next case adds one element.
When you introduce a recursive case like this, you often have the choice of whether to do the recursion on the left or on the right—that is, to replace x : y*; with x : y x | or with x : x y |. Usually your parser will tell you to prefer one over the other due to the algorithm it’s using. For example, a top-down parser cannot do left recursion at all, while Yacc can do either but prefers right recursion.
The last multiplicity marker is +. This is similar to * but the terminal case is a single item rather than none, so we can replace x : y+ with x : y | x y (or x: y | y x to avoid left recursion). Doing this to the contact example yields:
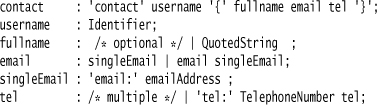
Since the single email expression is used twice in the email rule, I’ve extracted it into its own rule. Introducing intermediate rules like this is often necessary in transforming to basic BNF; you also have to do this if you have groups.
I now have the contact grammar in basic BNF. It works just fine, but the grammar is much harder to follow. Not only do I lose the multiplicity markers, I also have to introduce extra subrules just to make the recursion work properly. As a result, I always prefer to use EBNF if all else is equal, but I still have this technique for the occasions when basic BNF is necessary.

19.1.5 Code Actions
BNF provides a way of defining the syntactic structure of a language, and Parser Generators typically use BNF to drive the operation of a parser. BNF, however, isn’t enough. It provides enough information to generate a parse tree, but not enough to come up with a more useful abstract syntax tree, nor to do further tasks like Embedded Translation or Embedded Interpretation. So the common approach is to place code actions into the BNF in order for the code to react.
Not all Parser Generators use code actions. Another approach is to provide a separate DSL for something like Tree Construction.
The basic idea behind code actions is to place snippets of Foreign Code in certain places in the grammar. These snippets are executed when that part of the grammar is recognized by the parser. Consider this grammar:
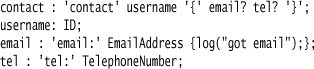
In this case, the message is logged once an email clause is recognized in the parse. A mechanism like this could be used to keep track of when we run into emails. The code in a code action can do anything, so we can also add information to data structures.
Code actions often need to refer to elements that are recognized in the parse. It’s nice to log the fact that an email was found, but we might also want to record the email address. To do this, we need to refer to the email address token as we parse it. Different Parser Generators have different ways of doing this. Classic Yacc refers to the tokens by special variables that index the position of the element. So we would refer to the email address token with $2 ($1 would refer to the token email:). Positional references are brittle to changes in the grammar, so a more common approach in modern Parser Generators is to label the elements. Here, this is done ANTLR’s way:

In ANTLR, a reference to $e refers to the element labeled by e= in the grammar. Since this element is a token, I use the text attribute to get the matched text. (I could also get hold of things like the token type, line number, etc.)
In order to resolve these references, Parser Generators run code actions through a templating system, which replaces expressions like $e with the suitable values. ANTLR, in fact, goes further. Attributes like text don’t refer to fields or methods directly—ANTLR performs further substitution to get hold of the right information.
Similarly to referring to a token, I can also refer to a rule.

Here the log will record the full text matched by the email rule ("email: [email protected]"). Often, returning some rule object like this isn’t too helpful, particularly when we are matching larger rules. As a result, Parser Generators usually give you the ability to define what is returned by a rule when it’s matched. In ANTLR, I do this by defining a return type and variable for a rule and then returning it.

You can return anything you like from a rule and then refer to that in the parent. (ANTLR allows you to define multiple return values.) This facility, combined with code actions, is extremely important. Often, the rule that gives you the best information about a value isn’t the best rule to decide what to do with that data. Passing data up the rule stack allows you to capture information at a low level in a parse, and deal with it at a higher level. Without this, you would have to use a lot of Context Variables—which would soon get very messy.
Code actions can be used in all three styles of Embedded Interpretation, Embedded Translation, and Tree Construction. The particular style of code in Tree Construction, however, lends itself to a different approach that uses another DSL (“Using ANTLR’s Tree Construction Syntax (Java and ANTLR),” p. 284) to describe how to form the resulting syntax tree.
The position of a code action in a grammar determines when it’s executed. So, parent : first {log("hello");} second would cause the log method to be called after the first subrule was recognized but before the second. Most of the time it’s easiest to put code actions at the end of a rule, but occasionally you need to put them in the middle. From time to time, the sequence of execution of code actions can be hard to understand, because it depends on the algorithm of the parser. Recursive-descent parsers are usually pretty easy to follow, but bottom-up parsers often cause confusion. You may need to look at the details of your parser system to understand exactly when code actions get executed.
One of the dangers of code actions is that you can end up putting a lot of code in them. If you do this, the grammar becomes hard to see, and you lose most of the documentation advantage it brings. I thus strongly recommend that you use Embedment Helper when using code actions.
19.2 When to Use It
You’ll need to use BNF whenever you are working with a Parser Generator, as these tools use BNF grammars to define how to parse. It’s also very useful as an informal thinking tool to help visualize the structure of your DSL, or to communicate the syntactic rules of your language to other humans.