
Chapter 43. Parse Tree Manipulation
Capture the parse tree of a code fragment to manipulate it with DSL processing code.
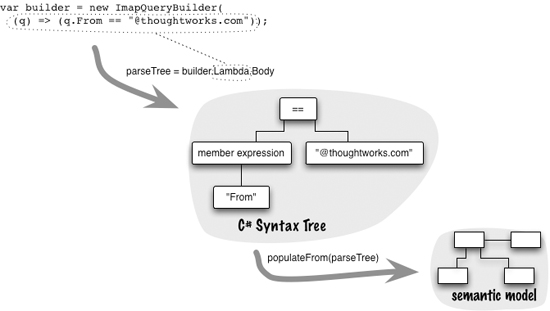
When you write code in a closure, that code is available to be executed at some future time. Parse Tree Manipulation allows you to not only execute the code but also examine and modify its parse tree.
43.1 How It Works
In order to use Parse Tree Manipulation, you need a programming environment that supports taking a code fragment and turning it into a parse tree that you can work with. This is a relatively rare programming language feature—rare both in that few languages support it and in that, even when it is supported, it’s rarely used. While I have not made any detailed survey of tools that support this, I can use the ones I have to give a rough picture of how one might use this kind of capability. The three examples I’ll talk about are C# (from version 3.0), Ruby’s ParseTree library, and Lisp.
C# and ParseTree operate in a similar way. You invoke a library call on a fragment of source code, and the library returns a data structure of that code’s parse tree. In C#, you can only do this on an expression inside a lambda. This limitation to expressions means you can’t take code with multiple statements. ParseTree allows you to take a class, a method, or a string containing Ruby code.
In C#, the returned data structure is a hierarchy of expression objects. These objects are purpose-built for representing parse trees, with an inheritance hierarchy for different kinds of operators. ParseTree returns nested Ruby arrays, with simple built-in types, such as symbols and strings, as leaves.
In both C# and Ruby, you then write a tree walker to walk the parse tree and examine it. In C#, the parse tree is immutable, but you can transform it by copying and modifying it as you copy. Both libraries provide a mechanism for taking a subtree and turning it back into executable code.
The approach Lisp takes is rather different. Lisp source is itself essentially a serialized parse tree of nested lists. Lisp provides syntactic macros that allow you to examine and manipulate any Lisp expression. The programming style is different, as it uses macros, but you can achieve much the same effects.
Although Parse Tree Manipulation allows you write an expression in your host language, you usually can’t use any expression you like. There are usually limits on what you can handle in expressions. In these situations, it’s important to fail fast should you get an expression that you can’t handle. Usually, when you walk over a parse tree, you know that the nodes in that tree will conform to what you expect. With Parse Tree Manipulation, your parse tree can contain any legal construct in the host language, so you have to do some checking yourself as you walk it.
Usually you won’t need, or want, to walk the entire parse tree of the expression. Most cases involve walking some parts of the tree, but leaving substantial subtrees for evaluation. That way you don’t have to build an entire parser, but only parse the bits you need to populate your Semantic Model, and evaluate subtrees as soon as you don’t need to do further navigation.
43.2 When to Use It
Parse Tree Manipulation allows you to express logic in your host programming language and then manipulate that expression with more flexibility than you would be able to get otherwise. With that, a driving reason to use Parse Tree Manipulation with a DSL is the desire to use a fuller range of the host language’s features to express something, instead of the pidgin of the usual internal DSL constructs.
Being able to make use of the host language isn’t the whole point of using Parse Tree Manipulation. After all, one of the advantages of internal DSLs is that you can intermix the full host language with DSLish constructs as much as you like. The key difference is that usually, you can only manipulate the executable results of the host language—you can’t dive into host language expressions and manipulate their structure.
Even so, there’s not that many examples when you need to use Parse Tree Manipulation for a DSL. (Like most things, Parse Tree Manipulation has many uses outside a DSL context, which I’m not going to touch on here.) One of the best ones to consider is the driving force behind .NET’s support for Parse Tree Manipulation—Linq.
Linq allows you to express query conditions—essentially Boolean expressions—using the standard .NET languages. These conditions can then be evaluated on .NET data structures—that much is trivial. The interesting thing is to take a C# condition and turn it into a SQL query—this allows you to write database queries without knowing SQL, or to write queries that will be executed against different data sources. In order to pull this off, you need to take the C# condition, turn it into a parse tree, and then walk the parse tree and generate the equivalent SQL. Essentially, you are doing source-to-source translation from C# to SQL (or some other target). Parse Tree Manipulation is good for these cases, as it allows you to use a familiar syntax for your conditions when your target language is not well known or you want multiple targets.
Another way to use Parse Tree Manipulation is to change the parse tree to carry out a useful manipulation. One example is changing all method calls on a certain object to be redirected to another object. But it’s not clear how useful that kind of surgery is in a DSL context (which is the focus of this book).
I also worry a bit that Parse Tree Manipulation is one of those techniques where the intricacies of doing it may be just too appealing for many programmers. It’s an appeal that can blindside people into missing other, simpler, ways of achieving the same goal.
43.3 Generating IMAP Queries from C# Conditions (C#)
Some of you may be familiar with the IMAP protocol for interacting with email servers. If you use IMAP, your email stays on the server and is brought down to the client only for reading or caching. As a result, if you want to search your email, that search needs to be done on the server.
To search with IMAP, your email client sends a search request. That search request is, like all IMAP commands, a string. There is a DSL that is used to express the IMAP search conditions. I won’t go into all the details here (if you want them, go to [RFC 3501]) but will just show a simple example. Let’s say I want to find all emails containing the phrase “entity framework,” sent by someone other than at thoughtworks.com, since 23rd of June 2008. Using IMAP, I would encode this query in a search command as SEARCH subject "entity framework" sentsince 23-jun-2008 not from "@thoughtworks.com".
IMAP’s search command DSL provides a good domain-specific query language for email. For this exercise, however, we want to express our query in C#, like this:

43.3.1 Semantic Model
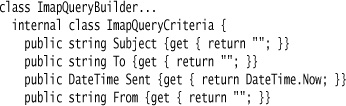
My first step is to create a Semantic Model for the IMAP output. This is a simple IMAP query object that contains elements for each clause in the query. These elements will be anded together to form the complete query.

I’m declaring an interface here for the query elements. This interface has two implementations: one to handle the basic query clauses (from "@thoughtworks.com") and the other to handle negations (not).

Although this query is a conjunction, IMAP can express general Boolean expressions. Doing so is more awkward, but then most email queries can be handled very nicely as a conjunction. This is where IMAP makes the common case easy, but allows you to be more expressive in the relatively rare situations that need it. For my purposes of illustrating this pattern, a simple conjunction will do fine.
Each basic query element has a keyword and value, mirroring the way IMAP forms its search language. In this situation, I’m adding some error checking into each element, throwing an exception should any of them be in error.

With this command-query interface, I can construct the model for my query like this:

With a Semantic Model in place, I can now generate the code for the IMAP search command. This is very simple code generation—just pushing out the result for each IMAP element.

43.3.2 Building from C#
This Semantic Model allows me to represent and generate search commands for IMAP queries (or at least for the subset of IMAP queries I’m using here). Now, let’s look at the builder to create them from C#.
The builder takes an appropriate lambda in its constructor.

In order to write the expression in the closure, we need some object that can act as the receiver for the keywords of the query (subject, sent, from). This object won’t ever do anything at runtime; it’s only there to provide the methods to help me compose the query. As a result, the return values of its methods are irrelevant as they’ll never actually be called.
To build the query, I use a lazily evaluated property.

The heart of the work is done by populateFrom—a recursive tree walk.

At this point, I confront the fact that, despite my desire to allow clients to construct IMAP queries in C#, they can’t use any C#. My Semantic Model can only handle a subset of possible C# expressions. The expression must consist of one or more element expressions connected by the && operator. Each of these element nodes must be a particular binary operator for which one side must be a keyword—a call to an IMAP query criteria object. There are then rules about what operators go with which keywords. String-oriented keywords (from, subject, to) can only take == and !=. Date-oriented keywords (sent, date) can take any equality or comparison operators.
As a result, I know that the only elements I’ll have to navigate through are binary expressions, so populateFrom throws an exception if it sees anything else. If the operator in the expression is && I can just recurse to the children. The interesting case is the element node—and there’s enough logic there that I’ve put it into a separate class.

These element nodes have two children: One is a keyword node (e.g., q.To) and one is some arbitrary C# that will return the value that will be compared in the query. I’m allowing the keyword and value to appear in any order, since that commutativity is expected in the host language.
To be a keyword, the child must have a method call on an instance of my criteria object. I’ll need to be able to extract that keyword from the child node, so I write a method that takes a child node and returns the keyword if it’s a keyword expression, or null if it’s not.

This utility method is very useful. Its first use is to allow me to check that I actually have a valid element node to work on. For this, I need to ensure that one of the children is indeed a keyword node.

Not only do I check that one of the children is a keyword node, I also need to check that I have a legal operator for the kind of keyword I have.

You might notice here that I’m doing a bit more checking for date keywords. For string keywords, I’m relying on the Semantic Model to tell me if I try to create an element with an illegal keyword. I have to handle the date keywords differently since there is a mismatch between the C# expression and the Semantic Model. If I want to find emails sent since a certain date, the natural way to say this in C# is something like q.Sent >= aDate; however, IMAP does this with sentsince aDate. Essentially, I need the combination of the C# keyword plus the operator to determine the correct IMAP keyword. As a consequence, I have to check the C# date keywords in the builder as they are part of the input DSL but not the Semantic Model.
By checking that I have a valid node in the constructor, I can simplify my later logic to extract the right data from the node.
Now let’s look at exactly that. I begin with a content property which separates the simple string case from the more complicated date case.

For the string case, I create a basic query element using whatever the keyword is and the value from the other side of the node. If the operator is !=, I wrap that basic element inside a negation.

To determine the value, I don’t need to parse the value node. Instead I can just toss the expression back to the C# system to get it. This allows me to put any legal C# into the value side of my elements without having to deal with it in my navigation code.

Dates are more complicated, but I use the same basic approach. The IMAP keyword I’ll need depends on both the keyword method in the node and the value of the operator. In addition, I need to throw in negations when I need to. As the first step, I’ll tease out the keyword method.
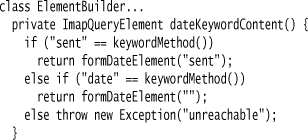
With the right date keyword sorted out, I’ll then break things out by the operator type.

Notice that I’m taking advantage of the similar names of the date-oriented IMAP keywords that I deal with. My first code for this had separate switch statements for each keyword, but I realized that by doing the prefix trick I could remove the duplication. The code’s a little cleverer than I like, but I think it’s worth that to avoid duplication.
43.3.3 Stepping Back
That sums up the implementation of IMAP search, but I need to mention a couple more things before I leave this example.
The first point is a difference between how I’ve described the example and how I built it. In describing the example, I found it easier to look at each part of the implementation separately: populating the Semantic Model with a command-query interface, generating the IMAP code, walking through the parse tree. I think looking at each aspect separately makes it easier to understand—which is also why the code is separated that way.
However, I didn’t actually build it that way. I did the example in two stages; first, I just supported simple conjunctions of basic elements, and then I added the ability to handle negations. I wrote the code for all elements on the first pass and then extended and refactored each section when adding the negations. I always advocate building software like this, feature by feature, but I don’t think that’s the best way to explain the final result. So don’t let the structure of the final result and the way I explain it fool you into thinking that it is how it’s built.
The second point I want to share is that although walking a parse tree like this yields that geeky pleasure of using fancy parts of a language, I wouldn’t actually build an IMAP DSL this way. An alternative is a dose of simple Method Chaining.

Here’s all the implementation I need to do this:

It’s not utterly trivial—including the negation makes me use a messy Context Variable—but it’s still small and simple. I’d need to add methods to support more keywords, but they would still be simple.
Of course, one of the main reasons this is so much simpler is that the structure of the internal DSL is more similar to the IMAP query itself. In fact, it’s really just the IMAP query expressed as Method Chaining. Its advantage over using IMAP itself boils down to IDE support. Some people might prefer the more C#ish syntax that the Parse Tree Manipulation example gives you, but I must admit I’m happier with the IMAPish version.