
Chapter 17. Delimiter-Directed Translation
Translate source text by breaking it up into chunks (usually lines) and then parsing each chunk.
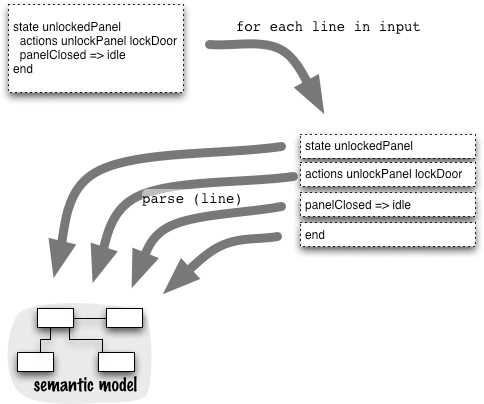
17.1 How It Works
Delimiter-Directed Translation works by taking the input and breaking it down into smaller chunks based on some kind of delimiter character. You can use any delimiter characters you like, but the most common first delimiter is the line ending, so I’ll use that for my discussion.
Breaking up the script into lines is usually pretty simple, as most programming environments have library functions that will read an input stream a line at a time. One complication you may run into is if you have long lines and want to break them up physically in your editor. In many environments, the simplest way to do this is to quote the line ending character; in Unix this means using backslash as the last character on a line.
Quoting the line ending looks ugly, however, and is vulnerable to whitespace between the quote and the end of line. As a result, it’s often better to use a line continuation character. To do this, you choose some character that, if it’s the last non-whitespace character on a line, indicates that the next line is really the same line. When you read in the input, you have to look for the line continuation character and if you see it, patch the next line onto the line you’ve just read. When you do this, remember you may get more than one continuation line.
How you process the lines depends on the nature of the language you’re dealing with. The simplest case is where each line is autonomous and of the same form. Consider a simple list of rules for allocating frequent sleeper points for hotel stays.
score 300 for 3 nights at Bree
score 200 for 2 nights at Dol Amroth
score 150 for 2 nights at Orthanc
I call the lines here autonomous since none of them affect the other ones. I could safely reorder and remove the lines without changing the interpretation of any line. They’re of the same form because each one encodes the same kind of information. Processing the lines is therefore quite simple; I run the same line processing function against each one, this function picks out the information I need (the points to score, the nights stayed, and the hotel name) and translates it into the representation that I want. If I’m using Embedded Translation, that means putting it into the Semantic Model. If I were using Tree Construction, that would mean creating an abstract syntax tree. I rarely see Tree Construction with Delimiter-Directed Translation, so for my discussion here I’m going to assume Embedded Translation (Embedded Interpretation is also quite common).
How to pick out the information you want depends on the string processing capabilities you have in your language and on the complexity of the line you have. If possible, the easiest way to decompose the input is to use a string splitter function. Most string libraries have such a function that splits a string into elements separated by a delimiter string. In this case, you can split with a whitespace delimiter and extract, for example, the score as the second element.
Sometimes a string won’t split cleanly like this. Often, the best approach is to use a regular expression. You can use groups in the regular expression to extract the bits of the string you need. A regular expression gives you much more expressive power than a string split; it is also a good way to check that the line is syntactically correct. Regular expressions are more complicated, and many people find them awkward to follow. It often helps to break a large regular expression into subexpressions, define each subexpression separately, and combine them (a technique I call a composed regex).
Now, let’s consider lines of different forms. This might be a DSL that describes the contents section of a home page for a local newspaper.

In this case, each line is autonomous but needs to be processed differently. I can handle this with a conditional expression that checks for the various kinds of lines and calls the appropriate processing routine.

The condition checks can use regular expression or other string operations. There’s an argument for showing the regular expression in the conditional directly, but I usually prefer using methods.
Apart from purely isomorphic and polymorphic lines, you can get a hybrid where each line has the same broad structure that divides it into clauses, but each clause has different forms. Here’s another version of hotel reward points:

Here we have a broad isomorphic structure. There is always a rewards clause, followed by for, followed by an activity clause, followed by at, followed by a location clause. I can respond to this by having a single top-level processing routine that identifies the three clauses and calls a single processing routine for each clause. The clause processing routines then follow the polymorphic pattern of using a conditional of tests and different processing routines.
I can relate this to grammars used in Syntax-Directed Translation. Polymorphic lines and clauses are handled in grammars by alternatives, while isomorphic lines are handled by production rules without alternatives. Using methods to break down lines into clauses is just like using subrules.
Handling nonautonomous statements with Delimiter-Directed Translation introduces a further complication, since we now have to keep track of some state information about the parse. An example of this is my introductory state machine where I have separate sections for events, commands, and states. The line unlockPanel PNUL should be handled differently in the events section than in the commands section, even though it has the same syntactic form. It also is an error for a line of this form to show up inside a state definition.
A good way to handle this is to have a family of different parsers for each state of the parse. So the state machine parser would have a top-level line parser, and further line parsers for a command block, event block, reset event block, and state block. When the top-level line parser sees the events keyword, it switches the current line parser over to an event line parser. This, of course, is just an application of the State [GoF] design pattern.
A common area that can get awkward with Delimiter-Directed Translation is handling whitespace, particularly around operators. If you have a line of the form property = value, you have to decide whether the whitespace around the = is optional or not. Making it optional may complicate line processing, but making it mandatory (or not allowing it at all) will make the DSL harder to use. Whitespace can get even worse if there is a distinction between one and multiple whitespace characters, or between different whitespace characters such as tabs and spaces.
There is a certain regularity to this kind of processing. There is a recurring programming idea of checking to see if a string matches a certain pattern, then invoking a processing rule for that pattern. Such commonality naturally raises the thought that this would be amenable to a framework. You could have a series of objects, each of which has a regex for the kind of line it processes and some code to do the processing. You then run through all these objects in turn. You can also add some indication of the overall state of the parser. To make it easier to configure this framework, you can add a DSL on top.
Of course I’m not the first person to think of that. Indeed that style of processing is exactly that used by lexer generators such as those inspired by Lex. There is something to be said for using these kinds of tools, but there’s also another consideration. Once you’ve got far enough into this to want to use a framework, then the jump to Syntax-Directed Translation is not much further, and you have a wider range of more powerful tools to work with.
17.2 When to Use It
The great strength of Delimiter-Directed Translation is that it is a technique that is very simple for people to use. Its main alternative, Syntax-Directed Translation, requires you to mount a learning curve to understand how to work with grammars. Delimiter-Directed Translation relies purely on techniques that most programmers are familiar with and thus easy to approach.
As is often the case, the downside of this approachability is the difficulty of handling more complex languages. Delimiter-Directed Translation works very well with simple languages, particularly those which don’t require much nested context. As complexity increases, Delimiter-Directed Translation can get messy quickly, particularly since it takes thought to keep the design of the parser clean.
As a result, I only tend to favor Delimiter-Directed Translation when you have simple autonomous statements, or maybe just a single nested context. Even then I’d prefer to use Syntax-Directed Translation unless I’m working with a team that I didn’t think is prepared to deal with learning that technique.
17.3 Frequent Customer Points (C#)
If you’ve had the misfortune to be a jet-setting consultant like myself, you’ll be familiar with the various incentives that travel companies dole out to try to reward you for traveling too much with opportunities to travel even more. Let’s imagine a set of rules for a hotel chain expressed as a DSL like this:

17.3.1 Semantic Model
Figure 17.1 Class diagram of semantic model
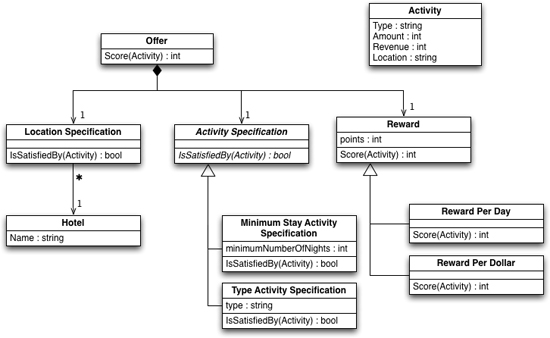
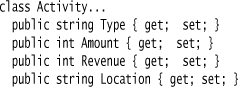
Each line in the script defines a single offer. The main responsibility of an offer is to score the frequent customer points for an activity. The activity is a simple data representation.
The offer has three components. A location Specification [Evans DDD] checks to see if an activity is in the right place to score for this offer; an activity specification checks to see if the activity merits reward points. If both of these specifications are satisfied, then the reward object calculates the score.
The simplest of these three components is the location specification. It just checks the hotel name against a list of stored hotels.

I need two kinds of activity specifications here. One checks that activity is a stay of more than the stated amount of nights.

The second checks to see if the activity is of the right kind.

The reward classes score the rewards according to the different bases.

17.3.2 The Parser
The basic structure of the parser is to read each line of the input and work on that line.
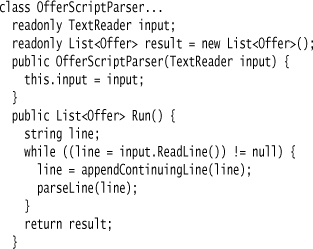
For this example, I want to support “&” as a continuation character. A simple recursive function makes this work.

This will turn all continuing lines into one line.
For parsing the line, I begin by stripping out comments and ignoring blank lines. With that done, I begin the proper parsing, for which I delegate to a fresh object.

I’ve used a Method Object [Beck IP] to parse each line here, since I think the rest of the parsing behavior is sufficiently complicated that I’d prefer to see it broken out. The method object is stateless, so I could reuse the instance, but I prefer to create a fresh one each time unless there’s a good reason not to.
The base parse method breaks the line down into clauses and then calls separate parse methods on each clause. (I could try to do everything in one big regular expression, but I get vertigo thinking of the resulting code.)

This is a rather long method by my standards. I thought of trying to break it up, but the core behavior of the method is to divide the regular expression into groups and then map the results of parsing the groups into the output. There’s a strong semantic linkage between the definition and the use of these groups, so I felt it was better to have the longer method rather than try to decompose it. Since the crux of this method is the regular expression, I’ve put the assembly of the regular expression on its own line to draw the eye there.
I could have done all this with a single regular expression instead of the separate regular expressions (rewardRegexp, activityRegexp, locationRegexp). Whenever I run into a complicated regexp like this, I like to break it up into simpler regular expressions that I can compose together—a technique I call a composed regex [Fowler-regex]. I find this makes it much easier to understand what’s going on.
With everything broken into chunks, I can look at parsing each chunk in turn. I’ll start with the location specification, as it’s the easiest. Here the main complication is that we can have one location or several locations separated by “or”:

With the activity clause, I have two kinds of activities to deal with. The simplest is the type activity, where I just need to pull out the type of activity.

For hotel stays, I need to pull out the minimum number of nights and choose a different activity specification.
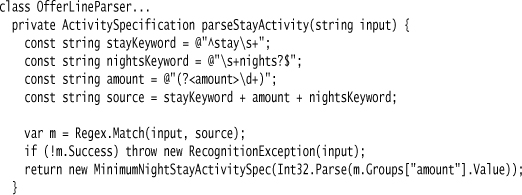
The last clause is the rewards clause. Here I just need to identify the basis of the reward and return the appropriate subclass of the reward class.

17.4 Parsing Nonautonomous Statements with Miss Grant’s Controller (Java)
I’ll use our familiar state machine as an example.


Looking at this language, I see it’s divided into several different blocks: command list, event list, reset event list, and each state. Each block has its own syntax for the statements within it, so you can think of the parser being in different states as it reads each block. Each parser state recognizes a different kind of input. As a result, I decided to use the State [GoF] pattern, where the main state machine parser uses different line parsers to handle the different kinds of lines it wants to parse. (You can also think of this as Strategy [GoF] pattern—the difference is often hard to tell.)
I begin loading the file with a static load method.

The run method breaks the input into lines and passes the line to the current line parser, starting with the top level.

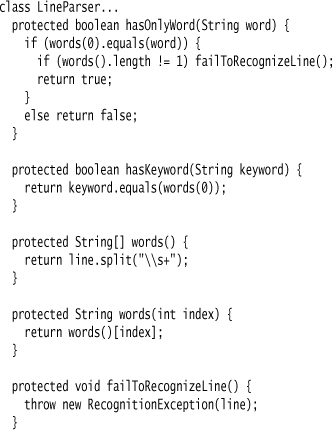
The line parsers are a simple hierarchy.

I make the superclass line parser parse a line by first removing comments and cleaning up whitespace. Once that’s done, it passes control to the subclass.

When parsing a line, I follow the same basic plan in all the line parsers. The doParse hook method is a conditional statement where each condition looks at the line to see if it matches a pattern for that line. If the pattern matches, I call some code to process that line.
Here’s the conditional for the top level:

The condition checks use some common condition checks that I place in the superclass.
In most cases, the top level just looks for a block opening command and then switches the line parser to the new one needed for that block. The state case is more involved—I’ll come to that later.
I could have used regular expressions in my conditionals instead of calling out methods. So, instead of writing hasOnlyWord("commands") I could say line.matches("commands\s*"). Regular expressions are a powerful tool. There are reasons I like a method here. First is comprehensibility: I find hasKeyword easier to understand than the regular expression. Like any other code, regular expressions often benefit from being wrapped in well-named methods in order to make them easier to understand. Of course, once I have the hasKeyword method, I could implement it with a regular expression rather than splitting the input line into words and testing the first word. Since many of the tests involved in this parse involve splitting up words, it seems easier to use the word splits when I can.
Using a method also allows me to do more—in this case, check that when I have “commands” I don’t have any other text following it on the line. This would have needed an extra regular expression check if I used bare regular expressions in the conditionals.
For the next step, let’s look at a line in the command block. There’s just two cases here: either a line definition, or the end keyword.
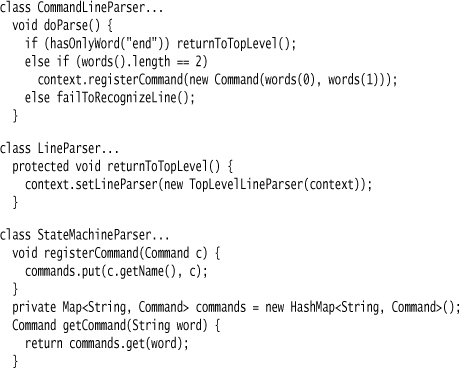
As well as controlling the overall parse, I also have the state machine parser acting as a Symbol Table.
The code to handle events and reset events is pretty similar, so I’ll move right along to look at handling states. The first thing that’s different about states is that the code in the top-level line parser is more complicated, so I used a method:
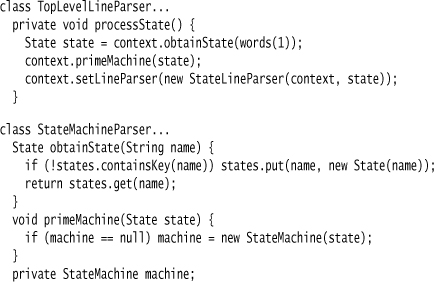
The first mentioned state becomes the start state—hence the primeState method. The first time I mention a state I put it in the Symbol Table, and therefore use an obtain method (my naming convention for “get one if exists or create if it doesn’t”).
The line parser for the state block is a touch more complicated as it has more kinds of lines it may match.

For actions, I just add them all to the state.

In this case I could have just used a loop like:
![]()
But I think using a loop initializer of 1 instead of the usual 0 is too subtle a change to communicate effectively what I’m doing.
For the transition case I have more involved code in both the condition and the action.

I don’t use the splitting into words that I used earlier, since I want drawerOpened=>waitingForLight (without spaces around the operator) to be legal.
Once the input file has been processed, the only thing left is to make sure the reset events are added into the machine. I do this last since the reset events can be indicated before the first state is declared.

A broad issue here is the division of responsibilities between the state machine parser and the various line parsers. This is also a classic issue with the state pattern: How much behavior should be in the overall context object and how much in different state objects? For this example I’ve shown a decentralized approach where I try to do as much as possible in the various line parsers. An alternative is to put this behavior in the state machine parser, using the line parsers just to extract the right information from the bunches of text.
I will illustrate this with a comparison of the two ways of doing the command block. Here’s the decentralized way I did it above:

And here’s the centralized way keeping the behavior in the state machine parser:

The downside of the decentralized route is that, since the state machine parser acts as a Symbol Table, it’s constantly being used for data access by the line parsers. Pulling data out of an object repeatedly is usually a bad smell. By using the centralized approach, no other objects need to know about the Symbol Table, so I don’t need to expose the state. The downside of the centralized approach, however, is that this puts a lot of logic in the state machine parser, which may make it overcomplicated. This would be more of an issue for a larger language.
Both alternatives have their problems, and I’ll confess I don’t have a strong preference either way.