
Chapter 18. Syntax-Directed Translation
Translate source text by defining a grammar and using that grammar to structure translation.
Computer languages naturally tend to follow a hierarchical structure with multiple levels of context. We can define the legal syntax of such a language by writing a grammar that describes how elements of a language get broken down into subelements.
Syntax-Directed Translation uses this grammar to define the creation of a parser that can turn input text into a parse tree that mimics the structure of the grammar rules.
18.1 How It Works
If you’ve read any book on programming languages, you’ll have come across the notion of a grammar. A grammar is a way of defining the legal syntax of a programming language. Consider the part of my opening state machine example that declares events and commands:

These declarations have a syntactic form that can be defined using the following grammar:

A grammar like this provides a human-readable definition of a language. Grammars are usually written in BNF. A grammar makes it easier for people to understand what is legal syntax in a language. With Syntax-Directed Translation we can take the grammar further and use it as the basis for designing a program to process this language.
This processing can be derived from the grammar in a couple of ways. One approach is to use the grammar as a specification and implementation guide for a handwritten parser. Recursive Descent Parser and Parser Combinator are two approaches to doing this. An alternative is to use the grammar as a DSL and use a Parser Generator to automatically build a parser from the grammar file itself. In this case, you don’t write any of the core parser code yourself; all of it is generated from the grammar.
However useful, the grammar only handles part of the problem. It can tell you how to turn the input text into a parse-tree data structure. Almost always, you’ll need to do more with the input than that. Therefore Parser Generators also provide ways to embed further behavior in the parser, so you can do something like populating a Semantic Model. So although the Parser Generator does a lot of work for you, you still have to do a fair bit of programming to create something truly useful. In this way, as in many others, a Parser Generator is an excellent example of a practical use of DSLs. It doesn’t solve the whole problem, but does make a significant chunk of it much easier. It’s also a DSL with a long history.
18.1.1 The Lexer
Almost always, when you use Syntax-Directed Translation, you’ll see a separation between a lexer and the parser. A lexer, also called a tokenizer or scanner, is the first stage in processing the input text. The lexer splits the characters of the input into tokens, which represent more reasonable chunks of the input.
The tokens are generally defined using regular expressions; here’s what such lexing rules might look like for the commands and events example above:

Here’s a very small bit of input:
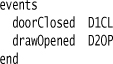
The lexer rules would turn this input into a series of tokens.

Each token is an object with essentially two properties: type and payload. The type is the kind of token we have, for example Event-keyword or Identifier. The payload is the text that was matched as part of the lexer: events or doorClosed. For keywords, the payload is pretty much irrelevant; all that matters is the type. For identifiers, the payload does matter, as that’s the data that will be important later on in the parse.
Lexing is separated out for a few reasons. One is that this makes the parser simpler, because it can now be written in terms of tokens rather than raw characters. Another is efficiency: The implementation needed to chunk up characters into tokens is different from that used by the parser. (In automata theory, the lexer is usually a state machine while the parser is usually a push-down stack machine.) This split is therefore the traditional approach—although it is being challenged by some more modern developments. (ANTLR uses a push-down machine for its lexer, while some modern parsers combine lexing and parsing into scannerless parsers.)
The lexer rules are tested in order, with the first match succeeding. Thus you can’t use the string events as an identifier because the lexer will always recognize it as a keyword. This is generally considered a Good Thing to reduce confusion, avoiding such things as PL/1’s notorious if if = then then then = if;. However, there are cases when you need to get around this by using some form of Alternative Tokenization.
If you’ve been suitably careful in comparing the tokens to the input text, you’ll notice something is missing from the token list. Nothing is missing—the “nothing” here being whitespace: spaces, tabs, and newlines. For many languages the lexer will strip out whitespace so that the parser doesn’t have to deal with it. This is a big difference to Delimiter-Directed Translation where the whitespace usually plays a key structuring role.
If the whitespace is syntactically significant—such as newlines as statement separators, or indentation signifying block structure—then the lexer can’t just ignore it. Instead, it must generate some form of token to indicate what’s happening—such as a newline token for Newline Separators. Often, however, languages that are intended to be processed with Syntax-Directed Translation try to make whitespace ignorable. Indeed, many DSLs can do without any form of statement separator—our state machine language can safely discard all whitespace in the lexer.
Another thing that the lexer often discards is comments. It’s always useful to have comments in even the smallest DSL, and the lexer can easily get rid of these. You may not want to discard comments; they may be useful for debugging purposes, particularly in generated code. In this case, you have to think about how you are going to attach them to the Semantic Model elements.
I’ve said that tokens have properties for type and payload. In practice, they may carry more. Often, this information is useful for error diagnostics, such as line number and character position.
When deciding on tokens, there is often a temptation to fine-tune the matching process. In the state controller example, I’ve said that the event codes are a four-character sequence of capital letters and numbers. So I might consider using a specific type of token for this, something like:
code: [A-Z 0-9]{4}
The problem with this is that the tokenizer would produce the wrong tokens in cases like this:
In that input, FAIL would be tokenized as a code rather than an identifier, because the lexer only looks at the characters, not the overall context of the expression. This kind of distinction is best left to the parser to deal with, as it has the information to tell the difference between the name and the code. This means that checking for matches of the four-character rule needs to be done later on in the parse. In general, it’s best to keep lexing as simple as possible.
Most of the time, I like to think of the lexer as dealing with three different kinds of tokens.
• Punctuation: keywords, operators, or other organizing constructs (parentheses, statement separators). With punctuation, the token type is important, but the payload isn’t. These are also fixed elements of the language.
• Domain text: names of things, literal values. For these, the token type is usually a very generic thing like “number” or “identifier.” These are variable; every DSL script will have a different domain text.
• Ignorables: stuff that’s usually discarded by the tokenizer, such as whitespace and comments.
Most Parser Generators provide generators for the lexer, using the kinds of regular expression rules I’ve shown above. However, many people prefer to write their own lexers. They are fairly straightforward to write using a Regex Table Lexer. With handwritten lexers, you have more flexibility for more complex interactions between the parser and the lexer, which can often be useful.
One particular parser-lexer interaction that can be useful is that of supporting multiple modes in the lexer and allowing the parser to indicate a switch between modes. This allows the parser to alter how tokenizing occurs within certain points of the language, which helps with Alternative Tokenization.
18.1.2 Syntactic Analyzer
Once you have a stream of tokens, the next part of Syntax-Directed Translation is the parser itself. The parser’s behavior can be divided into two main sections, which I’ll call syntactic analysis and actions. Syntactic analysis takes the stream of tokens and arranges them into a parse tree. This work can be derived entirely from the grammar itself, and in a Parser Generator, this code will be automatically generated by the tool. The actions take that syntax tree and do more with it—such as populating a Semantic Model.
The actions cannot be generated from a grammar, and are usually executed while the parse tree is being built up. Usually, a Parser Generator grammar file combines the grammar definition with additional code to specify the actions. Often, these actions are in a general-purpose programming language, although some actions can be expressed in additional DSLs.
For the moment, I’ll ignore the actions and just look at the syntactic analysis. If we build a parser using only the grammar and thus only doing syntactic analysis, the result of the parse will be either a successful run or a failure. This tells us if the input text matches the grammar or not. You’ll often hear this described as whether the parser recognizes the input.
So with the text I’ve used so far, I have this grammar:

And this input:

I’ve shown above that the tokenizer splits the input into this token stream:

Syntactic analysis then takes these tokens and the grammar, and arranges them into the tree structure of Figure 18.1.
Figure 18.1 Parse tree for the event input
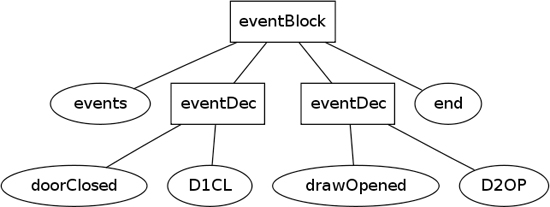
As you can see, the syntactic analysis introduces extra nodes (which I’ve shown as rectangles) in order to form the parse tree. These nodes are defined by the grammar.
It’s important to realize that any given language can be matched by many grammars. So for our case here, we could also use the following grammar:

This will match all the inputs that the previous formulation would match; however, it will produce a different parse tree, shown in Figure 18.2.
Figure 18.2 Alternative parse tree for the event input
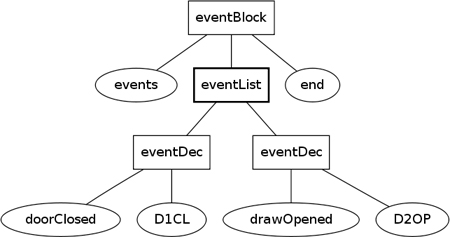
So, in Syntax-Directed Translation a grammar defines how an input text is turned into a parse tree, and we can often choose different grammars depending on how we want to control the parse. Different grammars also appear due to differences in Parser Generator tools.
So far I’ve talked about the parse tree as if it’s something that is explicitly produced by the parser as an output of the parse. However, this is usually not the case. In most cases, you don’t ever access the parse tree directly. The parser will build up pieces of the parse tree and execute actions in the middle of the parsing. Once it’s done with a bit of the parse tree, it’ll discard that bit (historically, this was important to reduce memory consumption). If you are doing Tree Construction, then you will produce a full syntax tree. However, in this case you usually don’t produce the full parse tree, but a simplification of it called an abstract syntax tree.
You may run into a particular terminological confusion around this point. Academic books in this area often use “parse” as a synonym for syntactic analysis only, calling the overall process something like translation, interpretation, or compilation. I tend to use “parse” much more broadly in this book, reflecting what I see as common usage in the field. Parser Generators tend to refer to the parser as the activity that consumes tokens—so they talk about the lexer and parser as separate tools. Since that’s overwhelmingly common, I do that in this section too, although you could argue that, to be consistent with other sections of this book, parsing should include lexing too.
Another terminological muddle is around the terms “parse tree,” “syntax tree,” and “abstract syntax tree.” In my usage, I use parse tree to refer to a tree that accurately reflects the parse with the grammar you have with all the tokens present—essentially the raw tree. I use abstract syntax tree (AST) to refer to a simplified tree, discarding unnecessary tokens and reorganizing the tree to suit that later processing. I use syntax tree as the supertype of AST and parse tree when I need a term for a tree that could be either. These definitions are broadly those you’ll find in the literature. As ever, the terminology in software varies rather more than we would like.
18.1.3 Output Production
While the grammar is sufficient to describe syntactic analysis, that’s only enough for a parser to recognize some input. Usually, we’re not satisfied with recognition; we also want to produce some output. I classify three broad ways to produce output: Embedded Translation, Tree Construction, and Embedded Interpretation. All of these require something other than the grammar to specify how they work, so usually you write additional code to do the output production.
How you weave that code into the parser depends on how you are writing the parser. With Recursive Descent Parser, you add actions into the handwritten code; with Parser Combinator, you pass action objects into the combinators using the facilities of your language; with Parser Generator, you use Foreign Code to add code actions into the text of the grammar file.
18.1.4 Semantic Predicates
Syntactic analyzers, whether written by hand or generated, follow a core algorithm that allows them to recognize input based on a grammar. However, there are sometimes cases where the rules for recognition can’t quite be expressed in the grammar. This is most notable in a Parser Generator.
In order to cope with this, some Parser Generators support semantic predicates. A semantic predicate is a hunk of general-purpose code that provides a Boolean response to indicate whether a grammar production should be accepted or not—effectively overriding what’s expressed by the rule. This allows the parser to do things beyond what the grammar can express.
A classic example of the need for a semantic predicate is when parsing C++ and coming across T(6). Depending on the context, this could either be a function call or a constructor-style typecast. To tell them apart, you need to know how T has been defined. You can’t specify this in a context-free grammar, so a semantic predicate is needed to resolve the ambiguity.
You shouldn’t come across the need to use semantic predicates for a DSL, since you should be able to define the language in such a way as to avoid this need. If you do need them, take a look at [parr-LIP] for more information.
18.2 When to Use It
Syntax-Directed Translation is an approach alternative to Delimiter-Directed Translation. The principal disadvantage of Syntax-Directed Translation is the need to get used to driving parsing via a grammar, while chopping up via delimiters is usually a more familiar approach. It doesn’t take long, however, to get used to grammars, and once you do, they provide a technique that is much easier to use as your DSLs get more complex.
In particular, the grammar file—itself a DSL—provides a clear documentation of the syntactic structure of the DSL it’s processing. This makes it easier to evolve the syntax of the DSL over time.
18.3 Further Reading
Syntax-Directed Translation has been a primary area of academic study for decades. The usual starting-point reference is the famous Dragon Book [Dragon]. An alternative route, deviating from the traditional approach to teaching this material, is [parr-LIP].