
Chapter 9. Language Workbenches
The techniques I’ve written about so far have been around, in some form or another, for a long time. The tools that exist to support them, such as Parser Generators for external DSLs, are similarly well seasoned. In this chapter, I’m going to spend some time looking at a set of tools that are rather more shiny and new—tools that I call language workbenches.
Language workbenches are, in essence, tools that help you build your own DSLs and provide tool support for them in the style of modern IDEs. The idea is that these tools don’t just provide an IDE to help create DSLs; they support building IDEs for editing these DSLs. This way, someone writing a DSL script has the same degree of support that a programmer who uses a post-IntelliJ IDE.
As I write this, the language workbench field is still very young. Most tools have barely left beta stage. Even those that have been out for a while haven’t garnered enough experiences to draw many conclusions. Yet there’s immense potential here—these are tools that could change the face of programming as we know it. I don’t know whether they will succeed in their endeavors, but I am sure that they are worth keeping an eye on.
This immaturity means that this topic is especially difficult to write about. I’ve wondered long and hard about what to say about language workbenches in this book. In the end, I decided that the fact that these tools are so new and volatile means I cannot write much in a book like this. Much of what I write now will be out-of-date by the time you read it. As ever in my work, I’m looking for core principles that don’t change much, but they are hard to identify in such a rapidly moving field. So I decided to just write this one chapter and not provide any more details in the reference section of the book. I also decided to only cover a few aspects of language workbenches here—those that I felt were relatively stable. Even so, you should take this chapter with caution and keep an eye on the Web to find out about more recent developments.
9.1 Elements of Language Workbenches
Although language workbenches differ greatly in what they look like, there are common elements that they share. In particular, language workbenches allow you to define three aspects of a DSL environment:
• Semantic Model schema defines the data structure of the Semantic Model, together with static semantics, usually by using a meta-model.
• DSL editing environment defines a rich editing experience for people writing DSL scripts, through either source editing or projectional editing.
• Semantic Model behavior defines what the DSL script does by building off the Semantic Model, most commonly with code generation.
Language workbenches use a Semantic Model as the core part of the system. As a result, they provide tools to help you define that model. Instead of defining the Semantic Model with a programming language, as I’ve assumed for this book, they define it within a special meta-modeling structure that allows them to use runtime tools to work on the model. This meta-modeling structure helps them provide their high degree of tooling.
As a result of this, there is a separation between schema and behavior. The Semantic Model schema is essentially a data model without much behavior. The behavioral aspects of the Semantic Model come from outside the data structure—mostly in the form of code generation. Some tools expose the Semantic Model allowing you to build an interpreter, but thus far code generation is the most popular way to make the Semantic Model run.
One of the most interesting and important aspect of language workbenches is their editing environments. This is perhaps the key aspect that they bring to software development, providing a much richer range of tools for populating and manipulating a Semantic Model. These vary from something close to assisted textual editing, to graphical editors that allow you to write a DSL script as a diagram, to environments that use what I call “illustrative programming” to provide an experience closer to working with a spreadsheet than that of a regular programming language.
Going much deeper than this would raise the problems of the tools’ newness and volatility, but there are a couple of general principles that I feel will have some lasting relevance: schema definition and projectional editing.
9.2 Schema Definition Languages and Meta-Models
Throughout this book, I’ve been stressing the usefulness of using a Semantic Model. Every language workbench I’ve looked at uses a Semantic Model and provides tools to define it.
There is a notable difference between language workbenches’ models and the Semantic Models I’ve used so far in this book. As an OO bigot, I naturally build an object-oriented Semantic Model that combines both data structure and behavior. However, language workbenches don’t work that way. They provide an environment for defining the schema of the model, that is, its data structure, typically using a particular DSL for the purpose—the schema definition language. They then leave the behavioral semantics as a separate exercise, usually through code generation.
At this point, the word “meta” begins to enter the picture, and things start looking like an Escher drawing. This is because the schema definition language has a semantic model, which is itself a model. The schema definition language’s Semantic Model is the meta-model for a DSL’s Semantic Model. But the schema definition language itself needs a schema, which is defined using a Semantic Model whose meta-model is the schema definition language whose meta-model is the . . . (swallows self).
If the above paragraph didn’t make perfect sense to you (and it only makes sense to me on Tuesdays) then I’ll take things more slowly.
I’ll begin with a fragment of the secret panel example, specifically the movement from the active state to the waiting-for-light state. I can show this fragment with the state diagram in Figure 9.1.
Figure 9.1 A simple state diagram of a light switch
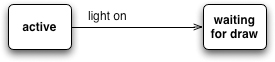
This fragment shows two states and a transition connecting them. With the Semantic Model I showed in the Introduction (“The State Machine Model,” p. 5), I interpret this model as two instances of the state class and one instance of the transition class, using the Java classes and fields I defined for the Semantic Model. In this case, the schema for the Semantic Model is Java class definitions. In particular, I need four classes: state, event, string, and transition. Here’s a simplified form of that schema:

The Java code is one way to represent that schema; another way is to use a class diagram (Figure 9.2).
Figure 9.2 A class diagram for a simple state machine schema
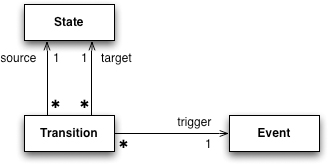
The schema of a model defines what you can have in the contents of the model. I can’t add guards to my transitions on my state diagram unless I add them in the schema. This is the same as any data structure definition: classes and instances, tables and rows, record types and records. The schema defines what goes into the instances.
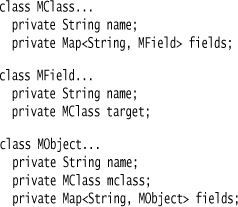
The schema in this case is the Java class definitions, but I can have the schema as a bunch of Java objects rather than classes. This would allow me to manipulate the schema at runtime. I can do a crude version of this approach with three Java classes for classes, fields, and objects.
I can use this environment to create a schema of states and transitions.

Then, I can use this schema to define the simple state model of Figure 9.1.

It can be useful to think of this structure as two models, as illustrated in Figure 9.3. The base model is the fragment of Miss Grant’s secret panel; it contains the MObjects. The second model contains the MClasses and MFields and is usually referred to as a meta-model. A meta-model is a model whose instances define the schema for another model.
Figure 9.3 Meta-model and base model for a state machine
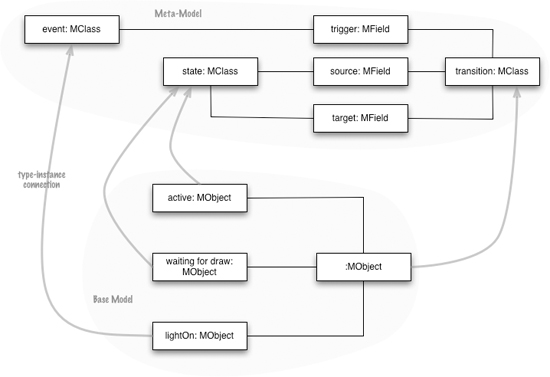
Since a meta-model is just another Semantic Model, I can easily define a DSL to populate it just like I do for its base model—I call such a DSL a schema definition language. A schema definition language is really just a form of data model, with some way of defining entities and relationships between them. There are lots of different schema definition languages and meta-models out there.
When rolling a DSL by hand, there usually isn’t much point in creating a meta-model. In most situations, using the structural definition capability of your host language is the best bet. A language you have is much easier to follow, as you are using familiar language constructs both for the schema and for the instances. In my crude example, if I want to find the source state of my transition, I have to say something like aTransition.get("source") rather than aTransition.getSource(); this makes it much harder to find what fields are available, forces me to do my own type checking, and so on. I’m working despite my language rather than with it.
Perhaps the biggest argument for not using a meta-model in this situation is that I lose the ability to make my Semantic Model a proper OO domain model. While the meta-model does a tolerable, if kludgy, job of defining the structure of my Semantic Model, it’s really hard to define its behavior. If I want proper objects that combine both data and behavior, I’m much better off with using the language’s own mechanism for schema definition.
These tradeoffs work differently for language workbenches. In order to provide good tooling, a workbench needs to examine and manipulate the schema of any model I define. This manipulation is usually much easier when using a meta-model. In addition, the tooling of language workbenches overcomes many of the common disadvantages of using a meta-model. As a result, most language workbenches use meta-models. The workbench uses the model to drive the definition of editors and to help with adding in the behavior that can’t exist in the model.
The meta-model, of course, is just a model. As with any other model, it has a schema to define its structure. In my crude example, that schema is one that describes MClass, MField, and MObject. But there’s logically no reason why this schema can’t be defined using a meta-model. This then allows you to use the workbench’s own modeling tools to work on the schema definition system itself, allowing you to create meta-models using the same tools that are used to write DSL scripts. In effect, the schema definition language is itself just another DSL in the language workbench.
Many language workbenches take this approach, which I refer to as a bootstrapped workbench. In general, a bootstrapped workbench gives you more confidence that the modeling tools will be sufficient for your own work, since the tool can define itself.
But this is also the point where you start to think of yourself as inside an Escher drawing. If models are defined using meta-models, which are just models defined using meta-models—where does it all end? In practice, the schema definition tools are special in some way, and there’s some stuff that’s hard-coded into the workbench to make it work. Essentially, the special thing about a schema definition model is that it’s capable of defining itself. So although you can imagine yourself popping up an infinite ladder of meta-models, at some point you reach a model that can define itself. That’s quite weird in its own way, of course. On the whole I find it easiest not to think about it too hard, even on a Tuesday.
A common question is what is the difference between a schema definition language and a grammar. The short answer is that a grammar defines the concrete syntax of a (textual) language, while the schema definition language defines the structure of the schema of a Semantic Model. A grammar will thus include lots of things that describe the input language, while a schema definition language will be independent of any DSL used to populate the Semantic Model. A grammar also implies the structure of the parse tree; together with tree construction rules, it can define the structure of a syntax tree. But a syntax tree is usually different from a Semantic Model (as I’ve discussed in “The Workings of a Parser,” p. 47).
When defining a schema, we can think of it in terms of data structures: classes and fields. Indeed, a lot of schema definition is about thinking of the logical data structure in which we can store the elements of a Semantic Model. But there’s a further element that can appear in a schema—structural constraints. These are constraints on what makes valid instances of the Semantic Model, equivalent to invariants in Design by Contract [Meyer].
Structural constraints usually are validation rules that go beyond what can be expressed within the data structure definition. Data structure definition itself implies constraints—we can’t say anything in the Semantic Model that its schema can’t store. Our state model above says there’s only one target state for a transition; we can’t add more because there’s nowhere to put it in. That’s a constraint that is defined and enforced by the data structure.
When we talk about structural constraints, we usually mean those that aren’t due to the data structure—we can store it, but it’s illegal. This might be a limitation imposed on a data structure, such as saying that a person’s number of legs must be 0, 1, or 2 even if we are storing that attribute in an integer field. Constraints can be arbitrarily complicated, involving a number of fields and objects—for example, saying that a person cannot be her own ancestor.
Schema definition languages often come with some way of expressing structural constraints. This may be as limited as allowing you to attach ranges to attributes, or it may be a general-purpose language to allow you to express any constraint. One usual limitation is that structural constraints cannot change the Semantic Model, they can only query it. In this way, these constraints are a Production Rule System without any chaining.
9.3 Source and Projectional Editing
One of the most notable features of many language workbenches is their use of a projectional editing system, not the source editing system that most programmers are used to. A source-based editing system defines the program using a representation that’s editable independently of the tools used to process that representation into a running system. In practice that representation is textual, which means the program can be read and edited with any text-editing tool. This text is the source code of the program. We turn it into an executable form by feeding the source code into a compiler or interpreter, but the source is the key representation that we programmers edit and store.
With a projectional editing system, the core representation of the program is held in a format specific to the tool that uses it. This format is a persistent representation of the Semantic Model used by the tool. When we want to edit the program, we start up the tool’s editing environment, and the tool can then project editable representations of its Semantic Model for us to read and update. These representations may be text, or they may be diagrams, tables, or forms.
Desktop database tools, such as Microsoft Access, are good examples of projectional editing systems. You don’t ever see, let alone edit, the textual source code for an entire Access program. Instead, you start up Access and use various tools to examine the database schema, reports, queries, etc.
Projectional editing gives you a number of advantages over a source-based approach. The most obvious one is that it allows editing through different representations. A state machine is often best thought of in a diagrammatic form, and with a projectional editor you can render a state machine as a diagram and edit it directly in that form. With source, you can only edit it in text, and although you can run that text through a visualizer to see the diagram, you can’t edit that diagram directly.
A projection like this allows you to control the editing experience to make it easier to enter the correct information and disallow incorrect information. A textual projection can, given a method call on an object, only show you the legal methods for that class and only allow you to enter a valid method name. This gives you a much tighter feedback cycle between the editor and the program and allows the editor to give more assistance to the programmer.
You can also have multiple projections, either at the same time or as alternatives. A common demonstration of the Intentional Software’s language workbench shows a conditional expression in a C-like syntax. With a menu command, you can switch that same expression to a Lisp-like syntax, or to a tabular form. This allows you to use whichever projection best fits the way you want to look at the information for the particular task at hand, or to follow an individual programmer’s preference. Often, you want multiple projections of the same information—such as showing a class’ superclass as a field in a form and also in a class hierarchy in another pane of the editing environment. Editing either of these updates the core model which, in turn, updates all projections.
These representations are projections of an underlying model, and thus encourage semantic transformations of that model. If we want to rename a method, this can be captured in terms of the model rather than in terms of text representations. This allows many changes to be made in semantic terms as operations on a semantic model, rather than in textual terms. This is particularly helpful for doing refactorings in a safe and efficient manner.
Projectional editing is hardly new; it’s been around for at least as long as I’ve been programming. It has many advantages, yet most serious programming we do is still source-based. Projectional systems lock you into a specific tool, which not only makes people nervous about vendor lock-in, but also makes it hard to create an ecosystem where multiple tools collaborate over a common representation. Text, despite its many faults, is a common format; so tools that manipulate text can be used widely.
A particularly good example of where this has made a big difference is source code management. There’s been a great deal of interesting developments in source code management over the last few years, introducing concurrent editing, representation of diffs, automated merging, transactional repository updates, and distributed version control. All of these tools work on a wide range of programming environments because they operate only on text files. As a result, we see a sad situation where many tools that could really use intelligent repositories, diffs, and merges are unable to do so. This problem is a big deal for larger software projects, which is one reason why larger software systems still tend to use source-based editing.
Source has other pragmatic advantages. If you’re sending someone an email to explain how to do something, it’s easy to throw in a text snippet, whereas explaining through projections and screenshots can be much more trouble. Some transformations can be automated very well with text processing tools, which is very useful if a projectional system doesn’t provide a transformation you need. And while a projectional system’s ability to only allow valid input can be helpful, it’s often useful to type in something that doesn’t work immediately, as a temporary step, while thinking through a solution. The difference between helpful restriction and constraints on thinking is often a subtle one.
One of the triumphs of modern IDEs is that they provide a way to have your cake and eat it. You work fundamentally in a source-based way, with all the advantages that implies; however, when you load your source into an IDE, it creates a semantic model that allows it to use all the projectional techniques to make editing easier—an approach I call model-assisted source editing. Doing this requires a lot of resources; the tool has to parse all the sources and requires a lot of memory to keep the semantic model, but the result comes close to the best of both worlds. To be able to do this, and to keep the model updated as the programmer edits, is a difficult task.
9.3.1 Multiple Representations
One concept I find handy when thinking about the flow of source and projectional editing is the notion of representational roles. Source code plays two roles: It is the editing representation (the representation of the program that we edit) and the storage representation (the representation that we store in persistent form). A compiler changes this representation into one that is executable—that is, one that we can run on our machine. With an interpreted language, the source is an executable representation as well.
At some point, such as during compilation, an abstract representation is generated. This is a purely computer-oriented construct that makes it easier to process the program. A modern IDE generates an abstract representation in order to assist editing. There may be multiple abstract representations; the one the IDE uses for editing may not be the same as the syntax tree used by the compiler. Modern compilers often create multiple abstract representations for different purposes, such as a syntax tree for some things and a call graph for others.
With projectional editing, these representations are arranged differently. The core representation is the Semantic Model used by the tool. This representation is projected into multiple editing representations. The model is stored using a separate storage representation. The storage representation may be human-readable at some level—for example, serialized in XML—but it isn’t a representation any sane person would use for editing.
9.4 Illustrative Programming
Perhaps the most intriguing consequence of projectional editing is its support for what I call illustrative programming. In regular programming, we pay most attention to the program, which is a general statement of what should work. It’s general because it’s a text that describes the general case, yielding different results with different inputs.
But the most popular programming environment in the world doesn’t work like that. The most popular environment, in my unscientific observation, is a spreadsheet. Its popularity is particularly interesting because most spreadsheet programmers are lay programmers: people who don’t consider themselves to be programmers.
With a spreadsheet, the most visible thing is an illustrative calculation with a set of numbers. The program is hidden away in the formula bar, visible just one cell at a time. The spreadsheet fuses the execution of the program with its definition, and makes you concentrate on the former. Providing a concrete illustration of the program output helps people understand what the program definition does, so they can more easily reason about behavior. This is, of course, a property shared with the heavy use of testing, but with the difference that in a spreadsheet, the test output has more visibility than the program.
I chose the term “illustrative programming” to describe this, partly because “example” is so heavily used (and “illustration” isn’t) but also because the term “illustration” reinforces the explanatory nature of the example execution. Illustrations are meant to help explain a concept by giving you a different way of looking at it—similarly, an illustrative execution is there to help you see what your program does as you change it.
When trying to make a concept explicit like this, it’s useful to think about the boundary cases. One boundary is the notion of using projections of program information during editing, such as in an IDE that shows you the class hierarchy while you are working on the code. In some ways this is similar, as the hierarchy display is continuously updated as you modify the program, but the crucial difference is that the hierarchy can be derived from static information about the program. Illustrative programming requires information from the actual running of the program.
I also see illustrative programming as a wider concept than the ability to easily run code snippets in an interpreter that’s a much beloved feature of dynamic languages. Interpreting snippets allows you to explore execution, but it doesn’t put the examples front and center, the way that a spreadsheet does with its values. Illustrative programming techniques push the illustration to the foreground of your editing experience. The program retreats to the background, peeping out only when we want to explore a part of the illustration.
I don’t think that illustrative programming is all goodness. One problem I’ve seen with spreadsheets and with GUI designers is that, while they do a good job of revealing what a program does, they de-emphasize program structure. As a result, complicated spreadsheets and UI panels are often difficult to understand and modify. They are often rife with uncontrolled copy-and-paste programming.
This strikes me as a consequence of the fact that the program is de-emphasized in favor of the illustrations, and the programmers often don’t think to take care of it. We suffer enough from a lack of care of programs even in regular programming, so it’s hardly shocking that this occurs with illustrative programs written by lay programmers. But this problem leads to programs that quickly become unmaintainable as they grow. The challenge for future illustrative programming environments is to help develop a well-structured program behind the illustrations—although the illustrations may also force us to rethink what a well-structured program is.
The hard part of this may well be the ability to easily create new abstractions. One of my observations on rich client UI software is that they get tangled because the UI builders think only in terms of screens and controls. My experiments here suggest that you need to find the right abstractions for your program, which will take a different form. But these abstractions won’t be supported by the screen builder, for it can only illustrate the abstractions it knows about.
Despite this problem, illustrative programming is a technique we should take more seriously. We can’t ignore the fact that spreadsheets have become so popular with lay programmers. Many language workbenches focus their attention on enabling lay programmers, and projectional editing leads to illustrative programming which could be a vital part of their eventual success.
9.5 Tools Tour
Thus far, I’ve been reluctant to mention any actual language workbenches in this section. With such a volatile field, anything I say about tools is likely to be out of date by the time this book is published, let alone by the time you read it. But I decided to do it anyway in order to provide a feel for the variety of tools in this world. Remember, however, that the actual details of the tools are almost certainly not going to be true when you read this.
Perhaps the most influential, and certainly the most sophisticated is the Intentional Workbench by Intentional Software (http://intentsoft.com). This project is led by Charles Simonyi, who is well known for his pioneering work at PARC on early word processors and leading the development of Microsoft Office. His vision is of a highly collaborative environment that includes programmers and nonprogrammers working in a single integrated tool. As a result, the Intentional Workbench has very rich projectional editing capabilities and a sophisticated meta-modeling repository to tie it all together.
The biggest criticisms of Intentional’s work are how long they’ve been beavering away at it and how secretive they are. They have also been rather active on the patent front, which alarms many in this field. They did start doing some meaningful public presentations in early 2009 and have demonstrated what looks like a highly capable tool. It supports all sorts of projections: text, tables, diagrams, illustrations, and all combinations.
Although Intentional is the oldest language workbench in terms of its development, I believe the oldest released tool is MetaEdit from from MetaCase (www.metacase.com). This tool is particularly focused on graphical projections, although it also supports tabular projections (but not text). Unusually, it isn’t a bootstrapped environment; you use a special environment for schema and projection definition. Microsoft has a DSL tools group with a similar style of tool.
Meta-Programming System (MPS) by JetBrains (www.jetbrains.com) takes another route at projectional editing, preferring a structured text representation. It also targets much more at programmer productivity rather than close involvement of domain experts in the DSLs. JetBrains has made a significant advancement of IDE capabilities with their sophisticated code editing and navigation tools and thus has built a strong reputation for developer tooling. They see MPS as the foundation for many future tools. A particularly important point is that most MPS code is open source. This might be a vital factor in getting developers to move into a very different kind of programming environment.
Another open source effort is Xtext (www.eclipse.org/Xtext), built on top of Eclipse. Xtext is notably different in that it uses source editing rather than projectional editing. It uses ANTLR as a parser back-end and integrates with Eclipse to provide model-assisted source editing for DSL scripts in a style similar to editing Java in Eclipse.
Microsoft’s SQL Server Modeling project (formerly known as “Oslo”) uses a mix of textual source and projections. It has a modeling language, currently called M, which allows you to define a Semantic Model schema and a grammar for a textual DSL. The tool then creates a plugin for an intelligent editor that gives you model-assisted source editing. The resulting models go into a relational database repository, and a diagrammatic projectional editor (Quadrant) can manipulate these models. The models can be queried at runtime, so the whole system could work entirely without code generation.
I’m sure this little tour isn’t comprehensive, but it gives you a flavor of the variety of tools in this space. Lots of new ideas are popping up, and it is still far too early to predict what combination of technical and business ideas will lead to a success. Purely in terms of technical sophistication, Intentional would surely take the prize, but as we know it’s often a lesser technology hitting the most important targets that wins in the end.
9.6 Language Workbenches and CASE tools
Some people look at language workbenches and see many parallels with CASE tools that were supposed to revolutionize software development a couple of decades ago.
For those who missed that saga, CASE (short for Computer-Aided Software Engineering) tools would allow you to express the design of your software using various diagrammatic notations and then generate your software for you. They were the future of software development in the 90s, but have since faded away.
On the surface, there are a few similarities. The central role of a model, the use of meta-models to define it, and projectional editing with diagrams were all characteristics of CASE tools.
The key technological difference is that CASE tools did not give you the ability to define your own language. MetaEdit is a language workbench probably closest to a CASE tool—but its facilities to define your own language and control code generation from your model are very different from what CASE tools provided.
There is a strand of thought that OMG (Object Management Group) MDA (Model-Driven Architecture) could play a large role in the DSL and language workbench landscape. I’m skeptical of this, as I see the OMG MDA standards as too unwieldy for a DSL environment.
Perhaps the most important difference, however, is cultural. Many people in the CASE world looked down on programming and saw their role as automating something that would then die out. More people in the language workbench community come from a programming background and are looking to create environments that make programmers more productive (as well as increase collaboration with customers and users). A result of this is that language workbenches tend to have strong support for code generation tools—as this is central to producing a useful output from the tool. This aspect tends to get missed during demonstrations, as it’s less exciting than the projectional editing side, but it’s a sign of how seriously we should take the resulting tool.
9.7 Should You Use a Language Workbench?
I don’t know if you’re as tired of reading this disclaimer as I am of writing it, but I’ll say it again. This is a new and volatile area, so what I say now could easily be invalid by the time you read it. Even so, here goes.
I’ve been keeping an eye on these tools for the past few years because I think they have extraordinary potential. If language workbenches pull off their vision, they could completely change the face of programming, altering our idea of a programming language. I should stress that it is a potential, and could end up like nuclear fusion’s potential to solve all of our energy needs. But the fact that the potential is there means it’s worth keeping an eye on developments in this space.
However, the newness and volatility of the field means that it’s important to be cautious at the moment (early 2010). A further reason for caution is that the tools inherently involve a significant lock-in. Any code you write in one language workbench is impossible to export into another one. Some kind of interoperability standard may come some day, but it will be very hard. As a result, any effort you commit to working in a language workbench could be lost if you run into a wall or there are vendor problems.
One way to mitigate this is to treat the language workbench as a parser rather than a full DSL environment. With a full DSL environment, you design the Semantic Model in the language workbench’s schema definition environment and generate pretty full-featured code. When you treat the language workbench as a parser, you still build the Semantic Model the usual way. You then use the language workbench to define the editing environment with a model that’s geared to Model-Aware Generation against your Semantic Model. That way, should you run into issues with your language workbench, it’s only the parser that’s affected. The most valuable stuff is in the Semantic Model which isn’t locked in. You will also find it easier to come up with an alternative parser mechanism.
My thought above, like much of using language workbenches, is somewhat speculative. But I do think the potential of these tools means they are worth experimenting experimenting with. Although it’s a risky investment, the potential returns are considerable.