
Chapter 28. Alternative Tokenization
Alter the lexing behavior from within the parser.

28.1 How It Works
In my simple overview of how Parser Generators work, I said that the lexer feeds a stream of tokens to the parser that assembles the stream into a parse tree. The implication is that it’s a one-way interaction: The lexer is a source that the parser simply consumes. As it turns out that isn’t always the case. There are times when the way the lexer does the tokenizing should change depending on where we are in the parse tree—meaning that the parser has to manipulate the way the lexer does the tokenizing.
For a simple example of this problem, consider listing a bunch of items that might appear in a catalog.
item camera;
item small_power_plant;
item acid_bath;
Using underscores or camelCase is familiar and normal for geeks like us, but regular human beings are more used to spaces. They would rather read something like:
item camera;
item small power plant;
item acid bath;
How hard can this be? As it turns out, when you’re using a grammar-driven parser, it can be surprisingly tricky, which is why I have a section here to talk about it. (You’ll notice that I’m using semicolons to separate the item declarations. You could also use newlines, and indeed may prefer to. I might too, but that introduces another tricky issue, that of handling Newline Separators, so I’ll use semicolons for now to deal with one tricky issue at a time.)
The simplest grammar allowing us to recognize any amount of words after the item keyword might look like this:
catalog : item*;
item : 'item' ID* ';';
The trouble is that this breaks down when you have an item that contains the “item” in its name, such as item small white item;.
The problem is that the lexer recognizes item as a keyword, not as a word, and thus hands back a keyword token rather than an ID token. What we really want to do is to treat everything between the item keyword and the semicolon as an ID, effectively altering the tokenization rules for this point in the parse.
Another common example of this kind of situation is Foreign Code—which can include all sorts of meaningful tokens in the DSL, but we want to ignore them all and take the foreign code as one big string to embed into the Semantic Model.
There are a number of approaches available for this, not all of which are possible with all kinds of Parser Generators.
28.1.1 Quoting
The simplest way to deal with this problem is to quote the text so the lexer can recognize it as something special. For our item names, it means putting them inside some kind of quotation characters, at least when we use the word item. This would read like this:

This would be parsed with a grammar like:

Quoting gobbles up all the text between the delimiters, so it is never touched by the other lexer rules. I can then take the quoted text and do whatever I like with it.
Quoting doesn’t involve the parser at all, so a quoting scheme has to be used everywhere in the language. You can’t have specific rules for quoting particular elements of the language. In many situations, however, this works out just fine.
An awkward aspect of quoting is dealing with delimiters inside the quoted string—something like Active "Marauders" Map where you need quotation marks inside the quoted string. There are ways of dealing with this, which should be familiar to you from regular programming.
The first is to provide an escaping mechanism, such as Unix’s beloved backslash or doubling the delimiter. To process item Active "Marauders" Map you would use a rule like this:
QUOTED_STRING : STRING_DELIM (STRING_ESCAPE | ~(STRING_DELIM))* STRING_DELIM;
fragment STRING_ESCAPE: STRING_DELIM STRING_DELIM;
fragment STRING_DELIM : '"';
The basic trick is to use the delimiters to surround a repeating group where one of the elements of that group is the negation of the delimiter (essentially the same thing as a nongreedy match) and the other alternatives are any escape combinations you need.
You’re more likely to see this written in a more compact form.
QUOTED_STRING : '"' ('""' | ~('"'))* '"';
I prefer the long-winded clarity here, but such clarity is particularly rare when it comes to regular expressions.
Escaping works well, but it may be confusing, particularly to nonprogrammers.
Another technique is to pick a more unusual combination of delimiter symbols that are unlikely to appear in the quoted text. A good example of this is the Java CUP Parser Generator Most Parser Generators use curly braces to indicate code actions, which is familiar but runs into the problem that curly brackets are a common thing to be found inside C-based languages. So CUP uses “{:” and “:}” as its delimiters—a combination you don’t find in most languages, including Java.
Using an unlikely delimiter is obviously only as good as the unlikeliness of its use. In many DSL situations, you can get away with it because there are only a few things you’re likely to run into in the quoted text.
A third tactic is to use more than one kind of quoting delimiters, so that if you need to embed a delimiter character, you can do so by switching to an alternative for quoting. As an example, many scripting languages allow you to quote with either single or double quote characters, which has the additional advantage of reducing the confusion caused by some languages using one or the other. (They often have different escaping rules with the different delimiters.) Allowing double or single quotes for the item example is as simple as this:
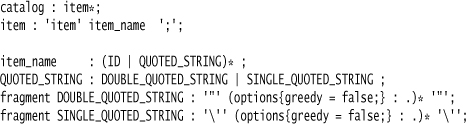
There’s a less common option that can occasionally be useful. Some Parser Generators, including ANTLR, use a push-down machine rather than a state machine for lexing. This provides another option for cases where the quoting characters are matching pairs (like “{...}”). This requires a slight variation on my example; imagine that I want to embed some Javascript in the item list to provide an arbitrary condition for when the item should appear in the catalog, for example:
item lyncanthropic gerbil {!isFullMoon()};
The embedding problem here is that Javascript code can obviously include curlies. However, we can allow curlies, but only if they are matched, by writing the quoting rule like this:

This doesn’t handle all embedded curlies—it would be defeated by {System.out.print("tokenize this: }}}");}. To conquer that, I’d need to write additional lexer rules to cover any elements that might be embedded in the condition that might include a curly. For this kind of situation, however, a simple solution will usually suffice. The biggest downside to this technique is that you can only do it if the lexer is a push-down machine, which is relatively rare.
28.1.2 Lexical State
Perhaps the most logical way of thinking about this problem, at least for the item name case, is to replace the lexer completely while we are looking at the item name. That is, once we’ve seen the keyword item, we replace our usual lexer with another lexer until that lexer sees the semicolon, at which point we return to our usual lexer.
Flex, the GNU version of lex, supports a similar behavior under the name of start conditions (also referred to as lexical state). While this feature uses the same lexer, it allows the grammar to switch the lexer into a different mode. This is almost the same thing as changing the lexer, and certainly enough for this example.
I’ll switch to Java CUP for this example code because ANTLR currently doesn’t support changing the lexical state (it can’t, as the lexer currently tokenizes the entire input stream before the parser starts working on it). Here’s a CUP grammar to handle the items:

For this example, I’m using two lexical states: YYINITIAL and gettingName. YYINITIAL is the default lexical state that the lexer starts up in. I can use these lexical states to annotate my lexer rules. In this case, you see that the item keyword is only recognized as a keyword token in the YYINITIAL state. Lexer rules without a state (such as “;”) apply in all states. (Strictly, I don’t need the two state-specific rules for {Word} as they are the same, but I’ve shown them here to illustrate the syntax.)
I then switch between the lexical states in the grammar. The rules are similar to the ANTLR case, but a little different as CUP uses a different version of BNF. I’ll first show a couple of rules that don’t get involved in the lexical state switching. First is the top-level catalog rule, which is a basic BNF form of the ANTLR rule.
catalog ::= item | catalog item ;
At the other end, there is the rule to assemble the item name.
item_name ::=
WORD:w {: RESULT = w; :}
| item_name:n WORD:w {: RESULT = n + " " + w; :}
;
The rule that involves the lexical switching is the rule to recognize an item.

The basic mechanism is very straightforward. Once the parser recognizes the item keyword, it switches the lexical state to just take the words as they come. Once it finishes with the words, it switches back.
As written, it is pretty easy, but there’s a catch. In order to resolve their rules, parsers need to look ahead through the token stream. ANTLR uses arbitrary look ahead, which is partly why it tokenizes the entire input before the parser gets to work. CUP, like Yacc, does one token of look ahead. But this one token is enough to cause a problem with an item declaration like item item the troublesome. The problem is that the first word in the item name is parsed before we change lexical state, so in this case it will be parsed as an item keyword, thus breaking the parser.
It’s easy to run into a more serious problem. You’ll notice I put the call to reset the lexical state (recognizedItem) before recognizing the statement separator. Had I put it afterwards, it would recognize the item keyword in look ahead before switching back to the initial state.
This is another thing to be careful with when using lexical states. If you use common border tokens (like quotes), you can avoid problems when you only have one token of look ahead. Otherwise, you have to be careful in how the parser look ahead interacts with the lexer’s lexical states. As a result, combining parsing and lexical states can easily get pretty messy.
28.1.3 Token Type Mutation
The parser’s rules react not to the full contents of the token, but to the token’s type. If we can change the type of a token before it reaches the parser, we can change an item keyword into an item word.
This approach is opposite to lexical states. With lexical states, you need the lexer to feed the parser tokens, one at a time; with this approach, you need to be able to look ahead in the token stream. So it’s no surprise that this approach is better suited to ANTLR than to Yacc, and I’ll therefore switch back.
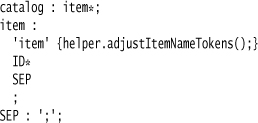
There’s nothing in the grammar that shows what’s going on; all the action occurs in the helper.

The code runs forward along the token stream, turning the token types to ID, until it runs into the separator. (I’ve declared the token type of the separator here to make it available from the helper.)
This technique doesn’t capture exactly what was in the original text, as anything that the lexer skips won’t be offered up to the parser. For example, whitespace isn’t preserved in this method. If that’s an issue, then this technique isn’t the right one to use.
To see this used in a bigger context, take a look at the parser for Hibernate’s HQL. HQL has to deal with the word “order” appearing either as a keyword (in “order by”) or as the name of a column or table. The lexer returns “order” as a keyword by default, but the parser action looks ahead to see if it’s followed by “by”, and if not changes it to be an identifier.
28.1.4 Ignoring Token Types
If the tokens don’t make sense and you want the full text, you can ignore the token types completely and grab every token until you reach a sentinel token (in this case the separator).
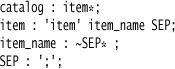
The basic idea is to write the item name rule so it accepts any token other than the separator. ANTLR makes this easy by using a negation operator, but other Parser Generators may not have this capability. If you don’t, you have to do something like:
item : (ID | 'item')* SEP;
You need to list all the keywords in the rule, which is more awkward than just using a negation operator.
The tokens still appear with the correct type, but when you’re doing this you don’t use the type in this context. A grammar with actions might look something like this:
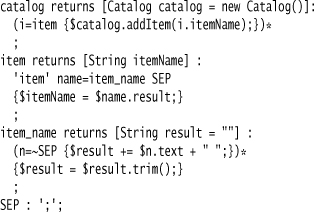
In this case, the text is taken from every token in the name, ignoring the token type. With Tree Construction you’d do something similar, taking all the item name tokens into a single list and then ignoring the token types when processing the tree.
28.2 When to Use It
Alternative Tokenization is relevant when you are using Syntax-Directed Translation with tokenization separated from syntactic analysis—which is the common case. You need to consider it when you have a section of special text that shouldn’t be tokenized using your usual scheme.
Common cases for Alternative Tokenization include: keywords that shouldn’t be recognized as keywords in a particular context, allowing any form of text (typically for prose descriptions), and Foreign Code.