
Chapter 21. Recursive Descent Parser by Rebecca Parsons
Create a top-down parser using control flow for grammar operators and recursive functions for nonterminal recognizers.

Many DSLs are quite simple as languages. While the flexibility of external languages is appealing, using a Parser Generator to create a parser introduces new tools and languages into a project, complicating the build process.
A Recursive Descent Parser supports the flexibility of an external DSL without requiring a Parser Generator. The Recursive Descent Parser can be implemented in whatever general-purpose language one chooses. It uses control flow operators to implement the various grammar operators. Individual methods or functions implement the parsing rules for the different nonterminal symbols in the grammar.
21.1 How It Works
As in the other implementations, we again separate lexical analysis and parsing. A Recursive Descent Parser receives a token stream from a lexical analyzer, such as a Regex Table Lexer.
The basic structure of a Recursive Descent Parser is quite simple. There is a method for each nonterminal symbol in the grammar. This method implements the various production rules associated with the nonterminal. The method returns a Boolean value which represents the result of the match. Failure at any level gets propagated back up the call stack. Each method operates on the token buffer, advancing the pointer through the tokens as it matches some portion of the sentence.
Since there are relatively few grammar operators (sequencing, alternatives, and repetition), these implementation methods take on a small number of patterns. We’ll start with processing alternatives, which uses a conditional statement. For the grammar fragment:
grammar file...
C : A | B
the corresponding function would simply be:

This implementation clearly checks one alternative and then the other, acting more like an ordered alternatives (p. 233). If you truly need to allow for the ambiguity introduced by unordered alternatives, it might be time for a Parser Generator.
After a successful call to A(), the token buffer would now be advanced to begin at the first token past that matched by A. If the call to A() fails, the token buffer remains unchanged.
The sequencing grammar operator is implemented with nested if statements, since we don’t continue processing if one of the methods fails. So, the implementation of:
grammar file...
C : A B
would simply be:

The optional operator is a bit different.
grammar file...
C: A?
We have to try and recognize the tokens matching nonterminal A, but there’s no way to fail here. If we match A, we return true. If we don’t match A, we still return true, since A is optional. The implementation is thus:
boolean C ()
A()
true
If the match for A fails, the token buffer remains where it was at the entry to C. If the match for A succeeds, the buffer is advanced. The call to C succeeds in either case.
The repetition operator has two major forms: zero or more instances (“*”), and one or more instances (“+”). To implement the one or more instances operator, such as this:
grammar file...
C: A+
we would use the following code pattern:

This code first checks to see if at least one A is present. If that is the case, the function continues to find as many more A’s as it can, but it will always return true, because it has matched at least one A—its only requirement. The code for a list that allows zero instances simply removes the outer if statement and always returns true.
The table below summarizes the above using pseudocode fragments to demonstrate the different implementations.

We use the same style of helper functions as in the other sections to keep the actions distinct from the parsing. Tree Construction and Embedded Translation are both possible in recursive descent.
To make this approach as clean as it is, the methods implementing the production rules must behave in a consistent fashion. The most important rule concerns management of the input token buffer. If the method matches what it is looking for, the current position in the input token string is advanced to the point just past the matched input. In the case of the event keyword, the token position is only moved one spot, for example. If the match fails, the position of the buffer should be the same as it was when the method was called. This is of most importance for sequences. At the beginning of the function, we need to save the incoming buffer position, in case the first part of the sequence matches (like A in the above example) but the match for B fails. Managing the buffer thus allows alternatives to be properly handled.
Another important rule relates to the population of the semantic model or syntax tree. As much as possible, each method should manage its own pieces of the model or create its own elements in the syntax tree. Naturally, any actions should only be taken when the full match has been confirmed. As with the token buffer management for sequences, actions must be deferred until the entire sequence completes.
One complaint about Parser Generators is that they require developers to become familiar with language grammars. While it is quite true that the syntax of the grammar operators does not appear in the recursive descent implementation, a grammar clearly exists in the methods. Changing the methods changes the grammar. The difference is not in the presence or absence of the grammar but in how the grammar is expressed.
21.2 When to Use It
The greatest strength of Recursive Descent Parser is its simplicity. Once you understand the basic algorithm and how to handle various grammar operators, writing a Recursive Descent Parser is a simple programming task. You then have a parser in an ordinary class in your system. Testing approaches work in the same way they always do; in particular, a unit test makes more sense when the unit is a method, just like any other. Finally, since the parser is simply a program, it is easy to reason about its behavior and debug the parser. The Recursive Descent Parser is a direct implementation of a parsing algorithm, making the tracing of flow through the parse much easier to discern.
The most serious shortcoming of Recursive Descent Parser is that there is no explicit representation of the grammar. By encoding the grammar into the recursive descent algorithm, you lose the clear picture of the grammar, which can only live in documentation or comments. Both Parser Combinator and Parser Generator have an explicit statement of the grammar, making it easier to understand and evolve.
Another problem with Recursive Descent Parser is that you have a top-down algorithm that can’t handle left-recursion, which makes it more messy to deal with Nested Operator Expressions. Performance will also be usually inferior to a Parser Generator. In practice, these disadvantages aren’t such a factor for DSLs.
A Recursive Descent Parser is straightforward to implement as long as the grammar is reasonably simple. One of the factors that can make it easy to deal with is limited look ahead—that is, how many tokens the parser needs to peek forward to determine what to do next. Generally, I wouldn’t use Recursive Descent Parser for a grammar that requires more than one symbol of look ahead; such grammars are better suited to Parser Generators.
21.3 Further Reading
For more information in a less traditional programming language context, [parr-LIP] is a good reference. The Dragon Book [Dragon] remains the standard of the programming language community.
21.4 Recursive Descent and Miss Grant’s Controller (Java)
We begin with a parser class that includes instance variables for the input buffer, the output of the state machine, and various parsing data. This implementation uses a Regex Table Lexer to create the input token buffer from an input string.

The constructor for the state machine class accepts the input token buffer and sets up the data structures. There’s a very simple method to start the parser, which invokes the function representing our overall state machine.
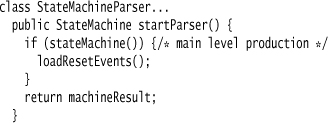
The method startParser is also responsible for the final construction of the state machine in case of success. The only remaining action not covered by the rest of the methods is to populate the reset event in the state machine.
The grammar rule for our state machine is a simple sequence of the different blocks.
![]()
The top-level function is simply a sequence of the various components of the state machine.

We’ll use event declarations to show how most of the functions work together. The first production constructs the event block, made up of a sequence.
![]()
The code for this sequence follows the pattern described above. Notice how the initial buffer position is saved in case the full sequence is not recognized.

The grammar rule for the list of events is straightforward.
grammar file...
eventDecList: eventDec+
The eventDecList function follows the pattern exactly. All the actions are performed in the eventDec function.

The real work happens when matching the event declaration itself. The grammar is straightforward.
grammar file...
eventDec: identifier identifier
The code for this sequence again saves the initial token position. This code also populates the state machine model on a success match.

Two helper functions invoked here require further explanation. First, consumeIdentifier advances the token buffer and returns the token value of the identifier so it can be used to populate the event declaration.

The helper function makeEventDec uses the event name and code to actually populate the event declaration.

From the perspective of the actions, the only real difficulty comes in processing states. Since transitions can refer to states that don’t yet exist, our helper functions must allow for a reference to a state that has not yet been defined. This property holds true for all the implementations that don’t use Tree Construction.
One final method is worthy of description. optionalResetBlock implements this grammar rule.

The implementation we use inlines the different grammar operator patterns, since the rule itself is so simple.

For this method, we return true if the reset keyword is not present, since the whole block is optional. If the keyword is present, we must then have zero or more reset event declarations followed by the end keyword. If these are not present, the match for this block fails and the return value is false.