
Chapter 23. Parser Generator
Build a parser driven by a grammar file as a DSL.
A grammar file is a natural way of describing the syntactic structure of a DSL. Once you have a grammar, it’s tedious work to turn it into a handwritten parser, and tedious work should be done by a computer.
A Parser Generator uses this grammar file to generate a parser. The parser can be updated merely by updating the grammar and regenerating. The generated parser can use efficient techniques that would be hard to build and maintain by hand.
23.1 How It Works
Building your own Parser Generator is no simple task, and anyone who is capable of doing such a thing is unlikely to learn anything from this book. So, here I’ll only talk about using a Parser Generator. Fortunately, Parser Generators are common tools, with some useful forms available in most programming platforms, often as open source.
The usual way to work with a Parser Generator is to write a grammar file. This file will use a particular form of BNF used by that Parser Generator. Don’t expect any standardization here; if you change your Parser Generator, you will have to write a new grammar. For output production, most Parser Generators allow you use Foreign Code to embed code actions.
Once you have a grammar, the usual route is to use the Parser Generator to generate a parser. Most Parser Generators use code generation, which may allow you to generate a parser in different host languages. There’s no reason, of course, why a Parser Generator shouldn’t be able to read a grammar file at runtime and interpret it, perhaps by building a Parser Combinator. Parser Generators use code generation due to a mix of tradition and performance considerations—particularly since they are usually aimed at general-purpose languages.
Mostly, you treat the generated code as a black box and don’t delve into it. It is, however, occasionally useful to follow what the parser is doing—particularly if you are trying to debug your grammar. In this case, there is an advantage in the Parser Generator using an algorithm that’s easier to follow, such as generating a Recursive Descent Parser.
I’ve illustrated many of the patterns in this book using the ANTLR Parser Generator. ANTLR is my usual recommendation for people getting into Parser Generators since it is an easily available, mature tool with good documentation. There’s also a nice IDE-style tool (ANTLRWorks) that provides some very handy UI affordances for developing grammars.
23.1.1 Embedding Actions
Syntactic analysis produces a parse tree; to do something with that tree, we need to embed further code. We place the code in the grammar using Foreign Code. Where we place it in the grammar indicates when the code is executed. Embedded code is placed in rule expressions to be executed as a consequence of the recognition of that rule.
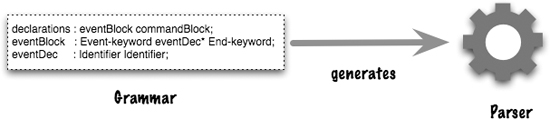
Lets take an example of registering events when we see event declarations.

This would tell us to invoke the registerEvent method just after the parser has recognized the second identifier in an eventDec. In order to pass data from the parse tree into registerEvent, we need some way to refer to the tokens mentioned in the rule. In this case I’m using $1, $2 to indicate the identifiers by position—which is the style of the Yacc Parser Generator.
The actions are usually woven into the generated parser while it is being generated. As a result, the embedded code is usually in the same language as the generated parser.
Different Parser Generator tools have different facilities for embedding code and linking the actions to the rules. While I don’t want to go through all the different features that the many tools have, I think it’s worth highlighting a couple. I’ve already talked about linking the embedded code to identifiers. Since the nature of a parser is to create a parse tree, it’s often useful to move data around this tree. A common and useful facility is thus to allow a subrule to return data to its parent. To illustrate, consider the following grammar using the ANTLR Parser Generator:
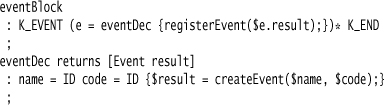
Here the eventDec rule is set to return a value which the higher-level rule can access and use. (With ANTLR, the actions refer to grammar elements by name, which is usually better than by position.) The ability to return values from rules can make it much easier to write parsers—in particular, it can remove a lot of Context Variables. Some Parser Generators, including ANTLR, also have the ability to push data down as arguments to subrules—which allows a lot of flexibility in providing context to subrules.
This fragment also illustrates that the placement of the actions in the grammar defines the moment an action is called. Here, the action in eventBlock is in the middle of the right-hand side, indicating that it should be called after each eventDec subrule is recognized. Placing actions like this is a common feature in Parser Generator.
When using Syntax-Directed Translation, a common problem I’ve seen is to put too much host code in the grammar. When this happens, it’s hard to see the structure of the grammar and the host code is difficult to edit—and requires a regeneration to test and debug. The key pattern here is Embedment Helper—shift as much code as you can to a helper object. The only code in the grammar should be single method calls.
The actions define what we do with the DSL, and the way you write them therefore depends on the overall DSL parsing approach: Tree Construction, Embedded Interpretation, or Embedded Translation. As Parser Generator isn’t really too interesting without one of these, you won’t find any examples in this pattern; instead, take a look at those other patterns for examples.
There’s another animal that’s similar to an action. A semantic predicate, like an action, is a block of Foreign Code, but it returns a Boolean that indicates whether the parse for the rule succeeds or fails. Actions don’t affect the parsing, but semantic predicates do. You usually use a semantic predicate when you’re dealing with areas of a grammar that can’t be captured properly in the grammar language itself. They usually appear in more complicated languages, so they tend to crop up more often in general-purpose languages. But if you’re having difficulty getting a grammar to work with the grammar DSL itself, then a semantic predicate opens the door to more complicated processing.
23.2 When to Use It
For me, the greatest advantage of using a Parser Generator is that it provides an explicit grammar to define the syntactic structure of the language you’re processing. This is, of course, the key advantage of using a DSL. Since Parser Generators are primarily designed to handle complicated languages, they also give you much more features and power than you would get by writing your own parser. While these features may require some effort to learn, you can usually start with a simple set and work your way up from there. Parser Generators may provide good error handling and diagnostics, which, despite my not talking about them, can make a big difference when trying to figure out why your grammar isn’t doing what you think it should.
There are some downsides to a Parser Generator. You may be in a language environment where there isn’t a Parser Generator—and it’s not the kind of thing you should be writing yourself. Even if there is one, you may balk at introducing a new tool to your mix. Since Parser Generators tend to use code generation, they complicate the build process, which can be a significant irritant.
23.3 Hello World (Java and ANTLR)
Whenever you start with a new programming language, it’s traditional to write a “Hello World” program. It’s a good habit because, when you’re not familiar with a new programming environment, there’s usually a certain amount of hassle to sort out before you can run even the simplest program.
A Parser Generator like ANTLR is much the same. It’s good to get a really simple thing going just to ensure you know what the moving parts are and how they fit together. Since I use ANTLR for several examples in this book, it seems worthwhile to run through pulling it together. The basic steps here are also worth knowing for when you play with a different Parser Generator.
The basic operating model of a Parser Generator is this: You write a grammar file and run the Parser Generator tool on that grammar to produce the source code for a parser. You then compile the parser, together with any other code that the parser works with. Then you can parse some files.
23.3.1 Writing the Basic Grammar
Since we’re looking to parse some text, we need some really simple text to parse. Here’s such a file:
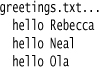
I’m treating this file as a list of greetings, where each greeting is a keyword (hello) followed by a name. Here’s a simple grammar to recognize this:
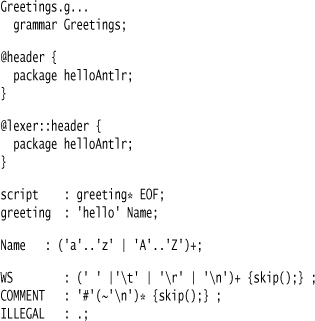
Although simple, the grammar file isn’t as simple as I’d like. The first line declares the name of the grammar.
grammar Greetings;
Unless I want to put everything in the default (empty) package, I need to ensure that the parser I generate goes into the proper package, in this case helloAntlr. I do this by using the @header attribute in the grammar to weave some Java code into the header of the generated parser. This allows me to weave in the package statement. If I needed to add some imports, I’d do that here too.
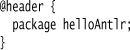
I do the same with the code for the lexer.

Now come the rules that are the meat of the file. Although ANTLR, like most Parser Generators, uses a separate lexer and parser, you generate both of them from a single file. My first two lines say that a script is multiple greetings followed by the end-of-file, and that a greeting is the keyword token hello followed by a Name token.
![]()
ANTLR distinguishes tokens by making them start with an uppercase letter. The name is just a string of letters.
![]()
I usually find it helpful to get rid of whitespace here and declare comments. When things are desperate, comments are a crude but reliable debugging aid.
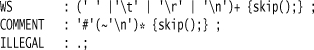
The last token rule (ILLEGAL) causes the lexer to report an error if it runs into a token that doesn’t fit any of its rules (otherwise such tokens are quietly ignored).
At this point, if you’re using the ANTLRWorks IDE, you have enough to run ANTLR’s interpreter and verify that it will read the text. The next step is to generate and run a basic parser.
(A small thing, but something that’s bitten me a couple of times. If you don’t put the EOF at the end of the top rule, ANTLR won’t report errors. It effectively stops parsing at the first point of trouble and doesn’t think anything went wrong. This is particularly awkward because ANTLRWorks will show an error in its interpreter when this happens—so it’s easy to get confused, frustrated, and ready to do violent acts against your monitor.)
23.3.2 Building the Syntactic Analyzer
The next step is to run the ANTLR code generator to generate the ANTLR source files. At this point, it’s time to futz with the build system. The standard build system for Java projects is Ant, so I’ll use that for my example (although at home I’m more likely to use Rake).
To generate the source files, I run the ANTLR tool, which is contained in the library JAR files.

This generates the various ANTLR sources and puts them into the gen directory. I keep the gen directory separate from my core sources. Since they are generated files, I’ll tell my source code control system to ignore them.
The code generator produces a number of source files. For our purposes, the key files are the Java sources for the lexer (GreetingsLexer.java) and the parser (GreetingsParser.java).
These are the generated files. The next step is to use them. I like to write my own class to do this. I call this a greetings loader, as ANTLR has already used the word “parser.” I set it up with a input reader.
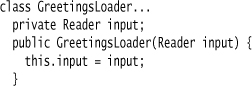
I then write a run method which is the one that actually orchestrates the ANTLR-generated files to do their work.

The basic idea is that I first create a lexer based on the input, followed by a parser that’s based on the lexer. I then call a method on the parser that is named the same as the top rule of my grammar. This will then execute the parser on the input text.
I can run this from a simple test.

This runs clean, but it isn’t very helpful. All it indicates is that the ANTLR parser didn’t blow up when it read the file. That, however, may not even tell you that it read the file without problems. So it’s useful to feed the parser some invalid input.

With the code as it is so far, that test will fail. ANTLR will print a warning telling you it had trouble, but ANTLR is determined to keep on parsing and recover from errors as much as possible. In general, this is a good thing, but particularly early on it can be frustrating to find ANTLR so tolerant and determined.
So, at this point there are issues. First, all the parser is doing is reading the file—not producing any output. Second, it’s hard to tell when it’s going wrong. I can fix both these problems by introducing some more code into the grammar file.
23.3.3 Adding Code Actions to the Grammar
With Syntax-Directed Translation, there are three strategies I can use to produce some output: Tree Construction, Embedded Interpretation, and Embedded Translation. When starting with something like this, I like to use Embedded Translation. This gives me a simple way to see what’s going on.
When I use code actions, I like to use Embedment Helper. The simplest way to use Embedment Helper with ANTLR is to take the loader class I already have and add it into the grammar as a loader. If I do this, I can also do something to better notify the user of errors.
The first stage of this process is to modify the the grammar file to inject some more Java code into the generated parser. I use the members attribute to declare the Embedment Helper and override the default error handling function for reporting an error.

In the loader, I can now provide a simple implementation for error reporting that records errors.
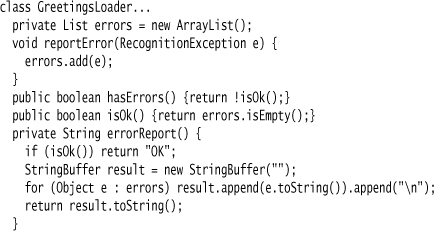
Now all I have to do is add a couple of lines to the run method to set up the helper and throw an exception if the parser reports any errors.

With the helper in place, I can also easily add some code actions to report the names of the people I greeted.

This is all very crude, but it’s enough to ensure that the Parser Generator is generating something that will parse a file, find errors, and communicate with something that will produce an output. Once this silly example is working, I can add some more useful functionality.
23.3.4 Using Generation Gap
Another way of weaving in the helper and error-handling methods into the parser is to use Generation Gap. With this approach, I handwrite a superclass of ANTLR’s generated parser. The generated parser can then use the helper’s methods as bare method calls.
Doing this requires an option in the grammar file. The whole grammar file then looks like this:

I no longer need to override reportErrors as I will do that in my handwritten superclass. Here is that superclass:

This class is a subclass of the base ANTLR parser class, so it has introduced itself into the hierarchy above the generated parser. The handwritten class contains the helper and error-reporting code that was in the separate loader class before. However, it’s still valuable to have a wrapper class to coordinate the running of the parser.

Both the inheritance and delegation relationships have their strengths for the Embedment Helper. I don’t have a strong opinion on the best one to use, and use both of them in this book’s examples.
Much more needs to be done for real work, but I think that these simple examples make a good starting point. You’ll find more examples of using a Parser Generator, including the gothic security state machine, in the rest of the patterns in this part of the book.