
Chapter 1. An Introductory Example
When I start to write, I need to swiftly explain what it is I’m writing about; in this case, to explain what a domain-specific language (DSL) is. I like to do this by showing a concrete example and following up with a more abstract definition. So, here I’m going to start with an example to demonstrate the different forms a DSL can take. In the next chapter I’ll try to generalize the definition into something more widely applicable.
1.1 Gothic Security
I have vague but persistent childhood memories of watching cheesy adventure films on TV. Often, these films would be set in some old castle and feature secret compartments or passages. In order to find them, heroes would need to pull the candle holder at the top of stairs and tap the wall twice.
Let’s imagine a company that decides to build security systems based on this idea. They come in, set up some kind of wireless network, and install little devices that send four-character messages when interesting things happen. For example, a sensor attached to a drawer would send the message D2OP when the drawer is opened. We also have little control devices that respond to four-character command messages—so a device can unlock a door when it hears the message D1UL.
At the center of all this is some controller software that listens to event messages, figures out what to do, and sends command messages. The company bought a job lot of Java-enabled toasters during the dot-com crash and is using them as the controllers. So whenever a customer buys a gothic security system, they come in and fit the building with lots of devices and a toaster with a control program written in Java.
For this example, I’ll focus on this control program. Each customer has individual needs, but once you look at a good sampling, you will soon see common patterns. Miss Grant closes her bedroom door, opens a drawer, and turns on a light to access a secret compartment. Miss Shaw turns on a tap, then opens either of her two compartments by turning on the correct light. Miss Smith has a secret compartment inside a locked closet inside her office. She has to close a door, take a picture off the wall, turn her desk light on three times, open the top drawer of her filing cabinet—and then the closet is unlocked. If she forgets to turn the desk light off before she opens the inner compartment, an alarm will sound.
Although this example is deliberately whimsical, the underlying point isn’t that unusual. What we have is a family of systems that share most components and behaviors, but have some important differences. In this case, the way the controller sends and receives messages is the same across all the customers, but the sequence of events and commands differs. We want to arrange things so that the company can install a new system with the minimum of effort, so it must be easy for them to program the sequence of actions into the controller.
Looking at all these cases, it emerges that a good way to think about the controller is as a state machine. Each sensor sends an event that can change the state of the controller. As the controller enters a state, it can send a command message out to the network.
At this point, I should confess that originally in my writing it was the other way around. A state machine makes a good example for a DSL, so I picked that first. I chose a gothic castle because I get bored of all the other state machine examples.
1.1.1 Miss Grant’s Controller
Although my mythical company has thousands of satisfied customers, we’ll focus on just one: Miss Grant, my favorite. She has a secret compartment in her bedroom that is normally locked and concealed. To open it, she has to close the door, then open the second drawer in her chest and turn her bedside light on—in either order. Once these are done, the secret panel is unlocked for her to open.
I can represent this sequence as a state diagram (Figure 1.1).
Figure 1.1 State diagram for Miss Grant’s secret compartment
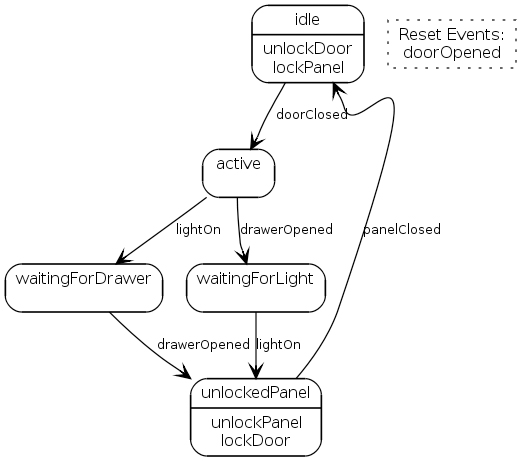
If you haven’t come across state machines yet, they are a common way of describing behavior—not universally useful but well suited to situations like this. The basic idea is that the controller can be in different states. When you’re in a particular state, certain events will transition you to another state that will have different transitions on it; thus a sequence of events leads you from state to state. In this model, actions (sending of commands) occur when you enter a state. (Other kinds of state machines perform actions in different places.)
This controller is, mostly, a simple and conventional state machine, but there is a twist. The customers’ controllers have a distinct idle state that the system spends most of its time in. Certain events can jump the system back into this idle state even if it is in the middle of the more interesting state transitions, effectively resetting the model. In Miss Grant’s case, opening the door is such a reset event.
Introducing reset events means that the state machine described here doesn’t quite fit one of the classical state machine models. There are several variations of state machines that are pretty well known; this model starts with one of these but the reset events add a twist that is unique to this context.
In particular, you should note that reset events aren’t strictly necessary to express Miss Grant’s controller. As an alternative, I could just add a transition to every state, triggered by doorOpened, leading to the idle state. The notion of a reset event is useful because it simplifies the diagram.
1.2 The State Machine Model
Once the team has decided that a state machine is a good abstraction for specifying how the controllers work, the next step is to ensure that abstraction is put into the software itself. If people want to think about controller behavior with events, states, and transitions, then we want that vocabulary to be present in the software code too. This is essentially the Domain-Driven Design principle of Ubiquitous Language [Evans DDD]—that is, we construct a shared language between the domain people (who describe how the building security should work) and programmers.
When working in Java, the natural way to do this is through a Domain Model [Fowler PoEAA] of a state machine.
Figure 1.2 Class diagram of the state machine framework
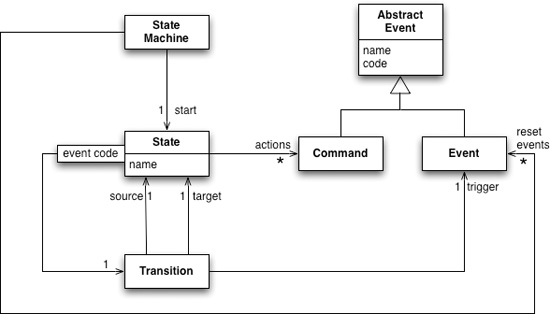
The controller communicates with the devices by receiving event messages and sending command messages. These are both four-letter codes sent through the communication channels. I want to refer to these in the controller code with symbolic names, so I create event and command classes with a code and a name. I keep them as separate classes (with a superclass) as they play different roles in the controller code.

The state class keeps track of the commands that it will send and its outbound transitions.

The state machine holds on to its start state.

Then, any other states in the machine are those reachable from this state.

To handle reset events, I keep a list of them on the state machine.

I don’t need to have a separate structure for reset events like this. I could handle this by simply declaring extra transitions on the state machine like this:

I prefer explicit reset events on the machine because that better expresses my intent. While it does complicate the machine a bit, it makes it clear how a general machine is supposed to work, as well as the intention of defining a particular machine.
With the structure out of the way, let’s move on to the behavior. As it turns out, it’s really quite simple. The controller has a handle method that takes the event code it receives from the device.

It ignores any events that are not registered on the state. For any events that are recognized, it transitions to the target state and executes any commands defined on that target state.
1.3 Programming Miss Grant’s Controller
Now that I’ve implemented the state machine model, I can program Miss Grant’s controller like this:

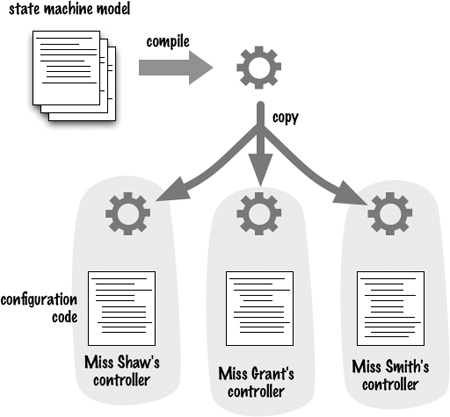
I look at this last bit of code as quite different in nature from the previous pieces. The earlier code described how to build the state machine model; this last bit of code is about configuring that model for one particular controller. You often see divisions like this. On the one hand is the library, framework, or component implementation code; on the other is configuration or component assembly code. Essentially, it is the separation of common code from variable code. We structure the common code in a set of components that we then configure for different purposes.
Figure 1.3 A single library used with multiple configurations
Here is another way of representing that configuration code:


This style of representation should look familiar to most readers; I’ve expressed it as an XML file. There are several advantages to doing it this way. One obvious advantage is that now we don’t have to compile a separate Java program for each controller we put into the field—instead, we can just compile the state machine components plus an appropriate parser into a common JAR, and ship the XML file to be read when the machine starts up. Any changes to the behavior of the controller can be done without having to distribute a new JAR. We do, of course, pay for this in that many mistakes in the syntax of the configuration can only be detected at runtime, although various XML schema systems can help with this a bit. I’m also a big fan of extensive testing, which catches most of the errors with compile-time checking, together with other faults that type checking can’t spot. With this kind of testing in place, I worry much less about moving error detection to runtime.
A second advantage is in the expressiveness of the file itself. We no longer need to worry about the details of making connections through variables. Instead, we have a declarative approach that in many ways reads much more clearly. We’re also limited in that we can only express configuration in this file—limitations like this are often helpful because they can reduce the chances of people making mistakes in the component assembly code.
You often hear people talk about this kind of thing as declarative programming. Our usual model is the imperative model, where we command the computer by a sequence of steps. “Declarative” is a very cloudy term, but it generally applies to approaches that move away from the imperative model. Here we take a step in that direction: We move away from variable shuffling and represent the actions and transitions within a state by subelements in XML.
These advantages are why so many frameworks in Java and C# are configured with XML configuration files. These days, it sometimes feels like you’re doing more programming with XML than with your main programming language.
Here’s another version of the configuration code:


This is code, although not in a syntax that’s familiar to you. In fact, it’s a custom syntax that I made up for this example. I think it’s a syntax that’s easier to write and, above all, easier to read than the XML syntax. It’s terser and avoids a lot of the quoting and noise characters that the XML suffers from. You probably wouldn’t have done it exactly the same way, but the point is that you can construct whatever syntax you and your team prefer. You can still load it in at runtime (like the XML) but you don’t have to (as you don’t with the XML) if you want it at compile time.
This language is a domain-specific language that shares many of the characteristics of DSLs. First, it’s suitable only for a very narrow purpose—it can’t do anything other than configure this particular kind of state machine. As a result, the DSL is very simple—there’s no facility for control structures or anything else. It’s not even Turing-complete. You couldn’t write a whole application in this language; all you can do is describe one small aspect of an application. As a result, the DSL has to be combined with other languages to get anything done. But the simplicity of the DSL means it’s easy to edit and process.
This simplicity makes it easier for those who write the controller software to understand it—but also may make the behavior visible beyond the developers themselves. The people who set up the system may be able to look at this code and understand how it’s supposed to work, even though they don’t understand the core Java code in the controller itself. Even if they only read the DSL, that may be enough to spot errors or to communicate effectively with the Java developers. While there are many practical difficulties in building a DSL that acts as a communication medium with domain experts and business analysts like this, the benefit of bridging the most difficult communication gap in software development is usually worth the attempt.
Now look again at the XML representation. Is this a DSL? I would argue that it is. It’s wrapped in an XML carrier syntax—but it’s still a DSL. This example thus raises a design issue: Is it better to have a custom syntax for a DSL or an XML syntax? The XML syntax can be easier to parse since people are so familiar with parsing XML. (However, it took me about the same amount of time to write the parser for the custom syntax as it did for the XML.) I’d contend that the custom syntax is much easier to read, at least in this case. But however you view this choice, the core tradeoffs of DSLs are the same. Indeed, you can argue that most XML configuration files are essentially DSLs.
Now look at this code. Does this look like a DSL for this problem?

It’s a bit noisier than the custom language earlier, but still pretty clear. Readers whose language likings are similar to mine will probably recognize it as Ruby. Ruby gives me a lot of syntactic options that make for more readable code, so I can make it look very similar to the custom language.
Ruby developers would consider this code to be a DSL. I use a subset of the capabilities of Ruby and capture the same ideas as with our XML and custom syntax. Essentially I’m embedding the DSL into Ruby, using a subset of Ruby as my syntax. To an extent, this is more a matter of attitude than of anything else. I’m choosing to look at the Ruby code through DSL glasses. But it’s a point of view with a long tradition—Lisp programmers often think of creating DSLs inside Lisp.
This brings me to pointing out that there are two kinds of textual DSLs which I call external and internal DSLs. An external DSL is a domain-specific language represented in a separate language to the main programming language it’s working with. This language may use a custom syntax, or it may follow the syntax of another representation such as XML. An internal DSL is a DSL represented within the syntax of a general-purpose language. It’s a stylized use of that language for a domain-specific purpose.
You may also hear the term embedded DSL as a synonym for internal DSL. Although it is fairly widely used, I avoid this term because “embedded language” may also apply to scripting languages embedded within applications, such as VBA in Excel or Scheme in the Gimp.
Now think again about the original Java configuration code. Is this a DSL? I would argue that it isn’t. That code feels like stitching together with an API, while the Ruby code above has more of the feel of a declarative language. Does this mean you can’t do an internal DSL in Java? How about this:


It’s formatted oddly, and uses some unusual programming conventions, but it is valid Java. This I would call a DSL; although it’s more messy than the Ruby DSL, it still has that declarative flow that a DSL needs.
What makes an internal DSL different from a normal API? This is a tough question that I’ll spend more time on later (“Fluent and Command-Query APIs,” p. 68), but it comes down to the rather fuzzy notion of a language-like flow.
Another term you may come across for an internal DSL is a fluent interface. This term emphasizes the fact that an internal DSL is really just a particular kind of API, designed with this elusive quality of fluency. Given this distinction, it’s useful to have a name for a nonfluent API—I’ll use the term command-query API.
1.4 Languages and Semantic Model
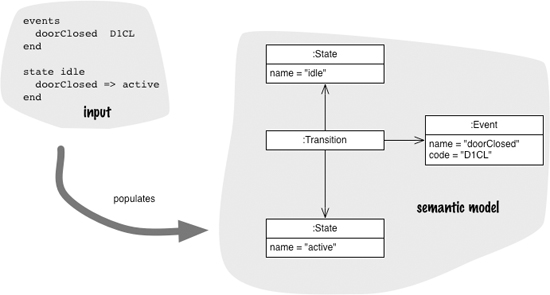
At the beginning of this example, I talked about building a model for a state machine. The presence of such a model, and its relationship with a DSL, are vitally important concerns. In this example, the role of the DSL is to populate the state machine model. So, when I’m parsing the custom syntax version and come across:
events
doorClosed D1CL
I would create a new event object (new Event("doorClosed", "D1CL")) and keep it to one side (in a Symbol Table) so that when I see doorClosed => active I could include it in the transition (using addTransition). The model is the engine that provides the behavior of the state machine. Indeed you can say that most of the power of this design comes from having this model. All the DSL does is provide a readable way of populating that model—that is the difference from the command-query API I started with.
From the DSL’s point of view, I refer to this model as the Semantic Model. When people discuss a programming language, you often hear them talk about syntax and semantics. The syntax captures the legal expressions of the program—everything that in the custom-syntax DSL is captured by the grammar. The semantics of a program is what it means—that is, what it does when it executes. In this case, it is the model that defines the semantics. If you’re used to using Domain Models [Fowler PoEAA], for the moment you can think of a Semantic Model as very close to the same thing.
Figure 1.4 Parsing a DSL populates a Semantic Model.
(Take a look at Semantic Model for the differences between Semantic Model and Domain Model, as well as the differences between a Semantic Model and an abstract syntax tree.)
One opinion I’ve formed is that the Semantic Model is a vital part of a well-designed DSL. In the wild you’ll find some DSLs use a Semantic Model and some do not, but I’m very much of the opinion that you should almost always use a Semantic Model. (I find it almost impossible to say some words, such as “always,” without a qualifying “almost.” I can almost never find a rule that’s universally applicable.)
I advocate a Semantic Model because it provides a clear separation of concerns between parsing a language and the resulting semantics. I can reason about how the state machine works, and carry out enhancement and debugging of the state machine without worrying about the language issues. I can run tests on the state machine model by populating it with a command-query interface. I can evolve the state machine model and the DSL independently, building new features into the model before figuring out how to expose them through the language. Perhaps the most important point is that I can test the model independently of futzing around with the language. Indeed, all the examples of a DSL shown above were built on top of the same Semantic Model and created exactly the same configuration of objects in that model.
In this example, the Semantic Model is an object model. A Semantic Model can also take other forms. It can be a pure data structure with all behavior in separate functions. I would still refer to it as a Semantic Model, because the data structure captures the particular meaning of the DSL script in the context of those functions.
Looking at it from this point of view, the DSL merely acts as a mechanism for expressing how the model is configured. Much of the benefits of using this approach comes from the model rather than the DSLs. The fact that I can easily configure a new state machine for a customer is a property of the model, not the DSL. The fact that I can make a change to a controller at runtime, without compiling, is a feature of the model, not the DSL. The fact I’m reusing code across multiple installations of controllers is a property of the model, not the DSL. Hence the DSL is merely a thin facade over the model.
A model provides many benefits without any DSLs present. As a result, we use them all the time. We use libraries and frameworks to wisely avoid work. In our own software, we construct our models, building up abstractions that allow us to program faster. Good models, whether published as libraries or frameworks or just serving our own code, can work just fine without any DSL in sight.
However, a DSL can enhance the capabilities of a model. The right DSL makes it easier to understand what a particular state machine does. Some DSLs allow you to configure the model at runtime. DSLs are thus a useful adjunct to some models.
The benefits of a DSL are particularly relevant for a state machine, which is particular kind of model whose population effectively acts as the program for the system. If we want to change the behavior of a state machine, we do it by altering the objects in its model and their interrelationships. This style of model is often referred to as an Adaptive Model. The result is a system that blurs the distinction between code and data, because in order to understand the behavior of the state machine you can’t just look at the code; you also have to look at the way object instances are wired together. Of course this is always true to some extent, as any program gives different results with different data, but there is a greater difference here because the presence of the state objects alters the behavior of the system to a significantly greater degree.
Adaptive Models can be very powerful, but they are also often difficult to use because people can’t see any code that defines the particular behavior. A DSL is valuable because it provides an explicit way to represent that code in a form that gives people the sensation of programming the state machine.
The aspect of a state machine that makes it such a good fit for an Adaptive Model is that it is an alternative computational model. Our regular programming languages provide a standard way of thinking about programming a machine, and it works well in many situations. But sometimes we need a different approach, such as State Machine, Production Rule System, or Dependency Network. Using an Adaptive Model is a good way to provide an alternative computational model, and a DSL is good way to make it easier to program that model. Later in the book, I describe a few alternative computational models (“Alternative Computational Models,” p. 113) to give you a feel of what they are like and how you might implement them. You may often hear people refer to DSLs used in this way as declarative programming.
In discussing this example I used a process where the model was built first, and then a DSL was layered over it to help manipulate it. I described it that way because I think that’s an easy way to understand how DSLs fit into software development. Although the model-first case is common, it isn’t the only one. In a different scenario, you would talk with the domain experts and posit that the state machine approach is something they understand. You then work with them to create a DSL that they can understand. In this case, you build the DSL and model simultaneously.
1.5 Using Code Generation
In my discussion so far, I process the DSL to populate the Semantic Model and then execute the Semantic Model to provide the behavior that I want from the controller. This approach is what’s known in language circles as interpretation. When we interpret some text, we parse it and immediately produce the result that we want from the program. (Interpret is a tricky word in software circles, since it carries all sorts of connotations; however, I’ll use it strictly to mean this form of immediate execution.)
In the language world, the alternative to interpretation is compilation. With compilation, we parse some program text and produce an intermediate output, which is then separately processed to provide the behavior we desire. In the context of DSLs, the compilation approach is usually referred to as code generation.
It’s a bit hard to express this distinction using the state machine example, so let’s use another little example. Imagine I have some kind of eligibility rules for people, perhaps to qualify for insurance. One rule might be age between 21 and 40. This rule can be a DSL which we can process in order to test the eligibility of some candidate like me.
With interpretation, the eligibility processor parses the rules and loads up the semantic model while it executes, perhaps at startup. When it tests a candidate, it runs the semantic model against the candidate to get a result.
In the case of compilation, the parser would load the semantic model as part of the build process for the eligibility processor. During the build, the DSL processor would produce some code that would be compiled, packaged up, and incorporated into the eligibility processor, perhaps as some kind of shared library. This intermediate code would then be run to evaluate a candidate.
Our example state machine used interpretation: We parsed the configuration code at runtime and populated the semantic model. But we could generate some code instead, which would avoid having the parser and model code in the toaster.
Figure 1.5 An interpreter parses the text and produces its result in a single process.
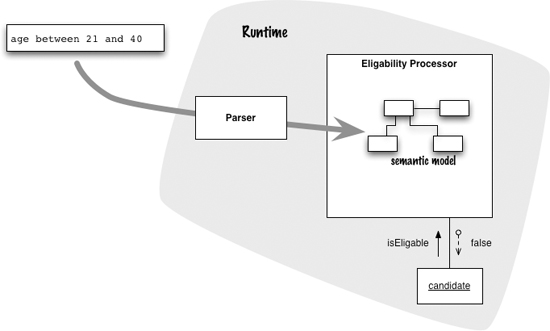
Figure 1.6 A compiler parses the text and produces some intermediate code which is then packaged into another process for execution.
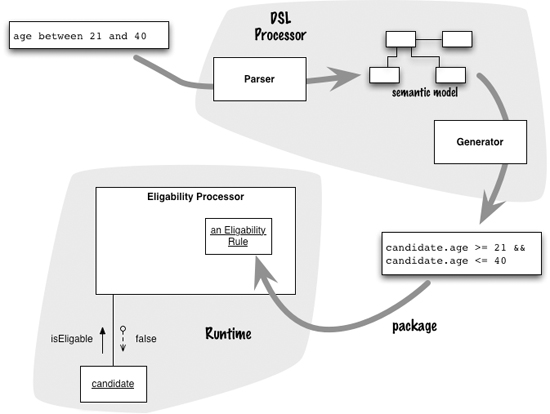
Code generation is often awkward in that it often pushes you to do an extra compilation step. To build your program, you have to first compile the state framework and the parser, then run the parser to generate the source code for Miss Grant’s controller, then compile that generated code. This makes your build process much more complicated.
However, an advantage of code generation is that there’s no particular reason to generate code in the same programming language that you used for the parser. In this case, you can avoid the second compilation step by generating code for a dynamic language such as Javascript or JRuby.
Code generation is also useful when you want to use DSLs with a language platform that doesn’t have the tools for DSL support. If we had to run our security system on some older toasters that only understood compiled C, we could do this by having a code generator that uses a populated Semantic Model as input and produces C code that can then be compiled to run on the older toaster. I’ve come across recent projects that generate code for MathCAD, SQL, and COBOL.
Many writings on DSLs focus on code generation, even to the point of making code generation the primary aim of the exercise. As a result, you can find articles and books extolling the virtues of code generation. In my view, however, code generation is merely an implementation mechanism, one that isn’t actually needed in most cases. Certainly there are plenty of times when you must use code generation, but there are even plenty of times where you don’t need it.
Using code generation is one case where many people don’t use a Semantic Model, but parse the input text and directly produce the generated code. Although this is a common way of working with code-generating DSLs, it isn’t one I recommend for any but the very simplest cases. Using a Semantic Model allows you to separate the parsing, the execution semantics, and the code generation. This separation makes the whole exercise much simpler. It also allows you to change your mind; for example, you can change your DSL from an internal to an external DSL without altering the code generation routines. Similarly, you can easily generate multiple outputs without complicating the parser. You can also use both an interpreted model and code generation off the same Semantic Model.
As a result, for most of my book, I’m going to assume that a Semantic Model is present and is the center of the DSL effort.
I usually see two styles of using code generation. One is to generate “first-pass” code, which is expected to be used as a template but is then modified by hand. The second is to ensure that generated code is never touched by hand, perhaps except for some tracing during debugging. I almost always prefer the latter because this allows code to be regenerated freely. This is particularly true with DSLs, since we want the DSL to be the primary representation of the logic that the DSL defines. This means we must be able to change the DSL easily whenever we want to change behavior. Consequently, we must ensure that any generated code isn’t hand-edited, although it can call, and be called by, handwritten code.
1.6 Using Language Workbenches
The two styles of DSL I’ve shown so far—internal and external—are the traditional ways of thinking about DSLs. They may not be as widely understood and used as they should be, but they have a long history and moderately wide usage. As a result, the rest of this book concentrates on getting you started with these approaches using tools that are mature and easy to obtain.
But there is a whole new category of tools on the horizon that could change the game of DSLs significantly—the tools I call language workbenches. A language workbench is an environment designed to help people create new DSLs, together with high-quality tooling required to use those DSLs effectively.
One of the big disadvantages of using an external DSL is that you’re stuck with relatively limited tooling. Setting up syntax highlighting in a text editor is about as far as most people go. While you can argue that the simplicity of a DSL and the small size of the scripts means that may be enough, there’s also an argument for the kind of sophisticated tooling that modern IDEs support. Language workbenches make it easy to define not just a parser, but also a custom editing environment for that language.
All of this is valuable, but the truly interesting aspect of language workbenches is that they allow a DSL designer to go beyond the traditional text-based source editing to different forms of language. The most obvious example of this is support for diagrammatic languages, which would allow me to specify the secret panel state machine directly with a state transition diagram.
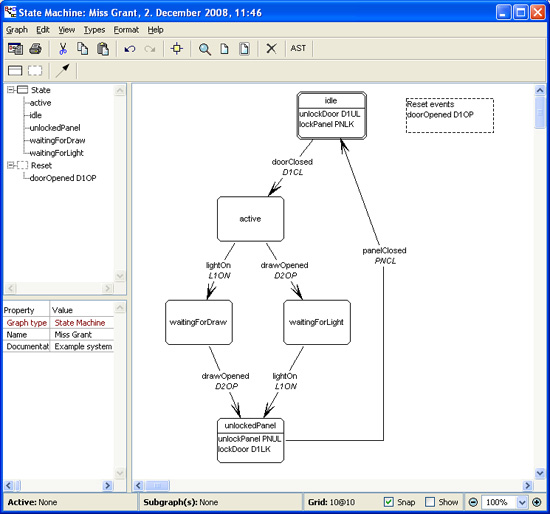
A tool like this not only allows you to define diagrammatic languages; it also allows you to look at a DSL script from different perspectives. In Figure 1.7 we see a diagram, but it also displays lists of states and events and a table to enter the event codes (which could be omitted from the diagram if there’s too much clutter there).
This kind of multipane visual editing environment has been available for a while in lots of tools, but it’s been a lot of effort to build something like this for yourself. One promise of language workbenches is that they make it quite easy to do this; indeed I was able to put together an example similar to Figure 1.7 quite quickly on my first play with the MetaEdit tool. The tool allows me to define the Semantic Model for state machines, define the graphical and tabular editors in Figure 1.7, and write a code generator from the Semantic Model.
Figure 1.7 The secret panel state machine in the MetaEdit language workbench (source: MetaCase)
However, while such tools certainly look good, many developers are naturally suspicious of such doodleware tools. There are some very pragmatic reasons why a textual source representation makes sense. As a result, other tools head in that direction, providing post-IntelliJ-style capabilities—such as syntax-directed editing, autocompletion, and the like—for textual languages.
My suspicion is that, if language workbenches really take off, the languages they’ll produce won’t be anything like what we consider a programming language. One of the common benefits of such tools is that they allow nonprogrammers to program. I often sniff at that notion by pointing out that this was the original intent of COBOL. Yet I must also acknowledge a programming environment that has been extremely successful in providing programming tools to nonprogrammers who program without thinking of themselves as programmers—spreadsheets.
Many people don’t think about spreadsheets as a programming environment, yet it can be argued that they are the most successful programming environment we currently know. As a programming environment, spreadsheets have some interesting characteristics. One of these is the close integration of tooling into the programming environment. There’s no notion of a tool-independent text representation that’s processed by a parser. The tools and the language are closely intertwined and designed together.
A second interesting element is something I call illustrative programming. When you look at a spreadsheet, the thing that’s most visible isn’t the formulae that do all the calculations; rather, it’s the numbers that form a sample calculation. These numbers are an illustration of what the program does when it executes. In most programming languages, it’s the program that’s front-and-center, and we only see its output when we make a test run. In a spreadsheet, the output is front-and-center and we only see the program when we click in one of the cells.
Illustrative programming isn’t a concept that’s got much attention; I even had to make up a word to talk about it. It could be an important part of what makes spreadsheets so accessible to lay programmers. It also has disadvantages; for one thing, the lack of focus on program structure leads to lots of copy-paste programming and poorly structured programs.
Language workbenches support developing new kinds of programming platforms like this. As a result, I think the DSLs they produce are likely to be closer to a spreadsheet than to the DSLs that we usually think of (and that I talk about in this book).
I think that language workbenches have a remarkable potential. If they fulfill this they could entirely change the face of software development. Yet this potential, however profound, is still somewhat in the future. It’s still early days for language workbenches, with new approaches appearing regularly and older tools still subject to deep evolution. That is why I don’t have that much to say about them here, as I think they will change quite dramatically during the hoped-for lifetime of this book. But I do have a chapter on them at the end, as I think they are well worth keeping an eye on.
1.7 Visualization
One of the great advantages of a language workbench is that it enables you to use a wider range of representations of the DSL, in particular graphical representations. However, even with a textual DSL you can obtain a diagrammatic representation. Indeed, we saw this very early on in this chapter. When looking at Figure 1.1, you might have noticed that the diagram is not as neatly drawn as I usually do. The reason for this is that I didn’t draw the diagram; I generated it automatically from the Semantic Model of Miss Grant’s controller. Not only do my state machine classes execute; they are also able to render themselves using the DOT language.
The DOT language is part of the Graphviz package, which is an open source tool that allows you to describe mathematical graph structures (nodes and edges) and then automatically plot them. You just tell it what the nodes and edges are, what shapes to use, and some other hints, and it figures out how to lay out the graph.
Using a tool like Graphviz is extremely helpful for many kinds of DSLs because it gives you another representation. This visualization representation is similar to the DSL itself in that it allows a human to understand the model. The visualization differs from the source in that it isn’t editable—but on the other hand, it can do something an editable form cannot, such as a render diagram like this.
Visualizations don’t have to be graphical. I often use a simple textual visualization to help me debug when I’m writing a parser. I’ve seen people generate visualizations in Excel to help them communicate with domain experts. The point is that, once you have done the hard work of creating a Semantic Model, adding visualizations is really easy. Note that the visualizations are produced from the model, not the DSL, so you can do this even if you aren’t using a DSL to populate the model.