
Chapter 12. Symbol Table
A location to store all identifiable objects during a parse to resolve references.
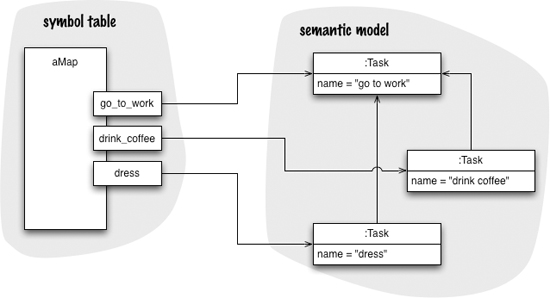
Many languages need to refer to objects at multiple points within the code. If we have a language that defines a configuration of tasks and their dependencies, we need a way for one task to refer to its dependent tasks in its definition.
In order to do this, we come up with some form of symbol for each task; while processing the DSL script, we put these symbols in a Symbol Table that stores the link between the symbol and an underlying object that holds the full information.
12.1 How It Works
The essential purpose of a Symbol Table is to map between a symbol used to refer to an object in a DSL script and the object that symbol refers to. A mapping like this naturally fits with the notion of a map data structure, so it’s no surprise that the most common implementation of a Symbol Table is a map with the symbol as a key and the Semantic Model object as a value.
One question to consider is the kind of object that should be used as the key in the Symbol Table. For many languages, the most obvious choice is a string, since the text of the DSL is a string.
The main case to use something other than a string is with languages that support a symbol data type. Symbols are like strings in a structural sense—a symbol is fundamentally a sequence of characters—but they usually differ in behavior. Many string operations (concatenation, substrings, etc.) do not make sense for symbols. The principal task of symbols is to be used for lookup, and symbol types are usually designed with that in mind. So, while the two strings, "foo" and "foo", are often different objects and are compared for equality by looking at their contents, the symbols :foo and :foo always resolve to the same object and can be compared for equality much faster.
Performance can be a good reason for preferring symbol data types to strings, but for small DSLs it may not make much difference. The big reason to prefer a symbol data type is that it clearly communicates your intention in using it. By declaring something as a symbol, you state clearly what you are using it for and thus make your code easier to understand.
Languages that support symbols usually have a particular literal syntax for them. Ruby uses :aSymbol, Smalltalk uses #aSymbol, and Lisp treats any bare identifier as a symbol. This makes symbols stand out all the more in internal DSLs—a further reason to use them.
The values in a symbol table can either be final model objects or intermediate builders. Using model objects makes the Symbol Table act as result data, which is good for simple situations—but putting a builder object as the value often provides more flexibility, at the cost of a bit more work.
Many languages have different kinds of objects that need to be referred to. The introductory state model needs to identify states, commands, and events. Having multiple kinds of things to refer to means you have to choose between a single map, multiple maps, or a special class.
Using a single map for your Symbol Table means that all lookups for any symbol use the same map. An immediate consequence of this is that you can’t use the same symbol name for different kinds of things—you can’t have an event with the same name as a state. This may be a useful constraint to reduce confusion in the DSL. However, using a single map makes it harder to read the processing code as it’s less clear what kind of thing is being manipulated when you refer to the symbol. I therefore don’t recommend this option.
With multiple maps, you have a separate map for each kind of objects you are referring to. For example, a state model may have three maps for events, commands, and states. You may think of this as one logical Symbol Table or three Symbol Tables. Either way, I prefer this option to a single map, as it’s now clear in the code which kind of object you are referring to in the processing steps.
Using a special class means having a single object for the Symbol Table with different methods to refer to the different kinds of objects stored in there: getEvent(String code), getState(String code), registerEvent(String code, Event object), etc. This can sometimes be useful, and it does give a natural place to add any specific symbol-processing behavior. Most of the time, however, I don’t find a compelling need to do this.
In some cases, objects are referred to before they are properly defined—these are called forward references. DSLs don’t usually have strict rules about declaring identifiers before you use them, so forward references often make sense. If you allow forward references, you need to ensure that any reference to a symbol will populate the entry in the symbol table if it isn’t already there. This will often push you to use builders as the values in the symbol table, unless the model objects are very flexible.
If there’s no explicit declaration of symbols, you also need to be wary of misspelled symbols, which can be a frustrating source of errors. There may be some way you can detect misspelled symbols, and putting that kind of checking in will prevent a lot of hair-pulling. This problem is one reason to require that all symbols are declared in some way. If you choose to require an explicit declaration, remember that symbols don’t need to be declared before usage.
More complicated languages often have nested scopes, where symbols are only defined in a subset of the overall program. This is very common in general-purpose languages, but much rarer in simpler DSLs. If you do need to do this, you can support this by using a Symbol Table for Nested Scopes [parr-LIP].
12.1.1 Statically Typed Symbols
If you are doing an internal DSL in a statically typed language, such as C# or Java, you can easily use a hashmap as your Symbol Table with strings as keys. A line of such a DSL might look something like this:
task("drinkCoffee").dependsOn("make_coffee", "wash");
Using strings like this certainly will work, but it comes with some disadvantages.
• Strings introduce syntactic noise, since you have to quote them.
• The compiler can’t do any type checking. If you misspell your task names, you only discover that at runtime. Furthermore, if you have different kinds of objects that you identify, the compiler can’t tell if you refer to the wrong type—again, you only discover this at runtime.
• If you use a modern IDE, it can’t do autocompletion on strings. This means you lose a powerful element of programming assistance.
• Automated refactorings may not work well with strings.
You can avoid these problems by using some kind of statically typed symbol. Enums make a good simple choice, as does a Class Symbol Table.
12.2 When to Use It
Symbol Tables are common to any language-processing exercise, and I expect you’ll almost always need to use them.
There are times when they aren’t strictly necessary. With Tree Construction, you can always delve around in the syntax tree to find things. Often, a search on the Semantic Model that you’re building up could do the job. But sometimes, you need some intermediate store, and even when you don’t, it often makes life easier.
12.3 Further Reading
[parr-LIP] provides a lot of detail on using various kinds of Symbol Table for external DSLs. Since Symbol Table is also a valuable technique for internal DSLs, many of these approaches are likely to be appropriate for internal DSLs as well.
[Kabanov et al.] provides some useful ideas for using statically typed symbols in Java. As usual, these ideas are often usable in other languages too.
12.4 Dependency Network in an External DSL (Java and ANTLR)
Here’s a simple dependency network:
go_to_work -> drink_coffee dress
drink_coffee -> make_coffee wash
dress -> wash
The task on the left-hand side of “→” is dependent on the tasks named on the right-hand side. I’m parsing this using Embedded Translation. I want to be able to write the dependencies in any order and return a list of the heads—that is, those tasks that aren’t a prerequisite of any other task. This is a good example of where it’s worthwhile to keep track of the tasks in a Symbol Table.
As is my habit, I write a loader class to wrap the ANTLR parser; this will take input from a reader:

The loader inserts itself as the Embedment Helper to the generated parser. One of the helpful things it provides is the symbol table, which is a simple map of task names to tasks.
class TaskLoader...
private Map<String, Task> tasks = new HashMap<String, Task>();
The grammar for this DSL is extremely simple.

The helper contains the code that handles the recognized dependency. To link together the tasks, it both populates and uses the Symbol Table.
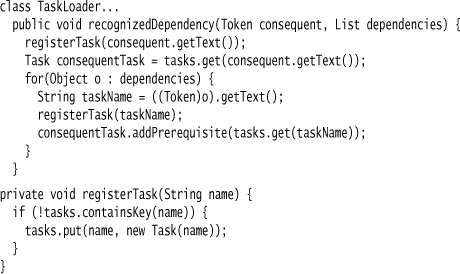
Once the loader has run, it can be asked for the heads of the graph.

12.5 Using Symbolic Keys in an Internal DSL (Ruby)
Symbol Tables come from the world of parsing, but they are just as useful with internal DSLs. For this example, I use Ruby to show the use of a symbol data type, which is the type to use if you have it in your language. Here’s the simple DSL script with breakfast tasks and prerequisites:
task :go_to_work => [:drink_coffee, :dress]
task :drink_coffee => [:make_coffee, :wash]
task :dress => [:wash]
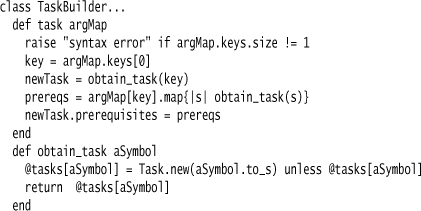
Each task is referred to in the DSL by Ruby’s symbol data type. I use Function Sequence to declare the list of tasks, with the details of each task shown using a Literal Map.
The Semantic Model is simple to describe, just a single task class.

The DSL script is read by an Expression Builder that uses Object Scoping with instance_eval.

The Symbol Table is a simple dictionary.
The task clause takes the single hash association argument and uses it to populate the task information.
The implementation of a Symbol Table using symbols is the same as with strings for identifiers. However, you should use symbols if they are available.
12.6 Using Enums for Statically Typed Symbols (Java)
Michael Hunger has been a very diligent reviewer of this book; he has steadily urged me to describe using enums as statically typed symbols, as it is a technique he’s had much success with. Many people like static typing for its ability to find errors, which isn’t something I’m as enthused about since I feel that static typing catches few errors that won’t be caught by decent testing—which you need with or without static typing. But one great advantage of static typing is that it works well with modern IDEs. It’s nice to just be able to type Control-Space and get a list of all the symbols that are valid for this point in a program.
I’ll use the task example again, with exactly the same Semantic Model as earlier. The Semantic Model has strings for task names, but in the DSL I’ll use enums. That will not only give me autocompletion, but it will also guard against typos. The enum is simple.
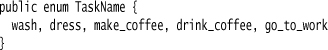
I can use this to define my task dependencies like this:

I’m using Java’s instance initializer here for Object Scoping. I also use a static import for the task name enum, which allows me to use the bare task names in the script. With these two techniques, I’m able to write the script in any class without needing to use inheritance that would force me to write it in a subclass of the Expression Builder.
The task builder builds up a map of tasks; each call to task registers a task in the map.

The prerequisite clause is a child builder class.
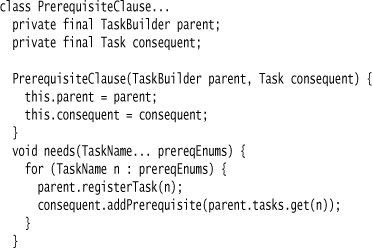
I made the child builder a static inner class of the task builder so it could access private members of the task builder. I could have gone further and made it an instance inner class; then I wouldn’t have needed the reference to the parent. I didn’t do this as it may be hard to follow for readers less familiar with Java.
Using enums like this is quite easy, and it’s nice that it doesn’t force inheritance or constraints on where you can write DSL script code—an advantage compared to a Class Symbol Table.
With an approach like this, bear in mind that if the set of symbols needs to correspond to some external data source, you can write a step that reads the external data source and code-generates the enum declarations, so that everything is kept in sync [Kabanov et al.].
A consequence of this implementation is that I have a single namespace of symbols. This is fine when you have multiple little scripts that share the same set of symbols, but sometimes you want different scripts to have different sets of symbols.
Suppose I have two sets of tasks, one devoted to morning tasks (such as those above) and the other dedicated to snow shoveling. (Yes, I’m thinking of that as I look at my driveway today.) When I’m working on morning tasks, I only want to see them offered to me by my IDE, and similarly for snow-shoveling tasks.
I can support this by defining my task builder in terms of an interface and having my enums implement that interface.
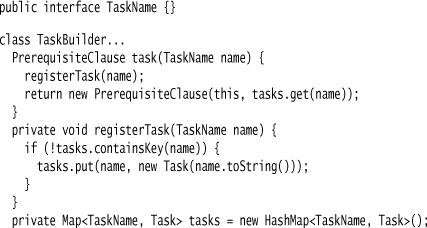
I can then define some enums and use them for a specific group of tasks by selectively importing the ones I need.

If I want even more static type control, I could make a generic version of the task builder that would check that it’s using the correct subtype of TaskName. But if you’re primarily interested in good IDE usability, then selectively importing the right set of enums is good enough.